hoceeding-
bookI
;
:,pf,ffiORIt'IANCE
IMPRO\EMENT
OF
BACK-PROpAGATION
NEURAT
NET.}YORK
I,BAR}IING ATGORITIIMS BY
INTROI}UCING GAIN VARIATION
OF'
ACTTVATION
F.[}NCTION
Nrlrt
MohdNrwL RozrHr Chrarll,
Mohd NeJlb Mohd Sellshr)t)
Faculty of Informatiou TechaoSgy aod Multimedia" Univcmiti Tun Hussein Onn lrdalaysia (LITHM),""tilffi^
[email protected], rozaid@rrfrm"cdu.my, naji@uthm. edumy
"ffifraa -Ye
? propose pnoposea
a
method nethodfor
for
inprovtng
theof
the
backprcpagation algarithm
bybyi.''
ifr{toduehggah voiation
of ,lre rctivationfwtion. In
'_ a
feedforwud' algoritla
tIrcslop
of the
xtiwtion
ii:fiorction
isdiretly
Wwted
by aparnw
,eM
i'
,ta as 'gain'.In
thispqer,
the idluarce of thewriation
'of
'galn' on the lc.arningeility $
a nanral rctwark isonlysd. tfrilti
lalterfed
forawd
neural naworb
,raw
been
awessed.Pbsiel
intapretatiat
6
t rcrelatiottship between
tlre
gsin valtte and thelernhg
rde
erd *elght
wfus
is
given.Instcd of
a
wstant
'gain'
vslue, tryWpose
analgaritlm
u
clwtge
thegain
wlrc
futfvegfor
erehn&.
ne
e$furcyolthe
p@
nethd
iswr$€d
by n e6u:s ofsinutaion
(m aWtty
problemand
classification prcblem. The results show that thepraposd
netld
considerably improwstlu
leaning
Wed
of tle
general
backprqngation
algorithm.
Kcywerds: Back-propgation Nearal rVenror&s, Gain.
Act iv at ion fu n c t ion, Le am i n g ro t e, Tra in i n g E_{li c i e nc
1-1.
Introduction
We considsr standard multi-layer fsed forrvard neural . networts that have an
inpU lalar of
neurons, a hiddenhyer
of
nsurons and an output layerof
neurons, and in that every nodein a
lalrr
is
connectedto
evcry othernode
in
the
adjacent forward
layer.
Tlrc
back-propagation algorithm has been
the
most popularand
mst
widely implerncntd
for
training thesetlpes
of
mral
network. When using
the
back-propagationalgorithm
to
hain
a
multibyer neural
oitood
th€dcsigncr
is
rpgrird
toarbihtrily
sclcct pararrcter suchas the network
toplogy,
initial
weightsald
biascga
l*iog
rate value, the activation function, and a valuefor the gain
in
the
activatibn function.An
irnproperchoicc
of
any
of
these paramcters can resultin
slow oonvergcnoeor
even
ncfworle paralysiswhere
thetaining
process colnesto a virtual
standstill. AnofrerProblem
i$
thc
ten&ncy
of
th€
steepest desccnttec$iqw, uftich
is usedin
thc trainingpi*rre,
to
get sfuck at local minimaIn
recent years,a
numberof
research shrdios have afi€mpt€d tro overcorne thcse problems. Thosesinvolvd
&c dovclopment of hcuristic tcchniques, based on sludies
of properties
of
thc gcnerat back-propagationalgorithn
Th€sc
tcqhniqrcs inolude
s|ltchidea as varying
thdlculdng raic, using momcntrm, gain tudng of activation
fimction
P€raofioaiset
aL[l]
proposcdm
algorithnfor
cfficient lcrrning
in
focd forcrad reural networlcsuing
norncntum accclcration. Ifumartbict
al. [2Jprwn8
auniversal accehrrtion
t€chniryle
for ttc
back-propagationalgoriem
brsedon
extrryotationof
eachiodividml
intcrmnnccfu T€ight
Researchhrs
elsofocused on the
ruc
of
S@
nwical
optimisationtechniques.
Molhr
[3] erylaincdbw
conjugate gradicnt algoritfun could be uscd t0 trsin mrlti-tayer feed forward ncur8l networtswhih
Lcn
ct
al.[4]
kibod
tho useof
l,cvenberg-Marquardt algorithmfor
$aining
multi-layer fecd forward neuralrctworts.
