© 2014 IJSRSET | Volume 1 | Issue 1 | Print ISSN: 2395-1990 | Online ISSN : 2394-4099 DOI : https://doi.org/10.32628/IJSRSET207277
Challenges and Cloud Computing Environments Towards Bid Data
Kiran Kumar S V N Madupu
Sr. PL SQL Dev / Data Base Specialist, System Soft Technologies, Herndon, VA
ABSTRACT
Big Data has terrific influence on scientific discoveries and also value development. This paper presents approaches in data mining and modern technologies in Big Data. Difficulties of data mining as well as data mining with big data are discussed. Some technology development of data mining as well as data mining with big data are additionally presented.
Keywords : Big Data, Data Mining, Cloud
I. INTRODUCTION
The current explosion of data that is being created is due to three main reasons: (1) hundreds of applications such as mobile sensing units, social media sites services, and various other associated devices are collecting details continually; (2) storage capacity has actually improved so much that accumulating data is less costly than ever before, making better to acquire more storage room rather than deciding what to remove; (3) Artificial intelligence as well as information retrieval techniques have actually reached a considerable enhancement in the ins 2014, thus allowing the purchase of a higher level of expertise from data.
Corporations understand these developments. Getting essential organisation understandings by querying as well as analyzing such large quantities of data is ending up being a (BI), which refers to choice support group that necessity. This problem is called Business Intelligence incorporate data gathering, data storage space, and also knowledge monitoring with analysis to give input to the choice procedure. Concerning the former problems, a new idea appears as an extra basic field, incorporating
data warehousing, Data Mining (DM), as well as data visualization for Service Analytics. This topic is referred to as Data Science.
The data monitoring as well as analytics performed in conventional database systems (and also other related remedies) can not deal with the Big Data challenges: data dimension is too large, worths are modified rapidly, and/or they do no more satisfy the constraints of Data source Management Solution (DBMS). According to this truth, new systems have actually emerged to solve the previous issues: (1) 'Not Only SQL' (NoSQL) systems that change the storage space and also access of key/value pairs for interactive data offering atmospheres as well as (2) systems for large analytics based on the MapReduce identical shows design, Hadoop being one of the most pertinent application.
scalability. The basis of Cloud Computer is the Service-Oriented Design, which is developed to allow designers to conquer numerous distributed company computing challenges consisting of application integration, purchase administration, and also security policies.
The benefits of this new computational standard relative to alternative technologies are clear, especially pertaining to BI. Initially, cloud application carriers aim to provide the same or much better service and also performance as if the software application were locally installed on end-user computer systems, so the end-users do not need to invest money getting complete hardware devices for the software application to be made use of. Second, this kind of setting for the data storage and also the computer plans allows companies to get their applications up and running faster. They have a lower need of upkeep from the Information
Technology division as Cloud Computer
immediately takes care of the business need by dynamically designating resources (servers, storage,
and/or networking) depending upon the
computational load in real time.
Data mining can be utilized to locate correlations or patterns amongst dozens of areas in huge relational data source [1] Data mining is also the process of uncovering or finding some new, valid, reasonable, and also possibly useful forms of data. Cloud data mining (CDM) is a very tiresome process that requires a special framework based on application of brand-new storage modern technologies, dealing with, and handling. Big Data/Hadoop is the latest hype in the field of data handling. With the assimilation of extensive evaluation of data (data mining) and cloud computer, options accessing data mining services every time and also everywhere and also from various platforms and tools will be implemented [2]
Platform-as-a-service (PaaS) is one of major service designs of cloud computing. The PaaS solution version means the libraries (e.g. R library optimized for parallel processing), data mining algorithms, and also other services. The advantages of using cloud computer in data mining (DM) are as adheres to [3]:
- Cost financial savings-- lower operational costs. - Investment-- lower key financial investments. - Faster release.
- Much easier maintenance-- most upgrades and also spots are done by the cloud carrier.
- Adaptability - capability to include brand-new organisations, spin up brand-new services, and reply to client needs.
- Scalability-- simpler to handle peaks anywhere accessibility as well as single atmosphere to take care of customer accounts as well as credentials throughout lots of gadgets.
nature. Streaming data may additionally include spatial features.
