International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 3, March 2018)270
Generation of Optimized B+ Tree Text Index using
Genetic Algorithm
Bhagatsingh D. Jitkar
1, Dr. S. D. Raut
21
PhD, Research Scholar, Shivaji University, Kolhapur, Maharashtra, India
2
Professor, Orchid COE, Solapur, Maharashtra, India
Abstract—The amount of data generated increases day by
day with unprecedented scale. In order to process such huge data an effective query mechanism needs to be developed. So, indexing plays a vital role in the query processing. Finding a proper indexing technique for efficient performance is a major challenge. In this paper, the optimized B+ tree index has been designed and developed based on the semantics of keyword and genetic algorithm. The semantic analysis is done by checking it with WordNet dictionary. The AES encryption technique has been used for maintain the secrecy of data present in the node. The result analysis has been made based on the different parameters which gives better result than the B+ tree index.
Keywords— Information Retrieval Systems, indexing, B+-tree, genetic algorithm, Semantic analysis, text pre-processing, AES encryption
I. INTRODUCTION
The very large modern text databases are commonly used to store the very large volume of the documents from various sources such as social media, research papers, news articles, e-books, digitals libraries, web pages, emails etc. These databases play an important role in the people daily life-style and working culture of different organizations. Therefore, to organize such huge data in efficient way there is a need of information retrieval indix mechanisms. The Information retrieval system includes different indexing techniques. The suitability of such technique is dependent upon the scalability of data, search performance and security of data stored in the nodes of the indices. The text or keyword indexing is based on the natural language processing of document to get the index nodes. The searching is a process in which the data keyword can be looked into the document stored into the database. The data collected from various sources are usually incomplete, inconsistent and noisy which leads errors and discrepancies in the codes. Text preprocessing has been applied on such data to remove all incomplete and noisy data [9]. The semantic analysis can be used before constructing the index.
It is the study of meaning of words which concentrates on the relation between words, phrases and symbols. Semantic knowledge can add a power and accuracy to indexing. Processing of the semantic disambiguation of words with multiple senses is also included in semantic analysis. WordNet dictionary is a most used semantic network, which is organized in such a way that synset and word senses are treated as nodes of the network, and relations among the synset and word senses are the edges of the network. It includes meaning of each word as word sense of the word, and a synset (i. e. synonym). B+ tree indexing technique is the most efficient technique used for the text indexing. The work presented in this paper includes optimized construction of B+ tree index. The semantic analysis has been performed before indexing for getting the accuracy in the result. Further it can be optimized by applying the genetic algorithm.
II. LITERATURE REVIEW
The aim of indexing is to improve the query performance of the system. Therefore indexing plays a vital role in processing of massive amount of datasets. The indexes are divided into full-text which operate on the whole input text and can answer arbitrary queries and keyword indexes which store a dictionary of individual words. There are many indexing techniques designed and developed by different authors in the literature.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 3, March 2018)271 Using semantic analysis [6] relevant information is not missed if exact keyword is not specified and the word information which is semantically related with keyword can be retrieved. In paper [5], author proposes the semantic relationship of the text by using the WordNet. Semantic similarity plays an important role in natural language processing, text summarization, information retrieval, text categorization, text clustering and so on. The similarity measures have been proposed based on the semantic relationship between synsets. It also proposes the lexical chain which is a sequence of related words that give important clues about the semantic of the text, thus allows identification of the topic of document. In iDistance[12], the new technique based on B+ tree for searching has been presented. First partition the data and then define the reference points for each data partition. The index has been constructed based on the distance of each data point to the reference point of the partition. In the distributed data management, the indexing technique plays an important role. It is also an essential part of the cloud computing. But current clouds use hash based approach for simple keyword searching inside storage of data which is not suitable. So, in this [4] paper author proposes a novel approach which combines Skipnet and B+ index to form the SNB-index which is two layer architecture where, at lower level B+ index is used for constructing the local index and at the higher level, skipnet has been designed. In paper [8], FAT file system has been modified by using the B+ tree index technique. It is used to increase the speed. It minimizes the number of disk accesses. Secure index has been constructed for preserving the privacy by encrypting the index by using the AES encryption algorithm. In paper [13], the B+ tree index nodes has been encrypted for maintaining the data privacy when data is stored on the different third party servers. The basic operations like insert, delete, update has been modified to maintain the data privacy and hiding the relation patterns from the third party users. The genetic algorithm [12] has been used for increasing speed and reducing the cost of computation while indexing. The genetic algorithm uses the different steps as initial population, fitness function, and applying the operator for improving the indexing. In this paper [3] new fitness function has been applied on the populated data. The results of this new fitness function are compared with the cosine fitness function and classical IR.
