2017 3rd International Conference on Computer Science and Mechanical Automation (CSMA 2017) ISBN: 978-1-60595-506-3
Detection Method for Abnormal User of Social Network Based on
Behavior Characteristics
Yun WU
1,aand Zhi-Xiong ZHANG
2,b,*1
BaoTou Teacher’s College of China
2
BaoTou Teacher’s College of China
a
[email protected], [email protected]
Keywords: Social networks, Anomalous users, Community discovery, Rough sets.
Abstract. In this paper, an anomaly user detection method based on user's basic characteristics is proposed for abnormal users in social networks. Using the G-N community discovery algorithm to divide users into orphan users and community users, combined with rough set theory, the basic characteristics of the user weight, according to the feature weight of the feature selection, the use of feature weight and feature trust value to calculate the user's credibility, and establish an exception user detection model. The experimental results show that the proposed model is suitable for detecting large-scale data sets, and has high stability and high accuracy compared with traditional methods.
Introduction
With the popularity and growth of social media, users spend a lot of time in the popular social networking platform, storage and sharing of rich personal information, this information increases the possibility of contact with thousands of users, but also has a negative impact, so that some Internet criminals can take advantage of. How to identify abnormal users to become an important topic in the field of social networking research.
According to the difference between the detection of abnormal users using the core algorithm, the detection method is divided into three kinds, based on the user behavior feature method, based on the user content message method, based on the map method. Akoglu[1] based on the graph of anomaly detection, studied a comprehensive, structured data using the graph to show the anomaly detection method. From the perspective of the map, Savage [2] builds the spam detection and capture graph model. Moh[3] based on the user's basic characteristics and content according to Twitter user characteristics and user behavior characteristics such as the number of messages published twitter, the number of friends, fans, etc., through different characteristics of the matrix to obtain the user's trust, to determine whether the user is abnormal. Thomas [4] found that abnormal users rarely participate in social interaction, but abnormal users take the initiative to focus on other users and in some hot topics published spam comments or spam links to promote normal users click to visit and other malicious acts. Hayati[5] extended the previous study, proposed based on the behavioral feature set using user action time and action frequency for spam detection method. In this paper, we use G-N community discovery algorithm and user-based basic characteristics to carry out abnormal user detection research.
Abnormal User Analysis and Detection Methods
Abnormal User Characteristics Analysis
According to Grier et al.'s study [9], it was found that about 8% of the links in Twitter and micro blogs were malicious links. Figure 1 shows the results of experiments using the G-N [12] community discovery algorithm to analyze the open data sets provided by Stanford University [10] and XU et al. [11]
[image:2.612.226.365.136.251.2]for data sets containing anomalous users open to social networks.
Figure 1.Analysis of abnormal user characteristics.
In Figure 1, the red is the abnormal node, green is the normal node. The experimental results show that both the normal node and the abnormal node are mostly in the form of community, and the probability that the isolated node is an abnormal node is relatively large. Community mapping makes the detection of abnormal users in the community as a unit more clear and detailed, so the model will use the G-N community discovery algorithm combined with abnormal user characteristics to establish abnormal user detection model.
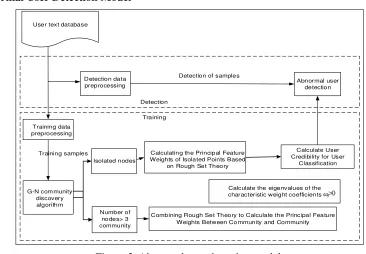
Abnormal User Detection Model
G-N com munity discovery algorithm
Number of nodes> 3 community Isolated nodes
Calculating the Principal Feature Weights of Isolated Points Based
on Rough Set Theory Training data
preprocessing
Detection data preprocessing
Training Detection User text database
Detection of samples
Training samples Calculate User
Credibility for User Classification Abnormal user
detection
Combining Rough Set Theory to Calculate the Principal Feature Weights Between Community and Community
Calculate the eigenvalues of the characteristic weight coefficients
Figure 2. Abnormal user detection model.
[image:2.612.116.482.381.635.2]weight to determine the existence of significant characteristics of abnormal user detection, calculate the corresponding characteristic trust value;5) Comprehensive user characteristic weight and eigenvalue to calculate the user's credibility, according to the credibility to determine whether the user is an abnormal point of the user, the community is divided into normal user community and unknown trust community, unknown trust community nodes in accordance with the isolated node Method to determine. Abnormal user detection model shown in Figure 2.
User Characteristics Attribute Weights
Using the G-N community discovery algorithm to divide the user into isolated nodes and communities, so that each node belongs to only one community, this paper regards the number of nodes in the community less than three as isolated nodes. The following are discussed from the isolated point and the community two aspects of the basic characteristics relationship of the user.
