525 | International Journal of Computer Systems, ISSN-(2394-1065), Vol. 03, Issue 07, July, 2016 Available at http://www.ijcsonline.com/
Refining Web Search Results by Combining Visual and Textual Information with
User Intention
Pradnya V. MoreȦ, Prof. P. M. PatilḂ
AME Student, Department of Computer Engineering, V.P. Kamalnayan Bajaj Institute of Engineering and Technology , Baramati, India B Department of Computer Engineering, V.P. Kamalnayan Bajaj Institute of Engineering and Technology, Baramati, India
Abstract
Web search engines are software systems which are designed to search information on World Wide Web. When the user searches for a query into a search engine, a list of relevant web pages with a short summary consisting the documents title and part of the text is provided to the user. A picture conveys information more efficiently and effectively comparative to words. Existing text-based search engines are based on textual similarity. Web search engines do not use images in the web pages to search relevant documents for a given user query. Instead of images, they operate by computing a measure of agreement between the keywords provided by the user and only the text portion of the web page. Here we propose the content of the pictures appearing in the web page which can be used with semantic description of a Web document which can be enriched and consequently the performance of a keyword-based search engine is boosted. Previous methods do not consider users’ visual intention behind web search. In addition to existing work, proposed system can identify the users search goals in terms of images and result context. We maintain a search log which helps to identify the user goal images and goal text. We use users’ search goals to refine the result in a systematic manner.
Keywords: Custom Search Engine, web page re-ranking, personalized search engine, scale invariant feature transform, color histogram, hierarchical clustering.
I. INTRODUCTION
Web has turned into the largest information repository in the world. Because of its large volume, users easily feel lost and difficult to get what they want from the repository. In consequence, research on Web search has attracted more and more attention. A picture is worth a thousand words. In spite of this old saying, current web search engines fail to consider pictures in web pages and retrieve documents simply by comparing the query keywords with the text in the documents [1]. This text involves the words in image captions and markup tags, but does not look at the pixels themselves. Usually, each Web page is considered as a text document and web as a large document collection. Thus, methods from conventional text retrieval, like Vector Space Model (VSM) [2] and Term Frequency Inverse Document Frequency (TFIDF) [3], were applied to search documents having text contents similar to the query. Later, considering that Web is a hyperlinked environment and links between web pages encode the importance of the pages to some extent, Link information is used in many approaches, such as PAGERANK and Hyperlink-Induced Topic Search (HITS) [4], as a helpful evidence to make the pages that are related to the query stand out. It is interesting that in addition to link and text, other modalities of information such as image, video and audio, also tell about rich and important information related to contents of Web pages. In fact, Web is a multimedia environment.
In the traditional Web search, the search process can be described as follows: first, query is given by a user; second, the search result consisting of text snippets of Web pages are returned to the user for browsing; third, if the search result is satisfactory to the user then the search
is completed; if no, the user may re-enter the query through labeling relevant/irrelevant pages or directly revaluate the query terms manually. A picture conveys information more efficiently and effectively comparative to words. Traditional text-based search engine is based on textual similarity.
Web search engines do not consider the pictures in web pages to find relevant documents for a given user query [1]. Instead of images, they operate by computing a measure of agreement between the keywords given by the user and only text portion of every page. If a web page is decided to be related to a query in multiple information modalities simultaneously, then the page has high chance to be really relevant than other page which is judged to be relevant in only the text mode. For example, when a user searches for the animal tiger, a web page which consisting a tiger photo as well as the word tiger would have a more chances to satisfy the query than a page including the word tiger without an image of a tiger. In other words, related images in web pages are treated as additional evidence in judging the relevance of those pages in the search process. The relevance of web pages in the search process is determined by using related images in the web pages.
II. RELATED WORK
the high level concentration of image examples associated to the query. To form a single prototypical representation of the query, these image examples are averaged. Then, an image-based rank of candidate Web pages is computed by calculating the gap between the pictures in the page and the visual prototype of the query. This image-based rank is combined with a conventional keyword-based rank to form the final sorted list of documents.
