Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
5-1-2000
Global optimization: techniques and applications
Nathan Cahill
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
Recommended Citation
Global Optimization: Techniques
and
Applications
Nathan
D. Cahill
May
2000
Rochester Institute
ofTechnology
Rochester,
NY
14623
Submitted in
partialfulfillment
ofthe
requirementsfor
the
degree
ofMaster
ofScience in
the
field
ofIndustrial
andApplied Mathematics
Thesis Committee:
Prof. Richard
Orr,
Chair
Dr. Maurino Bautista
Dr. Seshavadhani Kumar
This thesis fulfills the project/thesis requirement
for the degree of Master of Science in the field of
Industrial and Applied Mathematics
at Rochester Institute of Technology
Prof. Richard Orr, Chair
Dr. Maurino Bautista
Dr. Seshavadhani Kumar
RELEASE PERMISSION FORM
Rochester Institute of Technology
Global Optimization: Techniques and Applications
I,
Nathan D. Cahill, hereby grant permission to any individual or organization to reproduce this thesis in
whole or in part for non-commercial and non-profit purposes only.
Abstract
Optimization
problems arisein
a widevariety
of scientificdisciplines.
In many
practicalproblems,
a global optimumis
desired,
yetthe
objectivefunction has
multiplelocal
optima.A
number ofTable
of
Contents
Introduction
3
1
:Local
Optimization
1.1
Combinatorial Optimization
4
1.2
Continuous Optimization
4
1.2.1 Unconstrained Minimization
5
1.2.2
Constrained
Minimization
9
2: Monte Carlo Global Optimization
2.1 From Local
to
Global Optimization
11
2.2 Random Searches
12
2.3
Simulated
Annealing
13
2.4 Genetic Algorithms
18
3: Deterministic Methods for Global Optimization
3.1 Integer / Mixed Integer
Programming
25
3.2 Unconstrained Optimization: Transformation Methods
27
3.3 Constrained Optimization: Path
Following
31
4: Histogram
Thresholding
for Image Segmentation
4.1 The Image Segmentation Problem
36
4.2
Estimating
Population Mixtures
38
4.3 Simulated
Annealing
for
anIndeterminate Number
ofThresholds
40
4.4
Genetic Algorithms for
anIndeterminate Number
ofModes
41
5:
3-D Registration
ofPoint Sets
5.1 The 3-D Registration Problem
44
5.2 Algorithms for Known Point Correspondence
44
5.3 Global Solutions for Unknown Point
Correspondence
47
Acknowledgments
49
Introduction
Optimization
problems arisein nearly every
area of science and engineering.A
chemistmay
wantto
determine
the
minimumenergy
structure of a certainpolymer,
abiologist may
needto
investigate
optimal
dosages
andscheduling
ofdrugs
administeredto a cancerpatient,
a civil engineermay
needto
decide how many
elevatorsto
placein
an officebuilding
sothat
waiting
time
is
minimized,
and animage
scientist
may
wishto
be
ableto
automatically locate
peoplein
animage.
In
introductory
calculusclasses,
the
most complicated optimization problems students arefaced
withusually
soundsomething
like,
"What
is
the
maximum areathat
canbe
enclosed with afence
oflength
Fl"Even
though theseproblemsteachanimportant
lesson,
rarely
can real-world problemsbe
solvedsolely
by
the
analyticaldetermination
of pointsthat
satisfy
first- and second-orderoptimality
conditions.A
typical
optimization problemtakes
theform:
minimize
fix)
subject
to
xD
where x ={x\j.z,...jcn)T
is
a vector ofparameters,
and/isthe
objectivefunction.
In
otherwords,
find
x* suchthat
^x*)
<fix)
for
all x eD.
Note
that
maximization problems canbe
posedin
this mannerby
negating/.If D is
adiscrete
set, the
problemis
referredto
asa combinatorial optimization problem.If D is
closed and/
is
continuous,
thisis
a continuous optimization problem.This
thesis
will notfocus
on non-smooth optimization problems wherethe
objectivefunction is
discontinuous,
ornon-differentiable,
on a compact set(for
an analysis ofthese
typesof problems seeChapter 14
ofFletcher
[15]).
A variety
of methods existto
determine local
solutions(
is
alocal
solutionif
f(\)
<fix)
for
allx e
N
nD,
whereN is
a neighborhood of x')for both
combinatorial and continuous optimization problems.For
combinatorialproblems,
a simple choiceis
the
iterative
improvement
method(a
deterministic
descent
method).More
sophisticatedmethods,
such as thebranch
andbound
method(a
method that solves a series of continuous optimization
problems),
are also available.For
continuousproblems,
avariety
oflocal
minimization methods existthat
requirefunction
values(simplex),
function
valuesand
derivatives (conjugate
gradient and quasi-Newtonmethods),
orfunction
values,
first
and secondderivatives (Newton
and restrictedstep
methods).If D is
compact,
it
canbe
representedby
the
intersection
of
equality
andinequality
constraints.Such
constrained optimization problems arisefrequently
in
practice and canbe
solvedin
avariety
ofways;
many
of which arebased
onthe
idea
ofLagrange
multipliers.The
problem of global optimizationis
much more complicated.Theoretically,
global minimizationis
as simple asfinding
the
minimum of alllocal
minima andboundary
points.In
application,
this
canbe impractical.
All local
optimizationtechniques
require aninitial
feasible
point x(1)e
D from
which
to
begin
thealgorithm.In
order tofind
a givenlocal
minima,
it is necessary
to choose afeasible
pointthat
willconverge tothat minima;
however,
determining
such afeasible
point canbe
asdifficult
assolving
the
optimization problemitself!
Global
optimization canbe
categorized as stochastic ordeterministic.
Stochastic
orMonte Carlo
methods(e.g.,
randomsearch,
Metropolis
algorithm,
simulatedannealing,
geneticalgorithms,
etc.)
randomly
sampleD in
an attemptto
locate feasible
pointsthat
arelocal
minima
(or
lie sufficiently
closeto
local
minima).Deterministic
methodscarry
out some non-random search procedureto
weed throughlocal
minima andfind
the
global minimum.For
example,
branching
techniquessetup
simple sub-problemsto solve,
sub-energy
tunneling
iteratively
transforms the
objectivefunction
to
removelocal
minima,
and pathfollowing indirectly
locates local
minimaby
solving
a system ofdifferential
equations.This
thesis
is broken down into five
chapters.Chapter 1
gives an overview oflocal
optimization methodsfor
combinatorial and continuous problems.Chapters 2
and3
discuss Monte
Carlo
anddeterministic
techniques
for
globaloptimization,
respectively.Chapters
4
and5
illustrate
two
difficult
imaging
science problems andhow
they
canbe
attacked with global optimization algorithms.Chapter
4
discusses
the
thresholding
problemin image
segmentation,
andChapter 5
probesthe
3-D
registrationChapter 1: Local Optimization
1.1
Combinatorial
Optimization
The
combinatorial optimization problemhas
the
form:
minimize
fix)
(1.1.1)
where x=(xl,x2,...,xn)r
is
a vector of parameters.We
cansafely
assumethat
D is
afinite
set(if
not,
we canimpose
suitable restrictions onthe
*,-),
andthat
D
is
of sufficient size that abrute force
searchis
impractical.
