An Enhanced Low Complexity And Fast
Lossless Compression Technique For Textual
Data
H. Anwer Basha, Dr. S. Arivalagan, Dr. P. Sudhakar
Abstract: Text compression is an important sort of compression which mainly comes under the area of lossless compression. Under the presence of lossless compression, the actual data can be retrieved from the compressed data. In this paper, a new efficient and fast compression technique is developed to compress text files. By incorporating a b64pack and LZW coding techniques, a new bLZW model is introduc ed here. The bLZW model operates in a set of three phases: Initially, it transforms the input text into a format which could undergo compression. At the next stage, a conversion of the message takes place to reduce the file size. Finally, LZW algorithm is applied to further reduce the compressed file size. This bLZW model is experimented using a set of benchmark text files. The experimental outcome indicated that the presented model outperforms the other methods under diverse dimensions.
Index Terms: Lossless compression; LZW; b64pack; Text compression.
—————————— ——————————
1.
INTRODUCTION
Data compression usually converts the actual data to other kind of data in compact form. The data could be file, a buffer in storage space or individual bits transmitted on a communication medium [1]. The major aim of DC is the minimization of actual data size as well as memory utilization and maximization of transfer rate. Generally, the categories of DC falls under two categories namely lossy and lossless depending upon the reconstruction process. Text compression is a type of DC that utilizes the lossless model for converting an input data into other file. It could not utilize the lossy compression model due to the fact that it requires the reconstruction of the actual data from the compressed one. When the lossy compression method is applied, the actual and reconstructed data would not be same [2]. Different models have been presented to compress the text in last decades. A maximum of DC models follows the concept of eliminating or minimizing the redundancy of the data from the actual file. The concept is based on the allocation of shorter length codes to general portions of the character, syllable and so on.
Presently, diverse models are available for compressing textual files and they undergo categorization into four kinds namely substitution, statistical, dictionary, and context-based model. The first type begins to replaces the particular maximum length redundant characters to a shorter one. The second type generally computes the possibility of the characters for generating the minimum average code length. The third one comprises dictionary models involving the replacement of a substring of text using an index or a pointer code. It is related to the location of the dictionary of the substring. Some of the examples are LZ77 and LZ78. The final
model is context-based ones that involve the usage of least considerations related to the statistical analysis of the text. Each of the above explained models possesses its merits as well as demerits based on its application to a particular domain. But, no models showed their capability of attaining optimal CR. In general, the user has an option to select the optimal model based on the requirement. When the decompression needs not be perfectly identical to the actual one, lossy compression model is employed. In other cases, when the reconstruction process should generate the data that needs to be exactly identical to the original data, lossless model can be used. Presently many text compression models are designed using dictionaries. [3] introduced a model for converting the characters present in the source file to binary code, where frequently occurring characters in the file holds the minimum length binary codes and the least common holds the longer one. The binary codes undergo generation using the computed probabilities of the character present in the file and undergo compression utilizing an 8-bit character word length. [4] devised a model which combines the words with LZW. Initially, the input text is divided to word and non-word. It is utilized as a beginning letter of LZW. In [5], a word-based compression model deepening upon the LZ77 algorithm is presented and designed in diverse ways of sliding windows and a range of probabilities of output encoding. This model outperforms the word based model and the word structure present in the text is not considered. Besides, few models depending upon the syllables are presented to compress the textual data. It comprises few languages which has the morphology in the structure of words. [6] introduced an effective lossless compression model for textual data and make use of a syllable-based morphology of multi-syllabic languages. It is developed to split the words to syllables and then generates compact representation. The bit count in the syllable is based on the entry count in the dictionary file. In [7], a genetic algorithm is presented in the syllable-based model for compressing text. It is applied to compute the features of the syllables. The features are saved in the dictionary which is a portion of the compression technique and is unwanted to put it in the compressed data results in the minimization of utilized memory.
————————————————
Research Scholar, Department of Computer Science, Annamalai University, Chidambaram, India. [email protected]
Associate Professor, Department of Computer Science and Engineering, Annamalai University Chidambaram, India. [email protected].
