3122 IJSTR©2019
www.ijstr.org
Improved Image Retrieval And Classification
Using Color, Texture And Shape Features
Kais Khaldi
Abstract: This paper sheds the light on a new approach of Content Based Image Retrieval (CBIR). It combines the classification by SVM with the similarity measure using the GLCM, Gabor and Surf descriptors. This work focuses on these descriptors level of improvement. T his improvement paves the way to a new approach of image research. The proposed approach is applied to synthetic and real data. Thus, the results are compared to those obtained by other method. The compared results of those algorithms of images search has revealed the good performance of the proposed approach. It also highlights the capacities of SVM as a classification tool of images.
Index Terms: CBIR, SVM, RNN, Similarity, GLCM, Gabor, Surf.
. —————————— ——————————
1.
INTRODUCTION
THe striking increase of images bases volume necessitates transcending manual annotation because the automatic production of textual descriptors for a set of images is unfeasible due to several problems to be encountered [1], [2], [3]. In order to satisfy this necessity, the content-based approach has emerged to substitute for the textual approach. As a better alternative, the content-based approach constitutes of images indexing based not only on image names or keywords, but also on their contents as well. Several methods have been suggested, especially those focusing on color spatial features [4], [5], [6]. This new search system which is called the content- based approach is divided into three main generations: The first generation of this system is based on founding images that are stored in a data base by using the different names associated with it in the form of strings which are linked to the images and it can be searched by a structural way [2]. DIFFERENT WAYS OF IMAGE SEARCH HAVE BEEN PROVIDED BY THE SECOND GENERATION WHICH IS PRIMARILY BASED ON SEARCHING IMAGES ACCORDING TO SOME VISUAL CHARACTERISTICS LIKE TEXTURE, SHAPE AND COLOR
...THAT IS WHY THE SEARCH FOR IMAGES IN THIS GENERATION IS BASED ON THE DEGREE OF SIMILARITY TO THE REQUEST IMAGE [8].
THE THIRD GENERATION PROVIDES A CLEVER WAY WHICH IS SIMILAR TO THE FUNCTIONING OF THE HUMAN VISUAL SYSTEM, THE CHOICE OF DESCRIPTORS USED TOGETHER WITH THE TECHNIQUE USED RELATED TO THE EXTRACTION ARE VERY IMPORTANT IN THE PERFORMANCE OF RESEARCH SYSTEMS IN THE PAST VARIOUS DESCRIPTORS ARE USED IN SEARCH SYSTEMS, BUT RECENT STUDIES ON CONTENT BASED IMAGE
RETRIEVAL (CBIR) USED A SINGLE VISUAL CONTENT LIKE SHAPE OR COLOR TO DESCRIBE THE IMAGE.HOWEVER THESE TECHNIQUES ARE NOT VERY USEFUL THAT‘S WHY A NEW VERSION OF CBIR APPEARED TO IMPROVE THIS PERFORMANCE IT PROVIDES THE COMBINATION OF ALL DESCRIPTORS [10].
The performance of research systems depends largely on the choice of descriptors used and the techniques associated with their extraction [9]. Many descriptors are used in search systems to describe images. Early studies on CBIR used a single visual content such as color, texture, or shape to describe
the image. In the literature we classify the visual descriptors of the content of the images in three categories:
* Color: plays a very important role in the image search process. Several works have already proved that it is an efficient descriptor.
* Texture: is a fundamental characteristic of images because it concerns a considerable element of human vision. There is no relevant definition of texture. However, a common sense definition is: texture is the repetition of basic elements constructed from pixels that respect a certain order. Sand, water, grass, skin are examples of textures.
* The form: is one of the lowest level attributes also the most used to describe the visual content of images. However, the description of the forms is a difficult task, especially in a context of "weak segmentation" and in a context where the search is for similarity and not for accuracy. Thus among recent research systems, only some use form as a search criterion.
However these studies are not effective when using a minima number of descriptors. To ameliorate this performance, we propose a new approach of CBIR based on the combination of all descriptors i.e. color, texture, shape and features.
