More Efficient Cryptosystems From
k
th-Power Residues
?Zhenfu Cao1, Xiaolei Dong1, Licheng Wang2, and Jun Shao3
1
Department of Computer Science and Engineering, Shanghai Jiaotong University 2
State Key Laboratory of Networking and Switching Technology, Beijing University of Posts and Telecommunications 3
School of Computer and Information Engineering, Zhejiang Gongshang University
{zfcao,dong-xl}@cs.sjtu.edu.cn, [email protected], [email protected]
Abstract. At Eurocrypt 2013, Joye and Libert proposed a method for constructing public key cryptosystems (PKCs) and lossy trapdoor functions (LTDFs) from(2α)th-power residue symbols. Their work can be viewed as non-trivial extensions of the well-known PKC scheme due to Goldwasser and Micali, and the LTDF scheme due to Freeman et al., respectively. In this paper, we will demonstrate that this kind of work can be extendedmore generally: all related constructions can work for anykth
-power residues ifkonly contains small prime factors, instead of(2α)th-power residues only. The resultant PKCs and LTDFs are more efficient than that from Joye-Libert method in terms of decryption speed with the same message length.
Keywords:Goldwasser-Micali cryptosystem, kth-power residuosity,k-residue discrete logarithm, ad-ditive homomorphism, lossy trapdoor function
1 Introduction
Public key cryptosystem (PKC) is one of fundamental building blocks for securing digital communications. Many public key encryption schemes have been proposed so far [31,18,4,15,8,22,16,13]; however, it is fair to say that they can be classified into several main categories, such as the ElGamal-type [18,15,8,16,13], the RSA-type [31,4,8,22], the GM-type [20,23], and others [2,26,17,25,28]. Most of the first two types of cryptosystems focus on how to enhance the security or enrich the properties of original cryptosystem, while most of the third type of cryptosystems focus on how to improve the effectiveness and efficiency of the original cryptosystem.
At Eurocrypt 2013, Joye and Libert [23] proposed a very natural generalization of the GM cryptosys-tem, while it results in the most efficient GM-type cryptosystem in terms of bandwidth (i.e., the cipher-text length) and decryption speed. Specially, the GM cryptosystem uses quadratic residue symbols w.r.t. modulus n, while the Joye-Libert cryptosystem makes use of(2α)th-power residue symbols w.r.t. modu-lusn. The bandwidth and the time complexity of decryption of the Joye-Libert cryptosystem arelognand
O(α(logn)2(log logn)), respectively.
In this paper, we propose several new GM-type cryptosystems that take advantages ofkth-power residue symbols, wherek =pα1
1 · · ·pαss (2 ≤ p1 <· · · < ps) only contains small prime factors. Surprisingly, our proposal is more efficient than the Joye-Libert cryptosystem in terms of decryption speed. In particular, the time complexity of decryption in our proposal can be approximately reduced toO(α0(logn)2(log logn)), whereα0 = Ps
iαi in general is observably less than α with the similar scales of message space and ci-phertext space. Our proposal inherits the additive homomorphism property of the GM cryptosystem, which allows the additively homomorphic operation on larger messages while keeping the same efficiency. Hence, our proposal also yields efficient lossy trapdoor functions, even with better lossiness and faster inversion algorithm compared to the Joye-Libert constructions.
?This work was supported by the National Natural Science Foundation of China (NSFC) (nos. 61033014, 61371083, 61373154,
1.1 Related Work
At STOC 1982, Goldwasser and Micali proposed the first probabilistic key encryption scheme [20]. It is quite simple and elegant. The public key and private key are{n, a}andp, respectively. Here,nis an RSA modulusn=p·q, andais a non-square inJn,2(i.e., the set of elements inZ∗nwhose Jacobi symbol is 1). For an`-bit messagem, it is encrypted bit by bit. That is, the ciphertext is(c1,· · ·, c`)whereci =hamix2iinfor some randomxi ∈Zn. Accordingly, the message is recovered bit by bit: Ifciis a quadratic residue modulo p, then mi = 0; otherwise, mi = 1. The ciphertext is`lognbits in length, and the time complexities of encryption and decryption are bothO(`(logn)2). These results suggest that the GM cryptosystem is efficient in encryption and decryption, while it is inefficient in bandwidth utilization. Several proposals were made to address this issue.
Short afterwards (at CRYPTO 1984), by using the Blum-Blum-Shub pseudorandom generator [5,6], Blum and Goldwasser [7] proposed another efficient probabilistic encryption scheme that achieves a smaller bandwidth in`+ lognbits, and a smaller time complexity of encryptionO(`(loglog logn)n2). As mentioned in [7],
the decryption time complexity of the Blum-Goldwasser cryptosystem isO((logn)3) +O(`(loglog logn)n2), and it is slightly faster than schemes RSA [31] and Rabin [30] when` >logn.
During 1988 to 1990, Cao [9,10,11] proposed two types of extensions of the GM cryptosystem. One is based on the cubic residue in ringZ[ω]that allows 3-adic encoding. It results in an even fast decryption
with the same length message. The other extension is based on thekth-power residues that enables segment encryption instead of bit encryption in the GM cryptosystem. The concept of indistinguishability due to Goldwasser and Micali is also extended to k-indistinguishability in these work (it is also summarized in [12]).
Four years later (at STOC 1994), Benaloh and Tuinstra [3] makes another extension on the GM cryp-tosystem. Their cryptosystem sets the public key as a triple{n, k, a}such thatnis still an RSA modulus n=p·q,kis a prime,k|φ(n),k2-p−1,a∈Znandaφ(n)/k 6≡1 (mod n), whereφ(n)is Euler’s totient function. The encryption of a message m with `-bit length but smaller thank is given by c = hamxkin for a randomx ∈ Zn. Clearly, the encryption time complexity is O((logn)2(log logn))considering that the encryption cost is mainly occupied by two modular exponentiations. The most promising feature of the Benaloh-Tuinstra cryptosystem is that the bandwidth is reduced tolognbits. However, the decryption re-quires searching over the entire message space[0, k)for locatingmsuch thatam·φ(n)/k ≡cφ(n)/k (modn)
holds. Thus, the scheme is in practice limited to shortk, say no longer than40bits [23].
Another four years later (at CCS 1998), Naccache and Stern [27] further improved the GM cryptosystem along the line of the Benaloh-Tuinstra cryptosystem. The public key is still{n, k, a}, and onlykhas different properties. That is,kis a product of small (odd) primesk = Q
pi such thatpi|φ(n)andp2i -φ(n). With the new properties ofk, the messagemis recovered fromm≡mi (modpi)through Chinese Remainder Theorem (CRT). It results in that the size of message space could be as large asQ
pi, while the size of searching space is onlyP
pi. However, the conditionp2i -φ(n)makes its message space cannot be further enlarged.
Most recently (at EUROCRYPT 2013), Joye and Libert [23] made a further improvement on the Naccache-Stern cryptosystem by settingk= 2α. But the newly conceived decryption algorithm can be efficiently fin-ished by a bit-by-bit manner. The time complexities of encryption and decryption areO((logn)2(log logn))
1.2 Our Contribution
In this paper, we make a further extension on Goldwasser and Micali’s work and obtain several cryptosys-tems (including three main cryptosyscryptosys-tems, denoted by V0, V1 andV2 respectively) that are more efficient than other GM-type cryptosystems. The main idea is to setkas a product ofpowersof small primes, and coupling with a fast decryption algorithm for recoveringk-residue discrete logarithm (See Definition 4). To prove the security of our proposal, we introduce two assumptions. One is thekth-power residuosity (kth -PR) assumption: given an elementx ∈Z∗nsuch that the generalized Jacobi symbol (see Definition 3) is 1, no probabilistic polynomial time (PPT) adversary can decide whetherxis akth-power residue or not. The other is the strongkth-power residuosity (kth-SPR) assumption: given an elementx∈Z∗n, no PPT adversary can decide whetherxis akth-power residue or not. Our proposal is a generalized framework in the sense that it can be instantiated to the GM cryptosystem, the Benaloh-Tuinstra cryptosystem, the Naccache-Stern cryptosystem and the Joye-Libert cryptosystem with different choices ofk. In brief, the highlights of our proposal are summarized as follows.
