© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal
| Page 2890
Implementation of Sentimental Analysis of Social Media for Stock
Prediction in Big data
1
Er.Rooplal Sharma,
2Dr.Gurpreet Singh,
3Er.Baljinder Kaur
1
Head of Department,
2Director-cum-Principal,
3M.tech Student
1, 2, 3
Department of CSE,SSIET (Jal.)
---***---Abstract:- This paper covers plan, usage and assessment of a framework that might be utilized to anticipate future stock costs basing on examination of information from web-based social networking administrations. Twitter platform is used for the collection of datasets and stock market prediction is done with company apple datasets. The Data was gathered amid three months and handled for advance investigation. The sentimental classification is used for coming data from social networks in order to predict future stock prices using the ARIMA model .Assessment and discourse of consequences of expectations for various time based are discussed here:
Keywords: Sentiment Analysis, Big Data Processing,
Social Networks Analysis, Stock Market Prediction.
INTRODUCTION:-
It is trusted that data is the wellspring of energy. Late years have demonstrated not just a blast of information, in any case, likewise far reaching endeavors to break down it for handy reasons. PC frameworks work on information measured in terabytes or even petabytes and the two clients and PC frameworks at fast pace always create the information. Researchers what's more, PC engineers have made extraordinary term "enormous information" to name this pattern. Primary components of huge information are volume, velocity and variety. Volume remains for vast sizes, which can't be effectively prepared with customary database frameworks what's more, single machines. Velocity implies that information is always made at a quick rate and variety compares to various structures, for example, content, pictures and recordings. There are a few reasons of an ascent of enormous information. One of them is the expanding number of cell phones, for example, cell phones, tablets and PC portable workstations all associated with the Internet. It enables a large number of individuals to utilize web applications and administrations that make enormous measures of logs of movement, which thus are assembled and prepared by organizations.
Enormous size of information and the reality it is by and large not well organized outcome in circumstance that ordinary database frameworks and investigation devices
are not sufficiently proficient to deal with it. Keeping in mind the end goal to handle this issue a few new strategies extending from in-memory databases to new processing ideal models were made. Other than huge size, the examination and understanding are of primary concern and application for huge information viewpoint partners. Investigation of information, otherwise called information mining, can be performed with various procedures, for example, machine learning, counterfeit consciousness and insight.
A. Big data:
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal
| Page 2891
B. Social media
One of the patterns prompting ascent of huge information is Web 2.0. It is a noteworthy move from static sites to intuitive ones with client created content (UGC). Advancement of Web 2.0 brought about many administrations, for example, blogging, podcasting, person to person communication and bookmarking. Clients can make and share data inside open or shut groups and by that adds to volumes of enormous information. Web 2.0 prompted making of online networking that now are implies of making, contributing and trading data with others inside groups by electronic media. Social media can be likewise outlined as "based on three key components: substance, groups and Web 2.0" . Each of those components is a key factor and is important for social media. A standout amongst the most essential components boosting social media is expanding number of dependably Internet-associated cell phones, for example, cell phones and tablets. Twitter is a miniaturized scale blogging stage, which consolidates components of websites and interpersonal organizations administrations. Twitter was built up in 2006 and experienced fast development of clients in the primary years of operations. Right now it has more than 500 million enrolled clients and more than 200 million dynamic month to month clients . Enrolled clients can post and read messages called "tweets"; each up to 140 Unicode characters long – started from SMS transporter restrict. Unregistered clients can just view tweets. Clients can build up just take after or be followed connections. Twitter is a typical PR specialized device for government officials and different VIPs molding, or, then again having sway on the way of life and society of vast groups of individuals. In this way Twitter was decided for exploratory information hotspot for this work on anticipating stock advertise.
