A NOVEL CLASSIFICATION TECHNIQUE
BASED INTRUSION DETECTION SYSTEM FOR
SCADA NETWORK
R. B. Benisha, Dr. S. Raja Ratna
Abstract- The challenging task in the research area of network security is to detect and identify the attackers in the network. Intrusion detection system is used to protect the network from attackers and used to block the unauthorized access to network. The existing intrusion detection system has many drawbacks that it can detect only the known attacks and can produce false alarms due to their unpredictable behaviors of the network. To overcome this problem, Enhanced Markov Model (EMM) and Weight Vector Machine (WVM) are proposed to identify and classify the attacks from the Supervisory Control and Data Acquisition (SCADA) network. In this paper attack occurred in the power system dataset is used for analysis. During preprocessing process the relays are segregated from the dataset as S1, S2, S3, and S4. The details of the time, location, date, log report, and load condition are stored in each relay. Then Boyer String (BS) model is proposed to perform the operation of string matching. The WVM is used t o identify the known and unknown attacks of the SCADA network. The main objective of this paper is to train the data manually for unknown attacks, to reduce the features and to classify the attacks based on the best feature selection. Experimental results show the better performance in terms of the parameters such as False Acceptance Rate (FAR), False Rejection Rate (FRR), Error rate, detection accuracy rate, sensitivity, specificity and recall.
Keywords: Intrusion detection system; Weight vector machine; power attack; Supervisory Control and Data Acquisition.
————————————————————
1.INTRODUCTION:
In today’s technology internet is the major part used in all the marketing fields for their purpose. Through communication private companies develop the use of internet. The drawback associated with the network facility is if any data is hacked or the server is completely disrupted then the systems may lead to vulnerabilities. To prevent the network from such vulnerabilities intrusion detection system is the most wanted thing. SCADA network provides connection to the sensors and actuators that are highly controlled by the Programmable Logic Controller (PLC). A specialized gateway is provided for the private networks to connect with the network. In SCADA network protection is mainly given by firewall and secured passwords. It monitors the communication and user activities remotely even over a long distance. The harmful attacks are detected by the intrusion detection system. The pattern recognition helps in analyzing the network packets that causes traffic and delay. Two types of intrusion namely Signature based Intrusion Detection System (SIDS) and Anomaly based Intrusion Detection System (AIDS) can be done in this process. In SIDS, signature based on the known attacks is generated. In AIDS unknown intrusion can also be generated. The processes involved in the intrusion detection system are strategy, response, detection and preparation. In this paper a new Probabilistic Intrusion Filtering (PIF) technique is proposed to identify and classify the unknown and the known attacks that cause damage to the SCADA network. Boyer String model is used for matching the strings using the string matching algorithm. Generally this algorithm is calculated based on the complexity in time and space.
____________________
R. B. Benisha, Full-Time Research Scholar, Department of computer science and Engineering, V V College of Engineering, Tisaiyanvilai, India, [email protected]
Dr. S. Raja Ratna, Associate Professor, Department of computer science and Engineering, V V College of Engineering, Tisaiyanvilai, India, [email protected]
To cluster the data, EMM is used and to classify the attack WVM is used that produces complete probabilistic output. The major works processed in this paper are;
1) The power system attack dataset of SCADA network is taken for detecting the attacks.
2) In the preprocessing step, the relays from the dataset are separated in to s1, s2, s3 and s4. 3) The reports and details regarding the time, attack
location, date, and load information are stored in each relay.
4) After that strings are matched for the training dataset using BS algorithm.
5) Then the EMM is used to detect the kernels and to increase the efficiency.
6) Hence the attacks are classified using WVM based technique where known and unknown attacks are identified.
7) For the known attack, attack label is determined and the preventive measures are carried out. 8) If it is an unknown attack the energy level and
attack label is updated.
9) The novelty of this paper is it trains the features manually even for unknown attacks and provide reduced database by increasing the detection accuracy rate.
The paper is listed as follows; Section 2 presents the literature survey; Section 3 describes the proposed scheme; Scheme 4 describes the performance analysis of existing and proposed method; Section 5 concludes the paper with future work.
2. LITERATURE SURVEY:
3934 inspection performance to detect the unknown attacks in
the SCADA network. The multi-core application is developed using the approach. The overall performance is also increased by lowering the false rates.
Grilo et.al [5] developed a modeling wireless sensor network and SCADA system to control the real time, management and security systems. Almalawi et.al [6] introduced a superior AIDS approach to detect the integrity attacks present in the SCADA network. The work involved in this method is automatic detection of consistent states, inconsistent states and extraction. To separate the consistent and inconsistent observations, threshold is calculated. The proximity detection rules are extracted using fixed width clustering technique. Erez et.al [7] detected abnormal behavior in the modbus register values using AIDS. To learn the character of the network the registers are automatically ordered. Huang et.al [8] introduced a novel frame structure to transfer the data based on their transmission and operation.