However, mostof
thcse rnethods
arc
qtrite
aorylcrv
rcquirc
exccssive nrcinory and are computatbnally very cxpcnsivc.In
orderto
improvethc
pcrforrrunceof
theback-propagation algorithm an algorithm has bcen proposd in
this
paperto
changethe gain
valucadapivcly.
It
isshonn that changirg
the'gain'value
adaptivcly for each node can significantly reduce the training time. In ordcrto verifii
drc efficacyof
the propos€d metha4 and tocompar€
it with
the general back-prop4gation algorithm,w?
perform simulation
experimentson
a
function approximation problem using the sequcntial aswell
asbatch
md€s
ofhriaing
l.l
Blftct of
the
g*in
parsmster
on
.the
performtnce
of
a
neunl
network
An
activation firnction
is
used
for
limiting
theamplitude
of
thc ougut
of
a
reuron.
It
generatcs anouQut vafuc
for
a
nodein
a
predcfinedruUc
as thecloscd
unit
interual[0, U or
altcrnatively[-I,
+U.
Thisvaluc
is a
function
of
the
wcightcd inputs
of
the corrcsponding node. Thermt
cornrnonly uscd activationfinction
is
the
logietic sigrmid
activation firnction.Alternative choices are
the
hypcrbolic tangent, lincar,stcp activation firactions.
For th" Jo
node,a
logisticsigrnoid activation
finstion
which has a mnge of[OJ]
isa firnction of the following variablcs, viz.
I
ar=:
(l)
PERTORMANCEIMPROIfEIT{EhITOF BACK.PROPAGATIONNET'RAL NBTWORKLBARNINCAITIORMilISI...
--t
Whore,
IVhsre,
;.,
ortp^r1:{$c.r"*it
_.
Jwu
wcight of
thelink
from unit
i
tounit7.
d*,j
netinput activation function for
theTdunit.
er
biasfor
thc/
unit.
cl
gainof thc activation
function.'
The
vahre
of
the
g:in
parameter,c'
directlyinfluences
fts
slopc of the activation firnction. For large gain whrcs (c>> l),
the activation firnction approaches a'stcp
fmction'
whcrcasfor
smll
gain values (0<
c <<l),
thcq4lut
value
chroge friomzuo to unity
ovcr ahrgc
nngeof
thc wcightcd nrm offtc
input valucs and tLe eigpoid fimction rppmximatcs a lincar firnction.Most
of
tbc
application oricntcd papcrson
ncuralnetworls tcnd
to
advocate that neural nstvrorkf, opcratcIike
a
'magic black
box',
x,hich
can
eimulate thc'haening from
crqlle"
ability
of
our
hain
with
th€tc$
ofactwort
pffiqtctcrsari
as wcigftb, biascs,Fin,
ffi
rudcs
cb.
Lhcre arcvcry
fcrv publications,, orE*Soo*r,
rrytich givcphfical
inerprctation forrariou
puanc0ers
usd
in
6c
nctwort
Also,r
rmit valtrcfor
glin
hnd gpn€relly bccn uscdfor
mostof
the researchrcporbd
in
the
litcsatule
but
a
few
authors have r€scarcbod the rclationshipof
thc gain parameter withodrcr porarneFrs used
in
back-propagation algorithms.Thc
rwnt
results [5J show that learning rate, momentumconstant
and gain
of
the
activationfunction
have asignificant impact
on
training speed. Howevero highervalues
of
learning rate and/or gain cause instability [6].Thimm et. al, [7J also proved that a relationship between
thc gaia
value,a
set
of
initial
weight values. and alearning rate value exists. Looney [8J suggestcd to adjust
the gain value
in
small
incrernentsduring the
earlyitcrations and to keep it fixed sonrewhcre around halfway
ttrough the leanring. Eom et. al. [9] proposed a method
for rutomatic gain tuning using
atuzy
logic system"Howevcr,
the
authors
have
not
come
acrosspublications
ia
the
literaturethat have
implementedadaptive
gain variation as
go'poscdin
this
researchwork.
