Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 561
Real-Time Semantic Search Using Approximate Methodology for
Large-Scale Storage Systems
Laudia Sai Krishnaja & P. Sindhu
1
M. Tech Student, Department of CSE, Hyderabad Institute of Technology and Management, Govdavalli,
Medchal, Telangana, India.
2
Assistant
Professor, Department of CSE,Hyderabad Institute of Technology and Management,
Govdavalli, Medchal, Telangana, India.
Abstract—The difficulties of taking care of the dangerous development in information volume and many-sided quality reason the expanding requirements for semantic questions. The semantic inquiries can be deciphered as the relationship mindful recovery, while containing estimated comes about. Existing distributed storage frameworks predominantly neglect to offer a sufficient capacity for the semantic inquiries. Since the genuine esteem or worth of information vigorously relies upon how proficiently semantic inquiry can be done on the information in (close ) constant, expansive divisions of information wind up with their values being lost or altogether decreased because of the information staleness. To address this issue, we propose a close constant and financially savvy semantic questions based system, called FAST. The thought behind FAST is to investigate and abuse the semantic relationship inside and among datasets through connection mindful hashing and sensible level organized tending to essentially lessen the handling inactivity, while bringing about acceptably little loss of information look precision. The close constant property of FAST enables quick ID of associated records and the noteworthy narrowing of the extent of information to be prepared. FAST supports a few sorts of information examination, which can be actualized in existing accessible stockpiling frameworks. We direct a certifiable utilize case in which youngsters revealed missing in a to a great degree swarmed condition (e.g., a very well known grand spot on a pinnacle traveler day) are recognized in an opportune manner by breaking down 60 million pictures utilizing FAST. Quick is additionally enhanced by utilizing semantic-mindful namespace to give dynamic and versatile namespace administration for ultra-substantial capacity frameworks. Broad test comes about illustrate the
proficiency and adequacy of FAST in the execution upgrades.
Index Terms—Cloud storage, data analytics, real-time performance, semantic correlation
1 INTRODUCTION
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 562
business intelligence applications or new logical revelations in logical applications. Since the esteem/worth of information commonly lessens with time, a lot of information are frequently rendered pointless, albeit expensive assets, for example, calculation, capacity and system transfer speed, have just been expended to produce, gather or potentially process these information.
Along these lines, we contend that (close) constant plans are basic to acquiring significant information in accessible information investigation [7]. With regards to this paper, accessible information examination are translated as getting information esteem/worth by means of questioned comes about, for example, finding a profitable record, a connected procedure ID, a critical picture, a modify framework log, and so on. In the rest of the paper, the term information investigation will be utilized to allude to accessible information examination for curtness. With a specific end goal to productively and viably bolster (close ) continuous information investigation, we have to deliberately address the accompanying three look into issues: High access idleness. Existing ways to deal with unstructured information look and investigation depend on either framework based lumps of information records or interactive media based highlights of pictures.
The correct substance based system creates huge measures of helper information (e.g., high-dimensional vectors, complex metadata, and so on), which can be significantly bigger than the unique documents. Indeed, even with the help of cloud stages, it is non-trifling for these plans to get the coveted examination brings about a convenient way. For instance, handling a run of the mill picture of 1MB, utilizing the best in class PCA-SIFT approach [8], brings about 200 KB worth of highlights by and large. This implies examining 1 million such pictures will prompt around 200 GB of storage room prerequisite only for the highlights. A basic operation, for example, finding a match for a given picture from a 2-million-picture set, would require 12.6 minutes of time on a business stage, due to visit gets to hard circles [9], [10].
High question costs. Information investigation for the cloud ordinarily expend considerable framework assets, for example, memory space, I/O transfer speed, superior multicore processors (or, on the other hand GPUs) [11].
One of the fundamental guilty parties for the high asset costs is the serious execution bottleneck every now and again caused by question operations. Truth be told, numerous information investigation related operations vigorously depend on inquiries to recognize the possibility for different operations. For instance, inquiry is the key procedure for discovering access designs, corresponded documents, savvy information replication. Accordingly, we contend that
enhancing inquiry execution is of central significance to overcoming any issues between information investigation execution necessities and cloud framework bolster.
