BLIND SOURCE SEPARATUION BASED
ON THE WEIBULL MIXTURE MODEL
M. El-Sayed Wahed
Department of Mathematics, Faculty of Science Zagazig University, Zagazig, (Egypt). E-mail: [email protected] Abstract.
Modeling the distribution of the observed data with a parametric approach is an important tool of statistical signal processing. In applications where the data have many clusters, like image segmentation, a multi component probabilistic model representation such as mixture modeling is required. Actually, in many real applications in the field of image processing, Audio, blind equalization, there are a need to better approximate the observed data and the use of mixture approach. This paper aims to provide a realistic distribution based on Mixture of weilbull distribution, which has the advantage to characterize parameters estimation in each component in the mixture. We propose a formulation of the Nelder-Mead under weilbull distribution. For this, the method Likelihood function is used to update the mixture parameters. An application of this technique is considered for modeling signals. In which we used it as score function for blind signal separation (BSS), we resort to the Fast Independent Component Analysis (FICA) approach whilst to adaptively estimate the parameters of such score function.
Keywords:
Mixture Weilbull Distribution (MWD), Nelder-Mead (NM), Maximum Likelihood (ML), Independent Component Analysis (ICA), Blind Signal Separation (BSS).
1. Introduction
The problem of independent component analysis (ICA) has received wide attention in various fields such as biomedical signal analysis and processing (EEG, MEG, ECG), geophysical data processing, data mining, speech recognition, image recognition and wireless communications (Amari and Cichocki, 1998; Amari et al, 1997; Bell and Sejnowski, 1995; Cichock et al., 1997; Gardner, 1991; Slock, 1996). In many applications, the sensory signals(Observations obtained from multiple sensors) are generated by a linear generative model which is unknown to us . In other words, the observations are linear instantaneous mixtures of unknown source signals and the objective is to process the observations in such a way that the outputs correspond to the separate primary source signals.
The mixture modeling technique has been widely used for the estimation of the probability density function and has found significant applications in various domains (see for example, Refs. [10, 2,11]). We propose here the use of the weilbull distribution as the basic distribution in the mixture [9]. The weilbull distribution has been employed to model and detect Gaussian and non-Gaussian signals recently in speech modeling and image and video coding. We focus in this paper on the parameters estimation of the mixture weilbull model. To these end NM method used to obtain an ML (Maximum Likelihood) has been developed. In this method the shape parameters are updated by numerical optimization of the Likelihood function. Applications of this technique in BSS are considered. The rest of this paper is organized as follows: In section 2 we introduce the Mixture of Weibull (MW) approach. In Section 3, we present our approaches for the parameters estimation. In section 4, we introduce BSS. In section 5, we discuss the Application of the MW model in (BSS).
2. The Mixture of Weibull Distribution
A mixture of Weibull is a parametric statistical model which assumes that the data originates from a weighted sum of several Weibull sources. More specifically, a MW is defined as[12]:
ki
i i i i i
p
x
c
w
x
p
1
)
,
,
|
(
)
|
θ
(
w
i,
c
i,
i,
i)
,
i
1
,
2
,...,
k
.
k
is the number of mixture density components.
w
i is the ith mixture weight and satisfies
ki i
i
w
w
1
1
,
0
.
p
i(
x
|
c
i,
i,
i)
is an individual density of the Weibull density which is characterized by the following probability density function [9].