– Efficient in encryption and bandwidth. The encryption time complexity and the bandwidth of our pro-posal areO((logn)2(log logn))andlognbits, respectively. These features are as good as that in the Benaloh-Tuinstra cryptosystem, the Naccache-Stern cryptosystem and the Joye-Libert cryptosystem.
– Lower ciphertext expansion factor. With the same length of modulusn, the ciphertext expansion factor of schemeV2is about 2 under some reasonable setting onk. This feature is better than all aforementioned GM-type cryptosystems.
– Large message space. It would be good if the message space could be enlarged with the same ciphertext space while keeping the efficiency in encryption and decryption. When k = Q
pαi
i with thatpi’s are small primes, andαi’s are positive integers, the messagemin our proposal is reconstructed frommi ≡ m (modpαi
i ) through CRT like the Naccache-Stern cryptosystem does. However, the space ofmi is enlarged from[0, pi−1)to[0, pαii−1)without increasing the searching space.
– Faster in decryption. The decryption time complexity of our proposal isO(α0(logn)2(log logn)), where α0 = P
αi under the settingk = Qpαii with small distinct primespi and positiveαi (i = 1,· · · , s). Compared with the Joye-Libert cryptosystem, our schemes can decrypt even faster in practice. The reason is that the time complexity of decryption in our proposal is mainly occupied byα0, which is in general observably smaller thanαin the Joye-Libert cryptosystem, under the condition2α ≈Q
pαi
i (i.e., the roughly equal size of message space). This advantage is manifested by intensive tests (See Section 5.2).
– Additively homomorphic over large message space. Our proposal admits additive homomorphism over large message space. In particular, schemeV2 can also yields an efficient lossy trapdoor function with even better lossiness and faster inversion algorithm compared to the Joye-Libert constructions.
2 Background
In this section, we review some definitions related to our proposal, and introduce the notations in our paper. In particular, we review the definitions and theorems related tokth-power residuosity, generalized Legendre symbol, and generalized Jacobi symbol. We also define thek-residue discrete logarithm problem.
For simplicity, we would like to firstly introduce the notations used in the rest of this paper in Table 1.
Definition 1 (kth-Power Residuosity).For any positive integerskandn, we say that an integerb∈Z∗nis
akth-power residue w.r.t. modulusnif and only if the following congruent equation has solution(s)
Table 1.Notations used in this paper
Notation Description
Zn the set of non-negative minimal residues w.r.t. modulusn, i.e.,{0,1,· · ·, n−1}
hxin xmodn, result in a non-negative minimal residue
(x)n xmodn, result in an absolute minimal residue
(a, b) the greatest common divisor ofaandb [a, b] the least common multiple ofaandb
Z∗n the multiplication group w.r.t. modulusn, i.e.,{a∈Zn|(a, n) = 1}
ordn(a) a’s order w.r.t. modulusn
a p
k
a’s generalized Legendre symbol w.r.t modulusp(see Definition 2)
J(i)p,k the set of elementsa∈Z ∗
psuch that
a p
k
=ωp,i
p
k
(see Theorem 2) a
n
k a’s generalized Jacobi symbol w.r.t modulusn(see Definition 3)
Jn,k the set of elementsa∈Z∗nsuch that an
k= 1,Jn,k=Rn,k∪NRn,k
Rn,k the set ofkth-power residues w.r.t. modulus n, i.e.,{(xk)n|x∈Z∗n}
NRn,k the set ofkth-power non-residues inJn,k, i.e.,Jn,k\Rn,k
logx the logarithm ofxw.r.t. the base 2, i.e.,log2x
Accordingly, if Equation (1) has no solution, we saybis akth-power non-residue w.r.t. modulusn. ut
Theorem 1 (Existence of kth-Power Residuosity ). [12, Theorem 4.1, page 55] For any prime p and integern = pα or n = 2pα, an integer b ∈ Z∗n is a kth-power residue w.r.t. modulus n if and only if
b
φ(n)
(k,φ(n)) ≡1 (modn), whereφ(n)is Euler totient function. ut
Definition 2 (Generalized Legendre Symbol). For any integersa, k and primep such thatk|p−1and (a, p) = 1, the generalized Legendre symbol (GLS) is defined by
a p k =
ap−1k
p. (2)
u t
From Definition 2, it is easy to deduce that ifa ≡ b (modp), then
a p k = b p
k, and that GLS is multiplicative for any integersa, bsuch that(a, p) = (b, p) = 1, i.e.,
ab p k ≡ a p k b p k
(modp). (3)
Theorem 2 (Number of GLS).[12,24] There are exactlykdistinct generalized Legendre symbols, includ-ing 1, and there arek distinct elements ωp,0,· · · , ωp,k−1 ∈ Z∗p such that
ω p,0
p
k = 1and
ω p,i p k 6= ω p,j p
k (i
6=j). ut
Definition 3 (Generalized Jacobi Symbol).For integersa, k, n, wheren = pqwith two primespandq,
k|p−1,k|q−1and(a, n) = 1, the generalized Jacobi symbol (GJS) is defined by
Lemma 1 (Properties ofR,Jand NR).For arbitrary integersa, k and two primes p, qsuch that k|p−
1, k|q−1, we have
(1) Rp,k=Jp,k.
(2) |Rp,k|= p−k1.
(3) a∈Rpq,k⇔(a)p ∈Rp,kand(a)q∈Rq,k.
(4) a∈NRpq,k⇔(a)p ∈NRp,kand(a)q∈NRq,k.
Proof. Properties (1), (3) and (4) are apparently according to definitions on the related notions.1 So, let us prove property (2). The basic idea can be find in [24]. Suppose that g is one of p’s primitive roots, then when p - a, we have that xk ≡ a (modp) has a solution if and only if k = (k, p−1)|indg(a), whereindg(a)denotesa’s index (i.e., discrete logarithm) w.r.t. basegand modulusp. Thus, forindg(a) = k,2k,· · ·,p−k1·k,
gk, g2k, · · ·, gp−1k k (5)
are exactly allkth-power residues w.r.t. the modulusp. From expression (5), we can see that each number is distinct in the sense of taking modulop. Thus, property (2) holds. ut
Definition 4 (k-Residue Discrete Logarithm, k-RDL).For primep and two positive integers b, k such thatk|p−1andordp(b) =k, thek-discrete logarithm problem is to findx(0 ≤x < k) satisfyingbx ≡y
(modp)for a given integery ∈Z∗p. We callxasy’sk-discrete logarithm w.r.t. baseband modulusp. When kcontains only small prime factors, we callxasy’sk-residue discrete logarithm (k-RDL) w.r.t. baseband modulusp, denoted asx=RDLkb,p(y).
We will show that thek-RDL problem can be solved effectively and efficiently in Section 3.4. This fact is the base of our subsequent construction.
3 New PKC Schemes Fromkth-Power Residues
In this section, we further generalize the Joye-Libert cryptosystem by presenting two main schemes.
3.1 SchemeV0
Our first construction, denoted byV0, consists of the following three algorithms.
KeyGen: On inputting the security parameterκ,KeyGenoutputs the public keypk={n, k, a}and private keysk={p, q}, where
– n=p·q,p=k·p0+ 1,q =k·q0+ 1, and(k, p0q0) = 1;
– p, qare big primes, whilekis a product of small primes;
– p0, q0 both contain big prime factors.
– ais chosen at random fromZ∗nsuch thatordp(a) = ordq(a) =k(See the details on how to choose ain Section 3.3).
Enc: On inputting a messagem∈Zk, the encryptor selectsx∈Z∗nat random and outputs the ciphertext
c=hamxkin. (6)
1
Note that whenkis odd,NRpq,k=NRp,k=NRq,k=∅since in this case for anyainZ∗p(resp.Z∗q), we have that
a p
k
6
=−1
(resp.
a q
k6
Dec: On inputting a ciphertextc∈Z∗
n, the decryptor knowingpcan obtain the message as follows. 1. Computeb=
a p
k, which actually can be pre-computed. 2. Computey=cp
k.
