Algorithms for inverse big data problems
Serge Gratton University of Toulouse
CERFACS-IRIT
Joint work with E. Bergou, S. Gurol, E. Simon, D. Titley-Peloquin, Ph.L. Toint, J. Tshimanga,L.N. Vicente, Z. Zhang
A dynamical system is characterized by state variables, e.g. velocity components pressure density temperature gravitational potential
Goal: predict the state of the system at a future time from
dynamical integration model observational data
Applications: climate, meteorology, oceanography, neutronics, finance, ...
A dynamical integration modelpredicts the state of the system given the state at an earlier time.
! integrating may lead to very largeprediction errors
! (inexact physics, discretization errors, approximated parameters)
Observational data are used to improve accuracy of the forecasts.
! but the data areinaccurate (measurement noise, under-sampling
! 107 observations (109 variables) processed every day: inverse big
A dynamical integration modelpredicts the state of the system given the state at an earlier time.
! integrating may lead to very largeprediction errors
! (inexact physics, discretization errors, approximated parameters)
Observational data are used to improve accuracy of the forecasts.
! but the data areinaccurate (measurement noise, under-sampling
! 107 observations (109 variables) processed every day: inverse big
A dynamical integration modelpredicts the state of the system given the state at an earlier time.
! integrating may lead to very largeprediction errors
! (inexact physics, discretization errors, approximated parameters)
Observational data are used to improve accuracy of the forecasts.
! but the data areinaccurate (measurement noise, under-sampling
! 107 observations (109 variables) processed every day: inverse big
data
−2 −1 0 1 −1
0 1
known situation 2 days ago and background prediction
record data for the past 2 days
minimize the di↵erence between the model and observations
−2 −1 0 1 −1
0 1
known situation 2 days ago and background prediction record data for the past 2 days
minimize the di↵erence between the model and observations
−2 −1 0 1
−1 0 1
known situation 2 days ago and background prediction record data for the past 2 days
minimize the di↵erence between the model and observations
−2 −1 0 1 −1
0 1
known situation 2 days ago and background prediction record data for the past 2 days
minimize the di↵erence between the model and observations
Notations and toy example Subspace and model reduction Weak contraints Conclusion
Modeling and toy example Dual iterative solvers
Using subspace ideas, subspace reduction
Ensemble methods with a stochastic dynamical system Variational methods with a stochastic dynamical system Summary, caveat and ongoing related work
Notations and toy example Subspace and model reduction Weak contraints Conclusion
Modeling and toy example
Dual iterative solvers
Using subspace ideas, subspace reduction
Ensemble methods with a stochastic dynamical system Variational methods with a stochastic dynamical system Summary, caveat and ongoing related work
A vibrating string
We consider a vibrating string, hold fixed at both ends
It is released with a zero initial speed, from an unknown position The string remains in the vertical plane
The string is observed with a set of physical devices measuring the position string at regularly spaced points during a given time span We would like to
make a forecast of the string position outside the observation time span
Observations1
0 x
u(x)
A vibrating string : the model
The string positionu(x) is the solution of the partial di↵erential equation 8 < : @2 @t2u(x,t) @ 2 @x2u(x,t) = 0 in ]0,1[⇥]0,T[ u(0,t) =u(1,t) = 0, t 2]0,T[ u(x,0) =u0(x),@@tu(x,0) = 0, x 2]0,1[
Under regularity assumptions on u0, this system has one unique
solution
We suppose that the system is observed at timetn,n 0
The problem reads minu0
PNobt
n=0 ku(:,tn) ynk2
This is an infinite dimensional linear least squares problem, that has to
The observations
We consider now that the string is observed regularly in time and
space. No noise,moreobservations than unkonwns
The discretized version of linear least-squares problem minu0
PNobt
n=0 ku(:,tn) ynk2 is solved with aconjugate gradient
technique
! test(’over’)
Realistic di
ffi
cult case