Schroff et al. [6] presented the system which unites text, metadata and visual features to achieve a completely automatic ranking of the images related to a given query. Their approach starts from Web pages, recovered by text search for the query. Then images in the pages are re-ranked using both text and metadata features, and finally a form of pseudo relevance feedback (PRF) is used. PRF is a classifier which is trained to predict high rankings, and re-rank the image list.
J. Krapac et al. [7] proposed an image re-ranking technique, based on textual and visual features, that does not require learning a separate model for every query. Features for each image are query dependent. They showed how to construct query-relative features which can be used to train generic classifiers, and rank images for previously unseen search queries without additional model training. The features combined textual information about occurrence of the query terms and other words found to be related to the query, and visual information derived from visual histogram image representation.
Yeh et al. [8] proposed system which is example of multimedia search. However, their method needs extra user input, in the form of an image accompanying text query. A photo based question answering system allows exact use of a photo to refer object. PCA (Principal Component Analysis) SIFT (Scale Invariant Feature Transform) used to extract 12-dimensional feature vectors. Barnard and Johnson [9] overcome the problem of word sense disambiguation in context of words in image captions, and thus could wish to segment outcomes for ambiguous query terms. For word sense disambiguation approach image information and text is more useful. Thus system infers that images provides sufficient amount of information.
Xue et al. [10] proposed system to present image snippets with text snippets to user. It is easier and more accurate for the user to identify the Web pages he or she expects and to reformulate the initial query. An image snippet of a Web page is one of the images in the page that is both representative of the theme of the page and at the same time closely related to the query.
Woodruff et al. [11] proposed to use an improved thumbnail to help the user quickly find the Web pages he or she expects. This improved thumbnail is an image, where the whole Web page is resized to fit into this image and important text is highlighted in order to be readable for the user. It would also be interesting to consider how one
might build thumbnails into a production search engine. Doing so would found many significant issues, like bandwidth requirements to download images and time to generate thumbnails for a given query.
A. Problem Statement
Conventional search engine are based on textual similarity, while image search (Content Based Image Retrieval) considers the image feature to retrieve relevant images. An approach is needed to identify the user‟s search goals for both text and image search. The user search goals then can be applied to refine the web results from user perspective to enhance the rank quality of web search. In this system, user‟s visual-textual intention is considered.
III. PROPOSED SYSTEM
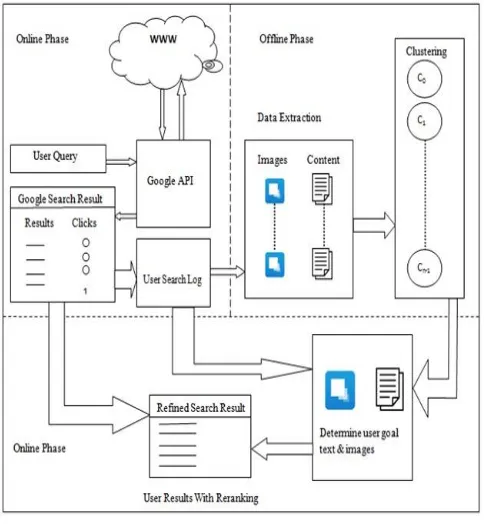
Proposed system is shown in Fig. 1. The user gives query to the system. According to the user query, Google search results are displayed. Images contained in the web page and the snippet of web page is extracted from each visited web page; user log is maintained. Preprocess the text and image. By using Similarity measure image and text similarity is calculated. Then clustering is made according to similarity of images and text. Hierarchical clustering algorithm is used for classifying data. Next, user goal images and goal text are determined by using clustering and user log. According to high-rank score results are refined and web page which have high rank score is displayed on top. Here, input to the system is query that user wants to search on internet and results from Google search engine retrieved for the user query. Finally, user will get refined Google search result with respect to user intention as output.
A. Google Custom Search Engine API
We collect Google search results runtime from Google CSE [12] to extract input data. Google API provides results from service instance and Google results comprise result title, URL and content.