3. Recover the messagem=RDLk
b,p(y)by using the method in Section 3.4.
Correctness At first, let us prove thatordp(b) =k, whereb=
a p
kis specified by the decryption process. Froma’s order iskand
1≡bordp(b)≡ap−1k ordp(b) (mod p),
we have thatk|p−k1ordp(b). Since(k,p−k1) = 1, we have thatk|ordp(b). On the other hand, it is easy to
verify thatbk ≡ ap−1k k ≡ 1 (modp). Thus,ordp(b)|k. Therefore, ordp(b) =k. Next, from Equation (7),
we can easily obtain the correctness of our proposal.
y≡
c p
k
≡
am p
k
xk p
k
≡
a p
m
k
≡bm (modp) (7)
Remark 1. Recall that Shor’s quantum algorithm [32] for factoringnconsists of the following classical step: If for some random elementa∈Z∗n,ordn(a) = kis even, then(ak/2±1, n)might be a non-trivial factor ofn. However, if we chooseasuch thatordp(a) =kandordq(a) =khold simultaneously, then even ifk is even, this will not lead to the factorization ofn. In fact, in this case we haven|ak/2+ 1,p-ak/2−1and
q-ak/2−1. That is,(ak/2±1, n)must be 1 orn.
Remark 2. In fact, scheme V0 still works well ifordp(a) = ordq(a) = t·k for some positive integert containing only small prime factors. Moreover, the method in Section 3.3 for generatingawith condition
ordp(a) = ordq(a) =kcan also work well for generatingawith conditionordp(a) = ordq(a) =t·k. The only thing we need to do is to viewt·kas a newk0and call Algorithm 2 with input(p, q, k0, k0)to get the requireda.
It is worth to mention that when both t and k only contain small prime factors, we further require
ordp(a) = ordq(a). If not, the following attack would work: Assume that all the prime factors oftandk are belong to{pi1,· · ·, pimax}, and the maximum exponent of the prime factor oftandkisαmax, then one
can find factorization ofnby computing(ap
j i1·...·p
j
imax −1, n)forj∈ {1,· · · , α
max}.
3.2 SchemeV1
Our second construction, denoted byV1, consists of the following three algorithms.
KeyGen: On inputting the security parameterκ,KeyGenoutputs the public keypk={n, k, a}and private keysk={p, q}, where
– n=p·q,p=k·p0+ 1,q =k·q0+ 1, and(k, p0q0) = 1;
– p, qare big primes, whilekis a product of small primes;
– p0, q0 both contain big prime factors.
– ais a primitive root w.r.t. the modulusp.
Enc: On inputting a messagem∈Zk, the encryptor selectsx∈Z∗nat random and outputs the ciphertext
Dec: On inputting a ciphertextc∈Z∗
n, the decryptor knowingpcan obtain the message as follows. 1. Computeb=ap
k, which actually can be pre-computed. 2. Computey=cp
k.
3. Recover the messagem=RDLkb,p(y)by using the method in Section 3.4.
Correctness The only difference between schemeV0 and schemeV1lies in the methods of choosinga. To prove the correctness ofV1, we only need to prove thatordp(b) = kstill holds. At first, it is easy to verify thatbk ≡ ap−1k k ≡1 (mod p), thusordp(b)|k. Next, if there isk0|k(k0 < k) such thatbk
0
≡ 1 (modp), then we have thataδ ≡ 1 (modp) forδ = k/kp−10 < p−1. This is contrary to the fact thatais a primitive
root w.r.t. the modulusp. Therefore,b’s order w.r.t. to the moduluspis exactlyk.
Remark 3. SchemeV1 still works well ifordp(a) = t·kfor some positive integertcontaining one large prime factor at least. In addition, Algorithm 1 in Section 3.3 for generatingawith conditionordp(a) = k can also work well for generatingawith conditionordp(a) =t·k. It is also worth to mention that scheme V1can resist the attack described in Remark 2 sincetcontains one large prime factor at least.
Remark 4. We notice that the cases k = 2and k = 2α (α ≥ 1) are roughly corresponding to the GM cryptosystem and the Joye-Libert cryptosystem, respectively. The only subtle difference is the choice ofa. In particular,ais not explicitly selected fromNRn,k in our proposal. Actually, Joye and Libert’s idea for proving thatordp
a p
2α
= 2α (whena ∈ NRn,2) cannot be easily extended to the case ofk > 2or
the case thatkonly contains small prime factors. Fortunately, we evade this obstacle by presenting different methods for choosinga.
3.3 Methods for Choosinga
In this subsection, we will discuss the methods for choosinga. Before giving the concrete methods, we need the following lemmas at first.
Lemma 2. Foru, v∈Z∗
pfor primep, if(ordp(u),ordp(v)) = 1, thenordp(uv) = ordp(u)ordp(v).
Proof. The proof follows the idea in [12, page 123]. From(uv)ordp(uv)≡1 (mod p), we have that
((uv)ordp(uv))ordp(u)≡(uordp(u)vordp(u))ordp(uv)≡vordp(u)ordp(uv)≡1 (modp).
The above reduction shows that ordp(v)|ordp(u)ordp(uv), which leads to ordp(v)|ordp(uv). Similarly,
ordp(u)|ordp(uv)holds. Hence, we have thatordp(u)ordp(v)|ordp(uv). On the other hand,(uv)ordp(u)ordp(v)≡1 (modp)leads toord
p(uv)|ordp(u)ordp(v). Hence, we have
thatordp(uv) = ordp(u)ordp(v). ut
Lemma 3. Ifp, p0 are primes,p0α|p−1,p0α+1 -p−1,α ≥1,b
p−1
p0 6≡1 (mod p), anda=hb p−1 p0αi
p, then
we have thatordp(a) =p0α.
Proof. The proof also follows the idea in [12, page 124]. Fromap0α ≡ (b(p−1)/p0α)p0α ≡ 1 (mod p),we have thatordp(a)|p0α. On the other hand, we also haveordp(a) = p0α. If not, we have thatordp(a) =p0α
0
for someα0 < α, which leads to
1≡aordp(a) ≡(b(p−1)/p0α)ordp(a)≡b(p−1)/p0α−α 0
Raise the both sides of the above equation to the power of p0α−α0−1, we can obtain that b(p−1)/p0 ≡ 1 (modp), which is a contradiction for the condition ofb. This finishes the lemma. ut
Now, let us at first give the method for choosing a ∈ Z∗
p such that ordp(a) = k. Assume that k =
Qs
i=1p αi
i , where pi (i = 1,· · ·, s, p1 < · · · < ps) are distinct primes, and αi ≥ 1. Our main idea is to generate ai ∈ Z∗p (i = 1,· · · , s)such that ordp(ai) = pαii, and then compute a = a1 ·. . .·asmodp. According to Lemma 2, we have thatordp(a) = Qsi=1ordp(ai) = Qsi=1pαi = k. Thus, we only need to show how to chooseaisuch thatordp(ai) =piαi. In fact, we can choose randomlybifromZ∗psuch that
b
p−1 pi
i 6≡1 (modp). (9)
After that, computeai =hb
(p−1)/pαii
i ip. According to Lemma 3, we have thatordp(ai) = pαii. Piecing all above together, the algorithmic description of generation ofacan be found in Algorithm 1.
Algorithm 1Generation ofawithordp(a) =k
Input:
Primepand integerk, wherek|p−1,k=Qs i=1p
αi
i , andpi’s are distinct primes. Output:
a∈Z∗psuch thatordp(a) =k.
1: a←1;
2: forifrom 1 tosdo 3: Loop:bi
$
←−Zp; .Chooseaisuch thatordp(ai) =pαii
4: ifb(p−1)/pi
i ≡1 (modp)then
5: goto Loop; 6: end if 7: ai← hb
(p−1)/pαii
i ip;
8: a← haaiip; 9: end for 10: Outputa.
