A PRACTICABLE CONSISTENCY SCHEME
FOR
FILE REPLICATION
Sebnem Baydere
D epartm ent o f C om puter Science U niversity C ollege L o ndon
All rights reserved INFORMATION TO ALL USERS
The qu ality of this repro d u ctio n is d e p e n d e n t upon the q u ality of the copy subm itted. In the unlikely e v e n t that the a u th o r did not send a c o m p le te m anuscript and there are missing pages, these will be note d . Also, if m aterial had to be rem oved,
a n o te will in d ica te the deletion.
uest
ProQuest 10610947
Published by ProQuest LLC(2017). C op yrig ht of the Dissertation is held by the Author.
All rights reserved.
This work is protected against unauthorized copying under Title 17, United States C o d e M icroform Edition © ProQuest LLC.
ProQuest LLC.
789 East Eisenhower Parkway P.O. Box 1346
Abstract
5
Acknowledgements
I w ish to thank Mr. B enjam in Bacarisse, for his encouragem ent, continuous support and supervision during the course o f m y research. W ithout his guidance I w ould not have been able to carry out this study.
I am indebted to Prof. Steve W ilbur who has given valuable advice at the initial stages o f the research and spent a great am ount o f tim e reading and com m enting during the w riting phase o f this dissertation.
I am also grateful to Prof. M. Sahinoglu and K aren Paliw oda who helped with the statistical analysis and to Dr. K en M oody for his constructive com m ents on the thesis.
I w ould like to make a special note o f thanks to my husband for the support he has given m e during the period o f m y research.
T able o f Contents
A bstract ... 3
A ck n o w led g em en ts... 5
T able o f C o n te n ts ... 7
List o f Figures ... 11
List o f Tables ... 13
1. C h a p te r O ne: I n t r o d u c t i o n ... 15
1.1 Objectives o f the th e s is ... 17
1.2 Outline ... 18
1.3 Distributed System M odels ... 19
1.4 Replicated File S y s te m ... 20
1.4.1 Concurrency Control P ro b le m ... 24
1.4.2 Consistency C ontrol P r o b le m ... 26
1.4.3 Com m unication S y s te m ... 27
1.4.4 File vs Block Level R eplication ... 28
1.4.5 Building R eplication into the File System ... 29
1.5 Types of Failure and R e c o v e ry ... 31
1.6 M easures of File A ccessibility ... 34
1.6.1 Availability ... 35
1.6.2 Reliability ... 37
1.7 S u m m a ry ... 37
2. C h a p te r Tw o: C o n s is te n c y C o n tr o l S c h e m e s ... 39
2.1 Unanimous A greem ent U pdate ... 40
2.2 Single-Primary U p d a te ... 41
2.3 M oving-Prim ary U pdate ... 41
2.4 Voting A lgorithm s ... 43
2.5 Efficient V ariations o f V o tin g ... 44
2.5.1 Reducing Storage C ost w ith W itn e sse s... 45
2.5.2 Enchancing A vailability with Ghosts ... 45
2.6 O ptim um Vote A ssignm ent or Coteries ... 46
2.7 Available Copies ... 47
2.8 R egeneration ... 49
2.9 D iscussion ... 51
2.10 Sum m ary ... 52
3. Chapter Three: A H y b r id R e p lic a tio n A l g o r i t h m ... 5 5 3.1 R eplication Control S e r v ic e ... 57
3.2 A vailability C ontrol Protocol ... 60
3.3 H istory Table Control P ro to c o l... 65
3.3.1 C om m unication L ayer ... 66
3.4 System Configuration ... 67
3.4.1 Exam ple Scenarios for the Configure O peration ... 69
3.5 U ser R e q u ire m e n ts... 71
3.6 D is c u s s io n ... 72
3.7 S u m m a r y ... 73
4. C hapter Four: S t e a d y -S ta te A v a ila b ility ... 7 5 4.1 C om binatorial A nalysis o f A vailability ... 77
4 .2 Stochastic A nalysis o f A vailability ... 80
4.2.1 M odelling Three N o d e s ... 82
4.2.2 M odelling Five N odes ... 85
4.2.3 C o n c lu s io n ... 86
4.3 M anaging Replicas in a Partitioned S y s te m ... 88
4.3.1 Com binatorial A pproach to a Sim ple Partitioning ... 88
4.3.2 Resilience to Copy P la c e m e n t... 91
4 .4 S u m m a ry ... 94
5. C hapter Five: R eliability in P a r titio n e d S y s te m s ... 95
5.1 System M odel for R eliability ... 96
5.2 R eliability in Partition-free N e tw o rk s ... 99
5.3 Effect o f Partitions on the Reliability ... 101
5.3.1 Reliability in T o p o lo g y -1 ... 104
5.3.2 R eliability in T o p o lo g y -2 ... 105
5.4 R esilience to C onfigurational Changes ... 106
5.5 A n A nalytical A pproach ... 107
5.5.1 Im proving R eliability w ith R egeneration ... 109
9
6. C h a p te r Six: P e rfo rm a n c e an d P ra c tic a lity ... 111
6.1 The R ange A lgorithm ... 112
6.1.1 S taggering the Replies ... 115
6.1.2 C om m unication Delay ... 116
6.1.3 C onclusion ... 116
6.2 Efficient Im plem entation o f the Schem e ... 117
6.3 N etw ork Traffic A n a ly s is ... 118
6.4 Sum m ary ... 122
7. C h a p te r S even : C o n c lu s io n a n d F u r t h e r W o r k ... 123
7.1 G eneral Sum m ary ... 123
7.2 Sum m ary o f Findings ... 130
7.3 Further W ork ... 131
References ... 133
Glossary ... 139
Appendix A: N otation ... 141
A ppendix B: A nalytic M odel for A vailability ... 143
Appendix C: A nalytic M odel for Finite S p a r e s ... 149
A ppendix D: S im ulation W o r k ... 155
List of Figures
Figure 1.1. A w orkstation environm ent (T opology-1) ... 21
Figure 1.2(a). Building replication on top o f the file s y s te m ... 29
Figure 1.2(b). Building replication as a block-structured device ... 30
Figure 1.3. Backup/recorder process during increm ental d u m p in g ... 33
Figure 2.1. A unanim ous update perform ed on 3 distinct copies ... 40
Figure 2.2 An update operation m aintained by M oving-Prim ary a p p r o a c h 43 Figure 2.3(a). Regeneration: recovery o f a repaired node (case-1) ... 50
Figure 2.3(b). Regeneration: recovery o f a repaired node ( c a s e - 2 ) ... 51
Figure 3.1. Interacting com ponents o f the replication control system ... 59
Figure 3.2. Layer interaction during create o p e ra tio n ... 60
Figure 3.3. Layer interaction during delete operation ... 61
Figure 3.4. Layer interaction during read o p e ra tio n ... 62
Figure 3.5. Layer interaction during w rite o p e ra tio n ... 65
Figure 4.1. States associated w ith R H algorithm w hen m — 3 ... 83
Figure 4.2. Analytic results w hen m =3 ... 85
Figure 4.3. Analytic results w hen m =5 ... 86
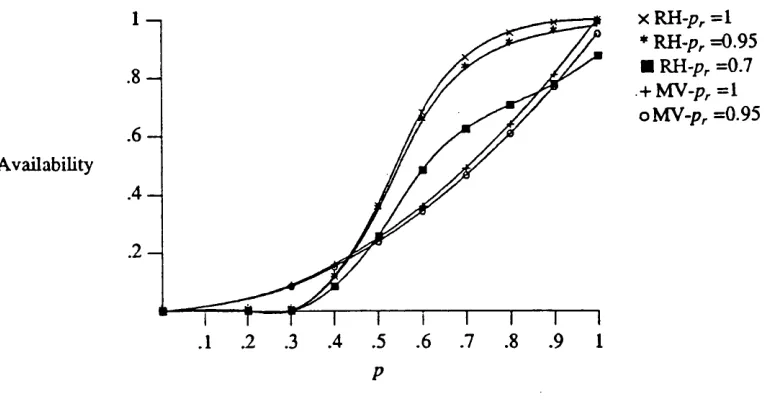