Big data mining is the ability of removing valuable details from these huge datasets or streams of data, which was not possible before as a result of data's volume, variability, and rate. Big data is a large volume of both structured and also unstructured data that is so large that it is difficult to process making use of standard database and software program methods. Big data technologies have terrific impacts on scientific discoveries and value creation. Structured (numerical) as well as unstructured (textual) are two main sorts of data kinds in big data. Their qualities and usages are detailed in Table 1.
TABLE 1 :
Characteristics and uses of structured and unstructured data typically row s and columns of
numbers
Volume Large and rapid growing; continually aggregating collected data to analyze choices
Velocity Real time and/or archival; utilized for operational performance
Velocity Data are auditable; resources can be confirmed
Internet mining can be split into 3 different types. They are: Internet use mining, web material mining, as well as Internet structure mining. Web use mining is a procedure of drawing out valuable info from web server logs, i.e. user's background. Internet structure mining is the procedure of using graph theory to evaluate the node and also connection framework of a web site. Internet material mining aims to finding beneficial info or
hyperlinks and surpasses using keywords in a search engine. Internet content contains information such as disorganized complimentary message, photo, audio, video, metadata, and also hyperlink.
The actual existing trouble is most data mining approaches do not function well with big data. There are a lot of obstacles when data mining methods relate to Big Data analytics. The objective of this paper is to identify what data mining approaches can be made use of in big data as well as present the improvements or novelties of these methods via introducing the technology progression of data mining with big data. This paper presents data mining, data mining with big data, and the challenges as well as modern technology development of data mining with big data. The obstacles offered in this paper partly indicate the gap/problem from previous research work in addition to some future job. Consequently, this paper will present some significant value of data mining applications in big data. The company of this paper is as follows: the following section presents methods of data mining and Big Data; Area 3 talks about obstacles of data mining and data mining with big data; Area 4 offers modern technology progress of data mining as well as data mining with big data; as well as the last area is verdicts.
II. CLOUD COMPUTING ENVIRONMENTS FOR
BIG DATA
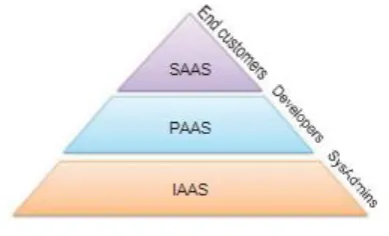
Cloud Computing is a setting based upon utilizing as well as providing services. There are various classifications in which the service-oriented systems can be clustered. One of the most pre-owned standards to group these systems is the abstraction degree that is offered to the system customer. This way, 3 various levels are commonly distinguished: Facilities as a Service (IaaS), System as a Service (PaaS), and also Software Application as a Service (SaaS) as we can observe in Figure 1.
flexibility in the rates version as well as movement for the software application customer. Under these assumptions, it is apparent that the Cloud Computer paradigm benefits big jobs, such as the ones connected with Big Data and BI.
In particular, a typical Big Data analytics framework is depicted, concentrating on the structure of the data administration industry we may specify, as the most ideal management company architecture, one based on a four-layer style, which includes the complying with elements:
Figure 1 : Illustration of the layers for the Service-Oriented Architecture
- A documents system for the storage space of Big Data, i.e., a large amount of archives of plus size. This layer is applied within the IaaS degree as it specifies the standard design company for the remaining tiers.
- A DBMS for arranging the data and gain access to them in an effective method. It can be watched in between the IaaS and also PaaS as it shares common attributes from both systems. Developers used it to access the data, yet its implementation lies on a hardware level. Indeed, a PaaS functions as a user interface where, at the upper side provides its performance, and also near the bottom side, it has the implementation for a specific IaaS. This attribute enables applications to be deployed on different IaaS without rewriting them.
- An execution device to distribute the computational lots amongst the computers of the cloud.
This layer is plainly associated with PaaS, as it is sort of a 'software application API' for the codification of the Big Data as well as BI applications.