4014
Syllable-based text compression models are presented in [8, 9] concentrating on the syllable specification, disintegration of words into syllables, and utilizing syllable-based compression in mixture of the concepts of LZW and Huffman coding. In [10], a small text file compression model is presented based on BWT along with Boolean minimization. In this paper, a new efficient and fast compression technique is developed to compress text files. By incorporating a b64pack and LZW coding techniques, a new bLZW model is introduced here. The bLZW model operates in a set of three phases: Initially, it transforms the input text into a format which could undergo compression. At the next stage, a conversion of the message takes place to reduce the file size. Finally, LZW algorithm is applied to further reduce the compressed file size. This bLZW model is experimented using a set of benchmark text files. The experimental outcome indicated that the presented model outperforms the other methods under diverse dimensions
1
THE
PROPOSED
BLZW
MODEL
A new efficient and fast compression technique is developed to compress text files. By incorporating a b64pack and LZW coding techniques, a new bLZW model is introduced here. The bLZW model operates in a set of three phases: Initially, it transforms the input text into a format which could undergo compression. At the next stage, a conversion of the message takes place to reduce the file size. Finally, LZW algorithm is applied to further reduce the compressed file size. First, the discussion of b64 pack model takes place. Fig. 1 shows the stages involved in it. The basic aim of the first stage is to transform the input text into a format that could undergo processing in the subsequent stage. The input undergoes optional pre-compression in the earlier stage for achieving maximum space savings. It is assumed that the input comprises of letters, spaces, numerals and punctuation symbols widely employed in English language. An input text consists of these characters are used for analysis.
Fig. 1. b64 stages
The outcome produced from the initial stage is computed in the second stage comprising an individual conversion which minimizes the message size through a predefined percentage. This step is therefore completely deterministic and leads to static compression ratio (CR). One essential feature of this model is the non-existence of meta-data. It implies that the encoded data does not contain any header which is needed on the compression of small text.
1.1 Message Transcoding
The compression takes place in the latter stage of b64 pack [11] that needs an input text conversion to a particular pattern. For achieving it, the transcoding of input data takes through a set of five rules.
Rule 1
It should be considered that the characters remain same.
Rule 2
Every space character undergoes replacement using a forward slash ‗/‘ character.
Rule 3
Every punctuation mark undergo replacement using a series of 2 characters such as + and a lowercase alphabet. The relationship among the punctuation marks and the respective alternate letters are provided in Table 1.
Table 1 Mapping of punctuation marks to letters
□ = reserved for future use
Rule 4
Every punctuation mark from the collection of letters depicted in Table 2 undergo replacement using a series of three characters namely ++ and respective letter from the second row of Table 2.
Table 2 Mapping of less frequent punctuation marks to letters.
Rule 5
When a punctuation mark comes along with a space, it will be encoded based on Rule 3 or 4 except that rather than a lowercase letter, its uppercase correspondent is utilized. Here, the encoded space character is not considered.
1.2 Compressing transcoded messages
Base64 encoding process will map the random series of 24 bites to a series of 4 printable characters. In a prearranged series of 24 bits (i.e., three octets) of data,
𝑎 𝑎 𝑎 𝑎 𝑎 𝑎 𝑎 𝑎 𝑏 𝑏𝑏 𝑏𝑏𝑏 𝑏𝑏 𝑐𝑐𝑐 𝑐𝑐 𝑐𝑐 𝑐 (1)
Every bit is clustered to generate 4-bit sextets as shown below.
𝑎 𝑎 𝑎 𝑎 𝑎 𝑎 𝑎 𝑎 𝑏𝑏 𝑏𝑏 𝑏𝑏 𝑏𝑏 𝑐𝑐𝑐 𝑐𝑐 𝑐𝑐𝑐 (2)
Every sextet undergoes replacement using a printable character depending upon the mapping done using Table 3. The reconstruction of the b64 process takes place in a reversible way where the table 3 is applied for retrieving the actual data. The dictionary of the bLZW model is shown in Table 3. As seen in the table, a set of 64 characters needs a minimum of six bits to encode a character. Then, the LZW will helps to further compress the number of bits required to store the
character.
1.3 LZW model
Table 3 bLZW Dictionary
Pattern Char Pattern Char Pattern Char Pattern Char
000000 A 010000 Q 100000 g 110000 w 000001 B 010001 R 100001 h 110001 x 000010 C 010010 S 100010 i 110010 y 000011 D 010011 T 100011 j 110011 z 000100 E 010100 U 100100 k 110100 0 000101 F 010101 V 100101 l 110101 1 000110 G 010110 W 100110 m 110110 2 000111 H 010111 X 100111 n 110111 3 001000 I 011000 Y 101000 o 111000 4 001001 J 011001 Z 101001 p 111001 5 001010 K 011010 a 101010 q 111010 6 001011 L 011011 b 101011 r 111011 7 001100 M 011100 c 101100 s 111100 8 001101 N 011101 d 101101 t 111101 9 001110 O 011110 e 101110 u 111110 + 001111 P 011111 f 101111 v 111111 /
A specific LZW model receives every input series of bits in a predefined length (for instance, 12 bits) and generates an entry in a table (called as codebook). The table consists of a pattern and a shorter code for every character. When the input is read, codewords are substituted to effective compressive the total amount of data. In contrast to previous models called LZ77 and LZ78, LZW model includes a look-up table of codes as a portion of the compressed file. The decoding program which decompresses the file has the ability to construct the table.
