CLOS, J. 2019. Representation and learning schemes for argument stance mining. Robert Gordon University [online], PhD thesis. Available from: https://openair.rgu.ac.uk
Representation and learning schemes for
argument stance mining.
CLOS, J.
2019
This document was downloaded from
https://openair.rgu.ac.uk
The author of this thesis retains the right to be identified as such on any occasion in which content from this thesis is referenced or re-used. The licence under which this thesis is distributed applies to the text and any original images only – re-use of any third-party content must still be cleared with the original copyright holder.
Representation and Learning Schemes for
Argument Stance Mining
C
LOS, J
ÉRÉMIEA thesis submitted in partial fulfilment of the requirements of Robert Gordon University
for the degree of Doctor of Philosophy
This research programme was carried out
in collaboration with the Department of Computer Science, University of Glasgow
Abstract
Argumentation is a key part of human interaction. Used introspectively, it searches for the truth by laying down argument for and against positions. As a mediation tool, it can be used to search for compromise between multiple human agents. For this purpose, theories of argumentation have been in development since the Ancient Greeks in order to formalise the process and therefore remove the human imprecision from it. From this practice the process of argument mining has emerged. As human interaction has moved from the small scale of one-to-one (or few-to-few) debates to large scale discussions where tens of thousands of participants can express their opinion in real time, the importance of argument mining has grown while its feasibility in a manual annotation setting has diminished and relied mainly on a human-defined heuristics to process the data. This underlines the importance of a new generation of computational tools that can automate this process on a larger scale.
In this thesis we study argument stance detection, one of the steps involved in the argument mining workflow. We demonstrate how we can use data of varying reliability in order to mine argument stance in social media data. We investigate a spectrum of techniques, from completely unsupervised classification of stance using a sentiment lexicon, automated computation of a regularised stance lexicon, automated computation of a lexicon with modifiers, and the use of a lexicon with modifiers as a temporal feature model for more complex classification algorithms. We find that the addition of contextual information enhances unsupervised stance classification, within reason, and that multi-strategy algorithms that combine multiple heuristics by ordering them from the precise to the general tend to outperform other approaches by a large margin. Focusing then on building a stance lexicon, we find that optimising such lexicons using a empirical risk minimisation framework allows us to regularise them to a higher degree than competing probabilistic techniques, which helps us learn better lexicons from noisy data. We also conclude that adding local context (neighbouring words) information during the learning phase of the lexicons tends to produce more accurate results at the cost of robustness, since part of the weights is distributed from the words with a class valence to the contextual words. Finally, when investigating the use of lexicons to build feature models for traditional machine learning techniques, simple lexicons (without context) seem to perform overall as well as more complex ones, and better than purely semantic representations. We also find that word-level feature models tend to outperform sentence and instance-level representations, but that they do not benefit as much from being augmented by lexicon knowledge.
Keywords:Argument Stance Mining ; Natural Language Processing ; Social Media Mining ;
Declaration of Authorship
I declare that I am the sole author of this thesis and that all verbatim extracts contained in the thesis have been identified as such and all sources of information have been specifically acknowledged in the bibliography. Parts of the work presented in this thesis have appeared in the following publications:
J. Clos, N. Wiratunga, J. Jose, S. Massie, and G. Cabanac: Towards Argumentative Opinion
Mining in Online Discussions. In: Proceedings of the SICSA Workshop on Argument Mining (2014)
(Chapter 5)
J. Clos, N. Wiratunga, S. Massie, and G. Cabanac: Shallow techniques for argument
mining. In: ECA’15: Proceedings of the European Conference on Argumentation (2016)
(Chapter 6)
J. Clos and N. Wiratunga: Neural Induction of a Lexicon for Fast and Interpretable Stance
Classification. In: International Conference on Language, Data and Knowledge (2017)
(Chapter 6)
J. Clos and N. Wiratunga: Lexicon Induction from Text for Interpretable Classification. In:
21 International Conference on Theory and Practice of Digital Libraries (2017)
(Chapter 6)
J. Clos, N. Wiratunga, and S. Massie: Towards Explainable Text Classification by Jointly
Learning Lexicon and Modifier Terms. In: IJCAI Workshop on Explainable Artificial Intelligence (2017)
(Chapter 6)
Acknowledgements
Due to the long overdue nature of this thesis, the list of people that I want to thank and acknowl-edge has grown beyond reason.
The Scottish Informatics and Computer Science Alliance (SICSA) for providing the initial funding for this research, and Prof. Susan Craw for helping me secure it ;
My very patient supervisory team, Prof. Nirmalie Wiratunga, Dr. Stewart Massie and Prof. Joemon Jose for their wisdom and advice, with specific mention to my long-lasting external advisor and friend Dr. Guillaume Cabanac for his mentoring and support ; My wonderful partner Yoke Yie Chen ;
My extremely supportive family, including my parents Marie-Pascale and Jean-Pierre, my brother Dimitri, as well as the only one of my cats who lived long enough to see me finish this thesis ;
The very helpful people I have met along the way, including those who employed me and helped me support myself. While this research was firstly funded by a SICSA scholarship, it was allowed to continue thanks to the generosity of the people who trusted me and allowed me to mature as a professional and an academic:
– from the Robert Gordon University, Prof. John McCall ;
– from Cognitive Geology, Luke and Fiona Johnson and Alex Shiell ;
– from the University of Nottingham, Dr. Steven Bagley, Dr. Rong Qu, Dr. Jason Atkin and Prof. Robert John.
And finally, last but not least, the very helpful people from the Robert Gordon University who allowed me to push the boundaries of how many times one can ask for an extension (Dr. Eyad Elyan) as well as the colleagues without whom I would be writing this from the cold padded cell of an asylum: Anil, Ahmed, Sadiq, Kyle, Pam, Anjana, Reginald, Ike, Adamu, Pat, Rustam, and many others.
Contents
Abstract i
Declaration of Authorship ii
Acknowledgements iii
Contents iv
List of Figures viii
List of Tables xi
1 Introduction 1
1.1 Applications of argumentative stance mining. . . 3
1.2 Related research fields . . . 4
1.3 Scope of the research . . . 6
1.3.1 Research motivation . . . 6
1.3.2 Research questions . . . 7
1.3.3 Research objectives. . . 9
1.4 Contributions . . . 9
1.5 Overview of the thesis . . . 10
2 Literature Review 12 2.1 Methods for Argument stance detection . . . 13
2.1.1 Unsupervised approaches to stance classification . . . 14
2.1.1.1 Conclusions from the unsupervised stance classification literature 16 2.1.2 Supervised approaches to stance classification. . . 16
2.1.2.1 Feature engineering and shallow stance classifiers . . . 17
2.1.2.2 Deep learning methods for stance classification . . . 26
2.1.2.3 Conclusions from the stance classification literature . . . 29
2.2 Corpora for stance classification . . . 30
2.2.1 Transcribed media corpora . . . 30
2.2.2 Free-form social media corpora . . . 32
2.2.3 Short text social media corpora. . . 33
2.2.4 Non-standard argumentation corpora . . . 34
Contents v
2.3 Chapter summary . . . 34
3 Background 35 3.1 The supervised learning process . . . 36
