International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
685
An Apotheosis Extraction Approach for Dynamic Web Data
Rajnish Kumar
1, Nidhi Bhirgu
2, Swati Shahi
31,2,3Pravara Rural Education Society’s Sir Visvesvaraya Institute of Technology, Nasik 1,2,3B.E. Computer Engineering Students
Abstract— To extract the data from a hidden dynamic Web
page is a very challenging work now a days because of existing many online databases. According to the survey, few years ago there were 10 million online databases but from the recent survey, now a days there are 30 million online database and the number is increasing day by day due to the revolution of technology in all the fields. Obviously, extracting the exact data is very hard. Already there are number of approaches which has been implemented but they generally filter the blocks after then they cluster, align and then extract the data but during this process, it is not guaranteed that we will get exact data.
This Apotheosis Extraction Approach which is a fully experimented over number of online databases, automatically detect the schema of html, dhtml, jsp and all the webpages including scripting webpage.in this approach, when any query is submitted to web page then first of all, it form a tree in which all the part of html, dhtml, jsp is identified internally and it differentiate by positional, layout, appearance and content features after then clustering and regrouping of data, alignment of data is done. Sometimes we are able to get records but not items of data. For this purpose, we have generated a sleeve which will also be helpful during complex data extraction.
Keywords— Hidden, Sleeve, SWETO, SwetoDblp,
I. INTRODUCTION
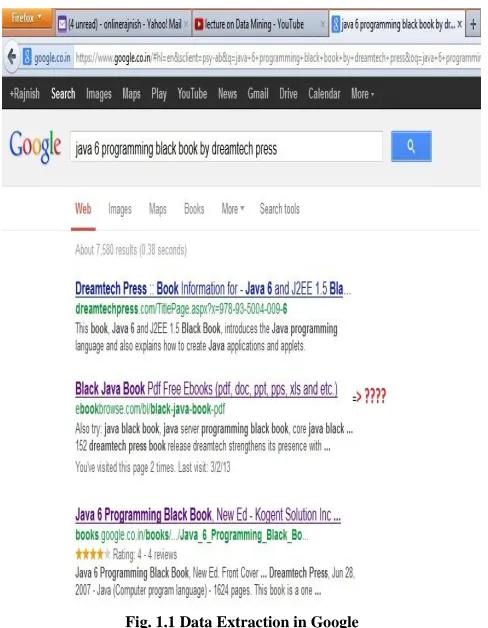
This Approach is mainly for search engines such as Google, Yahoo. In many of search engines, when we type something to get data then generally, we fail to get the exact data because of multiple extraction. Suppose, in Google, we type java black book then extracted data contains a number of java black book such as core java black book, servlet black book, jdbc black book and etc. hence we get confused that which one is the proper book. For that, if we know the book name then we type the specific name such as java 6 programming black book again we get so many books by different publication and having different ISBN number. Now we type suppose java 6 programming black book by dreamtech press but this time also we get so many extracted records which can be seen by the Fig. 1.1 clearly.
[image:1.612.323.567.275.589.2]This should not be happened. We should to get the proper data by using records and items. Records are nothing but the complete data and items are those parts which can be used for extracting. Suppose in above example, java 6 programming book is nothing but a record and ISBN, publication are the items.
Fig. 1.1 Data Extraction in Google
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
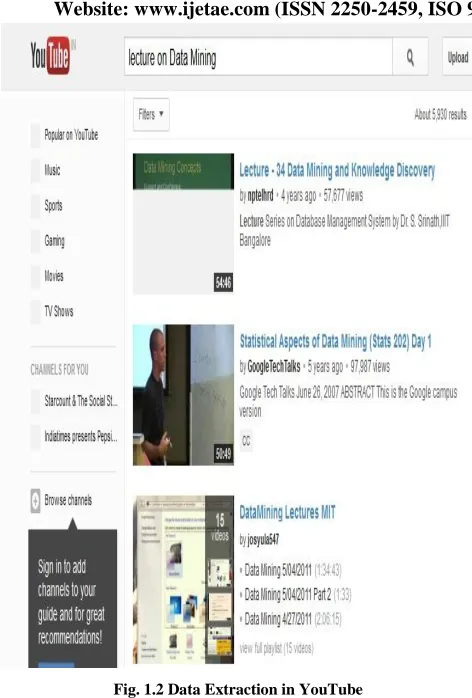
[image:2.612.328.556.105.283.2]686 Fig. 1.2 Data Extraction in YouTube
First, the question regarding extraction is that how the dynamic web page is represented?