Figure 4.4. Com parison o f availability obtained by different techniques ... 87
Figure 4.5. A simple network topology ... 89
Figure 4.6. Node availability vs File availability ... 91
Figure 4.7(a). Node distribution (5-7) ... 92
Figure 4.7(b). Node distribution (2-10) ... 92
Figure 4.8 A vailability w hen (1 - pr ) = 0.05 — (sim +analy) ... 93
Figure 4.9. Distribution o f availability at p =0.9 ... 94
Figure 5.1. Sim ulation for various tim e periods ... 98
Figure 5.2. Reliability offered by R H for various m ... 99
Figure 5.3. Elapsed time vs R eliability (RH ) ... 100
Figure 5.4(a). Elapsed time vs R eliability (p=0.025) ... 101
Figure 5.4(b). Elapsed time vs R eliability ( p = 0 .2 ) ... 101
Figure 5.5. Failure ratio vs decay constant ... 102
Figure 5.6. A distributed environm ent (Topology-2) ... 102
Figure 5.7. G raph representation ... 103
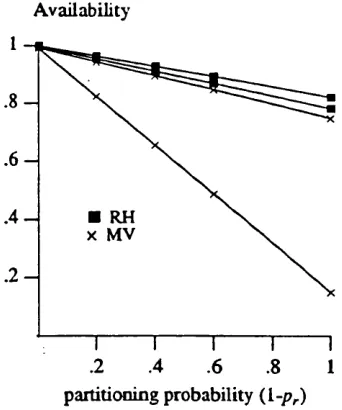
Figure 5.8(b). Elapsed time vs R eliability (RH , M V in T o po lo gy-1) ... 105
Figure 5.9 Elapsed time vs R eliability (RH , M V in Topology-2) ... 105
Figure 5.10 D istribution o f reliability at 1000 tim e u n i t s ... 106
Figure 5.11 D istribution o f decay c o n s ta n t... 108
Figure 6.1(a). M ulticast environm ent ... 120
Figure 6.1(b). U nicast e n v iro n m e n t... 121
Figure B .l. STR diagram for the availability w ith AC (n c o p ie s ) ... 145
Figure B.2. STR diagram for the availability w ith M V (n c o p ie s ) ... 145
Figure B.3. STR diagram for the availability w ith RH (m=5 ) ... 146
Figure C .l. STR diagram for the reliability w ith RH (m=3) ... 153
List of Tables
Table 1.1. Percentage o f accesses that represent w hole-file tr a n s f e r s ... 29
Table 1.2. T echniques used for recovery and availability ... 34
Table 4.1. A vailability offered by various replication schem es ... 79
Table 4.2. A vailability offered by RH for various m ... 87
Table 5.1. Percentage o f time nodes w ere up ... 98
Chapter One
Introduction
D istributed system s provide the opportunity to im prove the fault tolerance o f data through replication. It is often desirable to have m ultiple copies m ainly for applications where interruptions o f service due to node crashes or com m unication link failures cannot be tolerated and the com plexity o f the replication system can be justified by the unac ceptable cost o f failure. H ow ever, the designers o f general purpose distributed systems have concentrated m ainly on the advantages o f data sharing and efficient remote access rather than on high availability through replication [1].
that they allow control over the level o f reliability required for different sets o f files. In addition, replication is required to be transparent; that is its only observable affect is to make the data more available.
The basic aspect o f replication m anagem ent is to guarantee that there is no logical conflict in the u ser’s view. In other w ords, w hen the data is replicated accesses to it m ust be m anaged so as to m aintain consistency. The exact nature o f consistency changes from application to application. This will be discussed in m ore detail below. I f updates may be concurrent the locking protocols [2,3] used to ensure serialization to prevent physical conflicts may also provide the required consistency control. H ow ever, these tw o are separate concerns; consistency problem s are inevitable consequences o f replication w hereas the concurrency problem m ay arise in any concurrent or pseudo-concurrent environm ent.
All schem es developed so far that provide users w ith a consistent view o f replicated data are based on one o f tw o basic principles: The sim plest principle is read anyiw rite all. U nfortunately, this principle im proves the availability o f the file only for read operations by reducing the availability for write operations. In 1984, Bernstein and G oodm an refined the principle giving a schem e that reads from any available copy and w rites to all available copies [4]. This available copies schem e configures out failed nodes from the system and configures them back in w hen they recover; so that, in effect, the algorithm is read any /write all. This m ethod gives optim al availability provided the underlying netw ork never becom es partitioned into m ore than one independently func tioning set o f nodes. If the netw ork does becom e partitioned, this algorithm fails to preserve consistency.
Introduction 17
used by T hom as in 1978. He suggested a sim ple m ajority voting schem e [5]. In 1979, G ifford proposed assigning different weights to different copies and having different read and w rite quorum s [6], Recently, m any different variations to these basic schem es have been suggested [ 7 ,8 ,9 ,1 0 ]. These schem es are discussed in Chapter Tw o.
The principal disadvantage o f voting schem es is that at least three copies o f the data are required to give higher availability than a single copy. Five copies are needed to im prove availability further. This is a significant storage cost com pared to the available copies m ethod that gives considerably im proved availability with only tw o, but w hich cannot continue to w ork if the netw ork becom es partitioned. These claim s are justified in C hapter Four.
1.1 Objectives of the Thesis
There are m any possible approaches to the problem o f consistency control in repli cation. This dissertation investigates a design in w hich the storage cost o f replicated files as w ell as the gain in availability is considered. Such a low -cost im plem entation w ould be suitable for a w ide range o f applications in general-purpose com puting en viron m ents. The design focuses on providing high availability w ith a small num ber o f copies (especially tw o) and on the correctness o f the algorithm in the face o f partitions. Som e im plem entation techniques are also described to enhance the perform ance beyond that o f the basic design. The first objective o f the w ork is thus to show that going from a single copy to tw o copies results in a greater im provem ent in availability than going from two to three copies or beyond.