Reduced examination esteems. Because of the long dormancy caused in information preparing and the subsequent information staleness, the esteem/worth of information winds up noticeably decreased and in the long run invalidated. At times, the aftereffects of information examination on stale information can even be deluding, prompting potential deadly shortcomings. For example, the expectation for seismic tremor, tidal wave what's more, tornado depends intensely on dissecting a lot of information from seismic tremor sensors, sea mounted base sealevel sensors and satellite cloud symbolism. The investigation must be finished inside an extremely restricted time interim to stay away from or
limit appalling outcomes.
So as to help proficient information investigation in the cloud, ongoing preparing approaches are essential in managing with substantial scale datasets. This is additionally non-insignificant to cloud frameworks, in spite of the fact that they contain high handling capacity (a huge number of centers) and colossal stockpiling limit (PB-level). The key reason is on account of the examination must be liable to hard time due dates that normally can't be met by savage power with a wealth of assets alone.
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 563
in an ongoing way. The key thought behind FAST is to investigate and abuse the connection property inside and among datasets through enhanced connection mindful hashing [12] and level organized tending to [13] to essentially lessen the preparing inertness of parallel questions, while acquiring acceptably little loss of exactness. The rough plan for constant execution has been broadly perceived in system design and top of the line registering.
Generally, FAST goes past the straightforward mix of existing strategies to offer productive information examination through altogether expanded handling speed. Through the investigation of the Quick technique, we plan to make the accompanying commitments for close continuous information investigation. Space-productive synopsis. Quick use a Bloom-channel based rundown portrayal that has the remarkable highlights of effortlessness and usability. We hash the large size vectors of documents into space-proficient Bloom channels to effectively what's more, viably recognize comparative documents in a constant way. Two comparable records for the most part contain numerous indistinguishable vectors. Blossom channels can keep up the participations of vectors and briefly speak to the similitude of documents. Because of the space effectiveness, considerably more participation data can be put in the primary memory to altogether enhance the general execution. Vitality effectiveness by means of hashing. To generously decrease the measure of comparable pictures to be transmitted, Quick enhances the vitality effectiveness in the cell phones by means of a close deduplication plot. Our plan eases the calculation overheads of existing plans for likeness identification of documents by utilizing region touchy hashing (LSH) [12] that has a multifaceted nature of Oð1þ to recognize and total comparative documents into connection mindful gatherings. This enables the recovery to be limited to one or a set number of gatherings by utilizing connection mindfulness. Not at all like ordinary hashing plans that endeavor to evade or lighten hash crashes, LSH really misuses the impacts in its vertical tending to recognize the potential relationship in a ongoing way.
Semantic-mindful namespace. By misusing semantic relationships among documents, FAST utilizing SANE
[14] to powerfully total related documents into little, level yet promptly reasonable gatherings to accomplish quick and precise queries. Besides, with regards to semantic-mindful namespace, due to the variable lengths of connected records, LSH hash tables will likely prompt uneven burdens and unusual question execution of vertical tending to. To address this issue, Quick streamlines its LSH-based hash works by methods for a reasonable level organized tending to plot utilizing a novel cuckoo-hashing based capacity structure to bolster parallel questions. Quick endeavors the semantic connection to offer an Oð1þ tending to execution. In addition, Genuine framework usage. So as to exhaustively assess the framework execution, we actualize all parts what's more, functionalities of FAST in a model framework. The model framework is utilized to assess an utilization instance of close continuous information examination of computerized pictures. We gather a major what's more, genuine picture set that comprises of more than 60 million pictures (more than 200 TB stockpiling limit) taken of a best visitor spot amid an occasion. In the cloud, quickly transferring furthermore, generally sharing pictures are developing as a propensity and a culture, which helps shape extensive stores of crude pictures on which exact investigation results might be gotten. Utilizing this genuine picture dataset as a contextual investigation, we assess the execution of FAST of finding missing youngsters from the picture dataset and contrast it and the best in class plans. The contextual analysis assessment shows the proficiency and adequacy of FAST in the execution changes and vitality reserve funds.