Ignoring
multipleinstances
ofthe
samefunction
value,
we can establishby
the
Well
Ordering
Principle
that
a global minimum exists.This
global minimumis
notnecessarily
unique,
but it
satisfies:/(x*)</(x)
VxeD
(1.1.2)
In
orderto
attemptto
solve(1.1.1),
wemay design
a simple algorithmthat
canbe described in
the
following
steps:Algorithm (1.1.1): Combinatorial Steepest Descent
(i)
Set
k
=l.
Choose
x^.(ii)
Find
y
suchthat
/(y)</(x)
for
all xeNk
.(iii)
If
y
=x(k>,
terminate.
If
not,
set x^+1'=y
.(iv)
Set
lc
=k
+l.
Goto(ii).
In step
(ii), Nk
is
the
neighborhood of x^(the
setincluding
x^and all of
its one-step
transitions).
This
algorithmis
a steepestdescent
algorithm; that
is,
it iterates
by descending
in
function
value asfast
as possible.When
the
algorithmterminates
at x^,wenoticethat
x^m'satisfies:
/(x)</(x)
VxeNm
(1.1.3)
Since
x'"1^does
notnecessarily satisfy
(1.1.2),
it may
notbe
the
globalminimum;
ratherit is
alocal
minimum.The
steepestdescent
methoddescribed in Algorithm
(1.1.1)
is
a specifictype
ofiterative
improvement
algorithm.On
eachiteration,
it
selectsthe
valuethat
mostimproves
the
objectivefunction.
In
general,
iterative improvement
algorithmsonly
requirethat the
objectivefunction improves
somewhat on eachiteration.
Such
an algorithmis
categorized as adescent
method and canbe
carried outdeterministically
(by
searching
throughthe
neighborhoodin
a certainorder)
orstochastically
(by
randomly
choosing
pointsin
the neighborhood)
untilanimprovement is found.
1.2 Continuous Optimization
The
continuous optimization problemhas
the
sameform
asthe
combinatorial optimization problemin
(1.1.1).
In
this
contextthough, D
is
some continuousdomain. If D
is
9T
(or
Cn),
then
(1.1.1)
is
unconstrained.If D
is
a compactset,
thenit
canbe
represented asthe
intersection
of a set ofequality
andinequality
constraints,
andthe
optimizationproblemtakes the
form:
(1.2.1)
minimize
/W
subject
to
c,(x)=0,ie E
where
E
is
the
set ofequality
constraints and/
is
the
set ofinequality
constraints.Analogous
to
(1.1.3),
a pointis
consideredalocal
minimumif
there
exists an e >0
suchthat:
/(x')</(x)
Vxe B(x',e)nZ)
(1.2.2)
where
B(x',e)
is
the
openball
of radius e centered at .If
the
inequality
is
strict,
then wesay
is
a strictlocal
minimum.1.2.1
Unconstrained
Minimization
For
the
standard unconstrained optimizationproblem,
we will assumethat
D
=9T
(nearly
everything in
this
section generalizestothe
caseD
=C"
as well).
In
orderto
explainthe
methods usedto
find local
minima,
we must understandthe
properties ofthese
minima.If
is
alocal
minimum of(
1
.1
.1),
then there
are nodescent
directions
at x'.Mathematically
speaking,
fs(a)=/(x'+as)
has
zero slope and non-negative curvature atfor any direction
s.The
zeroslope conditionis
satisfied when=
0,
where
g
=V/(x)
is
the
gradient of/
andis
givenby:
(1.2.3)
V/(x)=(^/(x)^/(xy.,^/(x)
dx. '3v
(1.2.4)
The
curvature constraintis
satisfied whensTG's>
0
Vs
*0
,where
G
=V2/(x)
is
the
Hessian
matrix of/
andis
givenby:
(1.2.5)
VV(x>
dx2dxi
* ^ 'dx2dx2
^ 'dx2d:
Sr/W ^r/(x)
^-/(x)
dxnd:
dxndx2
(1.2.6)
Conditions
(1.2.3)
and(1.2.5)
statethat
atany local
minimum, the
gradient vanishes andthe
Hessian
is
positive semi-definite.If
the
Hessian is
positivedefinite;
i.e.:
sTG s >
0
Vs*0,
(1.2.7)
then the
minimumis
strict.Therefore,
(1.2.3)
and(1.2.5)
arenecessary
conditionsfor
alocal
minimum,
and(1.2.3)
and(1.2.7)
are sufficient.(1.2.7)
is
noteasy
to test
in
practice;
any
ofthe
following
conditionsare equivalent
to
positivedefiniteness
and canbe
easierto test:
(i)
all eigenvalues of G'are positive
(ii)
all principal minors of G'arepositive
(iii)
Cholesky
factors
G' =LLT
exist with
/,,
positiveDescent
methods with exactline
search were some ofthe
earliest methodsfor local
optimization(Curry
[10]).
These
methodsrely
onthe
fact
that
if
x^exist a
direction
s^) suchthat
s^ g^<0
.
Then
s^
is
adirection along
which/
canbe
reduced(a
descent direction).
An
exactline
searchis
performedto
locate
the
minimum of/
along
s^', and theresulting
pointbecomes
nextiterate
x^+1'.Descent
methods withline
search canbe described in
the
following
steps:Algorithm (1.2.1): Descent
methods withline
search(i)
Set
Jfc=l.
Choose
x(l).(ii)
Terminate if
x^satisfies
(1.2.4)
and(1.2.5).
(iii)
Choose
s^ suchthat
s^gW<
0
.(1.2.8)
(iv)
Find
y>
that
minimizes /(xW+ aH(t)).(1.2.9)
(v)
Setx(*+1W*)+ aHW.(vi)
Set
k
=k
+l.
Go
to
(ii).
In
general,
it is
noteasy
to
solve(1.2.9)
exactly;
therefore,
an approximationto
o>k> must suffice.A
comprehensivetreatment
ofthe
line
search sub-problemis
givenin Chapter 2
ofFletcher [15].
At
ahigh-level,
aninexact line
searchis
comprised of abracketing
phase,
where an acceptableinterval
of pointsis
located,
and asectioning
phase,
wherethe
bracket is
partitionedinto arbitrarily
small sections until a minimumis found
to
withina presettolerance.The
choice of s^in
(1.2.8)
canradically
affectthe
convergence properties ofadescent
method.An intuitive
choiceis
the
steepestdescent
direction,
the
direction
s^ thatleads
to the
most rapidinitial
descent in
/
.The
steepestdirection
at x^is
that
ofthe
negative gradient -g'*'.
Therefore,
the
steepestdescent
method withline
searchis
givenby
Algorithm
(1.2.1)
with(iii)
replacedby:
(iii)
Set
sW=-gW .In
practice,
however,
steepestdescent is
a poor methodin
that
it
can exhibitoscillatory behavior. In
fact,
it
canbe
shownthat
in
certaininstances,
steepestdescent
with exactline
search appliedtoa simple quadraticfunction
does
notterminate
in
afinite
number ofiterations!
In light
ofthe
poor convergence properties of steepestdescent,
another class ofline
search methods wasdeveloped
thatattemptto
improve
convergence whilemaintaining
some notion ofdescent.
These
methods,
called conjugate gradientmethods,
arebased
on theconjugacy
property
of vectors.The
vectors s^ ands'2'
are conjugate with respect
to
G
(or G
-conjugate)if:
s(l)TGs(2)=
0
(1.2.10)
For
a simple quadraticfunction,
a conjugate gradientmethod canbe
constructedby
choosing
s^'+1^to
be
the
component of-g^+1^conjugate
to
s'^.s'2' s'^and
performing
aline
search asin Algorithm (1.2.1).