Next, let us give the method for generatinga ∈ Z∗
pq such thatordp(a) = ordq(a) = k. By using the above method, we can finda1 ∈Z∗panda2 ∈Z∗qsuch thatordp(a1) =k1andordq(a2) =k2, respectively. Then, according to CRT, froma≡a1 (mod p)anda≡a2 (modq), we can obtain
a=hM1·q·a1+M2·p·a2ipq,
whereM1andM2are positive integers such that
M1·q≡1 (modp), and M2·p≡1 (modq).
Therefore,ordp(a) = ordp(a1) =k1andordq(a) = ordq(a2) =k2. This process is detailed in Algorithm 2. In particular, whenk1 =k2 =k, we obtainaas required in schemeV0. When(k1, k2) = 1, we obtaina as required in schemeV2that will introduced later.
3.4 Solve thek-RDL Problem
Algorithm 2Generation ofawithordp(a) =k1,ordq(a) =k2
Input:
Two primesp, qand two integersk1, k2, wherek1|p−1,k2|q−1,(k1, k2) = 1,k1=Qsi=1p αi
i ,k2=Qti=1q βi
i , andpi, qi’s are distinct primes.
Output:
a∈Z∗pqsuch thatordp(a) =k1,ordq(a) =k2.
1: Geta1∈Z∗psuch thatordp(a1) =k1by calling Algorithm 1 with input(p, k1); 2: Geta2∈Z∗qsuch thatordq(a2) =k2by calling Algorithm 1 with input(q, k2); 3: M1←1/qmodp;
4: M2←1/pmodq;
5: a← hM1·q·a1+M2·p·a2ipq; 6: Outputa.
exists a solution:
y≡bm (modp). (10)
The basic idea of computingm∈Zkfollows that in [12, pages 126–128]. Assume that k = Qs
i=1p αi
i , where pi are small primes such that p1 < · · · < ps and αi ≥ 1 (i =
1,· · · , s). Our main idea is to generatemi ∈Zpαii (i= 1,· · · , s)such that
mi ≡m (modpαii), (11)
and then computem ∈Zk satisfying Equation (10) by using CRT. Therefore, the main task of computing mis to computemi(i= 1,· · ·, s) satisfying Equation (11).
Firstly, suppose thaty0=yandmi can be represented as
mi =mi,0+mi,1·pi+· · ·+mi,αi−1·p
αi−1
i . (12)
Then from Equation (11), we have that
y0 p
pαii
≡
bmi
p
pαii
≡
b p
mi
pαii
(modp). (13)
Raise the both sides of Equation (13) to the power ofpαi−1
i , we have that
y
p−1 pi
0 ≡b
p−1
pi ·mi ≡b
p−1
pi ·(mi,0+mi,1·pi+···+mi,αi−1·p αi−1
i )≡b
p−1
pi ·mi,0 (modp). (14)
We can determinemi,0by searching it in{0,1,· · ·, pi−1}. This is quite efficient sincepiis small. Next, sety1 =hy0·b−mi,0ip. Similar with Equation (14), we have that
y
p−1 p2
i
1 ≡b
p−1 p2
i
(mi,1pi+···+mi,αi−1pαi −1
i )
≡b
p−1
pi ·mi,1 (modp). (15)
Again, we can determinemi,1 by searching it in{0,1,· · ·, pi−1}. Similarly, we can determinemi,j for
(j = 2,· · · , αi−1)iteratively, and finally recovermiaccording to Equation (12).
The above process of computing mi can be improved. Notice thathb
p−1 pi ·`ii
p (`i = 0,· · ·, pi −1) is independent withmi, we can pre-compute and store them in a tableTi. Then, after obtaininghy
we can look up it in the tableTito determinemi,j(j= 0,1,· · ·, αi−1) directly, without further exponen-tiation calculation. If necessary, we can further employ the hash table technique suggested in [27] to reduce the cost for storing and searching inTi.
The algorithmic description of solvingk-RDL problem can be found in Algorithm 3.
Algorithm 3Fast Solution ofk-RDL Problem
Input:
Prime modulusp, baseb, and integerk, whereordp(b) =k,k|p−1,k=Qsi=1p αi
i , andpi’s are small distinct primes. Integery∈Zp
Output:
m∈Zksuch thatbm≡y (modp)
1: forifrom 1 tosdo
2: βi,0←1; .Pre-computing, constructTi
3: βi,1,← hb
p−1
pi ip;
4: Ti← {βi,0, βi,1}; 5: for`ifrom 2 topi−1do 6: βi,`i =hβi,1·βi,`i−1ip;
7: Ti←Ti∪ {βi,`i};
8: end for 9: end for
10: forifrom 1 tosdo 11: mi←0;y0←y; 12: P0←1;P1←pi; 13: forjfrom 0 toαi−1do 14: t← hy(p−1)/P1
j ip;
15: locatet=βi,`iin TableTi; .Searching inTi
16: mi,j←`i; 17: P0 ←mi,jP0;
18: mi←mi+P0; .Reconstructmi
19: yj+1← hyjb−P0ip; 20: P0 ←P1;
21: P1 ←P1·pi; 22: end for
23: end for
24: m←CRT(m1, pα11;· · ·;ms, pαss); .Reconstructm
25: Outputm.
4 Security Proofs
In this section, we will give the security analysis of our proposal in two parts. In the first part, we obtain the semantic security under a weak assumption but with restrictions on the prime factors ofk. In particular, we prove that our proposal is semantically secure under thekth-PR assumption, whilekshould satisfy that k = 2αQs
i=1p αi
4.1 Security Under thekth-PR Assumption
Before giving the security analysis, we would like to introduce thekth-power residuosity (kth-PR) assump-tion and some basic results related to thekth-PR assumption.
Definition 5 (kth-Power Residuosity (kth-PR) Assumption). Let n = pq be the product of two large primesp andq withk|p−1 andk|q −1. Thekth-power residuosity problem in Z∗nis to distinguish the
following two distributions
D0 ={x:x $
←−NRn,k} and D1 ={x:x $
←−Rn,k}. (16)
Thekth-power residuosity assumption posits that, without knowing the factorization of n, the advantage
AdvkAth−P R(1κ) of any PPTkth-power residuosity distinguisher A defined as follows is negligible with respect to the system security parameterκ,
AdvkAth−P R(1κ) =|Pr[A(x, k, n) = 1|x←NRn,k]−Pr[A(x, k, n) = 1|x←Rn,k]|
where probabilities are taken over all coin tosses.
Theorem 3. Letk= 2αQs
i=1p αi
i andk0 = 2
Qs
i=1pi, whereα = max{α1,· · ·, αs}, andpi’s are distinct
small odd primes. Then, we have that the kth-PR assumption implies thek0th-PR assumption. More pre-cisely, for any PPTk0th-power residuosity distinguisherAwith advantage0, there exists a PPTkth-power residuosity distinguisherBwith advantagesuch that0 ≤ 4p2s·α
s .
The proof of this theorem is not as easy as it may seem. We shall postpone the proof until we have established a few preliminary lemmas. In this subsection, we implicitly contains n, p, q, k in all the parts related tokth-PR assumption, and they remain the same.
Lemma 4. Lett = (2·pi)αi andt0 = 2·pi for some small odd primepi, then we have that thetth-PR
assumption implies thet0th-PR assumption. More precisely, for any PPTt0th-power residuosity distinguisher Awith advantage0, there exists a PPTtth-power residuosity distinguisher Bwith advantagesuch that
0≤ 4p2s·α
s . In other words, define a series of sets as
D(i)j ={(x(2pi)j)
n:x∈NRn,2pi} (j= 0,· · · , αi−1). (17)
We have that if(2pi)th-PR assumption holds, then elements sampled randomly and uniformly from the set D(i)j are computationally indistinguishable from elements sampled randomly and uniformly fromRn,(2pi)αi for allj∈ {0,1,· · · , αi−1}. That is,
D0(i)≈c D1(i)≈ · · ·c ≈c D(i)αi−1≈c Rn,(2pi)αi. (18)
Proof. The proof is given in two steps.