From the above literature survey it has been observed that many indexing techniques have been used for text indexing and retrieval.
The B+ indexing technique has been widely used in many papers for efficient retrieval of text data. The privacy has been maintained by using the encryption technique.
The semantic analysis has been used for eliminating unwanted keywords. The B+ tree are optimized by using the genetic algorithm. The proposed novel approach incorporates all these technique to design and develop the efficient text indexing technique.
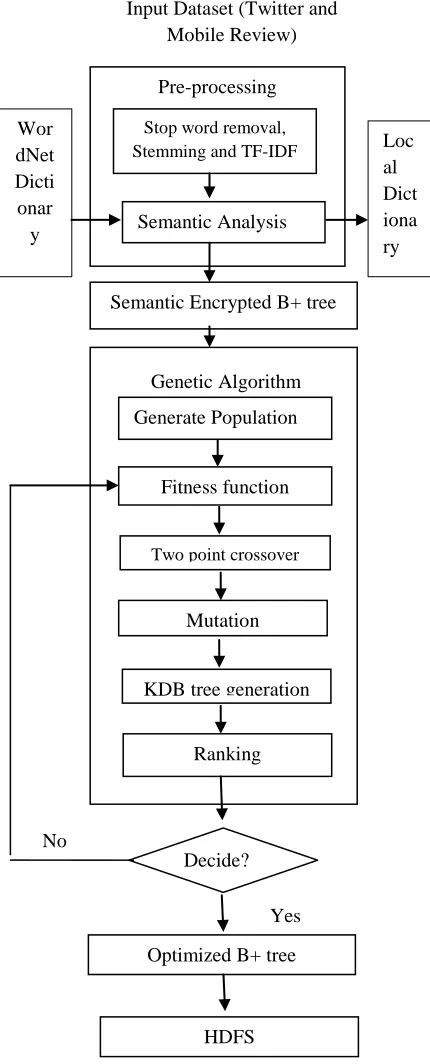
III. SYSTEM ARCHITECTURE
The work presented in this paper is focused on the design and development of efficient text indexing technique as shown in fig. 1. The input dataset like twitter, Mobile review etc. are passed to the preprocessing stage for removing stop words, stemming and calculating the term frequency. The semantic analysis has been performed for the keywords using WordNet Dictionary. If semantic is found then it has been stored inside the local directory for future search. The keywords are represented by using B+ tree index and are encrypted using AES encryption algorithm to form the encrypted B+ tree. The genetic algorithm has been applied on the encrypted B+ tree for doing optimization and reducing cost.