2,
The
Proposed
Method
Forouput unit
In
this
section,a
novel approachfor
improving theteining
efficiencyof
back propagation neuralnetwork
hidden units.algorithms is proposed.
firc
proposed algoritbm modifiesth€
initisl
search directionby
changing the gainvalue
values wouldadaptively
for
eachnode.
the
following zubsection
equations.describes
the
algorithn
The advantagerof
using rn
adaptivegain
value hsvc becn explored. Gain updateexpressions
asi
well as
wgight
and bias
updatc cxpressionsfor
ouQut and hidden nodcs have also beenproposed. These exprcssions have been dcrived using
2
salne principles as used
in
deriving weight
updatingexpressions.
Tbe sequcatial mode of fiaining requires an irnmediate
updating.
of
weights, biases
and
gains
after
the preEc,ntationof
nahing cxaryle
qfi€reasin
ft€
batchEodc
of
taining
tte
wcighf
bias andgain
updationterns
ari
catculateO andiurycd
for all
thc
frainingJxanpl"s.
In
this papcr, we only considsr on the batch mode naining as in thc batch modetaining
thc wcights,biases
and
gains
arc
updatcd afrer
one
completeprcsartation of thc entire
taining
sct An cpoch is said to be co'ryleteafur
tftc prc*cntotionof
the cntiretaining
sct. A. sum squarcdenof
rralueis
calculated after theprescntatim
of
the Eaining set and comparedwidr
thetrrget error. Training is done on an cpoch-by-epoch basis
rmtil6e
sum squard cnorhlls
bclow thc dcsired targetvalue. The following iteratirre algorithm is proposed by
the
authorsfor
the
batch modcof
taining.
Weights,biases and gains are calculatcd and updatcd for the
mtire
faining
sel ufiieh is bcingpresentcd totte
network.Tbe following iterative algodtrm is pmposed
by
theauthons
for
the batch modeof taining.
lVeight, biasesand gains are calcttlstcd aod updst€d
for
eachtaining
elample, which is berng presc,lrted to the networkForagiven
epoch,For each
uanple,
Stq
I
Calanhte the weight and bias values usingthe previousty converged gain value.
Stq
2
IJse the weightand
bias value calculated instep
(l)
to colculate the nev' gain value.Repeat steps (11 and (2)
for
each example on anepoch-b.r--epoch 6asis until the er','ot'on the entire training data
set reduces to a predefined value.
The gain update expression
tbr a
gradient descentmethod
is
calculatedby
differentiaing the
followingetror term
E
with
respectto
the
corresponding gain parameterThe network enor E is defined as follorvs:
a,nt;i=[*
wvo,)*t,
(2)
t
=
ll(tr-oo(o,,cr))'
(3)dE
oecds to. be calculated whercas fordrr
EE
ir
also required. The respective gainacj
thcn be
updatedwith
the
followingLc,=oCfil
=-(tr-or)os(r-o*)
(fnoo,
+or)
(6)' - -- - "- i exprcssion
for
lints
,ci r(n + r) = n
$,
-
o *) or(t
-
o)(Zn
*o,
*
or)
(7)lr, :'
l',iHicrcfore,
thc
gain
updsto expressionfor
the
linksproceeding _ book 1 simulations have been carried out on a Fe,ntiurn
w
with3
GIlz
PC
Dell,
I
GB
RAIU and
using IvIATLABversion 6.5.0
(Rl3).
On
qph
probleq
thefollowing
tbree algorithms were. auaily?rdaud simulated.l)
The slhndard gra{ignt desceirt with momentrm(traing&n)
from
'ldatlab
Neural
NchsorkToolbox version 4.0.
l'.
2)
Thc standard Gradient descc,nt with momentum(cDM)
(5)t',,,i,'
r;Simila'rly,6c weight aod bias cxprerrions arc calculated
.as followg:
i
Tbc werght rrydatc cxprcscion for thc links connectiry to
output nodes
wi&
a bias is:Anr =qkr -o*)o*(l-o.
)"ro,
(lo)
Simila'rly, the, bias
up$te
erprcssionsfor
the oueut
nodes would be:
A0r =e
Qr
-or)r.(l -o*br
(l
l)
flry
weight updaec exprcssion tbr the links connecting tohidden nodes is:
I
-orllr,o,lt-o,b,
J
Similarly,
thc
bias updat€ expressionsfor
the
hiddennodcs would be:
3.
