Training Neural Machine Translation to Apply Terminology Constraints
Full text
Figure

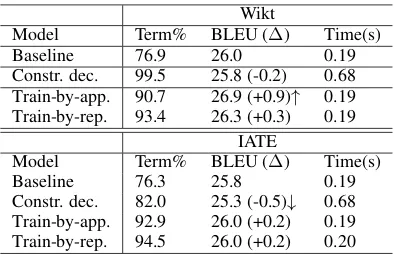
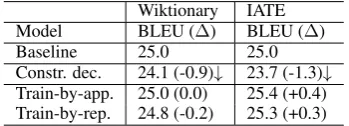
Related documents
Calculations of electronic and phononic states in a chain of the nanocrystalline Si dots indicate a possibility of strong suppression of electron energy relaxation, which may be
Regulation 26: Risk management procedures Compliant Regulation 28: Fire precautions Not compliant Regulation 29: Medicines and pharmaceutical services Not compliant Regulation
Sydney rock oysters, Saccostrea glomerata , were collected from the high-intertidal and subtidal areas of the shore and exposed in an orthogonal design to either an intertidal or
To characterize and quantify the acoustic parameters of RFM behaviour, we tested the effect on male free flight of artificial pure- tone stimuli over a frequency range intended to
We compared the pattern and distribution of ice formed in a nematode that survives intracellular freezing well ( Panagrolaimus sp. DAW1), one that survives poorly (
The first data on body density from two species of elasmobranch occurring in freshwater (the bull shark Carcharhinus leucas, Mu ̈ ller and Henle 1839, and the largetooth sawfish
In this article, we review our 8-year experience with the use of MR imaging, MR angiography, and catheter angiography in the evaluation of childhood idiopathic cerebral infarction
Although the small number of cases in some sections of this study limits the value of any statistical conclusions, the tables show that when the densities were