In practice, observing a 3D field at all space points is out of reach
! test(’under’)
The observations are noisy, which introduces high frequencies in the analysis
! test(’noisy’)
Both e↵ect (always) come together
Exploiting ”a priori” information
We do not consider the previous solution acceptable, because we doubt a string might take such positions. We expect the solution to be smooth enough
We would like to introduce the fact that the string position should
not vary too much when considering points that areclose in the
physical space
purely algebraic approach, e.g. minu0 PNobx j=0 1|u0j u0j+1|2+ PNobt n=0 ku(:,tn) ynk2s.t. discretized dynamics
using a pseudo-physical smoothing process
Smoothing in the discretized space with the heat equation
We consider the discretized heat equation
8 < : @ @tu(x,t) @ 2 @x2u(x,t) = 0 in ]0,1[⇥]0,T[ u(0,t) =u(1,t) = 0, t 2]0,T[ u(x,0) =u0(x), x 2]0,1[
For a given T,u(.,T) is smoother thanu0, because high frequency
Solve a large-scale non-linear weighted least-squares problem: min x2Rn 1 2kx xbk 2 B 1 + 1 2 N X j=0 Hj Mj(x) yj 2R 1 j where
x ⌘x(t0) is the control variable
Mj are model operators: x(tj) =Mj(x(t0))
Hj are observation operators: yj ⇡Hj(x(tj))
the obervations yj and the background xb are noisy
Back to the realistic di
ffi
cult case
Underdetermined case
! test(’under-reg’)
Noisy case
! test(’noisy-reg’)
Underdetermined and noisy case
Issues on background regularization
Background matrix mat-vec in CG : another di↵erential equationhas
to be solved
In case of modelling,when a direct solution not applicable, an
inner-outer iteration scheme has to be controlled
Determining a reasonable background matrix : based on physical
considerations, possibly onstatisticsover past assimilation periods
Introduction of balanced relations in the background : when variables
are related to each other by relations that are not accounted for in the model and not properly observed, an additional (weak) penalty term is added
min x2Rn 1 2kx xbk 2 B 1 + 1 2 N X j=0 Hj Mj(x) yj 2R 1 j Algorithmic considerations:
very largeproblem size: m⇠107 observations, n⇠108 unknowns
iterative methods for nonlinearproblems:
primal/dual formulations? [S. Gratton and J. Tshimanga (2009) ; S. Gratton, P. Toint, and J. Tshimanga, 2011.]
preconditioning? [S. Gratton, A. Sartenaer, J. Tshimanga, A.T. Weaver (2008) ; S. Gratton, P. Laloyaux, A. Sartenaer, and J. Tshimanga (2001) ]
using of subspace information? handle stochastic dynamical systems?
Notations and toy example
Subspace and model reduction Weak contraints Conclusion
Modeling and toy example
Dual iterative solvers
Using subspace ideas, subspace reduction
Ensemble methods with a stochastic dynamical system Variational methods with a stochastic dynamical system Summary, caveat and ongoing related work
Notations and toy example
Subspace and model reduction Weak contraints Conclusion
Solve a large-scale non-linear weighted least-squares problem:
min x2Rn 1 2kx xbk 2 B 1 + 1 2 N X j=0 Hj Mj(x) yj 2R 1 j
Typically solved using a truncated Gauss-Newton algorithm (known as 4D-Var in the DA community)
! linearize Hj Mj(x(k)+ x(k)) ⇡Hj Mj(x(k)) +Hj(k) x(k)
! solve the linearized subproblem
min x(k)2Rn 1 2k x (k) (x b x(k))k2B 1 + 1 2 H (k) x(k) d(k) 2 R 1 ! update x(k+1)=x(k)+ x(k)
Notations and toy example
Subspace and model reduction Weak contraints Conclusion
Defining the constraint as "=H x d we can write Lagrangian function
for the quadraticproblem as
L( x,", ) = 1 2kx+ x xbk 2 B 1+ 1 2k"k 2 R 1+ T(" H( x) +d)
From Karush-Kuhn-Tucker conditions, the following stationary conditions are satisfied at any optimum:
r xL( x,", ) =B 1(x+ x xb) HT = 0 r"L( x,", ) =R 1"+ = 0
r L( x,", ) =" H x +d = 0
Notations and toy example
Subspace and model reduction Weak contraints Conclusion
Exploiting the structure: Dual Approach
Theexact solution is either
xb xk+BHkT (HkBHkT+R) 1(dk Hk(xb xk))
| {z }
Lagrange mult. : requires solving a linear systemiterativelyinRm
or, from normal equations
xb xk+ (B 1+HkTR 1Hk) 1HkTR 1(dk Hk(xb xk))
| {z }
linear systemiterativelyinRn
Ifm<<n, then performing theminimization inRmcan both reduce memory and
computational cost
Nonlinear problem: we want to solve iteratively and truncate afterfew stepsin a
trust-region tuncated CG solver. Does it hurt to use this dual approach?
