University of Central Florida University of Central Florida
STARS
STARS
Electronic Theses and Dissertations, 2020-
2020
Improving Traffic Safety and Efficiency by Adaptive Signal Control
Improving Traffic Safety and Efficiency by Adaptive Signal Control
Systems Based on Deep Reinforcement Learning
Systems Based on Deep Reinforcement Learning
Yaobang GongUniversity of Central Florida
Part of the Civil Engineering Commons, and the Transportation Engineering Commons Find similar works at: https://stars.library.ucf.edu/etd2020
University of Central Florida Libraries http://library.ucf.edu
This Doctoral Dissertation (Open Access) is brought to you for free and open access by STARS. It has been accepted for inclusion in Electronic Theses and Dissertations, 2020- by an authorized administrator of STARS. For more information, please contact [email protected].
STARS Citation STARS Citation
Gong, Yaobang, "Improving Traffic Safety and Efficiency by Adaptive Signal Control Systems Based on Deep Reinforcement Learning" (2020). Electronic Theses and Dissertations, 2020-. 51.
IMPROVING TRAFFIC SAFETY AND EFFICIENCY BY ADAPTIVE SIGNAL CONTROL BASED ON DEEP REINFORCEMENT LEARNING
by
YAOBANG GONG
B.S. Central South University, 2016 M.S. University of Central Florida, 2018
A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy
in the Department of Civil, Environmental and Construction Engineering in the College of Engineering and Computer Science
at the University of Central Florida Orlando, Florida
Spring Term 2020
ii
iii
ABSTRACT
As one of the most important Active Traffic Management strategies, Adaptive Traffic Signal Control (ATSC) helps improve traffic operation of signalized arterials and urban roads by adjusting the signal timing to accommodate real-time traffic conditions. Recently, with the rapid development of artificial intelligence, many researchers have employed deep reinforcement learning (DRL) algorithms to develop ATSCs. However, most of them are not practice-ready. The reasons are two-fold: first, they are not developed based on real-world traffic dynamics and most of them require the complete information of the entire traffic system. Second, their impact on traffic safety is always a concern by researchers and practitioners but remains unclear.
Aiming at making the DRL-based ATSC more implementable, existing traffic detection systems on arterials were reviewed and investigated to provide high-quality data feeds to ATSCs.
Specifically, a machine-learning frameworks were developed to improve the quality of and pedestrian and bicyclist’s count data. Then, to evaluate the effectiveness of DRL-based ATSC on the real-world traffic dynamics, a decentralized network-level ATSC using multi-agent DRL was developed and evaluated in a simulated real-world network. The evaluation results confirmed that the proposed ATSC outperforms the actuated traffic signals in the field in terms of travel time reduction. To address the potential safety issue of DRL based ATSC, an ATSC algorithm optimizing simultaneously both traffic efficiency and safety was proposed based on multi-objective DRL. The developed ATSC was tested in a simulated real-world intersection and it successfully improved traffic safety without deteriorating efficiency. In conclusion, the proposed ATSCs are capable of effectively controlling real-world traffic and benefiting both traffic
iv
ACKNOWLEDGMENTS
First of all, I would like to express my sincere gratitude to my advisor Professor
Mohamed Abdel-Aty, for the continuous guidance and support of my master’s study and other research, for his patience, motivation and immense knowledge. I could not have imagined having a better advisor!
Secondly, I would like to appreciate the rest of my respectable committee members: Dr. Samiul Hasan, Dr. Qipeng Zheng and Dr. Qing Cai, for their invaluable comments.
I would like to thank my friends and my colleagues. I would also like to acknowledge Florida Department of Transportation for funding this research and providing data.
Finally, I would like to thank my parents. You gave me bravery to pursue my dream here, ten thousand miles away from home.
v
TABLE OF CONTENTS
LIST OF FIGURES ... ix LIST OF TABLES ... xi CHAPTER 1: INTRODUCTION ... 1 1.1 Background ... 1 1.2 Research Objectives ... 3 1.3 Dissertation Structure... 5CHAPTER 2: LITERATURE REVIEW ... 7
2.1 Deep Reinforcement Learning ... 7
2.2 ATSC Based on Conventional Reinforcement Learning ... 14
2.2.1 Problem Formulation ... 15 2.2.2 State Representation... 16 2.2.3 Action Definition ... 17 2.2.4 Reward Definition ... 18 2.2.5 Backend RL Algorithms ... 19 2.2.6 Simulation ... 20 2.2.7 Benchmark ... 21 2.2.8 Summary ... 21
vi
2.4 RL-based ATSC with multiple objectives ... 27
2.5 ATSC Considering Traffic Safety ... 29
2.6 Summary ... 30
CHAPTER 3: TRAFFIC DATA COLLECTION SYSTEMS ON ARTERIALS ... 31
3.1 Introduction ... 31
3.2 Counts Data from Infrastructure-based Detectors ... 31
3.3 Bluetooth Detection System (BDS) ... 33
3.4 Vehicle-Based Traffic Data ... 35
3.5 Summary ... 36
CHAPTER 4: ESTIMATING NON-MOTORIZED TRAFFIC COUNTS FROM BDS USING BLUETOOTH LOW ENERGY ... 37
4.1 Introduction ... 37
4.2 Assessing the Feasibility of BLE to Obtain Pedestrians and Bicyclists’ Counts ... 38
4.3 Methodology ... 42
4.4 Validation ... 49
4.5 Summary and Conclusion ... 55
CHAPTER 5: A DECENTRAILIZED NETWORK LEVEL ADAPTIVE SIGANL CONTROL ALGORITHM BY DEEP REINFORCEMENT LEARNING ... 57
vii
5.2 Decentralized Adaptive Signal Control Algorithm Based on 3DQN ... 57
5.2.1 State Representation... 58
5.2.2 Action Definition ... 60
5.2.3 Reward Definition ... 61
5.2.4 Deep Q Network Structure... 62
5.2.5 Supervised Pre-Training ... 63
5.2.6 Overall Algorithm ... 63
5.3. Experiment and Evaluation ... 65
5.3.1 Simulation Set Up ... 65
5.3.2 Training ... 69
5.3.3 Training Evaluation Results and Discussion ... 71
5.4. Conclusion ... 74
