Procedia Computer Science 18 ( 2013 ) 1684 – 1689
1877-0509 © 2013 The Authors. Published by Elsevier B.V.
Selection and peer review under responsibility of the organizers of the 2013 International Conference on Computational Science doi: 10.1016/j.procs.2013.05.336
International Conference on Computational Science, ICCS 2013
Cost-Sensitive Support Vector Machine for Semi-Supervised
Learning
Zhiquan Qi
a, Yingjie Tian
a,∗, Yong Shi
a,∗, Xiaodan Yu
baResearch Center on Fictitious Economy&Data Science, Chinese Academy of Sciences, Beijing 100190, China bCollege of Information Science&Technology, University of Nebraska at Omaha, Omaha, NE 68182, USA.
Abstract
Cost-sensitive learning has been a hot research topic in machine learning. Many cost-sensitive methods have been successfully applied in many real-world applications such as disease diagnosis, fraud detection and business decision making. In this paper, we proposed a new Cost-Sensitive Laplacian Support Vector Machine(called Cos-LapSVM) , which can deal with the cost-sensitive problem in Semi-Supervised Learning. The effectiveness of the proposed method is demonstrated via experiments on UCI datasets.
Keywords: SVM, Cost-Sensitive, Semi-Supervised Learning
1. Introduction
Semi-Supervised Learning (SSL) [1, 2, 3] has attracted an increasing amount of interests in machine learning [4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]. One main reason is that the labeled examples are always rare but there are large amount of unlabeled examples available in many practical problems. Several novel approaches for making use of the unlabeled data to improve the performance of classifiers have been proposed. Graph based methods are very important branch, where nodes in the graph are the labeled and unlabeled points, and weighted edges reflect the similarities of nodes. The initially assumption of these methods is that all points are located in a low dimensional manifold, and the graph is used to approximate the underlying manifold. Neighboring point pairs connected by large weight edges tend to have the same labels and vice versa. By the means, the labels associated with data can be propagated throughout the graph. By using the graph Laplacian, [16] proposed a novel Laplacian Support Vector Machine (LapSVM). Unlike other methods based on graph [17, 18, 19], LapSVM is a natural out-of-sample extension, which can classify data that becomes available after the training process, without having to retrain the classifier or resort to various heuristics [16]. A lot of experiments show that LapSVM achieves state of the art performance in semi-supervised classification [20].
In many real-world applications, different misclassifications often have different costs, such as disease di-agnosis, fraud detection, business decision making [21, 22] and object recognition [23, 24] and so on. These classification problem is usually called cost-sensitive learning problem [25, 26, 27, 28, 29, 30], which aimed to minimize the total misclassification costs.
∗Corresponding author
Email addresses:[email protected](Zhiquan Qi),[email protected](Yingjie Tian) Open access under CC BY-NC-ND license.
In this paper, we consider the problem of how to extend LapSVM algorithms to solve the cost-sensitive learn-ing problem and proposed a new algorithm: Cos-LapSVM.
The remaining parts of the paper are organized as follows. Section 2 describes the detail of Cos-LapSVM; All public datasets experiment results on real data sets are shown in the section 3; The last section gives the conclusions.
2. Cost-Sensitive Laplacian Support Vector Machine(Cos-LapSVM) 2.1. Laplacian Semi-supervised Learning Framework
Regularization [31] is a key technology for obtaining smooth decision functions and thus avoiding over-fitting to the training data, which is widely used in machine learning [32, 16]. Recently, the regularization framework has been recently extended in SSL field by [16] as follows.
