Bootstrapping Named Entity Recognition
with Automatically Generated Gazetteer Lists
Zornitsa Kozareva
Dept. de Lenguajes y Sistemas Inform´aticos University of Alicante
Alicante, Spain
Abstract
Current Named Entity Recognition sys-tems suffer from the lack of hand-tagged data as well as degradation when mov-ing to other domain. This paper explores two aspects: the automatic generation of gazetteer lists from unlabeled data; and the building of a Named Entity Recognition system with labeled and unlabeled data. 1 Introduction
Automatic information extraction and information retrieval concerning particular person, location, organization, title of movie or book, juxtaposes to the Named Entity Recognition (NER) task. NER consists in detecting the most silent and informa-tive elements in a text such as names of people, company names, location, monetary currencies, dates. Early NER systems (Fisher et al., 1997), (Black et al., 1998) etc., participating in Message Understanding Conferences (MUC), used linguis-tic tools and gazetteer lists. However these are dif-ficult to develop and domain sensitive.
To surmount these obstacles, application of machine learning approaches to NER became a research subject. Various state-of-the-art ma-chine learning algorithms such as Maximum En-tropy (Borthwick, 1999), AdaBoost(Carreras et al., 2002), Hidden Markov Models (Bikel et al., ), Memory-based Based learning (Tjong Kim Sang, 2002b), have been used1. (Klein et al., 2003), (Mayfield et al., 2003), (Wu et al., 2003), (Kozareva et al., 2005c) among others, combined several classifiers to obtain better named entity coverage rate.
1
For other machine learning methods, consult http://www.cnts.ua.ac.be/conll2002/ner/ http://www.cnts.ua.ac.be/conll2003/ner/
Nevertheless all these machine learning algo-rithms rely on previously hand-labeled training data. Obtaining such data is labor-intensive, time consuming and even might not be present for lan-guages with limited funding. Resource limitation, directed NER research (Collins and Singer, 1999), (Carreras et al., 2003), (Kozareva et al., 2005a) toward the usage of semi-supervised techniques. These techniques are needed, as we live in a multi-lingual society and access to information from var-ious language sources is reality. The development of NER systems for languages other than English commenced.
This paper presents the development of a Span-ish Named Recognition system based on machine learning approach. For it no morphologic or syn-tactic information was used. However, we pro-pose and incorporate a very simple method for automatic gazetteer2 construction. Such method can be easily adapted to other languages and it is low-costly obtained as it relies on n-gram extrac-tion from unlabeled data. We compare the perfor-mance of our NER system when labeled and unla-beled training data is present.
The paper is organized in the following way: brief explanation about NER process is repre-sented in Section 2. In Section 3 follows feature extraction. The experimental evaluation for the Named Entity detection and classification tasks with and without labeled data are in Sections 4 and 5. We conclude in Section 6.
2 The NER how to
A Named Entity Recognition task can be scribed as composition of two subtasks, entity
de-2
specialized lists of names for location and person names, e.g. Madrid is in the location gazetteer, Mary is in the person gazetteer
tection and entity classification. Entity delimita-tion consist in determining the boundaries of the entity (e.g. the place from where it starts and the place it finishes). This is important for tracing entities composed of two or more words such as ”Presidente de los Estados Unidos ”3, ”Universi-dad Politecnica de Catalu˜na”4. For this purpose, the BIO scheme was incorporated. In this scheme, tag B denotes the start of an entity, tag I continues the entity and tag O marks words that do not form part of an entity. This scheme was initially intro-duced in CoNLL’s (Tjong Kim Sang, 2002a) and (Tjong Kim Sang and De Meulder, 2003) NER competitions, and we decided to adapt it for our experimental work.
Once all entities in the text are detected, they are passed for classification in a predefined set of categories such as location, person, organization or miscellaneous5 names. This task is known as
entity classification. The final NER performance is measured considering the entity detection and classification tasks together.
Our NER approach is based on machine learn-ing. The two algorithms we used for the experi-ments were instance-based and decision trees, im-plemented by (Daelemans et al., 2003). They were used with their default parameter settings. We selected the instance-based model, because it is known to be useful when the amount of training data is not sufficient.
Important part in the NE process takes the lo-cation and person gazetteer lists which were au-tomatically extracted from unlabeled data. More detailed explanation about their generation can be found in Section 3.