CHAPTER 6: SATETY-ORIENTED ADAPTIVE TRAFFIC SIGNAL CONTROL WITH MULTI-OBJECTIVE REINFORCEMENT LEARNING ... 75
6.1 Introduction ... 75
6.2 Background: Real-Time Crash Risk Models ... 76
6.3 Algorithm ... 77
6.3.1 State... 77
viii
6.3.3 Reward ... 79
6.3.4 Weighted Sum Approach for Single Policy MORL ... 80
6.3.5 Backend Learning Algorithm ... 81
6.3.6 Pre-Training ... 81
6.3.7 Overall Algorithm ... 82
6.4 Case Study ... 84
6.4.1 Simulation Set Up ... 84
6.4.2 Real-time crash risk model ... 87
6.4.3 Algorithm Setting... 89
6.4.4 Results ... 90
6.5 Discussion ... 93
6.5.1 Control Policy Analysis: Opening the “Black Box” ... 93
6.5.2 Other Considerations of the Signal Settings ... 97
6.5.3 Hybrid Controller: A Better Solution ... 99
6.6 Summary and Conclusions ... 101
CHAPTER 7: CONCLUSION ... 103
7.1 Summary ... 103
7.2 Implications... 105
ix
LIST OF FIGURES
Figure 1 The Illustration of the Reinforcement Learning Problem Setting (Sutton & Barto, 2018)
... 8
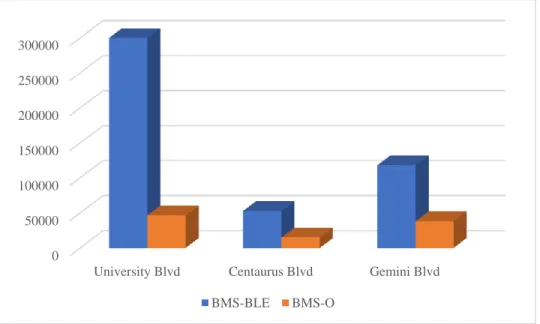
Figure 2 Comparison of unique devices detected from 07/01/2019 to 07/07/2019 ... 39
Figure 3 Comparison of unique devices detected from 07/01/2019 to 07/07/2019 ... 41
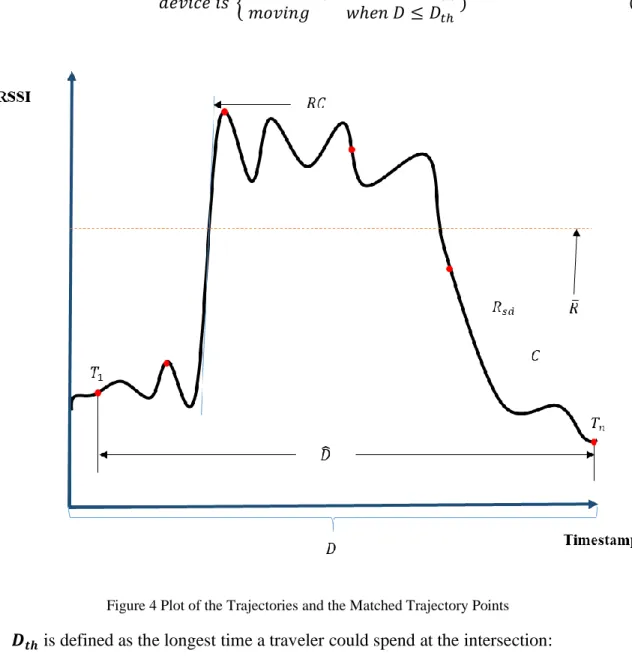
Figure 4 Plot of the Trajectories and the Matched Trajectory Points ... 44
Figure 5 Illustration of the speed-readings that are hard to be classified ... 46
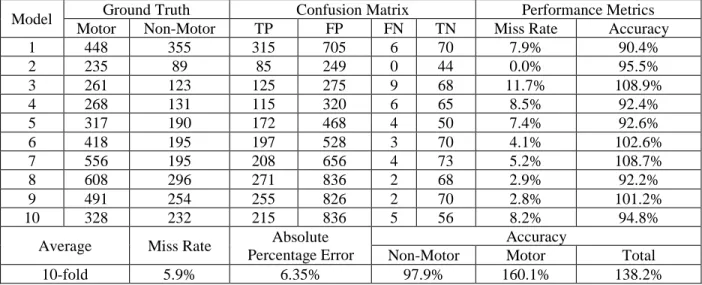
Figure 6 Illustration of the ten-fold cross-validation used in this study ... 50
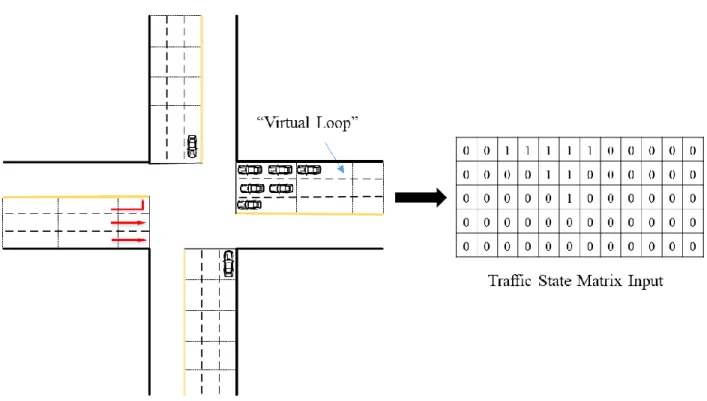
Figure 7 Traffic State Representation ... 59
Figure 8 Eight phases for four-way intersections ... 60
Figure 9 “Red Percentage” of the Yellow Time ... 60
Figure 10 Structure of the CNN used in the Algorithm ... 63
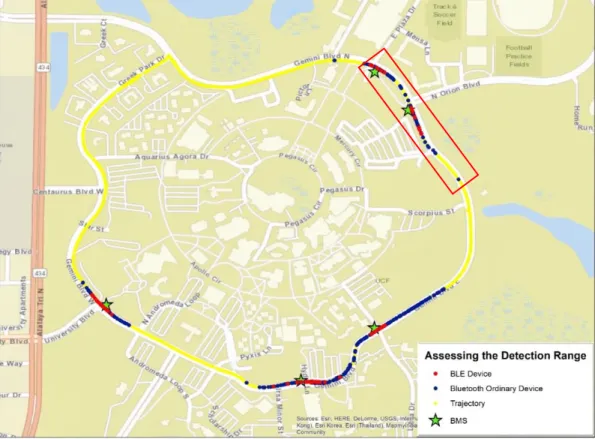
Figure 11 Location of the Simulation Test Site ... 67
Figure 12 High-Level Abstract of the Test Corridor ... 68
Figure 13 Location of the Simulation Test Site ... 71
Figure 14 Performance of Proposed ATSC algorithm and Benchmark ... 72
Figure 15 ATSC Algorithm flow chart ... 83
Figure 16 Lane configuration of the simulated intersection ... 85
Figure 17 15-minutes counts of all approaches ... 85
Figure 18 Benchmark signal timing ... 86
Figure 19 15-minutes aggregated performance measures of the controllers ... 92
x
xi
LIST OF TABLES
Table 1 Detection Rate Assessment (Raw Data) ... 40
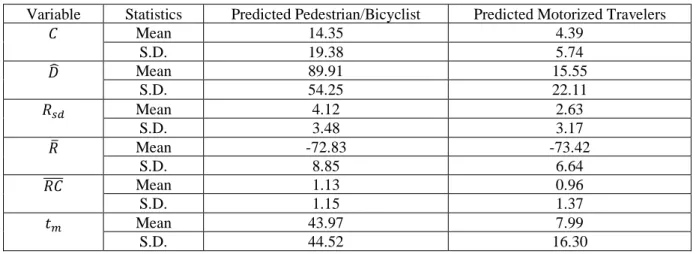
Table 2 Variables describing the RSSI-trajectory ... 49
Table 3 Ten-fold validation results. ... 52
Table 4 Statistics of variables describing the RSSI trajectories by class ... 54
Table 5 Information Regarding Signals under Control of the Algorithm ... 66
Table 6 Two-hour Aggregated O/D Matrix ... 70
Table 7 Parameters Used in Algorithm ... 70
Table 8 Results of the Real-Time Crash Risk ... 89
Table 9 Parameters Used of the Algorithm... 90
Table 10 Average Daily Performance of the Controllers ... 90
Table 11 Statistics of Green Interval Length, Activated Times and Green Ratio of Signal Groups ... 94
Table 12 Groups Average Daily Performance of the Adjusted Controller ... 97
Table 13 Average Daily Performance of the Other Tested Controllers ... 99
Table 14 Daily Performance of the Hybrid Controller Compared with the Benchmark and ATSC-MORL Controller... 100
xii
LIST OF ACRONYMS/ABBREVIATIONS
3DQN Double Dueling Deep Q network
AASE Average Absolute Speed Error
AI Artificial Intelligence
API Application Programming Interface
ATM Active Traffic Management
ATSC Adaptive Traffic Signal Control
ATSC-MORL ATSC Controller developed using a Multi-Objective RL algorithm
ATSC-SORL
ATSC Controller developed using a Single-Objective RL algorithm
ATSPM Automated Traffic Signal Performance Measures
BDS Bluetooth Detection System
BLE Bluetooth Low Energy
BMS Bluetooth MAC address scanner
BMS-BLE BLE based Bluetooth MAC address scanner
BMS-O Ordinary Bluetooth MAC address scanner
CAV Connected and Automated Vehicles
CNN Convolutional Neural Network
CV Connected Vehicle
DDPG Deep Deterministic Policy Gradient
xiii
DQN Deep Q Network
DRL Deep Reinforcement Learning
GPS Global Positioning System
MAC Media Access Control
MAD Median Absolute Deviation
MARL Multi-Agent Reinforcement Learning
MORL Multi-Objective Reinforcement Learning
MVDS Microwave Vehicle Detection System
O/D Origin-Destination
OUATS Orlando Urban Area Transportation Study
RHODES Real-time Hierarchical Optimizing Distributed Effective System
RL Reinforcement Learning
RSSI Received Signal Strength Indicator
SCATS Sydney Coordinated Adaptive Traffic System SCOOT Split Cycle Offset Optimization Technique
SEB Speed Error Bias
SVM Support Vector Machine
TD-Learning Temporal Difference Learning
TOD Time of Day
UCF University of Central Florida
1
CHAPTER 1: INTRODUCTION
1.1 Background
Growing economy and population result in increasing travel demand that often goes beyond the capacity of the current traffic system. This leads to inevitable traffic congestion. Rather than building more roadways that might incur even more demand, a cost-effective approach to address this issue is improving the efficiency of traffic management, such as traffic signal control. Even frequently re-timed, the traditional pre-timed signal controllers, whose timing are determined by historical traffic information, might not be able to handle the dynamic traffic demand. To overcome these limitations, many adaptive traffic signal control systems (ATSC) were developed, such as Split Cycle Offset Optimization Technique (SCOOT), Sydney Coordinated Adaptive Traffic System (SCATS) and Real-time Hierarchical Optimizing
Distributed Effective System (RHODES). Those ATSCs use traffic detectors to acquire current traffic flow information, especially the turning movement counts, then feed them into models to forecast near-future traffic flow profiles and finally adjust the signal timing according to the prediction. These systems were seen as successful in multiple deployments around the world over the years.
