0022-538X/81/080519-10$02.00/0
Nucleotide
Sequences
of the
mRNA's Encoding the Vesicular
Stomatitis Virus G and M Proteins Determined from cDNA
Clones
Containing the Complete Coding Regions
JOHN K. ROSE* AND CAROLJ. GALLIONE
Tumor VirologyLaboratory, The Salk Institute, San Diego, California 92138
Received 24 March 1981/Accepted 20 April 1981
The complete nucleotide sequences of the vesicular stomatitis virus mRNA's
encodingtheglycoprotein(G) and the matrixprotein (M) have been determined
from cDNA clonesthat contain the complete coding sequences from eachmRNA. The Gprotein mRNA is 1,665 nucleotides long,excluding polyadenylic acid, and
encodesaprotein of511amino acids including a signal peptide of 16 amino acids.
G protein containstwolarge hydrophobic domains, one in the signal peptide and
the other in thetransmembrane segment near the COOH terminus. Two sites of
glycosylation arepredicted at amino acid residues 178 and 335. The close
corre-spondence of the positionsof these sites with the reported timing of the addition
of the two oligosaccharides during synthesis of G suggests that glycosylation occurs as soon as theappropriate asparagine residues traverse the membrane of
therough endoplasmic reticulum. The mRNAencoding the vesicular stomatitis
virus M protein is831 nucleotideslong, excludingpolyadenylicacid, andencodes aprotein of229aminoacids. Thepredicted Mprotein sequence does not contain any long hydrophobic or nonpolar domains that might promote membrane
association.Theprotein is rich in basic aminoacids and contains a highly basic
amino terminal domain. Details of construction of the nearly
full-length
cDNAclonesare presented.
Vesicular stomatitis virus (VSV) buds from thesurface of the host cellandthereby acquires
amembrane that contains spikes composed of the
single
viralglycoprotein (G).
Ourprevious studies have shown thatG protein hasa COOH-terminal basic domain of29amino acids which isinternaltothelipid
bilayer of the virion andan
adjacent hydrophobic
segment of20 amino acids which spans thebilayer (27).
TheNH2-terminal 95% of G isexternaltothe
lipid bilayer
and containstwo
asparagine-linked
complex
ol-igosaccharides (10, 21). Gplays
anessential rolein
binding
of the virus to the host cell and presumably playsarolein directingbudding of virusfrom theplasma membrane of the host cell(2,5).
The Gprotein is synthesized on membrane-bound
polyribosomes (18)
and inserted into therough endoplasmicreticulumas a nascent pro-tein chain (29, 34).A short
hydrophobic signal
sequence of16 amino acids is cleavedfrom
theNH2 terminus after insertion into the
rough
endoplasmicreticulum (12, 15,
22).
Gassumes a transmembrane configurationin therough
en-doplasmic reticulum (6, 13) with
only
a smallCOOH-terminal segment
exposed
on thecyto-plasmic face ofthe
rough
endoplasmic
reticu-lum. Transport of Gto the plasma membrane
occursviathe
Golgi
apparatus(la), with inter-organelle transportprobably
occuring
via coated vesicles(28).
Atalatestageoftransport totheplasma
membrane,
one or twomolecules offatty
acidareesterified
toG(31).
TheVSV matrix
protein (M)
isthought
tobea peripheral membrane
protein
that lines the inner surface of the virionenvelope, perhaps
interacting with the
lipid
bilayer,
the internal portion ofG,
and thenucleocapsid
core(re-viewed
by Wagner [35]).
Inadditionto astruc-tural
function,
Mplays
aroleindirecting
bud-ding ofvirusfrom infected cells(14)
andmaybe involved inregulating
transcription
of mRNA from thesingle
negative
strandofgenomic
RNA(4, 7, 9,16).
In contrast to
G,
M issynthesized
on free polyribosomes(18)
andassociatesrapidly
withthe plasma membrane fraction after
synthesis
(14).Thenatureoftheassociation ofMwiththe
plasmamembranefractionisnotclear.Itcould
beby associationwith the
lipid
bilayer
inregions
containing
Gprotein
orby
association withother-proteins such as those in
nucleocapsids
whichare
already
associated with theplasma
mem-brane
(14).
519
on November 10, 2019 by guest
http://jvi.asm.org/
520
Knowledge of the complete primary amino acid sequences of G and M proteinsis clearly critical to a molecular understanding of their interactions with membranes and other cellular and viralcomponents.Ourpreviousstudieshave employed VSV cDNA clones that containonly fractions of the coding sequences from each
mRNA (24, 27), and only terminalmRNA and proteinsequences werereported. Wereporthere the isolation and the complete nucleotide se-quencesof cDNA clones that containtheentire
codingsequences ofG andM protein mRNA's.
From thesesequenceswepredicttheamino acid sequences of the G and M proteinsanddiscuss features of these predictedsequences.
MATERIALS AND METHODS
Materials. Reverse transcriptasewassupplied by
J.Beard,St.Petersburg,Fla.The Klenowfragmentof DNApolymeraseIandmostrestrictionendonucleases
were purchased from NewEngland Biolabs, Beverly,
Mass. NucleaseS1, PstI,and T4polynucleotidekinase
were fromBoehringer Mannheim, Indianapolis,
Indi-ana, and terminal deoxynucleotidyl transferase was
fromBethesdaResearchLaboratories, Bethesda,Md. Oligo(dT)12-18andoligo(dT)cellulose (T3)werefrom CollaborativeResearch, Waltham,Mass.[a-32P]dCTP and dGTPwerefromAmersham/Searle, Chicago, Ill.,
and unlabeled dNTP'swerefromP-LBiochemicals, Milwaukee,Wis.
RNAsynthesis. VSV mRNAwassynthesized in
vitro ina 10-mlreaction exactly asdescribed
previ-ously (26), with thefollowingmodification.After 4h
the reactionwasstopped byaddition ofsodium dode-cyl sulfateand sodiumacetate tofinalconcentrations of 1% and 0.5M, respectively.The entiremixturewas
then passed through a column containing 0.5 g of
oligo(dT)-cellulose,and thecolumnwaswashed with
10ml of 0.4 Msodiumacetate.The boundmRNAwas
eluted with distilled water and precipitated with ethanol. AllmRNAwasfrom the SanJuan strain of
the IndianaserotypeofVSV.