The Fletcher-Reeves
conjugategradient method(Fletcher
andReeves
[16])
usesthespecificformula:
sd)= _g(o,
s(*+o=_g(*+o+I^As(*)
(L2.n)
wThis
method preservesdescent
andterminates
in
n orfewer iterations for
a n-dimensional quadraticfunction.
Note
that
a positivedefinite
quadraticfunction
t7(x)
=-LxTGx+ gTx +b
canbe
minimizedanalytically
by
solving
the
system Gx*=
-g,
but for large-scale
problems conjugate gradient methodsdo
Another
family
oflocal
minimization methodsis based
oniteratively
minimizing
quadraticTaylor
series approximations
to
/
.Given
a point x^\Newton's
method constructs the truncatedTaylor
seriesapproximation
q^k'(s)
to
/
at x^:/(x+s)=
/)()
=!sTGH
+ gWTs +/(xW)
(1.2.12)
A
newiterate
is
computedby
finding
the
minimum of c/(s):
XM)=XW+
S(*),
(1.2.13)
where gHW=-g^
(1.2.14)
The
system(1.2.14)
canbe
solvedby
avariety
ofdifferent
methods.Solution
by
Cholesky
factorization
enables
the
positivedefiniteness
of G^'to
be
checked.(1.2.13)
canbe
replaced with aline
search asin
steps
(iv)
and(v)
in Algorithm
(1.2.1)
if desired. If
x'*'is sufficiently
closeto the
local
minimum x', thenNewton's
methodexhibits second order convergence.In
general, this
is
much more efficientthan
conjugate gradientmethods,
but Newton's
method(or
Quasi-Newton
methods)
may be impractical for large-scale
problems.
Newton's
method can alsobe
usedin
conjunction with aline
search carried outalong
s'^ .The
maindifficulty
withNewton's
methodis
that the
Hessian
matrixmay only be
positivedefinite
in
a small neighborhood ofthe
solution.This
difficulty
canbe
overcomeby
adding
a multiple oftheunit matrixandsolving
the
system:(*)J.A(*)__(0
(sW
+vI>^=-gW
(1.2.15)
in
place of(1.2.14).
This
idea
appearedoriginally in
Levenberg
[29]
andMarquardt [31].
By
selecting
vso
that
g'^+ vIis
positivedefinite, (1.2.15)
usesthe
quadraticinformation
presentin
(1.2.12)
to
find
the nextiterate
andeventually
convergesto the
local
solution.Restricted step
methodscarry
this
modification evenfurther
by
constraining
thesolutionto
(1.2.15)
to
lie
within some trustregion,
whichis generally
anellipsoid or
hyperparallelepiped
centered at x'*^ .When
secondderivatives
aredifficult (or
inefficient)
to compute,
anotherfamily
of methods(Quasi-Newton
methods)
canbe
used which approximate theinverse Hessian
matrix G^*'by
a positivedefinite
matrix H^ andthen
carry
on aline
search asin Newton's
method.The
matrix H^'is
updatediteratively
(starting
with someinitial
positivedefinite
matrix such as h'1'=I
)
by incorporating
secondderivative information
obtainedat eachiteration.
In
orderto
do this,
we willfirst
expand the gradient(1.2.4)
about xW:V/(x(*)+uW)=
V/(xW)+
^/(x^^^
+iU^in.
(1.2.16)
This
canbe
rewrittenas:>)
=g(^i)_gW=G^)+/p)|n.
(1.2.17)
Therefore,
H^ canbe
updatedsothat
h(*+1)v(*)=u^).
(1.2.18)
A
rank-twoupdating
method was proposedby
Davidon
[12],
Fletcher
andPowell
[13].
A
rankH(M=HW+ aiaaT
+ a.2bbT.
(1.2.19)
Since
the
quasi-Newton condition(1.2.
18)
mustbe
satisfied,
wehave
uM=HWvM+aiaaTvM
+ a2bbTvW.
(1.2.20)
If
the
choices a=uSk'and
b
=H^'V*^ aremade, then
(1.2.20)
reducesto the
DFP formula:
H^
=h(*)+^
\
.(1.2.21)
DFP
U(*)TV(*) v(*FH(*)y(*)
Broyden
[5],
Fletcher
[14],
Goldfarb
[18],
andShanno
[41]
introduced
anotherupdating formula
that
is
the
dual
ofthe
DFP formula. The
BFGSformula is
givenby:
Hfc&=H+
ooth(*)(*)i1i(*v.(*f
1
+U(*)TVW
L^WV^H^W^l
(*>%(*) u^V*)
(1.2.22)
In
fact,
aninfinite
number ofupdating formulas
existthat
satisfy
the
quasi-Newton condition.The Broyden
family
of methodsis
givenby
<+1)
=0H^+(l-*)H^).
(1.2.23)
,(*FV(*)
If
we choose0
=/ ^ , then we
have
a rank one updateto
h'*'.
Both
the
DFP
and ,(*)U(*)TV(^)_V(^TH(*)V(*)
BFGS
formulae
exhibitdesirable
properties;
they
preservethe
positivedefiniteness
of HK ' so adescent
direction is
alwayschosen,
they
generate conjugatedirections
andterminate
in
at most niterations
for
quadraticfunctions,
andthey
exhibit superlinear convergencefor
generalfunctions.
It
has been
shownin
the
literature
thatthe
BFGS
methodglobally
converges wheninexact line
searches are performed(under
certainconditions);
consequently,
it has become
the
quasi-Newton method of choice.When
it becomes difficult (or extremely
inefficient)
to
computefirst
derivatives,
any
ofthe
previous methods canbe
used withfinite difference
approximationsto the
gradient vector(and
the
Hessian
matrix,
for Newton's
method).Formula
(1.2.24)
showshow
to
approximate each element ofthe
gradient vectorwithcentereddifferences:
^/(x+
8ej-/(x-8e,)
(1224)
where
e,
is
the
j'thcolumn ofthe
identity
matrix.A
finite difference
approachis probably
the
best
no-derivative
methodsfor
unconstrainedoptimization;
however,
it
stillmay be
too
costly
to
performIn
function
evaluations eachiteration.
If
this
is
the case,
other no-derivative methods canbe
used.The
most popularones arebased
onthe
simplexmethod(Spendley
et al.[43]).
In
the
simplexmethod,
/
is
evaluatedat a set of(+l)
equidistant pointsin
9T.
A
new simplexis
formed
by
reflecting
the
point withthe
largest function
valuethroughthe
hyperplane
containing
the
other n points.When
a point xhas been in
a simplexfor
a given number ofiterations,
the
simplexis
contractedby
relocating
the
remaining
n pointshalf
the
distance
to
x.Termination generally
occurs whenthe
simplex occupies a smaller volumethan
somethreshold.
The Nelder-Mead
method(Nelder
andMead
[34])
is
a simplex methodthat
allowsfor
irregularly
shapedsimplices,
andfor
expansions as well as contractionsbased
onthe
local geometry
of/
.In
general, the
simplexmethod canbe
a poor choicebecause it does
not guarantee convergenceto
alocal
minimum.However,
it
canbe very
useful whenattempting
to
optimize1.2.2
Constrained
Minimization
For
the
standard constrained optimizationproblem, the
setD is
compact and canbe described
by
the
intersection
ofthe
equality
andinequality
constraints of(1.2.1).