Whatever remains of this paper is sorted out as takes after. Area 2.1 presents the aftereffects of a client overview, and additionally the FAST system. Segment 3 depicts the FAST design and execution points of interest. We assess the FAST execution in Section 4. Segment 5 exhibits the related work. Segment 6 closes the paper.
2 FAST METHODOLOGIES
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 564
of information sharing. Also, gigantic pictures are produced by the cell phones of clients who routinely take, share and transfer ictures with their phone'sHD cameras. These pictures all things considered shape colossal informational collections promptly accessible for some information investigation applications. Users must harge their cell phones after a single day of direct use. In a 2011 market contemplate led by ChangeWave [15] concerning cell phone disdains, 38 percent of the respondents recorded that the battery life was their greatest objection, with other normal reactions, for example, poor 4G limit and deficient screen measure lingering a long ways behind. A considerable division of vitality utilization in cell phones might be caused, ostensibly, by every now and again taking and sharing pictures by means of the cloud (transferring/downloading).
An instinctive thought is to fundamentally decrease the quantity of pictures to be transferred by sharing (what's more, transferring) just the most illustrative one rather than all, in any event when the cell phone is vitality obliged. This thought is attainable since the pictures to be transferred are regularly indistinguishable or fundamentally the same as the ones that have just been put away in the servers of the cloud. The challenge consequently lies in how to proficiently and precisely distinguish such indistinguishable and comparative pictures.
2.1 Observations, Insights and Motivations
In this segment, we initially exhibit an extensive review of heads/researchers at a cloud focus and afterward ponder three genuine cases, with an objective of increasing helpful bits of knowledge to spur the FAST research.
2.1.1 Insights from a Comprehensive Survey of Cloud Users
Keeping in mind the end goal to better comprehend the prerequisites from high performance cloud clients, we directed a client review to acquire experiences and perceptions that are extremely useful to our outline and, ideally, to the distributed storage inquire about group. The study was led among scientists in the figuring focus. A sum of 200 scientists, including 40 chairmen, 90 specialists and 70 researchers, were surveyed on their assessments on expansive scale information examination (e.g., estimate, sorts, calculation multifaceted nature, normal running time, asset utilization, top concerns, satisfactory exactness of examination comes about) in view of their encounters in utilizing the cloud administrations. The application spaces incorporate computational science and bioinformatics, computational earth and climatic sciences, computational science and computational material science, information examination and information mining, computational liquid progression, computational strong mechanics, solution and biotechnology registering, materials science, what's more, designing reproduction, and so forth.
The study comes about are outlined in Table 1. In particular, three classes of inquiries were asked, i.e., information characteristics (e.g., normal record estimate, add up to measure and the quantity of designs), errand properties (e.g., execution time and asset bottleneck) furthermore, general concerns (i.e., metric of significance and adequate precision of results). Answers to the inquiries are gathered into ranges (i.e., least and most extreme). PCT in the table demonstrates the level of all clients who give the comparing answers (in the section on the prompt cleared out). We accept that every individual has one dataset.
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 565
documents (littler than 10 MB for each document). This pattern infers that a disproportionally extensive size of record structure must be committed to little documents what's more, devours considerable space in the principle memory.
Continuous cloud applications require quick reactions. Over 71 percent of undertakings require over 1 hour execution time, of which 10 percent undertakings keep running for one week or more. This perception exhibits the significance of constant preparing. We examine with the specialists about the reasons. The fundamental reasons, as indicated by the specialists, are twofold.