First-strand DNA synthesis and purification. First-strand DNAcopiesof themRNA'sencodingthe N, NS, M,and Gproteinsweresynthesized ina4-ml
reaction containing300,ug of totalVSV mRNA, 0.5
mM dATP, dGTP, and dTTP, 0.25 mM [a-32P]-dCTP (10 Ci/mmol),30mM /3-mercaptoethanol, 120
mMKCl,10mMMgCl2,4,000U ofreverse
transcrip-tase,300jigofoligo(dT)12 8andacytoplasmicextract
(1 mg of total protein) from baby hamster kidney
(BHK-21) cells prepared as described below. After
incubation for 30min at42°C, the reaction mixture
was extracted with phenol. Unincorporated dNTP's
wereseparated from cDNA by chromatographyof the
aqueousphaseonSephadexG-50.Theexcluded
frac-tionwaslyophilizedinasilicatedglass tube. The yield
oftotal cDNAfrom 300 ,ugof VSV mRNAwas
ap-proximately 40,ugasdeterminedfrom the
incorpora-tion of[a-32P]dCTP. The full-lengthcDNA copiesof
eachmRNAspecieswerepurified by electrophoresis ona1.5%alkaline agarosegel (30 mM NaOH,5mM
EDTA;1.5 mmby18 cmby 20 cm). The cDNA's were located byautoradiography (Fig. 1) or by staining with ethidium bromide and UVillumination. Stained bands wereexcisedfrom the gel,electroeluted, and precipi-tated with ethanol. The yield offull-length cDNA's wasapproximately 0.7
jig
ofG,2,ugof N, and 3ytgof both NS and M. Reaction conditionsgiven were opti-mized with respect to the concentrations of reverse transcriptase, KCl, and cell extracts to give maximal sizes of cDNA's.Cell extract preparation. BHK cells (8 x 108 cells) growing in a 1-liter suspension werepelleted by centrifugation and suspended in 1.5 times the packed cell volume of 10 mM HEPES (N-2-hydroxyethylpi-perazine-N'-2-ethanesulfonic acid) (pH 7.5), 10 mM KCl, 1.5 mM magnesium acetate, and 7 mM
fl-mer-captoethanol. Cells were broken by 50 strokes of a Dounce homogenizer and centrifuged at 15,000 x g for 20min.The supernatant was dialyzed for 16 h against 1 liter of 10 mM HEPES (pH 7.5), 90 mM KCl, 1.5 mMmagnesium acetate, and 7 mM ,B-mercaptoetha-nol.The total protein concentration in the extract was 15 to20 mg/ml.All steps were carried out at 4°C, and samples of the extract were stored at -80°C.
Second-strand cDNA synthesis. Reactions for second-strand DNA synthesis (200
pl)
included 100 mM HEPES buffer (pH 6.9), 10mMMgCl2, 60 mM KCl,1mMdATP, dCTP, dGTP, and dTTP, 0.5jig
of apurified cDNA, and 5 U of the Klenow fragment of DNApolymerase I. Reactions were for 15 h at 15°C and were terminatedby extraction with phenol fol-lowed by precipitation with ethanol. Samples were thenresuspended in75pl ofasolution containing3 mM ZnCl2,30mM sodiumacetate(pH.4.5),300 mM NaCl, and 75U ofS1 nuclease. Digestionwasfor 30 min at 370C. S1-treated DNAswere extracted with phenol andprecipitatedwithethanol and thenpurified byelectrophoresis on a 6% polyacrylamide gel.The nearly full-length double-stranded DNAs were de-tectedbyautoradiographyorstainingwith ethidium bromide. Theamountsof double-stranded DNAsre-covered were 100 ng (G size class), 180 ng (N size class), and450ng(NSand M sizeclass),ascalculated from the cpm of32p in the first-strand DNA. Double-stranded DNAs were electroeluted and precipitated withethanol.
Homopolymer addition andcloning. Homopol-ymer addition wasbya modification ofapublished procedure(30). Addition of dCMP residuesto double-stranded cDNAwasfor10to30minat370C ina
25-pl
reactioncontaining100 to 500ngofDNA,0.2mM dCTP, and an amountof terminaldeoxynucleotidyl transferase (Tdt) that was known to add approxi-mately 10 to 20dC residues to HaeIIIfragments (5 pmol of total ends) of pBR322DNA.Thenumberof dC residues added wascalculated from the incorpo-ration of [a-32P]dCTP (100 Ci/mmol) that was in-cludedin testreactions. Unitsreported bythesupplier were generally 10- to 50-fold greater than whatweobserved. Addition of 10 to 20dG residues to PstI-cleaved pBR322 DNAwascarried out asabove (0.2 mMdGTP) using 1to 2,ugofDNA.The linearform ofPstI-cleavedpBR322wasalways purified by agarose gel electrophoresis and electroelution before tailing.
on November 10, 2019 by guest
http://jvi.asm.org/
Equimolarquantities of dC-tailed insert DNA and dG-tailed plasmid DNA were annealed for 15 min at4°C in 10
p1
of0.5MNaCI-10mMTris (pH 7.4) and used totransform Escherichia coli strain C600 to tetracy-cline resistance (30). From 10 to 40 colonies were obtained per ng of insert DNA. Approximately 80% of the colonies obtained were ampicillin sensitive and had inserts at the PstI site. Small preparations of plasmid DNA (1 to2 ug) were analyzed for the size of theinsert DNA by PstI digestion. HaeIII and Hinfl digestions gave partialrestriction maps for each insert. Bycomparing these maps with previous data (24, 25, 27) we were able to assign the clonesunambiguously tothe appropriate mRNA's. Although apparently full-lengthdouble-stranded DNAs were used as starting material, alarge fraction (80% for G) of the inserts had deletions at one or both ends.DNA sequence analysis. All sequence analysis was by the Maxam-Gilbert procedure as described previously (17, 25). DNAfragments (25 to 50 pmol) wereprepared by restriction enzyme digestion, alka-linephosphatase treatment, polyacrylamide gel elec-trophoresis,andelectroelution (25). End labeling was with 500,uCi of[y-32P]ATPand2Uof polynucleotide kinase (24).Labeled DNA strands were separated by electrophoresis onthin 5%polyacrylamide gels (0.35 mmby 16 cm by40cm) rather than the thickergels suggestedby Maxam and Gilbert (17). Thin gels gave betterresolution ofclosely spaced DNA strands. Gels were runat1,200 V with anelectric fan forcooling, and strand separation of fragments up to 800 base pairslongwasaccomplishedbyusing electrophoresis times of less than 8 h. Occasionally fragments for sequencing were obtained by cleavage with a second restriction enzyme followed by gel electrophoresis. Sequencinggels (0.35mmby16 cmby40,85,or152 cm) were electrophoresed at 1,500 to6,000 V, such that thegelremained warm(>40°C) throughout the run. Reaction times were reduced substantially for samples on which the sequence was to be readfor morethan300nucleotides from the labeled end. Gen-erally100,000to500,000dpmof32P-labeledfragment wereloaded per laneon152-cmgelssothatexposure could be carriedout at highresolution without flu-orescentscreens.Long (85or152cm)gelswerecutin sections, transferred to old exposedsheets ofX-ray filmfor backing, covered with plastic wrap, and ex-posedtoKodak XR-5 film for1to 4days.
RESULTS
The basic strategy we employed to obtain
nearly
full-length cDNAclones was: (i) to opti-mize reverse transcription offull-length
first-strand DNAcopies
of eachmRNA;
(ii)
to useisolated, full-lengthfirst strandsastemplates for
second-strandDNAsynthesis;and(iii)topurify
the nearly full-length double-stranded DNAs
(obtained after Si nuclease treatment) by
gel
electrophoresis
before cloning. All cloning was ofdC-tailedinserts into thedG-tailed PstIsite ofpBR322 (3).Inprevious experimentsweand othersfound thatadditionofa crude cellextract
greatly
en-hanced the synthesis of full-length VSV
mRNA's by theVSV viriontranscriptase(1, 26).