To explore the effect of labeled and unlabeled training data to our NER, two types of experiments were conducted. For the supervised approach, the labels in the training data were previously known. For the semi-supervised approach, the labels in the training data were hidden. We used bootstrapping (Abney, 2002) which refers to a problem setting in which one is given a small set of labeled data and a large set of unlabeled data, and the task is to induce a classifier.
• Goals:
- utilize a minimal amount of supervised ex-amples;
3
”President of the United States”
4”Technical University of Catalu˜na” 5book titles, sport events, etc.
- obtain learning from many unlabeled ex-amples;
• General scheme:
- initial supervision seed examples for train-ing an initial model;
- corpus classification with seed model;
- add most confident classifications to train-ing data and iterate.
In our bootstrapping, a newly labeled example was added into the training dataL, if the two clas-sifiers C1 andC2 agreed on the class of that ex-ample. The number n of iterations for our ex-periments is set up to 25 and when this bound is reached the bootstrapping stops. The scheme we follow is described below.
1. foriteration= 0. . . ndo
2. pool 1000 examples from unlabeled data; 3. annotate all 1000 examples with classifierC1
andC2;
4. for each of the 1000 examples compare classes ofC1andC2;
5. add example intoLonly if classes ofC1 and
C2 agree;
6. train model withL;
7. calculate result 8. end for
Bootstrapping was previously used by (Carreras et al., 2003), who were interested in recognizing Catalan names using Spanish resources. (Becker et al., 2005) employed bootstrapping in an ac-tive learning method for tagging entities in an as-tronomic domain. (Yarowsky, 1995) and (Mi-halcea and Moldovan, 2001) utilized bootstrap-ping for word sense disambiguation. (Collins and Singer, 1999) classified NEs through co-training, (Kozareva et al., 2005a) used self-training and co-training to detect and classify named entities in news domain, (Shen et al., 2004) conducted ex-periments with multi-criteria-based active learning for biomedical NER.
The experimental datawe work with is taken from the CoNLL-2002 competition. The Spanish
corpus6comes from news domain and was previ-ously manually annotated. The train data set con-tains 264715 words of which 18798 are entities and the test set has 51533 words of which 3558
are entities.
We decided to work with available NE anno-tated corpora in order to conduct an exhaustive and comparative NER study when labeled and unla-beld data is present. For our bootstrapping experi-ment, we simply ignored the presence of the labels in the training data. Of course this approach can be applied to other domain or language, the only need is labeled test data to conduct correct evaluation.
The evaluationis computed per NE class by the help ofconlleval7script. The evaluation measures
are:
P recision=number of correct answers f ound by the system
number of answers given by the system (1)
Recall=number of correct answers f ound by the system
number of correct answers in the test corpus (2)
Fβ=1=
2×P recision×Recall
P recision+Recall (3)
3 Feature extraction
Recently diverse machine learning techniques are utilized to resolve various NLP tasks. For all of them crucial role plays the feature extraction and selection module, which leads to optimal classifier performance. This section describes the features used for our Named Entity Recognition task.
Feature vectors φi={f1,...,fn} are constructed.
The total number of features is denoted byn, and
φi corresponds to the number of examples in the
data. In our experiment features represent contex-tual, lexical and gazetteer information. Here we number each feature and its corresponding argu-ment.
f1: all letters ofw08are in capitals;
f2-f8: w−3, w−2, w−1, w0, w+1, w+2, w+3 ini-tiate in capitals;
f9: position ofw0 in the current sentence;
f10: frequency ofw0;
f11-f17: word forms of w0 and the words in
[−3,+3]window;
f18: first word making up the entity;
f19: second word making up the entity, if present;
6
http://www.cnts.ua.ac.be/conll2002/ner/data/
7http://www.cnts.ua.ac.be/conll2002/ner/bin/ 8w
0indicates the word to be classified.
f20:w−1 is trigger word for location, person or organization;
f21:w+1 is trigger word for location, person or organization;
f22:w0belongs to location gazetteer list;
f23: w0 belongs to first person name gazetteer list;
f24:w0belongs to family name gazetteer list;
f25: 0 if the majority of the words in an entity are locations, 1 if the majority of the words in an entity are persons and 2 otherwise.