CLAIM1. If(2pi)th-PR assumption holds, forj= 1,· · · , αi−1, no PPT adversary can distinguish elements inDj(i)from elements inDj(i)−1.
distinguisherBthat can solve the(2pi)th-power residuosity problem with non-negligible advantagesuch that0 ≤4p2
i ·.
Btakes as inputw ∈Jn,2pi and aims to tell apartw ∈Rn,2pi orw ∈NRn,2pi. To this end,Bchooses
a random elementz←−$ Z∗n, setsx = (z(2pi)jw(2pi)j−1)
nand feedsAwith(x,(2pi)j, n). WhenAhalts,B outputs whateverAoutputs.
Now, let us show that the above reduction is correct.
– Case I: Supposew∈Rn,2pi, then we havex6∈Dj(i)−1and
w≡w02pi (modn) (19)
for some w0 ∈ Z∗n. Consider that the generalized Legendre symbol
w0 p 2pi (resp. w0 q 2pi
) takes at
most2pidifferent values, andz∈RZ∗nis chosen randomly and uniformly, then the probability to have
zw0 n
2pi
= 1 and zw06∈Rn,2pi (20)
is at least 4p12 i
according to property (2) of Lemma 1. If the condition (20) holds, the resultant elements
zw0 modnare statistically indistinguishable from random elements ofNRn,2pi. With Equation (19), we
can further havex≡(zw0)(2pi)j (mod n). Thus,x∈D(i)
j . Recall that the condition (20) is equivalent to zw0 p 2pi = zw0 q 2pi
=−1. (21)
We can deduce that x 6∈ D(i)j+1. If not, we have a representation x ≡ y(2pi)j+1 (mod n) for some
y ∈NRn,2pi, which impliesxp (2pi)j+1
= 1. But this is impossible, since from Equation (21) we have
that
x p
(2pi)j+1
= (zw
0)(2pi)j
p
!
(2pi)j+1
=(zw0)(2pi)j p−1
(2pi)j+1 = zw0 p 2pi
=−1. (22)
Consequently,x≡(zw0)(2pi)j (mod n)is uniformly distributed inD(i)
j with probability at least 4p12 i
.
– Case II: Supposew ∈NRn,2pi, then we clearly havex∈ D
(i)
j−1becausex ≡(z2piw)(2pi)
j−1
(modn)
andz2piw∈
NRn,2pi. ut
CLAIM 2. If (2pi)th-PR assumption holds, no PPT adversary can distinguish the uniform distribution of element inDα(i)
i−1from that inRn,(2pi)αi.
LetAbe an algorithm that can distinguish random elements inD(i)α
i−1from random elements inRn,(2pi)αi
with non-negligible advantage 0. Let us build a(2pi)th-power residuosity distinguisher Bwith the same non-negligible advantage=0.
Btakes as input an elementw ∈Jn,2pi with the goal of deciding whetherw∈Rn,2pi orw ∈NRn,2pi. To do this,Bsimply defines x = (w(2pi)αi−1)
n and runsA on input of(x,(2pi)αi, n). When Ahalts, B outputs whateverAoutputs.
It is easy to see that this reduction is correct: Ifw ∈ Rn,2pi, thenx ∈ Rn,(2p
i)αi. Ifw ∈ NRn,2pi, we
Combining CLAIM 1 and CLAIM 2, we can get the expected reduction chain (18). Note that the loss
factor of the advantages in each reduction step is at most 4p12
i, and all reductions are directly based on
the (2pi)th-PR assumption. For achieving the indistinguishability result of D(i)j c
≈ Rn,(2pi)αi for j = 0,· · · , αi−1, we need at mostαisteps. Thus, the total loss factor of the advantages is at most4p21
i·αi.
This concludes the Lemma.
Lemma 5. For a primepand two positive integersk1, k2withk1|p−1, k2|p−1. Ifx∈Rp,k1andx∈Rp,k2, thenx∈Rp,[k1,k2], where[k1, k2]denotes the least common multiple ofk1 andk2.
Proof. x ∈ Rp,k1 andx ∈ Rp,k2 imply that x ≡ r
k1
i ≡ r k2
2 (modp) for somek1, k2. Then, for p’s any primitive rootg, we have
r1≡ga (modp) and r2 ≡gb (modp)
for somea, b. Thus,
x≡gak1 ≡gbk2 (modp).
This suggestsak1 ≡bk2 (modp−1). Then, we have
a k1
(k1, k2)
≡ k2 (k1, k2)
b
mod p−1
(k1, k2)
.
and k1
(k1,k2)|b. Thus, we get
r2 ≡
gb/
k1 (k1,k2)
(kk1 1,k2)
(modp)
and
x≡
gb/
k1 (k1,k2)
k1k2 (k1,k2)
≡
gb/
k1 (k1,k2)
[k1,k2]
(modp).
That is,x∈Rp,[k1,k2]. ut
We are now in a position to prove Theorem 3.
Proof. Firstly, we set t = Qs
i=1(2pi)αi for some distinct primes pi’s and positive integers αi’s (i =
1,· · · , s), and defineI as the following Cartesian product
I ={0,1,· · · , α1} × · · · × {0,1,· · ·, αs}.
Then, for any given vectora= (a1,· · ·, as)∈I, let us define a series of Cartesian product sets
Da=Da(1)1 × · · · ×D
(s)
as, (23)
whereD(i)αi =Rn,(2pi)αi (i= 1,· · · , s), whileD
(i)
ai forai< αi(i= 1,· · · , s) is defined in (17).
The basic idea to prove Theorem 3 is that ifk0th-PR assumption holds, then for any given two vectors a,b ∈ I, the elements sampled randomly and uniformly from Da are computationally indistinguishable
from that fromDb. That is,
Da
c
More precisely, if there exists a PPT distinguisher Athat can tell apart elements randomly chosen from
Da from that from Db with advantage 0, then there exists a kth-power residue distinguisher B that can
decide whether a given random element is in NRn,k or not with advantage ≥ 4ps2 sα
0, where α =
max{α1,· · · , αs}.
At first, let us consider the case ofs= 2, i.e.,a = (a1, a2)andb= (b1, b2). We only need to discuss the situation whena1 6=b1anda2 6=b2(otherwise the conclusion is hold apparently according to Lemma 4.
A successful distinguisher that can tell apart uniform distributions overD(1)a1 ×D
(2) a2 andD
(1) b1 ×D
(2) b2
means that it cannot only tell apart uniform distributions overD(1)a1 andD
(1)
b1 , but also tell apart uniform
distributions over Da(2)2 andD
(2)
b2 . More precisely, if there exists a PPT distinguisher Athat can tell apart
uniform distributions overD(1)a1 ×D
(2) a2 andD
(1) b1 ×D
(2)
b2 with non-negligible advantage
0, then bothA’s
advantages for telling apart uniform distributions overDa(1)1 andD
(1)
b1 , andD
(2) a2 andD
(2)
b2 are no less than
0. However, according to the proof of Lemma 4, such A means a 2p1-th residue distinguisher B1 with advantage
1 ≥
1 4p21· |a1−b1|
0,
and a2p2-th residue distinguisherB2with advantage
2 ≥
1 4p2
2· |a2−b2| 0.