Notations and toy example
Subspace and model reduction Weak contraints Conclusion
Dual/Primal approach compared
Cost function: J( xk) = 12k xk xb+xkk2B 1+ 12kHk xk dkk2R 1
Blue primal - Red dual
the relation between primal and dual formula is lost when an iterative
solver is truncated prematurely
This is bad news for the nonlineariterations
Notations and toy example
Subspace and model reduction Weak contraints Conclusion
Preconditioned CG algorithm
For i = 0,1, ...
1 qi = (B 1+HTR 1H)pi
2 ↵i =<ri,zi > / <qi,pi > Compute the step-length
3 xi+1= xi+↵ipi Update the iterate
4 ri+1=ri ↵iqi Update the residual
5 zi+1= F ri+1 Update thepreconditioned residual
6 i =<ri+1,zi+1> / <ri,zi> Ensure A-conjugate directions
7 pi+1=zi+1+ ipi Update the descent direction
Notations and toy example
Subspace and model reduction Weak contraints Conclusion Initialization steps given v0;r0 = (HTR 1H + B 1)v0 b,. . . Loop: WHILE 1 HTbqi 1 = HT(R 1HB 1HT + Im)bpi 1 2 ↵i 1 = rT i 1zi 1/bqiT1bpi 1 3 BHTbvi = BHT(vi 1 + ↵i 1bpi 1) 4 HTbri = HT(ri 1 + ↵i 1qbi 1) 5 BHTbzi = FHTbri = BHTGbri FHT =BHTG 6 i = (rT i zi/riT1zi 1) 7 BHTbpi = BHT( bzi + ibpi 1)
Notations and toy example
Subspace and model reduction Weak contraints Conclusion Initialization 0= 0,br0=R 1(d H(xb x)), b z0=Gbr0,pb1=bz0,k= 1 Loop on k 1 bqi =Abbpi 2 ↵i=<bri 1,bzi 1>M/ <bqi,bpi >M 3 i = i 1+↵ibpi 4 bri =bri 1 ↵ibqi 5 i=<bri 1,bzi 1>M/ < bri 2,bzi 2>M 6 bzi=Gbri 7 bpi =bzi 1+ ibpi 1 b A=R 1HBHT+I m G is the preconditioner M is the inner-product RPCGAlgorithm: M=HBHT
preserves monotonic decrease on quadratic cost
Gshould be symmetric w.r.t. toM NeedBHTG=FHT
Notations and toy example
Subspace and model reduction Weak contraints Conclusion
Observations: SST (Sea Surface Temperature) and SSH(Sea Surface Height) observations from satellites. Sub-surface hydrographic observations from floats
Number of observations (m): 105
Number of state variables (n): 106for strong constraint and 107for weak constraint
Computation: 64 CPUs
Notations and toy example
Subspace and model reduction Weak contraints Conclusion
Let Fk be s.p.d.. Is the relationFkHkT =BHkTGk reasonable ?