It can be represented in different form. Let us take an example of html page. It generally contains four parts .in the first part, it contain the header part, in second, it contains the body part and in third and fourth part, generally it contains fonts, attributes, footer and etc.
Let us take an example of Google html page. In header, it contains search, images, web and so many things.in body part, Google India with search box, in footer it contains
[image:2.612.49.285.119.468.2]Google.co.in offered in: Hindi Bengali Telugu Marathi Tamil Gujarati Kannada Malayalam Punjabi.
Fig. 1.3 Representation of a web page in Html
1.1 Why this Approach Needed?
As we know that number of online databases are increasing day by day but all the previous approach are using the old technique, they are not upgrading their approach.
First, I want to describe the approaches which has been previously used: some of approaches were low efficient and not scalable. E.g. TSIMMIS, Web-OQL.
Some were time consuming. E.g. WIEN, XWrap. Some of approaches don‟t extract either data record or data item. Second thing, these approaches don‟t generate the sleeve due to which extraction process becomes very complex.
I am putting a question here from which the necessity of our approach can be significantly identified. Why some webpage opens only in Mozilla, some in opera, some in Google chrome. Why they get login information when we change the browser? Why the programming interfaces differ the extraction. If you will use this website http://selfcare.wdc.bsnl.co.in/irj/portal then it won‟t be open in Mozilla/opera//internet explorer now a days but it will open in Google chrome. Google chrome uses the updated approaches regarding alignment, block clustering, regrouping and so many technique but internet explorer/Mozilla don‟t use.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
687
Two years ago, someone was the website administrator who was maintaining the website. He was using html language and now a days, some different one is the website administrator who is maintaining the website by using xhtml, xml or any different language from html and second thing is that old administrator was using the version of html 4 and new administrator is using html 5 then will the previous approach extract data from the language used as xhtml, xml and so on. The answer is no.
In previous year, most of the work hasn‟t considered the scripting such as java script, Vb script so the extraction was something complex, time consuming and hard.
1.2 Objectives
The objective of this proposed approach is to automatically detect the schema of a hidden (dynamic) page and extract the data record and data item from the web page which may contain different version, language, scripting so this approaches will remove the limitation from version, language and scripting. In this approach, a block tree will be formed from the dynamic web page such as from html page which will contain some features after then data record, data item will be extracted. For not becoming complex extraction, data sleeve will be generated. We integrate many technique which includes filtering, clustering, regrouping, alignment to extract very complex and accurate data.
II. LITERATURE SURVEY
As the online databases are increasing day by day so the unstructured data is also increasing. Unstructured Data (or unstructured information) generally refers to data that either does not have a pre-defined data model and/or does not fit well into relational tables. Unstructured information is typically text-heavy, but may contain data such as dates, numbers, and facts as well. This results in irregularities and ambiguities that make it difficult to understand using traditional computer programs as compared to data stored in fielded form in databases or annotated (semantically tagged) in documents. The theme for this literature survey is to differentiate the existing approach to the new approach. We first describes necessary components that are not the main contributions of the thesis yet are important components of the proposed method. These components are a populated ontology, semantic annotation of document collection to identify the named entities from the ontology, indexing and retrieval based on keyword input from user. Second, related previous work is described.