3.2 Text preprocessing . . . 37
3.2.1 Tokenisation . . . 38
3.2.2 Annotation . . . 39
3.2.3 Standardisation of the vocabulary . . . 40
3.2.4 Filtering. . . 41 3.3 Text representation . . . 41 3.3.1 Sequential representations . . . 41 3.3.1.1 One-hot encoding . . . 42 3.3.1.2 Word embeddings . . . 44 3.3.2 Non-sequential representations. . . 46 3.3.2.1 Bag-of-words . . . 46 3.3.2.2 Mean embeddings . . . 49 3.4 Model building . . . 50
3.4.1 Taxonomy of machine learning algorithms . . . 51
3.4.2 Lexicon methods . . . 52
3.4.3 Support vector machines . . . 55
3.4.4 Neural networks . . . 60
3.4.4.1 Recurrent neural networks. . . 61
3.5 Model evaluation . . . 64
3.6 Chapter Summary . . . 64
4 Evaluation methodology 65 4.1 Evaluating classifiers . . . 65
4.1.1 Machine learning evaluation methodology. . . 65
4.1.2 Evaluating classification algorithms . . . 67
4.2 Datasets . . . 69
4.2.1 Internet Argument Corpus (IAC) . . . 69
4.2.2 Agreement By Create-Debaters (ABCD) . . . 69
4.2.3 SemEval Twitter Dataset (SETC) . . . 70
4.2.4 Reddit Noisy-Labelled Corpus (RNLC) . . . 70
4.3 Statistical testing for classification . . . 75
4.4 Chapter Summary . . . 75
5 Unsupervised Argument Mining 76 5.1 Sentiment as proxy approaches . . . 77
5.1.1 Sentiment as proxy with adaptive threshold (SP-ADAPT). . . 77
5.1.2 Sentiment as proxy with context-sensitive term selection (SP-CoSTS) . 80 5.2 Shallow linguistic approximations . . . 81
5.2.1 Unsupervised sentiment surface (USS) . . . 82
5.2.2 Augmented unsupervised sentiment surface (USS+) . . . 84
5.2.3 Multi-strategy Unsupervised Stance Classifier (MUSC) . . . 86
5.3 Evaluation . . . 91
Contents vi
5.3.2 Baselines . . . 92
5.3.3 Results . . . 93
5.3.3.1 Results of task CL-2 . . . 93
5.3.3.2 Results of task CL-3 . . . 96
5.3.3.3 Results of task CS-2 and CS-3 . . . 97
5.3.4 Discussion . . . 100
5.3.4.1 Using context to improve heuristics . . . 102
5.4 Chapter Summary . . . 103
6 Supervised Lexicon-Based Methods for Argument Stance Mining 104 6.1 Lexicon generation by backpropagation . . . 105
6.1.1 Differentiable architectures and backpropagation . . . 105
6.1.2 Application of backpropagation to lexicons . . . 107
6.1.2.1 The Lexicon network topology . . . 108
6.1.2.2 Optimisation . . . 110
6.1.2.3 Example . . . 110
6.2 Lexicon regularisation . . . 113
6.2.1 Complexity regularisation with p-norms . . . 113
6.2.1.1 L1-norm . . . 114
6.2.1.2 L2-norm . . . 114
6.2.1.3 Elastic-Net . . . 115
6.2.2 Drop-out regularisation. . . 115
6.2.2.1 Drop-out in neural networks. . . 115
6.2.2.2 Drop-out in lexicons . . . 116
6.2.2.3 Conclusion on lexicon regularisation . . . 116
6.3 Complex lexicon architectures . . . 117
6.3.1 Gating for information flow control . . . 117
6.3.2 Joint learning of lexicons and modifiers . . . 118
6.4 Evaluation . . . 121
6.4.1 Hyperparameter setting. . . 121
6.4.2 Baselines . . . 122
6.4.3 Results of shallow approaches . . . 123
6.4.3.1 Results of task SSC-2 . . . 123
6.4.3.2 Results of task SSC-3 . . . 126
6.4.3.3 Results of task STL-2 . . . 127
6.4.4 Discussion . . . 130
6.5 Chapter Summary . . . 131
7 Lexicon-based Feature Models for Stance Detection 133 7.1 Using lexicons for feature extraction . . . 134
7.2 Instance-level feature model using lexicon features . . . 135
7.2.1 Instance-level feature model with bag-of-words . . . 135
7.2.2 Instance-level feature model with mean embedding . . . 136
7.3 Sentence-level feature model using lexicon features . . . 137
7.3.1 Sentence-level lexicon model with frequency-based sentence encoding. 139 7.3.2 Sentence-level lexicon model with sentence embedding. . . 139
Contents vii
7.4.1 Word-level feature model with one-hot word encoding . . . 141
7.4.2 Word-level feature model with embedding. . . 141
7.5 Evaluating deep supervised argument mining . . . 143
7.5.1 Evaluation tasks . . . 143
7.5.1.1 Learning algorithms . . . 144
7.5.2 Results with instance-level feature models. . . 145
7.5.3 Results with sentence-level feature model . . . 153
7.5.4 Results with word-level feature model . . . 162
7.5.5 Discussion . . . 172
7.5.5.1 Lexicon-based enhancement of text representation . . . 172
7.5.5.2 Granularity of representation . . . 173
7.6 Chapter summary . . . 174
8 Conclusion and Future Work 177 8.1 Conclusion . . . 177
8.2 Research questions . . . 179
8.3 Objectives revisited . . . 180
8.4 Future work . . . 182
A Publications 184 B Background in Argumentation Theory 185 B.1 An overview of argumentation theories. . . 185
B.1.1 Monological versus dialogical argumentation . . . 185
B.1.2 The structure of an argument: the Toulmin model of argumentation . . 186
B.1.3 The argumentation process viewed as a graphical structure . . . 187
B.1.4 Dung’s unipolar abstract argumentation framework . . . 188
B.1.5 Bipolar argumentation . . . 190
B.1.6 Comparison in context . . . 191
B.2 Logical analysis of the interactions between arguments . . . 192
B.3 Pragmatic argumentation theory . . . 193
B.4 Impact on social media research . . . 193
C Example of lexicon computed by LEXICNET 195
List of Figures
1.1 Barack Obama’s AMA (Ask Me Anything) on Reddit . . . 2
1.2 A discussion tree from Reddit . . . 2
1.3 Rules of the Context Free Grammars in Palau and Moens (2009). . . 5
1.4 Symbols of the Context Free Grammars in Palau and Moens (2009). . . 5
1.5 The supervised classification process . . . 8
2.1 Graphical example of a debate graph . . . 13
2.2 Evolution of shallow versus deep learning approaches for stance classification . 25 3.1 The machine learning pipeline . . . 36
3.2 The pre-processing workflow . . . 38
3.3 One hot representation of text. . . 42
3.4 Embedding representation. . . 44
3.5 Mean embedding representation. . . 50
3.6 Example of a linear support vector machine. . . 56
3.7 Example of the influence of 2 support vectors on the shape of the separating hyperplane of a support vector machine. . . 59
3.8 Example of the different hyperplanes generated by a one-vs-all multi-class SVM. 60 3.9 Example of a 2 layer neural network. . . 61
3.10 Example of an Elman network architecture. . . 63
3.11 A LSTM unit. . . 64
4.1 Standard 4-fold cross-validation split . . . 66
4.2 Nested 4-fold crossvalidation split . . . 66
5.1 The Augmented Unsupervised Sentiment Surface process. . . 85
5.2 The Multi-strategy Unsupervised Stance Classifier process. . . 88
5.3 Accuracy results on Task CL-2.. . . 94
5.4 Accuracy results on Task CL-3.. . . 96
5.5 Accuracy results on Task CS-2. . . 99
5.6 Accuracy results on Task CS-3. . . 99
5.7 A comparison of context-sensitive vs context-insensitive methods on the IAC dataset. . . 102
6.1 A simple computational graph . . . 106
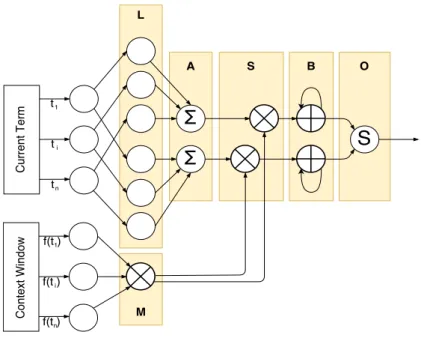
6.2 The LEXICNETnetwork topology . . . 108
6.3 Visualising drop-out. . . 116
6.4 The Sigmoid function . . . 118
6.5 The RELEXNETarchitecture . . . 119
List of Figures ix
6.6 Accuracy results of Task SSC-2 per dataset . . . 124
6.7 Accuracy results of Task SSC-2 averaged over all datasets . . . 125
6.8 Accuracy results of Task SSC-3 per dataset . . . 126
6.9 Accuracy results of Task SSC-3 averaged over all datasets . . . 127
6.10 Accuracy results of Task STL-2 per dataset . . . 129
6.11 Accuracy results of Task STL-2 averaged over all datasets . . . 129
7.1 Instance-level representation scheme using lexicon statistics. . . 136
7.2 Instance-level feature model with bag-of-words. . . 137
7.3 Instance-level feature model with mean embedding. . . 138
7.4 Lexicon representation of sentence level features. . . 138
7.5 Sentence level frequency-based representation. . . 139
7.6 Augmented sentence level frequency-based representation. . . 140
7.7 Lexicon representation of sentence level features. . . 141
7.8 Augmented sentence level mean embedding representation. . . 142
7.9 Lexicon representation of word level features. . . 142
7.10 One hot encoding augmented with lexicon representation of text. . . 143
7.11 Embedding augmented with lexicon representation of text. . . 144
7.12 Box plot of accuracy results of Task DSC-2 with instance-level feature models per dataset . . . 147
