Adaptive and Dynamic Load Balancing
Methodologies
For Distributed Environment: A Review
Sandip Kumar Goyal
Department of Computer Science &Engineering, M.M.Engineering College, Maharishi Markandeshwar University,
Mullana, Ambala, Haryana-133203
R.B. Patel
Department of Computer Science & Engineering,
Deen Bandhu Chotu Ram University of Science & Technology, Murthal, Haryana-131 039
Manpreet Singh
Department of Computer Science &Engineering, M.M.Engineering College, Maharishi Markandeshwar University,
Mullana, Ambala, Haryana-133203
Abstract:
Distributed network computing environments have become a cost effective and popular choice to achieve high performance and to solve large scale computation problems. Unlike past supercomputers, a cluster or grid or peer-to-peer (P2P) system can be used as multipurpose computing platform to run diverse high performance parallel applications. Cluster computing environment consist of Personal Computers (PCs) that are interconnected using high speed networks and are located at same location where as grid computing involves coupled and coordinated use of geographically distributed resources for purposes such as large scale computation and distributed data analysis. Peer-To-Peer is composed of participants that make a portion of their resources (such as processing power, disk storage, and network bandwidth) available directly to their peers without intermediary network hosts or servers. Load Balancing (LB) in a distributed system is a process of sharing computational resources by transparently distributing system workload. A workstation user may not use the machine all the time, but may require more than it while working actively. Some resources may be heavily loaded, while other remains idle. Performance enhancement is one of the most important issues in distributed system. The performance of the system can often be improved to an acceptable level simply by distributing the load among the resources.
Keywords: Cluster; Grid; Peer-To-Peer System; Load Balancing; Distributed System.
1. Introduction
A collection of autonomous intelligent resources [17] connected through a communication link is called Distributed System [3]. A major advantage of using Distributed System (DS) is resource sharing. A major shareable resource is Central Processing Unit (CPU) cycles. A distributed scheduler is a resource management component of a distributed operating system that focuses on redistributing the load of the system among the individual resources, such that the overall performance of the system is optimized.
each server, they derived the probability P that the system is in a state in which at least one task is waiting for service and at least one server is idle. From their analysis, the following two observations could be made: 1. For moderate values of p, the value of P is high, indicating a good potential for performance improvement
through load redistribution.
2. If pis either too small or too large, the value of P is low.
In the former case, most of the servers are lightly loaded, and redistribution does not help. In the latter case, most systems are likely to be busy, and finding an idle processor is unlikely. These observations indicate good scope for performance enhancement through load redistribution, since it is reasonable to expect that most of the time the utilization is moderate, and that the system reaches the two extremes only infrequently. From a real world perspective, the following scenario could be considered. In a typical university environment, the workstations and PCs are not used equally in all the departments at all times of the day. On the one hand, we have departments that carry out simulations of atmospheric systems, and similar applications that may run for days or even weeks on their workstations, while on the other hand there are departments that run only administrative workloads. So, while the PCs in the latter groups of departments are idle or are less loaded on holidays, the workstations in the former group of departments are heavily loaded, and are carrying out simulations that were started a long time back. In such a scenario, it makes sense if we could transfer at least some parts of the tasks from the heavily loaded resources to the lightly loaded ones. That way, the individual PCs in the system are used efficiently, at no extra cost.
Because of the differences in communication mechanisms in various architectures, the load balancing problem (LBP) takes different forms, viz;
(1) For multiprocessor systems, because of the presence of a global shared memory, the granularity of LB could be smaller. The shared memory provides easy synchronization constructs that can facilitate finer control over the load. Also, the interconnection networks in such systems are fast and reliable, providing scope for efficient information exchange about the current load information. To this category of LB belong a large number of algorithms that try to distribute a single parallel workload onto different resources such that the overall processor-memory and interprocessor communications are minimized.
(2) For distributed/cluster systems executing sequential workloads, the granularity of LB should be much larger, so that the balancing overhead is minimal. In this category of LB are the algorithms that try to balance the overall load, taking into consideration the nature of the interconnection network, the heterogeneity in the resources, and the failure aspects of the component resources and those of the communication channels.
(3) Lastly, there is the group of algorithms that map a parallel load onto a cluster of autonomous computers. In a way, these algorithms are hybrids of the algorithms in the previous two groups. They have to consider the communication aspects of the program, without the facility of shared memory, and in the presence of the restrictions imposed by the communication network and possible resource/channel failures. For parallel applications, LB attempts to distribute the computation load across multiple processors as evenly as possible with objective to improve performance. Generally, a load balancing scheme consists of three phases: information collection, decision making and data migration. During the information collection phase, load balancer gathers the information of workload distribution and the state of computing environment and detects whether there is load imbalance. The decision making phase focuses on calculating an optimal data distribution, while the data migration phase transfers the excess amount of workload from overloaded processor to under loaded ones.
