Feature Reduction using Principal Component
Analysis for Effective Anomaly–Based
Intrusion Detection on NSL-KDD
Shilpa lakhina1, Sini Joseph2 and Bhupendra verma3
1
PG Research Scholar Department of Computer Science and Engineering, TIT, Bhopal (M.P.)
2
Assistant Professor in Computer Science and Engineering, TIT, Bhopal (M.P.),
3
Professors in Computer Science and Engineering, TIT, Bhopal (M.P.),
Abstract: Attacks on the network infrastructure presently are main threats against network and information security. Most of the existing IDs use all 41 features in the network to evaluate and look for intrusive pattern
some of these features are redundant and irrelevant. The drawback of this approach is time-consuming
detection process and degrading the performance of ID system. In this paper a new hybrid algorithm
PCANNA (principal component analysis neural network algorithm) is used to reduce the number of
computer resources, both memory and CPU time required to detect attack. The PCA (principal component
analysis) transform used to reduce the feature and trained neural network is used to identify the any kinds of
new attacks. Test and comparison are done on NSL-KDD dataset. It is a new version of KDDcup99 and has
some advantages over KDDcup99, the experiments with NSL-KDD data demonstrate that our proposed
model gives better and robust representation of data as it was able to reduce features resulting in a 80.4%
data reduction, approximately 40% reduction in training time and 70% reduction in testing time is achieved.
Our proposed method not only reduces the number of the input features and time but also increases the
classification accuracy. The result indicates the superiority of algorithm.
Keywords: Principal component analysis, dimensionality reduction, neural network, NSL-KDD. 1. Introduction
Intrusion detection is the process of monitoring the events occurring in a computer system or network and analyzing them for signs of intrusion [1]. Intrusions are defined as attempts to compromise the confidentiality, integrity or availability of computer or network. They are caused by attackers accessing a system from the internet, by authorized User of the systems who attempt to gain additional privileges for which they are not authorized and by authorized user who misuse the privileges given to them [9]. Anomaly detection and misuse detection [11] are two general approaches to computer intrusion detection system. Unlike misuse detection, which generates an alarm when a known attack signature is matched, anomaly detection identifies activities that deviate from the normal behavior of the monitored system and thus has the potential to detect novel attacks [14].
detection evaluation [8]. The training dataset of NSL-KDD similar to KDD99 consist of approximately 4,900,000 single connection vectors each of which contains 41 features and is labeled as either normal or attack type ,with exactly one specific attack type . Empirical studies indicate that feature reduction technique is capable of reducing the size of dataset. The time and space complexities of most classifiers used are exponential function of their input vector size [15]. Moreover, the demand for the number of samples for the training the classifier grows exponentially with the dimension of the feature space. This limitation is called the ‘curse of dimensionality’.
In this work we aim to filter out redundant information and significantly reduce number of computer resources, both memory and CPU time required to detect attacks. This paper suggest Principal component analysis (PCA) as a reduction tool and back propagation algorithm as a learning tool for the developed system, firstly we reduce the features and then apply the learning algorithm. Neural network will help to identify the unknown attacks [7]. This paper organized as follows, in the second section we give an introduction to NSL-KDD dataset, section three gives the introduction IDs, section four give information about techniques of feature extraction, section fifth explains the proposed algorithm, section sixth gives a brief introduction to principal component analysis, section seventh shows the experimental result finally in section eight conclusion is shown.
2. Introduction of NSL-KDD:
KDDCUP’99 is the mostly widely used data set for the anomaly detection. But researchers conducted a statistical Analysis on this data set and found two important issues which highly affects the performance of evaluated systems, and results in a very poor evaluation of anomaly detection approaches. To solve these issues, they have proposed a new data set, NSL-KDD, which consists of selected records of the complete KDD data set [5].
The following are the advantages of NSL-KDD over the original KDD data set:
It does not include redundant records in the train set, so the classifiers will not be biased towards more frequent records.
The number of selected records from each difficulty level group is inversely proportional to the percentage of records in the original KDD data set. As a result, the classification rates of distinct machine learning methods vary in a wider range, which makes it more efficient to have an accurate evaluation of different learning techniques. The numbers of records in the train and test sets are reasonable, which makes it affordable to run the experiments
on the complete set without the need to randomly select a small portion. Consequently, evaluation results of different research works will be consistent and comparable.