7.13 Box plot of accuracy results of Task DSC-2 with instance-level feature models averaged over all datasets . . . 147
7.14 Box plot of accuracy results of Task DSC-3 with instance-level feature models per dataset . . . 148
7.15 Box plot of accuracy results of Task DSC-3 with instance-level feature models averaged over all datasets . . . 148
7.16 Box plot of accuracy results of Task DTL-2 with instance-level feature models. 152 7.17 Box plot of accuracy results of Task DTL-2 with instance-level feature models. 152 7.18 Box plot of accuracy results of Task DSC-2 with sentence-level feature model per dataset . . . 155
7.19 Box plot of accuracy results of Task DSC-2 with sentence-level feature model over all datasets . . . 156
7.20 Box plot of accuracy results of Task DSC-3 with sentence-level feature model per dataset . . . 158
7.21 Box plot of accuracy results of Task DSC-3 with sentence-level feature model over all datasets . . . 158
7.22 Box plot of accuracy results of Task DTL-2 with sentence-level feature model per dataset . . . 159
7.23 Box plot of accuracy results of Task DTL-2 with sentence-level feature model over all datasets . . . 161
7.24 Box plot of accuracy results of Task DSC-2 with word-level feature model . . . 164
7.25 Box plot of accuracy results of Task DSC-2 with word-level feature model . . . 164
7.26 Box plot of accuracy results of Task DSC-3 with word-level feature model . . . 167
7.27 Box plot of accuracy results of Task DSC-3 with word-level feature model . . . 167
7.28 Box plot of accuracy results of Task DTL-2 with word-level feature model . . . 168
7.29 Box plot of accuracy results of Task DTL-2 with word-level feature model . . . 170
7.30 Box plot of aggregated accuracy results of enriched approaches averaged per granularity level . . . 174
List of Figures x
7.31 Box plot of aggregated accuracy results of enriched approaches averaged per granularity level, separated by family of approaches . . . 175
B.1 Graphical example of an abstract argumentation framework . . . 189
List of Tables
2.1 Features from the stance classification literature: n-grams and tokens . . . 19
2.2 Features from the stance classification literature: hashtags and positional markers. 20 2.3 Features from the stance classification literature: dependency-parsing-based and durational features . . . 20
2.4 Features from the stance classification literature: specific counts and text statistics 21 2.5 Features from the stance classification literature: extracted from lexicons and lists of patterns . . . 22
2.6 Features from the stance classification literature: references, word vectors and sentiment-based features . . . 23
2.7 Features from the stance classification literature: features extracted from conver-sational context and topic analysis . . . 24
2.8 Learning algorithms used in the literature . . . 26
2.9 Descriptive statistics of two transcribed media stance detection datasets. . . 31
2.10 Descriptive statistics of three social media stance detection datasets. . . 32
2.11 Class distribution in the AWTP dataset. . . 32
3.1 Example of word embedding representation over a latent space of 5 dimensions 45 3.2 Table of logarithmically scaled frequencies . . . 48
3.3 Table of inverse document frequencies . . . 49
3.4 Table of tf-idf scores . . . 49
4.1 An example of confusion matrix for binary classification with classes A and B . 67 4.2 Descriptive statistics of our selected four stance detection datasets. . . 69
4.3 High-precision expressions indicative of agreement class . . . 72
4.4 High-precision expressions indicative of disagreement class. . . 72
4.5 Verbs indicating agreement . . . 73
4.6 Nouns/adjectives indicative of agreement class, targeting the author . . . 73
4.7 Nouns/adjectives indicative of agreement class, targeting the object. . . 73
4.8 Verbs indicating disagreement . . . 74
4.9 Nouns/adjectives indicative of disagreement, targeting the author . . . 74
4.10 Nouns/adjectives indicative of disagreement, targeting the object . . . 74
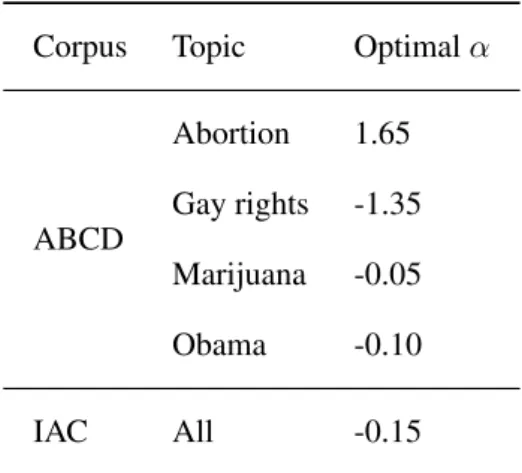
5.1 Optimalαthresholds on two datasets with SP-ADAPT . . . 79
5.2 High-precision regular expressions indicative of agreement class . . . 90
5.3 High-precision regular expressions indicative of disagreement class . . . 90
5.4 Task vs dataset . . . 92
5.5 Task vs algorithm . . . 92
5.6 Accuracy results of Task CL-2 . . . 94
5.7 Results of ANOVA on task CL-2 . . . 95
List of Tables xii
5.8 Tukey test for IAC and ABCD on CL-2 . . . 95
5.9 Accuracy results of Task CL-3 . . . 96
5.10 Results of ANOVA on task CL-3 . . . 97
5.11 Tukey test for IAC, ABCD and SETC on CL-3 . . . 97
5.12 Accuracy results of task CS-2 and CS-3 on the IAC dataset . . . 98
5.13 Results of ANOVA on tasks CS-2 and CS-3 . . . 100
5.14 Tukey test for IAC on CS-2 and CS-3 . . . 101
5.15 Mean accuracies when averaging over types of approaches . . . 102
5.16 Differences and p-values of a Tukey HSD test comparing class-sensitive vs class-insensitive methods . . . 103
6.1 Example dataset for stance classification . . . 111
6.2 Example of lexicon initialisation . . . 111
6.3 Example of lexicon after first iteration . . . 113
6.4 Accuracy results of Task SSC-2 . . . 124
6.5 Results of ANOVA on task SSC-2 . . . 124
6.6 Tukey test for IAC and ABCD on SSC-2.†indicates statistical significance at 0.95 confidence. . . 125
6.7 Accuracy results of Task SSC-3 . . . 126
6.8 Results of ANOVA on task SSC-3. † indicates statistical significance at 0.95 confidence. . . 127
6.9 Tukey test for ABCD and SETC on SSC-3.†indicates statistical significance at 0.95 confidence. . . 128
6.10 Accuracy results of Task STL-2 . . . 128
6.11 Results of ANOVA on task STL-2. † indicates statistical significance at 0.95 confidence. . . 130
6.12 Tukey test for IAC, ABCD and SETC on STL-2 . . . 131
7.1 Accuracy results of Task DSC-2 with instance-level feature model . . . 147
7.2 Results of ANOVA on task DSC-2 . . . 148
7.3 Results of Tukey test on task DSC-2 . . . 149
7.4 Accuracy results of Task DSC-3 with instance-level feature model . . . 150
7.5 Results of ANOVA on task DSC-3 . . . 150
7.6 Results of Tukey test on task DSC-3 . . . 151
7.7 Accuracy results of Task DTL-2 with instance-level feature models . . . 152
7.8 Results of ANOVA on task DTL-2 . . . 153
7.9 Results of Tukey test on DTL-2. . . 154
7.10 Accuracy results of Task DSC-2 with sentence-level feature model . . . 155
7.11 Results of ANOVA on task DSC-2 . . . 156
7.12 Results of Tukey test on task DSC-2 with sentence-level representations . . . . 157
7.13 Accuracy results of Task DSC-3 with sentence-level feature model . . . 158
7.14 Results of ANOVA on task DSC-3 . . . 159
7.15 Results of Tukey test on task DSC-3 . . . 160
7.16 Accuracy results of Task DTL-2 with sentence-level feature model . . . 161
7.17 Results of ANOVA on task DTL-2 . . . 162
7.18 Results of Tukey test on task DTL-2 . . . 163
7.19 Accuracy results of Task DSC-2 with word-level feature model . . . 164
List of Tables xiii
7.21 Tukey test for IAC, ABCD and SETC on DSC-2 . . . 166
7.22 Accuracy results of Task DSC-3 with word-level feature model . . . 167
7.23 Results of ANOVA on task DSC-3 . . . 168
7.24 Tukey test for IAC, ABCD and SETC on DSC-3 . . . 169
7.25 Accuracy results of Task DTL-2 with word-level feature model . . . 170
7.26 Results of ANOVA on task DTL-2 . . . 170
7.27 Tukey test for IAC, ABCD and SETC on DTL-2 . . . 171
7.28 Mean accuracies when averaging over types of approaches . . . 173
7.29 Differences and p-values of a Tukey HSD test comparing granularity level for different tasks . . . 175
C.1 Example toy lexicon computed on the IAC dataset, with seed dictionary from Hu and Liu (2004) (part 1 of 4) . . . 196
C.2 Example toy lexicon computed on the IAC dataset, with seed dictionary from Hu and Liu (2004) (part 2 of 4) . . . 197
C.3 Example toy lexicon computed on the IAC dataset, with seed dictionary from Hu and Liu (2004) (part 3 of 4) . . . 198
C.4 Example toy lexicon computed on the IAC dataset, with seed dictionary from Hu and Liu (2004) (part 4 of 4) . . . 199
I dedicate this to my parents, my brother, and my wonderful partner.