The aforementioned ATSCs are fully based on “human-crafted” traffic flow features such as traffic volume, queue length, delay or travel time; “human-crafted” traffic flow models; and “human-crafted” signal control elements such as cycle length, offset, splits, and etc. Admittedly, all those “human-crafted” features are valuable human knowledge. Yet the complex, discrete and heterogeneous demand and behavior of the vehicles might be overlooked by the model-based
2
decision making and aggregated input data. Especially with the rapid development of connected vehicle (CV) technology, vehicles could provide their real-time information to signal controllers via vehicle-to-infrastructure (V2I) communication. Therefore, the vehicle-based data will be largely available in the foreseeable future. To fully utilize the high-dimensional-high-complexity information, many researchers proposed ATSCs based on one of the artificial intelligence (AI) algorithms, reinforcement learning (RL), to let the “machines” learn how to control traffic signals ((Samah El-Tantawy et al., 2014). Although, most of the traffic flow models and most of the signal control parameters are no longer needed in such ATSCs, unfortunately, due to the limited computational power of conventional RL algorithms, most of the studies still need to aggregate the discrete traffic information in some degree to generate the input of the RL algorithms.
Recently, due to the rapid development of deep learning, the so-called deep
reinforcement learning (DRL) algorithms incorporated with deep neural networks (DNNs) shows its ability to handle high-dimensional-high-complexity-disaggregated input data. Hence, ATSCs based on DRL are able to get rid of “human-crafted” traffic information and high-resolution traffic data such as the position, speed or even the origin and destination of individual vehicles could directly be used. Nevertheless, with the help of better hardware and the improved
computational power of DRL, ATSCs based on DRL have the ability to achieve the centralized control of the roadway network that conventional-RL-based ATSCs have never accomplished. The flexibility of the objective definition in DRL algorithm also enlightens the possibility to develop a multi-objective ATSCs, which could pro-actively improve the traffic operation and safety at the same time.
3
Several exploratory studies in the last three years (L. Li et al., 2016a; Lin et al., 2018; Van Der Pol & Oliehoek, 2016) shows the bright future of ATSCs based on DRL. However, most of the existing DRL-based ATSCs are not practice-ready. The reasons are two-fold. First, most of them did not prove their capability in controlling real-world traffic. They were
developed and evaluated in simplified traffic networks with hypothetical traffic demands.
Moreover, most of them require the complete information of the entire traffic system, such as the location, and/or the speed, and/or even the origin-destinations of all the vehicles within the network. This is not feasible in practice. Therefore, a DRL-based ATSC that is developed based on real-world traffic dynamics is desired. As the ATSC should use data from traffic detection systems and/or connected and automated vehicles (CAV) as input rather than assuming the complete information is known, necessary knowledge about traffic data is also desired.
Second, the impact of DRL-based ATSCs on traffic safety is a concern by researchers and practitioners but remains unclear (Wei et al., 2019). As the DRL algorithms provide a
flexible definition of its objectives, an ideal solution might be developing an ATSC that is able to simultaneously optimize traffic safety and efficiency.
1.2 Research Objectives
In order to fill the research gap mentioned in the previous section, the primary research objective of this dissertation is making DRL-based ATSC more implementable. The detailed objectives are listed as follows:
4
• Understanding the types of traffic data on arterials that can be utilized as the data feeds of DRL-based ATSC
• Developing algorithms to improve existing traffic data collection systems that could be used as the data feed of ATSC
• Developing a network-level ATSC algorithm based on decentralized Multi-Agent Reinforcement Learning (MARL) based on limited traffic information and real-world traffic dynamics
• Conducting an exploratory study on a multi-objective ATSC aiming at optimizing traffic safety and efficiency simultaneously in real-time
The first objective has been achieved in Chapter 3 by the following sub-tasks:
a) Reviewing traffic data collection systems used by the state-of-the-practice ATSCs or other types of traffic control systems
b) Identifying other data collection systems that could serve as the potential data feeds of ATSCs
The seconds objective has been achieved in Chapter 4 by the following sub-tasks:
c) Assessing the feasibility of using Bluetooth Low Energy (BLE) to obtain traffic counts in terms of the detection rate and range of BLE scanners.
d) Developing an algorithm based on BLE for estimating the counts of pedestrians and bicyclists
5
e) Formulating the traffic control problem into a multi-agent deep reinforcement learning setting
f) Developing the microscopic traffic simulation environment based on real-world traffic data
g) Training the DRL-based ATSC algorithm in the simulation and evaluate its performance by the emulated field traffic control system
The fourth objective has been achieved in Chapter 6 by the following sub-tasks:
h) Formulating the traffic control problem into a multi-objective deep reinforcement learning setting
i) Estimate the real-time crash model based on the historical traffic and crash data j) Developing the microscopic traffic simulation environment based on real-world traffic
data
k) Training the Multi-objective-reinforcement-learning-based ATSC algorithm in the simulation and evaluate its performance by the emulated field traffic control system and DRL-based ATSC developed in Chapter 5
l) Analyzing the control policies of the developed safety-oriented ATSC
1.3 Dissertation Structure
The rest of the thesis is organized as follow: Chapter 2 provides a comprehensive review of state-of-art RL algorithms and early studies developing ATSCs based on DRL; Chapter 3 reviews and evaluates traffic data collection systems that can serve as the data feeds of ATSCs;
6
Chapter 4 elaborates two machine learning frameworks that aim at improving vehicular and non-motorized traffic data; Chapter 5 presents an exploratory study of a network-level signal control algorithm using deep reinforcement learning in a decentralized approach; Chapter 6 introduces a multi-objective ATSC that is able to improve traffic efficiency and safety simultaneously. Finally, Chapter 7 summarizes the overall dissertation and presents the implications of the work.
7
CHAPTER 2: LITERATURE REVIEW
2.1 Deep Reinforcement Learning
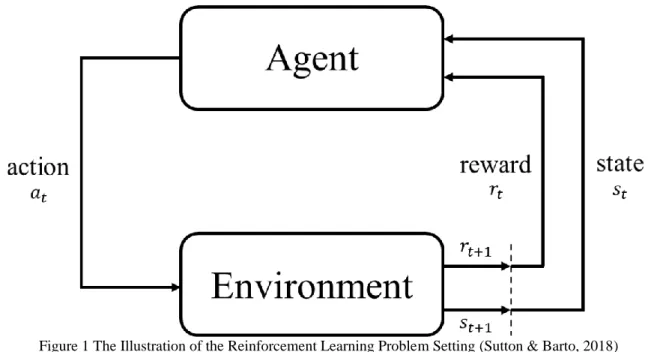
Deep Reinforcement Learning is a family of Reinforcement learning (RL) algorithms incorporated with Deep Neural Networks (DNNs). RL (Sutton & Barto, 2018) is a goal-oriented machine learning algorithm. It learns to achieve a complex goal over many discrete steps by interacting with the environment.