Given a set of labeled data
T ={(x1,y1),· · ·,(xl,yl)} ∈(n× Y)l, (1)
wherexi∈ n,yi∈ Y={1,−1},i=1,· · ·,l, and a set of unlabeled data
(xl+1,· · ·,xl+u), (2)
wherexi ∈ n. For a kernel functionK(·,·) , which associated with a reproducing kernel Hilbert spaceHk, the
decision function can be obtained by minimizing f∗=arg min f∈Hk l i=1 V(xi,yi,f)+γHf2H+γMf2M, (3)
where f is a unknown decision function,Vrepresents some loss function on the labeled data,γH is the weight off2
H and controls the complexity of f in the reproducing kernel Hilbert space. γMis the weight off2Mand
controls the complexity of the function in the intrinsic geometry of marginal distribution,f2
Mis able to penalize
f along the Riemann manifoldM. 2.2. Cos-LapSVM
Similar to the LapSVM, we use the decision function
f(x)=(w·Φ(x))+b, (4)
whereΦis a nonlinear mapping from a low dimensional space to a higher dimensional Hilbert spaceH. According to Hilbert space theory([33]),wcan be expressed asw=il+=u1αiΦ(xi). So, the decision function is written as
f(x)=
l+u
i=1
αiK(xi,x)+b, (5)
whereKis an chosen kernel function: K(xi·xj) = (Φ(xi)·Φ(xj)). Also, the regularization termf2H can be
expressed as
f2H =w2=(Φα)(Φα)=αKα. (6)
For the manifold regularizationf+2
M, a data adjacency graphW(l+u)×(l+u) is defined by nodesWi,j, which
repre-sents the similarity of every pair of input samples. The weight matrixWmay be defined byknearest neighbor or graph kernels as follows([16]):
Wi j=
exp(−xi−xj22/2σ2), ifxi,xjare neighbor;
wherexi−xj22denotes the Euclidean norm inn. So the manifold regularization is defined by f2 M= 1 (l+u)2 l+u i,j=1 Wi,j(f(xi)−f(xj))2= fL f, (8)
whereL = D−W is the graph Laplacian, D is a diagonal matrix with itsi-th diagonalDii = lj+=u1Wi j, and f =[f(x1),· · ·,f(xl+u)]=Kα, here we drop the bias termb. According to the cost-sensitive learning method of
[30], the primal problem of Cos-LapSVM can be written as min ξ∈Rl,α∈Rn[λ1 {i|yi=1} ξi+λ2 {i|yi=−1} ξi]+γHαKα +γMαKLKα, s.t. l+u j=1 αiK(xi,xj)+b≥1−ξi, yi=1, l+u j=1 αiK(xi,xj)+b≤ −λ3+ξi, yi=−1, ξi≥0, i=1,· · ·,l, (9) where λ1=C1, λ2 =2C−1−1, λ3= 1 2C−1−1, (10) C1andC−1are the penalty factors for the positive and negative class.
By introducing its Lagrange function L(ξ, α,b, β, ρ, η)=[λ1 {i|yi=1} ξi+λ2 {i|yi=−1} ξi]+γHαKα +γMαKLKα− {i|yi=1} βi( l+u j=1 αiK(xi,xj) +b−1+ξi)+ {i|yi=−1} ρi( l+u j=1 αiK(xi,xj)+ b+λ3−ξi)− l i=1 ηiξi, (11)
whereβi, ρi, ηi∈Rare the Lagrange multipliers, therefore the dual problem of (11) can be formulated as
max
ξ,α,b,β,ρ,ηL(ξ, α,b, β, ρ, η), (12)
s.t.∇ξ,α,bL(ξ, α,b, β, ρ, η)=0, (13)
βi, ρi, ηi≥0. (14)
From equation (13) we get
∇bL= {i|yi=1} βi− {i|yi=−1} ρi=0, (15) ∇ξiL=λ1−βi−ηi=0, yi=1, (16) ∇ξiL=λ2−ρi−ηi=0, yi=−1, (17) ∇αL=(2γHK+2γMKLK)α−K J1β +K J2ρ =0, (18)
whereJ1=[E1 0] is al×(l+u) matrix withE1asl×ldiagonal matrix ((E1)ii=1, ifyi=1, otherwise, (E1)ii=0);
similarly,J2 =[E2 0] is al×(l+u) matrix withE2asl×ldiagonal matrix ((E2)ii =−1, ifyi =−1, otherwise,
(E1)ii=0);β ∈Rl, ify i=−1,β i=0;η ∈Rl, ify i=1,η i=0.