2
EXPERIMENTAL
VALIDATION
2.1 Measures
The results of the bLZW model is validated by a set of two measures namely compression ratio (CR) and bits per character (BPC). They are defined in Eqs. (3) and (4). It should be noted that the value of minimum CR and BPC implies better performance.
𝐶𝑅 =No. of bits required to represent uncompressed file
Character count compressed file (3)
BPC
=Total no. of bits involved to represent a compressed file
Total Character count (4)
2.2 Results analysis
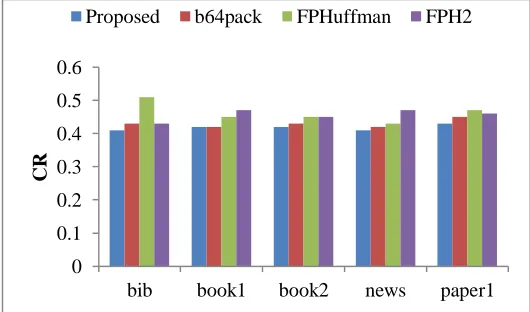
Table 4 and Fig. 2 provide a details compression performance analysis of diverse methods with respect to CR. By looking into the table, it is clear that that presented bLZW model attains a CR of 0.41 while compressing the ‗bib‘ dataset which is larger in size. The b64pack model achieves a CR of 0.43 during the compression of ‗bib‘ dataset. At the same time, the FPH2 also attains identical compression by attaining the same CR of 0.43. Besides, the FPHuffman model achieves CR of 0.51 while compressing the same ‗bib‘ dataset. On the compression of ‗book1‘ dataset, it is clear that that presented bLZW model attains a CR of 0.42. Then, the b64pack model achieves a CR of 0.42 during the compression of ‗book1‘ dataset. At the same
time, the FPH2 also attains compression by attaining the same CR of 0.47. Besides, the FPHuffman model achieves CR of 0.45 while compressing the same ‗book1‘ dataset. Similarly, on the compression of ‗book2‘ dataset, it is clear that that presented bLZW model attains a CR of 0.42. Then, the b64pack model achieves a CR of 0.43during the compression of ‗book2‘ dataset. At the same time, the FPH2 also attains compression by attaining the same CR of 0.45. Besides, the FPHuffman model achieves CR of 0.45 while compressing the same ‗book2‘ dataset.
Table 4 Compression performance analysis with respect to CR
Dataset [12]
CR
Proposed b64pack FPHuffman FPH2
bib 0.41 0.43 0.51 0.43
book1 0.42 0.42 0.45 0.47
book2 0.42 0.43 0.45 0.45
news 0.41 0.42 0.43 0.47
paper1 0.43 0.45 0.47 0.46
On the compression of ‗news‘ dataset, it is clear that that presented bLZW model attains a CR of 0.41. Then, the b64pack model achieves a CR of 0.42 during the compression of ‗news‘ dataset. At the same time, the FPH2 also attains compression by attaining the same CR of 0.47. Besides, the FPHuffman model achieves CR of 0.45 while compressing the same ‗news‘ dataset. On the compression of ‗paper1‘ dataset, it is clear that that presented bLZW model attains a CR of 0.43. Then, the b64pack model achieves a CR of 0.45 during the compression of ‗paper1‘ dataset. At the same time, the FPH2 also attains compression by attaining the CR of 0.46. Besides, the FPHuffman model achieves CR of 0.47 while compressing the same ‗paper1‘ dataset. On the whole, the presented model achieves better CR with minimum values of 0.41, 0.42, 0.42, 0.41 and 0.43 on the applied ‗bib, book1, book2, news and paper1‘ dataset respectively.