In the context of a control problem, in every discrete control step, an RL control agent
(e.g. signal controller) iteratively observes the states of the environment (e.g. roadway network), takes an actiona (e.g. directly change the signal phase or set the green duration of the signal phase) accordingly based on its underlying behavior policy π, receives a feedback reinforce
rewardr (e.g. waiting time, delay or travel time) for the action taken, which will be accumulated to its long-run goal (minimizing delay, decreasing travel time or minimizing stops), from the environment, and transits to the nextstate 𝑠′ according to the environment dynamics and state
transition probabilityP. The RL agent optimizes the policy, which is the mapping from the set of the all possible states S to the set of all possible actions A, by learning from the accumulated discounted long-term reward, with a discount factor γ, of applying different action sequences. During the learning process, it keeps adjusting its policy by maximizing the expectation of the long-term reward until it converges to the optimal policy 𝜋∗. Figure 1 gives an illustration of the
8
Figure 1 The Illustration of the Reinforcement Learning Problem Setting (Sutton & Barto, 2018)
The value function of the RL problem is the estimation of the long-term reward of each state or state-action pair. The state value is the expected long term discounted reward for following policy π from states, which is defined as:
𝑽𝝅(𝒔) = 𝑬[𝑹𝒕|𝒔𝒕 = 𝒔] (1)
and it decomposes into the Bellman equation:
𝑽𝝅(𝒔) = ∑ 𝝅(𝒂|𝒔) ∑ 𝑷(𝒔′, 𝒓|𝒔, 𝒂)[𝒓 + 𝜸𝑽
𝝅(𝒔′)] 𝒔′,𝒓
𝒂 (2)
The Q value, or action value, refers to the expected long-term discounted reward for selecting actiona and in states and then following the policy π, which is defined as:
9 and it also decomposes into the Bellman equation:
𝑸𝝅(𝒔, 𝒂) = ∑𝒔′,𝒓𝑷(𝒔′, 𝒓|𝒔, 𝒂)[𝒓 + 𝜸 ∑ 𝝅(𝒂𝒂′ ′|𝒔′)𝑸𝝅(𝒔′, 𝒂′)] (4)
If there are multiple objectives needs to be optimized, multi-objective reinforcement learning (MORL) should be used. In the context of MORL, multiple goals are optimized
simultaneously. In MORL, each objective has its associated reward and value function. Thus, Q-values are expressed as Q vector 𝑴𝑸𝝅(𝒔, 𝒂):
𝑴𝑸𝝅(𝒔, 𝒂) = [𝑸𝝅𝟏(𝒔, 𝐚), 𝑸𝝅𝟐(𝒔, 𝐚), … , 𝑸𝝅𝒏(𝒔, 𝐚) ]𝑻 (5)
Intuitively, the optimal Q vector is defined as
𝑴𝑸∗(𝒔, 𝒂) = 𝐦𝐚𝐱
𝒑 𝑴𝑸𝝅(𝒔, 𝐚) (6)
The “maximum operation” of a vector could have different definitions. Generally, there are two ways for MORLs handling the “maximum operation”: single-policy MORL approach and multi-policy MORL approach (C. Liu et al., 2015). Single policy approaches aim to find the best single policy representing the preferences or the trade-off among the objectives. Several different algorithms are developed to determine and express the preferences or trade-off, such as linear/non-linear weighted sum approach, W-learning, AHP approach, ranking approach, and geometric approach, etc. Multi-policy MORL aims at approximating the Pareto front by a set of policies. The Pareto front is a set of Pareto non-dominated solutions. If any objective of solution could not be improved without sacrificing at least one other objective, the solution is a Pareto non-dominated solution.
10
The most well-known algorithm family to learn the value functions is temporal difference (TD) learning. TD-learning and its extension TD(λ)-Learning (Sutton, 1988) learn the state value function 𝑉𝜋(𝑠), while SARSA (Singh & Sutton, 1996) and Q-Learning (Watkins & Dayan, 1992) learn the action value, or Q value. Among those algorithms, Q-Learning is the most common RL algorithm utilized in Adaptive Signal Control.
Q-learning is an off-policy algorithm, which means its policy being followed (the actioned chosen) is independent with its learning process. In Q-learning, the agent chooses the action 𝑎 ∈ 𝐴 with the highest value (greedy action) based on a matrix called table. The Q-table is a mapping Q-table of all discrete state value 𝑠 ∈ 𝑆 to all discrete action value 𝑎 ∈ 𝐴. At every discrete step, Q-learning improves its policy greedily. The adjusted Q-value is learned by
𝑸𝝅(𝒔, 𝒂) = ∑𝒔′,𝒓𝑷(𝒔′, 𝒓|𝒔, 𝒂)[𝒓 + 𝜸 ∑ 𝝅(𝒂𝒂′ ′|𝒔′)𝑸𝝅(𝒔′, 𝒂′)] (7)
where 𝑄𝑘 is the new Q-value after the adjustment at learning step k; 𝑄𝑘−1 is the current Q-value
stored in the Q-table; s, a, r are current state, action, and reward at step k; s’, a’ are the next state and action; α is the learning rate controlling the adjusting size.
Conventional tabular form Q-learning requires a Q-table to store Q-values for all (s, a)
pairs. However, when state set S (e.g. detailed representation of traffic states) is growing, the Q-table becomes extremely large, which makes the learning process intracQ-table (the curse of dimensionality). As a consequence, function approximation 𝑄(𝑠, 𝑎; 𝜃) (where 𝜃 is the hyper- parameters of the approximator) of the Q-table was introduced. Function approximation aims to generalize a “function” from examples to estimate the mapping. It is usually a concept of supervised learning. Linear function approximation is a popular choice before the age of deep
11
learning. However, the neural network was utilized dated back a long time ago (Bertsekas & Tsitsiklis, 1996).
Since the Q-values are estimated by a function, the learning process is no longer directly updating Q-value but updating the hype-parameters 𝜃. However, diverge and instability might occur when the neural network approximators are applied, especially for high-dimensional continuous state-action spaces (Tsitsiklis & Roy, 1997). It is because of the highly correlated consecutive states inputs and frequently changing policy due to slight changes in Q values.
Recently, Deep Q Network (DQN), one of the earliest DRL algorithm using deep neural networks (DNNs) as the functional approximator, shows its capability to deal with the large state-action space in RL problems (Mnih et al., 2015; Mousavi et al., 2018). Besides, it tackles the aforementioned instability and diverging issue by experience replay (LIN, 1993) and target network. Experience replay breaks the temporal correlation of states in the consecutive learning process. In every training step, the agent stores its ‘experience’ (𝑠, 𝑎, 𝑟, 𝑠′) into the experience
replay memory 𝜃 and then randomly samples a minibatch from it to update the 𝜃. In this way, the strong correlation between consecutive states is eliminated.
The target network also helps to mitigate the correlation issue. A target network is a DNN which has the same structure with the primary network (or value network) yet updates less
frequently. It is used to generate target-Q-value to update the hype-parameters 𝜃 of the primary network:
𝑱 = ∑ 𝑷(𝒔)(𝑸𝒕𝒂𝒓𝒈𝒆𝒕(𝒔, 𝒂; 𝜽−) − 𝑸(𝒔, 𝒂; 𝜽))
12
where 𝑃(𝑠) denotes the probability of the state s in the minibatch; 𝑄 and 𝑄𝑡𝑎𝑟𝑔𝑒𝑡 are Q-values estimated by primary network and target network respectively. 𝐽 is used as a loss function to update 𝜃 in backpropagation optimization. Every certain steps, the hyper-parameters of target network 𝜃− is updated by the hyper-parameters of primary network 𝜃. As a result, the loss function of the current training step is evaluated by an earlier snapshot, decorrelate the target and primary Q-values/state and increase the stability of the learning algorithm.
Double DQN (van Hasselt et al., 2015) is an improved version of DQN. In standard DQN, the selection of the greedy action and the evaluation of the Q-value are using the same action value (Q-value), which might lead to overoptimistic value estimates. van Hasselt et al. (van Hasselt et al., 2015) proposed to evaluate the greedy action by the online network but to estimate its value by the target network. This is achieved by modifying the calculation of the target Q value:
𝑸𝒕𝒂𝒓𝒈𝒆𝒕(𝒔, 𝒂) = 𝒓 + 𝛄𝑸 (𝒔′, 𝐚𝐫𝐠𝐦𝐚𝐱
𝒂′ (𝑸( 𝒔
′, 𝒂′; 𝜽)); 𝜽−) (9)
Double DQN is proved to be able to find better policies than standard DQN.
To get a faster converge, Wang et al. (Z. Wang et al., 2015) proposed the dueling DQN. The dueling DQN estimate the state value function and associated advantage function and then confine them to get the Q-value:
𝑸(𝒔, 𝒂) = 𝑽(𝒔; 𝜶) + [𝑨(𝒔, 𝒂; 𝜷) −|𝑨|𝟏 ∑ 𝑨(𝒔, 𝒂′; 𝜷)
13
where 𝑉(𝑠; 𝛼) is value function which indicates the expected overall rewards of a specific state
s; 𝐴(, 𝑎; 𝛽)is the state-dependent advantage of a specific action 𝑎 over other actions and it is then normalized by the average value of all actions 𝑎′∈ 𝐴. The performance of dueling DQN is shown better than the standard DQN especially when there exist several similar-valued actions.
However, one of the most serious problems of DQN algorithms is that it is hard for them to handle the case when the action set A (e.g. centralized network signal control) is extremely large or even continues. Since in continuous action spaces, finding the greedy policy requires optimization of a at each discrete timestamp. The optimization is too slow with large and unconstrained approximators like DNN (Lillicrap et al., 2015). There is another family of RL algorithms called policy-based methods is able to tackle this issue. Different from the value-based TD learning, policy-value-based methods optimized the function approximation of policy
𝜋(𝑎|𝑠; 𝜃) directly. The hyper-parameter 𝜃 of the approximation function is updated by gradient ascent on the expected long-term reward. REINFORCE (Williams, 1992) is a popular policy-based algorithm using policy gradient. However, the conventional policy gradient is relatively more stable than Q-learning but less efficient. Thus, the actor-critic algorithm (Sutton & Barto, 2018) takes advantage of both policy-based and value-based algorithm. The “critic” learns the hyper-parameters of action-value function while the “actor” learns the hyper-parameters of policy function. Asynchronous advantage actor-critic (Mnih et al., 2016) is a recently developed popular actor-critic algorithm based on DNN.
