International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
258
Synonym Based Ranked Secure Search Over Encrypted Data
Divya Sunny
1, Anupama George
21Assistant Professor, 2PG Scholar, Department of Computer Science and Engineering, St. Joseph’s college of Engineering and
Technology, Palai, Kottayam
Abstract— Most of the data owners and the web service providers uses the Cloud technology for store and share their data. Because the cloud computing will provide an efficient way to Store and Share the data without compromising the privacy. Security is enforced by encrypting the data. Encryption will complicate some basic properties of data set such as search over the data.
In earlier the searching is start done by exact query matching where the searching is done for a given search word inside the unencrypted document. Then searchable encryptions are developed for search over encrypted data. The index based scheme will solve the problem of security and provides the search over encrypted data. But the ranked search based on frequency of search key word in document challenges the security even if we are using the index based scheme. The multi-server secure scheme in which the data is divided into leaked information and data set and are separately stored in different servers will give extra security, but the servers must never integrate together. We cannot promise this over a long period of time. The continuous monitoring to the document ID, URL and the document indexes allows the hackers to break the system
Here we propose an efficient, secure and fast data searching scheme which will also capable of handling efficient data management in cloud servers. The index scheme is used to enable fast search while ensuring the security. Ranking of the document for displaying the document will improves the efficiency. The efficiency of searching can also be improved by synonym based search. The security can be enhanced by encrypting each of the documents with different keys. By the use of user-unaware-key-management we can improve confidentiality.
Keywords— Document Ranking, Secure Index, User unaware key management
I. INTRODUCTION
Due to the large advantages and application of the cloud computing, it becomes more popular. Now a days most of the sensitive data are stored in the cloud servers. The main corns of the cloud computing is security, which is enforced by the encryption. Search over the data and data managements are the main requirements of a large data storage systems. So the basic requirement of cloud data server are an efficient search scheme over encrypted data , good data management scheme and a secure storage scheme.
The fast search can be implemented easily by using the indexing of document. In indexing the key terms or main features of the document are provided as the index words. The indexes can be manually provided by the data owner or can be automated. The grouping of data with similar indexes will leads to efficient management and fast searching of data. The locally sensitive hashing (LSH) is the best method for the grouping the data and by provide a way for similarity search over the data.
The similarity search problem contains a collection of data items and that have some features or that are associated with some indexes. The search query will specifies an index or a value for a particular feature and a similarity metric to measure the relation between the query and the data items. The goal is to retrieve the items whose similarity with the specified query is greater than the predetermined threshold.
One of the important concerns of the data server is security. The security can be achieved by encrypting the data item. AES is the most popular encryption scheme which we are used today. Authentication can also be added to the system to improve the security. User unaware key management is a mechanism in which all the documents are encrypted using different keys and that keys are shared among the users; but the user are unaware about such keys and when they require the data the key is automatically generated by the system and decrypted the data. And the decrypted data is given to the user.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
259
II. RELATED WORKS
The searching technology is start with exact query matching where the searching is done for a given search word inside the whole document which is an unsecure and inefficient method. Then exact query matching technique is replaced by searchable encryptions. A mixture of protocols and security definitions are available for searchable encryptions. Optimal security is achieved by the oblivious RAM model [13]. It does not leak any information to the server but this model is impractical for real world scenarios due to the excessive computational costs. As an alternative to heavyweight oblivious RAM, there are approaches ([7]– [12]) to selectively leak information (e.g., search pattern and access pattern) to provide practical searchable encryption schemes. The first of such practical approaches was provided in [12] is to encrypt each word of a document with a special encryption construct. In [11] proposed a security definition to formalize the security requirements of searchable symmetric encryption in similarly. The [9] introduced a simulation based security definition, which is stronger than the [11]. The [9] and [11] do not consider adaptive adversaries which could generate the queries according to the outcomes of previous queries. This problem is handled in [7], which presented adaptive security definition for searchable encryption schemes and also provided a protocol that is compatible with their definition.
All these techniques are based on exact query matching do not implement the similarity matching. So these schemes are not resistant to the typographical errors. To overcome this wildcard based fuzzy keyword search scheme over encrypted data in [4] we use an fuzzy set based scheme. This fuzzy scheme will tolerate errors up to some extent only. And it also requires large space to store the fuzzy sets and the fuzzy sets may become too big if we have long words. Another similarity searching technique to search approximate string Hamming distance for encrypted data was proposed in [14]
The efficiency of the search scheme can be improved by using hashing techniques. The [6] introduce an efficient query handling scheme using hashing and record linkage. Mainly all the searching scheme in based on single query where as in [3] there introduced a search scheme based on multiple search queries. That is search can be done based on multiple features or multiple indexes.