II. Sentiment analysis and predict future stock prices
A. Experimental System Design and Implementation
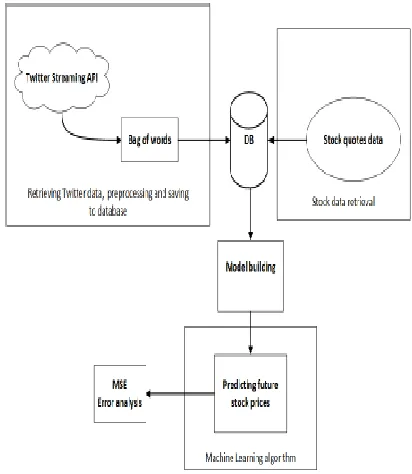
Principle objective of this area is to depict usage of a framework foreseeing future stock costs basing on supposition location of messages from Twitter smaller scale blogging stage. Dissimilar to the creators of we picked Apple Inc. – a surely understood buyer hardware organization – a maker of Macintosh PCs, iPod, iPad, iPhone items and supplier of related programming stages and online administrations just to name a maybe a couple. Framework configuration is displayed on Figure 1 and it comprises of four parts: Retrieving Twitter information, pre-handling what's more, sparing to database (1), stock information recovery (2), demonstrate building (3) and
[image:2.612.343.549.124.361.2]anticipating future stock costs (4). Each part is portrayed later in this content.
Figure 1: Design of the framework
1. Recovering Twitter information, pre-handling and sparing to database. This part is in charge of recovering, preprocessing information and get ready preparing set. There are two naming strategies utilized for building preparing set: manual and programmed.
2. Stock information recovery :-Stock information is accumulated on an every moment premise. A short time later it is utilized at evaluating future costs. Estimation depends on order of tweets (utilizing notion examination) and contrasting and real incentive by utilizing Mean Squared Error (MSE) measure.
3. model building:- This is used for the classification of sentiment emoticons for the analysis of sentiment.
4. Anticipating future stock costs :-This part joins aftereffects of feeling location of tweets with past intraday stock information to assess future stock esteems.
B. Twitter data acquisition and pre-processing:-
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal
| Page 2892
probability of separating tweets as indicated by a few classifications, for example, area, dialect, hashtags or words in tweets. One detriment of utilizing Streaming API is that it is incomprehensible to recover tweets from the past along these lines. Tweets were gathered more than 3 months time frame from april 2017 to july 2017 . It was determined in the inquiry that tweets need to contain name of the organization or hashtag of that name. For instance in the event of tweets about Facebook Inc. following words were utilized as a part of inquiry 'Apple', '#Apple', "AAPL" (stock image of the organization) and '#AAPL'. Tweets were recovered for the most part for Apple Inc. (exchanged as 'AAPL') to guarantee that
datasets would be adequately substantial for
arrangements. Recovered information contains a lot of commotion and it is not specifically reasonable for building grouping model and after that for conclusion discovery. With a specific end goal to clean twitter messages a program in R programming dialect was composed. Amid preparing information strategy following strides were taken. Dialect location data about dialect of the tweet is not generally right. Just tweets in English are utilized as a part of this look into work. Copy expulsion - Twitter permits to repost messages. Reposted messages are called retweets. From 15% to 35% of posts in datasets were retweets. Reposted messages are repetitive for arrangement and were erased. After pre-preparing each message was spared as sack of words demonstrate – a standard method of rearranged data portrayal utilized as a part of data recovery.
C. Sentimental Analysis
Not at all like established strategies for anticipating macroeconomic amounts expectation of future stock costs is performed here by consolidating after effects of assumption order of tweets and stock costs from a past interim. Assumption examination is otherwise called assessment mining alludes to a procedure of extricating data about subjectivity from a printed input. To
accomplish this it consolidates methods from
characteristic dialect handling also, printed examination. Abilities of supposition mining permit deciding if given literary info is objective or subjective. Extremity mining is a piece of supposition in which input is characterized either as positive or negative. Because of two classifiers were acquired utilizing physically named dataset. To start with classifier decides subjectivity of tweets. At that point extremity classifier orders subjective tweets, i.e. utilizing just positive and negative and precluding unbiased ones. Keeping in mind the end goal to utilize characterization result for stock expectation term: 'feeling esteem' (meant as a ɛ) was presented - it is a logarithm at base 10 of a proportion of positive to negative tweets .
number _ of _ positive_ tweets
ε = log10
number _ of _ negative_ tweets
In the event that ɛ is certain then it is normal that a stock cost is going to rise. If there should be an occurrence of negative ɛ it demonstrates likely value drop.
In order to predict the stock prices we use the arima models which is described as:
Yt =ϕ1Yt−1 +ϕ2Yt−2…ϕpYt−p +ϵt + θ1ϵt−1+ θ2ϵt−2 +…θqϵt−q
Where, Yt is the differenced time series value, ϕ and θ are
unknown parameters and ϵ are independent identically
distributed error terms with zero mean. Here,Yt is
expressed in terms of its past values and the current and past values of error terms.