Karthick et.al [9] introduced a framework with an adaptive network that includes two steps. In the first stage traffic attack is identified with the help of supervised classifier. In the second stage the location, IP addresses are detected using hidden traffic model. It is effective in real time during
functioning. Koc et.al [10] introduced a Enhance Naïve Bayes to classify the normal and abnormal behaviors in the network. The performance of the detection rate is better while comparing with the Naïve Bayes.
3. PROPOSED METHOD:
In this section, a new Probabilistic Intrusion Filtering (PIF) algorithm is proposed and the steps involved in this method are preprocessing, Matching the string, Clustering and classification, and label of attack. In this paper known and unknown attacks are detected and classified. The PIF based classification technique is used to classify the intruders. To evaluate the performance, power system attack dataset is used. The proposed system detects the known and unknown attacks as listed in table.1
The relays are segregated in to four parts S1, S2, S3, and S4 that contains the detailed information of time, date, location and load condition of the network. Figure.1 describes the block diagram of the proposed architecture.
Figure.1 Block diagram of the proposed architecture
Table.1 Attack types
Attacks Abbreviation
Normal Normal (0)
DoS Denial of Service (1)
Integrity Response Injection IRI (2) False data Injection FDI (3) Ultraviolent Data code Injection UDCI (4)
Reconnaisance Recon (6)
Malicious Code Injection MCI (7)
in controlling the circuit are power generator (P1 and P2), relays and breakers.
3.1 Preprocessing:
In this process, relays are segregated from the given dataset. In this stage gas and water dataset is used for preprocessing that segregates the relay and the log details. The water and gas dataset contains list of parameters described below in table.2
Table.2 Parameters of water and gas dataset Gas parameter Water parameter Addressing command Addressing command
Memory command Memory command
Addressing response Addressing response Memory response Memory response Reading command function Reading command function Writing Command function Writing Command function
Bandwidth HH
Length L
Set point Control
Location Control mode
Correction rate result
3.2 Matching the string:
The next step after preprocessing is matching the string for training data. To perform this operation Boyer String (BS) algorithm is used. It matches the string accurately due to its generalized technique. In bio application this type of algorithm is most commonly wanted. The strings are matched based on the order from right to left. At each alignment the behaviors of each pattern are analyzed. The current text is compared with the right most corner of the pattern and then it is shifted from left to right. The process involved in the string matching is shown in Algorithm 1. Algorithm.1 Matching the string using BS
Input: Initialize training data set
T
R and testingdata set
T
DOutput: String matching
M
and training set updationT
RStep.1 Set k=1
For j=1 to I; //length initialized Step.2 For j=1 to L; //Length of training set Step.3
h
S
(
D
)
; //SizeStep.4 if
(
I
T
R)
&h
S
(
T
R)
S
j
OZT
R(
k
)
T
R(
Size
)
; //training set updatedStep.5 else
OZT
R(
k
)
T
R(
j
)
; // training setupdated at
j
th index Step.6 End process3.3 Clustering and Classification:
After sting matching process, known and unknown attacks in the SCADA network is clustered and classified. The process involved in the clustering is it divides the data points in to different groups in which each groups resemble in some characteristics. The process of increasing the interclass similarities and reducing the inter cluster
similarities is commonly defined as clustering. This clustering technique can detects the patterns of unknown attacks with several dimensions. The major advantages of using EMM algorithm for clustering is it detects the attacks in audit data to remove the attacker and network interactions. The classification is based on the Weight Vector Machine (WVM) that classifies known and unknown attacks. Due to less support vector in SVM the usage of WVM provides better performance and reliability. This method is based on the Bayesian Linear Model that gives accurate outputs in a sparse form. Also the computational cost is very low in providing interferences.
The data set
{
I
i,
OZ
j}
R
nj1; whereI
i indicates theinput vector and
OZ
indicates output. The Output obtained using WVM is given as;)]
)
(
(
)),...
(
(
[
))
(
(
1 j L L n j jL
Z
R
I
C
R
I
C
C
I
OZ
(1) WhereZ
[
Z
o...
Z
j]
indicates the vector weightsand
[
R
(
I
(
C
L)),...
R
(
I
(
C
L)
j)]
indicates the kernels.Using WVM method the Gaussian kernel is calculated as given below; 3
5
)
(
)
(
exp[
)]
)
(
(
)),...