In
unconstrainedminimzation,
any
local
minimum satisfies conditions(1.2.3)
and(1.2.5).
In
constrainedminimization,
theseconditions need nothold.
All
that
is necessary for
alocal
minimumis
that
nofeasible descent direction
exists.In
orderto
describe
this mathematically,
let
usfirst
considerthe
case whereD
contains noinequality
constraints(i.e.,
/
=cj>). The
following
development is based
onthat
givenin
Chapter
9
ofFletcher [15].
Suppose
is
alocal
minimizer of(1.2.1).
Expanding
theconstraints about x',wehave:
+
5)=c,(x')+5Ta;+0|5|).
(1.2.25)
where
a,
=Vc,(x)
is
the
Ithcolumn of
the
Jacobian
matrix.If
we assumethat
8 is
afeasible
step,
thenc,
(x'
+
5)
=c,
(x')
=0
,so we
know
that
5Ta;=0
V<e.
(1.2.26)
If
the
condition5Tg'<0
(1.2.27)
holds,
then8 is
adescent direction
at .Since
this
contradictstheassumptionthat
is
alocal
minimizer of(1.2.1),
it
mustbe
truethat
nodirection 8
satisfies(1.2.26)
and(1.2.27)
simultaneously.If
wesay
that
g'r^;a;=AV,
(1.2.29)
then we can see that
8Tg'
=
^^5Ta;
=0, so(1.2.29)
does
not allowfor
(1.2.26)
and(1.2.27)
to
be
;<=
simultaneously
satisfiedfor any 8
.In
fact,
it
canbe
shownthat
(1.2.29)
musthold
at alocal
minimum,
so(1.2.29)
becomes
anecessary
conditionfor
alocal
minimum.The
condition(1.2.29)
statesthatat alocal
minimum,
thegradientmustbe
alinear
combination ofthe
constraint gradients.The
coefficients(Vs)
f^e linear
combination are referredto
asLagrange
multipliers.A
simpleway
to
restatethe
first
ordernecessary
conditions arisesfrom
theLagrangian
function:
L(x,X)=/(x)-V;(x).
d-2.30)
i
The
condition(1.2.29)
is
equivalentto:
VxL(x'X)=0,
(1.2.31)
and satisfaction of
the
constraintsin
(
1
.2.1)
is
equivalentto:
VxL(x'X)=0.
(1.2.32)
<5TV2L(x'Y)8>0
(1.2.33)
for
all5
*0 that
satisfy
(1.2.26)
is
a sufficient conditionfor
alocal
minimum.When D
containsinequality
constraints,
we areonly
concerned withthe
active constraints at a givenminimum; that
is,
the
set of constraintsthat
satisfy
c,(x')=0.We
willdenote
the
active set of constraints atby
/l'
,and
the
set of activeinequality
constraints atby
/'=
rf
c\I.If
we now observethe
Taylor
series expansion ofthe
constraints at givenby
(1.2.25),
we see that c,(x')=0 andc,
(x' +
8)
>0
, so we
know
that
8Ta;>0
V/e/'.
(1.2.34)
It
canbe
shownthat the
following
conditions musthold for
(1.2.34)
and(1.2.26)
to
be
satisfied while(1.2.27)
is
not satisfied:=*>;=
AY,
(1.2.35)
X',>0
Vie
I'.
(1.2.36)
Therefore,
any
activeinequality
constraints musthave
positive multipliers.By
convention,
wesay
thatany
inactive
inequality
constraints correspondto
zeromultipliers.The
first-order necessary
conditionsfor
minimizationcanbe
restated asfollows:
(1)
vxl(x'X)=q
(ii)
c,(x')=0,V/e E
(iii)
c,(x')>0,V/e
/
(iv)
X\
>0,
V/e/
(v)
V;(x')=0,
Vi
These
conditions areknown
asthe
first-order KT
conditions(Kuhn
andTucker [27]).
The
first
two
conditions
follow
directly
from
(1.2.31)
and(1.2.32). The
third
conditionfollows from
(1.2.1),
the
fourth
from
(1.2.36),
andthefifth from
the
conventionthat
inactive
constraintshave
zero multipliers.The
theoretical approachto
solving
constrained minimization problemsis
to
locate
all pointsthat
satisfy
the
KT
conditions and seewhich,
if
any,
satisfy
the
second-order conditions.This
approachis
known
asthe
methodof Lagrange
multipliers.Like
the
theoretical approachto
unconstrainedminimization,
it is
frequently
difficult,
if
notimpossible,
toapply
this
methodto
a given "practical" problem.Because
ofthis,
a number of alternate algorithmshave
arisenbased
onthe
structure ofthe
objective
function
and constraintfunctions.
If
the
objectivefunction
and constraintfunctions
arelinear, (1.2.1)
is
alinear programming
problem.A LP
is
mostreadily
solvedby
eitherthe
Dantzig-Wolfe
simplex method(Dantzig
andWolfe
[1
1])
orthe
activeset method.Both
methodsrely
onthe
fact
that
in
aLP
problem,
any
extreme value musttake
placeat a vertex ofthe
set of constraints.At
ahigh
level,
they
searchthroughdifferent
vertices ofthe
feasible
region,
swapping
constraintsin
andout ofthe
active set until a minimumis
found.
For
quadraticprogramming
problems,
wherethe
objectivefunction is
quadratic andthe
constraints arelinear,
a similar activeset approachis
employedthat
solvesthe
equality
constrainedQP
at eachiteration
by
transforming
it
into
an unconstrainedQP (via QR decomposition
or generalizedelimination;
seeFletcher
[15]).
General
linearly
constrained problems canbe
solvedin
the
samemanner,
by iteratively
transforming
into
an unconstrainedproblem,
andsolving
each unconstrained problemby
aQuasi-Newton
method,
for
example.The
most complicated constrained minimization problems are called nonlinearprogramming
problems,
Chapter 2: Monte Carlo Global Optimization
2.1 From Local
to
Global Optimization
The
task
of global minimization canbe
daunting
comparedto that
oflocal
optimization.The
theoretical
solutionto the
global optimization problemis
to
determine
the
set of all pointsthat
satisfy
(1.1.3)
or(1.2.2),
sortthem
by increasing
function
value,
andtake the
first
element(or
elements,if
the
function
valueis
notunique)
ofthe
setto
be
the
global minimum.This
process canrarely be
carried outanalytically,
unlessthe
objectivefunction
and constraints are simplein
nature.In
general,
though,
eventhesimplest
looking
problems canbe extremely difficult
to
optimize.It
is
no wonder,then,
thatmany
algorithmsbased
onMonte Carlo
techniques
have
emergedin
recent years.One way
to
setup
a simpleMonte Carlo
algorithmis
to
representthe
search spaceD
asthe
union of afinite
number of(not
necessarily mutually
exclusive)
setsSk,
k
=l,...,N.
In
the
case whereD
is
unbounded,
suitablelower
and upperbounds
onthe
parameters mustbe
chosen.A
set of pointsjx'^lx^e
Sk,k
=1,...,n\
is
randomly
chosen,
and each xik)used as an
initial
pointin
one ofthe
local
optimization algorithms
described in
theprevious chapter.We
willillustrate
this techniqueby
minimizing
the
following
function:
/(x)=
sir^Tu:!