Becauseourinitialreversetranscription experi-ments showed that the yields of full-length cDNA's of VSV G and N mRNA's were low
relative tothe yieldsof cDNA's of the smaller
mRNA's(NS andM), weexaminedthe effect of
suchanextractonreversetranscription. Figure
1showstheproducts of reversetranscriptionof
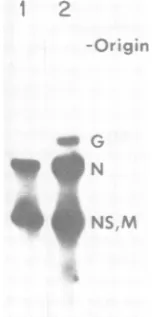
total VSV mRNA synthesized in the absence andpresence ofthe extract. The yields of full-lengthG and NcDNA's were increased 5- and
2-fold, respectively, whereas the M and NS
cDNA's were increased only marginally
(1.2-fold). Becauseof the dramatic enhancementof
the yield of large cDNA, the cell extract was
included in all syntheses of single-stranded cDNA's for cloning. The mechanism of action of thecellextractisnotknown,but it presumably
acts by inhibiting RNase or bypromoting
un-folding of mRNA secondarystructure.
G and M cDNA clones contain the
com-plete coding sequences. Two recombinant plasmids,
pG1
andpM309,wereobtained which had insert sizes ofca.1,700and850nucleotides, respectively, consistent with theirhavingnearly complete copies of the G and M mRNA se-quences. Todeterminethe exact 5'endpoints of each clonedsequencerelativetothemRNA,
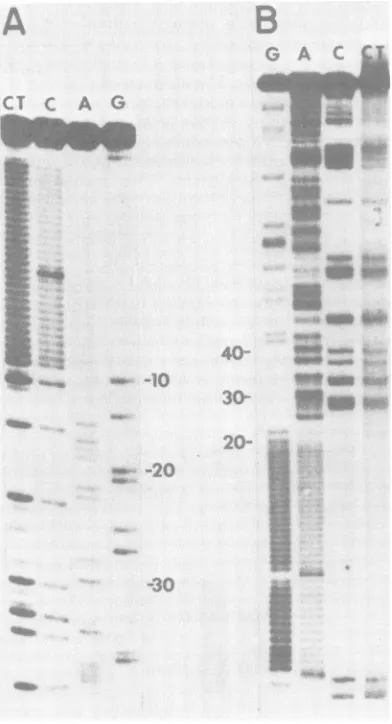
wedetermined the nucleotidesequenceatthe end of the insertcorrespondingtothe 5' endof the RNA. The
sequencing
gel showing this region from thepGl
insert is shown in Fig. 2. The sequence preceding thehomopolymer
tails is12
-Origin
4PG
N
NS,M
FIG. 1. ReversetranscriptsofVSVmRNA
synthe-sized inthe presence(lane 2)orabsence(lane 1)
of
acytoplasmiccellextract.Reversetranscriptswere la-beled with[a-32P]dCTPand
analyzed
byelectropho-resis on an alkaline agarose gel. Identities
of
the cDNAbandsin theautoradiogramareindicated.on November 10, 2019 by guest
http://jvi.asm.org/
[image:3.503.319.395.431.590.2]522
complementarytoallbutninenucleotidesatthe
5'end of theGmRNA sequence (24).Similarly,
the sequenceof the pM309 insert(Fig. 2) showed that it containedall but19nucleotides from the
5' M mRNA sequence (24). Because the
trans-lation initiation codons for theG andMmRNA's
are located 30 and 42 nucleotides from the 5' ends ofthe mRNA's(23, 24), these clonesclearly contain thesequencesencoding the NH2 termini ofG andMproteins.Subsequentsequence anal-ysisshowed that these clones contained the 3'-terminal mRNAsequences aswell.
FIG. 2. Sequencinggelsshowing thesequencesin
theregions ofpGlandpM309thatcorrespondtothe
5'-proximal regionsof Gand M mRNA's.Panels: A,
sequencefrom the5'-proximalAluIsite of thepGl
insert through the C-tails. Panel B, sequencefrom
the pBR322 HpaII site proximal to the 5' end of
pM309 readingintothe insert DNA. Numbers indi-catethealignmentof thesequenceswith the mRNA
sequence(see Fig.4and6).
The mechanism of formation of pGl and
pM309 can be explained from the 5'-terminal
sequencesof the mRNAs(Fig.4and6of
refer-ence 24). The priming of second-strand DNA synthesisinpG1 presumably occurred from the
3' end ofthe cDNA looped back to base pair perfectly with positions 13 through 18, leaving
anunpaired loop of six nucleotides. After second
strandsynthesis,digestion of the
loop
withnu-clease S1 must have left the unpaired
nucleo-tides 10through 12 intact because they appear
in theclone. Inthe formation ofpM309, the 3' end of the cDNA
presumably
looped back topair with positions 21
through
24 and began priming. Nuclease S1digestionwascompleteornearly complete, generating aclone lacking 19
nucleotides of the 5' mRNAsequence.
Sequencing
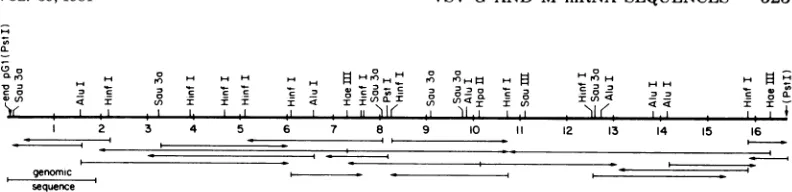
strategy forpGl.
Initialre-strictionmapping combined with previous
par-tialsequences (24) allowedus tolocate thetwo
HaeIII sites within the
pGl
insert(Fig. 3).
Initialsequences were then established from the cen-tralHaeIIIsitereading520nucleotides toward
the 5' end of the mRNA and 350 nucleotides toward the 3' end. Additionalsequence was de-termined from the3' HaeIII site for520 nucleo-tides toward the 5' end of the mRNA. This approach, with sequencing gels 152 cm long, allowedus to establishatentativesequencefor almost the entire Ggeneusing onlytwo restric-tion sites.Arestrictionmap wasthenestablished
from this sequence by computer analysis (32).
Subsequentlywe were able to identify specific restrictionfragments requiredto complete the sequence onboth DNA strands and correct a
few errors that were generated by reading se-quences more than 450 nucleotides from the
labeled end. Figure3shows the locationsof sites
for restriction enzymes that were used in the sequence analysis and the
specific
regionsse-quenced.SeveralEcoRII sites
(CC
T GG) wereencountered in this
analysis.
These sequencesshowed gaps in the sequence ladderatthe
sec-ondC residue (20), and thesequences atthese siteswere alwaysconfirmed
by
sequencing
thecomplementarystrand.