Secure index based search in [14] was also applied in the context of encrypted multimedia databases is introduced in [15]. Here extract visual words from images and construct indexes according to them.
[image:2.612.326.564.189.287.2]Their approach is slightly different than traditional search such that query is not a specific feature for an image but all features of an image. The goal is to retrieve images that are similar to the query image.
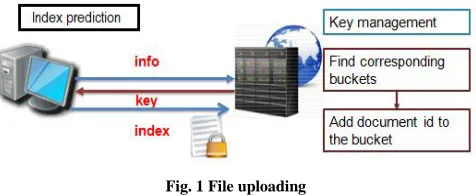
Fig. 1 File uploading
The approach in [1] integrates the advantages of [6], [3] and [14]. The [1] contain a similarity search which makes use of locally sensitive hashing (LSH) for efficient search, fuzzy set implementation for fault tolerant key word search and multi-keyword search.
In addition to index based schemes, there are some other wildly used techniques that enable security challenges. One of these in [5] introduces a searching scheme which contains the interaction with data owner for creating the search query.
III. PROPOSED SYSTEM
All In the new system we build a secure index and outsource it along with the encrypted data items. Each index is mapped to a data bucket. Data bucket contain id of all the documents which have the bucket index as one of its index. At time of document upload the client send a request to the server for a unique password. Then the server generate the password form the features of document and how uploading the document and send to the client/data owner. Then using that password the data owner encrypt the document and uploaded the document along with the secure indexes.
At the time of file upload the server check for corresponding bucket in the data base based on the index word given by the user and selects the corresponding bucket to a data item. If there is no such a bucket then the server creates a new bucket for the documents index and adds the document to the newly created bucket.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
260
The data owner’s unique identifier, the file’s unique identifier and the file name are used to generate the message digest. The AES is the encryption scheme used to encrypt the files.
Based on the words inside the document the system itself able to predict the index words, but the final submission is by the data owner. He can select from the predicted words by the system or can add manually.
Secure LSH index prediction based on the count of each word inside the document, file uploading and bucket management is summarized in Alg.1 and the figure for this is shown in fig.1 File uploading.
Algorithm.1
I Document index
Ii ith word in the I
Bi ith Data bucket
g(Ii) Mapping function from Ii to Bi
Di Document to be uploaded
Pi Password for encrypt the document
F Predicted indexes
W Word count list of the Di
Fi ith index in F
FID unique identifier for file
OID unique identifier for Data owner
E(Di) Encrypted Di
Provide the details about the document Di
And load the document Di.
F PredictIndes(W)
Fi Selected Fi from F + added by the Data Owner
Pi Password Generate(FID,OID,File name)
E(Di) Encrypt (Di,Pi)
for all Ii Ido
Ii apply metric space translation on Ii
if g(Ii) bucket identifier list then
Add g(Ii) to the data bucket list
Set size of g(Ii) = 1
Map Di to g(Ii)
else
Set size of g(Ii) = size +1
Map Dito g(Ii) end if
end for
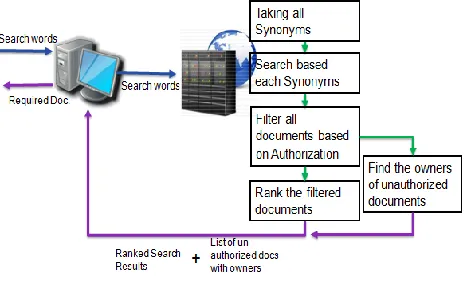
[image:3.612.328.561.365.516.2]At the time of searching the user enter the search words the searching is done across the bucket index. The process of searching starts with taking the synonyms of the search words.
Fig. 2 File searching
Then search is performed based on the all the synonyms and search words across bucket indexes and return all the authorized documents corresponding to from the selected buckets. The results are ranked based on the history and the number of times the document id is present in the buckets. That is it support for multi-key word search and then returns the best result as the first document in the result list. The file searching is summarized in the figure fig.2 File searching and also shown in the Algorithm 2.