Substituting the above equations into problem (13), the dual problem can be expressed as max β,ρ − 1 2(β J1−ρ J2)K(2γH +2γMKL)−1(J1β −J2ρ) + l i=1 (βi+λ3ρ i) s.t. {i|yi=1} βi− {i|yi=−1} ρi=0, 0≤βi≤λ1, yi=1, 0≤ρi≤λ2, yi=−1. (19)
It is not difficult to find that (19) will degenerate to the standard LapSVM whenC1 =C−1=1. 3. Experiments
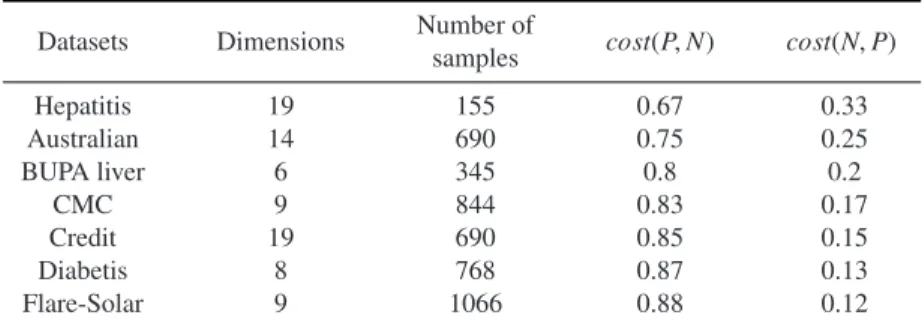
Table 1. Parameters and Samples on UCI datasets
Datasets Dimensions Number of cost(P,N) cost(N,P)
samples Hepatitis 19 155 0.67 0.33 Australian 14 690 0.75 0.25 BUPA liver 6 345 0.8 0.2 CMC 9 844 0.83 0.17 Credit 19 690 0.85 0.15 Diabetis 8 768 0.87 0.13 Flare-Solar 9 1066 0.88 0.12
Table 2. Results on UCI datasets
Datasets Cos-LapSVM LapSVM T S V M
Hepatitis 0.208 0.223 0.254 Australian 0.424 0.476 0.462 BUPA liver 0.389 0.412 0.433 CMC 0.485 0.521 0.553 Credit 0.343 0.432 0.411 Diabetis 0.457 0.460 0.471 Flare-Solar 0.477 0.501 0.535
The performance of the LapSVM was evaluated in UCI datasets (see Table 1). We compare the Cos-LapSVM against Cos-LapSVM and TSVM[34]. Cos-LapSVM and TSVM are cost-blind. We use sampling method [35] to make these two method solve the cost-sensitive problem. Each data set is split into two equal halves, one for training and the other for testing. Each training set contains 20% labeled examples. The RBF kernel is always used. The testing accuracies of all experiments are computed using standard 10-fold cross validation.γH, γMand RBF kernel parameterσare all selected from the set{2i|i=−7,· · ·,7}by 10-fold cross validation on the tuning
to the training set to learn the final decision function. We use the Average Cost(AC) to evaluate these algorithms’ performance. The AC can be expressed as
AC= FP×cost(N,P)+FN×cost(P,N)
T P+T N+FP+FN , (20)
where TP is true positive, TN is true negative, FP is false positive and FN is false negative;cost(N,P) is the cost of which negative data is classified into positive one andcost(P,N) is the cost of which positive data is classified into negative one. All algorithms are implemented by using MATLAB 2010. The experiment environment: Intel Core i7-2600 CPU, 4 GB memory.