)cos(47tt2)+cos(47t
XyX2)
0
<xx
<1,
0
<x2
<1
(2.1.1)
As
canbe
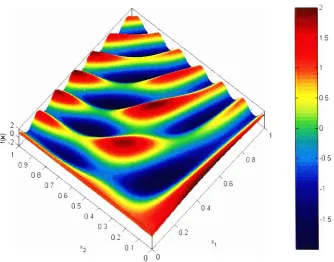
seenin Figure (2.1.
\),
fix)
has many local
minimain
this
region.The
globalminimum occurs atapproximately
.-05
0 o
Figure (2.1.1): Surface
plot offix)
We
canapply
aMonte Carlo
algorithmby dividing
the
feasible
regioninto
a5
x5
grid.We
then
choose a random point
from
eachpatch,
andapply
the
SQP
method(Schittowski
[40])
iteratively
with eachrandom point as a
starting
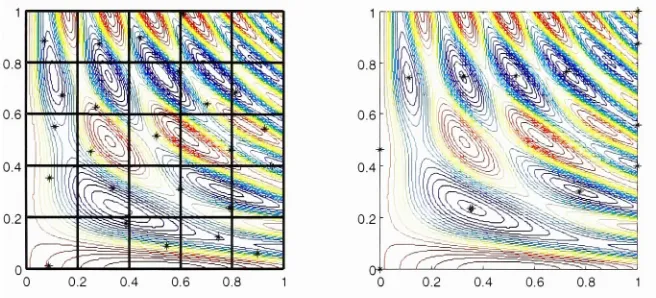
point.The left half
offigure (2. 1
.2)showsthe
5
x5
grid with a random point [image:15.546.120.454.342.604.2]chosen
in
eachsquare,
andthe
right half
showsthe
set oflocal
minimafound
by
different
runs ofthe
SQP
method.
Note
thatin
this case,
alllocal
minima(including
the
globalminimum)
werefound.
06
%
4*
.;-.'s,...
1.2 0.4 0
Figure (2.1.2): Monte
Carlo
algorithmfor minimizing
fix)
In
orderfor
aMonte
Carlo
algorithmlike
this
oneto
be
robust, the
covering
setsSk
shouldbe
small enough
that
they
canbe
contained withinbasins
of attraction oflocal
minima.If
the
Sk
aretoo
large,
the
global minimummay
notbe
found.
On
the otherhand,
if
the
Sk
aretoo small, the
algorithm canbecome very inefficient. One
majordifficulty
withthis type
of algorithmis
that
theonly way
to
construct an"optimal"collectionofcovering
sets requiresknowledge
ofthe
basins
of attraction ofthelocal
minima.Another
major problem withthis
Monte
Carlo
algorithmis
that the
required number ofcovering
sets
Sk
increases exponentially
withthe
dimension
ofthe
problem.One way
to
combatthis problemis
to
keep
track ofthe
sets thathave been
visitedduring
successive callsto the
local
optimizer.If
alocal
optimizer enters a setthat
has previously been
visited, the
local
optimizer canbe prematurely
terminated.
However,
the
Sk
mustbe sufficiently
small(and hence
there
mustbe
alarge
number ofthem)
in
orderto
reap
the
benefits
ofprematuretermination.
In
some optimizationproblems,
it may be very
expensiveto
computefunction
values,
gradientvectors,
andHessian
matrices,
soperforming local
minimizationsfrom
a succession of pointsmay be
out ofthe
question.In
these cases, the
only
recourse(given
current processorspeeds)
is
to
searchfor
minimabased
onfunction
values alone.One way
ofdoing
this
is
the
simplexmethod,
asdescribed in
Chapter
1.
However,
sincethe
simplex methodis
alocal
minimizationmethod,
global minimization still requiresthat
it be
carriedoutfrom
avariety
ofinitial
points.More
efficient methods canbe based
on random searchtechniques.
The
rest ofthis
chapterdiscusses
pure and adaptive randomsearches,
simulatedannealing,
andgenetic algorithms.
2.2 Random Searches
The
simplest random search techniqueis
the
pure random search.The
algorithmis very
straightforward:
randomly
generateN
feasible
points,
and choosethe
point withthe
smallest objectivefunction
valuefor
the
global minimum.The
pure random searchis
described
as adescent
methodin
Algorithm (2.2.1).
If
refinementis
needed,
alocal
minimization canbe
performedfrom
the
optimalpointfound
by
the
search.The
pure random searchdoes
not yield anefficiency improvement
overthe
algorithmof
Section
2.1;
in
addition,
it
requiresthat
N
growexponentially
withthe
dimension
ofthe
problemin
order [image:16.546.109.437.143.292.2]Algorithm (2.2.1): Pure Random Search
(i)
Set
k
=0
, c=
0
,y
= .(ii)
Randomly
generate x^+1^e
D
(D
is
the
feasible
region)
(iii)
If
/(x(*+l))<y
, sety
=/(x(*+l))
andk
=k
+1
.(iv)
Set
c=c+1
.If
c <N
,go
to
(ii).
Patel,
Smith,
andZabinsky
[36]
andZabinsky
andSmith
[47]
describe
a pure adaptive search algorithmthat
only
requiresN
to
growlinearly
withthe
dimension
ofthe
problem.The
PAS
algorithm canbe described
in
the
following
way:Algorithm (2.2.2):
Pure Adaptive Search
(i)
Set
k
=0
,
y
=- .(ii)
Randomly
generate eSk+l
={x
I
xeD
n/(x)<
>>}.(iii)
Set
y
=/(x(,:+l)).
If
k
<N
,goto
(ii).
Even
thoughthis
search methodis
theoretically
more efficient thanthe
PRS,
it may be
difficult,
if
notimpossible,
to
generatethenested setsin step
(ii).
Romeijn
[37]
describes
an adaptive search methodthat
differs from
the
PAS
algorithmin
that
iterates
are chosenfrom
the
feasible
region(i.e.,
Sk
=D
in step (ii)). The
adaptive nature ofRomeijn's
method
is
that
theprobability distribution
usedto
generate x'A+1'changes on each
iteration
(not
like
the
PRS,
in
whichthe
distribution is generally
uniform).The
sequence ofdistributions is
chosento
convergeto the
stationary distribution
of aMarkov Chain. In
the
nextsection,
simulatedannealing is
introduced;
this
is
a specifictype
ofRomeijn's
adaptive search method.2.3 Simulated
Annealing
Since
being
introduced
by
Kirkpatrick, Gelatt,
andVecchi
[26]
andCerny
[7],
simulatedannealing
has quickly become
one ofthebest
general purposeMonte Carlo
global optimization algorithms.It is
based
onthe
physical modelofannealing,
where a solidis
coaxedinto
a minimumenergy
crystalline stateby
slowly
reducing its
temperature.If
the temperature
is
reducedtooquickly,
metastable structures result thathave higher energy
thanthe
crystalline state.The fundamental
building
block
of simulatedannealing
is
the
Metropolis
algorithm,
introduced
some30
years earlierby
Metropolis, Rosenbluth, Rosenbluth,
Teller,
andTeller
[33],
whichsimulatesthe
energy
configuration of athermally
equilibrating
solid.This
section will
develop
simulatedannealing in
a combinatorialsetting
andthenshowhow it
canbe
extendedto
thecontinuous case.When
a solidis in
thermal equilibrium, the
probability
that the
solidis
configuredin
a givenenergy
stateis
governedby
the
Boltzmann distribution:
PT(x
=i)=e-E-/T,
(2.3.1)
where ;
is
a state withenergy
,
(i
canbe
thought of as a vector of parameters and,
the
corresponding
valueof
the
objectivefunction),
Z
is
a partitionfunction,
andT is
a parameterthat
actslike
temperature.