2.2 The Methodology
2.2.1 The Idea
The thought behind FAST is to investigate and misuse the semantic connection property inside and among datasets by means of connection mindful hashing [12] and level organized tending to [13] to fundamentally diminish the preparing idleness, while bringing about acceptably little loss of exactness, as appeared in Fig. 1. In particular, the correlationaware hashing is to distinguish the associated records by means of the hash-processing way, for example, region delicate hashing. In addition, not at all like the regular examining and tending to in the traditional multi-level order, the flatstructured tending to will be to discover the questioned thing by specifically testing the pail.
2.2.2 Extension to Multiple Types of Data
The FAST methodology can be extended to and well suited for multiple data types. The generality of FAST can be The first is that, consistent with our first insight above, explained as follows. First, most data types can be represented as vectors based on their multi-dimensional attributes, including metadata (e.g., created time, size, filename/ record-name, etc.) and contents (e.g., chunk fingerprints, image interest points, video frames, etc.). FAST extracts key property information of a given type in the form of multidimensional attributes and represents this information in dimensional vectors (i.e., multi-dimensional tuples).
As appeared in Table 2, we expand on the comparing connection between the modules of the FAST technique and common accessible stockpiling frameworks, for example, Spyglass [22] and SmartStore [23], and also an utilization case represented in Section 3.1. The comparing relationship incorporates the vector extraction (VE) for metadata and content, and the information investigation in a close ongoing way. The examinations furthermore, examination can be considered in two viewpoints. In the first place, FAST is a generalizable philosophy, of which a few segments and perspectives are gotten from and have been halfway utilized as a part of existing stockpiling frameworks, for example, Spyglass and Smart- Store.
3 DESIGN AND IMPLEMENTATIONS
In this Section, we present the architecture and implementation details of the FAST methodology via a use case.
3.1 A Use Case and Its Problem Statement
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 566
and the substantial dependence on manual perceptions from overpowering volumes of information.
3.2 The Architecture of Use Case
Quick backings a quick and financially savvy conspire for close realtime information investigation. It utilizes a straightforward and simple to-utilize file structure with three one of kind properties: space-productive condensed vectors, semantic-mindful hashing and level organized tending to for inquiries. The abridged vectors fit the list into the primary memory to enhance ordering execution. The semantic-mindful hashing altogether lessens the many-sided quality of recognizing comparative pictures. The level organized tending to offers Oð1þ multifaceted nature for realtime questions.
The distinguished highlights for the most part require a generally vast space for portrayal, for instance, 200 KB for every 1 MB picture in the best in class PCA-SIFT conspire [8]. One billion such pictures would in this manner require around 200 TB storage room. The capacity and upkeep of these highlights expend considerable space, as a rule too huge to be completely held in the principle memory. The SM module, in view of Bloom channel [29], is hence intended to speak to these highlights in a more space-productive way. The Bloom channels in SM hash the information highlights into steady scale positions in a bit exhibit. Since just the hashed bits should be kept up, these
channels help essentially diminish the space prerequisite of highlights.
3.3 Semantic-Aware Grouping
The element based portrayal for the most part requires largesized memory. To diminish space overhead, we utilize Bloom-channel based bits as the contribution of semantic gathering to get noteworthy space reserve funds [29]. The space-proficient portrayal enables the fundamental memory to contain more highlights. By and large, two comparative pictures suggest that they contain numerous indistinguishable highlights. The indistinguishable highlights are hashed into a similar piece areas in Bloom channels. Thus, two Bloom channels speaking to two comparative pictures will share a critical number of indistinguishable bits. In the multi-dimensional space, each Bloom channel can be considered as a bit vector. Two comparable Bloom channels can speak to near to things by excellence of their Hamming separation. Two comparable pictures can be spoken to as two close by focuses/things in the multi-dimensional space.
A Bloom channel is a bit exhibit of m bits speaking to a dataset S ¼ fa1; a2; . . . ; ang of n things. All bits in the cluster are at first set to 0. A Bloom channel utilizes k free fiery remains capacities to outline of the dataset to the bit vector ½1; . . .;m. Each hash work maps a thing a to one of the m-exhibit bit positions. To decide if a thing an is a correct individual from dataset S, we have to check whether all k hash-mapped bit places of an are set to 1. Something else, an is not in the set S.
