3005
Comparative Study On Effort Estimation Using
Different Data Mining Techniques
Prof. A. J. Singh, Mukesh Kumar
Abstract:Machine Learning (ML) technique is one of the most efficient ways to analyze the performance of the student in academics and hence, the total effort required for that. In this paper, different ML techniques are taken into consideration and consequently evaluated based on the overall effort needed for analyzing the student dataset. Estimating total effort is one of the important parameters to check the success or failure of any software application projects. Here, Naive-Bayes (NB), Random Forest (RF), Artificial Neural Network (ANN) and Support Vector Machine (SVM) techniques of ML has taken into consideration for estimating the total effort of the project. In our implementation of MATLAB, ANN-ML techniques gave us better accuracy as compared to NB, RF, and SVM. The average effort estimation by the ANN-ML algorithm is 39.148, which is much better than NB-ML (50.67), RF-ML (51.87) and SVM-ML (44.61).
Index Term: Artificial Neural Network, Machine Learning, Data Mining, Effort Estimation, Random Forest, MATLAB, Support Vector Machine
————————————————————
1.
INTRODUCTION
EE-ML is used to accurately predict the total effort required to develop a software application projects. EE-ML not only includes the software development effort but also estimating the overall effort needed for its maintenance. In some research papers, the term effort estimation is often used interchangeably with cost estimation. It has believed that, if estimating the total effort required of any software application development in advanced is crucial in practical software development execution. Since the 1990s, lots of effort estimation methods have proposed by the research community around the world in EE-ML domain. Jørgensen and Shepperd in his study found that regression-based algorithms are dominating in EE-ML domain, and the exercising of traditional methods like expert judgment and analogy techniques has decreased. Nowadays, ML algorithms have been receiving more attention in EE-ML research community. Boehm and Sullivan, in his study, found the learning-oriented technology is most critical software effort estimation techniques. EE-ML is an essential area of the software engineering development process. If effort estimated is not calculated accurately, then it may lead to compromise the quality and testing of the development process of software application. The overestimation of effort may also lead to the over-allocation of the workforce and resource. In this paper, implementing techniques like ANN, NB, RF, SVM and DT to estimate the total effort required for any software application development.
2.
LITERATURE SURVEY
There is many effort estimation models are developed in recent years and has surveyed. The effort done by the different researcher has been discussed here: R. Malhotra and A. Jain presented a paper titled "Software Effort Prediction using Statistical and Machine Learning Methods ". In this paper, authors estimate and compares different machine learning algorithms like Linear Regression, Artificial Neural Network, Decision Tree, Support Vector Machine and Bagging techniques on software project dataset. In his work, they used a dataset which has further taken from 499 different software projects. Initially, the dataset contains 19 features, but after pre-processing only ten features are selected using feature selection algorithms
3006 authors implemented a Neural Fuzzy machine learning
algorithm to predict the total cost of the project. They compared the implemented algorithm with ML techniques like Least-squares multiple linear regression and Neural Network algorithms. The results of their analysis show that the predictive accuracy of different ML techniques varies according to the dataset used. After a review on Effort Estimation, we found that Artificial Neural Network, Regression Tree, Regression Analysis, Decision Tree, Random Forest, Logistic Regression, Naive Bayes, K-Nearest Neighbor, Case-based reasoning, Support Vector Machine and Fuzzy Logic are the most used algorithm. But in our research study here, we selected four ML algorithms (ANN, RF, NB and SVM) for estimating total effort for developing a software application.
3.
