Boosting the Efficiency in Similarity Search on Signature Collections
Full text
Figure



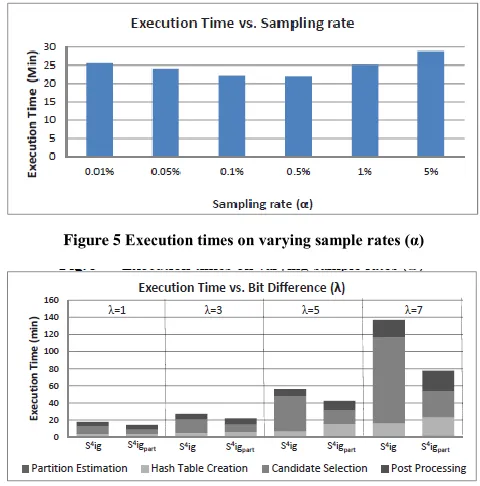
Related documents
10.2.4 Suppliers shall where ever possible purchase items in support of MAv orders from a source certified by a recognised certification body (e.g. UKAS accredited) to an
It was decided that with the presence of such significant red flag signs that she should undergo advanced imaging, in this case an MRI, that revealed an underlying malignancy, which
There are infinitely many principles of justice (conclusion). 24 “These, Socrates, said Parmenides, are a few, and only a few of the difficulties in which we are involved if
In the other hand we notice that catalase, superoxide dismutase, glutathione reductase activity and peroxidized lipid level (TBARS or malondialdehyde) + aqueous
If you wish to take Clinical Mental Health Counseling, Human Sexuality and Development, or School Counseling for 3 graduate credit hours, register for PSYC 630, PSYC 601
The anti- oxidant activity was performed by DPPH free radical scavenging method using ascorbic acid as standard and compound IIa, IIc and IId showed significant free
The total coliform count from this study range between 25cfu/100ml in Joju and too numerous to count (TNTC) in Oju-Ore, Sango, Okede and Ijamido HH water samples as
ABSTRACT We present a new approach for fine-grained classification of retail products, which learns and exploits statistical context information about likely product arrangements