The second objective is to com pare the netw ork and system architecture assum ed by the various algorithm s to determ ine their practicability. This com parison also includes an exam ination o f the facilities provided for reconfiguration (changing the location o f copies and altering the degree o f replication).
bility o f replicated files. C om m on m easures o f accessibility include availability, w hich is the steady-state probability that the file is accessible at any given m om ent, and reliabil ity, w hich is the probability that a replicated file w ill rem ain continuously accessible over a given period of time. This objective has proved to be more difficult to satisfy m ainly because o f the problem o f adequately generalizing the characteristics o f partitioning. A detailed theoretical analysis o f accessibility has been done for partition free system s and this analysis has been extended to include a sim ple case o f partitioning. T his partitioning analysis has been carried out through sim ulation, and the behavior o f the proposed algo rithm and the related algorithm s have been analyzed in some typical topologies. Some interesting results have been obtained concerning the sensitivity o f different algorithm s to changes to the netw ork topology and copy placem ent. T he proposed design was presented at the IEEE C O M P C O N '89 conference in San Fransisco [11] and the original w ork on the effect o f partitions on reliability o f replicated files will be presented in N ovem ber 1990 at the IE E E W orkshop on M anagem ent o f R eplicated D ata in Hous- ton[12]).
1.2 Outline
The remainder o f this ch apter presents a m odel o f a distributed environm ent, the underlying com m unication m edium and the abstract definition o f the file system includ ing the level at w hich replication is introduced, before outlining the consistency problem o f replicated files. Later som e alternative w ays o f building replication control algo rithm s into the file system are discussed together w ith the effectiveness o f replication in term s o f storage cost and abstract perform ance m easures such as availability and reliabil ity.
Outline 19
Chapter T hree introduces a new low -cost hybrid algorithm called reliable histories for m aintaining consistency o f replicated files in applications w here the storage cost must be kept down.
Chapter Four is the first o f the tw o analysis chapters. First the steady-state availa bility of a replicated file is analyzed using two different techniques: &-out-of-Ai reliability theory and M arkov processes. The analysis focuses on the m inim um num ber o f copies and processing nodes required before the reliable histories algorithm provides better availability than other algorithm s. Secondly, the m anagem ent o f replicated copies in a netw ork that m ay becom e partitioned is exam ined; and the resiliency o f various con sistency schem es to random copy placem ent and netw ork topology is investigated.
Chapter Five contains an original analysis o f the reliability o f a replicated file both in partition-free and partitioned networks. The reliability offered by various consistency schemes is com pared using different failure models and the com parison is extended to include the effect o f partitions in various topologies. Since the technique know n as regeneration affects reliability (not availability), its integration w ith the reliable histories algorithm is also analyzed in this chapter.
Chapter Six concerns the perform ance and the practicality o f the reliable histories algorithm. It focuses on the num ber o f netw ork operations inherited by the algorithm and proposes an algorithm called range, for reducing the cost o f history operations.
Chapter Seven includes a sum m ary o f the basic results obtained from the analytical models and sim ulation. This is follow ed by some suggestions for future work including the investigation o f the interfaces required by users and system adm inistrators. The benefits o f added dynam icity through calculation o f overall reliability are also discussed.
1.3 Distributed System Models
Many different m odels have been suggested. T anenbaum states that these models can be grouped into three general categories [13]: The first m odel consists o f a num ber o f m inicom puters each with m ultiple users. Each user logs onto one m achine w ith rem ote access to other m achines. This system is sim ilar to a central tim e-sharing machine.
In the second category each user has a single w orkstation usually equipped w ith processor, m em ory and a disk. This system becom es distributed w hen it supports a sin gle global file system so that the data can be accessed regardless their location.
The third category is an evolutionary step. All processors are kept in a pool and allocated upon request by the clients. W hen the jo b is com pleted, allocated processors return to the available pool. This m odel m ight becom e w idespread w hen the C P U ’s becom e m uch cheaper. However, there have been some attem pts to com bine the second and third m odels providing each user w ith a w orkstation in addition to the processor pool for general use. A n exam ple o f this type is the A m eoba O perating System [14].
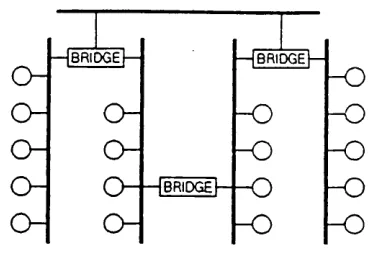
System s consisting o f w orkstations (called processing nodes throughout the disser tation) connected by fast local area netw orks are becom ing w idespread. These system s offer a general purpose distributed com puting environm ent for a large num ber o f applica tions. The possibility o f connecting a large num ber o f processing nodes m akes them suit able for replicating objects such as files, replication histories, etc. T he replication control protocol w hich the dissertation presents and analyzes is designed for an environm ent in w hich a large num ber o f processing nodes are spread across a series o f local area n et w orks connected by bridges. A n exam ple topology is illustrated in Figure 1.1.
1.4 Replicated File System
Replicated F ile System 21
o
H B R I D G E I— — (B RID G E 1—
-o
o-
o-
-o
—
o
o-
o-
^ 0-o
o-
O
H b r id g eI --o
-o
o
O
-o
Figure 1.1. A workstation environment (Topology-1)
The efficiency is m ainly determ ined by the environm ent and the features related to the environm ent such as the resources provided by the distributed system m odel, the underly ing com m unication m edium and the failure to repair ratio o f the individual com ponents o f the network. The second group determ ine the effectiveness o f the replication system. This is predom inantly a property o f the consistency control algorithm. Effectiveness m easures the accessibility o f a file (its availability and reliability) together w ith other abstract properties o f the algorithm , such as any assum ptions made for its operability and correctness. This includes the failure m odes o f the netw ork that can be tolerated and w hether individual com ponents share the sam e view o f the status o f the other co m ponents or not.
The effectiveness o f a replication system is determ ined by the control protocol used to manage the replication. Som etim es effectiveness m ay trade o ff efficiency and thereby the perform ance o f the w hole system . The reverse is also true to a lesser extent.
The aim o f this section is to create a general view about the distributed file system m odel in which the proposed design can perform efficiently.
been tried [13]. In the first approach file system s are not m erged. A ccess to a rem ote file can only be done by running special file transfer protocols that copy the rem ote files to the local machine. This approach has been used in early designs and cannot provide replication transparently.
The next step tow ards a DFS is to have adjoining file system s. In this approach, program s on one m achine can open files on another m achine by providing a path nam e w hich determ ines w here the file is located. This is either done by creating a virtual superdirectory above the root directories o f all the connected m achines (as in the N ew c a s tle Connection [15] and N etix [16]) or by providing a rem ote m ount operation (as in S u n ’s NFS [17]). R eplication can only be em ployed statically since the operating system cannot m ove files around am ong nodes by itself.