From Table 2, we find that Cos-LapSVM significantly outperforms the cost-sensitive extensions of LapSVM and TSVM. LapSVM has a better performance than TSVM in most cases. The main reason is that our cost-sensitive method roots in the method of [30], which is derived as the minimizer of the associated risk and can avoid the shortcomings of previous approaches to cost-sensitive SVM design.
4. Conclusion
In this paper, we proposed a new Cost-Sensitive Laplacian Support Vector Machine(called Cos-LapSVM). All experiments in datasets show that the performance of the Cos-LapSVM is better than that of the LapSVM and the TSVM. However, since Cos-LapSVM needs to computing an extra inverse matrix before solving the quadratic programming, so in the future work, we will try to solve the Cos-LapSVM in its primal formulation.
5. Acknowledgment
This work has been partially supported by grants from National Natural Science Foundation of China( NO.70921061, NO.11271361, No. 61202226), the CAS/SAFEA International Partnership Program for Creative Research Teams, Major International( Ragional) Joint Research Project(NO.71110107026), the President Fund of GUCAS. References
[1] M. Seeger, Learning with labeled and unlabeled data, Tech. rep. (2001).
[2] O. Chapelle, B. Sch¨olkopf, A. Zien (Eds.), Semi-Supervised Learning (Adaptive Computation and Machine Learning), The MIT Press, 2006.
[3] X. Zhu, Semi-supervised learning literature survey (2006).
[4] Y. Tian, Y. Shi, X. Liu, Recent advances on support vector machines research, Technological and Economic Development of Economy 18(1) (2012) 5–33.
[5] Z. Qi, Y. Tian, S. Yong, Twin support vector machine with universum data, Neural Networks 36C (2012) 112–119. doi:doi:
10.1016/j.neunet.2012.09.004.
[6] Z. Qi, Y. Tian, S. Yong, Robust twin support vector machine for pattern classification, Pattern Recognition 46(1) (2013) 305–316. doi:doi:10.1016/j.patcog.2012.06.019.
[7] Z. Qi, Y. Tian, Y. Shi, Structural twin support vector machine for classification, Knowledge-Based Systems.
[8] C. Zhang, Y. Shao, Y. Tan, N. Deng, Mixed-norm linear support vector machine, Neural Comput & Applicdoi:10.1007/ s00521-012-1166-0.
[9] N. C.Zhang, Y.Tian, The new interpretation of support vector machines on statistical learning theory, Science China Mathematics 53(1) (2010) 151–164.
[10] Y. Shao, C. Zhang, X. Wang, N. Deng, Improvements on twin support vector machines, Neural Networks, IEEE Transactions on 22 (6) (2011) 962–968.
[11] Y. Li, Y. Shao, N. Deng, Improved prediction of palmitoylation sites using pwms and svm, Protein and Peptide Letters 18 (2) (2011) 186.
[12] Z. Qi, Y. Tian, S. Yong, Regularized multiple criteria linear programming via linear programming, in: Procedia Computer Science, Vol. 9, 2012, pp. 1234–1239.
[13] Z. Qi, Y. Tian, S. Yong, Regular multiple criteria linear programming for semi-supervised classification, in: ICDM(OEDM), 2012. [14] Z. Qi, Y. Tian, S. Yong, Multi-instance classification based on regularized multiple criteria linear programming, Neural Computing &
Applicationsdoi:10.1007/s00521-012-1008-0.
[15] Z. Qi, S. Yong, Structural regular multiple criteria linear programming for classification problem, International Journal of Computers, Communications & Control 7(4) (2012) 732–742. doi:doi: http://dx.doi.org/10.1016/j.neunet. 2012.07.011.
[16] M. Belkin, P. Niyogi, V. Sindhwani, Manifold Regularization: A Geometric Framework for Learning from Labeled and Unlabeled Examples, Journal of Machine Learning Research 7 (2006) 2399–2434.