When
T
approacheszero, the
Boltzmann distribution
concentratesits
massin
the
low energy
states.In
the
limit,
the
only
states with non-zeroprobability
arethe
minimum-energy
states.Metropolis illustrated
that
a combinatorial optimization scheme similarto
a stochasticiterative
improvement
algorithmcanbe
constructed sothat the
long-term
probabilities ofthe
occurrence ofenergy
states approach a
Boltzmann distribution.
The difference between
the
Metropolis
algorithm and astochastic
iterative improvement
algorithmis
that
Metropolis
allowstransitions to
higher-energy
stateswithpositive
probability, whereas,
aniterative improvement
algorithmonly
allowstransitions to
lower-energy
states.
Because
ofthis,
the
Metropolis
algorithmhas
the
potentialto
"jump" out of alocal
minimumto
explore other
feasible
areas ofthe
state space.The probability
that
ahigher energy
transitionis
acceptedis
given
by:
Pacceptkn
=; I
x*
=i.Ej
>,-)=e-{ErEy.
(2.3.2)
This is known
asthe
Metropolis
criteria.We
canencapsulatethe
probability
ofaccepting
atransitionto
any
stateby:
A(r)=
Paccep,(x,+1
=j
I xk
=,-)=eHv^>.o}(2.3.3)
We
can now statethe
Metropolis
algorithm(note
the
similaritiesto
aniterative improvement
algorithm):Algorithm
(2.3.1):
Metropolis
algorithm(i)
Set
k
=\.
Choose
x.(ii)
Randomly
choose x^k+1'e
Nk
(the
neighborhood ofone-step transitions)
(iii)
Accept
x^'+1'with
probability
A,y(r).
If
notaccepted,
set x^+1) =x^.(iv)
Set
k
=k
+l.
Go
to
(ii).
No
termination
criteria areexplicitly
statedin Algorithm (2.3.1).
In
practice, the
algorithm canbe
terminated
whenno substantialdecrease in
function
valuehas been
made overthe
last
niterations.
It
is
interesting
to
notethat
any
given run of aMetropolis
algorithmis
a realization of aMarkov
Chain. In
orderto
constructthecorresponding probability
transition matrix,
we must notonly
considerthe
transition acceptance probabilities givenby
(2.3.3),
but
the
probability
thata particular stateis
generated(as in step
(ii)
ofAlgorithm
(2.3.1)).
Since
eachiterate is randomly
chosenfrom
theset of possibleone-step
transitions
from
the
previousiterate,
the
generation probabilities are givenby:
Gij
=Pchoose&k+i
=J
! x*
=')=,
rr
(2.3.4)
#ot
states inNk
The probability
transition matrixP(T)
is
found
by
considering both
the
generation and acceptance probabilities:[
GijAyiT),
j*i
^)
=l-G,4v(r)
j
=i-(2-3-5)
[
r*iAarts
and vanLaarhoven
[1]
provethat the
stationary distribution
ofthis
Markov
Chain is
indeed
Boltzmann.
Ross
[38]
shows thatthe
vectorofstationary
probabilitiesis
aleft
eigenvector ofP(T)
withcorresponding
eigenvalueX
=1
.Therefore,
oneway
to
solvethe
optimization problemis
to
form
P(T)
andfind
the
appropriateleft
eigenvector.However,
forming
P(T)
requiresthat the
objectivefunction be
evaluated
for every
possiblestate,
whichis
equivalentto
abrute force
search.It
stillbehooves
usto
performthe
analysis on a small problem.Consider
a combinatorial optimization problem withonly four
states.The
possibletransitions
areindicated
by
arrowsin
the
following
diagram:
o
*_y
o
*^y
o
y^s
o
[image:18.546.163.394.602.646.2]We
will assign objectivefunction
valuesto
each state:/(l)
:,=!./(2)=2=0,
/(3)=E3=2,
and/(4)=
4=1.
The
generation and acceptanceprobability
matrices caneasily
be
constructed:G
=From
(2.3.5),
we can constructthe transition
matrix:0
1
0
2
0
0
i
0
0
x
2 . A(r)=0
0
1
0
1
-1/71
e "''1
e0
1
1
0
0
r^0
0
2/r0
1
1
(2.3.6)
p(r)= 20
0
1 -2/r0
-l/r0
0
21-e
(2.3.7)
It
canbe
verifiedthat
Jt(r)
=-i/r -i/r
2g"2/r
+
2^
+2
' e'2'7 + e-1'7 +1
' e~2lT +7^
+1
' 2e"2/r
+2e^T+
2
is
aleft
eigenvector of
p(r)
with unit eigenvalue andthat the
elements ofjt(r)
arethe
masses of aBoltzmann
distribution.
Also,
it is
clearthat
lim
it(r)=(0,1,0,0),
sothe
Metropolis
algorithm appliedto this
problemr->o
can
identify
the
global minimumif
asufficiently large
number ofiterations
are performed andif T is
small.One
ofthe
mostdifficult
aspects ofperforming
combinatorial optimization withthe
Metropolis
algorithm
is
the
choice of an appropriatetemperature
parameter.If T is
too
large,
the
stationary Boltzmann
distribution may
notbe
concentrated enough at the global minimum.If T is
toosmall, the
number ofiterations
requiredto
convergeto
thestationary distribution
canbe
tremendous.
There
is
definitely
atrade
off
that
mustbe
made,
but
the
decision
ofhow
to
makeit
canbe very difficult.
Simulated annealing
utilizes a series of
Metropolis
algorithms,
each with smallerT,
so asto
converge morerapidly
to
astationary distribution
highly
concentrated atthe
global minimum.In
terms
ofthephysicalanalogy,
a solidis
cooledslowly
enough sothat thermal
equilibriumis
achieved at eachtemperature, resulting in
aminimum
energy
crystalline structure.Therefore,
much ofthe
success of a simulatedannealing
algorithmdepends
onthe
cooling
schedule,
orthe
choice ofdecreasing
values ofT.
Simulated annealing
canbe
described
by
Algorithm (2.3.2):
Algorithm (2.3.2):
Simulated annealing
Set
m=l.
Choose
x(l),r(l).
Run Algorithm
(2.3.1)
starting
at x(m)with
T
=T^ .Set
x'm+1'to
be
the
state at which(ii)
wasterminated.
Generate
T^m+1'according
to
cooling
schedule.Set
m=m+1
.
Go
to
(ii).
(i)
(ii)
(iii)
(iv)
(v)
As
wasthe
casein
the
Metropolis
algorithm, termination
ofstep
(ii)
and overalltermination
ofAlgorithm
(2.3.2)
canbe
chosento
occurby
avariety
of means.For
example, the
user could chooseto
perform a singleiteration
atstep
(ii)
andhave
alarge
number ofslowly-changing
temperatures
in
the
cooling
schedule.In
this case,
a run ofthealgorithm wouldbe
a realization of aninhomogeneous Markov Chain.
For
anotherproblem,
the
user could choose arelatively
coarsecooling
schedule andterminate
eachMetropolis
algorithm afteralarge
number ofiterations.
Because
the
success andefficiency
of simulatedannealing greatly
depends
onthe
cooling
schedule,
it
is
important
to
pick a schedulethat
works well.A
simplegeometric schedule wasproposedby
Kirkpatrick, Gelatt,
andVecchi
[26],
andmany
variantsofthis
methodhave
appearedin
the
literature
sincethen.