Chapter 1
Introduction
The advent of the social web has transformed the way we communicate on the Internet. While the World Wide Web was created as a mean to disseminate knowledge so as to prevent information loss in CERN (Berners-Lee,1989) ; the several improvements in networking infrastructure and
the invention of web technologies that were able to make use of the faster speed paved the way for complex web platforms that allowed for not only producer-to-consumer communication, but also for user-to-user interaction. With the popularisation of social websites, the richness of human interactions soon were adapted to their virtual equivalent, bringing casual discussions, debates, and all out profanity-rich "shouting matches" to the comment sections of many websites. However, the architecture of the World Wide Web allowed for bringing these activities to scales that were never explored before, with sometimes tens of thousands communicating with each other on a common topic of interest. For example, the social link aggregator Reddit.com held an informal interview (AMA, for Ask Me Anything, in the Reddit terminology) with Barack Obama which contained more than 20,000 comments (figure1.1).
This increase in communication has consequentially led to an increase in the data generated by these interactions, which has made it more and more difficult for both human users and algorithms to make use of such data. This had led to a significant amount of research effort being dedicated at automated techniques that are able to make sense of these quantities of data, whether it is mining the political opinions of Twitter users (Pak and Paroubek,2010), detecting customer
tastes to improve product recommendation using Amazon reviews (Chen et al.,2014) or trying to
predict the emotional reaction to Facebook posts (Clos et al.,2017).
Chapter 1.Introduction 2
FIGURE1.1: Barack Obama’s AMA (Ask Me Anything) on Reddit contained more than 20,000 comments over the few hours of the event.
FIGURE1.2: A discussion tree from Reddit where users discuss United Kingdom politics.
Online discussion forums (Figure1.2) typically manifest into tree-like structures that are
reminis-cent of argument trees. Whilst these discussion forums contain a wealth of information related to people’s opinions they also include implicit argumentation information. However unlike argument trees any relationship between posts in a discussion tree remains implicit. In recent years there has been considerable interest in harnessing opinionated knowledge that is buried in discussion forums in a variety of domains (e. g., retail, health and politics).
However to-date the main focus of opinion mining has been on mining raw opinion, sentiment and emotion without paying much regard to some of the relational characteristics of user comments. Consider the discussion excerpt presented in Figure1.2. We consider the outcome of applying the
SMARTSA state-of-the-art sentiment analysis system (Muhammad et al.,2013) to argumentative
content. The aggregated sentiment of comment 1 (circled in green) is positive with a value of
Chapter 1.Introduction 3
−0.23. A casual observation would suggest that the opinion expressed in both comments are not opposed but aligned.
However, a closer examination shows us that there is indeed a discrepancy between the actual opinions expressed, which are similar, and what a sentiment analysis algorithm tells us, which is that comment 1 is positive while comment 2 is negative. This is due to the fact that sentiment analysis algorithms, such as SMARTSA, generally rely only on the aggregated sentiment mined from the terms contained in the sentences, thus considering user comments in a vacuum. In this thesis, we tackle the challenge of argument stance mining by exploring the use of argumentation constructs for argumentative stance mining in social media. We explore a series of techniques that make a progressively heavier use of context and machine supervision, drawing from unsupervised heuristics to recurrent neural networks.
1.1
Applications of argumentative stance mining
Debating and arguing has always been a fundamental process of human cognition and interaction. Only recently have those debates moved from the small scale of panel discussions and expert-driven arguments to the large-scale, comparatively messy process of online argumentation. Traditionally, when a user seeks to understand a debate, it is a trivial matter for them to simply ask multiple participants of the debate for their point of view, and the facts they are basing them on, before synthesising their own conclusion. That process does not work when the participants are counted in the thousands and the facts, reasoning patterns and opinions in the tens of thousands. Considering that online user discussions are already structured as interaction graphs, being able to instantly know how much and where people are agreeing and disagreeing would provide systems with valuable information to summarise a debate. One could, for instance, use the average number of agreement and average number of disagreement as a social signal that allows the system to rank and organise user comments by level of controversiality. Conversely, it would allow, given enough data to begin with, for a user to know the likely response of a community to a given idea, argument or statement by simply looking at similar cases from the recent past.
Chapter 1.Introduction 4
Finally, being able to provide an argumentative stance between pairs of argument would simply allow experts to better understand the finer points of a debates. This has led to the creation of multiple software tools to analyse arguments in different types of text in a guided way: Araucaria (Reed and Rowe, 2004), OVA+ (Reed et al., 2014) and the Argument Analysis
Wall (Bex et al.,2013), both as a way to study argumentation in the wild and to build better
systems able to analyse arguments in more standard documents.
1.2
Related research fields
Argument stance mining draws upon the research of many neighbouring fields that have dealt with data of the same nature, such as argumentation mining, sentiment analysis, text classification (supervised and unsupervised) and information retrieval. This section focuses on relating all these fields to argument stance mining and contextualising them with respect to this thesis.
Argument mining Argument mining as a field tends to focus on detecting the presence of
arguments in formal or informal text. As such it is often used as a precursor of argument stance mining. Traditional approaches pioneered byPalau and Moens(2009) make heavy use of
supervised classifiers such as the Maximum Entropy Classifier (detailed inJaakkola et al.(2000)
and Support Vector Machines (detailed inHearst et al.(1998)) trained on legal documents, as
well as context-free grammars (detailed in Figures1.3and1.4) to detect the internal structure of
arguments before classifying them.
In this thesis we focus on informal arguments. In order to make the task feasible, and because informal argumentation does not tend to focus on following a strict representation, we make the simplifying assumption of considering the entire posts as potential arguments, and then attempt to detect their argumentative stance with respect to their parent post.
Sentiment analysis Sentiment analysis is the field focusing on detecting the strength and
polarity of sentiment in informal or formal text. It is often used in social media analysis in order to provide a high level overview of what users think about a topic, whether it is a political topic/idea, a product, or an event. Sentiment and stance are two highly related topics, with
Chapter 1.Introduction 5
FIGURE1.3: Rules of the Con-text Free Grammars inPalau and
Moens(2009).
FIGURE 1.4: Symbols of the Context Free Grammars inPalau and Moens(2009).
sentiment being often seen as a proxy for stance towards a global topic. In this thesis, we explore the use of sentiment as a proxy for stance using a series of heuristics. We also use sentiment as a feature model for supervised stance classification.
Supervised text classification Supervised text classification focuses on building a supervised
model that is able to learn from data and classify new data. Its main drawback is the need for a lot of training data. Its advantage is how powerful and accurate it can be given the right representation and the right algorithm. In this thesis we explore supervised classifiers to classify the argument stance of informal posts and focus on representation schemes in order to enhance argument stance classification.
Unsupervised text classification Unsupervised text classification is similar to supervised text
classification but replaces the training data with heuristic rules that have been designed by humans. Its advantage is that it is not affected by the absence of data, and its drawback is that human heuristics are plagued by human bias and are never as powerful as statistical correlations. In
Chapter 1.Introduction 6
this thesis we explore unsupervised classifiers to classify the argument stance of informal posts, particularly unsupervised techniques that make use of heuristics to detect the target of local sentiment such as the Sentiment Surface algorithm.