Perfect preconditioner :
(B 1+HkTR 1Hk) 1HkT =BHkT(HkBHkT+R) 1
IfHkBHkT is nonsingular, andIm(FHkT)⇢Im(BHT), there is always
a unique Gk that corresponds to Fk. But don’t want to compute
Gk = (HkBHkT +R) 1FkHkT: too expensive
We focus on quasi-Newton Limited Memory Preconditioner [Morales
and Nocedal 2000] [Gratton, Sartenaer and Tshimanga 2011] that are widely
used in applications
[Gratton, Gurol and Toint 2012] derivethe quasi-Newton LMP in dual
space which generatesmathematically equivalent iterates to those of primal approach
Notations and toy example
Subspace and model reduction Weak contraints Conclusion
F
as a Quasi-Newton Limited Memory Preconditioner
Quasi-Newton LMPs are simply based on the idea that generatespreconditioners by using LBFGSupdating formula
Fk+1 = (In ⌧kpkqkT)Fk(In ⌧kqkpkT) +⌧kpkpkT ⌧k = 1/(qkTpk) qk = (B 1+HTR 1H)pk The pairs Fk defined by Fk =Fk+1 Fk, is min Fk W1/2 FkW1/2 F subject to Fk = FkT, Fk+1qk =pk
whereW is a positive definite matrix satisfying Wpk =qk. MatrixF
approximates the inverse of the system matrix: a preconditioner Serge G. Large-scale inverse problems
Notations and toy example
Subspace and model reduction Weak contraints Conclusion
G
as a Quasi-Newton Limited Memory Preconditioner
GivingF, we can find G that satisfies FHT =BHTG
G can be derived by using the formula for F using the relations
pi = BHTbpi,
qi = HTbqi
Gk+1 = (Im b⌧kbpk(Mbqk)T)Gk(Im ⌧bkbqkbpkTM) +b⌧kbpkbpkTM
M =HBHT
b
pk is the search direction
b
qk = (Im+R 1HBHT)bpk The dual pairs
b
⌧k = 1/(bqkTHBHTbpk)
Notations and toy example
Subspace and model reduction Weak contraints Conclusion
The quasi-Newton LMP in dual space (Nonlinear case)
In the nonlinear iterations, inheriting the previous preconditioner Gk 1
may not be possible because we need the existence ofFk, s.p.d,
satisfying FkHkT =BHkTGk 1
Theinherited matrixGk 1 may not satisfy HkFkHkT
=HkBHkTGk 1 for anyFk, s.p.d..
The method can be improved by using a safeguarding strategy, whose convergence relies on the Cauchy decrease and a trust-region
”magical” step
Notations and toy example
Subspace and model reduction Weak contraints Conclusion
Numerical experiment on heat equation (1/3)
The dynamical model is considered to be the nonlinear heat equation defined by x t 2x u2 2x v2 +f[x] = 0 in⌦⇥(0,1) x[u,v,t] = 0 on ⌦⇥(0,1)
where the temperature variable x[u,v,t] depend on both timet and
position given by spatial coordinates u and v. The functionf[x] is defined by
f[x] =exp[⌘x]
Notations and toy example
Subspace and model reduction Weak contraints Conclusion
Numerical experiment on heat equation (2/3)
f[x] =exp[⌘x] ⌘ = 2
Notations and toy example
Subspace and model reduction Weak contraints Conclusion
Numerical experiment on heat equation (3/3)
f[x] =exp[⌘x] ⌘= 4.2
Notations and toy example
Subspace and model reduction Weak contraints Conclusion
Modeling and toy example Dual iterative solvers
Using subspace ideas, subspace reduction
Ensemble methods with a stochastic dynamical system Variational methods with a stochastic dynamical system Summary, caveat and ongoing related work
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
Nemo, GYRE configuration
Sea level anomaly (top left), velocities (top right), temperature (bottom left) and salinity (bottom right)
North Atlantic circulation with its Gulf stream current.