The third approach is the distributed operating system s approach: having a single global file system visible from all processing nodes. This approach allow s the operating system to move files around am ong nodes. T he system can m aintain replicated copies of files [1 8 ,1 9 ,2 0 ,2 1 ,2 2 ,2 3 ,2 4 ].
Sturgis has grouped the basic issues that DFS designers are faced into five categories [25]: com m unication prim itives required, nam ing and protection, resource m anagem ent, choosing the services to be provided and fault tolerance. It is the last p ro b lem for w hich replication is a solution.
R eplicated File System 23
Once the data in a file is no longer needed, the application can delete the file ID, so that the file system may reclaim the space occupied by the file.
In this light we m ay now define a replicated file as a set o f file copies, each one im plem ented on a different node in the distributed system.
A replicated file system presents applications w ith the abstraction of a logical file consisting o f a sequence o f bytes and identified by a unique identifier. In the thesis, data and file are used synonym ously w ith the term logical file. Logical files are im plem ented by a set o f physical files each holding a com plete copy o f the file and each residing at a single distinct processing node. B oth the terms copy and replica w ill stand for a full copy o f the file. The degree o f replication is defined as the num ber o f the file copies. The files are created, accessed for read or write and deleted by m eans o f logical opera tions defined on them. A replicated file can have different active versions at one time as a result o f failures and repairs o f the processing nodes holding them. A read on the file w ill return the current version and a w rite is assum ed to be an update on the current v er sion.
The m ultiple copies o f a replicated file are m anaged by a replication method. This is an algorithm for m anaging the distributed copies of the files so that its functional behavior is equivalent to that o f a file having only a single copy. This property is know n as o n e -c o p y serializability [26]. Consistency problem s can arise from two different sources in a distributed environm ent.
1) Consistency in the face o f failures: the data needs to be correct. Incorrect behavior should not occur as a result o f system failures such as node crashes, netw ork parti tions or tim ing anom alies.
A replication m ethod m ay address these problem s independently. Consistency con straints are defined to ensure that the data m eets the above conditions; at one level a stan dard concurrency-control protocol synchronizes access to the individual com ponents and at a higher level, a replica-m anagem ent protocol reconstructs the file’s consistent state from its distributed copies w ithout concern for concurrency. This distinction is m ade in order to discuss the problem s separately. These problem s have a lot in com m on and it may be difficult to distinguish them in practice. The definition o f consistency given in Section 1.4.2 will justify w hy the concurrency control protocol is considered to be the low er o f the two.
1.4.1 C o n c u r r e n c y C on trol P r o b lem
This section sum m arizes the protocol required in the low er layer if the updates may be concurrent. This problem has been actively investigated w ithin the environm ent o f centralized and distributed databases in recent years. Concurrency control algorithm s w ithin centralized and distributed environm ents are surveyed by Bernstein et a l [26] and K ohler [27].
In a concurrency control protocol, logical operations are com posed o f a series o f accesses, called transactions, that change the state o f the system from one consistent state to another. There are tw o possible anom alies that are to be considered w hen the transactions are running: updates m ight be lost or the retrieval m ight be inconsistent because o f interleaved access to the data. The correctness o f a concurrency control algo rithm is defined relative to u sers’ expectations. B ernstein defined tw o correctness criteria regarding the above anom alies [26]:
a) Users expect that each transaction subm itted to the system will eventually be ex e cuted.
Replicated File System 25
In order to satisfy these requirem ents all concurrent operations are required to be atom ic w hich means a ll- o r - n o th in g [28]. A n atom ic operation w ould only m odify the file if it is com pleted successfully, otherw ise has no effect on the file. A tom ic com m it m ent protocols are discussed by G ray et al [29] and H am m er et al [30].
A concurrency control protocol m ust ensure that concurrent execution o f a set of transactions, where requests belonging to different transactions are interleaved, produces the same result as if those transactions w ere executed serially. These transactions are said to be serializable. The sem inal paper on serializability theory w as w ritten by Papa- dim itriou [31].
There are two synchronization problem s that the protocol should consider separately: read-read and read-w rite synchronization. M any different m echanism s have been proposed. The three prim ary m echanism s are tw o-phase locking [3 2,2], tim estam p ordering[33] and so called optim istic m ethods [34],
The two-phase locking m ethod synchronizes reads and writes by explicitly detect ing and preventing conflicts betw een concurrent operations. Before reading a file a tran saction m ust own a read-lock on it, likew ise a w rite-lock must be obtained before w rit ing. The ow nership of locks is governed by tw o rules:
1) D ifferent transactions cannot sim ultaneously ow n conflicting locks.
2) A dditional locks may never be obtained once a transaction surrenders ow nership of a lock.
The definition of a conflicting lock depends on the type o f synchronization being perform ed. For read-write synchronization tw o locks conflict if both are on the sam e data and one is a read-lock while the other is a w rite-lock. For w rite-w rite synchronization, two locks conflict if they lock on the same data and both are w rite-locks.
unique tim estam p and conflicting operations must be processed in this tim estam p order. The definition of conflicting operations is the same as for tw o-phase locking.
The concurrency control protocols based on com m it protocols are intended for applications where reads predom inate. T hey are poorly suited for applications such as ticket reservation systems w here w rite operations occur frequently. Herlihy proposed optim istic concurrency protocols [35] for the applications w here write operations predom inate. A concurrency protocol is optim istic if it allows transactions to execute w ithout synchronization, relying on com m it-tim e validation to ensure serializability.
Since this dissertation investigates a consistency control schem e w ithout being con cerned with the details o f concurrency control protocols, the synchronization techniques will not be discussed further. B esides the above references, interested parties can refer to Bennett [36] and G elenbe [37].
1.4.2 C o n sisten cy C o n tr o l P r o b le m
The work presented in this dissertation relies on the follow ing definition:
D efinition 1.1. Let a , b be tw o distinct consecutive operations on a replicated file, / , satisfying a —>b where »” is the happened before relation w hich defines an arbitrary total ordering of the events in a distributed m ultiprocess system as an extension to their partial ordering [38]. Let f/, = Rj u C, is the set o f up-to-date copies o f f after the operation / is com pleted, w here /?, is the set o f up-to-date copies w hich has directly accepted the operation / and C, is the set o f up-to-date copies w hich has becom e up-to- date by copying from C onsistency is preserved if and only if p = p! =s> p i is true where p i and p2 are the follow ing propositions.
p 1: a has succeeded on a set o f physical copies, Ua , and b is applied to Rf,
p
2:Rb
QUa
R eplicated File System 27
be concurrent if a—»b and b —>a.
It is the responsibility o f a consistency control protocol to satisfy the integrity con straints explained as the first form o f consistency in Section 1.4. These constraints assure the correctness o f the consistency protocol w hich guarantees that incorrect behavior should not occur as a result o f netw ork failures such as node crashes, netw ork partitions or tim ing anom alies. It is the jo b o f the consistency schem e to coordinate the accesses and updates to the file copies so that clients o f the replicated file system see a consistent view o f the file. That is, any client that reads a file after a w rite operation has succeeded will see the data as it was left by the w rite operation.