The initial
value ofT is experimentally determined
sothat the
acceptanceratio(ratio
ofacceptabletransitions to
possibletransitions
at a givenpoint)
is
closeto
one(usually
around0.95).
Then
the
first
Metropolis
algorithmis
almost a random walkthrough
the
state space.New
values ofT
are generatedgeometrically;
i.e.,
r(m+1)=aT^m\
withatypically
between 0.9
and0.99.
Termination
ofthe algorithmcan occur
if
no substantialimprovement
is
observed over a number ofiterations.
Johnson
et al.[25]
describe
some other simplecooling
schedules.Besides
thegeometricschedule,
they
describe
alinear
schedule,
whereT decreases
linearly,
and alogarithmic
schedule,
whereT decreases
according
to:
rW=
--.,
(2.3.8)
l
+ln(m)
where
C is
a constant.They
conclude that none ofthese
schedules yield adramatic
advantage overthe
geometric schedule.
Aarts
and vanLaarhoven
[1]
describe
a more sophisticatedcooling
schedule.Like
thegeometricschedule,
theinitial
valueofT is
determined
sothat
the
acceptance ratiois
closeto
one.New
values ofT
are given
by
the
iteration:
rO+0= jL
8>0,
(2.3.9)
| +
rWln(l
+5)
3o^>
where
8 is
small andis
the
standarddeviation
offunction
valuesfound
during
the
mth
execution of
step
(ii)
ofAlgorithm (2.3.2).
If 8 is sufficiently
small,
thensucceeding Markov Chains have
"nearby"stationary
distributions,
sothe
number ofiterations
requiredfor
eachMetropolis
algorithm toconvergeis
small.
All
ofthe
previous schedulesmonotonically decrease
the
temperature.
In
someinstances,
however,
it may be
valuableto
allow a non-monotonic schedule.Osman
andChristofides
[35]
describe
a"strategic
oscillation"in
whichT is repeatedly decreased according
to
a geometriccooling
schedule untilprogress
halts,
andthenincreased
tohalf
ofits
previousinitial
value.As
an example ofhow
simulatedannealing
canbe
applied to a combinatorial optimizationproblem,
let
us considerthetraveling
salesman problem.This
problem canbe
statedin
thefollowing
way:a salesman
leaves
home,
visits ndifferent
houses,
and returnshome.
How
canthe
salesmanconstructhis
route so
that
thedistance
he
travels
is
minimized?In
orderto
solve this problemusing
simulatedannealing,
wemustappropriately define
a state or configuration and a methodfor
transitioning
toanearby
state.
Each
state canbe
consideredas a possible pathfor
the
salesmanto
travel,
and canbe
representedas a cyclic permutation vector.
For
example,
if
there
are5
houses,
the state(13
4 5
2)
represents a pathfrom house 1
to
house
3
to
house 4
to
house 5
tohouse
2
andback
to
house 1
.In
general,
for
nstates, there
are
(n-l)!/2
cyclic permutations ofthese states,
andhence (n-l)!/2
possible paths.Clearly,
there
aretoo
many
pathsto
performabrute
force
search.We
willdefine
anearby
state as onethat
canbe
reachedby
a2-change.
In
a2-change,
a single element ofthe
permutation vectoris
chosen,
andthe
elementdirectly
to
the
right is
exchanged withthe
elementdirectly
tothe
left.
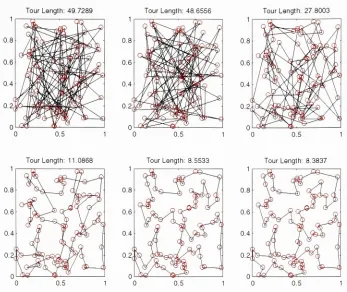
Figure
(2.3.2)
showsthe
results ofapplying
simulatedannealing
to the
traveling
salesman problemwith n =
96
randomly
chosen points.T
was chosenaccording
to
a geometriccooling
schedule witha=0.98,
and500 iterations
were performed.At
eachiteration,
the
Metropolis
algorithm wasiterated
approximately 200
times.
The
plotsin
Figure
(2.3.2)
show samples ofthe
initial
path(upper
left)
andthe
paths afterthe 100th
(upper
middle),
200th(upper
right),
300th(lower
left),
400th(lower
middle),
and500th(lower
left)
iterations
of a single simulatedannealing
run with aninitial
random path.Even
though the
solution
is
notnecessarily
the
global minimum(we
wouldhave
to
iterate
infinitely
to
guaranteethis),
it
is
agood solution.
Upon performing
simulatedannealing five
times
for
this
particularproblem,
different
optimalpaths were
found
eachtime, but
allofthe
solutions were closein
total travel
distance
required.Out
of the
five
trials,
the
best
solution required atraveldistance
of8.1914
units,
whereasthe
worst requiredTour Length: 49.7289
0.8
0.6
0.4
Tour Length:48,6556
0.8
0.6
0.4
iw|3K
)0.2,
53t"fii8sm(
>$s55rTour Length: 27.8003
0.5 0.5
Tour Length: 11.0868
0.8
0.6
0.4
0.2f
n
TourLength: 8.5533
0.8
0.6
0.4
,
<T\
J
qO ci0.2{
TourLength: 8.3837
0.5 0.5
Figure
(2.3.2):
Paths
producedby
simulatedannealing
afterthe
0th(upper
left),
100th(upper middle),
200th(upper
right),
300th(lower
left),
400th(lower
middle),
and 500th(lower
right)
iterations.
Simulated annealing
can alsobe
appliedto
continuous optimization problems.In
orderto
extendthe
paradigmfrom
combinatorialproblems,
we mustappropriately define
the
generation mechanism andneighborhood
in step
(ii)
ofAlgorithm (2.3.1).
Corana, Marchesi, Martini,
andRidella
[9]
describe
analgorithm where
the
neighborhoodNk
is
ahypercube
centered at x^', and a candidate point x't+1'is
chosen
from
a uniformdistribution
overNk
.If
the
candidate pointis infeasible due
to
equality
orinequality
constraints,
a new candidate pointis
chosen.In
orderto
improve
the
efficiency
and convergence properties ofthe algorithm,
Corana
etal. updatethe
size ofthe
hypercube
at eachiteration. If
the
ratioxofthe
number of accepted movesto the
number of rejected movesis
large,
the
searchis progressing
too
slowly,
sotheneighborhoodsize shouldbe increased.
If
this
ratiois
small,
computational effortis
being
wasted,
sothe
neighborhoodsize shouldbe decreased.
Ideally,
x shouldbe
0.5.
A
suggested schemefor
updating
the
radiusis
givenby:
r(*+0=
Akh+v
5t-3
,.(*)
1
+p
2-5t
r(0
T>0.6
T<0.4 ,
otherwise
(2.3.10)
where
(3 is
anexperimentally determined
constant.The
mechanismfor generating iterates
can alsogreatly
influence
the
efficiency
of simulatedannealing.
For
example,
if
a minimumlies
in
along,
narrowvalley,
it is generally
morefruitful
to
search [image:21.546.103.450.57.349.2]along
the
axisthrough the
valley
than
normalto
it.