3. Intrusion detection System Model
During a certain attacks, an attacker sets up a connection between a source IP address to a target IP, and sends data to attack the target. The simulated attacks fall in one of the Following four categories [3]:
(i) Denial of Service Attack (DoS): is an attack in which the attacker makes some computing or memory resource too busy or too full to handle legitimate requests, or denies legitimate users access to a machine. For example: ping of death and SYN flood.
(iii) Remote to Local Attack (R2L): occurs when an attacker who has the ability to send packets to a machine over a network but who does not have an account on that machine exploits some vulnerability to gain local access as a user of that machine. For example: password guessing.
(iv) Probing Attack: is an attempt to gather information about a network and find the system’s known vulnerabilities.
These vulnerabilities will be exploited to attack the system. For example: Port scanning. 3.1 Network Data Feature Label
Table 1: Basic features of individual TCP connection
Label Network Data Features
A Duration
B protocol_type
C Service
D flag
E src_bytes
F dst_bytes
G land
H wrong fragment
I urgent
Table 2: Content features within a connection suggested by domain knowledge
Label Network Data Features
J Hot
K num_failed_logins
L logged_in
M num_compromised
N root_shell
O su_attempted
P num_root
Q num_file_creations
R num_shells
S num_access_files
T num_outbounds_cmds
U is_hot_login
Table 3: Traffic features computed using a two-second
Label Network Data Features
W Count
X sev_count
Y serror_rate Z sev_serror_rate AA rerror_rate BB srv_rerror_rate AC same_srv_rate AD diff_srv_rate AE srv_diff_host_rate AF Dst_host_count AG Dst_host_srv_count AH Dst_host_same_srv_rate AI Dst_host_diff_srv_rate AJ Dst_host_same_src_port_rate AK Dst_host_srv_diff_host_rate AL Dst_host_server_rate AM Dst_host_srv_serror_rate AN Dst_host_rerror_rate AO Dst_host_srv_rerror_rate
Table 1, Table 2 and Table 3 show all the features found in a connection. For easier referencing, each feature is assigned a label (A to AO).some of the features.
4. Techniques of Feature Reduction:
examples of infrequent classes tend to be easily removed as a result of dimensionality reduction making use of the class distribution.
5. Proposed Algorithm:
In this paper a new hybrid algorithm PCANNA (Principal component analysis Neural Network algorithm) is proposed to reduce the dimension of dataset required to detect attacks. Feature reduction process can be viewed as a preprocessing step which removes distracting variance from a dataset, so that classifiers can perform better. In our proposed algorithm PCA transform used for dimensionality reduction which is commonly used step, especially when dealing with high dimensional space of features. PCA-based approaches improve system performances and a trained artificial neural network to identify any unknown attacks.
Following are the steps used in our algorithm 1. Data Preprocessing
Normalization is used for data preprocessing, where the attribute data are scaled so as to fall within a small specified range such as -1.0 to 1.0 or 0.0 to 1.0. If using neural network back propagation algorithm for classification, normalizing the input values for each attribute measured in the training samples will help speed up the learning phase.
2. Dimensionality reduction
Principal component Analysis (PCA) is used for dimensionality reduction. The goal of PCA is to reduce the dimensionality of the data while retaining as much as possible of the variation present in the original dataset.
3. Classification Using Back-Propagation Algorithm
Back-propagation algorithm is used for classification of attack classes as is capable of making multi-class classification.
6. Principal component analysis
PCA is a useful statistical technique that has found application in fields such as face recognition and image compression, and is a common technique for finding patterns in data of high dimension. The entire subject of statistics is based on around the idea that you have this big set of data, and you want to analyze that set terms of the relationships between the individual points in that set [4].
The goal of PCA is to reduce the dimensionality of the data while retaining as much as possible of the variation present in the original dataset. It is a way of identifying patterns in data, and expressing the data in such a way as to highlight their similarities and differences[6].
Algorithm:
Suppose , , … are N 1 vectors Step 1: ∑
Step 3: From the matrix … (N *M matrix), then compute: ∑ AAT
(Sample covariance matrix, N*N, characterizes the scatter of the data) Step 4: Compute the eigenvalues of : Step 5: Compute the eigenvectors of : , , …
Since C is symmetric, , , … form a basis, (i.e., any vector x oractually ), can be written as a linear combination of the eigenvectors):
Step 6: (dimensionality reduction step) keep only the terms corresponding to the K largest eigen values: ∑
How to choose the principal components?
- To choose K, use the following criterion ∑∑ > Threshold (e.g., 0.9 or 0.95 )
7. Experimental setup and Results:
We used java programming for implementation. Feed forward back propagation neural network algorithm has been developed for training process.