1.4.3 C o m m u n ic a tio n S y ste m
This section describes the assum ptions on w hich the underlying com m unication sys tem is based. There is server softw are in each node w hich im plem ents a set o f operations that can be invoked over the netw ork. Individual processing nodes in the system are assum ed to provide this abstraction o f a file through locally connected hardw are. The local connection is im portant since it allow s to assume that the success or failure o f a file operation can be determ ined by the local file system. In contrast, it is assum ed that nodes connected by the data netw ork can only determ ine the outcom e o f an operation p er formed rem otely by another node by the arrival o f a m essage from the remote node. M essages m ay be lost in transit but we assume that corrupted m essages are detected and removed by the com m unications softw are. In particular, we assum e that the netw ork may becom e partitioned. Failed com ponents such as nodes, bridges, etc. can recover spontaneously or because o f system m aintenance.
m echanism that offers at-m ost-once sem antics [3 9 ,4 0 ,4 1 ,4 2 ] is likely to be the best com m unication protocol for the system.
The characteristics o f the com m unication m edium have a m ajor effect on the perfor m ance. M any o f the lo w -lev e l operations required to support replication w ould benefit from a m ulticast request-response m echanism . [43] If the underlying com m unication sys tem uses a broadcast link level protocol, the cost o f such a m echanism is a function o f the num ber o f replies required from a request, not the num ber o f servers to w hich the request was sent, nor the size o f the request param eters.
1.4.4 File vs B lock L evel R eplication
Some system designers choose to introduce the replication at block level while oth ers prefer to do so at file level [44]. M any studies [4 5 ,4 6 ,4 7 ] o f distributed file systems (including my own results o f the actual perform ance o f N FS — Sun M icrosystem ’s N et w ork File System ) have show n that m ost file accesses are w hole-file transfers. An
analysis o f file access patterns in the UNIX 1 O perating System has been done by O usterhout [45]. This reveals that more than 90% percent o f all files processed sequen tially and more than two thirds o f all file accesses are w hole-file transfers. These figures also show that w hile operations on small files predom inate, large files account for almost 20% o f all file accesses. Table 1.1 presents the results from this study together with the results o f m y ow n study o f netw ork file accesses in the last column. The values presented show percentage o f the accesses. For exam ple, first row is the percentage o f w hole file read transfers o f all read-only accesses etc.
This suggests that in some application environm ents, w hole-file replication m ight be m ore advantageous and m ore practical than block-level replication. Therefore the thesis is based on the replication o f whole files.
File vs B lock Replication 29
System-1 System -2 System -3 System -4
A ll read accesses 69% 63% 70% 75%
A ll w rite accesses 82% 81% 85% 90%
Sequential read-only accesses 92% 91% 93% 90%
Sequential write-only accesses 97% 96% 98% 98%
Sequential read-write accesses 19% 21% 35%
Table 1.1 — Percentage o f accesses that represent whole-file transfers.
1.4.5 B u ild in g R eplication into the File S y stem
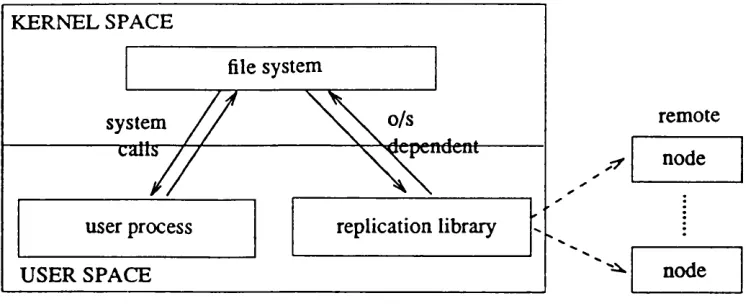
Even if it is conceptually sim ple, building replication into the file system while try ing to preserve file system sem antics is very com plicated. In m ost cases the file system is part o f the operating system kernel. In these system s replication can be im plem ented on top o f the operating system as a set o f library procedures as in Figure 1.2(a) or can be m oved into the operating system kernel. In the first case the im plem entor m ust provide an interface that preserves the sem antics o f the original file system using only available system services. An entire replicated file system m ust be built on top o f the original file system. The second case is m ore com plicated because it requires the m odification o f the operating system kernel.
In order that replicated file system s can becom e com m onplace in general purpose com puting environm ents, they should provide fault tolerance efficiently as an extension to sim ple file systems.
KERNEL SPACE
file system
system
calls tependent
replication library user process
USER SPACE
remote
node
node
One suggestion for im plem enting replication at the block level is a reliable device [44] w hich appears to the file system as an ordinary block-structured device but im plem ented as a set o f server processes on several nodes. Because it presents the same sim ple inter face as an ordinary device, it provides replication while leaving the operating system ker nel and the file system unchanged. T his approach has the advantage that existing pro grams can operate on replicated files w ithout m odification.
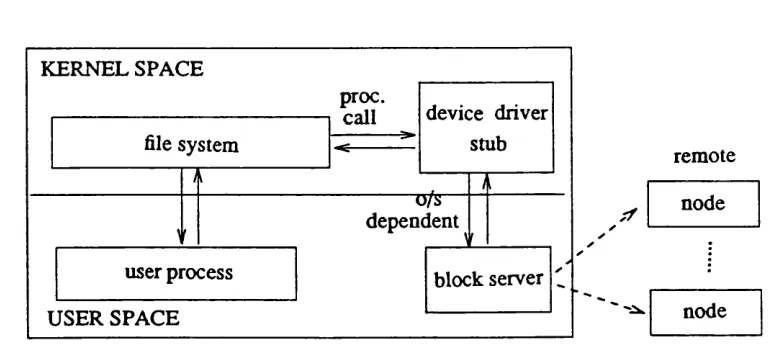
In the case o f a conventional operating system w here the file system is part o f the operating system kernel, it has been suggested by Carroll [44] that a device driver stub could receive requests for access from the file system and forw ard those requests to a server w hich w ould perform the d ata access and consistency control algorithm s. Such a scheme is illustrated in Figure 1.2(b).
In this system , a user-state process m akes a file system request to the operating sys tem kernel. The file system consults internal data structures to ascertain if it has the requested file in the buffer cache. If the block is not present then the file system requests the device driver to fetch the file. The device driver stub then com m unicates this request to the user-state server w hich executes the consistency control and data access algo rithms.
remote node
node block server
device driver stub
user process file system KERNEL SPACE
USER SPACE
proc. call
dependent
Building Replication 31
1.5 Types of Failure and Recovery
In this section a discussion on typical failures that can occur in a general distributed environm ent is follow ed by the failure specifications and the assumptions on w hich our failure m odel is based. The section concludes w ith a discussion o f some m ethods used for recovering data after the failures.