The paper is organized as follow: section 2 explains basic descriptors. Section 3 describes our proposed approach, while section 4 gives simulation results and comparisons with other method.
2 BASCIC DESCRIPTORS
The visual descriptors are divided into three main parts:
2.1 Color descriptors
Color is the most used visual information in content search systems. The high power of color discrimination makes it an omnipresent attribute in the vast majority of indexing and content search systems. It is the first descriptor that is used for image search. These three-dimensional values make its discriminatory potential greater than the gray-scale discriminatory potential greater than the gray-scale value of the images. In the literature, color indexation is based on two main categories: color space descriptors to represent the main colors of an image, while providing information on their importance and color distribution descriptors including the mode of representation of the color in the space.
The three extraction axes of color descriptors for content-based image search systems are histograms, color moments, and color self-correlograms [8].
The first color moment is the mean, it is given as follows: ————————————————
Kais Khaldi is Assistant professor in College of Science and Arts-Tabarjal , Jouf University, P.O.Box 2014, Al-Jouf , Skaka,42421, KSA., and research member in Unité Signaux et Sytèmes, ENIT, ElManar University
3123 y x N i N j y x
d
i
j
P
n
Correlatio
0 0) , (
(
,
)
N j ij i iP
N
E
1 3 ... 0 /1
(1)where
P
ij is the pixel number i, j.The second color moment is the standard type:
2 1
)
(
1
i N j iji
P
E
N
(2)
The third color moment is asymmetry; it is calculated as the following: 3 1 3
)
(
1
N j i iji
P
E
N
S
(3)2.2 Texture descriptors
Texture represents a very important feature of images since it is used widely by content search in images. It is very difficult to find a precise definition for texture. The literary definition of texture remains incomplete because it defines texture as a repetition of the same pattern in different directions of space. That‗s why researchers who use content-based image search systems apply one of three types of classical texture:
- Statistical descriptors in which the grey scale is very important and its extraction is considered as a technique for analyzing statistical textures.
- Its statistical analyzes is calculated on pixels for both the color distribution of pixels and spatial correlation between color pairs.
- Three-dimensional histogram is present to represent this information. The first both dimensions is a combinations of pairs of pixels and the third dimension is their spatial distances
Attributes of different types and different levels of resolution are extracted by the wavelet transform.
Today for analyzing textures there are several ones used and the method which is used widely is based on Gabor filters. The main reason for its use is that it is similar to the human visual system. The Gabor method is essentially focused on decomposing the image on analytic function. After that a texture region is characterized by the several of its transformation coefficient. Gabor filters are used as a bunch .it is a set of features that combine 4 scales (0.05, 0.1, 0.2 and 0.4) and 6 orientations (0 °, 30 °, 60 °, 90 °, 120 ° and 150°) together with the shape descriptors. Taking into considerations the information that exists on the contour as well as the information that exists inside the image [1], [4].
The contrast: it represents the variation change of gray level intensity volume in an image.
(4)
Correlation: the measures of uniformity texture, it is defined as follows:
(5)
Where and denote respectively the averages and deviations standard of pixels Px and Py.
Inertia: it is a descriptor which describes the homogeneity of texture. It is defined by the following equation.
(6)
Cluster shade: it is a descriptor that quantifies the textures Symmetry.
(7)
With a distance equal to 1 combined with respective angles will give us a vector of 16 terms as descriptor of the texture for each image Filter of Gabor: a Gabor function is the association of a Gaussian curve and an oriented sinusoid / sine wave. It is defined as the following:
(8)
2.3 Shape descriptors representation compared to other features, like texture and color, is much more effective in semantically
characterizing the content of an image [1]. However, the challenging task of shape descriptors is the accurate extraction and representation of shape information
Shape representation compared to other features, like texture and color, is much more effective in semantically
characterizing the content of an image [1]. However, the challenging task of shape descriptors is the accurate extraction and representation of shape information.
Shape representation compared to other features, like texture and color, is much more effective in semantically characterizing the content of an image [14]. However, the challenging task of shape descriptors is the accurate extraction and representation of shape information.