The design and development of new optimized B+ tree index for text by using semantic and genetic algorithm has been divided into different modules as –
1. Preprocessing –
The preprocessing of the text [10] is called text normalization. The dataset of twitter or mobile review has been taken as input for preprocessing. The keywords are extracted from the dataset before constructing the tree structure by using the preprocessing stage. It includes following steps as –
a) Stop word removal –
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 3, March 2018) [image:3.612.55.270.153.685.2]272 Fig. 1 System architecture for Text indexing
document because these words are not treated as the keywords in the text processing. The benefit of the stop word removal is that it reduces the size of indexing structure. In our work the google‟s stop word list [14] has been referred.
b) Stemming
The stemming has been performed for removing the suffixes from the word. Stemming is useful operation in the Information retrieval. In the information retrieval system the document is represented by the list of terms or the keyword. The terms or keywords with common stem usually have similar meaning. For example, the word „connect‟ can be inflected with morphological suffix to produce „connected, connection, connecting, connections‟. So, removal of various suffixes –ED, -ION, -ING, -S will improve the performance of the information retrieval system. The following points are taken into consideration while performing the stemming operation as –
Those words which have different meaning should be kept separate.
Morphological forms of a term are assumed to have the same base meaning and hence it should be mapped to the same stem.
Many algorithms are used for the stemming like porter, Lovins, Krovetz‟s etc.. In our work, Porters stemming algorithm has been used for stemming. It is the popular and mostly used stemming algorithm. It uses the 6 rules for stemming to remove the suffixes [15][16].
c) TF-IDF calculation –
By using the stop word removal and stemming operation, the keywords are extracted from the input dataset. Further the importance of each word has been taken into consideration by calculating the IDF of each term. TF-IDF stands for Term Frequency-Inverse Document Frequency, and the TF-IDF weight is often used in information retrieval and text mining. This is used to evaluate the importance of the word to the document in a dataset. The importance increases as the number of times the word appeared in the document. The term frequency measures how frequently a keyword/term occurs in a document. Since every document having different length, it may be possible that a term would appear much more times in long documents than shorter ones. So, the term frequency is often divided by the document length i.e. the total number of terms in the document. It is calculated by using following formula as
Pre-processing
Semantic Analysis
Semantic Encrypted B+ tree Wor
dNet Dicti onar y
Fitness function Genetic Algorithm
Two point crossover
Mutation
KDB tree generation
Ranking Generate Population
Decide?
Optimized B+ tree
HDFS Yes No
Input Dataset (Twitter and Mobile Review)
Stop word removal,
Stemming and TF-IDF Loc
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 3, March 2018)273
Number of times term t appears in a document TF t
Total number of terms in the document
Inverse Document Frequency measure how important a term is. The IDF has been calculated by using following formula as
logTotal number of documents IDF t
Number of documents with term t in it
So, TF-IDF is calculating by multiplying the TF with IDF as –
*
TFIDFTF IDF
The pseudo code for TF/IDF calculation is shown in fig 2 as follows –
Count the number of times the keyword appeared in the document
Calculate the number of keyword in the document Calculate the TF weight and store it
Calculate the total number of documents
Calculate the number of documents with keyword in it Determine IDF
if IDF == zero then
Remove the word from the WordList Remove the corresponding TF from the WM Else
Calculate TF-IDF and store normalized TF/IDF in the corresponding element of the weight matrix.
Fig. 2 Pseudo code of TF-IDF calculation
d) Semantic analysis –
The semantic of the keyword is found in the WordNet dictionary. WordNet [19] is one of the large lexical databases of English. It includes nouns, verbs, adjectives and adverbs which are grouped into sets of synonyms (synsets). In WordNet, each meaning of a word is represented by a unique word sense of the word, and a synset is consisting of a group of word senses sharing the same meaning. WordNet has been commonly used to measure semantic similarity among words. Synsets are interlinked by means of conceptual-semantic and lexical relations. The resulting network of meaningfully related words and concepts can be navigated with the browser. WordNet is also freely and publicly available for download. WordNet structure makes it a useful tool for computational linguistics and natural language processing.
Once the semantic is found in the WordNet dictionary it is stored in a local dictionary, so that whenever same keyword is to be searched, instead of referring WordNet dictionary the user can directly search the semantic of the keyword in the local dictionary. This improves the speed of searching.