IMPLEMENTATION OF THE MACHINE
LEARNING ALGORITHMS
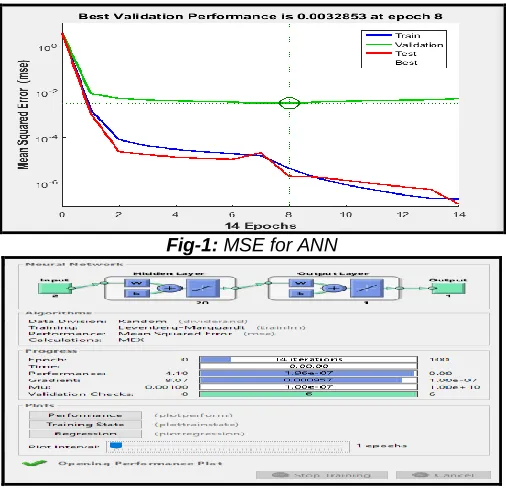
In this section, different ML algorithms are implemented using MATLAB software toolkit. MATLAB is very helpful for the development of high-performance computing. Data visualisation, advanced programming, integrating computation, supports OOP, data structures and built-in editing and debugging tools make MATLAB an excellent tool for the research community. The most typical uses of MATLAB include simulation, data analysis (DA), software application, graphical user interface (GUI), algorithm building, data visualisation etc. Due to reason mentioned above; we are selecting MATLAB for the implementation purpose in work research work. Artificial Neural Network Algorithm Implementation: This is a supervised approach as the other algorithms in the proposed work. The algorithmic architecture takes the group-1 element and group-2 elements and cross-validates those utilising propagating neurons. A total of 50 neurons has supplied into the test scenario with a varying epoch counter from 100-1000. Artificial Neural Network classification algorithm trains on the training data taken from given dataset based on the segmented values of K-Means. This particular classification algorithm provides multiple validation factors likes Mean Square Error, as shown in Fig - 1. So, our evaluation criteria for this dataset has based on Mean Square Error for ANN. The performance of the ANN algorithm is represented in the form of a graph, as shown in fig - 1. The training of the ANN algorithm has concluded for 14 iterations. In fig-1, four lines represented by different colours blue, green, red and dotted line signifies training, validation, test value and best value of ANN algorithm respectively. The best value is achieved at 8th iteration with Mean Square Error less than 0.1. Lower the cost of Mean Square Error better is the training of the ANN algorithm.
Fig-1: MSE for ANN
Fig-2: ANN using MATLAB interface
Total Effort Estimation helps in the evaluation of the correctness and effort required to group the elements for the evaluation of the students. Table-1 illustrates the values of the total effort applied for the algorithms.
overallmse = (sum (res-group)/numel(group))^2;
effort = ((1-overallmse) * 100)-(overallmse * numel (group));
Table-1: Effort Estimation by ANN
Student Records Effort Estimation by ANN
100 23.56
200 31.25
300 39.336
400 41.256
500 48.339
600 51.148
From Table -1 and fig -3, it is clear that as the student record increases the effort required to analyse the student performance is
Fig-3: Graphical representation
3007 X-axis represents the petal length, and Y-axis represent the
petal width. Here, the red and blue colour represents the two data types. Below fig – 4 represent the performance of the NB Algorithm on student dataset has taken into consideration.
Fig - 4: NB using MATLAB Interface
Table - 2: Effort Estimated by NB
Student Records Effort Estimated by NB
100 36.336
200 42.125
300 51.145
400 53.332
500 57.896
Figure - 5 and Table - 2 shows the effort estimation utilising the Naïve Bayes Algorithm. In Figure - 5, X-axis shows the records of the total number of supplied student data and for the estimation, 600 students' records have considered, and Y-axis shows the
Fig – 5: Graphical Representation of NB
values obtained after the evaluation. The average value of Effort Estimation by Naïve Bayes Algorithm is 50.67. Random Forest Algorithm Implementation: RF algorithm is bendy, user-friendly ML algorithm, which produces outstanding results in almost all situations. It is a supervised classification algorithm. Below is the implementation result which has implemented in the MATLAB tool. Student data with different records are taken as input and then estimating the total effort required has calculated. Below table - 3 give us the result.
Table - 3: Effort Estimated by RF
Student Records Effort Estimated by RF
100 36.7854
200 43.14
300 52.221
400 55.69
500 59.325
600 64.112
Fig - 6: Effort Estimated by RF
Figure - 6 and Table – 3, shows the Effort Estimation utilising Random Forest Algorithm. In Figure - 6, X-axis shows the records of the total number of supplied student data for the effort estimation, 600 student’s records has considered, and Y-axis shows the values obtained after the evaluation. The average value of effort estimation by the Random Forest algorithm is 51.87. Support Vector Machine Implementation: This algorithm is a classifier technique which executes classification tasks through building hyper-planes in a multi-dimensional space, which divides cases of different and dissimilar class labels. It helps both types of tasks which are a regression in addition to classification tasks and also can handle numerous categorical as well as continuous variables. It can have used in separating of categories, points in space, mapping of data. Linear SVM has used for solving multiclass classification task. Linear
SVM gives high accuracy, Vandana Korde et al. (2002).
