A Reconfigurable Streaming Processor
for Real-Time Low-Power Execution
of Convolutional Neural Networks
at the Edge
Justin Sanchez(B), Nasim Soltani, Pratik Kulkarni, Ramachandra Vikas Chamarthi, and Hamed Tabkhi University of North Carolina at Charlotte, Charlotte, NC, USA
Abstract. With the recent advances in machine learning and the deep learning paradigm, there is a huge demand to push the data analytics and cognitive inference to the edge of the network near the data pro-ducers and sensors. Edge analytics are essential for real-time video ana-lytics and situational awareness; which is required for the wide range of cyber-physical applications such as smart transportation, smart cities, and smart health. To this end, novel architectures and platforms are required to enable real-time low-power deep learning execution at the edge.
This paper introduces a novel reconfigurable architecture for real-time execution of deep learning and in particular convolutional Neural Net-works (CNNs) at the edge of the network, close to the video camera. The proposed architecture offers a set of coarse-grain function blocks required for realizing CNN algorithms. The macro-pipelined datapath is created by chaining the function blocks with respect to the topology of the target network. The function blocks operate over the streaming pixels (directly fed from the camera interface) in a producer/consumer fashion. At the same time, function blocks offer enough flexibility to adjust the processing with respect to area, power, and performance requirements. This paper primarily focuses on the two first layers of CNNs as the two most compute-intensive layers of CNN network. Our implementation on Xilinx Zynq FPGAs, for the first two layers of the SqueezNet Network, shows 315 mW power consumption when designed at 30 fps, with only a 0.24 ms one-time-latency. In contrast, the Nvidia Tegra TX2 GPU is lim-ited to perform at 32.2 fps due to the 31.4 ms delay, with a much higher power consumption (7.5 W).
1
Introduction
Deep learning paradigm has emerged as a promising scalable machine learning solution for extensive data analytics and inference [1–4]. Many applications from smart transportation, and smart and connected communities, inherently require
c
Springer International Publishing AG, part of Springer Nature 2018 S. Liu et al. (Eds.): EDGE 2018, LNCS 10973, pp. 49–64, 2018. https://doi.org/10.1007/978-3-319-94340-4_4
real-time or near real-time scalable deep-learning inference. One major example is real-time video analytic for object localization, detection, and classification. With the tight latency requirements, long communication latency, and scarcity of communication bandwidth, the cloud comping paradigm is not able to offer a scalable sustainable solution for real-time deep learning inference. Therefore, novel architecture and design paradigms are required to push deep learning from the cloud to the edge of the network near to the data producers (e.g. video cameras).
While GPUs are widely used for training, they are not an efficient platform for real-time deep learning inference at the edge. GPUs are inherently throughput-oriented machines which makes them less suitable for the edge. GPUs require the large batch size of data (multiple video frames) to achieve high performance and power efficiency. Furthermore, GPUs have lack of deterministic execution patterns; [5,6]. To overcome the limitations of GPUs, we have seen many new cus-tom hardware approaches for accelerating deep learning inference. Few industrial examples are Google TPU [7], and Microsoft Brainwave [8]. While these plat-forms offered much higher performance and power efficiency compared to GPUs they still rely on throughput-oriented processing principles, which is more suit-able for cloud computing, than the real-time inference at the edge. There is a need for novel custom platforms that offers latency-aware scalable acceleration for real-time deep-learning analytics over streaming data at the edge.
In this paper, we propose a novel reconfigurable architecture template for real-time low-power execution of Convolutional Neural Networks (CNNs) in the edge devices next to the camera. In principle, our proposed architecture is a coarse-grain dataflow machine, which performs CNN computation over stream-ing pixels. It consists of basic functional blocks required for CNN processstream-ing. The blocks are configurable with respect to data window size (size of convolution) and stride, and other network hyperparameters. The macro data-path is constructed by proper chaining of the function blocks with respect to targeted network topol-ogy. Function blocks are fused together and work concurrently to realize the convolutional operations without the need to store the streaming pixels in the memory hierarchy. Furthermore, the architecture provides enough configurabil-ity to adjust itself to rapidly growing and continuously evolving CNN topologies. As a result, the proposed architecture offers a reconfigurable template (rather than a single solution) that is able to generate efficient architecture instances. This feature gives us the possibility of easily adapting the architecture to any desired network topology. Furthermore our architecture works in a streaming fashion with minimum memory access, with respect to the algorithm’s intrinsic parallelism.
The major focus of our architecture is on accelerating the first two layers of CNNs, as they are the most compute-intensive kernels. The first two layers will run on the edge device, next to the camera, while other layers will run on the edge server in a proximity to edge devices. Our implementation of Xilinx Zynq FPGAs, for the first two layers of SqueezNet Network [9], shows 315 mW on-chip power consumption with an execution time of 0.24 ms. In contrast, the Nvidia
Tegra TX2 GPU is only able to perform with an execution time of 31.4 ms, with a much higher on-chip power consumption (135 W).