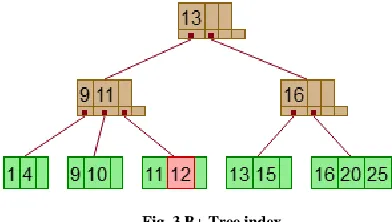
2. Semantic B+ tree generation –
The keywords are extracted from input dataset and calculating the importance of these keywords by using TF-IDF and applying the semantic analysis over them. These keywords are used as input to construct B+ tree. The generated tree is also called as semantic B+ tree. For hash index the frequency of index values may be revealed, and for B tree index may not preserved the order after encryption of nodes. So, for removing above drawbacks the B+ tree index has been used. The leaf nodes of B+ trees are linked, so doing a full scan of all objects in a tree requires just one linear pass through all the leaf nodes as shown in fig. 3.
Fig. 3 B+ Tree index
3. Semantic encrypted B+ tree generation –
[image:4.612.338.534.380.491.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 3, March 2018)274 AES uses 10 rounds for 128-bit keys. Each of these rounds uses a different 128-bit round key, which is calculated from the original AES key. The encrypted B+ tree has been used to create a Semantic encrypted B+ tree. Whenever a user has some keyword to search, its semantic will be considered for searching.
3. Optimized B+ tree –
The semantic encrypted B+ tree further optimized to increase the efficiency of the indexing and to increase the speed of searching by applying the genetic algorithm. In a genetic algorithm, a population of candidate solutions (called individuals, creatures, or phenotypes) to an optimization problem is evolved towards better solutions. Each candidate solution has a set of properties (its chromosomes or genotype) which can be mutated and altered; traditionally, solutions are represented in binary as strings of 0s and 1s, but other encodings are also possible. The genetic algorithm starts with set of individuals called population. This population evolves into different populations for several iterations. In each generation, for predefined probability the offspring are produced by using crossover for the population and with very low probability these offsprings are modified by using mutation.
The genetic algorithm contains the following steps as – a) Initial population –
The initial population in GA is generated randomly by using pseudo-random number generator. The tree balancing is done by order_key array of n size individual. The total individuals are determined by the pre-decided population size.
b) Fitness function –
Fitness of individual is a quality measure for adaption of environment and it is calculated by using fitness function. A fitness function simply defined as a function which takes the solution as input and produces the suitability of the solution as the output. In some cases, the fitness function and the objective function may be the same, while in others it might be different based on the problem. The fitness function is used to evaluate the current population to produce quality solutions for minimizing the memory tree and height of tree. In genetic algorithm our goal is to find the individuals with highest fitness value which is best suited for environment.
c) Two-point crossover –
Crossover is the main genetic operator. The core purpose of crossover operator is to exchange information between parents to produce better offspring‟s. Two break points are chosen with every second section to be swapped.
Two-point crossover is implemented for the task-assignment string by selecting two parents from the current population and by selecting two random points from the keys. Fig 4 shows the example of the two-point crossover.
Parent 1 10 12 5 8 34 21 2 Parent 2 12 21 8 5 10 2 34
a) Before two-point crossover
Random point: 3, 5
Parent 1 10 12 8 5 10 21 2 Parent 2 12 21 5 8 34 2 34
b) After two-point crossover
Fig. 4 Two-point crossover
d) Mutation –
After the crossover operation, the individuals perform for mutation operation. Mutation is a genetic operator used to maintain genetic diversity from one generation of a population to the next and enhance the scheduling process. The mutation operator is applied to a single individual. Mutation occurs during evolution according to a user-definable mutation probability. This probability should be set low. If it is set too high, the search will turn into a primitive random search.