Thecomplete sequence of theGmRNA pre-dicted from thesequence of the
pGl
clone(and
previousdata, references24and27)is shown in
Fig. 4. The sequence contains a
single
openreading frame for translation beginning at the
5'-proximal ATG codon (positions 29
through
31) andending 100nucleotides from the 3' end of the mRNA. That this is the
reading
frame encoding G proteinhas beenconfirmedby
directsequencing
of Gprotein
at both ends of the molecule (12, 15,27).Nucleotide
sequencing
of the M mRNA. A J. VIROL.on November 10, 2019 by guest
http://jvi.asm.org/
[image:4.503.52.248.207.569.2]a~
D v) <i 0 0 HI )I
C I,,H)PH,,H1,,re)H HH H
2 3 4 5 6 7 8 9 10 12 13 14 15 16
genonc . .
sequence
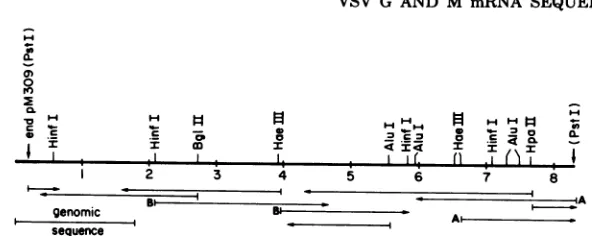
FIG. 3. Restriction map of thepGFI insert DNA. Sites for restrictionenzymnes that were used in sequencing are shown. The left end corresponds to the 5' end of G mRNA. Arrows indicate the regions sequenced andthe direction of sequencing. Numbers are in hundreds of nucleotides starting from the 5' end of the mRNA. Terminal PstI sites are at the junctions ofpBR32 sequences with the dG:dC tails. The 5'-terrninal sequence of G mRNA determnined previously from the genomic sequence is indicated (27). The sequence of the 3'. terminal 470 nucleotides were reported previously from a smaller clone, but also were sequenced on at least one DNA strand inpGI.
sequence from the 5' end of the M
protein
mRNA had been determined from thesequence
ofa DNA
primer
extended from theadjacent
NSgenealong the genomeintothe M
mRNA-codingregion (24).This sequence
overlaps
and agreeswith thesequencesdetermined from the pM309 insert (Fig. 5) and with thesequenceofa partial M clone
(pM101;
L.Iverson,
unpub-lished
results;
12a). The remainder of the MmRNAsequencewasdetermined
by sequencing
from the restriction sites indicated in
Fig.
5.Allregionswere
sequenced
onbothDNAstrandsorsequencedatleast twice
(from
differentsites)
to ensureaccuracy.TheMmRNA is831nucleotides
long
without polyadenylic acid and contains asingle
openreading framefortranslation
extending
from the 5'-proximal ATG codonatpositions
42through
44 to aTAGtermination codonatpositions
729through 831
(Fig. 6).
Otherreading
frames areblocked
extensively throughout
the mRNA se-quence,leaving
little doubt that thepredicted
Mprotein sequence iscorrect.
Although
nodi-rect protein sequence is available for
M,
thesequence of the ribosome
binding
site deter-mineddirectly
fromthe mRNA(23)
is incom-plete agreement with the sequence
predicted
here from the cDNA clone. The sequence also matches the
partial
RNA sequence of the MmRNA
determined
by
priming
ongenomic
RNAfromthe adjacent NSgene
(24).
DISCUSSION
VSV G
protein
structure and modifica-tion. The nucleotide sequencepresented
here for theVSVglycoproteinmRNApredicts
a pro-teinof511 aminoacids(57,416
daltons),
includ-ing the NH2-terminal
signal
sequence of 16 amino acids that isnot presenton the matureprotein (12, 15, 27). The
predicted
COOH-ter-minal sequence of G contains ahydrophobic
domain of20amino acids(residues
463through
482)followedby a hydrophilic domain (residues 483 through511). We have presented evidence
previously that the hydrophobic domain spans
thelipid bilayer ofthe viral envelope, and that
the COOH-terminal charged domain residues
insidethe viral envelope leaving more than95% of the protein protruding from the virus (27).
The COOH-terminal basic domain probably in-teractswith intemal virion proteins and
cellular
proteins during budding of the virus from the
plasma membrane.This portion ofGcouldalso
playarole in targeting the proteinto theplasma
membrane.
The VSV Gprotein contains twoapparently
identical Asn-linked complex oligosaccharides (10, 21). The precise locations of the
oligosac-charide attachment sites in G are of special
interest becausethetiming of the glycosylation eventsrelative to the timingofGprotein
syn-thesis has beenexaminedin detail invitro.
Ad-dition of
oligosaccharide
chainsby transfer fromalipid carrieroccurs onthe nascentpolypeptide chain (29, 34). The first addition occurs when about 38% of the chain has been synthesized, and the secondoccurswhen about70% has been
synthesized (29), assuming that therateof pro-teinsynthesisis
uniform
in thein vitrosystem.N-glycosidic linkage
ofoligosaccharides
to pro-teins occurs at Asn-X-Ser or Asn-X-Thr se-quences(19).Inspection of the predicted G pro-tein sequencereveals 18Asnresidues, but onlytwoofthese (amino acid residues 178and 335,
Fig. 4) occur in canonical glycosylation se-quences. We therefore presume that these are theactualglycosylationsites. These sites are at fractional distances of 0.35 and 0.66 from the NH2 terminus. Thenearlyexactcorrespondence ofthepositionsofthesesites with fraction ofG synthesizedwhen
glycosylation
occurs suggests thattransferofoligosaccharides tothenascentprotein chain occurs when theappropriate Asn residues traverse theroughendoplasmic
on November 10, 2019 by guest
http://jvi.asm.org/