The rest of this paper is organized as follows. Section2presents a summary on the existing methods and past literature on architectures for neural networks. Section3 motivates the proposed architecture. Section4 explains the details of the proposed architecture. Section4.4 presents function blocks integration and dimensioning. Section5presents our implementation results. Finally, Sect.6 con-cludes the paper.
2
Related Work
GPUs’ large power consumption conflicts with low power requirements in mobile applications [10–13]. This pushed the designers to use customized hardware accelerators for implementing CNNs at the edge. These custom accelerators could be targeted for ASIC [6] or FPGAs [14]. Most of recent works have focused on converting direct convolution to matrix multiplication. Among them, some have focused on doing the multiplication in a low-latency and low-power man-ner. Tann et al. [15] propose to map floating-point networks to 8-bit fixed-point networks with integer power-of-two weights and hence to replace multiplication with shift operations to do a low-power and low-latency multiplication.
A number of recent works have addressed this extensive memory requirement and have proposed different methods to reduce this memory access [16]. As some examples, [17] proposes entirely mapping a CNN inside an SRAM, consider-ing weights are shared among many neurons, and eliminate all DRAM accesses for weights. Later authors in [18] proposed a hardware accelerator targeted for FPGAs that exploits sparsity of neuron activation to accelerate computation and reduce external memory accesses. They exploit the flexibility of FPGAs to make their architecture work with different kernel sizes and number of feature maps. Han et al. [19] uses deep compression to fit large networks into on-chip SRAMs and accelerates resulting sparse matrix-vector multiplication by weight sharing. They decrease energy usage by going from DRAMs to SRAMs, exploit-ing sparsity in multiplication, weight sharexploit-ing, etc. Jafri et al. [20] presents an architecture targeted for ASIC that exploits the flexibility of compressing and decompressing both input image pixels and kernels to minimize DRAM accesses. They also presents an algorithm (LAMP) that intelligently partitions memory and computational resources of a MOCHA accelerator to map a CNN to it. [21] proposes a convolution engine that achieves energy efficiency by capturing data reuse patterns and enabling a large number of operations per memory access. Authors in [22] propose fusing the processing of multiple CNN layers by modify-ing the order that input data are brought on chip. They cache intermediate data (data that is transferred between layers) between the evaluations of adjacent CNN layers.
With all these different approaches towards reducing memory access, a lack of an architecture that separates the computation data from memory data and works on the streaming pixels is still sensed. This paper proposes such an archi-tecture that can be further configured for any desirable network topology.
3
Background and Motivation
In this section, we briefly overview data access types in CNN, and the differences between General Matrix Multiplication (GEMM) and direct convolution. We conclude with the motivation to focus on the first two layers of the CNN.
3.1 Data Access Types
Convolutional Neural Networks (CNN) are both memory and compute-intensive applications, often reusing intermediate data and while consistently doing mil-lions of parallel operations. Furthermore, the inherent memory intensive aspects of the algorithm are further exaggerated due to complex multi-dimensional data accesses. In this regard, we consider two major types of data when performing CNN.
(1) 2D Weight: The first type is 2D weight matrices. These weight matrices each correspond to a single channel and these channels weight matrices group together to construct the entire kernel. Multiple kernels form a layer, and multiple layers create a network topology.
(2) Frame Pixels: The streaming pixels which are the input to the CNN pro-cessing. Just like the weight matrices these are 2D matrices, with multiple channels. This is the data that flows through the network topology.
3.2 GEMM vs Direct Convolution
W0 W1 W2
W3
W6 W4 W5
W7 W8
P0 P1 P2 P3 P4
P5 P10 P15
P20
P6 P7 P8 P9 P11 P12 P13 P14 P16 P17 P18 P19
P21 P22 P23 P24
Fig. 1.Direct convolution Direct convolution is the point-wise Multiply
and Accumulation (MAC) operation across the 2D weight Matrices and frame pixels. In direct convolution, similar to the algorithmic level definition, the weight Matrices are used to perform multiple multiply and then accu-mulation operations directly on the 2D win-dow of input pixels. The direct convolution performs in a sliding window fashion with respect to a stride parameter that varies layer to layer in network topologies. Figure1
exem-plifies direct convolution operation, for a 3 by 3 convolution window over a frame with 5 by 5 pixels.
W0 W1 W2 W3 W4 W5 W6 W7
P0 P1 P2 P5 P6 P7 P10 P11 P12 P1 P2 P5 P6 P7 P10 P11 P12
P2 P3 P6 P7 P8 P11 P12 P13 P3 P4 P7 P8 P9 P12 P13 P14 P6 P7 P10 P11 P12 P15 P16 P17 P7 P8 P11 P12 P13 P16 P17 P18 P8 P9 P12 P13 P14 P17 P18 P19 P11 P12 P15 P16 P17 P20 P21 P22 P12 P13 P16 P17 P18 P21 P22 P23 P13 P14 P17 P18 P19 P22 P23 P24
Pixels
Weights
Fig. 2.General Matrix Multiplica-tion (GEMM)
Traditionally, GPUs have seen much suc-cess in the cloud by using a linear algebra transformation called General Matrix Multi-plication (GEMM) to lower the dimensions of convolution to regular matrix multiplica-tion. GEMM transforms all the temporal par-allelism into spatial parpar-allelism. This helps GPUs to achieve a high throughput assuming the large data batches are available. However,
this comes at a significant memory cost. The transformation is done by rear-rangement with redundant copies of input image pixels. Our estimation reveals that the rearrangement results in 11X data duplication only for the first layer of any CNN network. This translates to significant power and energy overhead for accessing the redundant pixel data throughout memory hierarchy. Figure2 exemplifies GEMM operation, for the same example illustrated in Fig.1. As we observe, redundancy of frame pixels is required to transfer the convolution oper-ation to a large matrix multiplicoper-ation. For this example, the pixels will be 9 by 9 compared to original frame size which is 5 by 5.