e) KDB-tree generation –
KDB tree has been used for balancing the tree for providing the search efficiency and providing the block oriented storage for optimizing external memory accesses. [20]. The Insertion of the node inside the KDB tree is done by using the following algorithm 1 –
Algorithm 1: insert (key[], value) 1: if root==null
2: insert the node; 3: else
4: if there is space 5: insert into the leaf node 6: else
7: split the node 8: repeat
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 3, March 2018)275 f) Ranking –
Rank Selection also works with negative fitness values and is mostly used when the individuals in the population have very close fitness values. This leads to each individual having an almost equal share of the pie and hence each individual no matter how fit relative to each other has an approximately same probability of getting selected as a parent. This in turn leads to a loss in the selection pressure towards fitter individuals, making the GA to make poor parent selections in such situations. However, every individual in the population is ranked according to their fitness. The selection of the parents depends on the rank of each individual and not the fitness. The higher ranked individuals are preferred more than the lower ranked ones. Fig. 5a), 5b) shows the situation before and after ranking
Fig. 5a) Situation before ranking (graph of fitness)
Fig. 5b) Situation after ranking (graph of order numbers)
If rank generated is above predefined threshold then stop the population process else go to fitness function to repeat the steps again. This optimized semantic B+ tree structure has been given to HDFS (Hadoop Distributed File system).
4. Search by using keywords–
The keywords are searched inside both dataset of Twitter and Mobile review by using optimized semantic B+ tree indexing technique. In our system, user can search by using the keyword, date or using location. The optimized semantic B+ tree index has been generated and is used to
[image:6.612.323.554.166.340.2]retrieve resultant file depending upon the search keyword as shown in fig. 6.
Fig. 6 Search for Keywords inside Mobile review Dataset using optimized B+ tree
IV. EXPERIMENTAL SETUP
[image:6.612.80.262.318.560.2] [image:6.612.80.265.341.462.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 3, March 2018) [image:7.612.322.563.158.521.2]276 So, CDH5 has been installed inside the centOS for executing our system by using netbeans IDE. It uses JAVA as a programming language. The fig. 7 and fig 8 shows the optimized B+ tree generation of twitter and mobile review dataset respectively.
[image:7.612.323.563.195.356.2]Fig. 7 Optimized B+ tree generation for Twitter Dataset
Fig. 8 Optimized B+ tree generation for Mobile Dataset
V. RESULT ANALYSIS
The result analysis has been done on the basis of the different index performance parameters. The B+ tree index, semantic B+ index and the optimized B+ tree index which includes the semantics and genetic algorithm have been compared on the input of Twitter dataset and mobile review dataset. The following are the parameters as –
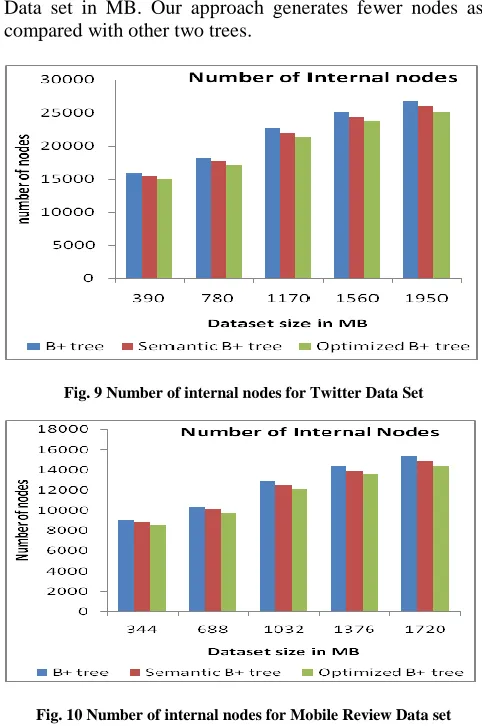
1. Number of Nodes – It includes the comparison between the number of nodes generated and the size of the
[image:7.612.49.278.202.375.2]Data set in MB. Our approach generates fewer nodes as compared with other two trees.
Fig. 9 Number of internal nodes for Twitter Data Set
Fig. 10 Number of internal nodes for Mobile Review Data set 2. Memory –
[image:7.612.50.275.404.584.2]It includes the memory required for indexing and the dataset in MB. Our approach requires less memory compared with other.