i
i i
i i i
x
c
p
β
|
x
c
|
exp
-
|
x
-
c
|
2
1
)
,
,
|
(
α 1 ii i
i i
(2)where
c
i is the location parameter,
i
0
is the scale parameter,
i
0
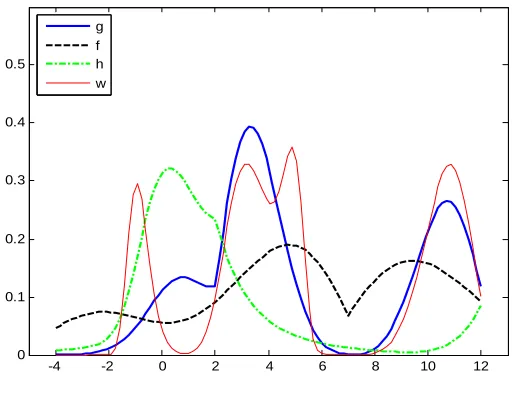
is the shape parameter .By varying the parameters of (Weibull), it’s possible to characterize a large class of distributions such as gaussian, subgaussian (more peaked, than gaussian, heavier tail) and supergaussian (flatter, more uniform).Fig 1 show some examples of pdfs for MW for k=2 ( k=1 is Weibull that introduce in[9]) .Thanks to the shape parameters the MW is more flexible and can approximate a large class of statistical distributions, this distribution requires to estimate4
*
k
parameters,
(
m
i,
c
i,
i,
i)
i
1
,
2
,...,
k
. Particular we discuss the estimation of these parameters in detail in the following sections.-4 -2 0 2 4 6 8 10 12
0 0.1 0.2 0.3 0.4 0.5
g f h w
Fig 1:the probability density functions of MW
for
k
2
,
c
1
2
,
c
2
7
,
2
4
,
2
,
7
,
3
,
1
2
,
5
,
4
,
3
,
2
4
,
2
,
7
,
9
with different weight.3,0.4,0.6
0
.7,
0
1
m
,m
2
1
m
1and
1
2
,
3
,
1
,
8
are(
g
,
f
,
h
,
w
)
respectively. 3. The log-likelihood function to estimate MWD parametersThe log-likelihood function of (2), given by [2].
k1 i
1 -N
1 j
i i i i
i j
i,
log
[
w
p
(x
|
c
,
α
,
β
)
]
)
|
L(
x
θ
j (3)where
N
the sample size and
i,j
p
(
i
|
x
j)
(
i
1
,...,
k
,j
[
0
,
N
1
]
)
represents the conditionalIn the case of Generalized Gamma distribution, if we substitute (2) into (3) and after some manipulation we obtain the following form of
L(
x
|
θ
)
:
k i N j k i N j i j i i j i i i j i i ic
c
w
1 1 1 1
, j
i,
log
(
)
log
(
)
log
(
)
log(
2
)
(
1
)
log
|
x
|
|
x
|
)
|
L(
x
θ
(4) Accordingly, we obtain for
i
1
,
2
,...,
k
the following nonlinear equation related to the estimated parameters by derivatives of the log-likelihood function with respect toc
i,
i,
i and setting these derivatives to zeros we obtain the following equations.0
)
(
,
,
0
)
(
,
0
)
(
i i iL
L
c
L
θ
|
x
θ
|
x
θ
|
x
(5)
N j i i i i i i i iij
c
c
c
i 1
0
|
x
|
log
|
x
|
|
x
|
log
1
(6)
N j i i i i ij ic
10
|
x
|
1
(7)
N j i i i i i i i i i i iij
sign
c
c
sign
c
c
i
1
1
(
x
)
0
|
x
|
)
x
(
|
x
|
1
(8)After a little mathematical manipulation, the ML estimate of
i is obtained.0
1
|
x
|
|
x
|
|
|
log
ˆ
1 ˆ 1 ˆ 1 1
N j i j N k i k k i N k k i i j j i N j j i i i ic
c
c
u
(9)Where
ˆ
i is the estimator of
ithen the estimator of
ˆ
iandc
ˆ
i are given by the following equations:
N k i k k i N k k i i ic
1 ˆ 1|
x
|
ˆ
(10)0
|
ˆ
x
|
ˆ
ˆ
)
ˆ
x
(
|
ˆ
x
|
1
ˆ
1 ˆ
N j i j i i i j i j i j i ic
c
sign
c
(11)4. Blind Signal Separation (BSS).