B.User Search Log
To get user intention towards a specific query, we need to identify his/her goal images and goal text which is extracted from his/her viewed web pages for that query. C. Features for Clustering
1) Text Feature:
By tokenizing and stemming algorithm we get a textual feature. A token is an instance of a sequence of characters in some particular document that are grouped together as a useful semantic unit for processing. Stemming is a crude heuristic process that chops off the ends of words in the hope of being correct most of the time. Then Cosine Similarity measure is used for Textual similarity. 2)Image Feature:
a) SIFT: SIFT image features are invariant to image scaling and transformation and rotation, and partially invariant to illumination changes and angle of view changes, affine and noise. SIFT descriptors are first extracted from a set of viewed images and stored on server side. A key point match is identified in a new image by individually differentiating each feature descriptor from the new image and finding candidate matching features based on Cosine Similarity of their feature vectors.
b) Color Histogram: Color feature is a global feature which cannot be expressed as rich regional object details. A color histogram of an image represents the distribution of the composition of colors in the image. It shows different types of colors appeared and the number of pixels in each type of the colors appeared. The similarity of images then normalized to a defined scale for similarity measure.
D. Clustering
User data in terms of images contained in web page and the snippet of web page is extracted from each visited web page. Preprocessing is performed on text data. After using SIFT feature and color histogram similarity of images and TF-IDF of snippets we adopt Hierarchical clustering to classify the user data. Algorithm 1 is implemented for image clustering and by using algorithm 2 text is clustered. E. Goal Image and Goal Text
For a particular user, we extract user goal images and goal text for specific query by considering largest cluster
found in clustering phase. This goal image and text is useful when user will give same query next time when he will log in again.
Algorithm 1 Hierarchical Clustering Algorithm for Images Input : Image set I= {i0, i1…… in-1}, threshold Ɵ = 0.1
Output: Cluster set C= {c0, c1……..cn-1}
1. Create new cluster ‘C0’ 2. Add ‘I0’to ‘C0’
3. Add C0 to C
4. for each remaining ‘Ir’ do
5. Initialize flag = 0, mostmatching = -1 6. for each „Cj’ in ‘C’ do
7. calculate sim (Cj,Ir )
8. if sim >=Ɵ && sim >= flag then 9. flag = sim
10. mostmatching = j 11. if mostmatching != -1 then 12. Add ‘Ir’ to ‘Cmostmatching’ 13. else
14. Create new cluster ‘Cn’ 15. Add ‘Ir’ to ‘Cn’
16. Add „Cn’to „C’ 17. Stop
Algorithm 2 Hierarchical Clustering Algorithm for Text Input : Token set T= {t0, t1…… tn-1}, threshold Ɵ = 0.5
Output: Cluster set C= {c0, c1……..cn-1}
1. Create new cluster ‘C0’ 2. Add ‘T0’to ‘C0’ 3. Add C0 to C
4. for each remaining „Tr’ do
5. Initialize flag = 0, mostmatching = -1 6. for each „Cj’ in ‘C’ do
7. calculate sim (Cj, Tr )
8. if sim >=Ɵ && sim >= flag then 9. flag = sim
10. mostmatching = j 11. if mostmatching != -1 then 12. Add ‘Tr’ to ‘Cmostmatching’ 13. else
14. Create new cluster ‘Cn’ 15. Add ‘Tr’ to ‘Cn’
16. Add „Cn’to „C’ 17. Stop
F. Refined Results
IV. EXPERIMENTAL RESULTS A. Dataset:
To evaluate our system, we collect web results from Google search engine. Each result contains result title, URL and content. We then extract each result page to collect image set and context set. The number of results from Google search engine is set to user defined number (for eg.12). Here we restrict our experimental analysis only to the pages for which we downloaded images linked in original web document. Table I gives the information about the number of retrieved documents which are relevant and a number of clusters for some queries of our dataset.
TABLEI INFORMATION OF COLLECTED DATA
Query # Relevant
Results
#Image Clusters
#Text Clusters
Jaguar 8 35 2
Tiger 8 29 3
Swift Car 11 14 1
Apple iPhone 9 25 5
Tajmahal 10 20 3
B. Performance Evaluation:
For evaluating the performance of the system, the metric such as Precision (P) is used. The precision of the system denotes the fraction of retrieved instances that are relevant. Precision is calculated by using eq. (1).
) 1 ( Re Re . Re Re . ) ( Pr
sults levant of No sults fined Correctly of No P ecision C. Outcome:We tested the performance of this system using precision for all queries which are discussed in dataset shown in Table I. Table II shows evaluation measures for JAGUAR query in which system considers visual + text features and text features.