Results
rnd
lllscussionc
The
pcrformancecritcrion used
in
this
researchfocuses
on
the
speedof
convergence, messurod in numberof
iterations andCpU timc. The
benchmark ptoblems us€d to
verifr
our algoritlrn are taken &omtte
open literature. Four classification problems have been
5F
includingparity 7 bit,
Wisconsin breast gancetr,ulabetes
and IRIS
classification
problern
The3)
The plopoecd Gradient descent withmnsntum
and Adgptive Gain (GD!WAG)
To
oompasothe
perfornance
of
the
proposedalgoriftn
wie
respectto o6sr
rtandrrd
optimization algorithms from thcI{ATLAB
redral nctwoik toolbor;mtTyork pammsters
such
as
network
sizc
and architecture (nunber of nodes, hidd€n layers etc), valuesbr
the initial
wcighf
and gain parametcrs wcre kept sarn€.For .all
psobbmstho nclrrrt retwort. had
onehidden
lrycr
with
Iive
hid&n
nodesand
sigmid
activation frtnctioo uns usodfora[oodes. All algorisns
were
tpsbd
usiagthc
gam€initiEl weighb, initslized
raodomly
fiom
raage[0, U
snd
receivedthe
igputpafiems for hriniqg in
fu
rams scglcoc€.For all trainhg
elgorithms, theharnhg
rate nalueqns 0.3
a4dthc
Emnrum
tcrm rnlue
was0.2.
Thcinitial rlrhlc
usedfor
thcgrin psrmster
was one. Forcach
nrn'
tbcnrrrulicel
data,is
gorcdin
two ,fihg-ltc
rxuls
file, andth
surmary filc. Thcrc$lt
filc liss
dataabout each
networt
Tb
nurser
of
ircraftrns
untilconvergenc€
is
amrmuhtsd
for
mh
Cgorithm &ourwhich thc ncan" the strndard
&viation
and the numberof
faihnesare
calculatcd.The
networksthat
fail
toconvcrg€ are
obviousll'crchded
ftomtlr
calculationsof
the
mean and standrrd der.iationbut arc
rcported asfailures.
.
For each protrlcru 100 diftbrent trials were run, eachwith diftbrent inirial random set of u'cights. For each run,
fic
numbcrof
itcrations requiredfor
convcrgence isreportcd. For an experiment
of
100 nuu, tlrc nrceR of the number of iterations (mean). the strndard deviation (SD),and the number of failurcs are
colleted. A
failure occurswhen the rrctwork exceeds the maximum iteration limit;
each
experimentis
run
to
tsn
thousand iterations; otherwise,it
is hdted and th€ nrn is rcportod as a failure.Convergence
is
achievedwhen
the
oueuts
of
thenetwork conform
to
tlreeror
criterion as compared to.
(13)
the desired outPuts'3i.17
Bit
Perity Problem
Thc
ptty
problemis
also oneof
the most popularinitial tcsting tasks and vcry deruanding chssification for
neural nctwork
to
solve,
becauscthe
target-outputcbanges uAcnsver
a
singlc
bit
in
th€
input
voctor changesand
this
makes generalizationdifficult
andlearning
does
not
always
oonvergeeasily[l0].
Theselccted architecture
of
thc FNN
is
Z-5-1. The targcflenor has been sct to 0.05.
The resulb
in
cble
I
showthat the
convergence success rateof
GDIWAG is 960/o, and tbat thc average lcormecting hiddcn nodes is:,l
r, (o * r) =
r['1",*
*a. (t - o. ) (r. - o,\o,$ -o,t(T
"rr, J. r, )
tt'
r
o*,i
=4t*r,
or(t-o*)ftr
(12)
ot,
=PERFOB}{AI'ICE IMPRO\Er&,IT.OF BACK-PROPAGATION NBT RAL NETWORK IBARMNG ALCORIffiI'{S... _s.
ntrmber learqing iterations.
is
rcduccdby
about 607ocoryared
to
GDM, and
by
about 96%coryarcd
to fiBingdm.An
out3tantting chsrastpristfcof
thg proposedGDtvl/AG method is thnt the parity 7 bit problem can be
solvodwith very few learning itsrations.