Fig - 7: Regression State of SVM
Fig - 8: SVM plot
3008 is 0.99996, then the testing data is equal to 0, validation
value is 0.99132 and regression value is 0.99611. The regression value represents the output measured by combining training, testing and validation values. The performance of the system has measured in terms of classification accuracy, classification error and time of calculation.
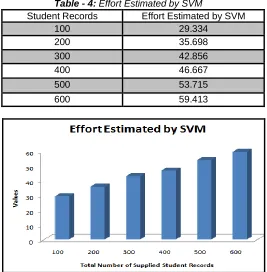
Table - 4: Effort Estimated by SVM
Student Records Effort Estimated by SVM
100 29.334
200 35.698
300 42.856
400 46.667
500 53.715
600 59.413
Fig -9: Effort Estimated by SVM
Fig - 9 represents the SVM plot for the proposed classification algorithm. The training of the classifier using the SVM classification algorithm has shown in the graphical form in fig - 8. The plus sign in red colour represents the training data, whereas cyan plus sign represents the classification data of the category-1. The category-2 data has represented by a star, where the green star represents the training data, and cyan colour represents the classified data. The black circle represents the support vector data which is used to train the model. The average value of effort estimation by the SVM algorithm is 44.61.
4.
RESULT AND DISCUSSION
For the classification of the data to have accurate analysis and prediction, several classification algorithms have considered. In this research, ANN, NB, RF and SVM algorithm has used. RF algorithm has utilised, which helps in classification and regression problems. Subsequently, the implementations of these algorithms according to their execution, has explained above.
Table – 5: Effort Estimation by ANN, NB, RF, SVM Techniques
From table – 5 above, the average value of EE-ML by Artificial Neural Network is 39.148, which are much lower than other ML algorithms used. The average effort estimation for the Naive Bayes algorithm is 50.67, Random Forest Algorithm is 51.87, and for Support Vector Machine are 44.61. So from the above implementation result of ML algorithms that ANN performs much better than another algorithm. As we can see, the values of EE are rapidly increasing as the student record increase in the entire algorithm, but overall the accuracy of ANN is better, and RF performs worst.
Fig – 10: Graphical representation of EE-ML by ANN, NB, RF and SVM Techniques
From fig – 10, X-axis represents the number of students, and Y-axis represents the total effort required for estimation. In the figure above the blue bar, which represents the ANN algorithm, have a lower value than other algorithms.
5.
CONCLUSION
In this paper, we implement the four selected ML algorithm to estimate the total effort required to develop a software application and then compare their results. EE-ML approaches could be appropriate in effort estimation, which accurately calculates estimation as compared to the traditional method. There are so many factors that impact effort estimates such as concurrency, software complexity, computer platform and different site characteristics in case
Student Records
Effort Estimation
(ANN)
Effort Estimated
(NB)
Effort Estimated
(RF)
Effort Estimated
(SVM)
100 23.56 36.336 36.78 29.334
200 31.25 42.125 43.14 35.698
300 39.336 51.145 52.221 42.856
400 41.256 53.332 55.69 46.667
500 48.339 57.896 59.325 53.715
600 51.148 63.21 64.112 59.413
3009 of software development. Researchers have developed
different methods for estimation, but there is no estimation method, which can present the best estimates in all various situations, and each technique can be suitable in a particular project. The average value of EE-ML by Artificial Neural Network is 39.148, which are much lower than other ML algorithms used. The average effort estimation for the Naive Bayes algorithm is 50.67, Random Forest Algorithm is 51.87, and for Support Vector Machine are 44.61. So from the above implementation result of ML algorithms that ANN performs much better than another algorithm.
REFERENCE:
[1] M. O. Elish, ―Improved Estimation of Software Project Effort using Multiple Additive Regression Tree,‖ Expert Systems with Applications, vol.36, pp. 10774-10778, 2009.
