Part-of-speech Sequences and Distribution in a
Learner Corpus of English
Rebecca H. Shih
*, John Y. Chiang
+and F. Tien
+*
Department of Foreign Languages and Literature
+
Department of Computer Science and Engineering,
National Sun Yat-sen University
Page 171 ~ 177
Proceedings of
Research on Computational Linguistics
Conference XIII (ROCLING XIII)
Part-of-speech Sequences and Distribution
in a Learner Corpus of English
Rebecca H. Shih*, John Y. Chiang+ and F. Tien+
*Department of Foreign Languages and Literature +Department of Computer Science and Engineering
National Sun Yat-sen University, Kaohsiung,Taiwan, R.O.C. E-mail: [email protected]
Abstract
Computer learner corpora have been widely used by SLA/EFL specialists since mid 1990s to gain better insights into authentic learner language. The work presented in this paper examines the inter-language of Taiwanese learners of English from a part-of-speech sequence perspective. Two pre-tagged corpora (one learner corpus and one native corpus) are involved in this work. The experimental results indicate that there are more than one third of eligible POS trigrams that are never practiced by the Taiwanese learners in their writing and the learners have stronger preference than native speakers in using pronouns, especially right after punctuations, verbs and conjunctions.
1. Introduction
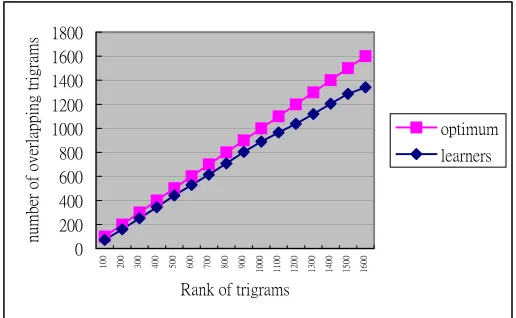
BNC TLCE overlap
100 200 300 400 500 600 700 800 900 1000 1100 1200 1300 1400 1500 1600
Rank of trigrams
number of overlapping trigrams
4. Discussions and future work
The results of the preliminary experiments above show that there are more than one third of BNC trigrams that the learners never practice in their writing, whereas there are 4.5% of TLCE trigrams which do not appear in the BNC’s. It is intended to believe that this small proportion of TLCE trigrams is contributed from the learner’s writing errors. However, increasing the size of the native speaker corpus to observe any changes in the distribution of the trigrams will clarify the findings. It is also worth looking into those BNC trigrams that the learners do not know or are not aware of, and then isolating those with high frequency for the pedagogical purpose.
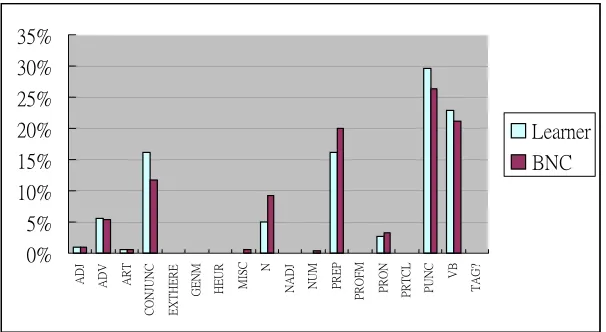
The experimental results also suggest that the learners use pronouns excessively in their writing and that they have stronger preference than native speakers in using pronouns right after punctuations, verbs and conjunctions but less preference after prepositions and nouns. Pronouns often appear in the informal register, and as the corpus is composed of college students’ compositions as well as their weekly journals, the informality of the journals may contribute partly to their excessive use of pronouns. So, it is desirable in the next stage of the work to divide the learner corpus in terms of its different registers and compare their POS distributions with the native speaker corpus.
Acknowledgements