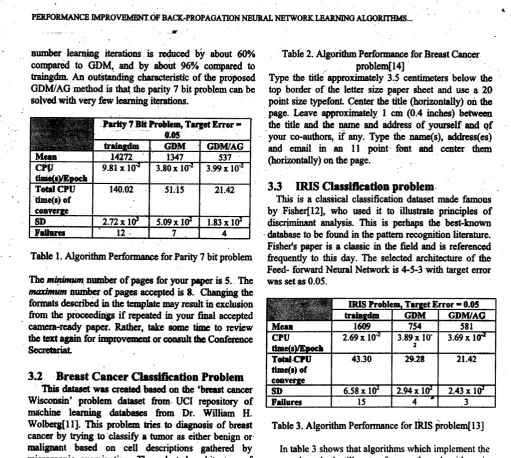
Tablc
l.
Algorithm Performanoo forParity 7 bitproblem@
llrgiAlllltnrqbcr
of pagcs forlour
prper is5.
The ,rrar;irtwrr aumbsr,ofpages accgptcd isS.
Changiqg thcforbts
describcd intc
terylatc
may result in"oGioo
.
from thc pr-ooocdingsif
rqcatcd in yorr
fnal
acceptedcamcra*cady paper. Rathgr"
tab
sffi
tinreto rcvbw
thc
f*
sgab forirycovarncd
or consult tho Conforacc Sccretuiar3.2
Breaet Csncer
Clrestfication
Problem
Thb
drta$ct wrg er€atod.bdod on the'berut
canccrWiscssin'
problem datrset ftsm.
UCI
rcpositoryof
mrchim
learning
databasosftrom
Dr.
William
H.Wolbcryfl
U.
Tbispoblcm tics. to
diegnosisof
brcegt c'anccfby trt'iqg
io-classiry e firmor as either benign ornalignut
bsscd
on cell
descriptions gathered bymicroscopic cxamination.
The
sclectcd architectureof
thc Feed- fonvard Neural Netrrorkis
9-5-2. The targeteror
is set as to 0.02.Tablc
2
clcarly
shows
that
algorithms
whichirylcmcnt
our
pmposednrthod
exhibit very
goodaycragc perforrnancc
in
order
to
reachftrget
eror.
Furthermorethe numbs
of
faihncsfor
the
proposednffi
is
smallcr as
comparedto
others. GDL{/AGned*
only
405 epochsto
converge as opposedto
the standard GDM at aboutll05
epochs and traingdmwith
3419 epochs. The rcsults elearly show that the proposed
method
GDil#AG
outperforrrreural
oetworkbolbsx
algoriftm
with
an improvemcnt ratio, nearly 3.2, for thetotal time of eonuergo,
Table 2. Algorithm Pcrforuaqc€ for Breast Cancer
problemfi4J
T1rye
&e
title
ly
3,5 centimeters below thetop border
of
the letter size paper sheet and usea
20point size
tlpefont
Center tbe title (hofizontally) on the pagc.I*ave
approximalclyI
cm (0.aincb*)
bcfireonthe
title
and the nanrc and addressof
yoursclf,md
gf
your co-arfrors,
if
*y.
Typc the namc(s), address(es)and
in
rn lt
point
font
md
c€ntcr
thc,m(horizonally) on thc page.
3.3
IRIS
Clarslficrtlon
problem.
Thtq
is
a classical olassification dataset mado famotsby
Fisher[2J, who
usedit
to
illusbafia principlesof
discr.ininrnt analyois.
This is
pertapsthc
b€st-knoqm -database to be formd in the pattem recognition literaaue. Fisheds pap€ris
a classiciu
thefield
and is referencedfrequently
to
this day. The selectsd architectur€of fte
Feed- forward Netnal Network is 4-5-3 with target errorwas set as 0.05.
Table 3. Algorithm Performance for
ruS
fblem[l3]
In table 3 shows that algorithms rvhich implement the
proposed method
still
outperfonr's other algorithms interm of CPIJ time and number of epochs. As we can see
that GDM/AG was
97o/o successfulat
learning the patterns and the av'ciag€ nrunbcrof
learning itcrationswas
reducedgreatly
as
it
is
thrce times
fbtcr
ascompared to ncural network toolbox.