TABLEIII EVALUATION MEASURES ON JAGUAR QUERY
Viewed Results (K) Relevant Results Correctly Refined Results P Visual+ Text
Text Visual+
Text
Text
2 8 7 6 0.87 0.75
4 8 6 4 0.75 0.75
6 8 5 5 0.71 0.62
8 8 6 6 0.75 0.75
As shown in Table II we evaluated the performance for remaining queries. Table III shows evaluation measures for all queries which are discussed in dataset.
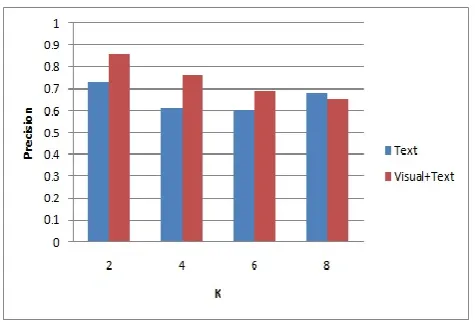
TABLEIIIII EVALUATION MEASURES ONDATASET
Viewed Results (K)
Text Visual+Text
2 0.73 0.86
4 0.61 0.76
6 0.60 0.69
8 0.68 0.65
Figure 2 shows precision obtained with text and visual+text for varying number of viewed documents (K). Here we focus on performance when K is small, as in web search we are mostly interested in producing accurate results for the first few documents retrieved. The proposed system gives better precision only on visual queries i.e. the queries which have a strong visual meaning.
Figure 2. Text vs. Visual+Text
V. CONCLUSION
In this system, images to improve Web document search is investigated. By using current methods and representations for image understanding, it is possible to enhance the semantic description of a Web page with the content extracted from the pictures appearing in it. This system uses text-based search engine to find a beginning set of candidate documents for given query. Then, the candidate set is refined by using visual information extracted from the images and textual information similarities of pages by considering user intention. Visual and textual information is used to refine web search results.
REFERENCES
[1] J. S. Sergio Rodriguez-Vaamonde, Lorenzo Torresan, Andrew W. Fitzgibbon, “What Can Pictures Tell Us About Web Pages? Improving Document Search Using Images,” IEEE transaction on Pattern Analysis And Machine Intelligence, vol. 37, no. 6, June 2015.
[2] V.V. Raghavan and S.K.M.Wong, “A critical analysis of vector space model for information retrieval,” Journal of the American Society for Information Science, vol.37, no.5, pp.279- 287, 1986. [3] G. Salton and C. Buckley, “Term-weighting approaches in
automatic text retrieval,” Elsevier Information Processing and Management, vol. 24, no.5, pp.513-523, 1988.
[5] Z.-H. Zhou and H.-B. Dai, “Exploiting image contents in websearch,” Journal of the ACM, pp. 2922-2927, 2007.
[6] F.Schroff, A.Criminisi, and A.Zisserman, “Harvesting image databases from the web,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 33, no. 4, pp. 754-766, Apr. 2011.
[7] J. Krapac, M. Allan, J. J. Verbeek, and F. Jurie, “Improving web image search results using query-relative classifiers,” IEEE Conf. Comput. Vis. Pattern Recognit., pp. 1094-1101, 2010.
[8] T.Yeh, J. J. Lee, and T.Darrell, “Photo-based question answering,” in Proc. 16th ACM Int. Conf. Multimedia , pp. 389-398, 2008. [9] K.Barnard and M.Johnson, “Word sense disambiguation with
pictures,” Artif. Intell. ACM , vol. 167, no. 1, pp. 13-30, 2005. [10] X.B. Xue, Z.-H. Zhou, and Z.Zhang, ”Improve Web search using
image snippets,” Journal ACM Transactions on Internet Technology, vol. 8 no. 4, September 2008.
[11] A. Woodruff, A. Faulring, R. Rosenholtz, J. orrison, and P. Pirolli, “Using thumbnails to search the Web,” In Proceeding of the SIGCHI Confrence on Human Factors in Computing Systems, pp. 198-205, 2001.