3.3 CNN Execution Bottlenecks
conv0
s1e1 s2 e2s3 e3 s4e4 s5 e5 s6 e6 s7 e7 s8 e8 conv9
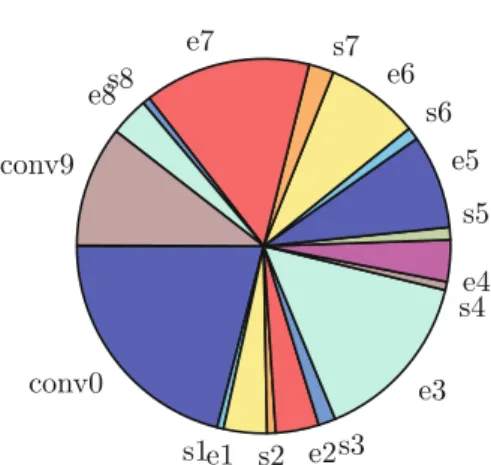
Fig. 3. Computation distribution across the SqueezNet layers
In this paper, we primarily focus on accelerating the first two layers of CNN as the major execution bottlenecks. We specifically target SqueezNet [9], a DCNN design with memory effi-ciency in mind. To motivate our argu-ment, we have estimated the compu-tation demands across the CNN lay-ers for the example of SqueezNet [9]. Figure3 shows the computation dis-tribution across the SqueezNet layers. Overall, SqueezNet contains 10 layers. The first and last layers are traditional convolution layers (conv0 and conv9). The intermediate layers are squeeze (s) and expand (e) convolutional layers.
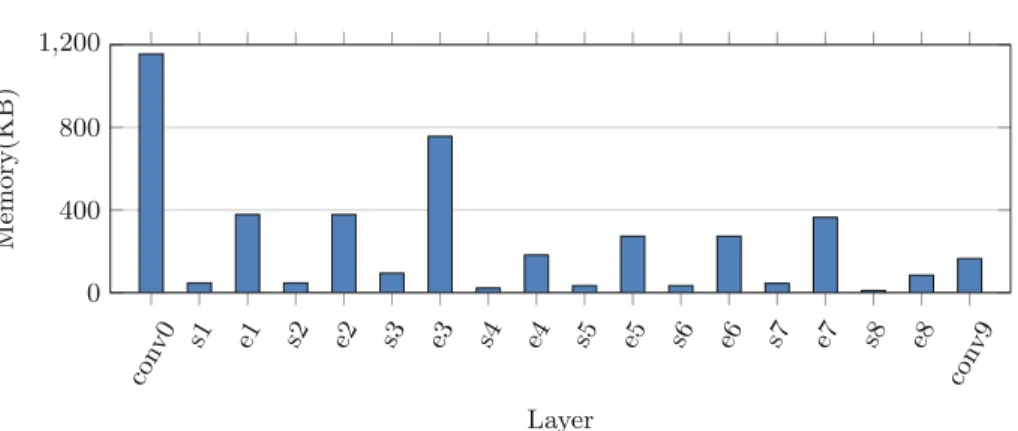
The squeeze layers combine the feature maps to make the network more effi-cient and expand layers expand the feature map. As we observe, the first layer (conv0) has the highest computation demand with 21% contribution to overall computation demand. The first layer also generates the largest size of feature map across all layers which can lead to significant communication and memory traffic. Figure4 presents the contribution of layers on feature map. To mini-mize the memory access and communication demand, it would be beneficial to accelerate the second layer (s1, e1) along with the first layer. In this way, much
con
v0 s1 e1 s2 e2 s3 e3 s4 e4 s5 e5 s6 e6 s7 e7 s8 e8 con
v9
0 400 800 1,200
Layer
Memory(KB)
Fig. 4.Feature map distribution
smaller feature maps will be transferred to the edge server for processing of the remaining layers.
4
Architecture Template
This section introduces our proposed architecture template, for real-time exe-cution of CNN inference on the edge. The proposed template targets FPGA devices, as they offer both efficient execution and sufficient reconfigurability to cope with continuously growing CNN topologies [23]. Furthermore, by target-ing the FPGAs, we are able to generate a customized datapath per each CNN network as such to best fit the processing requirements. The major premise of our proposed architecture is to remove the gap between the algorithm execution semantic and architecture realization. Therefore, our proposed architecture is primarily a data flow machine working on streaming data based on direct con-volution. It consists of three main function blocks for realizing the wide range of CNN inference topological structure. The blocks are Convolutional Processing Element (CPE), Aggregation Processing Element (APE), and Pooling Processing Element (PPE). The blocks will be configured and connected with respect to tar-get network topology, creating a macro-pipeline datapath. Figure5presents over-all architecture realization from logical domain (algorithm) to physical domain (architecture).