3.4 Diabetes
Classiflcrtion
Problem
This dataset was created based on the 'Pima Indians
diabetes' problem dataset
from
theUCI
repositoryof
rnachine learning database. From the dataset doctors try to diagnose diabetesof
Pirna Indians based on personal data (age, numberof
times pregnanQ and the resultsof
medical examinations (e.g. blood pressure, body nrass
index, result 9f glucose tolerance tesf etc.) before
&cide
whether a Pima Indian individual is diabetes positive ornot. The selected architecture of the Fced-forward Neural Network is 8-5-2. The target €nor is set to 0.01.
In table 4,
it
is worth noticingtbt
&o perforrnancpof
the
proposedGDIWAG
is
almost .twice
faster
as cornparedto
neural network toolbox.GDlvt/AC
tookonly
417 epochsto
reach the target error compare toGDM at about 520 epochs and worst
fot
traingdmttat
nscd about 965 epochs
to
convcrge.Stilt
the proposedatgoritbm
ouperform othsr algori6ms
in
termof
the. total time of convcrgeBrcrrt Cenccr Problcm, Tergct Error
-0.02
[image:4.550.16.528.10.468.2]Trble'4. Algorithm Performance for Diabctos
probbmll4l
Advrntages
of
Us
Gain
Variation
'i.'."'
Anslgorien
hrs been proposed inftis
paper for the1;
offcicnt
cabutatioriof
tbe adaptivc gnin valrrcin
bodri
bc+rcotielrnd
batch modesof
learning. We propoecd&d
tk
totd
l€sming ratc value can be pplitinto
two",'p11S
*
Ebcal
(noda[)l€ming
rafiewlrrc rnd
a g[obal'
(sarc
fbr all nodos in a dehvork) l@ning rd€yahr.
Tb
.
rnhp
of
pclm
gdn
is
iht€ryrttcd
s
trs
locat ,:.bof,[irg
rataof
r
nodein
lbo tr€turcrLTb
m,tsork
is,. haind
rning a fixed valueof
lcarning rat€e$nl
!o 0.3nrhich
ii
intcrpretcd as the global leaming rateof
thenbhvort- Honrever, as the gain vahle was
difie4
Sc
wcigbls rnd bisscs werer@ted
using thc oew valucof
Sain" This nozultcd in higbcr rnlucs of grin which
causd
instability
[{.
To svoid oscillgtions drlriog Hainingad
torhierrc
snycrgcncc, sn upperlimit of
2.0 is set for ihc gnin valuc. Thiswill
be explainedin deail in
otrrncxt
prbllcation.
The nrethod has bcen illustrated forkadient
Desccnt training atgorithm using the sequential and batch modesof
naining.fui
advanageof
using the adaptive gain proccdure isthu
it is casy to inroduce intoa back-propagation algorithm and
it
also acceleratcs thel€anrir€
processwithout
a
needto
invoke
solutionprocedurcs other than thc Gradicnt Desccnt method. The
adaptive
gain
procedure hasa
posiliveeffet in
thekning
processby modiffing
the magnitude, and notfu
direction,of
tbc weight change vector. This greatlyincreases thc lcarning speed by ampli$ing the dirictions
in
the weiglrt spacc that are zuccessfully chosen by the Grradient-Descent msthod. However,the
rnsthodwill
also
be
rdvantagcous
when using other
fastoroptimization algorithms such
as
Conjugate€radient nothod and Quasi-Newton method. Thesemetffi
can only optimize an equivalentof
the global learning rate(lb
rtop lmglh).
By
incoducingan
additional local lcandng rate paranretcr, firrther incrcascin
the lcamingsp€ed can be achieved. Wor& is currently under prognass
to
inplemcnt
&is
algorittrm usingotbcr
optimizationmctHs.
5.
Conclusion
While tbe back-propagation algoritbm is used
in
tbcnajority
of prac'tical ncural networks ryplication and hasmg
Adapative
been sbown to perform relatively
wpll,'thre
still
existar€es whcre
iryroveaent
can be made. We propoced analgori6n
to adrytivcly change the gain pamreterof &e
activation fimction
b
iuprove the leanripg speed"It
unsobssvcd.tht
&einflume
of variation.h th€ gafui valucis similar to thr
infhuce
of r.aridion in tho lcarning ratcvalue..An
algprithn
ha$ bcco proposcd itr this paper to.
cha4ge thC gain vduc adaptively foabach mdc.In
ordcrto vcrify thc
offectivenessof
thc propsed
algorithq
Eomc bcnchmrr,tproblcps wcrc
*-imtrhtrC and aoalyrrd rning bailch modcsof
training. The reeulbshowd thd
6c p$pord
@eivc
gain algotrithm bae abetter
convergqncetatq and
learning efficicncy
as compared to6egacral
bace-pryopagationaborieu.