Each picture portrayal comprises of Bloom-channel based vectors, which are the contributions to LSH gathering component. LSH figures their hashed esteems and finds them in the pails. Since LSH is area mindful, comparable vectors will be put into the same or nearby cans with a high likelihood. We select them from the hashed pails to shape the relationship mindful gatherings and bolster closeness recovery.
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 567
With a specific end goal to assess the execution of the proposed FAST strategy for close ongoing information examination, we utilize an a valid example situation. This application means to recognize pictures like a given arrangement of representations from huge picture datasets in the cloud. A potential utilize instance of this application could be to discover a tyke detailed missing in a swarmed stop by recognizing pictures containing highlights like the given representations of this youngster (e.g., by his/her folks) from pictures taken and transferred by sightseers of that stop in the previous couple of hours. The method of reasoning for this is triple. Initially, this application has the solid prerequisites for close continuous handling, for which long question inactivity will seriously debilitate the esteem/worth of the outcomes. Second, to offer quick question execution, a proficient information structure, as opposed to a
basic list structure is required for the huge picture store to encourage semantic gathering and tight the question scope. Third, because of the post-check property, e.g., results will be confirmed by the missing youngster's folks or gatekeepers, this utilization case is tolerant to little false outcomes, which exchanges for essentially expanded inquiry proficiency.
4.1 Results and Analysis
Fig. 3 demonstrates the normal question inertness. The question inertness incorporates the calculation time of descriptors, e.g., picture inclinations and SIFT, as depicted in Section 3.3. We look at inquiry execution as a component of the quantity of synchronous solicitations from 1,000 to 5,000 with an augmentation of 1,000. The inertness of PCA-SIFT, at 2 min, is one request of size superior to SIFT's 35.8 min, because of its PCA property. In any case, SIFT and PCA-SIFT depend on beast constrain like coordinating to recognize comparable highlights that are then put away into a SQL-based database. Their space wastefulness causes visit circle I/Os, prompting long question inertness. We likewise watch that RNPE performs better when the quantity of question
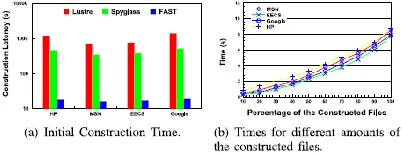
demands is littler (e.g., littler than 1,000) however its execution corrupts recognizably, as the quantity of inquiry demands increments, to as long as 55 s. This is on account of the high-intricacy MNPG recognizable proof calculation and the R-tree based Oðlog nþ question unpredictability of RNPE [39]. The question inertness of FAST is substantially shorter than any of alternate plans and remains generally at 102.6 ms for all datasets and quantities of inquiries, making FAST more than 3 requests of extent quicker than PCA-SIFT and 2 requests of greatness speedier than RNPE.
The explanations behind FAST's leverage are triple. To start with, FAST use main parts investigation for dimensionality lessening and acquires conservative element vectors. The quantity of measurements to be handled is significantly decreased, which thus brings down the space overhead. Second, the Bloom channel based rundown additionally improves the portrayal of highlight vectors, which enables us to put more vectors into the principle memory. Third, FAST uses cuckoo hashing level organized tending to get Oð1þ continuous inquiry execution.
4.1.1 Rehash Probability
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 568
happen. All the more particularly, repeating is required in FAST when an unending circle shapes in the recursive cuckoo hashing process amid the thing addition operation, which thus renders the inclusion operation a disappointment. At the end of the day, go over likelihood is equivalent to the disappointment likelihood of the inclusion operation in FAST. Attributable to the level organized cuckoo hashing plan utilized, in any case, FAST can fundamentally lessen the reiterating likelihood from that of the standard cuckoo hashing. To assess FAST for its repeat likelihood and contrast it and the standard cuckoo hashing, we exhibit the exploratory outcomes by plotting the addition disappointment likelihood as a component of the quantity of things embedded in Fig. 4. The normal disappointment likelihood of FAST is 3 requests of greatness littler than that of the standard cuckoo hashing.