With access to eitherB1orB2, we can easily decide whether a given elementx∈Z∗nis belong toNRn,2p1p2
or not. Thus, we obtain a(2p1p2)-th residue distinguisherBwith advantage
=1+2≥
1 4p21|a1−b1|
+ 1
4p22|a2−b2|
0. (25)
By a very similar reduction, we have that fors > 2, if there exists a PPT distinguisherAthat can tell apart uniform distributions overDa(1)1 × · · · ×D
(s) as andD
(1)
b1 × · · · ×D
(s)
bs with non-negligible advantage
, then we can obtain ak0th residue distinguisherB, which can be used to decide whether a given element x∈Z∗nis belong toNRn,kor not, with advantage
=1+· · ·+s≥
1 4p2
1|a1−b1|
+· · ·+ 1 4p2
s|as−bs|
0. (26)
In particular, whena= (0,· · · ,0)andb= (α1,· · · , αs), we have that
Da
c
≈Db=Rn,(2p1)α1 × · · · ×Rn,(2ps)αs
and Equation (26) becomes
=1+· · ·+s≥
1 4p2
1α1
+· · ·+ 1 4p2
sαs
0 ≥ s 4p2
sα
0. (27)
Further, according to Lemma 4, Lemma 5 and
withα = max{α1,· · ·, αs}, if there is a PPT distinguisher that can tell apartDa andDb, we can easily
decide whether a given elementx∈Z∗
nis belong toNRn,kor not.
This finishes the proof. ut
Now, we can give the security proof of our proposal based on thekth-PR assumption.
Theorem 4. Letk= 2αQs
i=1p αi
i andk
0 = 2Qs
i=1pi, whereα = max{α1,· · ·, αs}, andpi’s are distinct
small odd primes. Ifa∈NRn,k0, then schemeV0 and schemeV1 are semantically secure under thekth-PR assumption. More precisely, for any PPT IND-CPA adversaryA, we have a distinguisherBsuch that
AdvAind−cpa(1κ)≤ 4p
2 s·α
s ·Adv kth−P R
B (1
κ).
Proof. The basic idea is very similar to the proof of Theorem 2 of [23] in which the so-called Gap-2α-Res assumption was used. Let us define two gamesG0andG1as follows: InG0, the challengerCsends the real public key(n, k, a)to the adversaryA, while inG1,Cat first picksz∈Z∗nat random and setsa0=hxk
0 in, then sendsAthe forged public key(n, k, a0). Apparently, inG1,a0∈Rn,k0. Thus, the ciphertext carries no
information about the message andAhas no advantage in GameG1. The left thing is to prove that these two games are indistinguishable inA’s view. The only difference betweenG0 andG1 is thata∈NRn,k0 inG0,
whilea∈Rn,k0 inG1. Therefore, under thekthresiduosity assumption,Ahas no non-negligible advantage
to distinguish them. ut
4.2 Security Under thekth-SPR Assumption
Definition 6 (StrongkthPower Residuosity (kth-SPR) Assumption).Letn = pqbe the product of two large primespandqwithk|p−1andk|q−1. The strongkth-power residuosity problem inZ∗nis to decide
whether a given random elementa∈ Z∗
n is akth-power residue or not. The strongkth-power residuosity
assumption posits that, without knowing the factorization ofn, the advantageAdvkAth−SP R(1κ)of any PPT strongkth-power residuosity distinguisherA, defined as the follows, is negligible with respect to the system security parameterκ,
AdvkAth−SP R(1κ) =|Pr[A(x, k, n) = 1|x←Z∗N]−Pr[A(x, k, n) = 1|x←Rn,k]|
where probabilities are taken over all coin tosses.
Theorem 5. Scheme V0 and schemeV1 are semantically secure under the strong kth-power residuosity
assumption.
Proof. Under the strongkth-power residuosity assumption, our scheme is still provably secure even without the conditiona∈ NRn,k0. Consider that in GameG0,ordp(a) = kin schemeV0 andordp(a) =p−1in
schemeV1, then(a)p6∈Rp,kin both cases. Thus,a6∈Rn,k. The remained reduction is identical to what was
given in the proof of Theorem 4, except that in GameG1, the assignmenta0 = hxk
0
in should be replaced
witha0 =hxkin. ut
5 Implementation Issues, Performance and Applications
5.1 Provable Security Under thekth-PR Assumption
Careful reader may notice that there exists a small gap between the proof of Theorem 4 and real setting of our proposal. That is, the part of public keyadoes not always satisfya∈NRn,k0. In this section, we fill the
gap by introducing a probabilistic generation of sucha. Recall thatk = 2αpα1
1 · · ·pαss,k0 = 2p1· · ·ps, andp−1 =kp0. We selecthp ∈Z∗pat random, and set r =hhkp0·p0ip. Clearly, we have that
r p
k0 = 1. Ifp ≡3 (mod 4), we then setrp ← h−rip. In this case, r
p
p
k0 =
−r p
k0 =−1. Ifp≡1 (mod 4), thenα > 1. We need further elaboration. Letζ =e
2iπ/2α be
the primitive2α-th root of unity, wherei=√−1, we then setrp =hζ·rip. Now, we have that
rp p
k0 ≡
ζ p
k0
≡ζp−1k0 ≡e 2iπ 2α·
p−1
2p1···ps ≡eiπ· p−1
2αp1···ps ≡ −1 (modp).
Similarly, we can selecthq ∈Z∗q at random and getrqsuch that
r q
q
k0 =−1. By using CRT, we have
that
a=rp+php−1(rq−rp)iq
as what we need. In fact, sincea≡rp (modp)anda≡rq (modq), we have that
a
n
k0 =
rp p
k0 ·
rq q
k0
= (−1)·(−1) = 1.
That is,a∈NRn,k0.
Next, let us analyze the order ofb= ap
k. It is easy to check thata 2k/k0
≡1 (mod p)holds in both
cases. Thus, we have thatl = ordp(b)|ordp(a)|2k/k0. Based on our test, we find that whenhp andhq are selected at random,lreaches the up bound2k/k0 with high probability. Note that due to the decrease ofl, the message space is reduced from[0, k)to[0, l).
5.2 Performance Analysis and Comparisons
In this section, we only count the time cost in algorithmsEncandDec, but not that in algorithmKeyGen, since it is run only once.
The workload of algorithmEncin our proposal is the same as the Joye-Libert cryptosystem, i.e., it is mainly occupied by two modular exponentiations. However, the time cost in algorithm Dechas a subtle difference.Decin the both cryptosystems is quite efficient due to efficient solutions ofk-residue discrete logarithm that is performed by a “bit-by-bit” manner. The “bit-by-bit” manner is actually performed in a binary manner in the Joye-Libert cryptosystem, while it is performed in api-adic manner in our proposal, where pi could be larger than 2. Theoretically, for message space Z2α, the decryption time in the
Joye-Libert cryptosystem is proportional toα. That is, its time complexity in algorithm Dec isO(α·Te(n)), where Te(n) = O((logn)2(log logn)) is the time complexity for performing modular exponentiations. While it is proportional toα0 = P
our proposal can be made to constant, say by using the hash table technique as used in [27]. Therefore, the time complexity in algorithmDecin our proposal can be approximately reduced to
Tdec(n) =O Te(n)· s
X
i=1 αi
!
.
The above analysis also says that for the same size message space, as long asα0 < α, our scheme could outperform the Joye-Libert cryptosystem in algorithmDec. This is manifested by our testing on different choice onk. Our testing environment and common settings are given below.
– CPU: Intel(R) Core(TM)2 Duo [email protected].
– RAM: 3GB.
– OS: Windows 7, Service Pack 1.
– Supporting Library: MIRCAL Version 5.4, produced by Shamus Software Corp.
– p0, q0: Large numbers contain a big prime no less than 600 bits.
– Size of message space: Roughly equal to2128.
– n’s in all tests are of similar bit-length.