Tb
!Gt*o*
alro dcoonstsatcdep prirciilcr
of
ovcr fifringw.
gcmatization as the numbciof
niCaon nodeein
thsnctwo[t
rmeimor*d
and6c
targct cmor wa$reducod
fir&er.
Thc
choicoof
mrmally
disEibutcd random numbersin
6G rEgG
[-t,
+lJ
f6r
tre
initial
values
of
weights aad bisscsin
fu
networt
greatlyspccded
6c
fidnhS
prooFss. T:hcrcnrls
stag&cn
ourbelief
in
thc
bcttcr
worting
of
tbs
adrytive
gainalgorithm"
Acknowledgement
Th alrful
wouHlitc
b
&8trk Univ€rgiti Tua HusscinOnn
lvlalayriafor
supeordngrhis
rcsearchuodcf &c
Short Tcrm Rcseuch Gr,ant
Reference$
fil
Pcrantonis S.J.
anO KarrasD. A.. An Efrictent
Constrsined
Learning
Algorithm x'ith
;l{ouentam
Acceleration.
Neural
Nenr-orks.
1995(8(2)):
p.237-249.
[2f
Kamarthi
S.
V.
and Pitner
S..
Accelerating
Nearal
l,,letyr'ork
Training usitrg
WeightExtrapolations.
Neural
Netrvorks.
1999. 12:
p.l 285- 1299.
[3] Moller
M.
F.,
A
Scaled
Conjugate Gradient
Algorithm
for
fast
Supervised
Learning.
Ncural
Networks,
1993.6(a): p.
525-533.[4J Lera G.
and PinzolasM., Neighborhood
basedLevenberg-
Marquardt Algorithm
fo,
Neural
Network Training. IEEE
Transaction
on
NeuralNetworks,
September2002.
l3(5): p.
1200-1203.[5]
Holgcr R.
M.
and GraemeC.
D.,
TheEffect
of
Internal
Parameters
aid
Geometry
on
thePerformance
of
Back-Propagation
Neural
Networks. Environmental Modeling and
Softwatre, 199E.r3(1):
p.
193-209.[6J Hollis
P.W.,
Haqpcr J. S., aud PaulosI.
1., TheEffects
of
Precision
Constraints
ln
a
PERFORMANCE IMPROVEMNT OF BACK.PROPAGATIOX NET'RAI NETWORK TEARNING AII]ORInilfiI.,.
.
[7] Ihimm
G.,
Moerlaqd
F.;
'nd
Fiesler
E.,
TheInterehangeabili|y
of
Learning Rate
an
Gain
in&ac@ropagation
.
Neural
Networks.
Nesnl
gomputation,
1996. SQ):p.
451.460.[8]
Looney
C.
G.,
Stabilization
and
Speedupof
'
Convergenc,ein
Training
Feed
Foiward
Nearal
N erwarks.
Neurocomputing;.fgg
6. .1 0(1) :p.
7 -3 | .[9]
EomK.,
JungK,,,and
Siriscna H.,.PerformantceImprouement
o.f
Bacfuropagation
olgorithm
byoutomatic aetivation.
function gain
taning
usingfu?zy
logic.
Neurocorhputing,
2003.
50:
p.
439-460.tl0l
Erik Hjclmas
and P.W.Munro, A
commbnt onparity problem.
TeohnicalReport,
1999:p.
l-7.
. tltJ
Maagasaria$
,O,
L.
asd
\Molberg
lV.
H.,
'Cancer diagnosis
vls
linear programming. SIAM
-,Is*r,
1990.23(5):
p.
l-18.
set
Fisher
R.A., The
use
of
.multiplefteasurements
in
taxonamie problems. Annals
of
Eugenics,
t936. 7:
p.
179-lSS,tt3lR-A.
Fisher,
fu:/lfu.ics.uii.edu/pubhnachine-fuaingdatobas as