The basin has 3180 km length, 2120 km width and 4, 5 km depth. State of length 90000
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
A subspace from physical considerations
Physical considerations:
The ocean and the atmosphere exhibit anattractor: a slowly varying
geometrical oject that contains the state
Most of the variability can be explained in the “attractor subspace”
(of low dimension r)
! Minimize first in this subspace (of basisL)
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
Empirical Orthogonal Functions (EOFs)
Construction of L:
Let x1, . . . ,xp2Rn be a set ofstate vectors
BuildC = p11Ppi=1(xi ¯x)(xi ¯x)T
Compute theeigenvectors of C (EOFs)
Storer eigenvectorscorresponding to thelargest eigenvalues
! Already used in the reduced Kalman filters(SEEK filter)
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
Choice for
r
Selectr such that: Pr i=1 i Pn i=1 i 0.9 ( i &)
!Ther= 100 yields more than 90%
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
Using the subspace
[Gratton, Laloyau, Sartenaer, Tshimanga 2011]The solution of the first system in the subspace spanned byLcan be
obtained with a Ritz-Galerkin formula:
x00=xb+L(LTA0L) 1LTb0
It is also possible to approximate the inverse Hessian with aLimited
Memory Preconditioner H =hIn L(LTA0L) 1LTA0 i h In A0L(LTA0L) 1LT i + L(LTA0L) 1LT
We also experimented the use of asmoother (↵t based) on the
vectors in L
Possible to keepA0L from past iteration orrecompute (linearization)
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
Subspace solution
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
Subspace solution with linearization
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
Using the subspace
[Gratton, Laloyau, Sartenaer 2014]The Ritz-Galerkin starting point corresponds to solving the quadratic
minimisation probleminside the subspace Im(L)
Since this subspace it typically of dimension less then 1000, using derivative free optimization techniques is conceivable, even on the
nonlinear function
Possible scheme, by processing vectors by e.g. batches of 10 members
fork= 1, ..
1 Build a new subspaceLk
2 Minimize function in affine spacexk+ImLk to getxk+LkwK
SID-PSM[Custodio, Vicente 2007], see also [Vaz, Vicente 2009])
3 Setxk+1=xk+LkwKr
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
Subspace solution
A criterion⇡i to promote subspace vectorsli for whichlarge variationof the cost function
occurs (singular value i) is used:
⇡i=⌧i+ ·
maxj⌧j
maxj j i
,where⌧i =kh(x0) h(x0+li)kR 1
Vectorsli can besmoothed
See[Gratton, Vicente, Zhang 2014]for extension to full domain decomposition and stochastic methods. Also see[Gratton, Royer, Vicente, Zhang 2014]for a complexity analysis ofstochastic direct searchand[Diouane, Gratton, Vicente 2014]for similar algorithms in globally convergent evolution algorithms
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
Modeling and toy example Dual iterative solvers
Using subspace ideas, subspace reduction
Ensemble methods with a stochastic dynamical system
Variational methods with a stochastic dynamical system Summary, caveat and ongoing related work
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
Weak-constraint 4D-Var
min x2Rn 1 2kx0 xbk 2 B 1+ 1 2 N X j=0 Hj xj yj 2R 1 j +1 2 N X j=1 kxj Mj(xj 1) | {z } qj k2 Qj 1 x = 0 B B B @ x0 x1 .. . xN 1 C C C A2Rnis the control variable (withx
j =x(tj))
xb is the background given at the initial time (t0).
yj 2Rmj is the observation vector over a given time interval
Hj maps the state vector xj from model space to observation space
Mj represents an integration of the numerical model from timetj 1 totj B,Rj andQj are the covariance matrices of background, observation and
model error.
We have a large-scale weighted nonlinear least-squares problem. Serge G. Large-scale inverse problems
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
A data assimilation approach
The objective function to be minimized
1 2kx0 xbk 2 B 1+ 1 2 k X i=1 xi Mi xi 1 2Q 1 i +1 2 k X i=1 kdi Hi(xi)k2R 1 i .
The corresponding LMM linearized least-squares is
1 2kx0+ x0 xbk 2 B 1+ 1 2 k X i=1 xi mi Mi xi 1 2Q 1 i +1 2 k X i=1 kyi Hi xik2R 1 i + 2 k X i=0 kxik2, whereyi=di Hi(xi), Hi=H0i(xi), mi=Mi xi 1 xi,Mi=M0i xi 1 .
The penalty termcan be considered asfurther observations.
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
Kalman Filter
Kalman filter (KF) Initialization Prediction step xi|i 1 =Mi xi 1|i 1+mi, Correction step xi|i = xi|i 1 Pi|i 1H>i (HiPi|i 1H>i +Ri) 1(Hi xi|i 1 yi), wherePi|i 1=MiPi 1|i 1M>i +Qi.Pi|i 1 is expensive to compute and store) ensemble Kalman filter.
