Turbo Decoding and Detection for Wireless Applications
Full text
Figure
![Fig. 1. Turbo encoder schematic, Berrou et al. [4], [5].](https://thumb-us.123doks.com/thumbv2/123dok_us/8492846.345093/2.576.62.521.201.352/fig-turbo-encoder-schematic-berrou-et.webp)
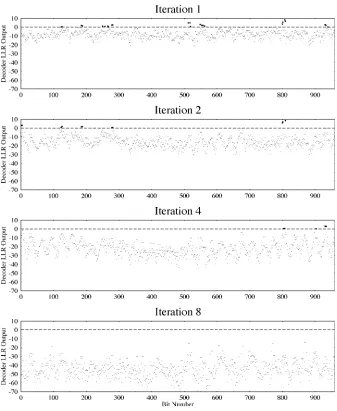


![Fig. 10. Effect of frame length on BER performance of turbo coding. All interleavers except L ¼ 169 block interleaver use random separatedinterleavers [42]](https://thumb-us.123doks.com/thumbv2/123dok_us/8492846.345093/14.576.138.440.78.310/effect-length-performance-coding-interleavers-interleaver-random-separatedinterleavers.webp)
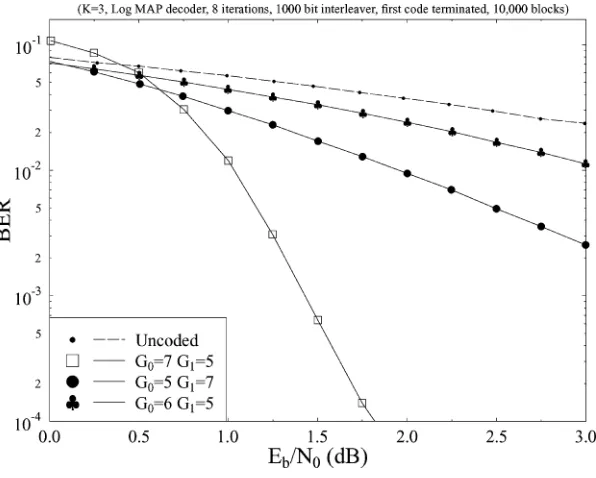

Related documents
On the other hand, the spatial distribution of motor unit action potentials has recently been assessed with activation maps obtained from High Density EMG signals (HD-EMG), these
Unlike conventional name and address matching, data quality, or CDI (customer data integration) technologies, which can be used to identify that Mr. Kumar is the same as Arvind
AN INTEGRATED ENVIRONMENT FOR LEXICAL ANALYSES O Introduction This article describes a project whose aim is to specify tools to be integrated in an e n v i r o n m e n t for
Because we have business process logics represented as DTs, data model in ER and data values filled into the database it is possible the generation of information system (IS)
Hasil penelitian menunjukkan bahwa implementasi revitalisasi permukiman kumuh di Kota Makassar telah sesuai dengan zonasi yang ada dalam Perda RTRW Kota Makassar, NUSSP
Since all VNFs including Layer 2 MAC are only attached to NoC (network-attached functions) they are clearly decoupled from the high speed I/Os. This allows for a highly
Analysis of the DNA from postautogamous rescued cell lines showed that wild-type macronuclear chro- mosomes containing the A serotype gene were pres- ent, rather
Implementation of the face detection algorithm using various models demon- strates that applications with non-uniform message processing time require an exe- cution strategy