[17] T. Joachims, Transductive learning via spectral graph partitioning, in: In ICML, 2003, pp. 290–297.
[18] M. Belkin, P. Niyogi, Using Manifold Structure for Partially Labelled Classification, in: NIPS, 2002, pp. 953–960.
[19] X. Zhu, Z. Ghahramani, J. Lafferty, Semi-supervised learning using gaussian fields and harmonic functions, in: IN ICML, 2003, pp. 912–919.
[20] Z. Qi, Y. Tian, S. Yong, Laplacian twin support vector machine for semi-supervised classification, Neural Networks 35 (2012) 46–53. doi:doi: http://dx.doi.org/10.1016/j.neunet. 2012.07.011.
[21] X. Yu, D. Khazanchi, An exploratory study of the impact of it capabilities adaptation on shared mental models similarity, in: MWAIS 2011, 2011.
[22] X. Yu, D. Owens, D. Khazanchi, Building socioemotional environments in metaverses for virtual teams in healthcare: A conceptual exploration, in: Health Information Science, Springer, 2012, pp. 4–12.
[23] Z. Qi, Y. Xu, L. Wang, Y. Song, Online multiple instance boosting for object detection, Neurocomputing 74 (10) (2011) 1769–1775. doi:10.1016/j.neucom.2011.02.011.
URLhttp://dx.doi.org/10.1016/j.neucom.2011.02.011
[24] Z. Qi, Y. Tian, S. Yong, Efficient railway tracks detection and turnouts recognition method using hog features, Neural Computing & Applicationsdoi:10.1007/s00521-012-0846-0.
[25] M. Kubat, S. Matwin, Addressing the curse of imbalanced training sets: One-sided selection, in: In Proceedings of the Fourteenth International Conference on Machine Learning, Morgan Kaufmann, 1997, pp. 179–186.
[26] S. ichi Amari, S. Wu, Improving support vector machine classifiers by modifying kernel functions, NEURAL NETWORKS 12 (1999) 783–789.
[27] N. V. Chawla, K. W. Bowyer, L. O. Hall, W. P. Kegelmeyer, Smote: Synthetic minority over-sampling technique., J. Artif. Intell. Res. (JAIR) 16 (2002) 321–357.
[28] G. Wu, E. Y. Chang, KBA: Kernel Boundary Alignment Considering Imbalanced Data Distribution, IEEE Transactions on Knowledge and Data Engineering 17 (6) (2005) 786–795. doi:10.1109/TKDE.2005.95.
[29] H. Masnadi-Shirazi, N. Vasconcelos, Cost-Sensitive Boosting, IEEE Transactions on Pattern Analysis and Machine Intelligence 33 (2) (2011) 294–309.
[30] H. Masnadi-Shirazi, N. Vasconcelos, Risk minimization, probability elicitation, and cost-sensitive SVMs, in: J. F¨urnkranz, T. Joachims (Eds.), Proceedings of the 27th International Conference on Machine Learning (ICML-10), Omnipress, Omnipress, Haifa, Israel, 2010, p. 759–766.
URLhttp://www.icml2010.org/papers/376.pdf
[31] A. Tikhonov, Regularization of incorrectly posed problems, Sov. Math. Dokl. 4 (1963) 1624–1627.
[32] T. Evgeniou, M. Pontil, T. Poggio, Regularization Networks and Support Vector Machines, Advances in Computational Mathematics 13 (1) (2000) 1–50.
[33] B. Sch¨olkopf, A. J. Smola, Learning with kernels: support vector machines, regularization, optimization, and beyond, Adaptive compu-tation and machine learning, MIT Press, 2002.
[34] V. N. Vapnik, The Nature of Statistical Learning Theory, Springer New York, 1996.
[35] C. Elkan, The foundations of cost-sensitive learning, in: In Proceedings of the Seventeenth International Joint Conference on Artificial Intelligence, 2001, pp. 973–978.