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
Ensemble
Kalman filter
Ensemble Kalman filter
Initialization Prediction step xn i|i 1 =Mi xin 1|i 1+mi+Vin, Vin⇠N(0,Qi), n = 1, . . . ,N, Correction step xin|i = xin|i 1 PNi|i 1H>i (HiPNi|i 1H>i +Ri) 1(Hi xin|i 1 Win yi), Win⇠N(0,Ri), n = 1, . . . ,N, PNi|i 1=N11PNn=1⇣ xn i|i 1 N1 PN n=1 xin|i 1 ⌘ ⇣ xn i|i 1 N1 PN n=1 xin|i 1 ⌘> . Serge G. Large-scale inverse problems
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
Derivative-free implementation of the EnKS
Mi =M0i(xi 1)occurs only in advancing the time as action on an ensemble member Mi xin|i 1⇡ Mi ⇣ xi 1+⌧ xin|i 1 ⌘ Mi(xi 1) ⌧ .
Hi =H0i(xi)occurs only in the action on an ensemble member
Hi xi|in ⇡ Hi ⇣ xi +⌧ xin|i ⌘ Hi(xi) ⌧ .
The algorithm has to be transformed to get the least-squares solution:
ensemble smoother
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
Globalization of LMM-EnKS
Initialization: choose ⌘12(0,1), ⌘22(0,1), min >0, max >0, >1,x0
and 02[ min, max]. Forj = 0,1,2, . . .
1 Approximatethe solution of the linearized LMM subproblem byEnKS. 2 Add the regularization term as further observations.
3 Compute⇢= f(x
j) f(xj+ xj)
mj(xj) mj(xj+xj), where x
j is the EnKS mean.
If⇢ ⌘1, then setxj+1 =xj+ xj and
j+1= 8 > < > : j if kgmjk<⌘2/ j, max ( j 1 pj pj , min ) if kgmjk ⌘2/ j.
Otherwise, the step is rejected and j+1 = j.
[E. Bergou and L.N. Vicente]
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
Experiments set-up
Dynamical model = Lorenz 63 model dx dt = (x y) dy dt = ⇢x y xz dz dt = xy z Simplified mathematical
model foratmospheric
convection [Lorenz 63]. Model describing idealized thermal convection in the Earth’s atmosphere. The system if fully observed at each time stepdt = 0.11.
k = 40,N = 400.
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
Numerical experiments
Objective function values Root mean square error
[E. Bergou, S. Gratton, L.N. Vicente, submitted to SIAM/JUQ]
Notations and toy example
Subspace and model reduction
Weak contraints Conclusion
Gradient based approach DFO
Modeling and toy example Dual iterative solvers
Using subspace ideas, subspace reduction
Ensemble methods with a stochastic dynamical system
Variational methods with a stochastic dynamical system
Summary, caveat and ongoing related work
Variational approach: the linearized subproblem (Inner
loop)
The linearized problem at thek-th outer loop is given by
min x 1 2kx0 b (k) k2B 1+ 1 2 N X j=0 H(jk) xj d(jk) 2 Rj 1+ 1 2 N X j=1 kxj Mj(k) xj 1 | {z } qj k2Q 1 j x= 0 B B B B @ x0 x1 . . . xN 1 C C C C A2R nis the increment.
The vectorsb(k),cj(k)anddj(k)are defined by
b(k)=xb x0(k) dj(k)=yj Hj(xj(k))
Rewriting the linearized subproblem
min x2Rn 1 2kL x bk 2 D 1+ 1 2kH x dk 2 R 1 where L= 0 B B B B B @ I M1 I M2 I . .. . .. MN I 1 C C C C C A d= 0 B B B @ d0 d1 .. . dN 1 C C C A andb= 0 B B B @ b c1 .. . cN 1 C C C A H=diag(H0,H1, . . . ,HN)Rewriting the linearized subproblem
min x2Rn 1 2kL x bk 2 D 1+ 1 2kH x dk 2 R 1 L x = 0 B B B B B @ I M1 I M2 I . .. . .. MN I 1 C C C C C A 0 B B B B B @ x0 x1 x2 .. . xN 1 C C C C C A = 0 B B B B B @ x0 x1 M1 x0 x2 M2 x1 .. . xN MN xN 1 1 C C C C C ARewriting the linearized subproblem
Making change of variables
p =L x
the subproblem can also be rewritten as min p2Rn 1 2k p bk 2 D 1+ 1 2kHL 1 p dk2 R 1 x =L 1 p issequential ! x j =Mj xj 1+ qj
The linearized subproblems
State Formulation min x 1 2kL x bk 2 D 1+ 1 2kH x dk 2 R 1 Forcing Formulation min p 1 2k p bk 2 D 1+ 1 2kHL 1 p dk2 R 1Matrix-vector products withL
can be parallelizedin the time
dimension.