Various shape descriptors exist in the literature, mainly categorized into two groups: contour-based shape descriptors and region-based shape descriptors. Contour-based methods need extraction of boundary information which in some cases may not available. Region-based methods, however, do not rely on shape boundary information, but they take into account all the pixels within the shape region. Hybrid descriptors that combine the both shape descriptors that are based on the outline that characterizes only the outline or boundary of the object by ignoring its interior. Therefore, for generic purposes, both types of shape representations are necessary. An extensive evaluation of MPEG-7 shape descriptors have been presented in [5] where the effectiveness of Zernike moments and Fourier descriptors was confirmed through experimental results. In [16], the curvature scale space descriptor outperforms the other evaluated shape descriptors when compared in the
N j d N ij
i
p
i
Contrast
0 ) , ( 2 0)
,
(
*
)
(
N i N jd
i
j
p
j
i
Inertia
0 0 ) , ( 2)
,
(
*
)
(
N i N j d yx
p
i
j
j
i
de
ClusterSha
0 0 ) , ( 3)
,
(
*
)
(
) sin( ) cos( ) sin( ) cos( ) 2 cos( exp 2 1 ) , , , ( 2 2 2 2
x y y y x x fx y x f y x G y x y x
3124 IJSTR©2019
www.ijstr.org
MPEG-7 Core Experiment. In [17], descriptors based on complex moments and spectral transforms, such as Zernike moments and Fourier descriptors, are proved to be the best choices for general shape applications. While the aforementioned descriptors are some of the most important shape descriptors, they have never been evaluated against each other. One of the most popular methods of point-of-interest detection is Scale-Invariant Feature Transform (SIFT). This last is a feature detection algorithm in computer vision to detect and describe local features in images. The SIFT detector has four main stages namely, scale space extrema detection, key point localization, orientation computation and key point descriptor extraction [18]. SURF Detector, also known as approximate SIFT employs integral images and efficient scale space construction to generate key points and descriptors very efficiently.
2.3.1 SURF detector
The basic idea of SURF is similar to that of SIFTs, but SURF uses different methods for locating, detecting, and generating descriptors because there is a large amount of data in an image database, and the consumption time of SIFT is rather high. H.Bay [11] proposed SURF to improve the efficiency of detection and description of extreme points. The SURF feature detector is depends on the matrix Hessian which has competitive advantages of speed and accuracy. SURF uses a hessian blob detector whose purpose is to determine points of interest. The determinant of a hessianne matrix expresses the importance of the response, and the expression of the local variation around the zone [12]. The SURF detector expands on Lowe's idea of using the Gaussian difference as an approximation of the Laplacian of the Gaussian filter [13]. As represented by "Lowe" the "Difference of Gaussian" (DoG) provides a good approximation for Laplacian Gaussian. It can be calculated by subtracting adjacent the optimal pyramid scale space. Approximation of second Gaussian derivatives by filters presented in SURF the gray regions are equal to zero [3]. This approximation relies on the integral images to reduce the computation time. This is what makes SURF-detector literally named the Fast-Hessian Detector.
2.3.2 SURF descriptor
The purpose of a descriptor is to provide a unique and powerful description of a feature. A descriptor can be generated based on the area surrounding a point of interest. The SURF descriptor is based on the Haar wavelets and can be calculated SIFT by using an alternative method for Hough transform descriptors. SURF divides the neighborhood region of each point into a number of 4 × 4 square sub regions. Next, a Haar wavelet response of each sub region is calculated. Each response has four-dimensional vectors (wheel). Once the wavelet responses are computed and weighted with a Gaussian centered on the point of interest, the responses are represented as vectors in space with the horizontal reaction force along the line. x-axis and the vertical reaction force along the ordinate. The predominant orientation is estimated by computing sums of all responses in a sliding window overlap orientation of an angle of π / 3. The horizontal and vertical responses inside the window are summed. The two answers joined to give then a new vector of size point 64 terms.