[image:7.612.323.559.556.697.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 3, March 2018) [image:8.612.53.286.130.281.2]277 Fig. 12 Memory for Mobile Review Data set
3. Search time –
It is the time required to search the keyword into the tree. It is the graph of dataset in MB and the time in the millisecond. The time required to search inside the optimized B+ tree is very less compared with other two trees.
[image:8.612.321.562.208.445.2]Fig. 13 Search time for Twitter Data Set
Fig. 14 search Time for Mobile Review Data set
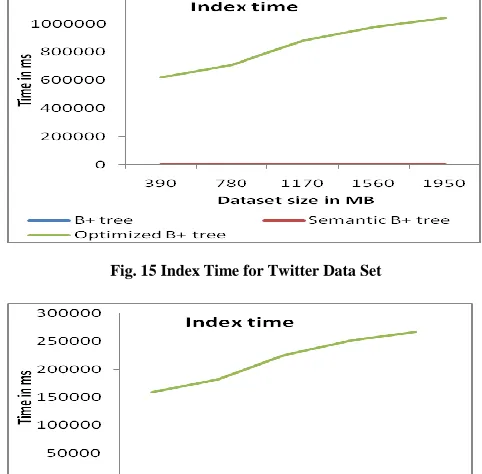
4. Index time –
It is time required to generate the index. The graph shows the time in milliseconds and dataset size in MB. Here our approach required much more time compared with other two trees.
Fig. 15 Index Time for Twitter Data Set
Fig. 16 Index Time for Mobile Review Data set
5. Insertion time –
[image:8.612.320.564.575.695.2]It is the time required to insert the node into the all three types of tree. It grows as the size of the dataset increases. Our approach takes less time to insert any node.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 3, March 2018) [image:9.612.49.285.121.287.2]278 Fig. 18 Insertion Time for Mobile Review Data set
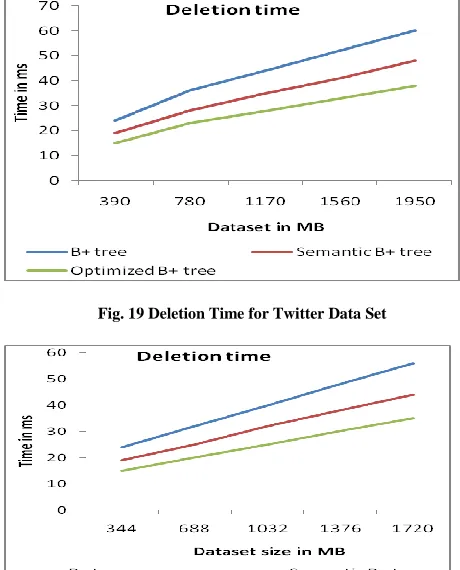
6. Deletion time –
It is time required to delete the node from the B+ tree, semantic B+ tree and Optimized B+ tree. Our approach takes less time for deleting any node from the tree compared with other two.
[image:9.612.47.281.384.529.2][image:9.612.47.277.387.672.2]
Fig. 19 Deletion Time for Twitter Data Set
Fig. 20 Deletion Time for Mobile Review Data set
VI. CONCLUSION
Keyword search and indexing plays an important role in text retrieval. In our work the optimized B+ tree has been designed and developed by using semantic and genetic algorithm. The system has been tested on the twitter and Mobile review data set. The keywords from the dataset are preprocessed by using stop word removal, Porters stemming and TF-IDF calculation. These keywords are then checked for semantics by using WordNet dictionary. The Semantic B+ tree index has been generated for these keywords and it has been encrypted by using AES to maintain the data privacy. Genetic algorithm has been applied further on these to optimize the cost of memory and searching. The result analysis shows that the number of nodes generated and memory required by using our approach is less than B+ tree. Even though system presented in this paper taken more time to generate the index, but the insertion, deletion and search time is less compared to B+ tree.