The network has to discriminate the different kinds of anomaly –based intrusions. We used 11850 training sample, 9652 sets of test samples with 41featuers of data set. After Feature, reduction 41 features are reduced to 8 features. First training and testing is applied on all 41 features and the results of classification are calculated. After that training and test is done with reduced features and the results of, classification is calculated.
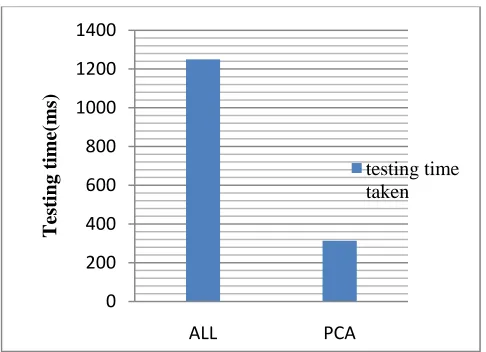
The various results of our experiments are given below. we show the results of our experiment by taking different input values such as in table 4 we have taken 9642 test sample and 11850 training samples, 200 steps to train the network, 25 hidden layers, learning rate 0.5, momentum is 1, results of table 4 shows the classification in 5 classes (Normal, DOS , Probe ,U2R , R2L). We can see from this table the accuracy achieved before and after the features reduction, the training time is reduced by 40%, testing time is reduced to 78.5 %.
Before features reduction
(With all 41 features
)
After features reduction
(with 8 features)
Original record
Normal 5702 5489 5551
DOS 2137 2174 2141
Probe 780 989 902
U2R 9 0 30
Training time taken
67906 ms 40688 ms Testing time
taken
1234 ms 265 ms
Table 4. Experimental results before and after feature selection: (Training steps=200, hidden layer=25)
Figure 1. Comparison of number of detections before and after feature reduction (Hidden Layers=25 and Max Steps for Training taken =200)
Figure 2. Training Time Before and after Reduction
0 1000 2000 3000 4000 5000 6000
Number of
detections
Attack classes ANN Classifer
41 features 8 features target results
0 10000 20000 30000 40000 50000 60000 70000 80000
ALL PCA
Training time
taken(ms)
Figure 3. Testing Time Before and after Reduction
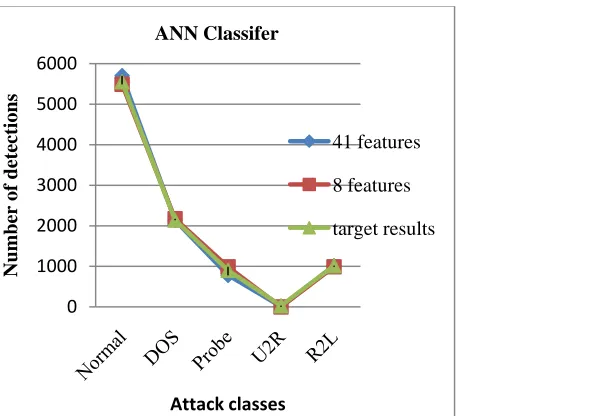
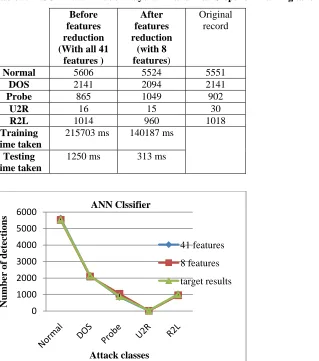
The results of next table is calculated by taking 11850 samples of training data, 9652 samples of Test data, 700 steps are taken for training of network and 25 hidden layer are taken for optimum results. Results of table 2 show the classification accuracy, reduced training and testing time.
Table 5.RESULT with Hidden Layers=25 and Max Steps for Training taken =700
Before features
reduction (With all 41
features )
After features reduction
(with 8 features)
Original record
Normal 5606 5524 5551
DOS 2141 2094 2141
Probe 865 1049 902
U2R 16 15 30
R2L 1014 960 1018
Training time taken
215703 ms 140187 ms Testing
time taken
1250 ms 313 ms
Figure 4.Comparison of number of detections before and after feature reduction. (Hidden Layers=25 and Max Steps for Training taken =700)
0 200 400 600 800 1000 1200 1400
ALL PCA
Testing
Time
(ms) Testing time
taken
0 1000 2000 3000 4000 5000 6000
Number of
detections
Attack classes ANN Clssifier
Figure 5. Training Time Before and after Reduction
Figure 6. Testing Time Before and after Reduction
8. Conclusion:
Our research work based on Intrusion detection system, we found that Most of the existing IDs use all 41 features in the network to evaluate and look for intrusive pattern some of these features are redundant and irrelevant. The drawback of this approach is time-consuming detection process and degrading the performance of ID system. To solve this problem we proposed an algorithm PCANNA (Principal Component Analysis Neural Network Algorithm) uses Principal Component Analysis as a Features reduction algorithm. The goal of PCA is to reduce the dimensionality of the data while retaining as much as possible of the variation present in the original dataset and trained artificial neural network to identify any kind of new attacks .Tests and comparison are done on NSL-KDD dataset an improved version of KDD-99. The test data contains 4 kinds of different attacks in addition to normal system call.