Information retrieval Information Retrieval (IR) focuses on the storage, indexing and retrieval
of documents given an information need formulated by a user (implicitly or explicitly). A large part of the focus of information retrieval as a field is term weighting, in order to represent documents not by all of their terms in an equal manner, which would give an unwarranted over-importance to documents which are very long, but by their most representative terms (both representative at a document level and at a corpus level). In this thesis we investigate IR-inspired term weighting techniques used to enhance supervised and unsupervised classification of argument stance in social media posts.
1.3
Scope of the research
In this section we detail the scope of our research, first by detailing our research motivation and how it fits in the scientific landscape of social media mining and debate analysis, and then moving on to the research objectives that stem from this motivation.
1.3.1 Research motivation
The classification pipeline (illustrated in figure1.5) is a multi-step process. First, the complete
dataset is split into two datasets: a hold-out evaluation dataset, typically composed of 20% of the data (using a stratified sampling strategy to not bias the evaluation), and a training dataset that is used for tuning model parameters. We then useK−Fold cross-validation (withKtypically being 5 or 10) to select the optimal parameters for our model. This process works on the following steps: first, the training dataset is split intoKpartitions using a stratified sampling strategy. Then, every one of these partitions is used as a test set with a model that is trained on the remaining K−1partitions. This process producesKperformance scores, which are averaged to produce an overall score for the given hyperparameters. Then, either the parameters which are issued from the fold that produced the best performance score or a weighted combination of the parameters of
Chapter 1.Introduction 7
all folds using the performance metrics as weights is used to produce the optimal model, which is finally evaluated against the hold-out evaluation dataset that was held out in the first step. This process requires that the data be represented in a way that allows the learning algorithm to perform the training stage in an efficient and effective way. This is typically called the feature engineering phase.
Traditional stance classification feature engineering techniques lean in either one of the following extremes: on one hand, a complex representation model that uses up to a few hundreds manually crafted features in order to enhance the learning process using human common sense, and on the other hand an overly simplistic feature model that is built only on raw term frequencies (bag of word models) which are fed to a complex classifier. Both of those approaches present crucial flaws:
• Complex feature models are highly platform specific, and thus any knowledge learned from them is specific to the data on which is it used and cannot be ported to alternative platforms.
• Bag of word models fed into complex classifiers are turned into black boxes in which it is virtually impossible to inspect a classification a posteriori and justify it by looking at the model (explanation by transparency).
In this thesis we aim to bridge that gap by developing a model that is simple, knowledge-light (in that it doesn’t require specially hand-crafted features) and competitive with common black box models.
1.3.2 Research questions
In order to bridge this gap, we derive a list of research questions that will guide our investigation throughout this thesis. Each of those research questions builds upon the potential findings of the previous one.
RQ1. Can we use the direct conversational context to improve classification accuracy by helping a naive classifier focus on relevant terms? Concretely, can we use our knowledge of the
Chapter 1.Introduction 8 Dataset Evaluation data Training data K-Fold Cross-Validation Training set Test set 20% 80% (k-1)/k 1/k Learning algorithm Trained model
Fold evaluation Optimal model
Evaluation Performancescores
FIGURE1.5: The supervised classification process
direct context of a conversation to improve the performance of a naive classifier? This research question is addressed in chapter 5.
RQ2. Can we use empirical risk minimisation techniques to learn a regularised stance classifica-tion lexicon? This research quesclassifica-tion is addressed in chapter 6.
RQ3. Can we leverage the neighbourhood of words to learn a context-sensitive classification lexicon? This research question is also addressed in chapter 6.
RQ4. Can class-sensitive features learned on a corpus enrich an existing term representation and allow it to better represent argumentative content? This is addressed in chapter 7.
RQ5. At what level of granularity (words, sentences, or entire instance) does lexicon enhancement performs better when applied to standard representation schemes? This question is also answered in chapter 7.
These research questions lead us to formulate a set of research objectives which are detailed in the following section.
Chapter 1.Introduction 9
1.3.3 Research objectives
We formulate the following four research objectives in order to answer our research questions.
To develop an unsupervised classification algorithm that leverages conversational context and existing resources from the field of opinion mining.
To develop a novel approach to learn an argument lexicon from weakly labelled data.
To develop a novel learning algorithm to jointly learn an argument lexicon and its modifiers.
To develop a representation scheme using the argument lexicon as a feature extractor that can leverage the temporal nature of text.
1.4
Contributions
The contributions in this thesis are multiple, and target different research questions and research objectives mentioned in the previous sections.
Firstly, we contribute a novel stance classification dataset built on a large scale mining of the Reddit social link aggregation website, and a distant labelling strategy. This dataset is used to experiment on the transfer learning capabilities of regularised lexicons and lexicon-enhanced representations.
Secondly, we contribute a series of unsupervised stance classification algorithms. Those algorithms allow us to investigate the use of complex heuristics in order to approximate stance classification using approaches inspired from the already well explored field of opinion mining. We explore a set of techniques that make use of opinion as a way to approximate stance by augmenting it with additional heuristics, either by using simple lexicon classification or by utilising natural language processing heuristics.
Thirdly, we contribute two approaches to learn regularised lexicons from data of varying quality. LEXICNET is the first of those approaches, using a regularised gradient-based optimisation
Chapter 1.Introduction 10
in the form of RELEXNET, which adds contextual terms in order to offer a richer way to model argumentative language.
Finally, we offer a series of representation schemes that use the argument stance lexicons previously computed (LEXICNETand RELEXNET) in order to enrich semantic and/or statistical
representations of the data, before feeding it into traditional machine learning algorithms. Those representation schemes operate at multiple levels of granularity (representing words, representing sentences, and representing the whole instance) and use different lexicons, in order to provide a comparative study of those effects.
1.5
Overview of the thesis
In this section we will detail an overview of the thesis and the mapping between each chapter and the corresponding contributions.
In chapter 2, we present a review of the literature in argument stance mining, starting with argumentation in social media, algorithms to detect and process arguments and modern methods for stance classification. The first part of this chapter is dedicated to explaining the main theories of argumentation and how they relate to stance detection. The second part of this chapter is divided into two sections. The first section focuses on the different corpora built by the stance detection and social media mining communities; the second section gives a detailed overview of the literature in methods for stance classification, separating the related works into unsupervised, supervised shallow, and supervised deep methods to illustrate the evolution of the field from heuristic-based approaches to deep neural networks.
In chapter 3, we introduce the background knowledge necessary for the rest of the thesis. We begin with a detailed explanation of the general field of text classification by explaining its theoretical underpinnings, the standard methodologies for evaluating its algorithms, and an explanation of two types of methods popular in the social media mining literature: supervised classifiers and lexicon-based methods. We finally present standard evaluation methodologies that will be used to validate our research objectives against the state of the art.
Chapter 1.Introduction 11
In chapter 4 we present our evaluation methodology, starting with the datasets collected for this research and finishing with the statistical testing procedure used to formally test the significance of our results.
In chapter 5, we present our first contribution: three novel unsupervised argument stance mining algorithms using sentiment-as-a-proxy heuristic-based methods. The first one, SP-ADAPT, relies on existing sentiment analysis resources along with adaptive thresholding to approximate the stance of the user. The second one, USS+, extends the existing Unsupervised Sentiment Surface with different failure modes to account for malformed data that is typical of social media corpora. Finally the third one, SP-COSTS, uses relational knowledge between a post and its parent post to perform term selection and improve the classification stage, while relying on different failure modes for when the heuristics do not apply.
In chapter 6, we present our second contribution: an approach to learning lexicons, which we extend to joint learning of lexicon and modifier terms. We formalise lexicon learning in an empirical risk minimisation framework, and then apply gradient-based optimisation in order to induce optimal lexicon weights from very small datasets (the LEXICNETalgorithm). This allows
us to apply different regularisation methods that make our lexicon more robust to overfitting. We extend our lexicon learning method to take into account modifier terms using a simple additive gating model (the RELEXNETalgorithm) along with a recurrent network-inspired architecture.
In chapter 7, we present our third and final contribution: a representation scheme that preserves the temporal structure of posts using lexicons as feature extractors. Our representation models the temporal nature of posts by keeping the structure of discourse, which allows us to train a supervised classification algorithm not only on the semantic vectors of terms (traditional embeddings) but also on class vectors of terms. We build a set of representations at multiple levels of granularity in order to evaluate its usefulness on a diverse class of datasets.