A failure in the system can be defined as an event at w hich the system does not p er form according to its specifications. W e divide distributed system failures into four categories:
1) Node Crashes
2) Bridge Failures
3) Com m unication Link Failures
4) Byzantine Failures
The first three o f these can be thought o f as failures causing the network to becom e partitioned. W hen the netw ork is partitioned the system is divided into two or m ore dis joint sets w ithin w hich com m unication is possible. There is no com m unication between any two o f these sets in the sense that all m essages betw een them will be lost. A failure is detected when a node fails to receive a response to its m essage after a certain duration o f time. A fault can only be suspected; the absence o f a reply m ight be merely an indica tion that the recipient is slow to respond but we do not consider tim ing anom alies. Since com m unication link failures occur very rarely in to d ay ’s netw ork technology, they are not discussed further, although their properties could be sim ulated by a highly intercon nected netw ork o f unreliable bridges. A rbitrary partitioning o f the system caused by bridge failures is im portant for replication and is studied at length in Chapter Four and Chapter Five.
[48]. W e assum e that the software is correct so we need not consider this sort o f failure further.
As far as com m unication is concerned node crashes can be view ed as a special case o f partitioning: all incom ing and outgoing m essages are lost. From the point o f view of the integrity o f the files we must m ake the follow ing assum ptions:
1) M achines are fail-stop. That is, at any m om ent, each m achine is either up or down.
2) Local hardw are failures are detectable. It is assum ed that a device controller satisfies this assum ption.
3) A bsence o f storage m edia failures, faults that cause crashes o f a file server are classified into tw o groups: server failures and disk controller failures. Since the replicated file system creates copies o f the file on distinct processing nodes rather than by local disk replication, this requirem ent is satisfied.
A lthough the effects of a crash cannot be com pletely hidden, they can be limited to a single w ell-defined event. The details and requirem ents o f low -level protocols to achieve this aim is described by Schlichting [49] and by Bernstein et a I [50].
Types o f Failure and Recovery 33
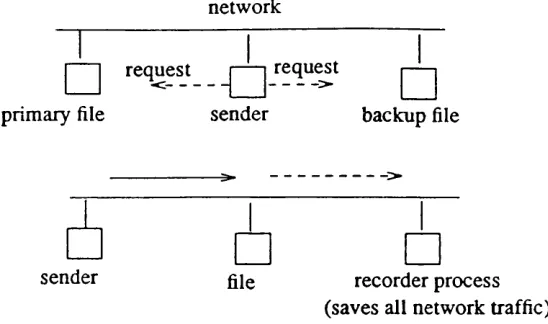
Increm ental D um ping: C opying o f updated files onto archival storage after a jo b has finished or at regular intervals. This creates checkpoints to updated files. B ackup files can be restored after a crash. Pow ell et a l [54] have described a redundant system that puts very little additional load on the process being backed up. In their system all m essages sent on the netw ork are recorded by a special "recorder" process. From tim e to tim e each process checkpoints itself onto a rem ote disk (Figure 1.3).
netw ork
| | request request |——j prim ary file sender backup file
sender file
□
recorder process□
(saves all network traffic)
Figure 1.3. Backup!recorder process during incremental dumping
D ifferential Files: A file can consist o f two parts; the m ain file w hich is unchanged, and the differential file w hich records all the alterations requested for the m ain file. The m ain files are regularly m erged w ith the differential files. Records in the differential files can be stored w ith the process identifier, a tim e stam p and other identification inform a tion to aid recovery.
Backup!C urrent Version: The files containing the present values o f existing files are the current versions. Files containing previous values are backups. Backups can be used to restore files to previous values.
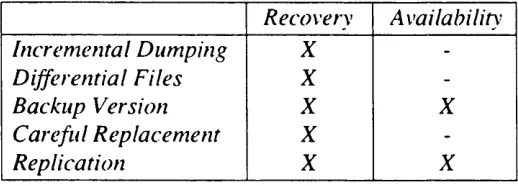
Table 1.2 lists the m ethods dealing w ith recovery and availability.
Recovery Availability
Increm ental D um ping X
-D ifferential Files X
-B ackup Version X X
C areful R eplacem ent X
-R eplication X X
Table 1.2 — Techniques used fo r recovery and/or availability
1.6 Measures of File Accessibility
W hen files are not replicated, they obviously becom e unavailable during the crash and recovery o f the node holding the file. No updates m ay be m ade and the data is sim ply not available for either read or write until the node recovers. No special operations are required upon recovery to be sure o f consistency of the copy as there is only one copy. If the file is required w hile the node is dow n, it can m anually be reloaded into another operating node from a back-up resource. T hen, one m ust make sure that no inconsistencies exist after the crashed node is returned to service. M anual loading som e times may be useful but it is not transparent.
M easures o f File Accessibility 35
cost and com plexity the reliability offered by replication is only used in certain applica tions where the cost is justifiable. The rest o f this section concerns the measures o f file accessibility and m ethods to compare them.
In a replicated file system design it is essential to know the effectiveness and trade offs of different options in improving perform ance and dependability. Since the main goal of replication is to increase the accessibility o f data by tolerating system failures and making the file m ore available than a single copy, the sim plest m easure o f accessibility is availability. In fact, it is possible to distinguish the factors effecting availability into two: environm ental effects such as failure frequency, netw ork topology etc. and the lim i tations o f the replication m ethod used to manage the file copies. In order to simplify the availability analysis and ease the com parison betw een m ethods, topological factors have usually been disregarded and partitioning has been ignored, although it is a com m on problem . The following sub-sections explain different form s o f availability; steady-state and continuous availability. Continuous availability w ill be referred as reliability throughout.
1.6.1 Availability
The success o f a file operation on a replicated file depends on a num ber o f indivi dual nodes being operational at the time of the request. If a sufficient num ber o f nodes is not available w hich is required for a consistent read or w rite then the data is not avail able. Availability is a probabilistic measure calculated in term s o f the probability o f required num ber o f independent com ponents being up at the time o f the request. There are two possible availability measures in general:
2) Steady -s ta te availability is the availability w hen the system is in steady state. This is the equilibrium state w hen tim e goes to infinity. Steady-state availability can be defined as the probability that the file w ill be accessible at any random point of tim e. Since it is assum ed that the replication system is repairable i.e. failed nodes are always recovered after a certain period o f tim e, only the steady-state availability o f files is considered in the thesis. The follow ing is the definition o f the steady-state availability o f a replicated file.
D efinition 1.2. The availability P(A {n ,m )) o f a replicated file with n replicas in a system o f m processing nodes where (m - n) nodes do not contain a replica o f the file is defined as the probability that the system will operate correctly at any given point o f time as time goes to infinity given that initially m nodes w ere operating correctly.
A vailability has two facets according to the type o f the access: availability for a read access (read-availability) and availability for an update (w rite-availability). It is a feature o f the consistency schem e to determ ine w hether these availabilities are equal or one trades-off the other.