2. Related Work
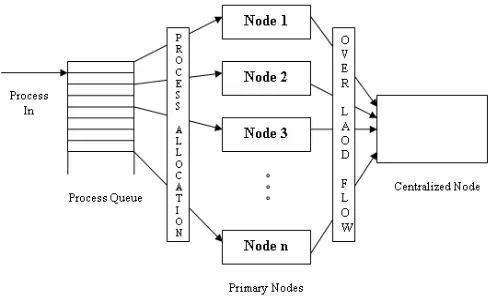
Fig. 1: Simple dynamic load balancing architecture
Fig. 2: Centralized node based load balancing
In [13] authors presented an algorithm for LB in dynamic, heterogeneous P2P systems. Presented
algorithm may be applied to balance one of several different types of resources, including storage, bandwidth, and processor cycles. That algorithm is designed to handle heterogeneity in the form of varying object loads and varying node capacity, and it can handle dynamism in the form of continuous insertion and deletion of objects, skewed object arrival patterns, and continuous arrival and departure of nodes. But it does not focus on prediction of change in load, balance of multiple resources and beneficial effect of heterogeneous capacities.lead to large communication overhead. So the problem of frequent exchange of information is alleviated by estimating the load, based on the system state information received at sufficiently large intervals of time. For a dynamic load-balancing algorithm, it is unacceptable to frequently exchange state information because of the high communication overheads.
In order to reduce the communication overheads, in [5] authors studied the effects of communication latency, overhead, and bandwidth in cluster architecture to observe the impact on application performance and in [18][19] authors presented an ant colony based method for load distribution in which appropriate attention is not given for job migration cost. In [21] authors presented a tree based algorithm for dynamic load balancing in grid environment. Several issues such as adaptability, heterogeneity are considered. Proposed method performance can be enhanced by using it with simulators such as GridSim. [20] addresses several issues that are imperative to grid environments such as handling resource heterogeneity and sharing, communication latency, job migration from one site to other, and load balancing. Two job migration algorithms, which are MELISA (Modified ELISA) and LBA (Load Balancing on Arrival) are proposed. The algorithms differ in the way load balancing is carried out and is shown to be efficient in minimizing the response time on large and small-scale heterogeneous grid environments, respectively. MELISA, which is applicable to large-scale systems, is a modified version of ELISA [6] in which job migration cost, resource heterogeneity, and network heterogeneity when load balancing are considered. The LBA algorithm, which is applicable to small-scale systems, performs load balancing by estimating the expected finish time of a job on buddy processors on each job arrival. Both algorithms estimate system parameters such as the job arrival rate, CPU processing rate, and load on the processor and balance the load by migrating jobs to buddy processors by taking into account the job transfer cost, resource heterogeneity, and network heterogeneity. In this, the performance of proposed method is quantisized using several influencing parameters such as the job size, data transfer rate, status exchange period, and migration limit, and discussed the implications of the performance and choice of approaches used. No provision is provided for fault tolerance. In [26] authors presented an algorithm for dynamic load balancing in distributed systems with multiple supporting nodes by exploiting the interrupt service. In this algorithm no provision is made for measuring the complexity.
3. Load Balancing Schemes
In the past decades, a lot of research has focused on the development of effective load balancing algorithms for distributed computing environment. Load balancing algorithms can be classified into static and dynamic approaches.
(1) Static load balancing algorithms assume that a priori information about all the characteristics of the jobs, the computing resources and the communication network are known and provided. Load balancing decisions are made deterministically or probabilistically at compile time and remain constant during runtime. The static approach is attractive because it is simple and requires minimized runtime overhead. However, it has two major disadvantages. Firstly, the workload distribution of many applications cannot be predicted before program execution. Secondly, it assumes that the computing resources and communication network are all known in advance and remain constant. Such an assumption may not apply to a distributed environment. As static approach cannot respond to the dynamic runtime environment, it may lead to load imbalance on some resources and significantly increase the job response time.