Cloud
Edge Server
Layer 1
K96
FM= 3 C= 3
k0
FM=96 K0 K16
Layer 2
Edge Node
Layer 1 &2 < Layer 2
FM= Number of Feature Maps C= Number of Channels
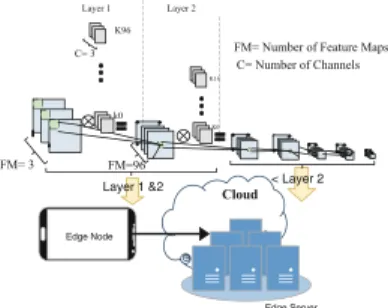
Fig. 6. CNN computation map-ping between the edge node and edge server
Our architecture is designed based on the natural dataflow of CNNs. It is able to exploit both spatial parallelism across the convolu-tions within the same layer, as well as tem-poral parallelism between the blocks across the layers. The blocks are configurable with respect to network parameters such as size of convolution and stride. This gives us the pos-sibility of easily adapting the architecture to any desired network topology.
In this paper, we focus our architecture realization of the first tow layers of CNNs. While our proposed architecture template is
extensible and can support the entire CNN topology, the primary limitation is available hardware resources on FPGAs of the edge devices. At this moment, we are targeting smaller FPGAs, e.g. Xilinx Zynq [24], with small reconfigurable fabric. However, by accelerating the first two layers on the edge node, we will able to relax the computation demands on the edge server. Figure6 shows the logical mapping of the network between the edge node and edge devices. The edge node will perform the heavy computation of the first layer. Furthermore, it runs the second layer to significantly shrink the feature map. Then it sends the feature maps to the edge server for the remaining layers to do the processing.
4.1 Covolutional Processing Elements (CPE)
Convolutional Processing Element (CPE) is responsible to perform the primary computation of CNN which is direct convolution over two-dimensional pixel stream. Figure7presents the internal architecture of CPE block. It contains two primary blocks: (1) 2D-line Buffer and (2) Multiply and Accumulator (MAC) engines.
+
Stream Accumulator
+
2D-Line Buffer MAC Engine
Weight Matrix Data
Kernel
Buffer Kernel Buffer
*
*
Fig. 7. Convolutional Processing Element
2D-Line Buffers. The 2D-line buffer is what enables convolution neural networks to oper-ate in an streaming manner. This is achieved by maintaining the reused pixels for multi-ple cycles. The pixels that must be reused are determined by the network topology and the receptive field of the layer the 2D line buffer is mapped to. Every layer of a convolutional neural network has a hyperparameter called stride that dictates how the receptive field slides through the feature maps, both
horizon-tally and vertically. No matter what the stride is set to, the minimum amount of data that must be stored is determined by the size of the receptive field or filter window. However, when the stride is less than the filter dimension size, extra feature map data must be kept in a buffer.
To deal with the horizontal reuse, only twice the extra pixels must be kept at max, however, vertical stride requires all rows that were used in the filter window to be available. The 2D-line buffer that is used in our approach is able to overcome this by keeping the minimum amount of rows needed. We keep at least one row of the streaming input to preserve the horizontal reuse and we maintain extra rows depending on the filter size in order to preserve the vertical reuse of data. This is done for all streaming feature map data in each layer through the accelerator. The 2D-line buffer is expanded by having an input FIFO which we call stream accumulator to allow the buffer to receive input while operating on the data at the same time.
Multiply and Accumulator (MAC) Engines. The convolution unit is the heart of the architecture. It is composed of a series of independent MAC units that perform parallel multiply and accumulate operations together each cycle. The MAC units are able to execute any kernel size by simply changing the number of cycles it operates on data. These MAC units further enable efficient and flexible convolution by exploiting the multiple forms of parallelism inherent to the convolution operation. The first form of parallelism we exploit is Intra-Kernel parallelism. Intra-Intra-Kernel achieved by dividing the convolution of a single kernel to multiple MAC units. By exploiting this parallelism a 7×7 kernel which would normally take 49 cycles can only take 7 cycles, by dedicating 7 MAC units to operate on the pixel and weight data in parallel.
The next form of parallelism, Inter-Kernel parallelism, is achieved by fetching multiple kernels at once and having at least one MAC dedicated to each. The main benefit to this form of parallelism comes when you exploit the full available inter-kernel parallelism. When all kernels are run together the kernel weights can be kept in the buffer thus removing unnecessary memory fetches. The 2D-line buffer allows data0-level parallelism by reusing the same kernel on all the feature map data available on the buffer. This approach leaves less of a memory footprint on the system. Further feature map parallelism is also a possibility by running multiple feature map sections concurrently, however, this would increase the memory footprint left on the main system, so we do leave it to be explored in future work.