Finally in chapter 8, we present the conclusion to this thesis. We re-state our research questions and the interpretation of our experimental results and use them to outline potential future directions of our research.
Chapter 2
Literature Review
Argumentation theory is a highly interdisciplinary domain, spanning a period of time starting with the study of rhetoric in ancient Greece to, more recently, the use of abstract argumentation for collaborative decision-making systems. This multidisciplinary status allows us to examine it under multiple lenses. Philosophers, linguists, and computer scientists have all built their own theories of argumentation with the goal of modelling specific phenomena (e. g., multi-agent negotiation). In this thesis we focus on the role of argumentation as a formalisation of the interaction between multiple users in a social media context, and therefore select Pragmatic Argumentation Theory (van Eemeren,1993,Hutchby,2013) as our underlying target.
Pragmatic Argumentation Theory defines an argument as an opinionated piece of text which can arise in the presence of two elements: (1) a target, being some other action by another actor, has been called out as being problematic ; (2) astance, i.e. whether it is supporting or attacking the target regarding the problematic element, has been stated. This simplification of the argumentation representation helps with applying those mappings to social media content, by relaxing the definition of an argument. Indeed, users of social media tend to prefer a highly informal language and as such are less likely to worry about formulating a well-formed argument. We thus study the classification of argument stance in a Pragmatic Argumentation Theory setting, where the dialogue between users can be viewed as a graph, and more specifically a tree, and the stance of each contribution can be seen as an edge that is present between two vertices of that graph (local stance), an edge that is present between one vertex and the root of the tree (global
Chapter 2.Literature Review 13
FIGURE 2.1: Graphical example of a debate graph. The vertices are arguments, while the arcs are interactions between arguments, where a crossed arc between an argumentai and
an argumentajmeans that argumentaiattacks argumentaj, and therefore an observer who
believesaito be true must believeajto be false in order to maintain consistency.
stance). Argument stance detection thus consists in the classification of such edges, and lies on existing research in stance detection, sentiment analysis, and general text classification.
A detailed analysis of the relevant theories can be found in appendixB.
2.1
Methods for Argument stance detection
In this section we will detail datasets and methods for stance classification, both in the context of argument mining and in more general terms as it relates to this thesis. Being bound to the study of dialogical argumentation, the task of stance classification has multiple definitions, according to the use case it is attached to. We can broadly divide them into two different cases: (1) global stance classification, and (2) local stance classification.
Global stance classification is the study of the stance of a claim with respect to an overarching
topic. While it is possible that global stance can be inferred from the network of local stances, the difference in granularity makes it almost impossible: the root topic can contain a multitude of details, and any further comment can agree or disagree with any arbitrary subset of those
Chapter 2.Literature Review 14
details. For example, in Figure2.1depicting a graphical example of a debate wherea1is the root
argument, which can be thought of as the core topic of the discussion (e. g., , "I am for LGBTQ rights" is both an argument in favour of LGBTQ rights and a topic of discussion), the global stance of argumenta5 is the stance ofa5with respect to the argumenta1. Becausea5 attacks
argumenta2, which itself is attacking argumenta1, we can infer that it is likely thata5 has a
positive stance towardsa1and therefore the topic at hand.
Local stance classification is the study of the stance of a claim with respect to the claim it is
responding to. For example, in figure2.1depicting a graphical example of a debate wherea1is
the core topic of the discussion, the local stance of argumenta5is the stance ofa5with respect to
the its most immediate parenta2, and is therefore a negative stance.
In this section we will go into more details about the methods that have been used in the literature to perform stance classification. This section is organised in the following way: first, we will give an overview of unsupervised approaches that can be applied to stance classification. We will then give more details on supervised approaches to stance classification, starting with shallow classifiers and feature engineering-based approaches and ending with newer deep learning-based methods.
2.1.1 Unsupervised approaches to stance classification
Because resources for unsupervised stance classification are scarce, this section will merge both original approaches from the stance classification literature as well as methods adapted from the closely related field of sentiment analysis.
Unsupervised stance classifiers The sentiment surface feature representation was built as a
baseline algorithm to extract significant features inWang and Cardie(2014), based on previous
work by Hassan et al. (2010) where the feature extractor extracts the minimum, mean and
maximum distance (in number of words) between words of negative polarity and second person pronouns. Those features are then fed into a support vector machine to provide the classification.
Wang and Cardie (2014) find that the sentiment surface representation is a strong baseline,
Chapter 2.Literature Review 15
of the authors. Because of the scarcity of unsupervised stance classification algorithms, we leverage the sentiment surface heuristic as a baseline algorithm along with sentiment analysis-inspired methods.
Ghosh et al.(2018) take a different approach to detect the stance of a statement, focusing on
syntactic rules and aspect extraction in order to provide a representation for each person’s position. Once they have determined the positions with respect to each aspect of the conversation, they formulate the classification of the overall stance as an integer linear programming problem and optimise an objective function in order to provide a consistent stance classification for the entire set of statements. Their final approach, which combines an improved lexicon, a co-reference resolution, an aspect importance weighting and a negation handling procedure outperforms several baselines on the MPQA political debate dataset (Somasundaran and Wiebe,2010a).
Adapting sentiment analysis for stance classification Sentiment analysis is the
computa-tional task of determining the underlying sentiment (positive, negative, or neutral) within an extract of text (Pang and Lee,2008). Unsupervised approaches to sentiment analysis focus on
the use of sentiment lexicons. Due to the relatedness between sentiment and stance, they can be adapted to the context of stance classification. Lexicons are a classification model where instead of using every word as a feature, only certain words which are deemed to be sentiment-bearing are considered. A list of those words is called a sentiment lexicon. After detecting sentiment-bearing words within an arbitrary textual content, a computational aggregation rule is used to determined whether the overall content is deemed positive or negative.
There are a number of freely available sentiment lexicons, the three most popular being:
• TheGeneral Inquirer lexicon(Stone et al.,1966) is composed of 1,915 positive words
and 2,291 negative words.
• TheMPQA Subjectivity lexicon (Wilson et al.,2005) is composed of 2,718 positive
and 4,912 negative words from multiple sources such as the General Inquirer lexicon, a list of sentiment-bearing adjectives (Hatzivassiloglou and McKeown,1997), and a list of
Chapter 2.Literature Review 16
• TheSentiWordNet lexicon(Baccianella et al.,2010) is a lexicon induced from the
Word-Net (Miller, 1995) ontology. It contains over 38,000 words from WordNet to which it
assigns a positive, negative and objective score.
Several additional works focus on optimising the use of such lexicons, either by fine-tuning them, or by modifying their scores based on contextual clues. For example,Muhammad et al.(2016)
enhance an existing general purpose lexicon (SentiWordNet) for a domain-specific application by adding additional vocabulary and sentiment scores.
Sentiment lexicons typically output scores based on which the classification is made, they can be trivially adapted to stance classification by changing the threshold at which the classification is made.
2.1.1.1 Conclusions from the unsupervised stance classification literature
We can see that there is no clear unsupervised stance classification literature to speak of, where most of the unsupervised techniques are either built from external resources such as the graphical structure of the discussion, or directly ported from the sentiment analysis literature. This points towards a need for more robust and specialised approaches that can deal with a variety of datasets without requiring a learning phase, which we will develop in chapter4.
2.1.2 Supervised approaches to stance classification
Supervised text classification is the process of automatically discovering a function that maps a piece of text, formally represented as a set of numerical features, to one or more classes. It does so by observing a dataset composed of a set of training instancesXand a set of their corresponding labelsY, and iteratively refining its model (the mapping function) by minimising its propensity to commit classification errors. Supervised approaches to stance classification can be put into two broad categories, which we will discuss in this section: a)feature engineeringandshallow
classifier-based stance classifiersfocus on manually extracting an enormous number of relevant
features and using state-of-the-art shallow classifiers such as Support Vector Machines and the Maximum Entropy Classifier in order to build a model ; b)deep learning-based classifiersfocus on jointly learning features and a classifier from the data itself using deep neural networks.