III. Result And Analysis
Prediction ere prepared using the dataset of time interval of stock prices and the forecast was prepared. Prediction were conducted using the two tweets dataset were used .one with message contain company stock symbol ‘AAPL’ and the other data set included only the tweet contains name of the company i.e ‘Apple’. Training dataset consisted of million tweets with stock symbol and number of million tweets with company name accordingly. tweets used for prediction were retrieved from April to July 2017.
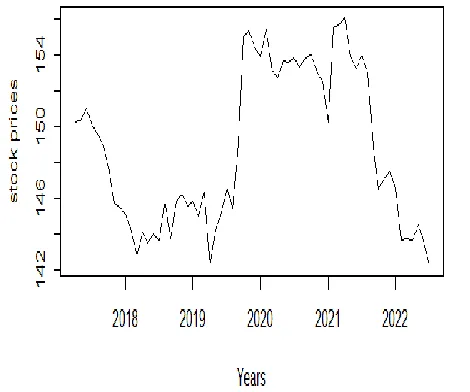
[image:3.612.336.571.447.643.2]Experiment were conducted using the arima model with the following :
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal
| Page 2893
Figure :- 3 DifferencedLog (Stock prices) in relative to years
Fig :- 4 Autocorrelation Function of stock prices
Fig :- 5 Partial Correlation Function of stock
Training set error measures:
ME RMSE MAE MP
E MAPE MASE ACF11
0.000337 0.0050
253 0.003602 0.015
85 1
0.1658
54 0.241 6 6
0
[image:4.612.313.582.108.405.2]0.00888 1
Figure :- 6 Prediction Result (Stock prices) in future (years related)
The function accuracy gives you multiple measures of accuracy of the model fit: mean error (ME), root mean squared error (RMSE), mean absolute error (MAE), mean percentage error (MPE), mean absolute percentage error (MAPE), mean absolute scaled error (MASE) and the first-order autocorrelation coefficient (ACF1)
Discussion of result:-
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal
| Page 2894
asset for assessment feeling mining. It empowered to make greater preparing datasets, which brought about constructing more exact models. Last factor that is essential for expectation is number of showing up messages per time interim. It is additionally vital to take note of that stock expectation techniques are not ready to foresee sudden occasions called 'dark swans'
Conclusion:
This paper talks about a probability of making forecast of securities exchange basing on characterization of information coming Twitter smaller scale blogging stage. Consequences of forecast, which were exhibited in past area demonstrate that there is relationships between's data in social administrations and stock showcase. There are a few factors that influence precision of stock forecasts. As a matter of first importance decision of datasets is exceptionally vital. In the paper two sorts of datasets were utilized one with name of the organization and the other with stock symbol. Expectations were made for Apple Inc. with a specific end goal to guarantee that adequately huge datasets would be recovered. There were huge contrasts in estimate between these two sets. In the event of tweets with stock symbol there is greater likelihood that individuals who presented are relating on stock costs. Forecasts can be enhanced by Adding examination of metadata, for example, correct area of a man while posting message, number of retweets, number of supporters and so forth. Including examination of other may contribute to more precise expectations.
References:-
1. Andrzej romanowski et al: sentiment analysis of
twitter data Proceedings of the Federated Conference on Computer Science and Information Systems pp. 1349–1354 DOI: 10.15439/2015F230 ACSIS, Vol. 5 IEEE 2015
2. R. Suresh ramanujam et al: sentiment analysis
using big Data 2015 international conference on computation of power, energy, information and communication 2015 IEEE
3. Arock et al., International Journal of Advanced
Research in Computer Science and Software Engineering 5(9),September- 2015, pp. 590-595 IJARCSSE
4. Modha et al., International Journal of Advanced
Research in Computer Science and Software Engineering 3(12),December – 2013 IJARCSSE
5. Indumathi S1, Shreekant Jere A Survey on Stock
Prediction with Statistical and Social
Media Analytics (IRJET) e-ISSN: 2395 -0056 April 2016
6. Ramesh R Big Data Sentiment Analysis using
Hadoop IJIRST –International Journal for Innovative Research in Science & Technology| Volume 1 | Issue 11 | April 2015
7. https://dev.twitter.com/docs/api/1.1/post/statu
ses/filter
8. https://dev.twitter.com/docs/auth/oauth
9. http://json.org/