4.2 Aggregation Processing Elements (APE)
+ 000...0
Input MSB
0 Input
Fig. 8. Aggregation Processing Element (APE)
This layer performs aggregation across mul-tiple output streams representing different channels. Figure8presents overall view of our proposed APE module. APE is perhaps the simplest functional block in our architecture. It takes the stream of input pixels that have negative and positive values, rectifies the neg-ative values to zero and passes the positive values as they are. Therefore, the output of APE is a non-negative sequence of pixel values.
4.3 Pooling Processing Elements (PPE)
Fig. 9. The sliding window with stride
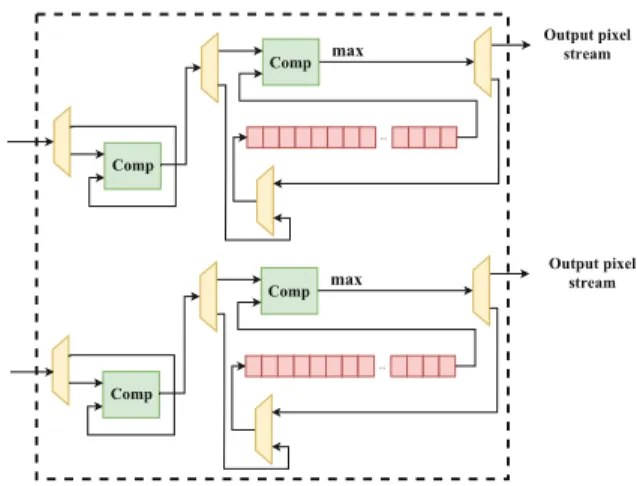
Pooling Processing Elements (PPEs) are in charge of down-sampling the image. Every pooling process has two parameters of stride and window (filter) size. The degree of com-pression actually depends on the stride. The core idea of pooling with a n ×n window is to replace each window with the maxi-mum among all the elements in that window. Figure9shows an example of pooling with the window size of 3×3 and stride of 2.
To avoid the unnecessary memory and buffer requirements to store the entire feature map, the proposed pooling block works on the
stream of pixels while supporting variable horizontal and vertical pooling strides. Figure10presents the architecture details of our proposed PPE. In the following we will present a detailed description of 3×3 window with a stride of two as an example to illustrate the on-the-fly pooling process. For horizontal stride, the pooling block receives the first pixel and keeps it in a register until the second pixel arrives. When the second pixel arrives, a comparator will compare the two and keeps the result in a register since it is not the end of our window yet. When the third pixel arrives, it is sent to the comparator to determine the maximum of the first three pixels. This maximum is then stored in the FIFO. The third pixel is also kept separately in a register to be compared with pixel 4. (Because in a stride of 2, pixel 3 is shared between the first and second windows.) The same process repeats until all the pixels in the first row are received. By this time, maximum values in each window, for the first row of the image, are stored in the FIFO and the FIFO is full now.
Fig. 10.Pooling Processing Elements (PPE) For taking care of
ver-tical stride, when the sec-ond row arrives, maxi-mum of the three first pixels is calculated like the first row. However, it is time for the old-est input of the FIFO to pop out. This oldest ele-ment would be the maxi-mum of the first window in the first row, which is then compared to our new maximum in the sec-ond row and the largest between the two is fed to the FIFO. Similarly,
when the third row arrives, the process for the second row is repeated and finally, the maximum of all nine pixels in the first window is Fed to the FIFO. Moreover, to take care of the horizontal stride, since the third row is also the horizontal end of our window, as the pixel stream for the third row arrives, we also feed it to another pooling block as the first row of the image. All the process described above is replicated in this second pooling block. The first pooling block is vacated after all the maximums for first row windows are calculated and sent out, and by the time the sixth row arrives, pooling block is ready to receive this row as the first row.
4.4 Function Blocks Integration
The Macro-pipeline consists of single CPEs mapped to one input channel of a layer. The full layer is then constructed by multiple CPEs operating in parallel. The CPEs are then wired together by the APE to aggregate the convolutions and pass data to the next layer. A PPE is optionally generated after the aggregation if the network topology demands it with the data stream then being fed into the multiple CPEs of the next layer.
This MACRO-pipelined datapath is generated layer by layer until the desired network topology is achieved. By changing the number of CPEs we can support multiple layers with multiple channels. Each CPE itself is also able to handle customization to each layer’s hyper parameters such as stride, Kernel dimensions and input frame size. The system receives image data directly from the sensor, this allows users to separate the input and memory traffic and minimize the memory footprint. To handle the kernel data we include on-chip memory to double buffer access to the main memory and hide the latency. That becomes an end to end accelerator capable of flexible acceleration over the domain of CNNs.
5
Evaluation
This section presents our evaluation results based on implementation on Xilinx Zynq FPGAs.
5.1 Experimental Setup
The full architecture template was constructed using chisel [25], a high-level hardware construction language. We feed the chisel code multiple parameters of the network topology as well as design parameters on how we should extract the natural parallelism. The code then generates a Macro-pipelined datapath to run the network topology. We have implemented an instance of our architecture template for the first two layers of the SqueezNet [9]. We focused on SqueezNet network because it was designed with computational and memory efficiency. The design was realized with a Xilinx Zynq-7000 FPGA [24], due to its low power footprint and embedded Processor.