Solution algorithm:
Preconditioned Lanczos or PCG type methods.
Preconditioningis difficultsince
D1/2eL T(LTD 1L)eL 1D1/2
can be ill-conditioned depending on the accuracy ofeL 1.
Matrix-vector products withL 1
issequential.
Solution algorithm:
Preconditioned Lanczos or PCG type methods.
PreconditioningbyD often
e↵ective. The structure ofD is tri-diagonal by blocks!
Saddle Point Approach
In matrix form: 0 @D0 R0 HL LT HT 0 1 A | {z } A 0 @µ x 1 A= 0 @bd 0 1 AwhereA is a (2n+m)-by-(2n+m) indefinite symmetricmatrix.
The solution of this problem is a saddle point
! This approach istime-parallel.
Preconditioning Saddle Point Formulation of 4D-Var
A= 0 @D0 R0 HL LT HT 0 1 A= ✓ A BT B 0 ◆B is the most computationally expensive block and calculations
involving Aare relatively cheap.
Theinexact constraint preconditioner proposed by (Bergamaschi et. al. 2005) is promising for our application. The preconditioner can be chosen as: P = Ae BeT B 0 ! = 0 @D 0 eL 0 R 0 e LT 0 0 1 A, where e
Lis an approximation to the matrixL
e
B= [eLT 0] is a full row rank approximation of the matrix B2Rn⇥(m+n)
Notations and toy example Subspace and model reduction
Weak contraints
Conclusion
Numerical Results
Implementation platform
We used the Object Oriented Prediction System (OOPS) OOPS consists of simplified models of a real-system The model
It is a two-layer quasi-geostraphic model with 1600 grid-points Implementation details
There are 100 observations of stream function every 3 hours, 100 wind observations plus 100 wind-speed observations every 6 hours The error covariance matrices are assumed to be horizontally isotropic and homogeneous, with Gaussian spatial structure
The analysis window is 24 hours, and is divided into 8 subwindows 3 outer loops with 10 inner loops each are performed
Notations and toy example Subspace and model reduction
Weak contraints
Conclusion
Numerical Results
Methods1 Forcing formulation withD preconditioning
!Solution method is preconditioned conjugate-gradients
2 Saddle point formulation with an updated inexact constraint preconditioner !Solution method is GMRES
!The initial preconditioner is chosen as
P0= 0 @D 0 e L 0 R 0 e LT 0 0 1 A with eL= 0 B B B @ I I I . .. ... I I 1 C C C A. P01= 0 @ 0 0 e L T 0 R 1 0 e L 1 0 eL 1DeL T 1 A and eL 1= 0 B B B @ I I I .. . . .. ... I · · · I I 1 C C C A.