(2) Dynamic load balancing algorithm attempts to use the runtime state information to make more informative decision in sharing the system load. However, dynamic scheme is used a lot in modern load balancing method due to their robustness and flexibility. In [21] authors give classification schemes for dynamic algorithms which differ in number and type of parameters. A list of common parameters that can be used to characterize most of dynamic load balancing algorithms are:
(i) Centralized vs. Decentralized. An algorithm is centralized if the parameters necessary for making the load balancing decision are collected at, and used by, a single resource i.e. only one resource acts as the central controller and all the remaining resources act as slaves. The centralized approach is more beneficial when the communication cost is less significant e.g. in the shared-memory multi-processor environment. Its limitation is single point of failure and non-scalable. However, in decentralized approach all the resources are involved in making the load balancing decision. Decentralized algorithms are more scalable and have better fault tolerance.
(ii) Cooperative vs. Non-cooperative. An algorithm is said to be cooperative if the distributed components that constitute the system cooperate in the decision-making process. Otherwise, it is non-cooperative. (iii) Adaptive vs. Non-adaptive. If the parameters of the algorithm can change when the algorithm is being
(iv) Source-initiated vs. Destination-initiated. In a source-initiated algorithm, an over-loaded node starts negotiations with the other nodes for a potential process-migration. If a negotiation is started by an under-loaded node, the algorithm is said to be destination-initiated.
(v) Preemptive vs. Non-preemptive. If a process that has started its execution can be transferred to some other node, then the algorithm is called a preemptive algorithm. If, on the other hand, only those processes that are in the ready queue but have not yet received CPU service could be considered for migration, the algorithm is called a non-preemptive algorithm.
4. Load balancing Policies
An algorithm for the load balancing problem can be broadly categorized in terms of four policies. They are: Location Policy is the policy that affects the finding of a suitable node for migration. The common
technique followed here is polling, on a broadcast, random, nearest-neighbour or roster basis.
Transfer policy is that which determine whether a node is suitable for participating in a process-migration. One common technique followed is the threshold policy, where a node participates in a negotiation only when its load is less than (in destination-initiated algorithm) or greater than (in sender-initiated algorithm) a threshold value.
Selection policy is the policy that deals with the selection of the process to be migrated. The common factors which must be considered are the cost of migration (communication time, memory, computational requirement of the process, etc.) and the expected gain of migration (overall speedup of the system, etc.).
Information policy is that component of the algorithm that decides what, how and when the information regarding the state of the other nodes in the system is gathered and managed. They can be grouped under demand-driven, periodic, or state-change-driven policies.
The following are desirable properties of a load balancing algorithm:
Optimal overall system performance, defined as the total processing capacity being maximized, while retaining acceptable delays in metrics that are visible to the users.
Fairness of service, defined as uniformly acceptable performance provided to jobs, regardless of the node on which each job arrives.
Good performance under rare but not-impossible extraneous condition, like sudden bursty arrival of jobs, resource and communication channel failures, etc.
Low overhead in implementation of algorithm.
Algorithm should be stable and should not generate process thrashing. A process should not be transferred between nodes without much productive work being done on it between successive transfers.
5. Conclusions
The development of adaptive and dynamic load balancing algorithms is challenging because intelligent resources are prone to failures and the topology of a distributed system changes frequently due to resource failures and scalability. Key open research issues include the following:
i) The proposed load balancing schemes/methodologies for DS focus on centralized based method only, ignoring decentralization. Load balancing algorithms for decentralized based method need to be investigated. ii) Current dynamic load balancing schemes such as MELICA and LBA are not fault tolerant. So new techniques that are fault tolerant are desirable.
iii) New schemes with higher scalability and efficiency in terms of communication overhead, heterogeneity need to be developed for the distributed systems.
iv) Recent studies on decentralized dynamic load balancing schemes have demonstrated that decentralized dynamic schemes may be practical in distributed systems. However, adaptive nature is still too expensive in terms of computation and job migration cost to accomplish in a distributed system. The application of adaptive nature in load balancing schemes needs to be studied further.
Selecting the appropriate LBP for distributed systems is fundamental to provide load balancing in DS. However, the decision depends on the computation, storage and communication capability of the resources.
References
[1] Casey, L.M. (1981): Decentralized Scheduling. The Australian Computer Journal,13(2), pp. 58- 63.
[2] Livny, M.; Melman, M. (1982): Load Balancing in Homogeneous Broadcast Distributed Systems. Proceedings of the ACM Computer
[3] Casauant, T.L.; Kuhl, J. G. (1988): A Tamnomy of Scheduling in General-Purpose Distributed Computing Systems. Institute of Electrical and Electronics Engineer Transaction on Software Engineering, 14 (1 l), pp. 1578-1588.
[4] Hotovy, S. ; Schneider D. ; O’Donnell, T. (1996) : Analysis of the early workload on the cornell theory. ACM SIGMETRICS Conference on Measurement and Modeling of Computer Systems,24(1), pp. 272-273.