1) isolated nodes. It can be seen from Figure 1 for the isolated point of the user almost no contact with other users, through a large number of statistical analysis of data found that the basic characteristics of the isolated point of the user there are eight main features shown in Table 1.
2) community. The relevant characteristics of the community and the analysis of the characteristics of isolated nodes, the difference lies in the relationship between the community and the community, the community characteristics shown in Table 2.
3) Important feature extraction. The user set through the artificial observation and induction to get the initial feature set, the theory of rough set is to express the knowledge of decision table composed of conditional attribute set C = {C1, C2 ... Cn} and decision attribute D. By calculating the influence of each condition attribute CiεC on decision making, that is, calculate the size of the user attribute weight, remove the redundant attributes [13-14]. Therefore, in order to calculate the importance of each behavior in the main behavioral characteristics of the user, the weights of the user characteristic attribute in determining the user category and the attribute weight coefficient
ω
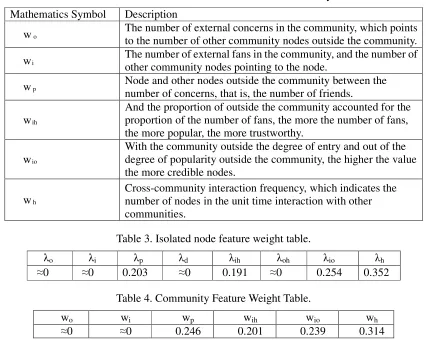
i are calculated by using the rough set theory. If ωi>0, then the characteristic Ci is necessary in the characteristic C, which can influence the final decision, that is, the user classification and recognition, and mark the characteristic of the corresponding user behavior. Ifωi=0, it means that the characteristic Ci is redundant in the characteristic C, and does not affect the user classification recognition [15-16]. [image:3.612.100.524.506.736.2]The rough set theory is used to calculate the rough set matrix. As shown in Table 3, the community rough set matrix decision is shown in Table 4.
Table 1. The main behavioral characteristics of the isolated point user.
Mathematics Symbol Description
o
λ The number of concerns, the number of connections indicated by
the node is also called node out.
i
λ The number of fans, the number of connections to that node.
p
λ Nodes are concerned about each other, that is, the number of
friends.
d
λ The degree of the node, said the number of nodes connected, the
node into the degree and out and.
ih
λ The proportion of nodes into the degree of nodes, the more fans,
the more popular, the more trustworthy.
oh
λ The proportion of nodes out of the node degree, said the node
concerned about the extent of other people.
io λ
Node entry and out of the ratio, the higher the value of the number of nodes that the number of fans more concerned about the number, the more credible.
h
λ The frequency of interaction indicates the number of times the
Table 2. The main behavioral characteristics of community users.
Mathematics Symbol Description
o
w The number of external concerns in the community, which points to the number of other community nodes outside the community.
i
w The number of external fans in the community, and the number of other community nodes pointing to the node.
p
w Node and other nodes outside the community between the number of concerns, that is, the number of friends.
ih
w
And the proportion of outside the community accounted for the proportion of the number of fans, the more the number of fans, the more popular, the more trustworthy.
io
w
With the community outside the degree of entry and out of the degree of popularity outside the community, the higher the value the more credible nodes.
h w
Cross-community interaction frequency, which indicates the number of nodes in the unit time interaction with other communities.
Table 3. Isolated node feature weight table.
λo λi λp λd λih λoh λio λh
≈0 ≈0 0.203 ≈0 0.191 ≈0 0.254 0.352
Table 4. Community Feature Weight Table.
wo wi wp wih wio wh
≈0 ≈0 0.246 0.201 0.239 0.314
User Feature Trust Value
By calculating the characteristic weight coefficients of the user, the characteristics of the weight coefficient of the user's feature in the isolated point and the community are calculated respectively. It shows that these characteristics play a decision component for the discriminant user type, select important features from the main features of the user and calculate the characteristic trust value, So as to further study the characteristics of the following calculation of isolated points and community eigenvalues:
1) Figure 1 can be seen for the isolated point of the user almost no contact with other users, so the user characteristics are simple, from the 2.3 section of the user isolated point of the important characteristics of the characteristics of the weight coefficient is λp (friends), λih (Degree of occupancy ratio), λio (degree and exit ratio), λh (interaction frequency).
2) In the community, the relevant characteristics of the community and the characteristics of isolated nodes, the following analysis of the main community and the relationship between the community. The characteristics of the weight coefficient of the nodes in the community are obtained from section 2.3, and the wp (the number of friends outside the community), the wih (the ratio of the external nodes to the community), the wio (the external degree of the node community, wh (cross - community interaction frequency).
undetected user i is that the measured characteristic trust value is, for example, the value in the third subinterval, and the corresponding characteristic trust value is 3.