A vailability behavior o f a consistency schem e can be m odeled analytically. This analytical model is an abstraction o f the various assum ptions about the sy stem s’ behavior as a function o f the failure/repair probabilities o f individual nodes. Under the assum ption o f exponential failure/repair rates, it is possible to derive a M arkov model for the cases w here the num ber o f possible states that the system can be in is within reason. U nfor tunately, reality tends to deviate from exponential m odels because exponential repair rate is not realistic for com puter system s [56].
M easures o f File Accessibility 37
1.6.2 Reliability
Reliability can form ally be defined as the conditional probability at a given confidence level that the file system will perform its intended function (read/w rite access) properly w ithout failure and satisfy the specified requirem ents o f continuous availability during a given time interval {0, t}. In other w ords, reliability is the continuous availabil ity o f a file over a given period o f time.
D efinition 1.3. The reliability R(n ,m ,t) o f a file w ith n copies in a system o f m process ing nodes — including the nodes holding a copy, is defined as the probability that the system will operate correctly over a time interval o f duration t given that initially m nodes w ere operating correctly at tim e t -0.
A vailability has received m uch m ore attention, because its analysis is m ore tractable than that o f the reliability [58]. In fact, there are some applications in w hich the reliabil ity o f a system is a m ore im portant m easure o f its perform ance than its availability. These applications include process control, d ata gathering, and tasks requiring interaction w ith real-tim e processes, w here the data w ill be lost w hen it is not available. The com puter systems used for stock trading are an exam ple o f this situation. If these m achines were to fail, the resulting chaos w ould halt trading.
Reliability analysis through analytic m odels is too com plicated. It is possible to derive closed-form solutions for differential-difference equations if the num ber o f possi ble states is small and the system does not partition. A nalytic m odels becom e too com plicated to solve in the analysis o f netw ork partitions. In the reliability analysis a M onte-Carlo sim ulation is done and the results are validated by an analytic m odel for a sim ple partitioning case.
1.7 Summary
out-lines the replicated file system model on top o f which the consistency control schemes
are going to be built in the follow ing chapters.
T he m ost im portant points made in this chapter are as follows:
i. Storage cost is a very im portant issue to be considered in order that replication can becom e com m on place in general purpose com puting environm ents.
ii. G oing from single to tw o copies has m uch higher advantages than going from two to three, four copies.
iii. C oncurrency and consistency are tw o separate concerns; the consistency problem is an inevitable consequence o f replication w hereas concurrency problem can occur in any concurrent or pseudo-concurrent environm ent.
iv. Tw o com m on principles are used in various algorithm s for m anaging the consistent view o f replicated files: read any/w rite a ll and read som e /w rite some. A m ong the algorithm s, correctness trades o ff perform ance.
v. A ll consistency schem es in the literature up to June 1989, becom e inefficient when the num ber o f copies is small (especially tw o) either because o f adm inistrative com plexity and requirem ents from the hardw are or providing a desired level of availa bility especially w ith sm all num ber o f copies.
Chapter Two
Consistency Control Schemes
This chapter exam ines the requirements (assum ptions m ade for its operability and correctness) and the behavior o f consistency control schem es.
The algorithm s are studied in two groups: V oting algorithm s [5 ,6 ,5 9 ,6 0 ] and A vailable Copies algorithm s [4,9]. Voting algorithm s use a quorum -consensus approach whereas the A vailable Copies algorithm s provide high availability as a m odification o f two older methods: U nanim ous A greem ent [61] and Single-Prim ary U pdate strategy [62,61].
2.1 Unanimous Agreement Update
This approach requires that all copies should be identical before and after each operation. In o ther w ords, it uses read any /w rite all principle. Updates are propagated to all replicas im m ediately. Since all physical copies o f a logical file are kept in the sam e state, a single copy im age o f the data is achieved. As the algorithm assumes that every node in the system has a replica o f the data, all read requests can be perform ed locally. This assum ption reduces the traffic on the com m unication netw ork for read requests.
U nanim ous agreem ent enhances read availability, but as the num ber o f replicas are increased, the file will be less available for updates. A replicated file with any num ber of copies w ill provide lesser availability for update than a single copy file. A dditionally, the system is required to support control m essage traffic in order to send the update to all replicas and confirm or cancel it, based on w hether or not unanim ous agreement was obtained. A lthough the idea is sim ple, its im plem entation requires a tw o-phase com m it protocol for confirm ation as it cannot afford an inconsistency am ong the copies.
This approach does not tolerate node crashes for updates. As it is not realistic to consider a failure-free distributed system , it offers very low reliability com pared to all the other approaches. Its advantages are high read availability and consistency even if the netw ork is partitioned by preventing updates in any partition that does not have access to all replicas. I f a replicated file has a very high ratio o f read requests to update requests, unanim ous agreem ent (Figure 2.1) m ight be cost-effective for small degree file replication.
update
copy-3 copy-2
copy-1
U nanimous A greem ent 41
2.2 Single-Primary Update
This algorithm designates one replica as prim ary and all the others as secondaries. U pdate requests are sent to the prim ary replica w hich serves to serialize updates and thereby preserve data consistency. The prim ary acquires a lock, perform s the update, broadcasts the change to all the secondaries and releases the lock. There are three dif ferent schemes for this broadcast:
1. Update request is sent to the secondaries im mediately,
2. U pdates are packaged and sent at the end o f the transaction,
3. U pdates are broadcast only at specific intervals — once an hour, overnight, etc.
In all the prim ary-secondary schem es, the delay caused by update propagation from prim ary to secondary can increase the response tim e to a local read issued after an update to the data, if the update is at a rem ote prim ary, and the read is at the local replica.
This scheme does not tolerate the failure o f the prim ary copy but it m aintains con sistency in the face o f netw ork partitions. In the case o f a partition failure, only the p arti tion containing the prim ary copy can access the data. Updates are forw arded to secon daries at recovery to regain consistency. The availability o f the data is sim ply the p roba bility that the prim ary is up and com m unicating. Therefore it provides the sam e write availability as single copy. R eplication enchances only read availability. As it is sim ple and practicable, it has been used in m any designs [68,69].
2.3 Moving-Primary Update
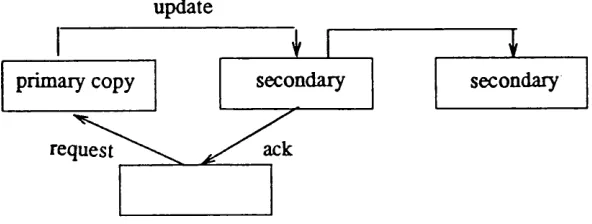
This algorithm is proposed by A lsberg [62] and it is an extension to the single prim ary strategy. The principle is that an update can be made to the prim ary copy or any secondary copy. The initiator is not aware o f w hich node is functioning as the prim ary for any particular update.
perform s the update, acknow ledges to the prim ary and also the local node before passing the request on to the next secondary (Figure 2.2). Once the prim ary has received the ack now ledgem ent from the secondary, it is certain that tw o-host resiliency has been achieved. The update is lost only if both prim ary and the cooperating secondary fail.
If the node receiving the request is a secondary, it forw ards the request to the p ri m ary and algorithm proceeds as above.