(
(
[
j L L j L LC
I
C
I
C
I
R
C
I
R
(2)
Where
determines the Gaussian kernel width. The data set likelihood is given as;
OZ
Z
OZ
P
3 3 n/3 33
1
exp[
)
2
(
)
,
/
(
(3))]
)
(
(
),...
)
(
(
,
1
[
)
)
(
(
I
C
L j
R
I
C
L 1R
I
C
L n
(4) To improve the WVM ability an probability distribution is
calculated as;
)
)
(
/
(
)
/
(
1 j n j Lj
OZ
C
Z
N
Y
Z
P
(5)Where
Y
represent the hyper parameter vector. The WVM based classification is given as;)]
)
(
(
,
)
(
[
))
(
(
'
))
(
(
1 j L n j j L LL
I
C
OZ
C
I
C
C
I
OZ
(6)
Algorithm.2 Clustering the attributes
Input: Updated training set
T
R, testing data setT
D and labelL
AOutput: Clustered data
C
LStep.1 Initialize
P
R(
Z
i
Size
)
; //probability arrayStep.2 for j=1 to S(D); // Row size Step.3 for j=1 to S(D); //Column size
Size
OZT
R(
i
,
j
)
; Attributes extractionStep.4
D
(
s
j
d
j)
(
s
j
d
j)
3936
Step.6
nj
i
S
Q
D
Z
1
))
(
(
Step.7 2
1
)
(
1
j j n
j j
D
D
s
d
Z
n
; //length representationStep.8
I D
D n
D
j
e
D
P
2 31 { 3 / 3
*
)
3
(
)
(
; // probabilityestimation
Step.9 if
OZT
R/
j)
j)
P
(
D
)
; //attack conditionStep.10
C
L
L
AP
(
D
)
; //attack node identifiedStep.11 End process
Moreover set of kernel functions are produced by this method that contains the set of weight functions to represent the dataset for studying purpose. The kernels, functions and modeling functions are studied in this process by placing weighted kernels in a stable position. The sparse subset is chosen from the set of WVM based training vectors. The outputs are estimated and a relevant vector computes a basic model function. After clustering, data is classified in to normal and abnormal data. The gas and water dataset is used for the training and testing purpose. In the training process PIF based IDS classifies the attacked and normal data. Based on their rules and functions in the proposed method the IDS classify the audit data as attacked or normal.
4. PERFORMANCE EVALUATION:
In this section performance of the proposed method PIF based IDS is analyzed to determine the power system attack in the SCADA network. The dataset contains 15 sets of data with 37 scenarios. It is divided in to three events namely natural attack, event attack and no attack. Three datasets are used to sample randomly such as single class, three class and multi class. The results are validated using water and gas data set. The parameters used for the analysis are False Acceptance Rate (FAR), False Rejection Rate (FRR), Error rate, detection accuracy rate, sensitivity, specificity and recall.
Table.3 Classification output of existing and proposed method
Negative alarm rate
Parameter (%) HNN PIF
FPR 0 0
FNR 1 0
Accuracy 100 100
M set point
FPR
3.2
0.4
FNR 4 0.5
Accuracy 94.6 99.4
R set point
FPR 3.5 1.0
FNR 4 0.5
Accuracy 93.7 99.52
RR alarm rate
FPR 2.5 1.2
FNR 0 0
Accuracy 93.9 99.4
The error rate detects the amount of errors that are caused during transmitting the data. If the data transferred has low reliability then it produces higher
Figure.2 Error rate of the proposed method with respect to the attackers
Figure.3 Recall of the proposed method with respect to the attackers
Figure.4 False detection rate of the proposed method with respect to the attackers
error rate. The error rate in terms of probability
P
ER is determined to find the maximum number of incorrect decisions. Figure.2, 3 and 4 describes the error rate, recall and false rate of the proposed method with respect to the attackers. The performance of the classified output with the proposed method is evaluated in this work.-0.05 0 0.05 0.1 0.15 0.2 0.25 0.3
0 10 20 30 40 50 60
E
r
r
o
r
r
a
te
Attacks (%)
0 0.2 0.4 0.6 0.8 1 1.2
0 10 20 30 40 50 60
R
ec
all
Attacks (%)
-0.02 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 0.2
0 10 20 30 40 50 60
Fals
e
d
etec
tio
n
r
ate
Table. 4 Performance metrics with the proposed method
Parameter Value
True positive 1760
True Negative 341
False positive 34
False negative 0
Sensitivity 100
Specificity 99.75
Recall 99.82
Accuracy 99.92
False acceptance rate 0.127 False rejection rate 0.185
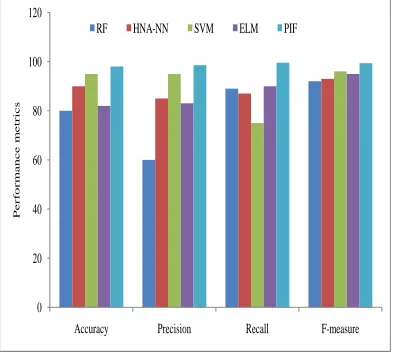
