© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal
| Page 2803
Comparative Study of ETL and E-LT in Data Warehousing
Dipti M. Tayade
---***---Abstract-Numerous associations depend vigorously on
their information stockroom for big business level basic leadership. Building an information stockroom requires concentrating intently on understanding three primary regions: the source zone, the goal region, and the mapping zone wherein the ETL and E-LT procedure happens. Since an information stockroom pulls information from different heterogeneous sources, the concentrate and burden procedures assume significant jobs in structure an improved information distribution center arrangement. In this paper we look at the Extract, Transform and Load (ETL) approach and Extract, Load and Transform (E-LT) approach for stacking information into an information stockroom. In this paper, we will measure the presentation distinction for both ETL and E-LT approaches
Keywords: Extraction, Load, Transformation, Datawarehouse
I. INTRODUCTION
In this day and age, each organization needs helpful data to improve basic leadership quality dependent on information-based existing framework thus an idea known as business knowledge of using an enormous number of corporate information prepared in such an approach to deliver valuable data comes into the image. So as to run BI, one ought to have an information stockroom that can store the whole information from the different information source and various sorts of information.
Since an information stockroom is a focal storehouse for revealing and scientific purposes, the extraction of information from different heterogeneous sources and stacking it into an objective information distribution center assumes a significant job in structure an advanced information distribution center. There are various methodologies that can be utilized for removing information from different heterogeneous source frameworks and stacking this information into an Enterprise Data Warehouse [1]. The point of this paper is to look at the conventional Extract, Transform and Load (ETL) approach versus Concentrate, Load, and Transform (E-LT) approach for stacking information into the information distribution center.
II. LITERATURE REVIEW
The exploration introduced by A.Simitsis, P.Vassiliadis and T.Sellis[2] secured the Extract, Transform and Load (ETL) approach for structure an
information stockroom arrangement. The old emerged view approach is examined and contrasted with show how the ETL approach is better. It further centered around how to construct an information stockroom arrangement by advancing the ETL approach. Interestingly, G.X. Zhou and Q.S. Xie [3] exhibited how to assemble a fruitful information stockroom arrangement utilizing the Extract, Load and Transform (E-LT) approach. It exhibited favorable circumstances regarding cost and time in structure the E-LT arrangement over the conventional ETL approach. The up and coming age of structure information distribution center arrangements dependent on the Corporate Information Factory is examined in [3]. It additionally displays the significance of the ETL approach in structure the proposed arrangement. The ETL approach and its key highlights like metadata, review trails and information quality are the first rates by I. William, S. Derek, and N. Genia [4]. Both the ETL and the E-LT methodologies are completely talked about by R. J. Davenport [5], where the professionals and the cons of the two methodologies are additionally displayed.
III. EXTRACTION TRANSFORM LOAD PROCESS
While working with databases, it is fundamental to appropriately design and plans information so as to stack it into information stockpiling frameworks. E-T-L are three separate however pivotal capacities joined into a solitary programming instrument that aides in getting ready information and in the administration of databases. Underneath we will see the functionalities of every one of the three procedures.
Extract: Information from a source database is perused and the ideal subset of information is extricated in this process. The motivation behind this progression is to recover all the required information from the source framework with the least assets. The concentrating procedure should be planned such that it doesn't influence the source framework contrarily regarding execution or reaction time.
Transform: In this procedure, the sifting, purging of information is done and it likewise readies the removed information utilizing query tables or administers or by making blends with other information and changes over it to the ideal state. The change step incorporates the approval of records, dismissal of information (in the event that they are not worthy) and information mix.
Arranging, separating, clearing the copies,
© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal
| Page 2804
portion of the generally utilized procedures for change transformation.
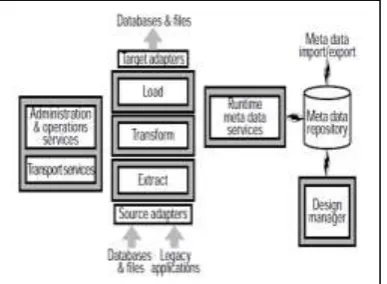
[image:2.595.63.257.313.455.2]Load: The way toward stacking the information into the information distribution center is one of the elements of the procedure. The heap capacity composes the subsequent information, for example the extricated and changed information in like manner to an objective information vault. A few devices physically embed each record as another column into the tabl of the objective database utilizing SQL embed explanation, while numerous different devices interface the extraction, change, and stacking forms for each record from the source [6].