2.1 Semantic Web
The Semantic Web is a perception that describes a possible form that the Web will take as it evolves. Such vision relies upon added semantics to content that in the first version of the Web was intended solely for human consumption. This can be viewed from the perspective that a human could easily interpret a variety of web pages and glean understanding thereof. Computers, on the other hand, can only achieve limited understanding unless more explicit data is available. It is expected that the mechanisms to describe data in Semantic Web terms will facilitate applications to exploit data in more ways and lead to automation of tasks. The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries.
One of the basic means to explicitly state or add meaning to data is the Resource Description Framework, which provides a framework to capture the meaning of an entity (or resource) by specifying how it relates to other entities (or classes of resources). Thus, this is a step beyond metadata, in particular, semantic metadata, which can be described as content enriched with semantic annotations using classes and relationships from an ontology. Semantic technologies are gaining wider use in Web applications.
2.2 Large Populated Ontologies
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
688
Another important factor related to the population of the ontology is that it should be possible to capture instances that are highly connected (i.e., the knowledge base should be deep with many explicit relationships among the instances). This will allow for a more detailed analysis of current and future semantic tools and applications, especially those that exploit the way in which instances are related.
In some domains, there are available ontologies that were built with significant human effort. However, it has been demonstrated that large ontologies can be built with tools for extraction and annotation of metadata. Industry efforts have demonstrated capabilities for building large populated ontologiesError! Reference source not found., which are sometimes called shallow ontologies. Shallow
ontologies contain large amounts of data and the concepts and relations are unlikely to change, whereas deep
ontologies contain smaller (or not any) amounts of data but the actual concepts and relations require extensive efforts on their building and maintenanceError! Reference source not found..
An ontology intended for search of documents calls for focusing on a specific domain where populated ontologies are available or can be easily built. Ontologies used in our approach need to contain named-entities that relate to other entities in the ontology (i.e., resource-to-resource triples). The named-entities from the ontology are expected to appear in the document collection. This can be a limitation in certain domains for which ontologies are yet to be created. However, techniques and developments continue for metadata extraction of semantics. For example, a recent work opens possibilities of ontology creation from wiki content. In domains such as life sciences and health-care many comprehensive, open, and large ontologies have been developed.
2.3 SWETO Ontology
We now review our earlier work for building a test-bed ontology, called SWETO (Semantic Web Technology Evaluation Ontology). SWETO has demonstrated that large populated ontologies can be built from data extracted from a variety of Web sources. We have found that the richness and diversity of relationships within an ontology is a crucial aspect. SWETO captures real world knowledge with over 40 classes populated with a growing set of relevant facts, currently at about one million instances. The schema was created in a bottom-up fashion where the data sources dictate the classes and relationships. The ontology was created using Semagix Freedom, a commercial product which evolved from the LSDIS lab‟s past research in semantic interoperability.
The Freedom toolkit allows for the creation of an ontology, in which a user can define classes and the relationships that it is involved in using a graphical environment.
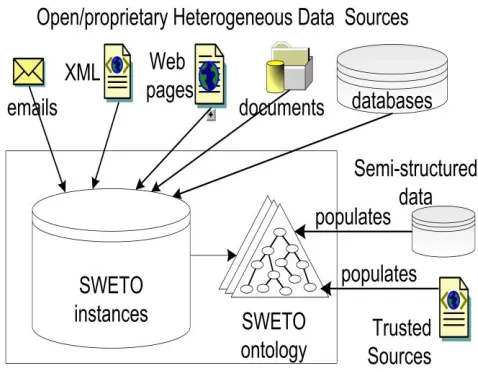
[image:4.612.322.561.367.553.2]We selected as data sources highly reliable Web sites that provide instances in a semi-structured format, unstructured data with structures easy to parse (e.g., html pages with tables), or dynamic sites with database back-ends. We carefully considered the types and quantity of relationships available in each data source by preferring those sources in which instances were interconnected. We considered sources whose instances would have rich metadata. For example, for a „Person‟ instance, the data source also provides attributes such as gender, address, place of birth, etc. Last, public and open sources were preferred, such as government Web sites, academic sources, etc. because of our desire to make SWETO openly available. Error! Reference source not found..1 illustrates the fact that a variety of heterogeneous data sources are extracted for the instance population of the ontology.