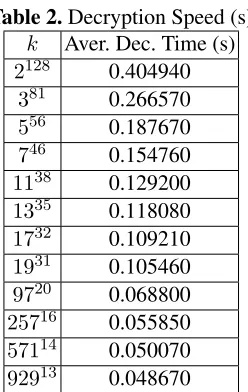
Table 2.Decryption Speed (s) k Aver. Dec. Time (s)
2128 0.404940
381 0.266570
556 0.187670
746 0.154760
1138 0.129200
1335 0.118080
1732 0.109210
1931 0.105460
9720 0.068800
25716 0.055850
57114 0.050070
92913 0.048670 When k = 2128 (i.e., α = 128), our proposal is
instan-tiated to the Joye-Libert cryptosystem, the average decryption time, over 100 trials, is about 400ms. Whenk = 381, the aver-age decryption time is reduced to about 267ms. Whenk = 556
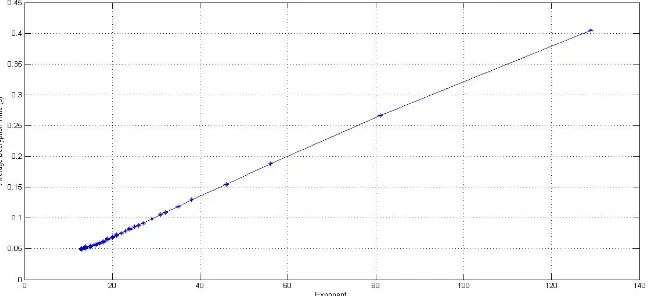
and k = 746, the decryption time is further reduced to about 188ms and 155ms, respectively. We performed similar tests on all small primes less than 1000, while keeping the message space size similar with but not smaller than 2128. The results are il-lustrated in Figure 1, and some results with typical settings on k are given in Table 2. From Figure 1, we can see that when small primes, say pi < 100, are used, the average decryption time decreases dramatically along the increase of used primes. It follows the fact that oncekis fixed, whenpi increases, the ex-ponentαi =dlogpikedecreases apparently, and the decryption
cost is mainly determined byαi, instead of the value ofpi. This conclusion is further manifested by Figure 2, where the average decryption time is plotted w.r.t. each setting on exponent value.
Our test also suggests that this kind of speed-up ratio vanishes whenpibecomes too large.
5.3 Enlarge Message Space by Using Chinese Remainder Theorem
In our schemesV0andV1, the message space isZk, while the ciphertext space isZ∗n. Thus, if we assume that the bit-lengths ofk,p0andq0 are roughly equal, i.e.logp≈logq≈2 logk. Then, the ciphertext expansion factor is
ρV0 =ρV1 = logn
logk =
logp+ logq
logk ≈4.
Fig. 1.Decryption Speed
– n=p·qandk=k1·k2.
– (k1, k2) = (k1, p0) = (k2, q0) = 1.
– p0,q0both contain large prime factors
– k1,k2both only contain small odd prime factors.
– ais a common primitive root w.r.t. the moduluspand the modulusq.
Then, upon receiving a ciphertext c = amxk ∈ Z∗n, the decryptor knowing(p, q, k1, k2) can recover the messagem∈Zkas follows.
1. Computebp=
a p
k1
, bq=
a q
k2
, which can actually be pre-computed.
2. Computeyp=
c p
k1
, yq=
c q
k2
.
3. Computem1 =RDLkbp1,p(yp)andm2 =RDLkbq2,q(yq)by using the method in Section 3.4. 4. Reconstruct the messagem∈Zkfrom
m≡m1 (modk1) and m≡m2 (modk2),
by using CRT.
The correctness of the above scheme is apparently sinceordp(bp) =k1andordq(bq) =k2. By doing so, we obtain an improved scheme, denoted byV2, that achieves better ciphertext expansion factor
ρV2 = logn
logk ≈
logφ(n) logk =
logk1+ logk2+ logp0+ logq0
logk1+ logk2
≈2
under the reasonable assumption that the lengthes ofk1, k2, p0 andq0are roughly equal.
The security analysis of schemeV2can be obtained similar with that of schemesV0andV1.
Remark 6. In fact, schemeV2 still works well ifordp(a) = t1·k1 andordq(a) =t2·k2 for some positive integers t1, t2, where both t1 and t2 contain one large prime factor at least. In addition, Algorithm 2 in Section 3.3 for generating a with conditions ordp(a) = k1 and ordq(a) = k2 can also work well for generatingawith conditionsordp(a) =t1·k1andordq(a) =t2·k2.
5.4 Lossy Trapdoor Functions Fromkth-Power Residues
Lossy Trapdoor Functions (LTDFs), introduced by Peikert and Waters at STOC’08 [29], have been proven to be an extremely useful and versatile cryptographic primitive [21]. Many research efforts have recently been dedicated to design efficient LTDFs based on different cryptographic assumptions [21,19]. Recently, Joye and Libert [23] proposed a quite efficient LTDF with short outputs and keys, and large lossiness based on their GM-type cryptosystem. By using the same framework of Joye-Libert, our proposal can also yield an efficient LTDF with short outputs and keys, and large lossiness.
Before giving our construction on LTDFs, we briefly recall the definition of lossy trapdoor functions given in [29,21]. Informally, a collection of lossy trapdoor functions consists of two families of functions. Functions in one family are injective and can be efficiently inverted using a trapdoor. Functions in the other family are “lossy”, which means that the size of their image is significantly smaller than the size of their domain. The only computational requirement is that a description of a randomly chosen function from the family of injective functions is computationally indistinguishable from a description of a randomly chosen function from the family of lossy functions [19].
– InjGenoutputs a pair(σ, t)∈ {0,1}∗× {0,1}∗whereσ is an index of an injective functionf, whilet
isf’s trapdoor.
– LossyGenoutputsσ∈ {0,1}∗ as an index of an lossy functionf.
– Evaluationtakes as input an function indexσ ∈ {0,1}∗and an inputx ∈ {0,1}µ, outputs the value fσ(x)such that
• ifσis an output ofInjGen, thenfσ(·)is an injective function.
• ifσis an output ofLossyGen, thenfσ(·)has image size2µ−ν.
– Inversiontakes as input an imagefσ(x)and the corresponding trapdoort, outputsx.
– The two ensembles{σ|(σ, t) ←InjGen(1κ)}and{σ|σ← LossyGen(1κ)}are computationally indis-tinguishable.
Now, our construction goes as follows. Without loss of generality, let us assume that the desired input usingk-adic encoding and the length is no more than`(i.e.,µ=`logk).
– InjGen(1κ): To sample an injective function, algorithmInjGenperforms the following steps:
1. Generate a modulusn=pqsuch thatp=kp0+1andq=kq0+1, where bothp0andq0contain large prime factors, whilekis a product of small primes. Chooseasuch thatordp(a) = ordq(a) =k, or ais a primitive root w.r.t. modulusp.
2. For each i ∈ {1,· · ·, `}, pick hi in the subgroup of order p0q0, by setting hi = gki modnfor a randomly chosengi ∈Z∗n.
3. Chooser1,· · ·, r` R
←−Zp0q0 and compute a matrixZ = (zi,j)i,j∈{1,···,`}with
zi,j =
ahri
j modn,ifi=j hri
j modn, otherwise.
4. Output the function indexσ = (n, Z)and the trapdoorp.
– LossyGen(1κ): The process ofLossyGenis identical to the process ofInjGen, except that 1. the matrix entryzi,j =hrji modnfor∀i, j∈ {1,· · ·, `}.
2. without outputtingp.
– Evaluation: Givenσ = (n, Z = (zi,j)i,j∈{1,···,`}), the algorithmEvaluationencodes the inputxas
k-adic string x˜ = x1· · ·x` with xi ∈ Zk for eachi. Then, it computes and returnsy˜ = (y1,· · ·, y`) withyj =Q`i=1z
xi
i,j modn∈Z∗n.
– Inversion: Given trapdoorpandy˜= (y1,· · ·, y`) ∈Z`n, one can apply the decryption algorithm for each yj to recover xj ∈ Zk (j = 1,· · · , `) and then reconstructx = P`j=1xjkj−1, since when Z is
given by algorithmInjGen, we have thatyj
p
k
≡a p
xj
k (modp)holds.
It is easy to see that the above LTDF construction is quite similar with that in [23], which leads to the similar security analysis. Hence, we omit the security analysis, but just give analysis on the lossiness.