3 PROPOSED APPROACH
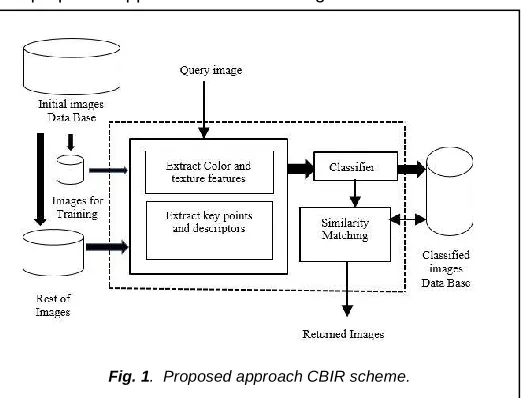
The proposed approach is shown in Fig.1.
We are concerned initially with the classification; since the issue becomes more intricate when the size of the database becomes essential and the descriptors become considerable. The search is generally perfect in an exhaustive way on the whole database which results in rejected response time by the user. For that, we select to classify the images by Support Vector Machine (SVM) before looking for those which are the most identical to the image request. Support vector machines (SVM) also called "maximum margin classifier" were introduced in 1995 by Cortes and Vapnik [4], [13]. They are characterized by rough performances obtained even with very high bases such as texts, images and speech. Recently, they demonstrate strong performance for multi-class classification problems. They are based on two concepts: *maximum margin *kernel function. A support vector machine or wide-margin separator (SVM) is a discrimination technique. It consists of two separating (or more) sets of points by a hyper plane. Indeed, these discriminant functions are simple classification methods that separate images belonging to different classes based on a linear analysis. Its norm is quite simple, the algorithm looks for the separation that maximizes the "margin". The margin can be defined as the Euclidean distance between the separation surface (hyper plane) and the closest point of the learning set, according to Boser et al. [2]. After the extraction phase of the descriptors of each image, we choose to use a phase classification of the latter to reduce the phase of matching and searching images similar to the image request. We have done a comparison between two classifiers (Neural Networks and Support Vector Machines), which will be mentioned in results section. The phase or stage classification is designed to classify the images and only the descriptor colors and texture which based on the algorithm of classification vector machine Support (SVM). The basic classification of images is intended to reduce the indexation. Indeed, when we have a classified database, during the query, in the first place the system will determine the class of the image request. Secondly, it will store and search for images that are the most similar to the query image, only with the images contained in the class returned by the classifier and not with all the images in the database. This one makes it easier to search and reduces complexity and response time. During a query, a descriptor is first extracted from the query image. This last is then used to find the descriptors stored in the database that is already ranked that
Fig. 1. Proposed approach CBIR scheme.
3125
are closest to them in terms of similarity. As an image descriptor we propose to use the color and texture descriptors to classify the images in order to obtain a classified image database. When a user initiates a query, the system first extracts the texture color features, then it determines its class that is determined by the SVM classifier. Finally he looks for the most similar images. The search for similar images is based on the similarity of visual characteristics such as color, texture or shape. The distance function used to evaluate the similarity depends on the criteria of the search but also on the representation of the characteristics. The main idea is generally to associate to each image a multidimensional vector representing the characteristics of the image, and to measure the similarity of the images by using a distance function between the vectors.
4 RESULTS
The proposed aim is evaluated on Wang database images. In a first step, the class of the request image is determined based on the SVM classification algorithm. The learning phase was treated with the 100 images (10 images for each class) for the SVM classifier, and the rest of the database (900 images) of test (90 images of class) were passed for the SVM classifier. All of this items, look us to the following results. Table 1 summarizes the results of both classifier algorithms:
According to Table 1, we can conclude that the accuracy of the RNN Classification of the class of monuments is very low, it is equal to 0.3 that means that 2 out of 90 images are well classified. The class of monuments while 88 pictures had other classes than that of monuments. We can note also that the RNN-Classification gave a precision equal to 0.93 and conformed the same accuracy as the SVM-Classification at the flower class level.