Figure 1 demonstrates the whole procedure of removing information from various sources to putting away the data into the archive.
• The structure chief gives a graphical mapping condition that gives engineers a chance to characterize source-to-target mappings, changes, process streams, and employments. The plans are put away in a metadata vault.
• Metadata the executives give a store to characterize, archive, and oversee data (i.e., metadata) about the ETL structure and runtime forms. The store makes metadata accessible to the ETL motor at run time and different applications
• Extracts sourced information utilizing connectors, for example, ODBC, local SQL arrangements, or level document extractors. These connectors counsel metadata to figure out which information to concentrate and how.
• ETL apparatuses give a library of change questions that let engineers change source information into target information structures and make rundown tables to improve execution.
• ETL instruments use target information connectors, for example, SQL or local mass loaders, to embed or adjust information in target databases or records.
• Transport administrations utilize the system and document conventions to move information among source and target frameworks and in-memory conventions (e.g., information reserves) to move information between ETL run-time segments.
• ETL utilities let chairmen calendar, run, and screen ETL occupations just as log all occasions, oversee mistakes, recoup from disappointments, and accommodate yields with source systems.[7]
IV.EXTRACT TRANSFORM AND LOAD (ETL)
APPROACH
The conventional Extract, Transform and Load (ETL) approach works by first removing information from different heterogeneous sources like databases, level documents, ERP frameworks, CRM frameworks, and centralized server frameworks. Diverse business principles are connected to the information extricated from different sources by the exclusive, center level ETL motor. The kneaded and changed information is stacked into the objective information stockroom framework or reconciliation framework [3]. ETL requires the board of the crude information, including the extraction of the required data and running the correct changes to at last serve the business needs. Each stage — extraction, change, and stacking — requires association by information specialists and designers, and managing limit impediments of customary information distribution centers. Utilizing ETL, experts and other BI clients have turned out to be acclimated with pausing, since basic access to the data isn't accessible until the entire ETL procedure has been finished.
© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal
| Page 2805
connections between the different substances in both the source and target, are planned and in this way coded into the schedules that execute the ETL procedure. This methodology prompts tight conditions in the schedules at each phase of the procedure.
Strengths:
• Designing from the yield in reverse guarantees that solitary information applicable to the arrangement is separated and handled, possibly lessening improvement, concentrate, and preparing overhead, hence decreasing an opportunity to construct the arrangement. [5]
• Due to the focus on the nature of the heap procedure, the information stockroom contains just information applicable to the presentation[5].
• ETL can perform increasingly complex tasks in single information stream graphs (information maps).
Weaknesses:
• The information change venture of the ETL approach is the most figure escalated and is performed completely by the exclusive ETL motor on a committed server. This expands the activity's runtime just as more equipment costs.
• The ETL motor performs information changes and here and there information quality minds the arow-by-push premise. This can without much of a stretch become the bottleneck in the general procedure [5].
• The information is moved over the system twice – once among sources and the ETL server and again between the ETL server and the objective information distribution center [3].
• Since just the pertinent information caught in the information distribution center, information required for any future necessities probably won't exist in the information stockroom and should be added to the ETL schedules. Because of the idea of tight reliance between the schedules built up, this frequently prompts a requirement for crucial overhaul and advancement. Subsequently, this expands the time and costs included.
V. EXTRACT, LOAD AND TRANSFORM (E-LT) APPROACH
The Extract, Load, and Transform (E-LT) approach consolidates both the manual coding just as utilizing the ETL approach in a similar arrangement [3]. The information is separated similarly as in the ETL approach. after you've extricated your information, you quickly begin the stacking stage — moving every one of the information sources into a solitary, incorporated information archive. At the point when the information
is separated from the source into the arranging tables, it is a crude duplicate, which means you keep the segment names equivalent to in the source database and you don't change over information, figure new information fields, and so on. You may, be that as it may, channel unneeded lines and sections as you remove information with the goal that you don't squander assets on unneeded information. With the present framework advances utilizing the cloud, frameworks would now be able to help enormous capacity and versatile figure. Subsequently, an enormous, growing information pool and quick preparing is for all intents and purposes interminable for keeping up all the extricated crude information.