Fig. 2. Compression performance analysis with respect to CR
0 0.1 0.2 0.3 0.4 0.5 0.6
bib book1 book2 news paper1
CR
4016
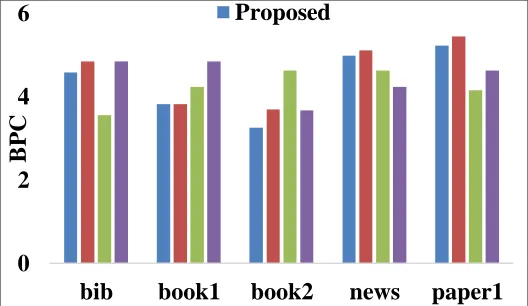
Table 5 and Fig. 3 provide a details compression performance analysis of diverse methods with respect to BPC. By looking into the table, it is clear that that presented bLZW model attains a BPC of 4.58 while compressing the ‗bib‘ dataset which is larger in size. The b64pack model achieves a BPC of 4.84 during the compression of ‗bib‘ dataset. At the same time, the FPH2 also attains identical compression by attaining the same BPC of 4.84. Besides, the FPHuffman model achieves BPC of 3.55 while compressing the same ‗bib‘ dataset. On the compression of ‗book1‘ dataset, it is clear that that presented bLZW model attains a BPC of 3.82. Then, the b64pack model achieves a BPC of 3.82 during the compression of ‗book1‘ dataset. At the same time, the FPH2 also attains compression by attaining the same BPC of 4.84. Besides, the FPHuffman model achieves BPC of 4.24 while compressing the same ‗book1‘ dataset. Similarly, on the compression of ‗book2‘ dataset, it is clear that that presented bLZW model attains a BPC of 3.25. Then, the b64pack model achieves a BPC of 3.69 during the compression of ‗book2‘ dataset. At the same time, the FPH2 also attains compression by attaining the same BPC of 3.67. Besides, the FPHuffman model achieves BPC of 4.63 while compressing the same ‗book2‘ dataset.
Table 5 Compression performance analysis with respect to BPC
Dataset
bits per character (bpc)
Proposed b64pack FPHuffman FPH2
bib 4.58 4.84 3.55 4.84
book1 3.82 3.82 4.24 4.84
book2 3.25 3.69 4.63 3.67
news 4.98 5.11 4.63 4.24
paper1 5.23 5.44 4.15 4.63
On the compression of ‗news‘ dataset, it is clear that that presented bLZW model attains a BPC of 4.98. Then, the b64pack model achieves a BPC of 5.11 during the compression of ‗news‘ dataset. At the same time, the FPH2 also attains compression by attaining the same BPC of 4.24. Besides, the FPHuffman model achieves BPC of 4.63 while compressing the same ‗news‘ dataset. On the compression of ‗paper1‘ dataset, it is clear that that presented bLZW model attains a BPC of 5.23. Then, the b64pack model achieves a BPC of 5.44 during the compression of ‗paper1‘ dataset. At the same time, the FPH2 also attains compression by attaining the BPC of 4.63. Besides, the FPHuffman model achieves BPC of 4.15 while compressing the same ‗paper1‘ dataset. On the whole, the presented method achieves better BPC with a minimum of 4.58, 3.82, 3.25, 4.98 and 5.23 on the applied ‗bib, book1, book2, news and paper1‘ dataset respectively. Table 6 and Fig. 4 provide a details compression performance analysis of diverse methods with respect to CT. By looking into the table, it is clear that that presented bLZW model attains a CT of 1123ms while compressing the ‗bib‘ dataset which is larger in size.
Fig. 3. Compression performance analysis with respect to BPC
The b64pack model achieves a CT of 1200ms during the compression of ‗bib‘ dataset. At the same time, the FPH2 also attains identical compression by attaining the same CT of 1111ms. Besides, the FPHuffman model achieves CT of 1263ms while compressing the same ‗bib‘ dataset. On the compression of ‗book1‘ dataset, it is clear that that presented bLZW model attains a CT of 22763ms. Then, the b64pack model achieves a CT of 23455ms during the compression of ‗book1‘ dataset. At the same time, the FPH2 also attains compression by attaining the same CT of 23366ms. Besides, the FPHuffman model achieves CT of 23518ms while compressing the same ‗book1‘ dataset.
Table 6 Compression performance analysis with respect to CT
Dataset Compression Time (CT)
Proposed b64pack FPHuffman FPH2
bib 1123 1200 1263 1111
book1 22763 23455 23518 23366
book2 14278 15666 15729 15577
news 3298 3457 3520 3368
paper1 1197 1290 1353 1201
Similarly, on the compression of ‗book2‘ dataset, it is clear that that presented bLZW model attains a CT of 14278ms. Then, the b64pack model achieves a CT of 15666ms during the compression of ‗book2‘ dataset. At the same time, the FPH2 also attains compression by attaining the same CT of 15577ms. Besides, the FPHuffman model achieves CT of 15729ms while compressing the same ‗book2‘ dataset. On the compression of ‗news‘ dataset, it is clear that that presented bLZW model attains a CT of 3298ms. Then, the b64pack model achieves a CT of 3457ms during the compression of ‗news‘ dataset. At the same time, the FPH2 also attains compression by attaining the same CT of 3368ms. Besides, the FPHuffman model achieves CT of 3520ms while compressing the same ‗news‘ dataset.