The Fig.2 shows the overall precision of SVM well as the RNN: so the results prove that SVM-Classification is more accurate at all categories and at the global level. Indeed, the average precision of RNN-Classification is equal to 51.66% while that of SVM-Classification is equal to 88.23%, which look us to confirm that the second classification is more efficient in terms of accuracy. After these results of comparison between these two classifiers, we prefer SVM as a classification tool in the our work. The suggested approach is estimated on Wang database images. The WANG database is a subset of the Corel database of 1000 images which were chosen manually to form 10 classes of 100 images each. The images are divided into 10 groups (e.g. Africa, beach, ruins, and food) such that it can be supposed that a user wishes to find the other images from a class if the question is from one of these 10 classes. This database was created at the Pennsylvania State University and is ready for download [6]. In a first step, the class of the request image is determined based on the SVM tabulation algorithm. The studying phase was executed with the 100 pictures (10 images for each class) for the SVM classifier, and the end of the database (900 images) of test (90 images of class) were gone over the SVM classifier.In a second step, we search for the 10 most identical images to the inquiry image based on a summation of Canberra Distance (between the descriptor wheels of color and texture) and the distances between the points of concen (detected and described by SURF algorithm). The Canberra Distance CD [10] is calculated as follows:
(10)
where u and v are n-dimensional wheels.
In order to execute the search for the most likeness images to the inquiry image, we used Surf descriptor. Given a request image represented by its characteristic vector, the class of this picture is the one with the littlest mistake value to the other portion of the classified image database. In the looking for 10 images most identical to the image inquiry; we will number the distance between the wheel of the request image and each wheel of the class of this image (request image), we get values, and we standing them from junior to enormous the first 10 values are the images identical to the image inquiry. 900 images are used as question images to apply and evaluate our process. The "similarity" module will first classify the demand image, and then calculate the likeness between it and the class images based on the Canberra Distance. The reply of the method with the MV approach (Mean Vector) differs according to the request image [10]. Indeed with images queries it returns the 10 most identical images without incorrect answers. It can also return the 10 images that are some or all enumerated as incorrect answers.
Fig. 3 clarifies the results of the mean vectors method(MV-approach) [10]. It presents the example system response with the 601 .jpg image as a question.
TABLE1
COMPARISON OF PRECISIONS OF RNN-CLASSIFICATION WITH THOSE OF SVM
Table 1: Comparison of Precisions of RNN-Classification with those of SVM
Fig. 2. Overall recognition rate comparison between RNN and
SVM.
Ni i i
i i
V
U
V
U
CD
3126 IJSTR©2019
www.ijstr.org
According to this Fig., the accuracy is equal to 0.6 because the images 391.jpg, .331.jpg, 381.jpeg and 395.jpg are estimated as false answers.
After stratifying the proposed approach with the "similarity" module, on image 601.jpg, amelioration in precision was noted as shown in Fig. 4. From the results we acquired we note that our process of searching for the most identical images exercised on all the basic elements of test (900 images) gave a global admission rate is equal to 90.6% for the 10 classes of Wang database. It was also noted that our process of image search and propinquity measurement yielded uncommonly good results contrasted to the results of other ancient works that used Wang database.
According to Table 2, it can be summarized that the integration of color, texture and shape descriptors (proposed approach) gives much better results than the combination of color and texture descriptors.
5 CONCLUSION
In this paper, a new proposed approach of CBIR is presented. The proposed approach is combined with a system of indexing and search of images by contents, this system works with an integration of the color descriptors such as the statistical intention with both descriptors reproducer of texture which are the GLCM and the nomination of Gabor. Our improvement is divided into two categories. In a first part, the class of the request image is defined based on the SVM classification algorithm. In a second part, we look for the 10 most similar images to the query image based on a combination of Canberra distances (between the descriptor vectors of color and texture) and the distances between the points of interest (detected and described by SURF algorithm). Finally we present an identical measurement method that integrates these and the distances between the points of concern based on the Canberra Distance. The comparison of our work with other research work in the literature showed a meaningful gain in the returned images. Moreover, gained results prove that the approach implement better than the Mean Vector (MV). As future work, we design to study the statistical and topical estimation of the weights assigned to the descriptors of the content, and richness of the descriptor of form or color.