If the prim ary fails, the secondaries w ill discover it w hen they forw ard their next request. Then, they elect a new prim ary am ong them selves. In a tw o-host resilient schem e, all n—1 secondaries, w here n is the num ber o f copies, must participate in this election. One way o f electing a new prim ary is to assign num bers to nodes and to choose the secondary with the highest num ber in the participating set as the next prim ary. In the second step, all other secondaries are inform ed o f the prim ary change. W hen the old p ri m ary recovers and attempts to ask cooperation for an update, it is inform ed by the secon dary of the change and the request is forw arded to the new prim ary. The old prim ary then becom es a secondary.
In general, in an m -host resilient schem e at least /i- m + 1 secondaries m ust partici pate in the election o f the prim ary. T he rest o f the algorithm is the sam e as the tw o-host resilient scheme.
M oving-Prim ary Update 43
update
ack
request
secondary secondary
primary copy
Figure 2.2 An update operation maintained by Moving-Primary approach
2.4 Voting Algorithms
Voting algorithm s use a quorum -consensus approach. Every node m aintains a num ber o f votes for read and writes. Each request m ust gather a quorum o f votes before being accepted. All voting algorithm s are robust as a side affect o f norm al operation. They rem ain consistent in the case o f com m unication failures w hich can cause partition ing in the system as well as in the face o f individual node crashes.
In m ajority voting, w hich is the earliest and sim plest form o f voting algorithm s, every copy has one read and one write vote. For a request to be accepted a m ajority o f the copies need to approve it. The algorithm in its original form em ploys tim estam ps both in the voting procedure and in the application o f updates. The file is available to update requests so long as there is a m ajority o f nodes in com m unication. Since only one m ajority can be form ed at a tim e, the file rem ains consistent even if the netw ork is parti tioned.
In all previous algorithm s, read requests w ere alw ays local. In voting algorithm s, if w is less than the num ber o f copies then a read quorum is required to obtain the current version number. If m ajority voting is applied, then all w rite quorum s are preceded by a read quorum w hich is the m ajority in either case. If w is equal to the num ber o f copies then voting degenerates into unanim ous agreem ent allow ing any one copy to be read.
V oting algorithm s provide serial consistency w hich m eans that it appears as if each transaction is running alone. H owever, they require a m inim um o f three copies to be of any practical u se.- H aving three copies o f the file, in order to increase the availability and the reliability, the best solution is to assign equal votes to all copies. The file w ill then be accessible as long as two out o f three copies are available. The increased level o f availa bility and reliability incurs a storage cost. If the size o f the file is very large, then the storage cost o f an extra copy m ay not justify the increase in availability.
2.5 Efficient Variations of Voting
In their original forms, consistency schem es relying on voting becom e m ore effec tive in providing availability as the num ber o f copies are increased (five or more). In these algorithm s read availability trades o ff w rite availability. In the follow ing sections
Voting Algorithm s 45
two recent extensions to w eighted voting are discussed. The first tends to reduce the storage cost and the second increases write availability.
2.5.1 Red uci ng Storage Cost with W it n es s es
Paris proposed to replace some o f the copies with sm all records that keep only the status o f the file but not the data. These records are called w itnesses [63]. The w itnesses have weights just like the norm al copies and can participate in a quorum . R ead and write quorum s are collected as if the w itnesses w ere conventional copies. The only restriction is that every quorum must include at least one current copy. Tw o copies and one witness provide sim ilar availability to that o f a file having three full copies. But still, voting algorithms with three copies provide lesser availability than that o f A vailable Copies method with only two copies. The A vailable C opies m ethod is discussed in Section 2.6. The availability analysis done with k-out-of-/2 reliability theory (Section 4.1) has shown that availability with voting becom es reasonably com parable w ith available copies algo rithms when five or more copies are used. For sm aller num ber o f copies, available copies algorithms provide higher availability than any variations o f voting. The result o f the analysis is discussed in C hapter Four.
2.5.2 E n ha nc in g Availability with G h o s t s
are detected on each segm ent w ith a boot service which keeps the status o f each node by polling them in regular intervals. This service is replicated as well. V an Renesse argues that, since the segments cannot be partitioned, the boot service can be controlled by either W eighted Voting or A vailable Copies algorithm .
V oting W ith G hosts enhances write availability com pared to V oting W ith W itnesses, but it has strong adm inistrative requirem ents such as; a separate replicated boot service for every segm ent and a recovery process to restore the recovered nodes. If the boot service becom es unavailable the algorithm degrades to W eighted Voting. Besides, since ghosts do not have storage, they cannot participate in a read quorum , so read availability rem ains the same. If the file has only tw o copies, ghosts have no use in the case o f partitioning. T herefore, it has restrictions w hich m akes it unsuitable for small degree replication.-* A dditionally, although it m ay be a m inor overhead, having replicated boot services on every segm ent generates extra netw ork traffic continually during p ol ling, and updating the service w hen a node is repaired.
2.6 Optimum Vote Assignment or Coteries
One difficulty w ith voting algorithm s is how to assign the votes optim ally. If the failure characteristics o f the nodes and the netw ork system is varying, then the optim um vote assignm ents vary also. It has been proved by G arcia-M olina et a l [71] that there are
2
up to 2"~ different vote assignm ents, where n is the num ber o f copies. This shows that the choice o f assignm ents are increased rapidly.
There is an alternative to vote assignm ent. The above m entioned authors introduced the term coteries to define the sets that can perform the read/w rite operations on the file. Coteries are the sets o f set o f nodes. Empty set is not a m em ber o f a coterie and each
C oteries 47
pair o f m em bers o f a coterie have at least one node in com m on, but none o f them is a subset o f another. Coteries can form ally be defined as follows:
D efinition 2.1. Let U be the set o f nodes that com pose the system . A set o f sets o f nodes 5 is a coterie under U iff each m em ber o f S obey the follow ing three conditions:
Say G, H are subsets o f U
i) G € S implies that G 0 and G <zU.
ii) If G, H e S, then G and H m ust have at least one com m on node. iii) There are no G, H e S such that G c H.
Each pair o f coteries should have a node in com m on to guarantee serializability. Up to five nodes, coteries and vote assignm ents are equivalent. It is easier to think o f in terms o f coteries but, votes are m ore efficient in im plem entation. G arcia-M olina argue that votes take less space to represent and are easier to im plem ent. Adding votes and checking for a m ajority is also faster than checking if a group o f nodes is in a coterie.
A lso, w ith five or few er nodes, the num ber o f choices for vote assignm ent or coteries are small enough for designers to inspect all choices and select the one that yields the best reliability for the given hardw are.
They prove that for systems w ith m ore than five nodes, coteries are m ore pow erful. There are coteries that cannot be represented by votes, not vice versa. H owever, in this case the num ber o f coteries is huge. Therefore, some heuristics are needed to trim dow n the num ber o f choices.
As stated above, for the system s w ith m ore than five copies, either assigning optim um votes or choosing optim um coterie is a tautology and difficult task for system designers.