Chapter 2.Literature Review 17
2.1.2.1 Feature engineering and shallow stance classifiers
Because of the novelty of deep learning models, most of the literature of the past decade has focused on traditional shallow models for stance classification, which will be explored in this section. Early work has been focused on structured debates (Janin et al.,2003,Carletta et al.,
2005,McCowan et al.,2005), which have the distinct advantage of being easy to label. However,
such data does not easily map to modern social media conversations, in two ways:
• Transcribed structured debates typically involve a reduced set of participants in a long-form debate on a pre-chosen topic of discussion. Conversely, social media debates typically involve a large number of participants who often do not follow up on their statements, which creates a large number of branches for each argument.
• Transcribed structured debates typically use a more formal vocabulary than social media debates.
Later work on stance classification involved more and more use of social media as a source of data, from Twitter and Weibo debatesMohammad et al.(2016),Xu et al.(2016) to debate-focused
internet forumsWalker et al.(2012a),Ferreira and Vlachos(2016),Rosenthal and McKeown
(2015). This has shifted the focus on the research from static techniques that rely on mining the
correct structure of arguments to a pervasive use of feature models, natural language processing techniques, and machine learning.
Anand et al.(2011) use a set of arbitrary text-focused features (unigrams, bigrams, punctuation
marks, syntactic dependencies and dialogic structure) to build a rule-based classifier. However the difference between systems using only unigrams and systems using more complex features such as generalised dependencies was not found to be significant.Walker et al.(2012b) propose the
use of dialogic relations in order to enrich the content-based features using the MaxCut algorithm, which is used to exploit the structure of the reply graph. While the core of their approach is feature engineering-based, they show a significant improvement over a purely content-based approach by exploiting this graphical structure.
Somasundaran and Wiebe(2010a) andFaulkner(2014) focus on detecting stance-taking language
Chapter 2.Literature Review 18
the route of pairing stance-taking expressions to expressions of sentiment (positive or negative) using a lexicon of argument trigger expressions in order to build a feature model for their Support Vector Classifier,Faulkner(2014) feed the stance language directly into their classifier (Support
Vector Machines and Multinomial Naive Bayes).
Ahmed and Xing (2010) use a Latent Dirichlet Allocation inspired approach to model the
generative process that generated each word as mixture of two distributions: a distribution over topics and a distribution over ideologies. They then use collapsed Gibbs sampling to infer the parameters of the mixture, leading to discover the most likely ideological stance with respect to the subject at hand.
Some works, such asHasan and Ng(2013a), put constraints on consecutive posts in order to
transform the problem from a classification task to a sequence labelling task. This approach is similar toRosenthal and McKeown(2015), who choose to study the role of conversational
structure using a set of features related to the thread structure: whether the post is the root of the discussion (Boolean feature), whether the reply was by the same author (Boolean feature), the distance in number of posts from the root of the discussion (numerical feature) and the number of sentences in the post (numerical features).
Because of the SemEval Task 6 challenge on stance detection (Mohammad et al., 2016), a
spike of works on the topic of stance detection on a Twitter corpus appeared in 2016. In those approaches, the most successful used complex deep learning models, which we will discuss in section2.1.2.2, while other high performing ones focused on clever feature engineering along with
very diverse classifiers such as Logistic Regression, Multinomial Naive Bayes, Decision Trees, Maximum Entropy classification, Support Vector Machines, and Ensemble learners. Most of those approaches relied on Twitter specific-features such as hashtags (Zhang and Lan,2016,Tutek et al.,
2016,Krejzl and Steinberger,2016), social media-specific features such as emoticons (Zhang
and Lan,2016,Tutek et al.,2016), but also on more complex features such as latent topics
discovered through Brown clustering (Zhang and Lan,2016), matrix factorisation (Elfardy and
Diab,2016) or frequency analysis (Wojatzki and Zesch,2016a) and features derived from popular
word embedding approaches such as Word2Vec (Zhang and Lan, 2016, Tutek et al., 2016),
Sentiment2Vec (Zhang and Lan,2016) and GloVe (Igarashi et al.,2016,Bøhler et al.,2016).
Chapter 2.Literature Review 19
N-grams/ tokens
Unigrams Hillard et al.(2003) ; Moens et al. (2007) ; Germesin and Wilson(2009) ;Palau and Moens(2009) ;Wang et al.(2011) ; Abbott et al.(2011) ; Hassan et al.(2012) ; Walker et al. (2012b) ;Yin et al.(2012a) ;Hasan and Ng(2013b) ;Hasan and Ng(2013a) ;Misra and Walker(2017) ;Wang and Cardie (2014) ;Rosenthal and McKeown(2015) ;Walker et al.(2012c) ;Sridhar et al.(2015) ;Elfardy and Diab(2016) ;Zhang and Lan(2016) ;Sun et al.(2016) ;Liu et al.(2016) ;Patra et al. (2016) ;Misra et al.(2016) ;Li et al.(2016) ;Mohammad et al. (2017) ;Tutek et al.(2016) ;Igarashi et al.(2016) ;Krejzl and Steinberger(2016)
Bigrams Moens et al.(2007) ;Palau and Moens(2009) ;Abbott et al. (2011) ;Hassan et al.(2012) ;Walker et al.(2012b) ;Yin et al. (2012a) ; Hasan and Ng(2013b) ; Hasan and Ng(2013a) ; Misra and Walker(2017) ;Wang and Cardie(2014) ;Rosenthal and McKeown(2015) ;Walker et al.(2012c) ;Sridhar et al. (2015) ;Elfardy and Diab(2016) ;Zhang and Lan(2016) ;Sun et al.(2016) ;Bøhler et al.(2016) ;Wojatzki and Zesch(2016a) ;Misra et al.(2016) ;Li et al.(2016) ;Mohammad et al.(2017) ;Tutek et al.(2016)
Trigrams Moens et al.(2007) ;Palau and Moens (2009) ; Misra and Walker(2017) ; Rosenthal and McKeown(2015) ; Elfardy and Diab(2016) ;Zhang and Lan(2016) ;Sun et al.(2016) ; Wojatzki and Zesch(2016a) ;Mohammad et al.(2017) ;Tutek et al.(2016)
4-grams Zhang and Lan(2016)
2-char Mohammad et al.(2017) ;Tutek et al.(2016) 3-char Bøhler et al.(2016) ;Tutek et al.(2016)
{3,4,5}-char Zhang and Lan(2016) ;Mohammad et al.(2017) Word pairings Moens et al.(2007) ;Palau and Moens(2009)
Punctuation Moens et al.(2007) ;Abbott et al.(2011) ;Yin et al.(2012a) ; Misra and Walker(2017) ;Rosenthal and McKeown(2015) ; Zhang and Lan(2016) ;Wojatzki and Zesch(2016a) ; Moham-mad et al.(2017)
Language model
perplexity Hillard et al.(2003) ;Hahn et al.(2006)
TABLE2.1: Features from the stance classification literature: n-grams and tokens
provided with a carefully crafted feature model could perform extremely close to a Convolutional Neural Network. However, considering the amount of work in crafting such feature models and then removing a significant portion of them through feature selection, it could be argued that the computational advantages of a shallow algorithm are not that significant.
For the sake of completeness, we illustrate the set of features that were the most used in the literature in tables2.1,2.2,2.3,2.4,2.5,2.6, and2.7, categorising them along 13 different themes:
• N-grams/tokens(Table2.1) refers to features which are extracted by an analysis of the
Chapter 2.Literature Review 20
Hashtags Hashtag unigrams Zhang and Lan(2016) ;Mohammad et al.(2017) ;Tutek et al. (2016) ;Krejzl and Steinberger(2016)
Hashtag bigrams Zhang and Lan(2016) ;Krejzl and Steinberger(2016) Initial
n-gram
First unigram Hillard et al.(2003) ; Abbott et al.(2011) ; Hasan and Ng (2013a) ;Walker et al.(2012c) ;Sridhar et al.(2015) ;Krejzl and Steinberger(2016)
First bigram Abbott et al.(2011) ;Hasan and Ng(2013a) ;Walker et al. (2012c) ;Sridhar et al.(2015) ;Krejzl and Steinberger(2016) First trigram Abbott et al.(2011) ;Hasan and Ng(2013a) ;Walker et al.
(2012c) ;Sridhar et al.(2015) ;Krejzl and Steinberger(2016) Final
n-gram
Last unigram Germesin and Wilson(2009) ;Wang and Cardie(2014) Last bigram Germesin and Wilson(2009) ;Wang and Cardie(2014) Last trigram Germesin and Wilson(2009) ;Wang and Cardie(2014) TABLE2.2: Features from the stance classification literature: hashtags and positional markers.