Features f22, f23, f24 were automatically ex-tracted by a simple pattern validation method we propose below.
The corpusfrom where the gazetteer lists were extracted, forms part of Efe94 and Efe95 Spanish corpora provided for the CLEF9competitions. We conducted a simple preprocessing, where all sgml documents were merged in a single file and only the content situated among the text tags was ex-tracted and considered for further processing. As a result, we obtained 1 Gigabyte of unlabeled data, containing 173468453words. The text was tok-enized and the frequency of all unigrams in the corpus was gathered.
The algorithm we propose and use to obtain location and person gazetteer lists is very simple. It consists in finding and validating common pat-terns, which can be constructed and utilized also for languages other than Spanish.
The location pattern hprepi, wji, looks for
prepositioniwhich indicates location in the Span-ish language and all corresponding right capital-ized context wordswj for prepositioni. The
de-pendency relation between prepi and wj,
con-veys the semantic information on the selection re-strictions imposed by the two related words. In a walk through example the pattern hen,∗i, ex-tracts all right capitalized context words wj as
{Argentina, Barcelona, Madrid, Valencia}placed next to preposition ”en”. These words are taken as location candidates. The selection restriction implies searching for words appearing after the preposition ”en” (e.g. en Madrid) and not before the preposition (e.g. Madrid en).
The termination of the pattern extractionhen,∗i, initiates the extraction phase for the next preposi-tions inprepi={en, En, desde, Desde, hacia,
Ha-cia}. This processes is repeated until the complete set of words in the preposition set are validated. Table 1 represents the number of entities extracted
by each one of the preposition patterns.
pi en En desde Desde hacia Hacia
wj 15567 2381 1773 320 1336 134
Table 1:Extracted entities
The extracted capitalized words are passed through a filtering process. Bigrams ”prepi
Capitalized wordj” with frequency lower than
20 were automatically discarded, because we saw that this threshold removes words that do not tend to appear very often with the lo-cation prepositions. In this way misspelled words as Bacelona instead of Barcelona were filtered. From another side, every capitalized word composed of two or three characters, for instance ”La, Las” was initiated in a trigram hprepi, Capitalized wordj, Capitalized wordj+1i val-idation pattern. If these words were seen in com-bination with other capitalized words and their tri-gram frequency was higher then 20 they were in-cluded in the location gazetteer file. With this tri-gram validation pattern, locations as ”Los Ange-les”, ”Las Palmas”, ”La Coru˜na” ,”Nueva York”10 were extracted.
In total 16819entities with no repetition were automatically obtained. The words represent countries around the world, European capitals and mostly Spanish cities. Some noisy elements found in the file were person names, which were accom-panied by the preposition ”en”. As person names were capitalized and had frequency higher than the threshold we placed, it was impossible for these names to be automatically detected as erroneous and filtered. However we left these names, since the gazetteer attributes we maintain are mutually nonexclusive. This means the name ”Jordan” can be seen in location gazetteer indicating the coun-try Jordan and in the same time can be seen in the person name list indicating the person Jordan. In a real NE application such case is reality, but for the determination of the right category name en-tity disambiguation is needed as in (Pedersen et al., 2005).
Person gazetteer is constructed with graph ex-ploration algorithm. The graph consists of:
1. two kinds of nodes: • First Names • Family Names 10New York
2. undirected connections between First Names and Family Names.
The graph connects Family Names with First Names, and vice versa. In practice, such a graph is not necessarily connected, as there can be unusual first names and surnames which have no relation with other names in the corpus. Though, the cor-pus is supposed to contain mostly common names in one and the same language, names from other languages might be present too. In this case, if the foreign name is not connected with a Spanish name, it will never be included in the name list.
Therefore, starting from some common Span-ish name will very probably place us in the largest connected component11. If there exist other differ-ent connected compondiffer-ents in the graph, these will be outliers, corresponding to names pertaining to some other language, or combinations of both very unusual first name and family name. The larger the corpus is, the smaller the presence of such ad-ditional connected components will be.