User Credibility Calculation Method
The user's i corresponds to the characteristic weight coefficient and the characteristic trust value of the characteristic Cj according to 2.3 and 2.4, calculates the user's credibility according to the user's important characteristic weight coefficient and the trust value of the important feature, and the user's Confident degree of judgment. Social community credibility in social networks is defined as follows:
1) Isolated node user confidence:
Let the j-th characteristic attribute weight ωj of user
i
a, the characteristic trust value λij of the
j-th characteristic Cj of user ai, the confidence degree T a( )i ,the credibility of an isolated point
user is the sum of the product of the characteristic weight coefficient ωj and the characteristic trust
value λij of all the characteristics of the user, as shown in Equation 1.
1 1
( )
n k
i i j i j
i j
T a
λ
ω
= =
=
∑ ∑
(1)
For userai, calculate the credibility of the user isT a( )i , the greater the value, ai is the greater the possibility of normal users. In order to achieve the purpose of detecting abnormal users, set the threshold T0, then T a( 0)>T0, ai for the normal user; otherwise, the exception of the user; Isolated
node trust is less than the community does not mean that it is an abnormal node, because isolated nodes and other contacts than the community nodes are relatively inactive.
2) Community user confidence
Let the community be represented by Si, the average characteristic trust value λijs of the j-th
characteristic Cj of the community Si, the j-th characteristic attribute weight
1 1 n k sij ij i j ω ω = =
=
∑ ∑
of thecommunity Si, the community trust degree T S( )i ,the credibility of a community is the sum of the
mean value of the characteristic weight coefficient ωj for all the characteristics of the community
and the average value of the characteristic trust value
1 1 n k sij ij i j λ λ = =
=
∑ ∑
of each user in the community, asshown in Equation 2:
1 1
1
(
)
n k
i s i j s i j
i j
T
S
n
λ
ω
= ==
∑ ∑
(2)For community Si, the community trust is calculated asT S( )i , the greater the value, the greater the likelihood that Si is a normal community. In order to achieve the purpose of detecting the abnormal community, set the threshold T0, then T S( )i >T0, Si is the normal community; the other side, if the
same community if the threshold is further detected, the detection of each user in the community,each user as an isolated node, the user's credibility calculation method and the same as the isolated node users.
3) Define the minimum threshold of confidence
If the isolated node is trusted by the user characteristic, it can be judged whether it is a normal user, and the node in the community needs to calculate the confidence degree T a( 0) and determine the minimum confidence thresholdT0.
Let T= f x( )be the change function of T value with x, where x is the probability threshold, the
decrement rate of the T value reaches the maximum, that is, the minimum threshold of the reliability, when it is reduced to an x value.
Experiments and Results
Performance Evaluation
In order to detect and analyze the performance and model of the user based on the basic characteristics of the user in the social network, performance evaluation was performed using Recall, Precision, Accuracy, F-measure, and Efficiency Criteria[17].
Experimental Results
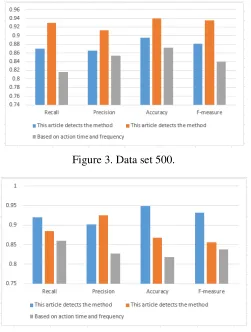
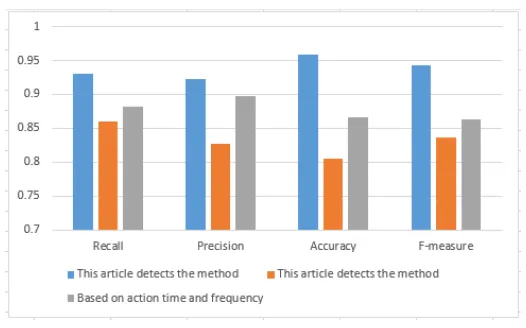
[image:6.612.182.433.312.644.2]The experimental data are derived from the open data set[10] provided by Stanford University and the data set containing the abnormal users about the social network, which is concluded by XU et al[11]. The abnormal user detection method proposed in this paper is compared with the method proposed in [3] and [5] to evaluate the abnormal user detection model proposed in this paper.In order to evaluate and analyze the better, respectively, to identify the different size of the data set, respectively, Figure 3 data set 500, Figure 4 data set 5000, Figure 5 data set 50000 to do comparison and analysis experiments.
Figure 3. Data set 500.
Figure 4.: Data set 5000.
Figure 5. Data set 50000 comparative analysis results.
It can be seen in Figure 3 that the detection method has some shortcomings when the data set is small, but it is better than the detection method based on the action time and frequency. As the data set is small, only the use of the characteristics of the relationship between users cannot play a better role in recognition, some abnormal users disguised as normal users, the need to further use the user to send the message content to distinguish.