[2] L. Radlinki and W. Hoffmann, ―On Predicting Software Development Effort Using Machine Learning Techniques and Local Data,‖ International Journal of Software Engineering and Computing, vol. 2, pp.123-136, 2010. [3] R. Malhotra, A. Jain, ―Software Effort Prediction using
Statistical and Machine Learning Methods,‖ International Journal of Advanced Computer Science and Applications, vol.2, No.1, January 2011.
[4] Ruchika Malhotra, ―Software Effort Prediction using Statistical and Machine Learning Methods‖, (IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 2, No.1, January 2011
[5] Jonathan Lee, Wen-Tin Lee, Jong-Yih Kuo, "Fuzzy Logic as a Basis for Use Case Point Estimation" IEEE International Conference on Fuzzy Systems, June 27-30, Taipei, Taiwan, 2011
[6] Khaled Hamdan, Mohamed Madi,‖ Software Project Effort: Different Methods of Estimation‖, International Conference on Communications and Information Technology (ICCIT), Aqaba., IEEE, 2011
[7] Abdulbasit S. Banga ―Software Estimation Techniques‖ National Conference; INDIACom-2011 Computing for Nation Development, March 10 – 11, 2011
[8] Roheet Bhatnagar1 and Mrinal Kanti Ghose, "Comparing Soft Computing Techniques For Early Stage Software Development Effort Estimation" International Journal of Software Engineering & Applications (IJSEA), Vol.3, No.2, March 2012
[9] Berna Seref and Necaattin Barisci, "Software Effort Estimation Using Multilayer Perceptron and Adaptive Neuro-Fuzzy Inference System" International Journal of Innovation, Management and Technology, Vol. 5, No. 5, October 2014
[10] N.-H. Chiu, S.-J. Huang, The adjusted analogy-based software effort estimation based on similarity distances, Journal of Systems and Software 80 (4) (2007) 628– 640.
[11] C. Mair, M. Shepperd, The consistency of empirical comparisons of regression and analogy-based software project cost prediction, in Proceedings of the International Symposium on Empirical Software Engineering, 2005, pp. 509–518.
[12] M. Shepperd, Software project economics: a roadmap, in: Proceedings of the Conference on Future of Software Engineering, Minneapolis, MN, USA, 2007, pp. 304–315.
[13] E. Mendes, I. Watson, C. Triggs, N. Mosley, S. Counsell, A comparative study of cost estimation models for web hypermedia applications, Empirical Software Engineering 8 (2) (2003) 163–196.
[14] IFB Tronto, J.D.S. Silva, N.S. Anna, An investigation of artificial neural networks based prediction systems in software project management, Journal of Systems and Software 81 (3) (2008) 356–367.
[15] P. Brereton, B.A. Kitchenham, D. Budgen, M. Turner, M. Khalil, Lessons from applying the systematic literature review process within the software engineering domain, Journal of Systems and Software 80 (4) (2007) 571–583.
[16] L.M. Pickard, B.A. Kitchenham, P.W. Jones, Combining empirical results in software engineering, Information and Software Technology 40 (14) (1998) 811–821. [17] G. Zhang, B.E. Patuwo, M.Y. Hu, Forecasting with
artificial neural networks: state of the art, International Journal of Forecasting 14 (1) (1998) 35–62.
[18] A.J. Albrecht, Measuring application development productivity, in Proceedings of the Joint
SHARE/GUIDE/IBM Application Development
Symposium, Monterey, CA, USA, 1979, pp. 83–92. [19] C.J. Burgess, M. Lefley, Can genetic programming
improve software effort estimation? a comparative evaluation, Information and Software Technology 43 (14) (2001) 863–873.
[20] A. Corazza, SD. Martino, F. Ferrucci, C. Gravino, E. Mendes, Investigating the use of support vector regression for web effort estimation, Empirical Software Engineering (2010) 1–33.