The algorithm performs an uninformed breadth-first search. As the graph is not a tree, the stop condition occurs when no more nodes are found. Nodes and connections are found following the patternhF irst name, F amily namei. The node from which we start the search can be a common Spanish first or family name. In our example we started from the Spanish common first nameJos´e. The notationhi, ji ∈ C refers to finding in the corpusCthe regular expression12
[A-Z][a-z]* [A-Z][a-z]*
This regular expression indicates a possible rela-tion between first name and family name. The scheme of the algorithm is the following:
LetCbe the corpus,F be the set of first names, andSbe the set of family names.
1. F ={”Jos´e”} 2. ∀i∈F do Snew=Snew∪ {j},∀j| hi, ji ∈C 3. S=S∪Snew 4. ∀j∈Sdo Fnew=Fnew∪ {i},∀i| hi, ji ∈C
11A connected component refers to a maximal connected
subgraph, in graph theory. A connected graph, is a graph containing only one connected component.
12
For Spanish some other characters have to be added to the regular expression, such as˜nand accents.
Manolo Jose Maria Garcia Martinez Fernandez John Lennon
First name nodes Relations Familyname nodes
Connected Component Connected Component
Figure 1: An example of connected components.
5. F =F ∪Fnew
6. if (Fnew6=∅)∨(Snew6=∅)
then goto 2. else finish.
Suppose we have a corpus containing the fol-lowing person names: {”Jos´e Garc´ıa”, ”Jos´e Mart´ınez”, ”Manolo Garc´ıa”, ”Mar´ıa Mart´ınez”, ”Mar´ıa Fern´andez”, ”John Lennon”} ⊂C. Initially we have F = {”Jos´e”}andS = ∅. Af-ter the 3rd step we would have S = {”Garc´ıa”, ”Mart´ınez”}, and after the 5th step:F ={”Jos´e”, ”Manolo”, ”Mar´ıa”}. During the next iteration ”Fern´andez” would also be added toS, as ”Mar´ıa” is already present in F. Neither ”John”, nor ”Lennon” are connected to the rest of the names, so these will never be added to the sets. This can be seen in Figure 1 as well.
In our implementation, we filtered relations ap-pearing less than 10 times. Thus rare combina-tions like ”Jose Madrid, Mercedes Benz” are fil-tered. Noise was introduced from names related to both person and organization names. For example the Spanish girl name Mercedes, lead to the node Benz, and as ”Mercedes Benz” refers also to the car producing company, noisy elements started to be added through the node ”Benz”. In total13713
fist names and103008surnames have been auto-matically extracted.
We believe and prove that constructing auto-matic location and person name gazetteer lists with the pattern search and validation model we propose is a very easy and practical task. With our approach thousands of names can be obtained, especially given the ample presence of unlabeled data and the World Wide Web.
The purpose of our gazetteer construction was not to make complete gazetteer lists, but rather generate in a quick and automatic way lists of names that can help during our feature construc-tion module.
4 Experiments for delimitation process
In this section we describe the conducted exper-iments for named entity detection. Previously (Kozareva et al., 2005b) demonstrated that in su-pervised learning only superficial features as con-text and ortografics are sufficient to identify the boundaries of a Named Entity. In our experiment the superficial featuresf1÷f10were used by the supervised and semi-supervised classifiers. Table 2 shows the obtained results forBegin andInside tags, which actually detect the entities and the total BIO tag performance.
experiment B I BIO
Supervised 94.40 85.74 91.88
Bootstrapped 87.47 68.95 81.62
Table 2:F-score of detected entities. On the first row are the results of the super-vised method and on the second row are the high-est results of the bootstrapping achieved in its seventeenth iteration. For the supervised learn-ing 91.88% of the entity boundaries were cor-rectly identified and for the bootstrapping 81.62% were correctly detected. The lower performance of bootstrapping is due to the noise introduced dur-ing the learndur-ing. Some examples were learned with the wrong class and others didn’t introduce new information in the training data.
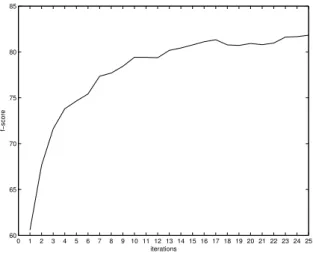
Figure 2 presents the learning curve of the boot-strapping processes for25iterations. On each it-eration 1000examples were tagged, but only the examples having classes that coincide by the two classifiers were later included in the training data. We should note that for each iteration the same amount of B, I and O classes was included. Thus the balance among the three different classes in the training data is maintained.