We have two perceptions from the outcomes. To begin with, contrasted and lump based transmission conspire, FAST can accomplish more than 55.2 percent transfer speed investment funds because of the essentially diminished measure of pictures to be transmitted.
Second, we watch that the level of data transfer capacity investment funds will increment with the expanding number of pictures. This is on the grounds that with more pictures there is a higher likelihood of pictures being comparable. These outcomes additionally show the adaptability of FAST.
To gauge vitality utilization, we utilize the Monsoon Power Monitor [41] and run the investigations of transferring and sharing the intrigued pictures. The Monsoon Power Monitor is designed by obstructing the positive terminalon the telephone's battery with electrical tape. The voltage typically provided by the battery is provided by the screen. It records voltage and current with a specimen rate of 6 kHz. Amid our trials, the screen is set to remain in the wakeful mode with steady splendor furthermore, auto-pivot screen off. All radio correspondence is crippled aside from Wi-Fi.
Fig. 5b demonstrates the vitality utilization with the increasein the quantity of the transmitted pictures. We watch that, contrasted and the piece based transmission conspire, the FAST plan can accomplish from 46.9 to 62.2 percent vitality reserve funds in the three client bunches because of the altogether diminished quantities of the pictures to be transmitted. In addition, the level of vitality reserve funds is steady with that of data transfer capacity reserve funds since less transmitted pictures devour less vitality. These outcomes demonstrate that FAST offers a vitality sparing advantage to some cell phone applications.
Those of write operations are respectively 0.667 million and 9.1 GB.
5 RELATED WORK
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 569
proposed, which incorporates an investigation motor for separating occurrences of client determined conduct models. ISABELAQA [48] is a parallel inquiry handling motor that is composed and upgraded for breaking down and preparing spatiotemporal, multivariate logical information. MixApart [49] utilizes an incorporated information reserving and planning answer for enable MapReduce calculations to investigate information put away on big business stockpiling frameworks. The frontend reserving layer empowers the nearby stockpiling execution required by information investigation. The mutual stockpiling back-end disentangles information administration. Three regular investigation procedures [50], including topological investigation, engaging insights, and representation, are investigated to help productive information development between in-situ and in-travel calculations. In this specific circumstance, FAST is a valuable apparatus that supplements and enhances the current plans to get connected liking from close copy pictures and execute semantic gathering to help quick question benefit.
Accessible document frameworks. Spyglass [22] misuses the region of record namespace and skewed dispersion of metadata to delineate namespace chain of importance into a multi-dimensional K-D tree and uses multilevel forming and apportioning to keep up consistency. Look [46], an in the nick of time testing based framework, can give exact responses to total and best k questions without earlier information. SmartStore [23] utilizes idle semantic ordering (LSI) instrument [51], [52] to total semantically corresponded records into gatherings and bolster complex inquiries. Ceph [53] and its exhibit framework [54] utilize dynamic subtree parcel to evade metadata-get to hot spots and bolster filename-based question. FastQuery [55] is a programming structure that uses a FastBit based record and inquiry innovation to process gigantic datasets on present day supercomputing stages. Region Sensitive Bloom Filter [56] proposes a region mindful and space-productive information structure that can effectively bolster the in-memory processing. SciHadoop [57] executes inquiries as guide/lessen programs characterized over the intelligent information model to lessen
add up to information exchanges, remote peruses, and superfluous peruses. Dissimilar to these methodologies,
FAST offers the notable highlights of questioning close copy pictures in a close constant way.