[21] A. Corazza, SD. Martino, F. Ferrucci, C. Gravino, F. Sarro, E. Mendes, How effective is tabu search to configure support vector regression for effort estimation?, in: Proceedings of the 6th International Conference on Predictor Models in Software Engineering, Timisoara, Romania, 2010, pp. 1–10. [22] R.A. Araújo, A.L.I. Oliveira, S. Soares, Hybrid intelligent
design of morphological-rank-linear perceptrons for software development cost estimation, in: Proceedings of the 22nd International Conference on Tools with Artificial Intelligence, Arras, France, 2010, pp. 160–167. [23] L.C. Briand, T. Langley, I. Wieczorek, A replicated
assessment and comparison of common software cost modelling techniques, in: Proceedings of the 22nd International Conference on Software Engineering, Limerick, Ireland, 2000, pp. 377–386.
[24] L.C. Briand, J. Wüst, Modeling development effort in object-oriented systems using design properties, IEEE Transactions on Software Engineering 27 (11) (2001) 963–986.
[25] G. Costagliola, SD. Martino, F. Ferrucci, C. Gravino, G. Tortora, G. Vitiello, Effort estimation modelling techniques: a case study for web applications, in: Proceedings of the 6th International Conference on Web Engineering, Palo Alto, CA, United States, 2006, pp. 9– 16.
[26] A. Idri, A. Abran, T.M. Khoshgoftaar, Fuzzy case-based reasoning models for software cost estimation, in: E. Damiani, L.C. Jain, M. Madravio (Eds.), Soft Computing in Software Engineering, Springer, 2004, pp. 64–96. [27] A. Idri, A. Zahi, E. Mendes, A. Zakrani, Software cost
3010 networks, in: Proceedings of the International Workshop
on Software Measurement, Palma de Mallorca, Spain, 2007, pp. 21–31.
[28] M. Jørgensen, U. Indahl, D. Sjøberg, Software effort estimation by analogy and "regression toward the mean", Journal of Systems and Software 68 (3) (2003) 253–262.
[29] E.S. Jun, J.K. Lee, Quasi-optimal case-selective neural network model for software effort estimation, Expert Systems with Applications 21 (1) (2001) 1– 14.
[30] M. Shin, A.L. Goel, ―Empirical data modelling in software engineering using radial basis functions‖. IEEE Transactions on Software Engineering, vol. 26, no. 6, pp. 567-576, June 2000.
[31] C. J. Burgess, M. Lefley. ―Can genetic programming improve software effort estimation? A comparative evaluation‖. Information and Software Technology, vol. 43, pp. 863-873, 2001.
[32] Hodgkinson, A.C., Garratt, P.W., "A Neuro-fuzzy Cost Estimator," Proc. 3rd International Conf. Software Engineering and Applications (SAE), 1999, pp. 401 - 406.
[33] Ruchika Malhotra, ―Software Effort Prediction using Statistical and Machine Learning Methods‖, (IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 2, No.1, January 2011.
[34] Mohd. Sadiq, Aleem Ali, Syed Uvaid Ullah, Shadab Khan, and Qamar Alam, International Journal of Information and Electronics Engineering, Vol. 3,No. 3, May 2013.
[35] Neha Saini , Bushra Khalid, "Empirical Evaluation of machine learning techniques for software effort estimation" Journal of Computer Engineering (IOSR-JCE) e-ISSN: 2278-0661
[36] Berna Seref and Necaattin Barisci, "Software Effort Estimation Using Multilayer Perceptron and Adaptive Neuro-Fuzzy Inference System" International Journal of Innovation, Management and Technology, Vol. 5, No. 5, October 2014
Authors Profile:
Prof A.J. Singh is a Professor in the Department of Computer Science in Himachal Pradesh University, Shimla. He has been in this Department since 1992. He has obtained his B.Tech in Computer Technology from National Institute of Technology (MANIT) Bhopal, Master of Science in Distributed Information Systems from University of East Landon (UK) and PhD degree from Himachal Pradesh University Shimla. He has published more than 50 research papers, supervised PhD and M.Tech students. His area of interests are Distributed System (Networks and DBMS), and ICT for Development.
Mukesh Kumar is completed his M.Tech in Computer Science and Engineering from HPU Shimla in 2008. He is currently pursuing PhD degree in the department of Computer Science, Himachal Pradesh University, Summer hill, Shimla, India and His research interest includes Machine learning, Artificial intelligence, Information security, Educational Data Mining. He has 10 years of teaching experience and published 15 research papers in different