In our LTDF, the input space isZ`k, but the output is entirely determined by
P`
i=1riximodp0q0, where r1,· · ·, r` ∈ Zp0q0 are selected at random, whilex1,· · · , x` ∈Zkare specified by inputs. Thus, the image
size is at most p0q0, and the residual leakage is at most log(p0q0) bits. That is, we lose ν(2) = `logk−
One interesting question is that the above LTDF is based on scheme V0 or scheme V1, how about the lossiness when the LTDF is based on schemeV2? As usual, we assume thatlogk1 ≈ logp0 ≈ logk2 ≈
logq0, then the lossiness could be improved toν(2) = (`−1)αforα= logkandν(k) =`−1. This result says that by using schemeV2, we can obtain an LTDF that keepsonly onek-adic “bit” and loses all other k-adic “bits”. This shows that by using the same building framework, the smaller the ciphertext expansion factor of the GM-type cryptosystem, the better the lossiness of the resulting LTDF. Recall the ciphertext expansion factor of the Joye-Libert cryptosystem, it is
ρJ L=
logn α >
logn 1
4logn−κ
>4≈ρV0 =ρV1 ≈2ρV2.
As a result, the LTDF based on schemeV2is better than that based on the Joye-Libert cryptosystem in terms of lossiness.
6 Conclusions
It never overestimates the importance of the GM cryptosystem. It enriches modern cryptography on many aspects. On one hand, it plays a major role in the development of modern cryptography by introducing the concept of “semantic security” and “indistinguishability”. On the other hand, it is the first additive homomor-phic encryption scheme. Many subsequent improvements focus on how to reduce the bandwidth, ciphertext expansion factor, or encryption/decryption cost, while keeping the property of additive homomorphism. By using(2α)th-power residues, the Joye-Libert cryptosystem, a non-trivial extension of the GM cryptosystem, is not only efficient in bandwidth and encryption/decryption speed, but also supports additive homomor-phism over an exponential-scale message space. In this paper, we have made further extension on the GM cryptosystem by usingkth-power residues wherekis merely required to be a product of powers of small primes. The proposed schemes do not only inherit all advantages from the Joye-Libert cryptosystem, but also enhance the decryption speed observably. Moreover, schemeV2achieves lower ciphertext expansion factor and results in a lossy trapdoor functions with better lossiness compared to the Joye-Libert constructions.
Acknowledgement
We would like to thank David Naccache, Daniel Brown, Richard Heylen, Zhengjun Cao, and Yanbin Pan for useful comments.
References
1. Leonard M. Adleman and Robert McDonnell. An application of higher reciprocity to computational number theory (abstract). InFOCS 1982, pages 100–106. IEEE Computer Society Press, 1982.
2. Miklos Ajtai. Generating hard instances of lattice problems (extended abstract). InSTOC 1996, pages 99–108. ACM Press, 1996.
3. Josh Benaloh and Dwight Tuinstra. Receipt-free secret-ballot elections. InSTOC 1994, pages 544–553. ACM Press, 1994. 4. Daniel Bleichenbacher. Chosen ciphertext attacks against protocols based on the RSA encryption standard PKCS #1. In
CRYPTO 1998, volume 1462 ofLecture Notes in Computer Science, pages 1–12. Springer-Verlag, 1998.
5. Lenore Blum, Manuel Blum, and Michael Shub. Comparison of two pseudo-random number generators. InCRYPTO 1982, pages 61–78. Plenum Press, 1983.
7. Manuel Blum and Shafi Goldwasser. An efficient probabilistic public-key encryption scheme which hides all partial informa-tion. InCRYPTO 1984, volume 196 ofLecture Notes in Computer Science, pages 289–299. Springer-Verlag, 1985.
8. Dan Boneh, Antoine Joux, and Phong Q. Nguyen. Why textbook ElGamal and RSA encryption are insecure. InASIACRYPT 2000, volume 1976 ofLecture Notes in Computer Science, pages 30–43. Springer-Verlag, 2000.
9. Zhenfu Cao. A type of public key cryptosystem based on Eisenstein ringZ[ω]. InProceedings of the 3rd Chinese Conference of Source Coding, Channel Coding and Cryptography, pages 178–186, 1988.
10. Zhenfu Cao. A type of puclic key cryptosystem based onkthpower residues (extended abstract).Chinese Journal of Natural, 12(11):877, 1989.
11. Zhenfu Cao. A type of puclic key cryptosystem based onkthpower residues (full version). Journal of Chinese Institute of Communications, 11(2):80–83, 1990.
12. Zhenfu Cao.Public-key Cryptography (in Chinese). Heilongjiang Education Press, 1993.
13. David Cash, Eike Kiltz, and Victor Shoup. The twin Diffie-Hellman problem and applications. InEUROCRYPT 2008, volume 4965 ofLecture Notes in Computer Science, pages 127–145. Springer-Verlag, 2008.
14. Josh D. Cohen and Michael J. Fischer. A robust and verifiable cryptographically secure election scheme. InFOCS 1985, pages 372–382. IEEE Computer Society Press, 1985.
15. Ronald Cramer and Victor Shoup. A practical public key cryptosystem provably secure against adaptive chosen ciphertext attack. InCRYPTO 1998, volume 1462 ofLecture Notes in Computer Science, pages 13–25. Springer-Verlag, 1998.
16. Ronald Cramer and Victor Shoup. Universal hash proofs and a paradigm for adaptive chosen ciphertext secure public-key encryption. InEUROCRYPT 2002, volume 2332 ofLecture Notes in Computer Science, pages 45–64. Springer-Verlag, 2002. 17. Jintai Ding and Bo-Yin Yang. Multivariate public key cryptography. InPost-quantum cryptography, pages 193–241.
Springer-Verlag, 2009.
18. Taher ElGamal. A public key cryptosystem and a signature scheme based on discrete logarithms. IEEE Transactions on Information Theory, 31(4):469–472, 1985.
19. David Mandell Freeman, Oded Goldreich, Eike Kiltz, Alon Rosen, and Gil Segev. More constructions of lossy and correlation-secure trapdoor functions. InPKC 2010, volume 6056 ofLecture Notes in Computer Science, pages 279–295. Springer-Verlag, 2010.
20. Shafi Goldwasser and Silvio Micali. Probabilistic encryption.Journal of Computer and System Sciences (preliminary version published at STOC 1982), 28(2):270–299, 1984.
21. Brett Hemenway and Rafail Ostrovsky. Lossy trapdoor functions from smooth homomorphic hash proof systems. Electronic Colloquium on Computational Complexity (ECCC), Revision 2 of Report No. 127 (2009), 2009.
22. Jakob Jonsson and Burton S. Kaliski Jr. On the security of RSA encryption in TLS. InCRYPTO 2002, volume 2442 ofLecture Notes in Computer Science, pages 127–142. Springer-Verlag, 2002.
23. Marc Joye and Benoˆıt Libert. Efficient cryptosystems from2k-th power residue symbols. InEUROCRYPT 2013, volume 7881 ofLecture Notes in Computer Science, pages 76–92. Springer-Verlag, 2013.
24. Zhao Ke and Qi Sun.Elementary Number Theory (in Chinese). Advanced Education Press, 2001.
25. R. J. McEliece. A Public-Key System Based on Algebraic Coding Theory, pages 114–116. Jet Propulsion Lab, 1978. DSN Progress Report 44.
26. Daniele Micciancio and Oded Regev. Lattice-based cryptography. InPost-quantum cryptography, pages 147–192. Springer-Verlag, 2009.
27. David Naccache and Jacques Stern. A new public key cryptosystem based on higher residues. InCCS 1998, pages 59–66. ACM Press, 1998.
28. Raphael Overbeck and Nicolas Sendrier. Code-based cryptography. InPost-quantum cryptography, pages 95–145. Springer-Verlag, 2009.
29. Chris Peikert and Brent Waters. Lossy trapdoor functions and their applications. InSTOC 2008, pages 187–196. ACM Press, 2008.
30. Michael Rabin. Digitalized signatures and public-key functions as intractable as factorization. Technical Report MIT/LCS/TR-212, Laboratory for Computer Science, Massachusetts Institute of Technology, January 1979.
31. Ronald L. Rivest, Adi Shamir, and Leonard M. Adleman. A method for obtaining digital signatures and public-key cryptosys-tems.Communication of ACM, 21(2):120–126, 1978.