Table 1.SqueezNet topology properties for the first two layers. Layer number Number of
CPEs Kernel size Number ofMACs Intra kernelparallelism Inter kernelparallelism Frequency(MHz)
0 3 (7×7) 49 2 98 71
1 96 (1×1) 1 1 1 11
Table1 presents SqueezNet architecture properties for the first two layers. Overall, the first layer, as the major compute-intensive layer, contains 96 kernels each one performing 7 by 7 convolution which translates to 49 MACs. It also contains three channel representing R, G, and B.
For evaluation, we use three different possible datapaths of our proposed architecture. Figures11, 12 and 13 shows these three implementations respec-tively, with respect to our proposed CPE and function block integration pre-sented in Sect.4. Intra kernel parallelism focuses on spatial parallelism in the MAC operations within each kernel. On the other extreme, inter kernel paral-lelism solely focuses on the spatial paralparal-lelism across MAC operations across all 96 parallel kernels. In between, the hybrid inter/intra kernel parallelism aims to find a balance between inter and intra kernel parallelism.
Fig. 11.Intra kernel parallelism K2
+
*
+
*
K1 K2
+
*
+
*
K1
K2
+
*
+
*
K1
+ 000...0
Input
+ 000...0
Input
CPE APE PPE
Fig. 12.Inter kernel parallelism
5.2 Resource Utilization and Power Overhead
This section presents the resource utilization and power overhead for the three proposed configuration.
intra hybrid inter
0 150 300 450 600
Type of Parallelism
Powe
r
(mw
)
Fig. 14.First layer dynamic power for differ-ent types of parallelism
Figure14 shows the dynamic power of our proposed architec-ture when running the first layer for three types of parallelism. The results gathered for real-time pro-cessing of 30 frames per second with 227×227 resolution. As the figure illustrates, the intra-kernel parallelism achieves the minimum power consumption by consuming only 135 mW dynamic power con-sumption. The hybrid parallelism is a close second and inter-kernel par-allelism has the highest power
con-sumption. The static power of entire FPGAs is about 180 mW. This leads to the overall power consumption of 315 mW.
In tra Hybrid In ter 0 10k 20k 30k T otal Amoun t
(a) LUT as logic
In tra Hybrid In ter 0 2k 4k 6k
(b) LUT as Mem
In tra Hybrid In ter 0 8k 16k 24k (c) Register In tra Hybrid In ter 0 30 60 90 (d) BRAMs
Fig. 15.Absolute FPGAs resource demand for the first layer across design points.
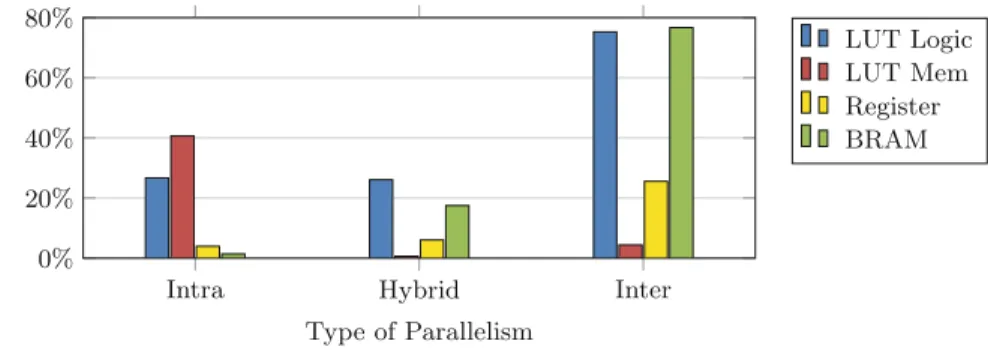
Figure15 presents the absolute resource consumption for the three design points. Figure16also presents relative resource utilization on Xilinx Zynq across the design points. Overall, intra kernel parallelism has the lowest utilization except for LUT as memory. In intra kernel parallelism, the 2D-line buffers are not mapped directly to BRAMs but instead to LUTs do to the extra Read ports need. Although overall intra kernel parallelism performs best for the first layer in SqueezNet, the remaining layers would map to better utilize different forms of parallelism with respect to their inter and intra kernel data sharing patterns which are directly driven from the network topology.
Intra Hybrid Inter 0%
20% 40% 60% 80%
Type of Parallelism
Resource
U
tilization
(%) LUT Logic
LUT Mem Register BRAM
Fig. 16.Relative resource utilization on Xilinx Zynq across design points
5.3 System-Level Impact
In this part, we quantify the system-level benefits of the computing the first two layers on the edge node. Figure17 compares two scenarios: (1) computing entire network on the edge server and (2) computing across the edge node and edge server (edge-node+edge-server). Figure17b compares the execution time. Overall, the server+node cooperative computation achieves 32% improvement in the performance. Figure17a compares the network communication traffic. Node+server cooperative computation reduces the communication and network traffic by more then 3x.