REFERENCES
[ 1] Sai Wu, Dawei Jiang, Beng Chin Ooi, Kun-Lung Wu “Efficient B-tree Based Indexing for Cloud Data Processing”, 2010 Proceedings of the VLDB Endowment, Vol. 3, No. 1.
[ 2] Jung-Yeon Yang, Ig-Hoon Lee , Ok-Ran Jeong, Jun-Young Song, Chul-Min Lee, Sang-goo Lee “An architecture for supporting batch query and online service in Very Large Database systems” IEEE International Conference on e-Business Engineering (ICEBE'06)
[ 3] Ahmed A. A. Radwan, Bahgat A. Abdel Latef, Abdel Mgeid A. Ali, and Osman A. Sadek “Using Genetic Algorithm to Improve Information Retrieval Systems” International Journal of Computer, Electrical, Automation, Control and Information Engineering Vol:2, No:5, 2008
[ 4] Wei Zhou, Jin Lu, Zhongzhi Luan, Shipu Wang, Gang Xue, Shaowen Yao, “SNB-index: a SkipNet and B+ tree based auxiliary Cloud index” Cluster Comput (2014) 17:453–462
[ 5] Tingting Wei, Yonghe Lu, Huiyou Chang, Qiang Zhou, Xianyu Bao “A semantic approach for text clustering using WordNet and lexical Chains” Expert Systems with Applications 42 (2015) 2264–2275
[ 6] Rada Mihalcea and Dan Moldovan “Semantic Indexing using WordNet Senses” Proceedings of the ACL-2000 workshop on Recent advances in natural language processing and information retrieval: held in conjunction with the 38th Annual Meeting of the Association for Computational Linguistics - Volume 11 Pages 35-45
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 3, March 2018)279 [ 8] Haoyu ZHAO, Xiongfei LI, Liang CHANG, Xuebai ZANG “Fat File
System Design and Research” 2015 International Conference on Network and Information Systems for Computers.
[ 9] Arjun Srinivas Nayak, Ananthu P Kanive, Naveen Chandavekar, Dr. Balasubramani R “Survey on Pre-Processing Techniques for Text Mining” International Journal Of Engineering And Computer Science Volume 5 Issues 6 June 2016, Page No. 16875-16879
[ 10] Pritam C. Gaigole, L. H. Patil, P.M Chaudhari “Preprocessing Techniques in Text Categorization” NCIPET-2013 Proceedings published by International Journal of Computer Applications® (IJCA)
[ 11] H.-J. Song, J.-H. Ahn, H.-J. Kim “Using genetic algorithms to work out index configurations for the class-hierarchy indexing in object databases” Information and Software Technology 42 (2000) 731-741
[ 12] H. V. JAGADISH, CUI YU, RUI ZHANG “iDistance: An Adaptive B+ Tree Based Indexing Method for Nearest Neighbor Search” ACM Transactions on Database Systems, Vol. 30, No. 2, June 2005, Pages 364–397.
[ 13] Sunil B. Mane, Pradeep K. Sinha, “Analysis of Encryption Algorithms to Basic Operations on Outsourced B+ Trees for Data Privacy”, IEEE 3rd International Conference on Electronics Computer Technology, 2011
[ 14] http://www.earningguys.com/seo/stop-word/
[ 15] http://snowball.tartarus.org/algorithms/porter/stemmer.html
[ 16] http://people.scs.carleton.ca/~armyunis/projects/KAPI/porter.pdf
[ 17] http://www.obitko.com/tutorials/geneticalgorithms/selection.php
[ 18] C. Fellbaum, WordNet: An Electronic Lexical Database, MIT Press,1998.
[ 19] http://stp.lingfil.uu.se/~santinim/sais/Ass1_Essays_FinalVersion/Se geblad_Jesper_essay.pdf