[image:5.503.63.459.66.162.2]fl0 :t VA- MK CTS 0LYS PHE THR ILE VAL PHE PRO HIS ASN GLN LYS GLY ASN TRP LYS
TCATTGGGGTGAATTGCAAGTTCACCATAGTTTTTCCACACAACCAAAAAGGAAACTGGA
70 80 90 100 110 120
ASN VAL PRD SER ASN TYR HIS TYR CYS PRO SER SER SER ASP LEU ASN TRP HIS ASN ASP AAAATGTTCCTTCTAATTACCATTATTGCCCGTCAAGCTCAGATTTAAATTGGCATAATG
130 140 150 160 170 180
LEU ILE GLY THR ALA ILE GLN VAL LYS MET PR) LYS 5ER HIS LYS ALA ILE GLN ALA ASP ACTTAATAGG CACAGCCATACAAGTCAAAATGCCCAAGAGTCACAAGG C3TATTCAAGCAG
19 200 210 220 20 240
GLY TRP MET CYS HIS ALA SER LYS TRP VAL THR THR CYS ASP PHE ARG TRP TYR GLY PRD ACGGTTGGATGTGTCATGCTTCCAAATGGG TCACTACTTGTGATTTCCGCTGGTATGGAC
250 260 270 280 290 300
LYS TYR ILE THR 1Q1]. 5ERR ILE ARG SER PHE THR Pr) SER VAL GLV GiLN CYS LYS GLU 5E
CGALASG TTART AITAAACACG TSCECRAAT CGATCTTCACTCCAT TGTA GAACA TGC AAGGAAA
310 320 330 0 0 350 360
ILE GLV GLN THR LYS GLN GLY THR TRP LE ASN PR GLY PHE PR) PR) GLN S CYS GLY
GCATTGAACAAACGAAACAAGGAACTTGGCTGAATCCAGGCTTCCCTCCTCAAAGTTGTG
370 380 390 400 410 420
TYR ALA THR VAL THR ASP ALA GLU ALA VAL ILE VAL GLN VAL THR PR) HIS HIS VAL IL GATATGCAAG M40 TGTGACGGATGCCGAAGCA~4A40TG 45&TGGTGCGTAT~ACTTAT T G TC4i60 GGTGACTC4C70 CAC CA TG Ta C
VAL ASP GLU TYR THR GLY GLU TRP VAL ASP SER GIL PHE ILE ASN GLY LYS CYS SER ASN
TGGTTGATGAATACACAGGAGAATGGGTTGATTCACAGTTCATCAACGGAAAATGCAGCA
490 500 510 520 530 540
TYR ILE CYS PR) THR VAL HIS m. THR TRP HIS SER ASPTYR LYSVAL LYS GLY
ATT ACA TA 5GCC C C ACTGW6CCA TAA C TCW7AC AA CC T G G&AT TCT G ACT G TCAA8 LEW CYS ASP SER ASN LEU ILE SER MET ASP ILE THR PHE PHE SER GLU ASP GLY GLU LW
GGCTATGTGATTCTAACCTCATTTCCATGGACATCACCTTCTTCTCAGAGGACGGAGAGC
610 620 630 640 650 660
SER SER LEW GLY LYS GLU GLY THR GLY PHE ARG SER ASN TYR PHE ALA TYR GLU THR GLY
TATCATCC%TGGGAAAGGAGGGCACAGGgTTCAGAAGTAACTACTTTG5 TATGAAACT2
60 680 690 7007172
GLY LYS ALA CYS LYS MET GLN TYR CYS LYS HIS TRP GLY VAL ARG LW PR SER GLY VAL
GAGGCAAGGCCTGCAAAATGCAATACTGCAAGCATTGGGGAGTCAGACTCCCATCAGGTG
730 740 750 760 770 780
TRP PHE GL] MET ALA ASP LYS ASP LEW PHE ALA ALA ALA ARG PHE PR) GLU CYS PR) GLU
TCTGGTTC9AGATGGCTGATAAGGATCT ,TTGCTGCAi2CAGATTCCJGAATGCCCftg
790 800 1o 38
GLY SER SER ILE SER ALA PR) SER GLN THR SER VAL ASP VAL SER LW ILE GiLN ASP VAL
AAGGGTCAAGTATCTCTGCTCCATCTCAGACCTCAGTGGATGTAAGTCTAATTCAGGACG
850 860 870 880 890 900
GLU ARG ILE LEW ASP TYR SER LEW CYS GLN GL T1R WRP SER LYS ILE ARG ALA GLY LW
T T G A G AGG A T C T T G G A T T AWTCC C TC TGj3gA A G A A ACCC48G A GCAAA A 5EA G AG C G G G
PR) ILE SER PR) VAL ASP LEU SER TYR LWU ALA PR) LYS ASN PR) GLY TM GLY PR) MA
TTCCAATCTCTCCAGTGGATCTCAGCTATCTTGCTCCTAAAAACCCAGGAACCGGTCCTG
970 980 990 1000 1010 1020
PHE
TTILEA ILE LEU LYS TiR PHE GUl THR ARG TiE IIC ARG AGL ASP ILE
CTTTCACCATAATCA
~~A'"TA
'CCTAAAATACTTTGAGACCAGATACATCAGAGTCGATA
1030 1040 1050 1060 1070 1080
ALA ALA PR) ILE LEW SER AR MET VAL GLY MET IE SER GLY THR THR T11 GLU ARG GLU
TTGCTGCTCCAATCCTCTCAAGAATGGTCGGAATGATCAGTGGAACTACCACAGAAAGGG
1090 1100 1110 1120 1130 1140 LEU TRP ASP ASP TRP ALA PR) TYR GLU ASP VAL GLU IIE GLY PR) ASN GLY VAL LW ARG
AACTGTGGGATGACTGGG6tCCATATGAG Al8GTGGACCCAfACGTGGAGGGAGTTCT1G
THR SER SER GLY TYR LYS PHE PRO LEU TYR Mr IIE GY HIS GLY MET LEU ASP SER ASP
GGACCAGTTCAGGATATAAGTTTCCTTTATACATGATTGGACATGGTATGTTGGACTCCG
1210 1220 1230 1240 1250 1260
LEU HIS LEU SER SER LYS ALA GLN V'L PHE GiL HIS PR) HIS ILE GLN ASP ALA MA SE
ATCTTCAT WTAGCTCAAAgGCTCAGGT TTCGAACAT5TC ATC GCCGC2
ATCTTCA1217ATGCCTTACAC128T G 90TC
GLN LEU PR ASP ASP GLU SER LEU PHE PHE GLY ASP THR GLY LEU SER LYS ASN PR) ILE
CGCAACTTCCTGATGATGAGAGTTTATTTTTTGGTGATACTGGGCTATCCAAAAATC CAA 1330 1340 1350 1360 1370 1380 GiL LW ML GiLU GLY TRP pHE SSE SER TRP LYS .. U5
TCGAGCTTGTAGAAGGTTGGTTCAGAT GAA
3125TATTOPT36144
1390 1400 1411 142 A3ItTT
ALU. M: VAL GLY ILE LW CYS ILE
CATAGGGTTAATC A
GG4T
CTCCCA GTTGGTATCCATCTTTTG CATTA1450 1460 1470 1480 1490 1500 LWIUSLW 1W 115 WI ~GilN IL.8 TYR THR ASP ILE (LU MET ASN S L L I
AATTAAAGCAC ACCAA AAA ACAGATTTATACAGACATAGAGATG1AAC ACTTGGAA
1510 1520 1530 1540 1550 1560
AGTAACTCAAATCCTGCACAACAGATTCTTCATGTTTGGACCAAATCAACTTGTGATACC
1570 1580 1590 1600 1610 1620
ATGCTCAAAGAGGCCTCAATTATATTTGAGTTTTTAATTTTTATG
1630 1640 1650 1660
524
on November 10, 2019 by guest
http://jvi.asm.org/
-4
if
0) 0
e .C
I
t
H 14 M
z m I
i
2 3 4,<, I H I
I r Il )
5 6 7 8
AA
genomic
At-sequence
FIG. 5. Restriction map of the pM309 insert DNA. Sites for restrictionenzymes used in sequencingare
shown. The left end corresponds to the 5' end of M mRNA. Arrows indicate the regions and directions sequenced; numbersrepresenthundredsof nucleotides. Arrows labeled A and Brepresentsequences
deter-minedfrom cDNA clones pM32andpM37 which contain smaller portions of the MsequencethanpM309.
Terminal PstI sitesareatthejunctions ofpBR322sequenceswiththedG:dC tails. The 5'-terminal mRNA sequence(genomic sequence) reported previously is indicated (24).
lum. Extensivefolding ofthepolypeptide chain
onthe COOH-terminal site of theglycosylation
sites is apparently notrequired to specify gly-cosylation.