Another popular DRL based on actor-critic is Deep Deterministic Policy Gradient (DDPG) (Lillicrap et al., 2015). For the continuous action space, the so-called Deterministic Policy Gradient comes up with a deterministic policy rather than a stochastic policy as conventional
14
actor-critic algorithms, which is more efficient. Besides, with the help actor-critic structure, the DDPG avoids the optimization of a at each discrete timestamp. In addition, similar to DQN, DDPQ employs the experience reply and a “soft” updating target similar to the target network in DQN. The tests of the DDPG algorithm on some benchmark environments showed that DDPG can solve problems 20 times faster than DQN.
However, DDPG is still not the perfect solution to a continuous action space problem. There is a potential issue of all actor-critic-like algorithms is that learning rate of the actor and critic needs to be tuned very carefully to avoid inconsistent learning process. There are a few studies aiming at improving of DQN to make it suitable for continuous action space (Gu et al., 2016).
Deep reinforcement learning is a still active research domain. In terms of its application in the ATSC and ramp control, the DQN-like algorithms are suitable for ATSC of an isolated intersection and it could be applied decentralized network control. Whereas, actor-critic-like algorithms could be applied to adaptive ramp metering which might require a continuous ramp metering rate.
2.2 ATSC Based on Conventional Reinforcement Learning
The research use of RL as the back algorithm of ATSC dates back to the mid-1990s. As the best of the authors’ knowledge, Thorpe and Anderson (Thorpe & Anderson, 1996) firstly developed a traffic signal control algorithm using SARSA. Although its state, action and reward formulation are still crude, the evaluation shows that it outperforms the fixed timing plan by 29%
15
when it is implemented in a simulate 4×4 grid network. During the past two decades, a lot of researchers developed ATSCs based on different kinds of RL algorithms without the help of DNNs, which is classified as ATSC based on “conventional” reinforcement learning. A review of previous studies is given below.
2.2.1 Problem Formulation
Although, there are several studies developed and tested their ATSCs on an isolated intersection (Abdulhai et al., 2003; Arel et al., 2010; S El-Tantawy & Abdulhai, 2010; Shoufeng et al., 2008), surprisingly, the majority of the previous works developed ATSC for a roadway network. In addition, all the proposed ATSCs for network control are formulated as distributed multi-agent systems, which means each agent (signal controller) is autonomous and responsible for controlling only a signal intersection. The centralized system, which one signal controller controls the whole roadway network, is not preferred as it is computational extremely expensive to deal with such a large state-action space. Therefore, the Multi-agent Reinforcement Learning (MARL), which consists of a number of RL agents, is employed. In the context of MARL, each agent observes a partial state, makes independent actions to maximum its local rewards but learns and acts in the same environment.
However, the coordination between the autonomous agents is always a problem
especially sometimes the coordination between signal controllers is needed. Some studies tried to coordinate the neighboring agents by sharing information such as observed state (Balaji et al., 2010; S El-Tantawy & Abdulhai, 2010; Houli et al., 2010; Wiering, 2000; Wu et al., 2012) and reward or Q-value (Salkham et al., 2008; Vidhate & Kulkarni, 2017). Others (Monireh Abdoos et
16
al., 2014; Tianshu Chu et al., 2016; Jin & Ma, 2018; Kuyer et al., 2008; Xu et al., 2013) define a hierarchical learning structure that the lower level is the MARL and the upper level governs the communications between agents.
2.2.2 State Representation
The definition of state s will highly influence how the traffic control agent observes the environment. Traffic flow parameters are widely used in ATSCs by Conventional RL, such as: flow or vehicle counts (Balaji et al., 2010; Camponogara & Kraus, 2003; de Oliveira et al., 2006; Salkham et al., 2008; Thorpe & Anderson, 1996; Wiering, 2000), occupancy (de Oliveira et al., 2006; Jin & Ma, 2015; Salkham et al., 2008; Thorpe & Anderson, 1996), and speed (Kuyer et al., 2008). Current traffic signal status like current phase and/or the elapsed green time are also considered by some research (Aslani et al., 2017; S El-Tantawy & Abdulhai, 2012; Jin & Ma, 2015; LA & Bhatnagar, 2011; Lemos et al., 2018; Richter et al., 2007). Some measures of effectiveness (MOEs) are also employed such as queue length (M Abdoos et al., 2011; Abdulhai et al., 2003; Balaji et al., 2010; S El-Tantawy & Abdulhai, 2012, 2010; LA & Bhatnagar, 2011; Lemos et al., 2018; Vidhate & Kulkarni, 2017), the number of queued (waiting) vehicles and/or its waiting time (Aslani et al., 2017; Bazzan et al., 2010; Heinen et al., 2011; Vidhate &
Kulkarni, 2017) and delay (Arel et al., 2010; S El-Tantawy & Abdulhai, 2010; Shoufeng et al., 2008). Interestingly, the early works tend to depend more on traffic flow parameters while relatively recent works tend to utilize more MOE related parameters which directly influence the long-run goal or are even part of it. This implies the change from less to more model-based. It is expected the performance of the model should be better since in extreme cases, learning from
17
scratch is definitely more difficult than learning a deterministic function. However, the benefits of the model-free system will highly possibly decrease.
2.2.3 Action Definition
Action defines how the agent controls the signal. There are three major kinds of action definitions: directly change a specific (group of) signal indication (Abdulhai et al., 2003; Arel et al., 2010; Camponogara & Kraus, 2003; S El-Tantawy & Abdulhai, 2012, 2010; Houli et al., 2010; Khamis & Gomaa, 2014; Kuyer et al., 2008; LA & Bhatnagar, 2011; Lemos et al., 2018; Richter et al., 2007; Shoufeng et al., 2008; Thorpe & Anderson, 1996; Vidhate & Kulkarni, 2017; Wiering, 2000), find out the splits of phases for next (few) cycles (Monireh Abdoos et al., 2014; Aslani et al., 2017; Balaji et al., 2010; Salkham et al., 2008) and select a particular pre-defined signal timing plan from several candidates (Bazzan et al., 2010; de Oliveira et al., 2006; Heinen et al., 2011).
Directly changing the indication is the most flexible among all three. It makes the agent be able to respond to the traffic dynamic instantly (the decision step lasts typically one second). However, since it is acyclic, sometimes traffic of one specific direction might wait for the green light for a relatively long time. In addition, the acyclic phase structure will make the coordination between adjacent intersections difficult.
Setting the splits is less flexible since the phase sequence typically is fixed to form a cycle and the decision step lasts at least the length of the cycle. It is similar to forecast the traffic dynamics of the next cycle; therefore it might be more challenging due to the stochastic nature of
18
traffic. However, it makes the coordination relatively easier as long as the coordinated signals have similar cycle lengths and appropriate offsets.
Selecting a particular signal timing plan is the strictest one, and in certain cases, it could not adapt to the traffic dynamics.
2.2.4 Reward Definition
The long-run goal of a signal controller is either to minimize the delay and/or the number of stops or maximize the throughput (Actually they are MOEs of signalized intersections). (Note that the “goal” will be used to evaluate the performance of the control algorithms). Therefore, the reward is typically the discretized goal which is the total delay or the waiting time of the queued vehicles during a certain time period (actually it is the penalty) (Abdulhai et al., 2003; Arel et al., 2010; Balaji et al., 2010; Camponogara & Kraus, 2003; S El-Tantawy & Abdulhai, 2012, 2010; Jin & Ma, 2015; Salkham et al., 2008; Shoufeng et al., 2008; Thorpe & Anderson, 1996;
Wiering, 2000), stopped vehicles (Bazzan et al., 2010) or the discharged vehicles (Richter et al., 2007). And Khamis and Gomaa used all three MOEs to form a multi-objective reinforcement learning framework (Khamis & Gomaa, 2014). Some studies use queue length directly (Monireh Abdoos et al., 2014; de Oliveira et al., 2006; Heinen et al., 2011; Houli et al., 2010; LA & Bhatnagar, 2011; Vidhate & Kulkarni, 2017). While the number of vehicles discharged from the queue within a short time period is a good approximation of the delay, whether the queue could be to accumulate to a clear long-run goal is questionable.