Algorithm.2
Q Search query
Qi ith word in the Q
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
261
g(fi) Mapping function from Qi to Bi
Di ith Document
Si Synonyms of Qi
V Set of pointers to each result
Di ith Document
for allQiQdo
Si synonyms(Qi)
for all SijSi
Sij apply metric space translation on Sij
if g(Sij) bucket identifier list then
Select the buckets Bi
temp = all Di where Di Bi
end if
end for
end for
for all Di temp
if the user is authorized to view that document
Add document to result
else
Add document to list
end if
end for
Rank the Doc.ID in result based on history and the number of times the document id is present in the buckets
for all Diresult crate a pointer to result
Create pointer Vi to Di
end for
Return V and list
V contains a pointer to each authorized document and is displayed as document link. On selecting one of the links send a request to the server for that document. Then the key for that document is generated. The key generation is same as that of uploading face. That is the key is generated using the SHA-1.
The input to the SHA-1 is the data owner’s unique identifier, the file’s unique identifier and the file name. Then the 160 bit is converted to 128 bit and the 128 bit key is used for the AES decryption. The file and the key are given to the client and the decryption is performed in the client side.
The document download is given in Alg.3 and summarised in the figure fig.3.Document download.
Algorithm.3
Pj Password for decrypt the document
CLIENT SIDE
for allVi in V
Display the Vi as link
end for
while selecting the link
Send request contain Doc. ID
end while
SERVER SIDE
Pj Password Generate(FID,OID,File name)
return encrypted data and key corresponding to Doc.ID
CLIENT SIDE
Decrypt the document using the key
[image:4.612.325.563.495.577.2]return the document to client.
Fig. 3 Document download
IV. EXPERIMENTAL EVALUATION
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
262
A. User Unaware Key Management
To verify the user unaware key management we want to evaluate mainly 2 things. First one is the uniqueness of the key. The second is the same key generation at the time of encryption and decryption. First one is evaluated using uploading same document with same indexes by same and different data owners. And the result is checked by performing search on the data base for any two similar encrypted documents. 10 data owners are uploaded the same document 5 tines but cannot find the similar encrypted files in the data base. The rest is evaluated by downloading random 100 documents and check they are perfectly decrypted or not. We observed that all are decrypted correctly.
B. Automatic Index Prediction
The automatic index prediction is evaluated by checking the predicted indexes and keywords of the documents. Testing is done with 20 document files, 20 text files, 20 PDF files and 20 PPT files.
The most frequent words, which may consider as the candidate for the index, are successfully predicted by the system.
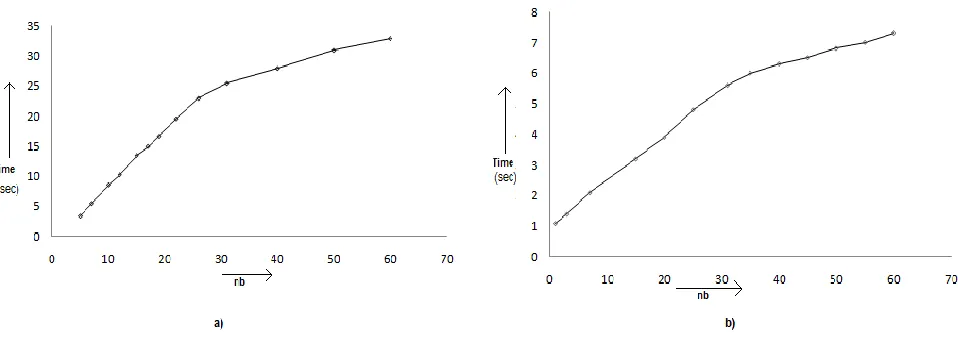
C. Search Performance based on number of documents in each bucket
[image:5.612.66.545.383.556.2]The performance of the system is checked by testing the execution time of the search with different indexes which have various numbers of documents inside each index bucket. The number of documents in each bucket is denoted by nb. The nb-time graph is plotted for synonym based and non synonym based search in figure 4. At the starting the search time is increased with increasing number of documents inside the bucket. But later it become almost constant. Figure 4(a) shows the graph for synonym based search and Figure 4(b) shows the graph for non synonym based search.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
[image:6.612.52.285.136.308.2]263
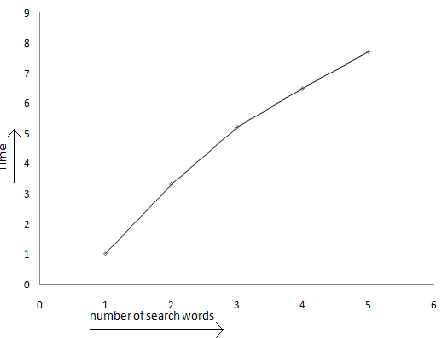
Fig. 5 Graphical representation of performance of synonym based search, based on the number of synonyms
Fig. 6 Graphical representation of performance of based search, based on the number of search words
D. Search Performance based on number of Synonyms
The performance of the system based on number of synonyms is checked by reviewing the search time of different indexes with different number of synonyms. The observations are graphically plotted in figure 5.