Oneto twomolecules offatty acidare
esteri-fiedtoGproteinatalatestageinpassageof G
from the rough endoplasmic reticulum to the plasma membrane (31). The evidence suggests that thefatty acid isesterifiedtoserine residues (31). Ourpreliminary evidence (W. J. Welch, B. M. Sefton, and J. K. Rose, unpublished data) indicates that[3H]palmitate labelcanbe found
associated specifically with the 64-amino acid,
membrane-protectedtailpieceofG isolatedafter proteolysis of intact virions (27). Thereareonly
fiveserine residues in thisportionofG,andthey
are clustered around the NH2-terminal side of
the hydrophobic domain (Fig. 4). Presumably,
one or more of these residues are esterified to
fatty acid. Fatty acid esterified in this region could serve the obvious function ofpromoting stable association of the hydrophobic protein domain with the membrane.
Structure and function of VSV M. The nucleotidesequence of theVSV M mRNA
pre-sented here predicts a proteinsequence of 229 amino acids (26,064 daltons). The predicted amino-terminalsequence of M is highly basic. Eightlysine residuesoccurinthe first 19 posi-tions,and thesearetheonly chargedresiduesin this region (Fig. 6). A triple proline sequence
separates this domain from the remainder of the
molecule. There isevidence from analysisof M protein mutants andfrom in vitro studies that Mmayregulate VSV transcription (4,7, 9, 16). This basic domain might play a role in such
regulation, perhaps by interacting with the
ge-nomic RNA. The predictedsequence indicates
that M is themostbasic of the VSV N, NS, M, and G proteins,having 21 Lys, 10Arg, and8His residues and only 13 Asp and 13Glu residues. Although there isnodirect amino acidsequence
analysis available for M protein, this basic char-acter isconsistent with its isoelectric point de-termined by gel electrophoresis (4). Our at-temptstoobtainanNH2-terminalsequencefrom
M havebeen unsuccessful, suggesting that the NH2 terminus is blocked.
Evidence indicates that M protein is released into the soluble fraction ofinfected cells after
synthesis. It then associates rapidly with the plasma membrane fraction (14). It is notclear, however, whether there isanydirectassociation
of M withthelipid bilayer of the plasma
mem-brane. There is evidence that M will associate with membrane fractionsfromuninfectedcells,
although it is notclear that this interaction is biologically significant (8). Inspectionofthe
pre-dicted M protein sequence (Fig. 6) does not reveal any long hydrophobic or nonpolar
do-mains that might be inserted into the
mem-brane. This situation contrasts with that of the influenza virusmatrixproteinwhich hasa
cen-tralhydrophobicdomainthatmaybe membrane
FIG. 4. Nucleotide sequence ofthe VSV G mRNA and thepredicted protein sequence. The shaded
nucleotidesequenceis the ribosomebindingsite.NH2-terminalandCOOH-terminalhydrophobicdomains
areshaded,as arethetwopotentialglycosylationsitesand basic residues in the COOH-terminalhydrophilic
domain. The bracketed G residue(317) appeared clearlyas aGontwosequencing gels ofthe DNAstrand shown. ThesequenceofthecomplementaryDNA strandusingthesameDNApreparationshowedaclearA residueinsteadoftheexpectedC in thispositionin twoseparateexperiments. Thisresidue and the amino acid encoded shouldthereforebe considered tentative. Nucleotidenumberoneis linked tothe 5'capinthe mRNAsequence.
0.
I
I
on November 10, 2019 by guest
http://jvi.asm.org/
[image:7.503.106.402.63.181.2]526 ROSE AND GALLIONE
AACAGATATCACGATCTAAGT
10 20
G
Gtt*$£e:q-bt.C¢.-s-T-C: C.¢...-m..f..
.7...C77CILLEW GLY LEU GLY LEU GLY ILE ALA TYR
G GfA AGGGATCG^CACcACfi
GLU G ASPM TH SER MET GW TI ALA PR SM ALA PR ILE ASP LYS SE TE PHE GLY
ATGAAGAGGACACTAGCAT4GGAGTATGCTCCGAGCGCTCCAATTGACAAATCCTATTTTG
13 0 40 150 160 170 180
VAL ASP GLU MEr ASP THR TYR ASP PRO ASN GLN LEU ARG TYR GLU LYS PHE PHE PHE THR
GAGTTGAC GAGGACTGATG TCG ACA TTAAGATATGAGAAATTCTTCTT TA
A0 0 220 230 0
VAL LYS MET T VAL ARG SER ASN ARG PRO PHE ARG TH TYR SER ASP VAL ALA ALA ALA
CAGTGAAAATGACGGTTAG6ATCTAATCGTCCGTTCAGAACATACTCAGATGTGGCAGCCG
250 260 270 280 290 300
VAL SER HIS TRP ASP HIS MET TYR ILE GLY MET ALA GLY LYS ARG PRO PHE TYR LYS ILE
CTGTATCCSATTGG GATCACATGTACATSCGGAATGGCAGGGAAACGTCCCTTCTACAAAA
310 320 303 340 350 360
LEU ALA PHE LEU GLY SER SER ASN LEU LYS ALA T1 PRO ALA VAL LEU ALA ASP GLN GLY
TCTTGGCTTTTTTGGGTTCTTCTAATCTAAAGGCCACTCCAGCGGTATTGGCAGATCAAG
370 380 390 400 410 420
GUL] PR GLU TYR HIS TH HIS CYS GLU GLY ARG ALA TYR LEU PR) HIS ARG MET GLY LYS
GTCAACCAGAGTATCACACTCACTGCGAAGGCAGGGCTTATTTGCCACATAGGATGGGGA
430 440 450 460 470 480
THR PRO PRD MET LEU ASN VAL PRO GLU HIS PHE ARG ARM PRO PHE ASN ILE GLY LW TYR AGACCCCTCC~CATGCTCAATGTACCAGA ,CACTTCAGAAGACCATTCA 3TATAGGTCT
AGACCCCT490CAG 500 10 520
A30
A40
LYS GLY THR ILE GLU LEU TH MET THR ILE TYR ASP ASP GLU SER LW GLU ALA ALA PRO ACAAGGGAACGATTGAGCTCACAATGACC7ATCTACGATGATGAGTCACTG8GAA GCAG T
550 560 7 80 600
MET ILE TRP ASP HIS PHE ASN SER SER LYS PHE SER ASP PHE ARG GLU LYS ALA LW MET CTATGATCTGGGATCATTTCAATTCTTCCAAATTTTCTGATTTCAGAGAGAAGGCCTTAA
610 620 630 640 650 660
PHE GLY LEW ILE VAL GiL LYS LYS ALA SER GLY ALA TRP VAL LW ASP SER ILE SER HIS
TGTTTGGCCTGATTGTCGAGAAAAAGGCATCTGGAGCGTGGGTCCTGGATTCTATCAGCC
670 680 690 700 710 720
PHE LYS ***
ACTTCAAATGAGCTAGTCTAACTTCTAG CTTCTGAACAATCCCCGGTTTACTCAGTCT
730 740 750 760 770
7A0
CCTATT 5,t CCCTCGAACAACTAATAT CCTGTCTTT2TCTATC
C C T A A TTCC798GCCT
CTG800
820FIG. 6. Nucleotidesequence ofthe VSVMmRNA and thepredictedMprotein sequence. Theshaded nucleotidesequenceis the ribosomebindingsite(23).Basic residuesneartheNH2terminus and thetriplePro
sequence areshaded.
associated (37). The nature of VSV M
protein
association with the viral
envelope clearly
re-quires furtheranalysis.