!The low-rank low-cost preconditioner is denoted asCk !The low-rank least-Frobenius preconditioner is denoted asFk
Notations and toy example Subspace and model reduction
Weak contraints
Conclusion
Numerical Results with OOPS qg-model
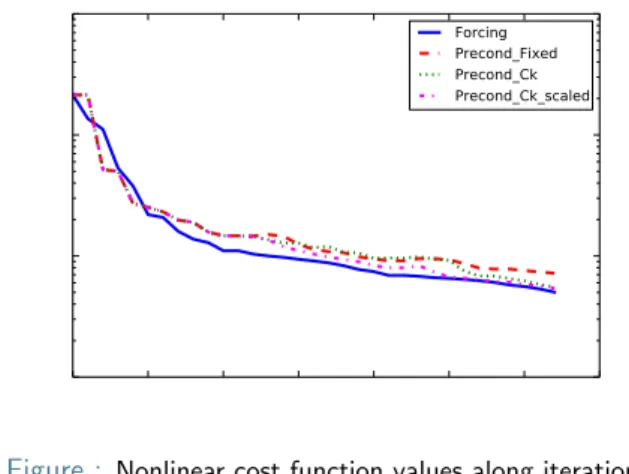
Figure : Nonlinear cost function values along iterations
!Last 8 pairs were used to construct the preconditioner ! B=↵vwT(where v=r
Notations and toy example Subspace and model reduction
Weak contraints
Conclusion
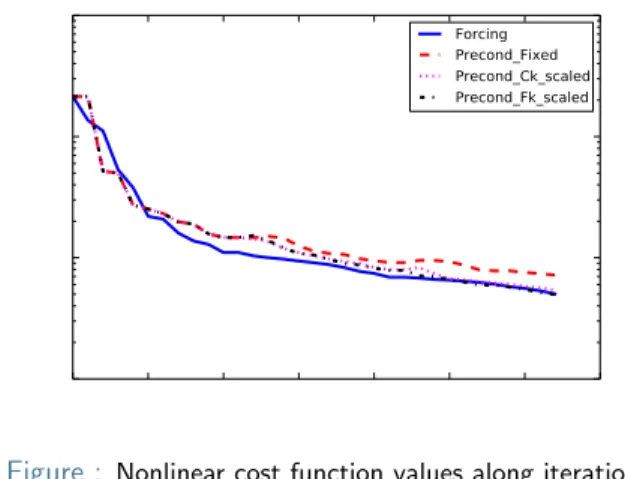
Numerical Results with OOPS qg-model
Figure : Nonlinear cost function values along iterations
!Last 8 pairs were used to construct the preconditioner Serge G. Large-scale inverse problems
Notations and toy example Subspace and model reduction
Weak contraints
Conclusion
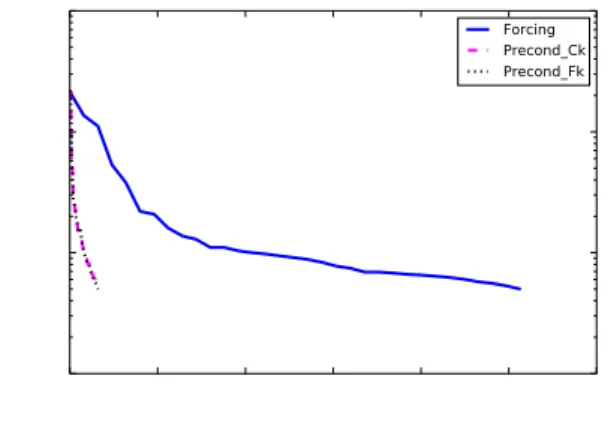
Numerical Results with OOPS qg-model
Figure : Nonlinear cost function values along sequential subwindow integrations
!At each iteration theforcing formulationrequires one application ofL 1, followed by one application ofL T(16 sequential subwindow integrations)
!At each iteration ofsaddle point formulationrequireone subwindow integration (provided thatL 1andL T are applied simultaneously)
Notations and toy example Subspace and model reduction
Weak contraints
Conclusion
Modeling and toy example Dual iterative solvers
Using subspace ideas, subspace reduction
Ensemble methods with a stochastic dynamical system Variational methods with a stochastic dynamical system
Summary, caveat and ongoing related work
Notations and toy example Subspace and model reduction Weak contraints
Conclusion
Conclusions
Very large scale higly-nonlinear forecasting problems can be solved
using dual methods, projection methods, satistical sampling,adapted
to nonlinearity
In some severe cases, having ”more” than a local minimum might be
needed. Model reductionand exploration techniques are useful
Most systems are a priori designed for solving the prediction problem. Using DA techniques to other settings not necessarily successful.
Further work. Errors between time-steps correlated. Having a parallel
codeis a challenge. Use nonlinear multigrid, domain decomposition
ideas forscalability.