The rate of increase in time based on the number of synonyms is gradually decreasing. So we can predict that at some point it may become zero.
E. Search Performance based on number of search words
The multi-key word search enabled here is tested by testing the performance of search by providing different number of search words in the search query. The observations are plotted in the figure 6.
Here also the initial increases is very high but the increasing rate is gradually decreasing and tends to become zero. That is the search time is become constant.
V. CONCLUSION
Synonym based Ranked Secure Search over Encrypted Data makes use of LSH based secure indexing, user unaware key management, automatic index prediction, synonym based searching, multi-key word search, user authentication and document ranking. Hence it will enable fast similarity search over encrypted data without compromising the security. User unaware key management, encrypting each document with unique key and user authentication will provide more security compare to other system. The integration of synonym based search, document ranking and multi-keyword search will provide more efficiency compare to existing ones.
VI. FUTURE SCOPE
The synonym mapping is the most difficult task. It can be done manually by the help of an administrator or automatically by the help of English dictionary or can be done by integrating the system with some topic mining data bases. The manual one is difficult at the starting face but it becomes like a topic miner after a long run. The use of English dictionary is not suitable for the technical words. The integration with the topic mining database is so expensive and it cannot be modified based on our system behaviour.
REFERENCES
[1] Mehmet Kuzu, Mohammad Saiful Islam and Murat Kantarcioglu, ―Efficient Similarity Search over Encrypted data‖, IEEE International Conference on Data Engineering, April 2012. [2] Cong Wang, Ning Cao, Jin Li, Kui Ren, and Wenjing Lou, ―Secure
Ranked Keyword Search over Encrypted Cloud Data‖, IEEE 30th International Conference on Distributed Computing Systems, June 2010
[3] Ning Caoy, Cong Wangz, Ming Liy, Kui Renz, and Wenjing Lou, ―Privacy-Preserving Multi-keyword Ranked Search over Encrypted Cloud Data‖, IEEE Transactions on Parallel and Distributed Systems, Jan. 2014
[4] J. Li, Q. Wang, C. Wang, N. Cao, K. Ren, and W. Lou, ―Enabling efficient fuzzy keyword search over encrypted data in cloud computing‖, in Cryptology ePrint Archive, Report 2009/593, 2009. [5] Yanbin Lu ―Privacy-preserving Logarithmic-time Search on
Encrypted Data in Cloud‖, Internet society, Feb 2012
[image:6.612.56.277.343.512.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
264
[7] R. Curtmola, J. Garay, S. Kamara, and R. Ostrovsky, ―Searchable symmetric encryption: Improved definitions and efficient constructions,‖in Cryptology ePrint Archive, Report 2006/210, 2006 [8] M. Bellare, A. Boldyreva, and A. ONeill, ―Deterministic and efficiently searchable encryption,‖ in Proc. of Crypto’07, 2007, pp. 535–552.
[9] Y. Chang and M. Mitzenmacher, ―Privacy preserving keyword searches on remote encrypted data,‖ in Proc. of ACNS’05, 2005, pp. 442–455.
[10] D. Boneh and B. Waters, ―Conjunctive, subset, and range queries on encrypted data,‖ in Theory of Cryptography, ser. LNCS, 2007, vol. 4392, pp. 535–554.
[11] E. Goh, ―Secure indexes,‖ in Cryptology ePrint Archive, Report 2003/216, 2003.
[12] D. Song, D. Wagner, and A. Perrig, ―Practical techniques for searches on encrypted data,‖ in Proc. of the IEEE Symposium on Security and Privacy’00, 2000, pp. 44–55.
[13] O. Goldreich and R. Ostrovsky, ―Software protection and simulation on oblivious rams,‖ Journal of the ACM, vol. 43, pp. 431–473, 1996. [14] H. Park, B. Kim, D. H. Lee, Y. Chung, and J. Zhan, ―Secure similarity search,‖ in Cryptology ePrint Archive, Report 2007/312, 2007.