One
way
to
controlthe
direction
of searchis
outlinedin
Vanderbilt
andLouie
[46],
They
describe
a schemefor generating
stepsaccording
to
aprobability
distribution
whose covariance matrixis
proportionalto the
inverse Hessian
matrix.A
growthfactor
similarto that
ofCorana
et al.is
also usedto
controlthe
size ofthe
search neighborhoods.We
willillustrate
the
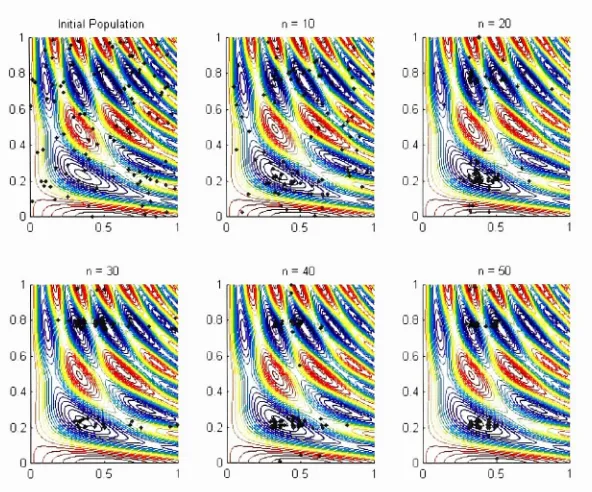
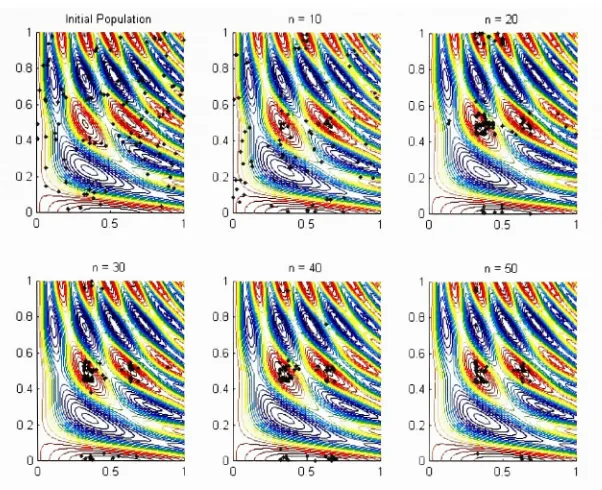
use of simulatedannealing for
continuous optimization problemsby
minimizing
the
function
(2.1.1). (We know
that
its
global minimumis
=(0.5293,0.7513)T
).
The cooling
schedule used
to
solvethis
problem wasgeometric,
with a =0.98
andinitial
temperatureT
-10.
Simulated
annealing
was performed at200
temperature
levels;
at eachlevel,
100
points wererandomly
chosen and
tested
using
the
Metropolis
criteria.Figure
(2.3.3)
showsthe
result of one simulatedannealing
run.
The initial
pointis inside
the thick circle,
andthe
best
pointthat
wasfound (which
is
nearthe trueoptimum)
is inside
the thick
square.All
ofthe
other points correspondto the
best
pointfound
at eachtemperature
level.
Note
that
simulatedannealing did
a goodjob
ofexploring
the
entirefeasible
regionbefore settling
around alocal
minimum.In 100
similarruns, the
solution yieldedby
simulatedannealing
wasin
the
samebasin
of attraction asthe
global minimum89
times.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Figure (2.3.3): Simulated annealing
appliedto
Equation (2.1.1). Initial
pointis in
thick circle,
solutionis
in
thick
square.Other
points arebest
points at eachtemperature
level.
There is
onefinal
note we needto
makein
regardsto
simulated annealing.Because
ofthe
stochastic nature of
this algorithm,
it
cantake
ahuge
number ofiterations
to
yield results ofarbitrary
precision.
Therefore,
it is
recommendedthat the
simulatedannealing
solutionis
used asthe
initial
pointin
a
local
optimizer.This is
a much simplerway
of"fine-tuning"
the
result.2.4
Genetic Algorithms
Genetic
algorithms wereintroduced
by
John Holland
[21]
in
orderto
mimicthe
theory
of naturalselection;
that
is,
the
development
overtime
of a speciesadapting
to
its
environment.In
sexual [image:22.546.140.414.224.489.2]adapt
to
its
environment.Over
generations, this
dependence
manifestsitself
in
apopulationwhoselevel
of adaptation(or
fitness)
continually improves.
In
orderto
understandthe
basic
geneticalgorithm,
we willfirst
introduce
some terminology.A
population of chromosomes
(or
vectors)
is
changed overtime
by
sexualreproduction.Each
chromosomecontains a certain number of
traits,
orgenes,
and each gene cantake
on certainvalues,
or alleles.The
fitness
of a chromosome canbe
evaluatedby
assessing its
particular combination of genes.The
mechanismof reproduction
is
crossover,
where allthe
genesup
to
a random position aretaken
from
oneparent,
and allthe
rest ofthe
genes aretaken
from
the
other parent.Occasionally
mutationstake place,
where one or morealleles are
randomly
perturbed.The basic
genetic algorithm updates a population of chromosomesby
sexual reproduction.Initially,
the
fitness
ofevery
chromosomeis
determined;
then,
two
chromosomes are selectedto
reproduce.Offspring
are producedby
applying
the
crossovermechanism; the
offspring may
thenundergo somedegree
of mutation.Once
the
number ofoffspring
producedis
the same asthe
number ofinitial
chromosomes, anew generation
is formed.
The
new generationis
treated
asthe
initial
population,
andthe
processis
repeated until an entire generation exhibits a predeterminedlevel
offitness.
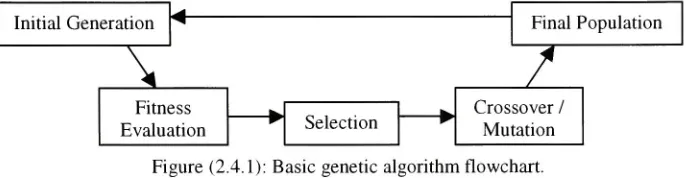
Figure
(2.4.1)
illustrates
the
flow
of abasic
genetic algorithm.^
Initial Generation
^Final Population
\
/
Fitness
h,Crossover /
Selection
^Evalu.
itionw w
Mutation
Figure (2.4.1):
Basic
genetic algorithmflowchart.
In
theinitial
generationC
,there
are nindividual
chromosomes(typically
anywherefrom 50-200).
Each
chromosome canbe
represented as a vector oflength
m,
where mis
the
number of genes.If
x=
(xl,
x2,...,x
is
achromosome, then
xt is
the
particular allele ofthe
i
gene.We
willdefine
>,
astheset of possible alleles ofthe
/
gene,
sothat xi
e>,
.We
will alsodefine
D
=Dx
D2
Dm
asthe
set of all possible chromosomes.
The fitness
of a chromosome xis
givenby
the
scalar-valuedfunction
/(x).
In
the selectionstep, the
probability
that
a chromosomeis
chosenis determined
by
its fitness.
Mathematically
speaking,
if
Sj
is
a random variablerepresenting
the
vector chosenfor
selection, the
distribution
ofS!
is
givenby:
ps,M=
yeC
(2.4.1)
Because
two
chromosomes are selectedfor
reproduction,
they
canbe
chosen with replacement(using
the
distribution
in
(2.4.1))
or without replacement.If
they
are chosen withoutreplacement, the
first
vectorchosen
is
SY
,andthe
secondvector,
say
S2
,has
conditionaldistribution:
PSjIS,<