According to z0 statistics (Dietterich, 1998),
the highest score reached by bootstrapping can-not outperform the supervised method, however if both methods were evaluated on small amount of data the results were similar.
0 1 2 3 4 5 6 7 8 910 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 60 65 70 75 80 85 iterations f−score
Figure 2: Bootstrapping performance
5 Experiments for classification process In a Named Entity classification process, to the previously detected Named Entities a predefined category of interest such as name of person, orga-nization, location or miscellaneous names should be assigned. To obtain a better idea of the perfor-mance of the classification methods, several exper-iments were conducted. The influence of the au-tomatically extracted gazetteers was studied, and a comparison of the supervised and semi-supervised methods was done.
experiment PER LOC ORG MISC
N oGazetteerSup. 80.98 71.66 73.72 49.94
GazetteerSup. 84.32 75.06 77.83 53.98
Bootstrapped 62.59 51.19 50.18 33.04
Table 3:F-score of classified entities. Table 3 shows the obtained results for each one of the experimental settings. The first row indi-cates the performance of the supervised classifier when no gazetteer information is present. The classifier used f1, f2, f3, f4, f5, f6, f7, f8, f18,
f19, f20, f21 attributes. The performance of the second row concerns the same classifier, but in-cluding the gazetteer information by adding f22,
f23,f24andf25attributes. The third row relates to the bootstrapping process. The attributes used for the supervised and semi-supervised learning were the same.
Results show that among all classes, miscella-neous is the one with the lowest performance. This is related to the heterogeneous information of the category. The other three categories performed
above 70%. As expected gazetteer information contributed for better distinction of person and lo-cation names. Organization names benefitted from the contextual information, the organization trig-ger words and the attribute validating if an entity is not a person or location then is treated as an organization. Bootstrapping performance was not high, due to the previously 81% correctly detected named entity boundaries and from another side to the training examples which were incorrectly clas-sified and included into the training data.
In our experiment, unlabeled data was used to construct in an easy and effective way person and location gazetteer lists. By their help supervised and semi-supervised classifiers improved perfor-mance. Although one semi-supervised method cannot reach the performance of a supervised clas-sifier, we can say that results are promising. We call them promising in the aspect of constructing NE recognizer for languages with no resources or even adapting the present Spanish Named Entity system to other domain.
6 Conclusions and future work
In this paper we proposed and implemented a pattern validation search in an unlabeled corpus though which gazetteer lists were automatically generated. The gazetteers were used as features by a Named Entity Recognition system. The per-formance of this NER system, when labeled and unlabeled training data was available, was mea-sured. A comparative study for the information contributed by the gazetteers in the entity classifi-cation process was shown.
In the future we intend to develop automatic gazetteers for organization and product names. It is also of interest to divide location gazetteers in subcategories as countries, cities, rivers, moun-tains as they are useful for Geographic Informa-tion Retrieval systems. To explore the behavior of named entity bootstrapping, other domains as bioinformatics will be explored.
Acknowledgements Many thanks to the three anonymous reviewers for their useful comments and suggestions.
This research has been partially funded by the Spanish Government under project CICyT number TIC2003-0664-C02-02 and PROFIT number FIT-340100-2004-14 and by the Valencia Government under project numbers 276 and GV04B-268.
References
Steven P. Abney. 2002. Bootstrapping. InProceedings of Association of Computational Linguists, pages 360–367.
Markus Becker, Ben Hachey, Beatrice Alex, and Claire Grover. 2005. Optimising selective sampling for bootstrapping named entity recognition. In Pro-ceedings of the Workshop on Learning with Multiple View, ICML, pages 5–10. Bonn, Germany.
Daniel M. Bikel, Scott Miller, Richard Schwartz, and Ralph Weischedel. Nymble: a high-performance learning name-finder. InProceedings of Conference on Applied Natural Language Processing.
William J Black, Fabio Rinaldi, and David Mowatt. 1998. Facile: Description of the ne system used for muc-7. InProceedings of MUC-7.
Andrew Borthwick. 1999. A Maximum Entropy Ap-proach to Named Entity Recognition. Ph.D. thesis, New York University., September.