Deduplication based repetition location. DDFS [58] proposes exploiting the reinforcement stream territory to lessen arrange transmission capacity and gets to on-plate file. Extraordinary Binning [59] misuses the document similitude for deduplication also, can be connected to non-conventional reinforcement workloads with low-region (e.g., incremental reinforcement). ChunkStash [32] keeps up the piece fingerprints in a SSD rather than a hard plate to quicken the queries. Storehouse [60] is a close correct deduplication framework that endeavors both comparability what's more, region to accomplish high copy disposal and throughput with low RAM overheads. The group based deduplication [61] looks at the tradeoffs between stateless information directing methodologies with low overhead and stateful approaches with high overhead yet having the capacity to dodge awkward nature. Meager Indexing [62] abuses the natural reinforcement stream region to understand the file query bottleneck issue. In addition, by abusing similitudes between documents or, on the other hand forms of a similar record, LBFS [63] is appeared to be a lowbandwidth arrange document framework. The capability of information deduplication in HPC focuses is exhibited in [64] by means of quantitative examination on the potential for limit lessening for 4 information.
6 CONCLUSION
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 570 REFERENCES
[1] M. Armbrust, A. Fox, R. Griffith, A. D. Joseph, R. Katz, A. Konwinski, G. Lee, D. Patterson, A. Rabkin, I. Stoica, and M. Zaharia, "A perspective of distributed computing," Commun. ACM, vol. 53, no. 4, pp. 50– 58, 2010.
[2] A. Marathe, R. Harris, D. K. Lowenthal, B. R. de Supinski, B. Rountree, M. Schulz, and X. Yuan, "A near investigation of highperformance figuring on the cloud," in Proc. 22nd Int. Symp. High-Perform. Parallel Distrib. Comput., 2013, pp. 239– 250.
[3] P. Nath, B. Urgaonkar, and A. Sivasubramaniam, "Assessing the value of substance addressable capacity for elite information concentrated applications," in Proc. seventeenth Int. Symp. High-Perform.
Parallel Distrib. Comput., 2008, pp. 35– 44.
[4] Gartner, Inc., "Figure: Consumer computerized capacity needs, 2010– 2016," 2012.
[5] Storage Newsletter, "7% of purchaser content in distributed storage in 2011, 36% out of 2016," 2012.
[6] J. Gantz and D. Reinsel, "The advanced universe in 2020: Big information, greater advanced shadows, and greatest development in the far east," International Information Corporation (IDC) iView, Dec. 2012.
[7] Y. Hua, W. He, X. Liu, and D. Feng, "SmartEye: Real-time and effective cloud picture sharing for catastrophe situations," in Proc. INFOCOM, 2015, pp. 1616– 1624.
[8] Y. Ke and R. Sukthankar, "PCA-SIFT: A more particular portrayal for nearby picture descriptors," in Proc. IEEE Conf. Comput.
Vis. Example Recog., 2004, pp. 506– 513.
[9] Y. Ke, R. Sukthankar, and L. Huston, "Effective close copy recognition and sub-picture recovery," in Proc. ACM Multimedia, 2004, pp. 869– 876.
[10] J. Liu, Z. Huang, H. T. Shen, H. Cheng, and Y. Chen, "Displaying assorted area sees with ongoing close copy photograph end," in Proc. 29th Int. Conf. Information Eng., 2013, pp. 505– 56.
[11] D. Zhan, H. Jiang, and S. C. Seth, "CLU: Co-enhancing region and utility in string mindful limit administration for shared last level stores," IEEE Trans. Comput., vol. 63, no. 7, pp. 1656– 1667, Jul. 2014.
[12] P. Indyk and R. Motwani, "Estimated closest neighbors: towards evacuating the scourge of dimensionality," in Proc. thirteenth Annu. ACM Symp. Hypothesis Comput., 1998, pp. 604– 613.
[13] R. Pagh and F. Rodler, "Cuckoo hashing," in Proc. Eur. Symp. Calculations, 2001, pp. 121– 133.
[14] Y. Hua, H. Jiang, Y. Zhu, D. Feng, and L. Xu, "Normal: Semanticaware namespace in ultra-substantial scale document frameworks," IEEE Trans. Parallel Distrib. Syst., vol. 25, no. 5, pp. 1328– 1338, May 2014.