In Figure 4, we can see that the detection method in this paper, when the amount of data to improve the accuracy rate was significantly increased by about 91%, but compared to the user behavior and content is still similar, but the recall rate, accuracy rate and harmonic average are higher than the other two abnormal user detection methods, indicating that this article abnormal detection method of the user detection model is better to identify the user ability.
Figure 5 can be seen in this article abnormal user detection method in Recall, Precision, Accuracy, F-measure, and Efficiency Criteria compared to the other two detection methods are higher, more than 90%, indicating that abnormal user detection and abnormal user detection model is better,in the case of increasing the size of the data set, it is better to identify the results. It is proved that the anomaly user model is suitable for identifying relatively large data sets, which has high stability, high accuracy and high efficiency.
Conclusion
In this paper, based on the basic characteristics of users and the relationship between the user characteristics of the abnormal user detection, combined with G-N community discovery algorithm for community discovery, found in the community isolated nodes and communities, the user is divided into two types of abnormal detection, the community as a unit to narrow the detection range, so that the detection target more clearly. By using the rough set theory, the characteristics of the user characteristic weight coefficient greater than 0 are calculated, the feature selection is carried out. Based on the reliability of the user, the abnormal user detection model is established, and the user type is divided. In this paper, the detection method and content-based behavior detection method, based on the action time and frequency detection method for experimental comparison analysis shows that the detection method with the data set to increase the detection of abnormal user ability will be improved, can effectively carry out abnormal user testing. The experimental results show that the anomalous user detection model is reasonable and feasible.
References
[1] Akoglu L, Tong H, Koutra D. Graph based anomaly detection and description: a survey[J]. Data
[2] Wang G, Xie S, Liu B, et al. Identify Online Store Review Spammers via Social Review Graph[J]. Acm Transactions on Intelligent Systems & Technology, 2012, 3(4):1-21.
[3] Moh T S, Murmann A J. Can You Judge a Man by His Friends? - Enhancing Spammer Detection
on the Twitter Microblogging Platform Using Friends and Followers[M]//Information Systems, Technology and Management. Springer Berlin Heidelberg, 2010:210-220.
[4] Thomas K, Grier C, Song D, et al. Suspended accounts in retrospect: an analysis of twitter spam[J]. Proc of Imc, 2011:243-258.
[5] Hayati P, Potdar V, Chai K, et al. Web Spambot Detection Based on Web Usage Behavior[C]//
Advanced Information Networking and Applications (AINA). 2010.
[6] Qian Mo, Ke Yang. Research on Network Navy Identification [J]. Journal of Software,
2014(7):1505-1526. (In Chinese)
[7] Stringhini G, Kruegel C, Vigna G. Detecting spammers on social networks[C]// Computer Security Applications Conference. 2010:1-9.
[8] Yu-Qing Zhang, Shao-Qing Lv, Dan Fan. Research on Exception Account Detection Method in
Online Social Network [J]. Chinese Journal of Computers, 2015, 38(10):2011-2027. (In Chinese)
[9] Grier C, Thomas K, Paxson V, et al. @spam: the underground on 140 characters or less[C]// ACM Conference on Computer and Communications Security. ACM, 2010:27-37.
[10]http://snap.stanford.edu/data/egonets-Twitter.html
[11]Mislove A, Marcon M, Gummadi K P, et al. Measurement and analysis of online social networks[C]//ACM SIGCOMM Conference on Internet Measurement 2007, San Diego, California, Usa, October. 2007:1815-1816.
[12]Girvan M, Newman M E J. Community Structure in Social and Biological Networks[J].
Proceedings of the National Academy of Sciences of the United States of America, 2001, 99(12):7821-6.
[13]Xue-Tao Hu. Research on Abnormal User Detection Model of Social Network Based on Trust
Ranking [D]. Shanghai Jiao Tong University, 2014. (In Chinese)
[14]Shan Ling, Fei Xiang. An Improved Attribute Reduction Algorithm for Fuzzy Decision Table [J]. Computer Engineering and Applications Comput Eng Appl, 2011, 47(26):167-169. (In Chinese)
[15]Geng, Zhiqiang, and Qunxiong Zhu. Rough set-based heuristic hybrid recognizer and its application in fault diagnosis. Expert Systems with Applications 36(2):2711-2718.2009.
[16]Yu Liu, Ke-Rong Ben. Case-based Weight Determination Method Based on Attribute
Importance [J]. Computer Integrated Manufacturing System, 2012, 18(6):1230-1235. (In Chinese)
[17]Cai, Tao Yong, Xue Zheng Yuan, and Shi Lei. Map Reduce-based Bayesian anti-spam filtering