Fig. 2.1 Data Sources for SWETO Ontology
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
689 2.4 SwetoDblp Ontology of Computer Science Publications
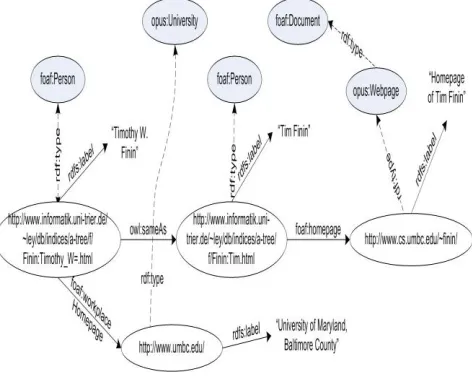
SwetoDblp builds upon our previous experience on creating and using SWETO. It integrates additional relationships and entities from other data sources. It is a large populated ontology with a shallow schema yet a large number of real world instance data. It was built from an XML file from DBLP whereby instead of a one-to-one mapping from XML to RDF, the creation of the ontology emphasizes the addition of relationships and the value of URIs. The hierarchical structure of XML documents implies relationships from parent to children elements. However, such relationships depend upon human interpretation. The creation of SwetoDblp is done through a SAX-parsing process that performs various domain-specific transformations on a large XML document to produce RDF. The schema-vocabulary part of the ontology is a subset of an ontology used by the back-end system of the LSDIS Lab‟s publications library. This schema adopts major concepts and relationships from other vocabularies and extends them where needed. We followed specific guidelines to provide the general framework under which various domain specific mappings were implemented for the creation of SwetoDblp. First, in the original XML document, the names of persons appear as plain literal values such as <author>Li Ding</author> but each of these is represented as an RDF resource in SwetoDblp having its own URI. Our goal was to create URIs so that they can be reused by other datasets based on the assumption that the URI of choice will likely be the URL pointing to the author‟s DBLP entry on the Web. However, other methods to create URIs do allow for content-negotiation depending on whether a request on the Web indicates that a Webpage is needed or that XML/RDF content is needed. The form in which URIs are set in DBPedia is one example of such content-negotiation. Second, we made an effort to reuse existing semantic web vocabularies whenever possible. For example, if the homepage of an author is available in the original XML document, then such relationship is kept in the resulting RDF by using foaf: homepage (of the FOAF vocabulary). In addition, the „homepage‟ is represented as an RDF resource (with the URL as its URI); this domain-specific mapping automatically assigns a label to the homepage resource with the prefix “Homepage of.” In very few cases, the data from DBLP indicates that a person can be referred to by more than one name. A dataset about Publishers is used to create a relationship from literal values such as <publisher>McGraw-Hill</publisher> to an RDF publisher entity with an URI that points to the actual website of the publishing company.
The Publishers dataset was created manually with the most commonly appearing names of publishers in the original XML document from DBLP, but more publisher entities were added to cover all publishers that appear in DBLP data. We could not locate the website of a small number of (arguably local or out of business) publishers. We assigned them an arbitrary URI using the “example.org” domain name as prefix. In addition, another dataset is of information about „Series‟ such as Lecture Notes in Computer Science and CEUR Workshops. Over 5,700 relationships were added from publication to series in SwetoDblp. These datasets are all represented in RDF to allow for easy inclusion of synonyms. A lookup operation on the respective datasets is in most cases the key to establish relationships that enrich SwetoDblp. Fig. 2.2
illustrates an example where a person entity has homepage from which the affiliation information is extracted. It also shows the case of two entities connected through same as
[image:5.612.327.563.357.547.2]relationships.