The information extricated from various sources is currently stacked into the objective information distribution center framework. When stacked, the changes and business rationales are connected utilizing local SQL drivers. The way toward moving information from the source to the organizing tables is done in SSIS utilizing information streams, however the way toward moving the information from the arranging tables to the information stockroom should be possible with T-SQL rather for an exhibition help alongside the way that it is generally simpler to code than utilizing SSIS information changes. This aide in sparing expense and additional handling required by the ETL center level.
Strengths:
© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal
| Page 2806
• Once the information is stacked on the objective stage, all changes/business principles are put on the RDBMS motor. This decreases organize clog.
•Since no additional server, innovation, or expertise necessity becomes possibly the most important factor, the E-LT engineering gives ideal execution and adaptability and facilitating the administration of the coordination framework [3].
Weaknesses:
• There are fewer E-LT apparatuses accessible in the market [5].
• Since this methodology is generally more up to date, there are exceptionally fewer engineers who have a decent comprehension of the basic standards.
VI. COMPARISON BETWEEN ETL VS. ELT USING DIFFERENT PARAMETERS
PParameters ETL ELT
PProcess Information is
changed at an organizing server& afterward
moved to
Datawarehouse DB.
Data remains in the DB of the Datawarehouse.
Usage Utiliz
ed for PC
concentrated Transformations and a limited
quantity of
information
Used
for High
amounts of data
Transformation Tran
sformations are done in ETL server/staging area.
Tran sformations are performed in the target system
Time-Load Infor
mation originally
stacked into
arranging and
later stacked
into the
objective framework. Time serious.
Data
loaded into
target system
only once.
Faster.
Time-Transformation information size As
develops, change time increments.
In
ELT process,
speed is never
dependant on
the size of the
data. Time-
Maintenance needs It highs
upkeep as you have to choose
information to
stack and
change.
Low maintenance as data is always available.
Implementation
Complexity early stage, At an
easier to
implement.
Need deep knowledge
of tools and
expert skills.
Support for
Data warehouse premises,
On-relational and
structured data.
Used in scalable cloud infrastructure which supports structured, unstructured data sources.
Complexity The
ETL process
loads only the important data, as identified at design time.
This process involves development from the
output-backward and
loading only
relevant data.
Cost High
costs for small
and medium
businesses.
Low entry costs using online Software
as a Service
Platforms.
Support for
Unstructured Data
Most
ly supports
relational data
Supp
ort for
unstructured
data readily
available.
VII. CONCLUSIONS
In this paper, we talked about both the ETL and the E-LT approach for stacking information into an information distribution center. The qualities and shortcomings of the two methodologies are displayed in this paper.
© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal
| Page 2807
BIBLIOGRAPHY
1. Vikas Ranjan, ‘A Comparative Study between
ETL (Extract-Transform-Load) and E-LT
(ExtractLoad-Transform) approach for loading data into a Data Warehouse’
2. A. Simitsis, P. Vassiliadis, T. Sellis “Optimizing ETL Processes in Data Warehouses,” in Proc. 21st International Conference on Data Engineering, 2005, (ICDE 2005), pp. 564-575. 3. G.X. Zhou, Q.S. Xie, Y. Hu, “E-LT Integration to
Heterogeneous Data Information for SMEs Networking based on E-HUB,” in Proc. Fourth
International Conference on Natural
Computation, 2008, IEEE, pp. 212-216.
4. I. William, S. Derek, and N. Genia, DW 2.0: The Architecture for the Next Generation of Data Warehousing. Burlington, MA: Morgan Kaufman, 2008, pp. 215-229.
5. R. J. Davenport, September 2007. [Online] ETL
vs. ELT: A Subjective View.
6.
www.springpeople.com/blog/data- warehousing-essentials-what-is-etl-tool-what-are-its-benefits.
7. Wayne Eckerson and Colin White, “Evaluating