19 2.2.5 Backend RL Algorithms
The majority of the previous research employed value-based RL algorithms such as Q-Learning (M Abdoos et al., 2011; Monireh Abdoos et al., 2014; Abdulhai et al., 2003; Arel et al., 2010; Balaji et al., 2010; Bazzan et al., 2010; Camponogara & Kraus, 2003; Tianshu Chu et al., 2016; de Oliveira et al., 2006; S El-Tantawy & Abdulhai, 2010; Samah El-Tantawy et al., 2014; Heinen et al., 2011; Jin & Ma, 2015, 2018; Khamis & Gomaa, 2014; Kuyer et al., 2008; LA & Bhatnagar, 2011; Lemos et al., 2018; Salkham et al., 2008; Shoufeng et al., 2008; Vidhate & Kulkarni, 2017; Wiering, 2000) and SARSA (Jin & Ma, 2015; Thorpe & Anderson, 1996), while only a few research used Actor-Critic (Aslani et al., 2017; Richter et al., 2007) which is the combination of value-based and policy-based RLs. A possible reason is that Actor-Critic requires a lot more computational resources than only value-based RLs. Therefore, as long as Q-Learning or SARSA have promising performance over the benchmarks, it is not necessary for researchers to use complicated actor-critic algorithms.
Since some studies use a large or even continuous state representation, for example, queue length, there might exists the curse of dimensionality. Some of those studies tackle the issue by function approximation like simple linear function (T Chu et al., 2016; LA & Bhatnagar, 2011; Vidhate & Kulkarni, 2017), tile coding (Monireh Abdoos et al., 2014; Aslani et al., 2017), K nearest neighbors (KNN) (Jin & Ma, 2018) and neural networks (Heinen et al., 2011). Some of those utilize model-based RL (Houli et al., 2010; Kuyer et al., 2008; Wiering, 2000) that Q-value is a pre-determined model of state and action based on human knowledge that is similar to RL with function approximation in some aspects. Others shrink the state space by fuzzy logic, for instance, categorize the continuous values into some levels (M Abdoos et al., 2011; Monireh
20
Abdoos et al., 2014; Arel et al., 2010; Balaji et al., 2010; Bazzan et al., 2010; S El-Tantawy & Abdulhai, 2010; Khamis & Gomaa, 2014). Admittedly, both function approximation and fuzzy logic lead to information loss. In order to reduce the loss as much as possible, fuzzy logic should be avoided and function approximation should be as complicated as possible.
2.2.6 Simulation
RL agents need training before the implementation like all other ML agents. None of the proposed RL-based ATSCs were trained in the real-world. It is obvious that no one could afford the cost of a non-mature signal control system. As a result, different kinds of simulation testbed are used by researchers, ranging from simple traffic simulators developed by the researchers themselves (Abdulhai et al., 2003; Camponogara & Kraus, 2003; Richter et al., 2007; Thorpe & Anderson, 1996; Wiering, 2000), open-source traffic simulators (Bazzan et al., 2010; de Oliveira et al., 2006; Heinen et al., 2011; Jin & Ma, 2015, 2018; Kuyer et al., 2008; LA & Bhatnagar, 2011; Lemos et al., 2018; Vidhate & Kulkarni, 2017), such as GLD (Camurri et al., 2006), ITSUMO (da Silva et al., 2006) and SUMO (Krajzewicz et al., 2012), to commercial traffic simulators (S El-Tantawy & Abdulhai, 2012, 2010; Xu et al., 2013) such as PARAMICS (Smith et al., 1995) and AIMSUN (Barcelo, 2018). Although open-source traffic simulators provide more flexibility for researchers to customize, the validity of the trained algorithms depends highly on how well the simulator could replicate the vehicle’s behavior in the real world.
21 2.2.7 Benchmark
Early exploratory studies might use random signals (Camponogara & Kraus, 2003). Almost all other previous studies use fix-timing signal control either hypothetical ones or those implemented in the real world as one of the benchmarks. Some study imitates commercial ATSC systems such as SCATS (Richter et al., 2007; Salkham et al., 2008), GLIDE (Balaji et al., 2010) SCOOT (S El-Tantawy & Abdulhai, 2012) as the benchmark since the technical details of aforementioned systems are prosperity. All the studies conclude that their proposed RL-based ATSCs outperform their different benchmarks.
2.2.8 Summary
Over the past twenty years, a number of researchers developed ATSCs based on conventional RL. The evaluation results show that the proposed ATSCs outperform the fix-timing signal control in terms of various MOEs.
However, the ATSCs based on conventional RL could be improved in several aspects. First of all, as mentioned in the previous sections, due to the curse of dimensionality, simple linear function approximation or fuzzy logic are employed to deduce the dimension of state space even though the information collected is very limited. Take a very simple isolated
intersection as an example. Assume an RL signal control agent controls a large intersection with four approaches. Each approach has three through lanes, one left-turning pocket lane and one right turning pocket lane. Two detectors are placed at the beginning and the end of each lane and only the actuation of the detector was collected as the state, which means there are no continuous states. The states of the intersection and its adjacent two intersections are collected to ensure the
22
coordination. Thus, the binary state values of a total of 120 detectors are used as the states. Therefore, there are totally 2120 ≈ 1.3 × 1036 different states. A Q-table is definitely impossible in this case. Take another example. If four levels of queue length (High, Medium, Low, No Queue) of all lanes are used, the state space (45×4×3 ≈ 1.3 × 1036) is also as large as the previous case. At the end of the day, the functional approximation is proved to be necessary for any realistic representation of the intersection. Furthermore, as the rapid development of connected vehicle technology, vehicle-based data will be largely available. Thus, the
complicated traffic states could be represented in a more detailed but nonlinear way. In the era of CAV, a linear function might not be suitable. A non-linear function like neural network make more sense but it is extremely hard to train (Tsitsiklis & Roy, 1997). As a result, both new function form and new training algorithms should be investigated.
Secondly, while there are several centralized successful model-based ATSC, for example, SCOOT (Bretherton, 1990), centralized model-free RL-based ATSC was seldom developed. Despite the benefits of the distributed multiple-agent system, intuitively, the coordination between intersections is never a problem a centralized system as the goal is naturally enhancing the performance of a roadway network as a whole. However, the curse of dimensionality would be even serious. On the one hand, the state space will increase exponentially. On the other hand, since the number of intersections controlled by the controller might be relatively large, the action space will also increase exponentially. While the large state space issue could be tackled by appropriate function approximation, dealing with large discrete action space in the context of signal control still need more research effort.
23
Thirdly, as discussed in the “Reward Definition” section, most of the previous works only focus on improving the efficiency of the traffic network. However, other important aspects such as safety and emission are overlooked. As a consequence, such factors should be considered as one of the multiple objectives. In order to implement such multi-objective system, the safety and environmental objectives should be carefully discretized into discrete rewards.
2.3 ATSC Based on Deep Reinforcement Learning
As discussed in section 2.2, the ATSCs based on Conventional RL need to be improved to response more complicated traffic dynamics, benefit the network performance by enhancing the coordination between the intersections, consider more factors as the goal of the control agent and adapt to the new era of connected and autonomous vehicles. The first step is developing a better approximator to account for high-dimensional state space. Recently, thanks to the rapid development of DRL which is able to handle the high-dimensional state space, several
researchers started to investigate how the DRL could improve the performance of ATSC.
Li, Lv and Wang (L. Li et al., 2016b) firstly conducted an exploratory study on ATSC Based on DRL for an isolated intersection. A four-layer deep stacked autoencoders was
employed as its function approximation. Although the state representation used in the proposed DRL control agent is still the queue length rather than more detailed representation of traffic dynamics, the evaluation results show that the proposed control algorithm could reduce the average delay of a simulated intersection by 14% than that with a conventional RL algorithm incorporating with a shallow neural network. Despite their great contribution as the pioneer, their
24
algorithms were trained and evaluated on a simplified simulated intersection. The intersection only has two phases and only allows through movements, which means the agent only needs to conduct a simple binary decision. And the signal might not be realistic enough since it does not configure the yellow and all-red clearance time.
Genders and Razavi (Genders & Razavi, 2016) firstly proposed a new state structure to represent the detailed complex traffic dynamics in replace of aggregated traffic flow parameters. Each lane approaching the intersection is segmented into several small cells and the present and the average speed of vehicles on the cell are used to represent the traffic dynamics. This
approach is similar to the “virtual loop detectors” widely used in the computer-vision-based vehicle detectors. Several other studies (der Pol & Oliehoek, 2016; Gao et al., 2017; Liang et al., 2018; Mousavi et al., 2017; Muresan et al., 2018) also utilized.