Syntactic parsing
Dependencies Moens et al.(2007) ;Palau and Moens(2009) ;Abbott et al. (2011) ;Hassan et al.(2012) ;Walker et al.(2012b) ;Hasan and Ng(2013b) ;Hasan and Ng(2013a) ;Wang and Cardie (2014) ;Walker et al.(2012c) ;Sridhar et al.(2015) ;Zhang and Lan(2016) ;Sun et al.(2016) ;Patra et al.(2016) ;Misra et al.(2016) ;Igarashi et al.(2016)
Part of speech
tagging Wang and Cardie(2014) ;Rosenthal and McKeown(2015) ; Zhang and Lan(2016) ;Sun et al.(2016) ;Misra et al.(2016) ; Mohammad et al.(2017) ;Igarashi et al.(2016)
POS-generalised
dependencies Abbott et al.(2011) ;Hassan et al.(2012) ;Walker et al.(2012b) ;Hasan and Ng(2013b) ;Hasan and Ng(2013a) ;Walker et al. (2012c) ;Sridhar et al.(2015)
Durational
# sentences Misra and Walker(2017) ;Rosenthal and McKeown(2015) ; Walker et al.(2012c) ;Sridhar et al.(2015)
# words/tokens Hillard et al.(2003) ;Galley et al.(2004) ;Hahn et al.(2006) ; Germesin and Wilson(2009) ;Wang et al.(2011) ;Yin et al. (2012a) ;Misra and Walker(2017) ;Wang and Cardie(2014) ; Walker et al.(2012c) ;Sridhar et al.(2015) ;Sun et al.(2016) ; Bøhler et al.(2016) ;Krejzl and Steinberger(2016)
# characters Walker et al.(2012b) ;Yin et al.(2012a) ;Misra and Walker (2017) ;Walker et al.(2012c) ;Sridhar et al.(2015) ;Bøhler et al.(2016)
TABLE2.3: Features from the stance classification literature: dependency-parsing-based and durational features
Chapter 2.Literature Review 21
Counts
Repeated
punctuation Walker et al.(2012b) ; Hasan and Ng(2013b) ; Wang and
Cardie(2014) ;Walker et al.(2012c) ;Sridhar et al.(2015) ;
Bøhler et al.(2016) # Repeated
words Germesin and Wilson(2009)
# Punctuation
marks Palau and Moens(2009) ;Wang et al.(2011)
Word
lengthening Rosenthal and McKeown(2015) ; Zhang and Lan(2016) ;
Bøhler et al.(2016) ;Mohammad et al.(2017) # Misspelled
words Tutek et al.(2016)
Repeated
vowels Tutek et al.(2016)
Upper-case
words Wang and Cardie(2014) ;Zhang and Lan(2016) ;Bøhler et al. (2016) ;Mohammad et al.(2017) ;Tutek et al.(2016)
Average word
length Palau and Moens(2009) ;Walker et al.(2012b) ;Walker et al. (2012c) ;Tutek et al.(2016)
Sentence
length Palau and Moens(2009) ;Wang et al.(2011) ;Walker et al. (2012c)
TABLE2.4: Features from the stance classification literature: specific counts and text statistics
n-grams in order to reduce the dimensionality of the classification problem. It also contains character-based n-grams, such as 2-char (sequences of 2 characters), 3-char (sequences of 3 characters) and {2,3,4}-char (sequences of 2, 3 or 4 characters), as well as exhaustive word pairings (an exhaustive combination of all possible bigrams, followed by feature selection), treatment of punctuation signs as special tokens, and statistics derived from the language model derived from the text.
• Hashtags(Table2.2) refers to special n-grams which are marked by the user/debater as
being topical, using a specific symbol (#). They are treated either as unigrams (the entire hashtag is a token) or as bigrams (if multiple hashtags follow each other).
• Initial n-grams (Table 2.2) is a positional n-gram, where the first 1, 2 or 3 terms are
extracted and given special importance. It is built on the assumption that some indicators of the argumentative stance can be found in the beginning of the text.
Chapter 2.Literature Review 22
Lexicons and patterns
Generic lexicon,
keywords Hillard et al.(2003) ; Moens et al.(2007) ;Germesin and Wilson(2009) ;Palau and Moens(2009) ;Walker et al.(2012b) ;Hasan and Ng(2013b) ;Misra and Walker(2017)
Negation Wang et al.(2011) ;Walker et al.(2012b) ;Wang and Cardie (2014) ;Rosenthal and McKeown(2015) ;Zhang and Lan (2016) ;Bøhler et al.(2016) ;Wojatzki and Zesch(2016a) Acquiescence Wang et al.(2011)
Subjectivity lexicon Misra and Walker(2017)
Stance lexicon Rosenthal and McKeown(2015) ;Wojatzki and Zesch(2016a) ;Krejzl and Steinberger(2016)
Modal verbs Wojatzki and Zesch(2016a)
Emoticons Yin et al.(2012a) ;Rosenthal and McKeown(2015) ;Zhang and Lan(2016) ;Mohammad et al.(2017) ;Tutek et al.(2016) Foul words Yin et al.(2012a)
Hedging {1,2,3}-grams Misra and Walker(2017) ;Wang and Cardie(2014)
LIWC lexicon Abbott et al.(2011) ;Walker et al.(2012b) ;Hasan and Ng (2013b) ; Rosenthal and McKeown(2015) ; Walker et al. (2012c) ;Sridhar et al.(2015) ;Elfardy and Diab (2016) ; Misra et al.(2016)
Adverbs Moens et al.(2007) ;Palau and Moens(2009) Verbs Moens et al.(2007) ;Palau and Moens(2009) Main verb tense/type Palau and Moens(2009)
Sentence patterns Palau and Moens(2009) ;Wang et al.(2011) Subject type Palau and Moens(2009)
Accommodation Rosenthal and McKeown(2015) Ends in question mark Rosenthal and McKeown(2015) Ends in exclamation mark Bøhler et al.(2016)
TABLE2.5: Features from the stance classification literature: extracted from lexicons and lists of patterns
• Final n-grams(Table2.2) is the converse of initial n-grams, where we assume that the
last 1, 2 or 3 terms are more indicative of the stance than the rest of the text, and therefore we extract them as specific features.
• Syntactic parsing (Table 2.3) are features which can be extracted by using a
depen-dency parser, such as the Stanford parser (Chen and Manning,2014). It contains special
annotations such as dependencies, part-of-speech tags, and generalised dependencies.
• Durationalfeatures (Table2.3) are features indicative of the length of the text. It can be
measured in different ways, e. g., characters, terms or sentences.
• Counts-based features (Table2.4) are features which depend on the triggering of specific
Chapter 2.Literature Review 23
Citation
Reference to
scripture Tutek et al.(2016) ;Krejzl and Steinberger(2016) Reference to
scientific article Palau and Moens(2009)
Word vectors
Word2Vec-based
features Zhang and Lan(2016) ;Tutek et al.(2016) GloVe-based
features Bøhler et al.(2016) ;Liu et al.(2016)
Sentiment
Sentiment of subject (I, we) Igarashi et al.(2016) Sentiment
of target Igarashi et al.(2016) Sentiment2Vec-based
feature Zhang and Lan(2016) Opinion-generalised
dependencies Abbott et al.(2011) ;Hassan et al.(2012) ;Walker et al.(2012b) ;Hasan and Ng(2013a) ;Wang and Cardie(2014) ;Walker et al.(2012c) ;Sridhar et al.(2015) ;Misra et al.(2016) Sentiment lexicon-based
features Hillard et al.(2003) ;Hahn et al.(2006) ;Germesin and Wilson (2009) ;Wang et al.(2011) ;Hassan et al.(2012) ;Yin et al. (2012a) ;Hasan and Ng(2013a) ;Misra and Walker(2017) ; Wang and Cardie(2014) ;Rosenthal and McKeown(2015) ; Elfardy and Diab(2016) ;Zhang and Lan(2016) ;Sun et al. (2016) ;Bøhler et al.(2016) ;Patra et al.(2016) ;Mohammad et al.(2017) ;Igarashi et al.(2016) ;Krejzl and Steinberger (2016)
TABLE2.6: Features from the stance classification literature: references, word vectors and sentiment-based features
(e. g., “terrrrrrible”). It also contains some text statistics such as average word length and average sentence length.
• Lexicons and patterns-based features (Table2.5) are features which are triggered by
lexicons, which are predefined lists of terms or