0
2
4
6
bib
book1
book2
news
paper1
B
P
C
Fig. 4. Compression performance analysis with respect to CT
On the compression of ‗paper1‘ dataset, it is clear that that presented bLZW model attains a CT of 1197ms. Then, the b64pack model achieves a CT of 1290ms during the compression of ‗paper1‘ dataset. At the same time, the FPH2 also attains compression by attaining the CT of 1201ms. Besides, the FPHuffman model achieves CT of 1353ms while compressing the same ‗paper1‘ dataset. On the whole, the presented method achieves better CT with a minimum of 1123ms, 22763ms, 14278ms, 3298ms and 1197ms on the applied ‗bib, book1, book2, news and paper1‘ dataset respectively.
3
CONCLUSION
The major aim of DC is the minimization of actual data size as well as memory utilization and maximization of transfer rate. Presently many text compression models are designed using dictionaries. In this paper, a new efficient and fast compression technique is developed to compress text files. By incorporating a b64pack and LZW coding techniques, a new bLZW model is introduced here. The bLZW model operates in a set of three phases: Initially, it transforms the input text into a format which could undergo compression. At the next stage, a conversion of the message takes place to reduce the file size. Finally, LZW algorithm is applied to further reduce the compressed file size. This bLZW model is experimented using a set of benchmark text files. The experimental outcome indicated that the presented model outperforms the other methods under diverse dimensions.
REFERENCES
[1] Uthayakumar, J., Vengattaraman, T. and Dhavachelvan, P., 2018. A survey on data compression techniques: From the perspective of data quality, coding schemes, data type and applications. Journal of King Saud University-Computer and Information Sciences.
[2] Uthayakumar, J., Vengattaraman, T. and Dhavachelvan, P., 2019. A new lossless neighborhood indexing sequence (NIS) algorithm for data compression in wireless sensor
[3] Al-Bahadili and S. M. Hussain, ―An adaptive character wordlength algorithm for data compression,‖ Computers and Mathematics with Applications, vol. 55, no. 6, pp. 1250–1256, 2008.
[4] J. Dvorskþ, J. Pokornþ, and J. Snásel, ―Word-based compression methods and indexing for text retrieval systems,‖ in Proceedings of the 3rd East European Conference on Advances in Databases and Information Systems (ADBIS '99), pp. 75–84, Maribor, Slovenia, 1999. [5] J. Platos and J. Dvorskþ, ―Word-based text compression,‖
CoRR abs /0804.3680, 2008.
[6] Akman, H. Bayindir, S. Ozleme, Z. Akin, and S. Misra, ―A lossless text compression technique using syllable based morphology,‖ The International Arab Journal of Information Technology, vol. 8, no. 1, pp. 66–74, 2011.
[7] T. Kuthan and J. Lansky, ―Genetic algorithms in syllable-based text compression,‖ in Proceedings of the Dateso Annual International Workshop on Databases, Texts, Specifications and Objects, Desna, Czech Republic, April 2007.
[8] J. Lansky and M. Zemlicka, ―Text compression: syllables,‖ in Proceedings of the Dateso Annual International Workshop on Databases, Texts, Specifications and Objects, pp. 32–45, Desna, Czech Republic, April 2005. [9] J. Lansky and M. Zemlicka, ―Compression of small text
files using syllables,‖ in Proceedings of the Data Compression Conference, Snowbird, Utah, USA, March 2006.
[10]J. Platoš, V. Snášel, and E. El-Qawasmeh, ―Compression of small text files,‖ Advanced Engineering Informatics, vol. 22, no. 3, pp. 410–417, 2008.
[11]: Kenan Kalajdzic, Ahmed Patel, Samaher Hussein Ali, Rapid Lossless Compression of Short Text Messages, Computer Standards & Interfaces (2014), doi: 10.1016/j.csi.2014.05.00
[12]Witten, I.H. and Bell, T., 1990. The Calgary/Canterbury text compression corpus. Anonymous ftp from ftp. cpsc. ucalgary. ca:/pub/text. compression. corpus/text. compression. corpus. tar. Z.
bib book1 book2 news paper1
Proposed 1123 22763 14278 3298 1197
b64pack 1200 23455 15666 3457 1290
FPHuffman 1263 23518 15729 3520 1353
FPH2 1111 23366 15577 3368 1201
0 5000 10000 15000 20000 25000
Co
m
p
u
tat
io
n
T
im