REFERENCES
[1] R.Haralik, M. Shanmugam, K. Dinstein and I. Textural, ―features for Images Classification,‖IEEE Transaction on System, Man, Cybernetics, vol. 3, pp. 610-621, 1973. [2] B. Manjunath and W.Y.Ma, ―Texture features for browsing
a retrieval of image data,‖ IEEE Transaction on Pattern analysis and machine Intelligence, vol. 18, , no. 8, 1996. [3] D. Zhang and G. Lu, ―Content-based shape retrieval using
different shape descriptors: a comparative study,‖ IEEE International conference on multimedia and Expo, pp. 137-320, August 2001
[4] G. LOWE, ―Distinctive image features from scale-invariant key points,‖ IJCV, vol. 60, no 2, pp. 91-110, 2004.
[5] H. Bay, A. Ess, T. Tuytelaars and L. Gool, ―Speed-Up Robust Features (SURF),‖ ELSEVIER on Computer Vision and Image Understanding, 2007.
[6] R. Weber, S. H.Schok, and A Blott ,―Quantitative Analysis and Performance Study for Similarity-Search Methods in High-Dimensional Space,‖ Proceedings of the 24th VLDB Conference, New York, USA 1998.
[7] L. Amsaleg and P. Gros, ―Content-based retrieval using local descriptors: problems and issues from database perspective,‖ Pattern Analysis and Applications, Special Issue on Image Indexation, vol. 4, pp. 108-124, 2001. [8] M.A. Stricker and M. Orengo, ―Similarity of color images,‖
SPIE, Storage and Retrieval For image Video Databases, pp. 381-392, 1995.
[9] M. Christopher ―Pattern Recognition and Machine learning,‖ Library of Congress : Sparse Kernels Machines, ISBN-10: 0-387-31073-8, chapter 7 pp. 325-329, 2006. [10]J. Afifi and M. Ashour, ―Content based image retrieval
using invariant color and texture features,‖ IEEE Digital Image Computing Techniques and Applications, Dec 2012.
Fig. 3. System Response with VM Approach toRequest Image
601.jpg.
TABLE 2
COMPARISON BETWEEN OUR PROCESS AND THAT OF CBIR- 2012 (AFIFI AND AL) [10] AT THE LEVEL OF THE WAYS OF REGULATION FOUND FOR EACH CLASS OF THE
WANG DATABASE WITH 10 IMAGES RETURNED.
Fig. 4. System Response with theProposed Approach to the
3127
[11]M. Teague, ―image analysis via the general theory of moment,‖ Journal of optical society of America, vol. 20, n°8, p.920-930, 1980.
[12] C. Harris and M. Stephens, ―A Combined Corner and Edge Detector,‖ Proceedings of the 4th Alley Vision Conference, pp. 147–151, 1988.
[13]C. Schmid, R. Mohr and C. Bauckhage, ―Evaluation of Interest Point Detectors,‖ Int. J. Computer. Vision, vol. 37, no. 2, pp. 151–172, 2000.
[14]E. Persoon and K. Fu, ―Shape discrimination using Fourier descriptors,‖ IEEE Trans. Systems, Man and Cybernetics, vol. 7, no. 3, pp. 170–179, 1977.
[15]D. Zhang and G. Lu, ―Evaluation of MPEG-7 shape descriptors against other shape descriptors,‖ Multimedia Systems, vol. 9, no. 1, pp. 15–30, 2003.
[16]L. Latecki, R. Lakamper, and U. Eckhardt, ―Shape descriptors for non-rigid shapes with a single closed contour,‖ IEEE Conference on Computer Vision and Pattern Recognition, 2000.
[17]D. Zhang and G. Lu, ―Review of shape representation and description techniques,‖ Pattern recognition, vol. 37, no. 1, pp. 1–19, 2004.
![Fig. 3 clarifies the results of the mean vectors method(MV-approach) [10]. It presents the example system response with the 601 .jpg image as a question](https://thumb-us.123doks.com/thumbv2/123dok_us/8620284.1409992/4.612.39.283.601.730/clarifies-results-vectors-approach-presents-example-response-question.webp)