Although most of the recent studies (Gao et al., 2017; Genders & Razavi, 2016; L. Li et al., 2016b; Liang et al., 2018; Mousavi et al., 2017; Muresan et al., 2018) focus on controlling the isolated intersections, van der Pol and Oliehoek (Van Der Pol & Oliehoek, 2016) firstly implements the distributed MARL using DRL signal control agent on very small grid networks with two to four intersections. The coordination between the DRL agents is achieved by max-plus coordination and transfer planning. The evaluation shows the proposed algorithm is superior to those with a shallow neural network. However, the contribution of the study is limited by its unrealistic traffic simulation. The proposed algorithm only trained and evaluated in an
25
With the help of DNN, Tan (Tan, n.d.) firstly tried to develop a centralized signal control algorithm for a 3×3 grid network. Unfortunately, the algorithm is not evaluated by any MOEs, therefore, its validity is questionable. Lin et al. also proposed a centralized ATSC (Lin et al., 2018) based on DRL also for a 3×3 grid network. To tackle the possible large action space issue, the authors predefined a four-phase signal structure with a fixed sequence and the agent is only able to choose to either maintain the current phase or change to the next one. Thus, the action space collapse to only 512 actions which is manageable with scarifying the flexibility to skip the phases without any demand. As a result, it is expected that the evaluation results clearly show that the proposed algorithm outperforms the simple actuated signal control only for the saturated condition.
In terms of DRL algorithms employed, the majority of the previous studies utilized DQN like algorithms (Gao et al., 2017; Genders & Razavi, 2016; L. Li et al., 2016b; Liang et al., 2018; Mousavi et al., 2017; Muresan et al., 2018; Van Der Pol & Oliehoek, 2016) and others used actor-critic-like algorithms such as DDPG (Casas, 2017; Tan, n.d.) and Advantage Actor-Critic (A2C) (Lin et al., 2018). The possible reason for the popularity of DQL is that it is
computationally less expensive than actor-critic-like algorithms. However, it is not able to deal with large or continuous action space for centralized systems. Therefore, for all the studies aiming at developing a centralized system, actor-critic-like algorithms and necessary hardware are required.
It is great to see the computational power and bright future of ATSC based on DRLs, the current studies also show several limitations.
26
Firstly, ATSCs based on DRL are intensively validated to be effective for isolated
intersections, its effectiveness of network-wide signal control, especially for arterial networks, is not proven. Van der Pol and Oliehoek’s work (Van Der Pol & Oliehoek, 2016) is merely
effective for up to four intersections allowing only through movements. Casas (Casas, 2017) tested a DRL algorithm for a network-level signal control for a real roadway network in Barcelona. But unfortunately, his/her algorithm does not converge.
Secondly, the centralized DRL controller still needs to be further investigated. As
discussed in previous contexts, there is still no effective systems even for an urban gird network. The headache large action space is a potential issue. More advanced DRL algorithms and more reasonable agent design are expected.
Thirdly, as the simulation is inevitable and crucial, the traffic simulation scenarios used by the previous studies are unsatisfactory. Some of them used in early studies are far away from any real-world applications. The intersection geometric design is not considered. The urban grid network is designed with a constant number of lanes or even with a constant length. Some of them do not have turning lanes or even prohibit the turning movement. Others with turning lane do not consider the length of the turning storage bays. The traffic demand is hypothetical, and the route choice behavior is simplified. The only exception is Casas’s work (Casas, 2017) using a real-work network, but again his/her algorithm does not converge. The benchmark signal control system is an arbitrary fixed-timing signal, signal controlled by a conventional RL algorithm incorporating with a shallow neural network which is never be applied in the field, or even random signals. (The only exception is the study conducted by Muresan et al. (Muresan et al., 2018) which used a calibrated timing by Synchro based on hypothetical traffic demand.) No
real-27
world signal timing plans were used as the benchmark like the study of El-Tantawy and Abdulhai (S El-Tantawy & Abdulhai, 2012). As a consequence, the effectiveness of those algorithm on the real-world application is hard to evaluate.
Last but not the least, the ATSCs have to be acceptably safe to be implemented in the field. Existing studies neither evaluated the safety effects of their proposed ATSCs nor developed ATSCs that consider safety effects explicitly. Therefore, the impact of DRL-based ATSCs on traffic safety is still concerned yet unclear.
2.4 RL-based ATSC with multiple objectives
Some studies have proposed RL-based ATSC with multiple optimization objectives. Based on the way to achieve the multi-objective optimization, they could be classified into three different types.
The first type is an ATSC which is able to switch its objective dynamically. Houli et al. (2010) developed an ATSC with three different backend single-objective RL algorithms with different goals. But only one algorithm is activated according to the traffic condition. When the current traffic condition is free flow, the goal of the activated algorithm is minimizing the number of stops. When it is under medium traffic condition, the goal turns to minimize the overall waiting time. When there exists congestion, the goal is switched to minimize queue length to avoid queue spillover. This type of ATSC could be regarded as an ensemble of rule-based AI and RL. However, it might be not suitable if the objectives are required to be optimized simultaneously.
28
The second type of algorithms creates a synthetic reward to represent multiple objectives simultaneously. The most straightforward approach is using the simple/weighted average of multiple rewards. Each reward is associated with a goal. Khamis and Gomaa (2014) proposed an ATSC with 7 different objectives. Five of them indicate different aspects of traffic efficiency, one represents the fuel consumption and the last one is claimed to be “safety reward”. The so-called safety reward is not any safety measure but essentially the average speed of the vehicles. The potential issue of this type of algorithm is that its convergence is not thematically proved since the synthesizing reward is no longer the decomposition of any policy goals. It should be noted that the reward of several single-objective ATSCs (Muresan et al., 2018; Van Der Pol & Oliehoek, 2016; Vidhate & Kulkarni, 2017) could also be the average of several components.
The third type of algorithm is multi-objective RL (MORL). Although similar to the second type, MORL manipulates the value function (e.g. Q functions)rather than the rewards. In such algorithms, different value functions are learned independently using different rewards, while the second type of algorithms learns a signal value function by the single synthetic reward. This is beneficial to the convergence of the algorithm especially when the objectives are
irrelevant. For a multi-objective ATSC using the aforementioned algorithm, the control agent could either choose the action based on the weighted average of multiple value functions or use one or more of themas the thresholds. The study conducted by Jin and Ma (2015) utilized the later method to assign priority to arterials.
29
2.5 ATSC Considering Traffic Safety
Improving traffic safety is one of the most important objectives for transportation agencies (Lee et al., 2019; P. Li et al., 2020; M. H. Rahman et al., 2019; M. S. Rahman et al., 2019a, 2019b; Yue et al., 2018, 2019, 2020; Zhang et al., 2020). There have been several studies on optimizing signal timing considering traffic safety (Stevanovic et al., 2013, 2015; Zhu et al., 2019). Almost all of them employed surrogate safety measures as the safety indicator and all these studies focused on fixed-timing controllers. The burden of extending such fixed-timing controllers to safety-oriented ATSC is that the most modern ATSCs are designed to be pro-active/predictive. In other words, the ATSC needs to know how the signal timings affect the future safety condition. Therefore, to use the surrogate safety measures (e.g. traffic conflicts) as the safety indicator, a prediction model of the future surrogate safety measures needs to be developed.
To the best of the authors’ knowledge, only one published study (Sabra et al., 2013) developed a non-parametrical traffic conflict prediction model and proposed a safety-oriented ATSC accordingly. The study developed a four-stage algorithm tuning the cycle length, splits, offsets, and left-turn phase sequence sequentially. At each stage, the “predicted” number of traffic conflicts is used to evaluate the signal timing tuned by the control algorithm. If the “predicted” traffic conflict of new signal timing is greater than that of the current one, the
controller keeps using the current signal timing. Otherwise, the new signal timing is applied. The proposed algorithm is tested in a simulated real-life arterial corridor and a simulated real-life grid network. For the arterial case, although the proposed algorithm reduces the number of traffic conflicts compared with a coordinated actuated signal optimized by the authors, it does increase
30
the number of traffic conflicts compared with the existing field controllers. For the grid network, the algorithm increases the number of traffic conflicts compared with a coordinated actuated signal optimized by the authors, and no testing results of the existing field operation are provided. Therefore, the ability of the proposed algorithms in improving traffic safety is not conclusive.
2.6 Summary
During the past two decades, substantial studies have developed RL-based ATSCs. Most of them perform better than the fixed-timing signals. Due to the curse of dimensionality,
conventional RL-base ones utilize fuzzy logic to simplify the control problem. It might lead to its failure for complicated traffic conditions. And they might not be able to directly employ the heterogeneous data from CAVs as their input data. DRL-based ATSCs successfully resolve the issues by employing non-linear neural networks as its functional approximator. However, the existing DRL-based ATSCs did not prove their capability in controlling the real-world traffic at the network level. Besides, their impact on traffic safety remain unclear.