Xavier Carreras, Llu´ıs M`arques, and Llu´ıs Padr´o. 2002. Named entity extraction using adaboost. In Proceedings of CoNLL-2002, pages 167–170. Taipei, Taiwan.
Xavier Carreras, Llu´ıs M`arquez, and Llu´ıs Padr´o. 2003. Named entity recognition for catalan us-ing only spanish resources and unlabelled data. In EACL, pages 43–50.
Michael Collins and Yoram Singer. 1999. Unsuper-vised models for named entity classification. In Pro-ceedings of the Joint SIGDAT Conference on Empir-ical Methods in Natural Language Processing and Very Large Corpora.
Walter Daelemans, Jakub Zavrel, Ko van der Sloot, and Antal van den Bosch. 2003. Timbl: Tilburg memory-based learner. Technical Report ILK 03-10, Tilburg University, November.
Thomas G. Dietterich. 1998. Approximate statistical test for comparing supervised classification learning algorithms.Neural Computation, 10(7):1895–1923. David Fisher, Stephen Soderland, Joseph McCarthy, Fangfang Feng, and Wendy Lehnert. 1997. De-scription of the umass system as used for muc-6. In Proceedings of MUC-6.
Dan Klein, Joseph Smarr, Huy Nguyen, and Christo-pher D. Manning. 2003. Named entity recognition with character-level models. In Walter Daelemans and Miles Osborne, editors,Proceedings of CoNLL-2003, pages 180–183. Edmonton, Canada.
Zornitsa Kozareva, Boyan Bonev, and Andres Mon-toyo. 2005a. Self-training and co-training for span-ish named entity recognition. In4th Mexican Inter-national Conference on Artificial Intelligence, pages 770–780.
Zornitsa Kozareva, Oscar Ferr´andez, Andres Montoyo, and Rafael Mu˜noz. 2005b. Using language re-source independent detection for spanish named en-tity recognition. InProceedings of the Conference on Recent Advances in Natural Language Process-ing (RANLP 2005), pages 279–283.
Zornitsa Kozareva, Oscar Ferr´andez, Andr´es Montoyo, Rafael Mu˜noz, and Armando Su´arez. 2005c. Com-bining data-driven systems for improving named en-tity recognition. InNLDB, pages 80–90.
James Mayfield, Paul McNamee, and Christine Pi-atko. 2003. Named entity recognition using hun-dreds of thousands of features. In Walter Daelemans and Miles Osborne, editors,Proceedings of CoNLL-2003, pages 184–187. Edmonton, Canada.
Rada Mihalcea and Dan I. Moldovan. 2001. A highly accurate bootstrapping algorithm for word sense dis-ambiguation. International Journal on Artificial In-telligence Tools, 10(1-2):5–21.
Ted Pedersen, Amruta Purandare, and Anagha Kulka-rni. 2005. Name discrimination by clustering sim-ilar contexts. InComputational Linguistics and In-telligent Text Processing, 6th International Confer-ence, CICLing 2005, Mexico City, pages 226–237. Dan Shen, Jie Zhang, Jian Su, Guodong Zhou, and
Chew-Lim Tan. 2004. Multi-criteria-based active learning for named entity recognition. In Proceed-ings of Association of Computational Linguists. Erik F. Tjong Kim Sang and Fien De Meulder.
2003. Introduction to the conll-2003 shared task: Language-independent named entity recognition. In Walter Daelemans and Miles Osborne, editors, Pro-ceedings of CoNLL-2003, pages 142–147. Edmon-ton, Canada.
Erik F. Tjong Kim Sang. 2002a. Introduction to the conll-2002 shared task: Language-independent named entity recognition. In Proceedings of CoNLL-2002, pages 155–158. Taipei, Taiwan. Erik F. Tjong Kim Sang. 2002b. Memory-based
named entity recognition. In Proceedings of CoNLL-2002, pages 203–206. Taipei, Taiwan. Dekai Wu, Grace Ngai, and Marine Carpuat. 2003.
A stacked, voted, stacked model for named entity recognition. In Walter Daelemans and Miles Os-borne, editors,Proceedings of CoNLL-2003, pages 200–203. Edmonton, Canada.
David Yarowsky. 1995. Unsupervised word sense dis-ambiguation rivaling supervised methods. In Meet-ing of the Association for Computational LMeet-inguis- Linguis-tics, pages 189–196.