CG dinucleotide
deficiency
and codonusage. There is an overall
deficiency
of thedinucleotideCGin theG andMmRNA's. This deficiencyisalsoseenintheNandNS mRNA's (11). Onarandom basisconsideringbase
com-position, one would predict 74 CGs in the G mRNA-coding region and 34 CGs in the M
mRNA-coding region,whereas only24 and 18,
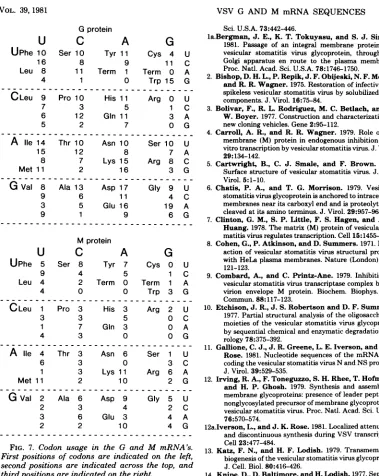
respectively, are observed. This deficiency is clear frominspection ofthe codon usage in both mRNA's(Fig. 7). ArgininecodonsAGAorAGG
are preferred over CGN arginine codons, and there isinfrequentuse of codons having CG in the second and third positions. The CG
defi-ciencyisalsoobservedbetween adjacent codons. Thatis,if one considers thefrequencyof codons
havingC in thethirdposition and G in the first
position, random assortment would generate 37 CGs in G mRNA and 20 CGs in M mRNA
betweenadjacent codons, whereas only 14 and
9,respectively,occur.Because theCGdeficiency
isobservedbetween
adjacent
codonsaswell aswithincodons, the
deficiency
isprobably
not anadaptationof the virus to arelativeshortage of cellular tRNA's recognizing codons containing CG. Consistent with thisinterpretation, wefind
that CG is also deficient in the 479noncoding nucleotide ofthe G, M, N, and NS mRNA's where 18CGs areexpected and only 9 are found. Vertebrate DNA is known to be deficient in the CG dinucleotide (33), although the reason for this is not known. Ifthe mechanismof
selec-tionagainst CG is the same for cellular DNA and VSV RNA the selection must be able to operate attheRNAlevelbecauseVSVhas only RNA intermediates in transcription and
repli-cation.
Both the G and M mRNA's aremoderatelyA rich(32 and 30% A,respectively).Thepreference for codonshaving Ain the thirdposition
pre-sumablyreflects this basecomposition (Fig.7).
on November 10, 2019 by guest
http://jvi.asm.org/
[image:8.503.71.445.75.395.2]Gprotein
U C
UPhe 10 Ser 10 Tyr
16 8
Leu 8 11 Term
4 1
CLeu 9 Pro 10 His
7 3
6 12 Gin
5 2
A lie 14 Thr 10 Asn
15 12
8 7 Lys
Met11 2
G Val 8 Ala 13 Asp
9 6
3 5 Glu
9 1
Mprotein
U C
UPhe 5 Ser 8 Tyr
9 4
Leu 4 2 Term
4 0
C Leu 1 Pro 3 His
3 3
1 7 Gin
4 3
A lle 4 Thr 3 Asn
6 3
1 3 Lys
Met11 2
GVal 2 Ala 6 Asp
2 3
3 6 Glu
2 2 l
FIG. 7. Codon usage in the I Firstpositions ofcodons are in secondpositions are indicated thirdpositionsareindicatedon
ACKNOWLEDGMI We thank Bart Sefton and Linda I mentsonthemanuscriptand otherr
Virology Laboratory for their helpft gratefultoLindaIversonfor providi pMlOl (IversonandRose,inpress)w firmsour5'-terminalsequencefromp: This workwassupported byPubli4
AI-15481 from the National Instituteo
Diseases andCA-14195fromthe Nati4
LrTERATURE CI 1. Ball,L.A.,and C. N. White. 197( ofgenesofvesicular stomatitis
VSV G SEQUENCES 527
Sci.U.S.A. 73:442-446.
la.Bergman,J. E.,K. T. Tokuyasu,and S. J.Singer. A
G
1981. Passage of an integral membrane protein, the 11 Cys 4 U vesicular stomatitis virus glycoprotein, through the 9 11 c Golgi apparatus en route to the plasma membrane. 1 Term O A Proc.Natl.Acad.Sci.
U.S.A.78:1746-1750.1 Tr 15 G 2. Bishop, D.H.L.,P.Repik, J. F.Obijeski,N. F. Moore,
0Trp15 G and R. R.Wagner.1975.Restoration ofinfectivityto spikeless vesicular stomatitis virus bysolubilized viral 11 Arg 0 U components. J.Virol.16:75-84.
5 1 C 3. Bolivar, F.,R.L. Rodriguez,M.C.Betlach, and H. 11 3 A W. Boyer. 1977.Construction and characterization of
7 0 G newcloningvehicles. Gene 2:95-112.
--- - - --- 4. Carroll, A.I.,andR. I. Wagner. 1979. Role of the
10 Ser 10 U membrane (M) protein in endogenousinhibitionof in 8 7 A vitro
trnscription
byvesicular stomatitis virus. J.Virol.
8
5
7rg
AC29:134-142.
15 Arg 8 C 5. Cartwright, B., C. J. Smale, and F. Brown. 1969.
16 3 G Surface structure of vesicular stomatitis virus. J. Gen.
-- - - --- - Virol.5:1-10.
17 Gly 9 U 6. Chatis, P. A., and T. G. Morrison. 1979. Vesicular 11 4 C stomatitis virusglycoproteinis anchoredtointracellular
16 19 A membranes nearits carboxyl end and isproteolytically
9966 G
G>
7. Clinton,cleaved at its amino terminus. J. Virol. 29:957-963.G.M.,
S. P.Little,
F. S. Hagen, and A. S. Huang.1978.The matrix(M) protein of vesicular sto-matitis virusregulatestranscription.Cell 15:1455-1462. 8. Cohen, G.,P.Atkinson,and D.Summers.1971.Inter-A G action of vesicularstomatitis virusstructural proteins 7 Cys 0 U with HeLaplasmamembranes. Nature(London)231:
7 Cys 0 U
~~~121-123.
5 1 C 9. Combard, A., and C.Printz-Ane. 1979. Inhibition of 0 Term 1 A vesicular stomatitis virustranscriptasecomplex by the
0 Trp 3 G virion envelope M protein. Biochem. Biophys. Res.
- - - . Commun. 88:117-123..