Fig. : 2.2 Relationships in SwetoDblp Entities
2.5 Discovery, Analysis and Ranking of Relationships
A key element present in Semantic Web is that of relationships, which a first-class object in RDF are. Relationships provide the context (or meaning) of entities, depending on how they are interpreted and/or understood. The value relies on the fact that they are named
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
690
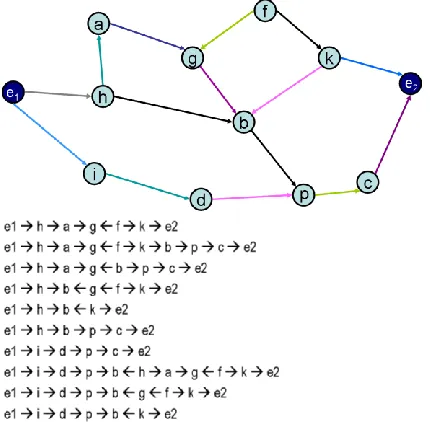
[image:6.612.62.277.252.463.2]A key notion to process relationships between entities is the concept of semantic associations, which are the different sequences of relationships that interconnect two entities; semantic associations are based on intuitive notions such as connectivity and semantic similarity. Each semantic association can be viewed as a simple path consisting of one or more relationships, or, pairs of paths in the case of semantic similarity. Fig. 2.3 illustrates a small graph of entities and the results of a query for semantic associations taking two of them as input.
Fig. 2.3 Semantic Associations from a small graph
Most useful semantic associations involve some intermediate entities and associations. Relationships that span several entities may be very important in domains such as national security, because this may enable analysts to see the connections between disparate people, places and events. In fact, applications that utilized the concept of semantic associations include search of biological terms in patent databases, provenance and trust of data sources, and national security. The applicability of semantic associations in my research comes from the need to analyze relationships.
The type of operations needed to discover semantic associations involve graph-based traversals. It has been noted that graph-based algorithms help analysts of information to understand relationships between the various entities participating in events, activities, and so on.
The underlying technical challenge is also related to the common connecting-the-dots applications that are found in a broad variety of fields, including regulatory compliance, intelligence and national security and drug discovery. Additionally, techniques that use semantic associations have been applied for Peer-to-Peer (P2P) discovery of data and knowledge aggregation. For example, a P2P approach was proposed to make the discovery of knowledge more dynamic, flexible, and scalable Since different peers may have knowledge of related entities and relationships, they can be interconnected in order to provide a solution for a scientific problem and/or to discover new knowledge by means of composing knowledge of the otherwise isolated peers.
Ranking of semantic associations has been addressed by our colleagues taking the approach of letting the user choose among discovery mode and conventional mode of discovery/ranking of relationships. They considered rare vs. common appearances of relationships in a populated ontology.
Research in the area of ranking semantic relations also includes, where the notion of “semantic ranking” is presented to rank queries returned within semantic Web portals. Their technique reinterprets query results as “query knowledge-bases”, whose similarity to the original knowledge-base provides the basis for ranking. The actual similarity between a query result and the original knowledge-base is derived from the number of similar super classes of the result and the original knowledge-base. In our approach, the relevancy of results usually depends on a context defined by users.
Ontocopi is an application that identifies communities of practice by analyzing ontologies of different domains. Ontocopi discovers and clusters related instances by following paths not explicit between them. Their work differs from ours in the dataset size. We aim at large scale algorithms that take advantage of the large metadata extracted from data sources.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
691
III. PROPOSED SYSTEM
This Approach will remove all the limitations which were present in previous approaches. This system will first form the visual block tree. This visual block tree has internally some features which will differentiate the data record and data items by position wise, layout wise, appearance wise and content wise. After then data record will be extracted with the help of filtering the unwanted block, clustering the block and regrouping the block. After then data items will be extracted with the help of alignment technique. Visual sleeve generation will be helpful for time consuming and complex data extraction.