By definition, independent component analysis (ICA) is the statistical method that searches for a linear transformation, which can effectively minimize the statistical dependence between its components [10]. Under the physically plausible assumption of mutual statistical independence between these components, the most application of ICA is blind signal separation (BSS). In its simplest form, BSS aims to recover a set of unknown signals, the so-called original sources
s
(t)
[s
1(t),
s
2(t),....,
s
n(t)]
T
R
n, by relying exclusively on information that can be extracted from their linear and instantaneous mixtures
x
(t)
[x
1(t),
x
2(t),....,
x
m(t)]
T
R
mm
,
2,
1,
,
(t)
(t)
A
s
t
x
(12) where A
R
mxn is an unknown mixing matrix of full rank and m
n. In doing so, BSS remains truly (blind) in the sense that very little to almost nothing be known a priori for the mixing matrix or the original source signals. Often sources are assumed to be zero-mean and unit-variance signals with at most one having a Gaussian distribution. The problem of source estimation then boils down to determining the un-mixing matrix W
R
nxm such that the linear transformation of the sensor observation is
u
(t)
W
x
(t)
, t = 1,2,…,n , (13) where u(t)=[u
1(t),
u
2(t),....,
u
n(t)]
T
R
n yield an estimate of vector s(t) corresponding to the original or true sources. In general, the majority of BSS approaches perform ICA, by essentially optimizing the negative log-likelihood (objective) function with respect to the un-mixing matrix W such that
nl 1
l
u
(u
)]
log
|
det(
)
|
p
E[log
)
,
L(
l
W
W
u
, (14)where E[.] represents the expectation operator and
p
u(u
l)
l is the model for the marginal probability density function (pdf) of
u
l , for alll
1
,
2
,...,
n
. Normally, matrix W is regarded as the parameter of interest and the pdfs of the sources are considered to be nuisance parameters. In effect, when correctly hypothesizing upon the distribution of the sources, the maximum likelihood (ML) principle leads to estimating functions, which in fact are the score functions of the sources [7].
(
)
log
u(
l)
ll
l
p
u
du
d
u
l
(15)In principle, the separation criterion in (14) can be optimized by any suitable ICA algorithm where contrasts are utilized (see e.g., [7]). A popular choice of such a contrast-based algorithm is the so-called fast (cubic) converging Newton-type (fixed-point) algorithm, normally referred to as FastICA [1], based on
1 k
(E[
(
)
T]
k
W
D
u
u
W
diag
(
E
[
l(
u
l)
u
l]))
W
k, (16) where, as defined in [8],
D
diag(1/(E[
l(u
l)u
l]
E[
l'(u
l)]))
, (17) with
(t)
[
1(u
1),
2(u
2),....,
n(u
n)]
T being valid for alll
1
,
2
,...,
n
. In the ICA framework, accurately estimating the statistical model of the sources at hand is still an open and challenging problem [7]. Practical BSS scenarios employ difficult source distributions and even situations where many sources with very different pdfs are mixed together. Towards this direction, a large number of parametric density models have been made available in recent literature. Examples of such models include the generalized Gaussian density (GGD)[4], the generalized lambda density(GLD) and the generalized beta distribution (GBD) or even combinations and generalizations such as super and generalized Gaussian mixture model (GMM) [5], the generalized gamma density (GGD) [3]. In the following section we show example Mixture Weibull Density (MWD) for signal modeling in blind signal separation.5. Application of MWD in blind signal separation
Novel flexible score function is obtained, by substituting (1) into (15) for the source estimates
n
l
l
,
1
,
2
,...,
k i i i i l i i l i i l i l i i i l u l i i il
u
c
c
u
c
u
sign
c
u
w
u
p
1 2 2 l|
|
1
|
|
exp
)
(
|
|
2
1
1
)
|
(u
θ
(18) In principle
l(
u
l|
θ
)
.Is capable of modeling a large number of signals, such as speech or communication signals. This is due to the fact that its characterization depends explicitly on all parametersw
i,
c
i,
i,
i,
i
1
,
2
,...,
k
Other commonly used score functions can be obtained by substituting appropriate values for
m
i,
c
i,
i,