III. CHALLENGES OF DATA MINING AND DATA MINING WITH BIG DATA
Protecting personal privacy and also confidentiality, stream preprocessing, timing and also availability of info, and also relational stream mining, and so on are difficulties. Difficulties of data stream handling and mining lie in the transforming nature of streaming data. Consequently, determining trends, patterns, as well as changes in the underlying procedures creating data is very important.
Data streams present difficulties for data mining. Initially, formulas should utilize minimal sources (time as well as memory). Second, they must deal with data whose nature or distribution changes in time. Distinct difficulties associated with creating dispersed mining systems are: on-line adjustment to inbound data qualities, online processing of big quantities of heterogeneous data, limited data accessibility and communication capabilities in between distributed learners, etc
matched for complex algorithms that have an iterative nature.
Big data mining is a lot more challenging compared with typical data mining algorithms. Taking clustering as an example, a natural method of clustering big data is to expand existing techniques (such as ordered clustering, K-Mean, and Blurry C- Mean) to make sure that they can deal with the substantial workloads. Most expansions normally rely on examining a certain quantity of samples of big data, and differ in exactly how the example- based results are used to obtain a dividers for the general data. Clustering big data is additionally developing to distributed and also identical execution. Lack of computational performance and storage capability were recognized as the major barriers of cloud computer in data mining with big data.
Big data mining has challenges in data accessing and calculating procedures. Big data are often kept at different areas. While common data mining algorithms need all data to be packed into the main memory, relocating data across different places is costly. Big data mining difficulties as well as difficulties in algorithm styles are increased by the big data quantities, distributed data distributions, as well as by complicated and also vibrant data attributes. The difficulties of big data mining formulas are listed as complies with:
- Neighborhood understanding and also version fusion for several information sources: A big data mining system has to enable an info exchange and also fusion system
to guarantee that all distributed sites (or info resources) can work together to accomplish a global optimization goal.
- Mining from sporadic, unsure, as well as
of to attract reliable conclusions. Typical strategies are to employ dimension decrease or function option to lower the data dimensions or to thoroughly consist of added samples, such as common not being watched learning techniques in data mining. For unclear data, each data product is stood for as some sample distributions. Common remedies are to take the data distributions right into consideration to estimate version specifications. The majority of data mining algorithms can deal with insufficient or absent data. Assigning missing values is a technique of generating improved models.
- Mining complex and dynamic data: Currently, there is no recognized effective as well as reliable data design to manage big data complexity (structured, disorganized, as well as semi-structured).
Mining big data streams deals with 3 primary challenges: quantity, rate, and volatility. Quantity and also speed require a high volume of data to be refined in limited time. Volatility represents a vibrant setting with ever-changing patterns. Old data is of limited usage. This is due to transform that can impact the generated data mining designs in numerous means: change of the target variable, adjustment in the available attribute info, and also drift. Mining heterogeneous details networks is a promising research study frontier in big data mining. Existing data mining methods face fantastic problems when they are called for to manage big data. Secret problems and challenges are heterogeneity, quantity, rate, precision, waste mining, and also dilemma in count on and personal privacy.
IV. CONCLUSION
concealed under large data. Structured data can be represented in conventional graphical methods, whereas it is tough to visualize high variety, unpredictable semi-structured as well as unstructured big data in real- time.
V. REFERENCES
[1]. J. Ding, S. L. Yang, H. Luo and S. Ding, Data mining service model in cloud computing environment, Computer Science. 6A, 39 (2012) 217-219+237.
[2]. X. Y. Wang, On cloud computing, Journal of Taiyuan University. 3 (2012) 135-137.
[3]. Y. Gao, T. Nie and Y. Mao, Research on principles and implementations of cloud computing, Computer CD Software and Applications. 16 105-106.
[4]. Y. Shen, The research of high efficient data mining algorithms for massive data sets, PhD. Dissertation, Jiangsu University, 2013.
Cite this article as :
Kiran Kumar S V N Madupu, "Challenges and Cloud Computing Environments Towards Bid Data", International Journal of Scientific Research in Science, Engineering and Technology (IJSRSET), Online ISSN : 2394-4099, Print ISSN : 2395-1990, Volume 1 Issue 1, pp. 203-208, 2014. Available at doi : https://doi.org/10.32628/IJSRSET207277