31
CHAPTER 3: TRAFFIC DATA COLLECTION SYSTEMS ON
ARTERIALS
3.1 Introduction
The capability of a traffic signal control system in handling dynamic traffic demands depends on how well it perceives the traffic demands. The fixed-timed signal does not capture the traffic dynamics and the actuated signal control only captures the presence of the traffic. Therefore, they could not well respond to dynamic traffic demands. Although knowing the real-time traffic condition is crucial, most of the existing DRL-based ATSCs go to another extreme as they assume the traffic information of every individual vehicle is known. This unrealistic
assumption prevents the implantation of based ATSCs in the field. Thus, to make the DRL-based ATSCs more implementable, they should utilize traffic data collection systems to perceive the real-time traffic condition. Therefore, existing traffic data collection systems and those will be available in the near future that are also to serve as the data feed of ATSCs should be understood.
3.2 Counts Data from Infrastructure-based Detectors
Traditional actuated traffic signal control systems require traffic detectors to inform the controller that there is a user requests service. Inductive loop detectors are widely used to detect the vehicles’ presence, and it could also be replaced by video detectors or microwave detectors (Arroyo et al., 2015). Inductive loop detectors detect the magnetic presence of a vehicle while video-based and microwave detectors are able to create “virtual loops” to detect the presence of a
32
vehicle. If the vehicles’ presence is recorded and aggregated, vehicular traffic counts data are available from those detectors designed for the signal actuation.
One of the most famous data systems utilizing the actuation data is Automated Traffic Signal Performance Measures (ATSPM). ATSPM is employed to measure the actual
performance of the traffic signal control systems and provide information for re-timing. In fact, ATSPM data consist of high-resolution monitoring logs of traffic signals which is not limited to the vehicle’s actuation. The logs have a simple data structure with only three attributes:
timestamp, event type and event parameter (for signifying detector numbers and phases). The events recorded in the log include active phase event (phase on, phase green, etc.), active pedestrian event, detector event (detector on/off), barrier/ring events, phase control events, overlap events, preemption events, coordination events, and cabinet/system events. ATSPM event log data provide rich information about the traffic condition and traffic signal performance on arterials. The actual signal phase sequence and phase timing are able to be estimated from the active phase events, the volume per lane per phase is able to be estimated from the detector events, and other signal performance measures such as queue length, v/c ratio and etc. The ATSPM could provide high-quality data inputs for ATSC, however, the deployment of such systems is really limited across the nation.
State-of-the-practice ATSCs use a combination of detection layouts to estimate the current traffic states, which is later used to adjust traffic control in a network (Board & National Academies of Sciences and Medicine, 2010). Most of the ATSCs require additional detectors beyond those used in the conventional actuated signal control systems to provide good traffic
33
measures for its adaptive control logic. For example, they employ advance detectors to estimate queue length.
In term of the detection technology, most of the state-of-the-practice ATSCs do not require using a specific detection technology as long as they could provide the required data. According to an international survey (Board & National Academies of Sciences and Medicine, 2010), more than 90% of implemented ATSCs utilize inductive loop detectors and no more than half of the implemented ATSCs use video detection systems. In fact, the majority of the state-of-the-practice ATSCs assume the conventional loop detectors as the defect detection technology. The major reason is to fully utilize the detectors of existing conventional actuated signal controllers to reduce the deployment cost. However, there does exist one ATSC, which are implemented widely across the nation, use video detection as its default detection technology. It fully utilizes the flexibility of the video detection system to acquire the lane-based traffic counts, the maximum waiting time and the queue length of each phase.
3.3 Bluetooth Detection System (BDS)
In recent years, traffic agencies have begun to implement Bluetooth detection systems (BDS) to collect travel time and origin-destination data on arterials in real time (Chung et al., 2020). BDS employed Bluetooth technology to detect the vehicles carried with a Bluetooth device (e.g. smartphones and hand-free devices). The advantages of BDS are its relatively low-installation and maintenance cost (Singer et al., 2013) and acceptable data quality (Bhaskar & Chung, 2013; Haghani et al., 2010).
34
BDS estimates origin-destination on urban arterials and freeways(Friesen & McLeod, 2015) by tracking the trajectory of detected devices. A number of studies have also investigated the feasibility of BDS to estimate the number of travelers. However, the most critical issue is that BDS tends to either underestimate or overestimate the number of travelers. First, as pointed out by several studies (Abedi et al., 2015; Bullock et al., 2010; Malinovskiy et al., 2012), the detection rate of such systems is relatively low. Because the Bluetooth MAC address scanner (BMS) using ordinary Bluetooth protocol could only detect the “discoverable” devices.
Typically, newer Bluetooth devices are in the discoverable mode only for the initial connection to enhance security and protect privacy. Thus, although we could assume that the penetration rate of the Bluetooth device is high enough because of the popularity of smartphones, most of them are not always discoverable, which reduces the number of travelers that could be detected by BMS. Second, the number of detected MAC addresses might be greater than the number of detected travelers. The duplicate detection issue occurs when a traveler carries two or more devices. It might lead to overestimating the actual counts. The issue would be more severe for estimating vehicular counts, as there could be multiple passengers in a vehicle, especially when there exist many transit buses. In addition, in order to save budget, ensure the power supply and increase the detection rate, for arterials, Bluetooth detectors are installed within or close to the signal cabinet near the intersection. And the detectors are configured to be able to detect all the “discoverable” vehicles within the intersection. Thus, a single vehicle could be detected by a specific detector more than once within a short period of time due to the large detection range (typically 300 to 400 feet). This leads to a location ambiguity and increases the error of travel time estimation (Araghi et al., 2013; José et al., 2015). Moreover, in an extreme case, when the
35
detection ranges of two detectors overlap, a single Bluetooth device could be seen
simultaneously by both detectors. The “ping-pong” effect might lead to detecting a traveler at the adjacent intersections, especially in the urban area where intersections are spaced closely. Third, as pointed out earlier, theoretically, it takes up to 10.24s for a Bluetooth device to be
“discovered” by the Bluetooth detectors (Kasten & Langheinrich, 2001). If the speed of a vehicle is high enough, it might not be detected.
3.4 Vehicle-Based Traffic Data
Probe vehicles are one of the most effective methods for collecting traffic data. State-of-the-practice probe-vehicle based data collection systems use the position and speed reported by the global positioning system (GPS)-equipped probe vehicles. Private sector traffic service companies such as INRIX, HERE and TomTom take advantage of probe vehicle tracking technologies to provide speed and travel time data of the road network including most of the arterials. The major advantage of the vehicle-based data from the private sectors is that the vendors are able to provide more extensive geographic data coverage than any kind of infrastructure-based traffic data. To benefit from this, one recent study (Sharma et al., 2019) employs the vehicle-based travel time (speed) data from the private sectors to develop a rule-based ATSC. The proposed ATSC first forecast the near-future speed using a single exponential smoothing technique. Then a multivariable linear regression model is developed by utilizing forecasted link-level speed, signal control variables, and link length as predictors to estimate traffic flow parameters. A simple signal timing algorithm uses the forecasted traffic flow parameters to generate an optimized signal timing. The study indicates that the widely available
36
travel time data could be used as a valuable input of ATSCs. However, there is often a concern that the exact data source and processing algorithms are always proprietary (Elefteriadou et al., 2014).
Connected vehicles (CV) are another source of vehicle-based data. Several studies (Feng et al., 2018; Goodall et al., 2013; Joyoung et al., 2013) have employed CV’s trajectory data as the ATSC’s input. However, the proposed ATSCs requires a relatively high market penetration rate. The least market penetration rate of CV required by these ATSCs is around 10% (Feng et al., 2018). Until March 2020, there is no ATSC based on the CV is implemented in the field.
3.5 Summary
Existing traffic data collection systems in the field include traffic counts from inductive loop detectors installed for signal actuation, travel time and origin-destination data from BDS and segment-based speed data from the private sectors. However, the infrastructure-based
systems, either the inductive loop detectors or BDS, is limited in terms of geographical coverage. Thus, the widely available segment-based speed data from the private sectors could be served as valuable data feeds of ATSCs.
Most of state-of-the-practice ATSCs requires customized detection layout for their own control logic. Especially some vendors depend on the video detection systems. The rapid development of CV brings the opportunity for ATSCs to use the vehicle’s trajectory as its input data. However, there is still no ATSC based on the CV is implemented in the field until March 2020.