Optimization of Fragment based Mining through Genetic Algorithm
Full text
Figure
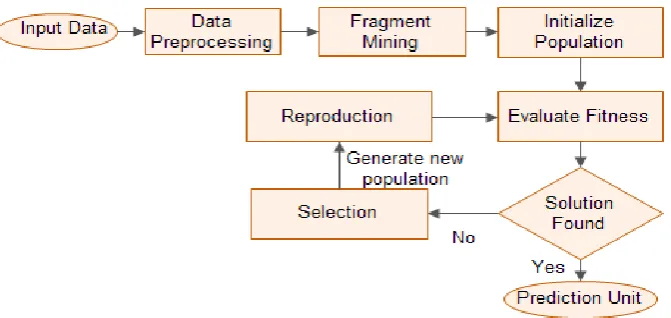
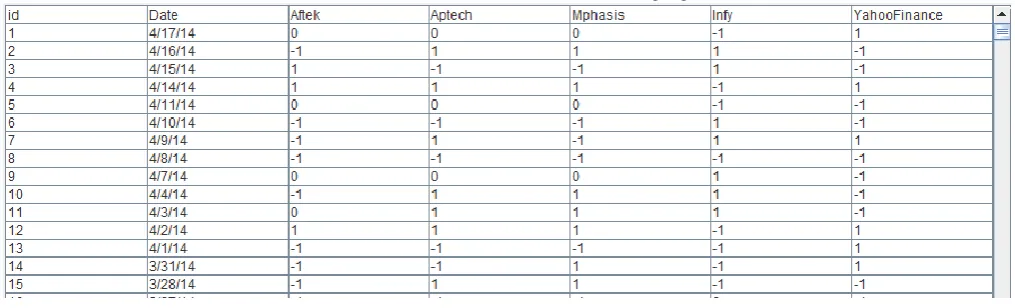
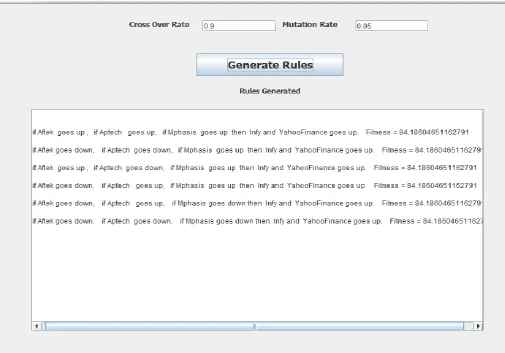
Related documents
Cross-sectional analysis of obesity and high blood pressure among undergraduate students of a university medical college in South India.. Sravan Kumar Chenji 1 ,
[87] demonstrated the use of time-resolved fluorescence measurements to study the enhanced FRET efficiency and increased fluorescent lifetime of immobi- lized quantum dots on a
Clubs and organizations: Business Professionals of America, or Skills USA are the leading CTSO (Career Technical Student Organizations) for students pursuing careers in
We show that in the subsample of retail- oriented funds where strategic complementarities are expected to have an effect, large investors’ redemptions are more sensitive to
This Standard specifies minimum requirements for optical fiber components used in premises cabling, such as cable, connectors, connecting hardware, patch cords and field
The current study represents a systematic effort to explore how transactional and transformational leadership style influence employee’s engagement and turnover
We investigated the magnitude of anaemia and emergency blood transfusion practices amongst children under 5 years presenting to the Emergency Department (ED) of Muhimbili
Buy-in from Lebanese teachers to develop and implement an SBBE program likely stems from their general belief in the maternal and/or infant benefits of breastfeeding, and in the