i in (18), for instance, whenk
1
we have score function
|
|
1
|
|
)
(
)
|
(u
1 1 1 11 1
l
1
c
u
c
u
c
u
sign
l l ll
θ
(19)When
1
1
and
1
1
we have a scaled form of the GGD-based score function constitutes such a special case of (17).1 1 1
)
|
|
1(
)
|
(
lu
lθ
sign
u
lc
u
lc
(20)The function
l(
u
l|
θ
)
could become singular, in some special cases, essentially those corresponding to heavy-tailed (or sparse) distribution defined for|
u
l
c
i|
0
. In practice, to circumvent such deficiency, the denominator in (18) can be modified slightly to read function
k i i i i l i i l i i l i l i i i l u l i i il
u
c
c
u
c
u
sign
c
u
w
u
p
1 2 2 l|
|
1
|
|
exp
)
(
|
|
2
1
1
)
|
(u
θ
(21)
where
is a small positive parameter (typically around 104) which, when put to use, can almost always guaranteethat the discontinuity of (18) or values in or approaching the region
|
u
l
c
i|
0
is completely avoided. 6. Numerical experimentsTo investigate the separation performance of the proposed MWD-based FastICA BSS method, a set of numerical experiments preformed in which we consider two example one artificial at
k
2
and anther real (speech signal), we illustrate this in the following two examples6.1. Example 1
In this example
k
2
and the data set used consists different realizations of independent signals, the number of data samples has also been designed to be relatively small, for example, N = 250. The source signals are mixed (noiselessly) with randomly generated full rank mixing matrices A. The FastICA method is implemented in the so-called simultaneous separation mode, whereas the stopping criterion is set to
10
4. FastICA is executed using the flexible MWD model is used to model the distribution of the unknown sources, while (9)–(11) are employed to adaptively calculate the necessary parameters of the MWD-based score function defined in (20). Now to show the performance in this case we consider three source signals (source) where this signals generated random from MWD. Let the mixing matrix A and un-mixing matrix W are defined as follow, .48 .32 .17 .86 .65 .75 .37 .79 .56 A 1.8687 1.8798 -1.9485 0.1646 0.1924 -0.2184 0.2566 0.2177 -0.2128 W
0 100 200 300 0
500 1000
fisrt mixing mixing signals
0 100 200 300
0 500 1000
second mixing
0 100 200 300
0 200 400
third mixing
0 100 200 300
0 500 1000
Source signals
fisrt source
0 100 200 300
0 5 10
second source
0 100 200 300
0 200 400
third source
Fig(2)
After using FastICA we recover the sources and we show the estimated signals in left and original signals in right in Fig (3) with different in scale only.
0 100 200 300
0 5
first estimated estimated Signals
0 100 200 300
0 5 10
second estimated
0 100 200 300
0 2 4
third estimated
0 100 200 300
0 500 1000
Source Signals
first source
0 100 200 300
0 5 10
second source
0 100 200 300
0 200 400
third source
Fig (3)
6.2. Example.1.
Consider three speech signals as sources, mixing matrix A and demixing matrix W are given as follow
.50
.78
.95
.96
.56
.22
.32
.89
77.
A
and
.0589
.0874
.0429
.0982
.0467
.0159
By using the equation
x
A
s
we obtain mixed signals as show in figure (4) where mixing signals in left and original signals in right. We recover the source by using FastICA and we show the estimated signals in left with scales, permutation and original signals in right in figure (5).0 2000 4000 6000 8000 -1
0 1
fisrt mixing mixing signals
0 2000 4000 6000 8000 -1
0 1
second mixing
0 2000 4000 6000 8000 -0.5
0 0.5
third mixing
0 2000 4000 6000 8000 -1
0 1
Source signals
fisrt source
0 2000 4000 6000 8000 -0.5
0 0.5
second source
0 2000 4000 6000 8000 -1
0 1
third source
Fig(4)
6. Algorithm performance
The separation performance for ICA algorithm is evaluated with the cross-talk error measure
nj n
i l n lj
j i n
i n
j l n il
j i
p
p
p
p
PI
1 1 1 2
2
1 1 1 2
2
1
|
|
max
|
|
1
|
|
max
|
|
(20)
Note that here
p
ij represents the elements of the permutation matrix P = WA, which after assuming that all sources have been successfully separated should ideally reduce to a permuted and scaled version of the identity matrix. The separation performance for first example isPI
18
.