Server Node+Server
0 1 2 3 4 5
Execution
time
(ms)
(a) Execution time
Server Node+Server
0 50 100 150 200
Net
w
ork
T
raffic
(KB)
(b) Network Traffic
Fig. 17.Network traffic and execution time comparison between server, and edge-node+edge-server scenarios
5.4 Comparison Against GPUs
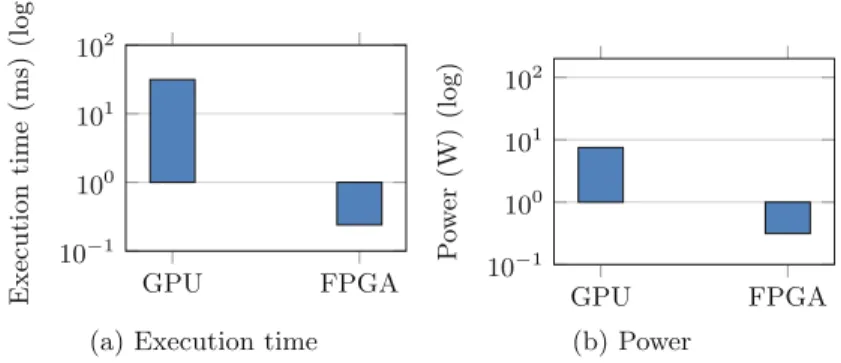
This section is the alternative solution comparison, which compares our proposed architecture (implemented on Zynq FPGA) against the state of the art mobile GPU, Nvidia Jestosn TX2 [26]. Figure18compares both execution time (as the latency for performing single frame), and power consumption in the logarithmic scale. Figure18a shows that our architecture (implemented on Zynq FPGA) has
a latency cost of 0.24 ms. While the mobile GPU solution imposes a latency of 31.4 ms. Figure18b shows that our proposed architecture can offer consider-ably lower power consumption over mobile GPUs. For execution 30 frames at the resolution of 227×227, GPU consumes 7.5 W. In contrast, our proposed architecture, implemented on Zynq FPGA, only consumes 0.315 W.
Our proposed architecture consumes about 24x lower power compared to Nvidia Jetson TX2 GPU, while imposing 130x less latency. Our proposed archi-tecture is a data-flow machine, thus it only operates when the streaming pixels of the new frame are available. It is able to process the entire frame at 0.24 ms. It then stays in the standby mode until it receives the next frame streaming data. As a result, our architecture is able to even perform real-time processing at the much higher frame rates such as 60 fps and 120 fps.
GPU FPGA
10−1 100 101 102
Execution
time
(ms)
(log)
(a) Execution time
GPU FPGA
10−1 100 101 102
P
o
w
er
(W)
(log)
(b) Power
Fig. 18.Power and performance comparison against Nvidia Tegra TX2 GPU
6
Conclusions
In conclusion, this paper proposed a novel architecture template for real-time low-power execution of Convolutional Neural Networks at the edge. The pro-posed architecture is primarily targeted for FPGAs, and is able to offer config-urable macro-pipeline datapath for scalable direct convolutions over streaming pixels. The proposed architecture is an example of a hybrid solution across edge nodes and edge servers for realizing compute-intensive deep learning applica-tions. The proposed architecture is able to reduce the network traffic and execu-tion time of the overall applicaexecu-tion. At the same time, it maintains the flexibility to map to any standard CNN network topology. Future work includes supporting full network topology acceleration on edge and supporting nonstandard CNN, as well as a workflow for mapping them efficiently to different FPGA boards.
References
1. Egmont-Petersen, M., de Ridder, D., Handels, H.: Image processing with neural networksa review. Pattern Recogn.35(10), 2279–2301 (2002)
2. Ciregan, D., Meier, U., Schmidhuber, J.: Multi-column deep neural networks for image classification. In: 2012 IEEE conference on Computer vision and pattern recognition (CVPR), pp. 3642–3649. IEEE (2012)
3. Collobert, R., Weston, J.: A unified architecture for natural language processing: deep neural networks with multitask learning. In: Proceedings of the 25th Inter-national Conference on Machine learning, pp. 160–167. ACM (2008)
4. Zhao, H., Wang, J., Gao, P.: A deep learning approach for condition-based, p. 32. STIoT Editorial Board (2017)
5. Paine, T., Jin, H., Yang, J., Lin, Z., Huang, T.: GPU asynchronous stochastic gra-dient descent to speed up neural network training. arXiv preprintarXiv:1312.6186
(2013)
6. Du, L., Du, Y., Li, Y., Su, J., Kuan, Y.C., Liu, C.C., Chang, M.C.F.: A recon-figurable streaming deep convolutional neural network accelerator for internet of things. IEEE Trans. Circ. Syst. I Reg. Pap.65(1), 198–208 (2018)
7. Wu, Y., Schuster, M., Chen, Z., Le, Q.V., Norouzi, M., Macherey, W., Krikun, M., Cao, Y., Gao, Q., Macherey, K., et al.: Google’s neural machine translation system: bridging the gap between human and machine translation. arXiv preprint
arXiv:1609.08144(2016)
8. Microsoft brainwave. https://www.microsoft.com/en-us/research/blog/microsoft-unveils-project-brainwave/