Recall defines the truly detected number of attacks and also it is used in many applications of network to calculate the accurate detection. The detection accuracy of other classes is less significant than this detection rate. This achieves higher detection rate performance with the proposed algorithm. It is more important to detect attacks in the network rather than honest users. Table.3 describes the classification results of existing and proposed method. The parameters such as false positive rate, false negative rate and accuracy are analyzed for comparison. The proposed PIF technique produces better results when compared with the existing methods. The above mentioned parameters are calculated for R set point, M set point, Negative alarm rate, and RR alarm rate. The parameters detection rate, precision, recall and false rate of the proposed method are valuated with the existing algorithms. Sensitivity is the proportional ratio of correctly identified true positive values. It determines the test result of true positive values expressed in percentage. It is the number of true positive assessments to the number of all positive assessments (true positive and false negative). The specificity is the number of true negative assessments to the number of all negative assessments. The accuracy is calculated in terms of both sensitivity and specificity which is defined by total number of true positive assessments to the overall assessments. False Rejection Rate is the number of false rejections to the number of items identified. False Acceptance Rate is the number of false acceptances to the number of items identified. The performance measures of the proposed PIF based IDS is illustrated in table.4. Figure.5 describes the comparison of parameters accuracy, precision, recall and F-measure of the proposed method with existing method.
Figure.5 Comparison of parameters accuracy, precision, recall and F-measure of the proposed
method with existing method
5. CONCLUSION:
In this work, Enhanced Markov Model based IDS and the Weight Vector Machine namely Probabilistic Intrusion Filtering based classification method is proposed. The dataset contains power system attack and the proposed system is used to evaluate the performance. First preprocessing is done to segregate the relays from the dataset in to S1, S2, S3, and S4.
Each relays predicts the information of the network. Then Boyer String algorithm is proposed for matching the operation of string. The PIF based IDS is proposed to detect the known and unknown attack. If attack is known care should be taken and if it is unknown the energy level and the label of attack is updated. The major contribution of this paper is to detect the attacks in the SCADA network accurately. In this work, the training data is detected manually to identify unknown attacks. Also reduced database is used and the increased detection rate is obtained. An experimental result of the proposed method is compared with the existing method that shows better performance with the proposed method.
FUTURE WORK:
The proposed IDS will be used to identify several attacks such as Sinkhole, Wormhole and replay attack in the SCADA network.
REFERENCES:
[1] M. A. Faisal, et al., "Data-Stream-Based Intrusion Detection System for Advanced Metering Infrastructure in Smart Grid: A Feasibility Study, "IEEE Systems Journal, vol. 9, pp. 31-44, 2015. [2] L. Aiping, et al., "A New Method of Data
Preprocessing for Network Security Situational Awareness," in 2010 2nd International Workshop on Database Technology and Applications (DBTA),2010, pp. 1-4.
[3] J. J. Davis and A. J. Clark, "Data preprocessing for anomaly based network intrusion detection: A review," Computers & Security, vol. 30, pp. 353-375, 2011.
[4] T. J. Parvat and P. Chandra, "A Novel Approach to Deep Packet Inspection for Intrusion Detection," Procedia Computer Science, vol. 45, pp. 506-513, 2015.
[5] A. M. Grilo, et al., "An integrated WSAN and SCADA system for monitoring a critical infrastructure," Industrial Informatics, IEEE
Transactions on, vol. 10, pp. 1755-1764, 2014. [6] A. Almalawi, et al., "An unsupervised anomaly
based detection approach for integrity attacks on SCADA systems," Computers & Security, vol. 46, pp. 94-110, 2014.
[7] N. Erez and A. Wool, "Control variableclassification, modeling and anomaly detection in Modbus/TCP SCADA systems,"
International Journal of Critical Infrastructure Protection, vol. 0,pp. 59-70, 2015.
0 20 40 60 80 100 120
Accuracy Precision Recall F-measure
P
er
f
o
r
m
an
ce
m
etr
ics
3938 [8] S.-C. Huang, et al., "Evaluation of AMI and SCADA
Data Synergy for Distribution Feeder Modeling," IEEE Transactions on Smart Grid, vol. 6, pp. 1639 -1647, 2015.
[9] R. R. Karthick, et al., "Adaptive network intrusion detection system using a hybrid approach," in Communication Systems and Networks (COMSNETS), 2012 Fourth International
Conference on, 2012, pp. 1-7.