3 Arg 2 U 10. Etchison, J.R.,J. S. Robertson and D. F. Summers. 5 0 C 1977. Partial structural analysis of theoligosaccharide 3 O A moieties of the vesicular stomatitis virusglycoprotein O 0 G by sequentialchemical andenzymaticdegradation.
Vi-rology78:375-392.
11.
Gallione,
C.J., J. R.Greene,L E.Iverson,and J. K.6 Ser 1 U Rose. 1981. Nucleotide sequences of the mRNA's en-0 3 C coding the vesicular stomatitis virus N and NS proteins. 11 Arg 6 A J.Virol.39:529-535.
10 2 G 12. Irving,R.A., F. Toneguzzo, S. H. Rhee, T.Hofmann,
_
- - - and H. P. Ghosh. 1979. Synthesis andassemblyof
9 Gly 5 U membraneglycoproteins:presenceof leaderpeptidein 4 2 C nonglycosylatedprecursorof membraneglycoproteinof vesicular stomatitis virus. Proc.Natl. Acad. Sci. U.S.A.
3 4 A 76:570-574.
10 4 G 12a.Iverson, L., and J. K. Rose. 1981.Localizedattenuation - ---- - - and discontinuoussynthesisduringVSVtranscription.
G and MmRNA's.
1.Cell
23:477-484.Gdicated
ontheNA's-,
13.Katz,F.N.,andH. F. Lodish. 1979.Transmembrane[dicated on the left, biogenesis of the vesicular stomatitis virus glycoprotein. acrossthe top, and J.Cell. Biol. 80:416-426.
theright. 14.Knipe, D., D.Baltimore, and H. Lodish.1977.Separate pathwaysof maturation of themajorstructuralproteins
ENTS of vesicular stomatitis virus. J. Virol. 21:1128-1139. 15.Lingappa, V. R.,F. N. Katz,H. F. Lodish,and G. verson forcriticalcom- Blobel. 1978. A signal sequence for the insertion of a members ofthe Tumor transmembrane glycoprotein. J. Biol. Chem. 253:8667-al suggestions. We are 8670.
ngsequencedata from 16.Martinet, C., A. Combard, C. Printz-Ane, and P. vhich overlaps and con- Printz. 1979. Envelope proteins and replication of
ve-M309. sicular stomatitis virus: in vivo effects of RNA' tem-cHealthService grants perature-sensitive mutations on viral RNA synthesis. J. ofAllergyandInfectious Virol.29:123-133.
onal Cancer Institute. 17. Maxam,A.M.,andW.Gilbert.1980.Chemical sequenc-ingof DNA.MethodsEnzymol.65:501-561.
[TED 18. Morrison, T. G., and H. F. Lodish.1975.Site of
synthe-6.Order oftranscription sis of membrane andnonmembrane proteinsof vesicu-virus. Proc.Natl. Acad. lar stomatitis virus. J. Biol. Chem.250:6955-6962.
on November 10, 2019 by guest
http://jvi.asm.org/
[image:9.503.56.435.51.527.2]19. Neuberger, A., A. Gottschalk, R.D.Marshall,andRI.
G.Spiro.1972.Carbohydrate-peptidelinkages in
gly-coproteins and methods fortheirelucidation, p. 450-490. In A. Gottschalk (ed.) The glycoproteins: their composition,structureand function.Elsevier, Amster-dam.
20. Ohmori, H., J. I. Tomizawa, and A. Maxam. 1978. Detection of5-methylcytosine in DNA sequences. Nu-cleicAcids Res. 5:1479-1485.
21. Reading,C. L.,E.E.Penhoet, andC. E. Ballou. 1978. Carbohydrate structure of vesicular stomatitis virus glycoprotein. J. Biol. Chem. 253:5600-5612.
22. Rose, J. K. 1977.Nucleotide sequences of ribosome rec-ognitionsitesonmessenger RNAsof vesicular stoma-titis virus. Proc. Natl. Acad. Sci. U.S.A.74:3672-3676. 23. Rose, J. K. 1978.Complete sequence of ribosome
recog-nition sitesinVSV mRNAs. Cell14:345-353. 24. Rose, J.K. 1980.Complete intergenic and flanking gene
sequencesfrom the genome of vesicular stomatitis virus. Cell 19:415-421.
25. Rose,J. K.,and L. E. Iverson.1979.Sequences from the 3' ends of VSV mRNA'sasdetermined from cloned DNA.J. Virol.32:404-411.
26. Rose, J. K., H. F.Lodish,and M. L. Brock. 1977. Giant heterogeneouspolyadenylic acid on vesicular stomatitis virus mRNAsynthesized in vitro in the presence of S-adenosyl hemocysteine. J. Virol.21:683-694. 27. Rose, J. K.,W. J.Welch, B. M.Sefton, F. S. Esch,
and N. C. Ling.1980.Vesicular stomatitis glycoprotein isanchored in the viral membrane byahydrophobic domain near the COOH-terminus. Proc. Natl. Acad. Sci.U.S.A. 77:3884-3888.
28. Rothman, J.E.; and R. E. Fine.1980.Coated vesicles transportnewly synthesized membrane glycoproteins from endoplasmic reticulum to plasma membrane in
twosuccessive stages. Proc. Natl. Acad. Sci.U.S.A.77: 780-784.
29. Rothman, J.E., and H. F. Lodish.1977.Synchronized transmembrane insertion andglycosylationofa mas-centmembraneprotein.Nature(London) 269:775-780. 30. Roychoudhury,R., E. Jay, and R. Wu.1976.Terminal labeling and addition ofhomopolymer tracts to duplex DNAfragments by terminal deoxynucleotidyl transfer-ase.Nucleic Acids Res. 3:101-116.
31. Schmidt, M.F., and M. J. Schlesinger. 1979. Fatty acid bindingtovesicular stomatitisvirusglycoprotein: a new typeofpost-translational modification of the viral gly-coprotein. Cell 17:813-819.
32. Staden, R. 1977. Sequence data handling by computer. Nucleic Acids Res. 4:4037-4051.
33. Swartz, M.N., T. A.Trautner,and A.Kornberg. 1962. Enzymaticsynthesis of DNA: further studies on nearest neighbor base sequences in deoxyribonucleic acids. J. Biol. Chem. 237:1961-1967.
34. Toneguzzo,F., andH. P. Ghosh. 1977.Synthesis and glycosylationinvitro ofglycoprotein of vesicular sto-matitis virus. Proc. Natl. Acad. Sci. U.S.A. 74:1516-1520.
35. Wagner, R. R.1975.Reproductionofrhabdovirus, p. 1-93. In H. Fraenkel-Conrat and R. R. Wagner (ed.), Comprehensive virology. Plenum Publishing Corp., New York.
36. Wensink, P.C.,D. J.Finnegan, J. E. Donelson, and D. S. Hogness. 1974. A system for mapping DNA sequences in the chromosomes of Drosophila melano-gaster.Cell 3:315-325.
37.Winter, G., and S. Fields. 1980. Cloningof influenza cDNA into M13: the sequence of the RNA segment encodingtheA/PR/8/34 matrix protein. Nucleic Acids Res.8:1965-1974.