9. Iandola, F.N., Han, S., Moskewicz, M.W., Ashraf, K., Dally, W.J., Keutzer, K.: Squeezenet: AlexNet-level accuracy with 50x fewer parameters and<0.5 mb model size. arXiv preprintarXiv:1602.07360(2016)
10. Strigl, D., Kofler, K., Podlipnig, S.: Performance and scalability of GPU-based convolutional neural networks. In: 2010 18th Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP), pp. 317–324. IEEE (2010)
11. Potluri, S., Fasih, A., Vutukuru, L.K., Al Machot, F., Kyamakya, K.: CNN based high performance computing for real time image processing on GPU. In: 2011 Joint 3rd International Workshop on Nonlinear Dynamics and Synchronization (INDS) and16th International Symposium on Theoretical Electrical Engineering (ISTET), pp. 1–7. IEEE (2011)
12. Nasse, F., Thurau, C., Fink, G.A.: Face detection using GPU-based convolutional neural networks. In: Jiang, X., Petkov, N. (eds.) CAIP 2009. LNCS, vol. 5702, pp. 83–90. Springer, Heidelberg (2009).https://doi.org/10.1007/978-3-642-03767-2 10
13. Latifi Oskouei, S.S., Golestani, H., Hashemi, M., Ghiasi, S.: CNNdroid: GPU-accelerated execution of trained deep convolutional neural networks on Android. In: Proceedings of the 2016 ACM on Multimedia Conference, pp. 1201–1205. ACM (2016)
14. Nagy, Z., Szolgay, P.: Configurable multilayer CNN-UM emulator on FPGA. IEEE Trans. Circ. Syst. I Fundam. Theory Appl.50(6), 774–778 (2003)
15. Tann, H., Hashemi, S., Bahar, R.I., Reda, S.: Hardware-software codesign of accurate, multiplier-free deep neural networks. In: 2017 54th ACM/EDAC/IEEE Design Automation Conference (DAC), pp. 1–6. IEEE (2017)
16. Sharma, H., Park, J., Mahajan, D., Amaro, E., Kim, J.K., Shao, C., Mishra, A., Esmaeilzadeh, H.: From high-level deep neural models to FPGAs. In: 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pp. 1–12. IEEE (2016)
17. Du, Z., Fasthuber, R., Chen, T., Ienne, P., Li, L., Luo, T., Feng, X., Chen, Y., Temam, O.: ShiDianNao: shifting vision processing closer to the sensor. In: ACM SIGARCH Computer Architecture News, vol. 43, pp. 92–104. ACM (2015) 18. Aimar, A., Mostafa, H., Calabrese, E., Rios-Navarro, A., Tapiador-Morales, R.,
Lungu, I.A., Milde, M.B., Corradi, F., Linares-Barranco, A., Liu, S.C., et al.: Null-Hop: a flexible convolutional neural network accelerator based on sparse represen-tations of feature maps. arXiv preprintarXiv:1706.01406(2017)
19. Han, S., Liu, X., Mao, H., Pu, J., Pedram, A., Horowitz, M.A., Dally, W.J.: EIE: efficient inference engine on compressed deep neural network. In: 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), pp. 243– 254. IEEE (2016)
20. Jafri, S.M.A.H., Hemani, A., Paul, K., Abbas, N.: MOCHA: morphable locality and compression aware architecture for convolutional neural networks. In: 2017 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pp. 276–286. IEEE (2017)
21. Qadeer, W., Hameed, R., Shacham, O., Venkatesan, P., Kozyrakis, C., Horowitz, M.: Convolution engine: balancing efficiency and flexibility in specialized comput-ing. Commun. ACM58(4), 85–93 (2015)
22. Alwani, M., Chen, H., Ferdman, M., Milder, P.: Fused-layer CNN accelerators. In: 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pp. 1–12. IEEE (2016)
23. Xu, L., Pham, K.D., Kim, H., Shi, W., Suh, T.: End-to-end big data processing protection in cloud environment using black boxes-an FPGA approach. Int. J. Cloud Comput.2, 14–27 (2014)
24. APU, A.P.U.: Zynq-7000 all programmable soc overview (2012)
25. Bachrach, J., Vo, H., Richards, B., Lee, Y., Waterman, A., Aviˇzienis, R., Wawrzynek, J., Asanovi´c, K.: Chisel: constructing hardware in a scala embed-ded language. In: Proceedings of the 49th Annual Design Automation Conference, pp. 1216–1225. ACM (2012)
26. Naphade, M., Anastasiu, D.C., Sharma, A., Jagrlamudi, V., Jeon, H., Liu, K., Chang, M.C., Lyu, S., Gao, Z.: The NVIDIA AI city challenge. In: IEEE Smart-World, Ubiquitous Intelligence and Computing, Advanced and Trusted Computed, Scalable Computing and Communications, Cloud and Big Data Computing, Internet of People and Smart City Innovation (Smart-World/SCALCOM/UIC/ATC/CBDCom/IOP/SCI) (2017)