3.1 Advantages
Following are the advantages from this approach: <1> No Web Page Programming Language Dependency <2> No Version Dependency
<3> No Scripting Dependency <4> No Software Plugins Requirement
IV. ARCHITECTURE
Fig3. Architecture of an Apotheosis Approach of Dynamic Web Data Extraction
In this approach, data is extracted through the query submitted in a dynamic web page. Once the query is submitted in a search box, a visual block tree is being formed.
The dynamic page consists of html, dhtml, xml tags which is used for web page representation. These tags are being converted into block tree and further it is processed through the algorithm used in this approach.
V. APPROACHES USED
Here, we have used 5 types of approaches:
<1> Visual Block Tree Formation
First, from a given hidden web page, all the html parts will be transformed in visual block tree. We employ an algorithm which will transform a deep web page into a visual block tree and will be used to extract the visual information such as videos, images, pdf, docs, text etc.
Visual block tree has internally some properties like as it can‟t overlap each other, the block with same parents are arranged in tree according to order of corresponding nodes.
<2> Data Record Extraction
As Visual Block tree has mainly 4 features namely as position features, layout features, appearance features and content features. Position feature, Layout feature and Appearance feature is used in data record extraction while Content feature is used in Data Item Extraction.
Position feature locate the data region on a hidden web page. Layout feature calculate that how the data record in data region are arranged i.e. is they adjoining or overlapping? Appearance feature capture the visual feature within data records i.e. this feature differentiate between them if the data records are of same type. Suppose there are five records in web data base. Each having same pixel, same font number, same size then this feature will automatically differentiate between them and extraction will be processed further.
Based on above three features, extraction is followed by passing three phases:
In phase one, some unwanted block is being filtered because of no use in extraction. Sometimes some noisy block automatically formed then in second phase, once the block filtered it is then clustered. For that appearance feature is used. After then in last phase, regrouping of block is done which can been clearly seen by the architecture diagram.
<3> Data Item Extraction
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
692
Each having same title name, same author name, same price, same publication then how it will be extracted. How the architecture will detect the internal schema? So there should be some mandatory so that we can extract. If we assign different ISBN to all 10 books then obviously, with the help of content feature mandatory thing such as ISBN will be identified and Data Item Can be extracted.
This extraction works on data item alignment phase. In this phase, we can‟t align data directly due to the existence of optional data item. For that, an algorithm is employed which will match the optional data item and process further after then data alignment algorithm is processed.
<4> Data Record Sleeve
Sometimes, we need a sleeve because of complex and time consuming process in data record extraction .data record sleeve first locate the data region in visual block tree from a hidden web page and then extract the data record from the child block of the data region.
<5> Data Item Sleeve
Data Item Sleeve will encourage the data alignment algorithm to group data items from different data record into columns or attributes such that data item under the same column have the semantic.
VI. CONCLUSION
In this paper, we proposed an approach which is very useful for hidden web data extraction due to formation of visual block tree which having internally some features to differentiate the optional and mandatory part and this approach also having data record sleeve and data item sleeve in case of time consuming and complex process. We can extract the data easily from web page language dependent page, version dependent page, scripting dependent page and sometimes plugins dependent pages.
REFERENCES
[1] H. Zhao, W. Meng, Z. Wu, and C. Yu, “Automatic Extraction of
Dynamic Record Sections from Search Engine Result Pages,” Proc.
32nd Int‟1 Conf. Very Large data Bases (VLDB), 2006.
[2] V. Crescenzi, P. Merialdo, and P. Missier, “Clustering Web Pages
Based on Their Structure,” Data and Knowledge Eng., vol.54, pp. 279-299, 2005.
[3] B. Liu, R.L. Grossman, and Y. Zhai, “Mining Data Records in Web
Pages,” Proc. Int‟l Conf. Knowledge Discovery and Data Mining (KDD), pp. 601-606, 2003.
[4] K. Simon and G. Lausen, “ViPER: Augmenting Automatic