[5] Martin, R. et al. (1997): Effects of Communication Latency, Overhead, and Bandwidth in a Cluster Architecture. Proceedings of 24th Annual International Symposium on Computer Architecture (ISCA ’97), 25(2), pp. 85-97.
[6] Anand, L. et al. (1999): ELISA: An Estimated Load Information Scheduling Algorithm for Distributed Computing Systems. International Journal on Computers and Mathematics with Applications, 37(8), pp. 57-85.
[7] Ratnasamy, S. et al. (2001): A Scalable Content-Addressable Network. Proceedings of ACM SIGCOMM, pp. 161-172.
[8] Ion Stoica et al. (2001): Chord: A Scalable Peer-to-peer Lookup Service for Internet Applications. Proceedings of ACM SIGCOMM,
pp. 149–160.
[9] Kris Hildrum et al (2002): Distributed Object Location in a Dynamic Network. Proceedings of ACM SPAA, pp. 41-52.
[10] Arora, M. et al. (2002): A De-Centralized Scheduling and Load Balancing Algorithm for Heterogeneous Grid Environments. Proceedings of International Conference on Parallel Processing Workshops (ICPPW ’02), pp. 499-505.
[11] David Karger ; Matthias Ruhl (2003): New Algorithms for Load Balancing in Peer-to-Peer Systems.Tech. Rep. MIT-LCS-TR-91. [12] Shan, H. et al. (2003): Job Superscheduler Architecture and Performance in Computational Grid Environments. Proceedings of
ACM/IEEE Conference on Supercomputing, pp. 44-48.
[13] Brighten Godfrey et al. (2004): Load Balancing in Dynamic Structured P2P Systems. Proceeding of Twenty-Third Annual Joint Conference of the IEEE Computer and Communication Societies (INFOCOM 2004), 4, pp. 2253-2262.
[14] Yu-kwong. ; Lap-sun. (2004): A new fuzzy-decision based load balancing system for distributed object computing.Journal of Parallel and Distributed Computing, 64(2), pp. 238-253.
[15] Xio Qin ; Hong Jeong (2005): Improving Effective Bandwidth of Networks on Clusters using Balancing for Communication-Intensive. Proceedings of the 24th IEEE Intern Computing and Communications Conference (IPCCC 2005), pp.27-34.
[16] Murata, Y. et al. (2006): A Distributed and Cooperative Load Balancing Mechanism for Large-Scale P2P Systems.Proceedings of International Symposium on Applications and Internet (SAINT ’06) Workshops,pp. 126-129.
[17] Paul Werstein et al. (2006) : Load Balancing in a Cluster Computer.Proceedings of the Seventh International Conference on Parallel and Distributed Computing, Applications and Technologies (PDCAT'06), pp. 569-577.
[18] Siriluck Lorpunmanee et al. (2007): An Ant Colony Optimization for Dynamic Job Scheduling in Grid Environment.International Journal of Computer and Information Science and Engineering, 1(4), pp. 207-214.
[19] Bing Qi Chunhui Zhao (2007): Ant Algorithm Based Load Balancing for Network Sessions. Proceedings of 3rd International Conference on Natural Computation, 4, pp. 771-775.
[20] Misra, M. et al. (2007): On the Design of Adaptive and Decentralized Load-Balancing Algorithms with Load Estimation for Computational Grid Environments. Institute of Electrical and Electronics Engineer Transaction On Parallel And Distributed System, 18(12), pp. 1675-1686.
[21] Yagoubi, B.; Slimani, Y. (2007): Task Load Balancing Strategy for Grid Computing. Journal of Computer Science,3 (3), pp.186-194. [22] Shahu Chatrapati ,K. et. all (2008): A Novel Approach for Effective Dynamic Load Balancing by using Tendensive
Weight.International Journal of Computer Science and Network Security, 8(6), pp. 42-48.
[23] Chen, C.; Tsai.K.C. (2008) : The server reassignment problem for load balancing in structured P2P systems.IEEE Transaction on Parallel Distributed Systems, 19(2), pp. 234–246.
[24] Sosa, C. ; Grimshaw, A.S. (2008): Bringing the Grid Home. Proceedings of 9th
IEEE/ACM International Conference on Grid Computing, pp. 152-159.
[25] Qingyang Meng et al. (2008): A Dynamic Load Balancing Method Based on Stability Analysis. Proceedings of International Symposium on Computer Science and Computational Technology (ISCSCT’08), pp. 404-408.