72
dB
and for second exampleis
PI
26
.
01
dB
0 2000 4000 6000 8000 -5
0 5
fisrt estimated estimated signals
0 2000 4000 6000 8000 -10
0 10
second estimated
0 2000 4000 6000 8000 -5
0 5
third estimated
0 2000 4000 6000 8000 -1
0 1
Source signals
fisrt source
0 2000 4000 6000 8000 -0.5
0 0.5
second source
0 2000 4000 6000 8000 -1
0 1
Fig(5)
5.Conclusion
The main motivation of this study is to provide estimators for the MWD parameters. For this, a new formulation of the NM algorithm is conducted to include the parameters estimation. We have derived a novel parametric family of flexible score functions, based exclusively on the MWD model. To calculate the parameters of these functions in an adaptive BSS setup, we have chosen to maximize the ML equation with the NM optimization method. Simulation results show that the proposed approach is capable of separating mixtures of signals.
Reference:
[1] A.Hyvarinen, E.Oja, A fast fixed-point algorithm for independent component analysis, Neural computation, vol 9, no 7, October 1997, pp. 1483-1492.
[2] C. Tzagkarakis, A. Mouchtaris, P. Tsakalides; .Musical Genre Classification VIA Generalized Gaussian and Alpha-Stable Modeling, ICASSP 2006 Proceedings. Vol.5, 14-19 May 2006 pp 217.220.
[3] E.W. Stacy, A generalization of the gamma distribution, Ann. Math. Stat. vol 33, no 3, September 1962, pp. 1187 - 1192.
[4] K. Kokkinakis, A.K. Nandi, Exponent parameter estimation for generalized Gaussian probability density functions with application to speech modeling, Signal Process. vol 85, no 9, September 2005,pp. 1852-1858.
[5] J.A. Palmer, K. Kreutz-Delgado, S. Makeig, Super-Gaussian mixture source model for ICA, in: Proceedings of the International Conference on Independent Component Analysis and Blind Signal Separation, Charleston, SC, USA, March 5-8 ,2006, pp. 854-861. [6] J. Eriksson, J. Karvanen, V. Koivunen, Source distribution adaptive maximum likelihood estimation of ICA model, in: Proceedings of the
Second International Conference on ICA and BSS, Helsinki, Finland, June 19-22, 2000, pp. 227- 232.
[7] J.-F. Cardoso, Blind signal separation: statistical principles, Proc. IEEE, vol 86, no 10, October 1998, pp. 2009- 2025.
[8] J. Karvanen, V. Koivunen, Blind separation methods based on Pearson system and its extensions, Signal Process. vol 82, no 4, April 2002, pp. 663-673.
[9] M. El-Sayed Wahed, (2009): Blind signal separation using an adaptive Weibull distribution. International Journal of Physical Sciences Vol. 4(5), pp. 265-270.
[10] Pekka Paalanen, Joni-Kristian Kamarainen, Jarmo Ilonen, Heikki Klviinen; .Feature representation and discrimination based on Gaussian mixture model probability densities Practices and algorithms. Pattern Recognition 39 (2006) pp. 1346-1358.
[11] Vimal Bhatia, Bernard Mulgrew, .Non-parametric likelihood based channel estimator for Gaussian mixture noise, Signal Processing Vol. 87 (2007) pp 2569-2586.