Our experimental results showed that the proposed model gives better and robust representation of data as it was able to reduce features resulting in a 80.4% data reduction and approximately 35%-40% reduction in testing time and 75%-80% reduction in testing time ,classification accuracy achieved in detecting new attacks. Meantime it
0 50000 100000 150000 200000 250000
ALL PCA
Training Time
(ms) Training time
taken
0 200 400 600 800 1000 1200 1400
ALL PCA
Testing time(ms)
significantly reduce a number of computer resources, both memory and CPU time, required to detect an attack. This shows that our proposed algorithm is reliable in intrusion detection.
References
[1] Sundaram, A., An Introduction to Intrusion Detection, Crossroads: The ACM student magazine, 2(4), 1996.
[2] The NSL-KDD Data Set.html.
[3] Neveen I. Ghali Faculty of Science, Al-Azhar University - Egypt Feature Selection for Effective Anomaly-Based Intrusion Detection
IJCSNS International Journal of Computer Science and Network Security, VOL.9 No.3, March 2009
[4] Lindsay I Smith A tutorial on Principal Components Analysis February 26,2002.
[5] Mahbod Tavallaee, Ebrahim Bagheri, Wei Lu, and Ali A. Ghorbani A Detailed Analysis of the KDD CUP 99 Data Set proceeding of
the 2009 IEEE symposium on computational Intelligence in security and defence application.
[6] S. Gong et al., Dynamic Vision: From Images to Face Recognition, Imperial College Press, 2001 (pp. 168-173 and Appendix C:
Mathematical Details, hard copy)
[7] Srinoy, S., Kurutach, W. Chimphlee, W. Chimphilee, S., Network Anomaly Detection Using Soft computing, Proceedings of World
Academy of Science, Engg. and Technology, vol. 9, pp.140-144, 2005.
[8] KDD Cup 1999. Available on http://kdd.ics.uci.edu/ Databases/kddcup 99/kddcup99.html, Ocotber 2007.
[9] M. Shyu, S. Chen, K. Sarinnapakorn, and L. Chang, “A novel anomaly detection scheme based on principal component classifier,
“Proceedings of the IEEE Foundations and New Directions of Data Mining Workshop, in conjunction with the Third IEEE International conference on Data Mining (ICDM03), pp. 172–179, 2003.
[10] Yuebin bai, hidetsune kobayashi,nihon university,beihang university ,intrusion detection systems: technology and development
Proceedings of the17th International Conference on Advanced information networking and applications (AINA’03) 2003 IEEE.
[11] F.sabahi, IEEE member, A.movaghar, IEEE senior member school of computer engg. intrusion detection: A survey, the third
international conference on systems and network communications.
[12] Gopi K. Kuchimanchi,Vir V. Phoha, Kiran S.Balagani, Shekhar R.Gaddam, Dimension Reduction Using Feature Extraction Methods for
Real-time Misuse Detection Systems, Proceedings of the IEEE on Information, 2004.
[13] Anil K. Jain,Robert P.W. Duin, and Jianchang Mao,“Statistical Pattern Recognition” IEEE transactions on pattern analysis and machine
intelligence, VOL. 22, NO. 1,January 2000.
[14] H. Debar etal. “Towards a taxonomy of intrusion detection systems” Computer Network,pp.805-822, April1999.
[15] R.O.Duda,P.E.Hart, and D.G.Stork, Pattern Classification, vol. 1. New York: Wiley, 2002.
[16] “Principles of Soft Computing”, a book by Dr. S.N. Sivanandam, S,N.Deepa, wiley Publication first Indian edition,2008.
[17] I.T. Jolliffe, “Principal Component Analysis” Springer-Verlag, 1986.
[18] K. Fukunaga. “Introduction to Statistical Pattern Recognition” Academic Press Professional, Inc., San Diego, CA, USA,1990.