S
KATHOLIEKE UNIVERSITEIT LEUVEN
FACULTEIT INGENIEURSWETENSCHAPPEN
DEPARTEMENT COMPUTERWETENSCHAPPEN
AFDELING INFORMATICA
Celestijnenlaan 200 A — B-3001 Leuven
A Dynamic Learning Object Life Cycle and its Implications for
Automatic Metadata Generation
Promotor :
Prof. Dr. H. OLIVI´E
Proefschrift voorgedragen tot het behalen van het doctoraat in de ingenieurswetenschappen door
Kris CARDINAELS
S
DEPARTEMENT COMPUTERWETENSCHAPPEN
AFDELING INFORMATICA
Celestijnenlaan 200 A — B-3001 Leuven
A Dynamic Learning Object Life Cycle and its Implications for
Automatic Metadata Generation
Jury :
Prof. Dr. ir. D. Vandermeulen, voorzitter Prof. Dr. H. Olivi´e, promotor
Prof. Dr. ir. E. Duval Prof. Dr. D. De Schreye Prof. Dr. M.-F. Moens
Prof. Dr. Daniel R. Rehak (University of Memphis, USA)
Proefschrift voorgedragen tot het behalen van het doctoraat in de ingenieurswetenschappen door
Kris CARDINAELS
U.D.C. 681.3∗H1, 681.3∗H3
c
°Katholieke Universiteit Leuven – Faculteit Ingenieurswetenschappen Arenbergkasteel, B-3001 Heverlee (Belgium)
Alle rechten voorbehouden. Niets uit deze uitgave mag worden vermenigvuldigd en/of openbaar gemaakt worden door middel van druk, fotocopie, microfilm, elek-tronisch of op welke andere wijze ook zonder voorafgaande schriftelijke toestemming van de uitgever.
All rights reserved. No part of the publication may be reproduced in any form by print, photoprint, microfilm or any other means without written permission from the publisher.
D/2007/7515/39
i
Voorwoord
Onmiddellijk na mijn opleiding als licentiaat Informatica ben ik in 1995 gestart als medewerker van prof. Henk Olivi´e en kreeg ik de kans mee te werken aan ARI-ADNE, een internationaal project waaruit nu dit doctoraatswerk voortvloeit. Omdat een doctoraat niet tot stand kan komen zonder de steun van een on-derzoeksgroep, wil ik ook al de (ex-)leden van HMDB bedanken voor de goede samenwerking. In de eerste plaats natuurlijk Henk Olivi´e voor het aanbieden van de mogelijkheid het onderzoek te starten en zijn steun al die jaren. Ten tweede, Erik Duval voor de begeleiding in het kader van het ARIADNE-project en de verderzetting van mijn onderzoek. En tenslotte de collega’s met wie ik bin-nen HMDB heb samengewerkt: Koen Hendrikx, Raf Van Durm, Bart Verhoeven, Thomas Cleenewerck, Stefaan Ternier en Michael Meire.
Ook wil ik de collega’s binnen Communicatie- en Multimediadesign van de KHLim bedanken voor de vaak pittige discussies over onderzoek in verschillende domeinen. Dit heeft me soms een heel andere kijk op het onderwerp gegeven en geholpen het verhaal af te werken.
Bedankt aan mijn ouders, mijn schoonouders, mijn zus, schoonbroers en schoon-zussen voor de steun al die jaren. Bedankt aan al diegenen die me te pas en te onpas naar de toestand van m’n thesis vroegen en hierdoor de druk op de ketel hielden. Maar vooral bedankt aan Christine, Stan, Simon, Marthe en Kaat, jullie weten waarom.
A Dynamic Learning Object Life Cycle and its Implications
for Automatic Metadata Generation
Starting from a reuse life cycle for courseware development, we define a dynamic learning object life cycle in which the dynamic character of the metadata is the key issue. The dynamic metadata help to enhance the reusability of the learning object as the metadata can contain much richer information. In this life cycle, we have taken the labeling phase out of the cycle and placed it in parallel with all the other phases. In this way, metadata can be added or updated throughout all the phases of the life cycle.
Second, we have developed a framework of automatic metadata generation for learning objects to overcome the problems with manual indexing. Within this framework, metadata are generated automatically taking into account different sources of information that are available in the different phases of the life cycle. Ex-amples are the learning objects themselves, user feedback, relationships with other learning objects, and so on. The implementation of this framework is based on a formal model of learning object metadata. This model defines how metadata can be associated with learning objects and how the metadata from different sources can be combined to overcome conflicts between sources. In the formal model we also introduce the notion of context-awareness for learning object metadata.
Een Dynamische Levenscyclus voor Leerobjecten en de
Gevol-gen voor Automatische MetadataGevol-generatie
Vertrekkende van een levenscyclus gebaseerd op hergebruik voor de ontwikkeling van cursusmateriaal, defini¨eren we een dynamische levenscyclus voor leerobjecten waarbij het dynamische karakter van de metadata de belangrijkste rol speelt. Deze dynamische metadata helpen de herbruikbaarheid van de leerobjecten te verbeteren doordat de metadata veel rijkere informatie kunnen bevatten. In de levenscyclus wordt dit benadrukt door de indexeringsfase uit de cyclus te halen en parallel te plaatsen aan al de andere fasen van de cyclus. Op deze manier kunnen metadata op elk moment van de andere fasen worden toegevoegd of aangepast. Ten tweede hebben we een raamwerk voor automatische metadatageneratie on-twikkeld om de problemen met manuele indexering op lossen. In dit raamwerk worden de metadata automatisch genereerd aan de hand van verschillende bronnen van informatie die beschikbaar zijn in de verschillende fasen van de levenscyclus. Voorbeelden hiervan zijn, de leerobjecten zelf, gebruikersfeedback en relaties met andere leerobjecten. Om dit raamwerk te implementeren, hebben we een formeel model voor leerobject-metadata gedefinieerd. Dit model definieert hoe metadata met leerobjecten geassocieerd kunnen worden en hoe metadata van verschillende bronnen gecombineerd kunnen worden door eventuele conflicten op te lossen. In het formele model introduceren we ook context-afhankelijke leerobject-metadata.
Contents
Contents iii
List of Acronyms vii
List of Figures ix
List of Tables xi
Preface xiii
1 Learning Objects & Learning Object Metadata 1
1.1 Introduction . . . 1
1.2 Learning Objects . . . 1
1.2.1 Categories of Definitions . . . 2
1.2.2 The Interest in Reuse . . . 6
1.3 Learning Object Metadata . . . 8
1.3.1 Definition . . . 8
1.3.2 IEEE Learning Object Metadata (LOM) . . . 9
1.4 ARIADNE . . . 10
1.4.1 Background . . . 10
1.4.2 ARIADNE Metadata Recommendation . . . 11
1.4.3 Knowledge Pool System . . . 13
1.4.4 ARIADNE Life Cycle . . . 14
1.5 Related Work . . . 14
1.5.1 Dublin Core Metadata Initiative . . . 14
1.5.2 IMS . . . 16
1.5.3 SCORM . . . 17
1.5.4 Merlot . . . 18
1.6 Conclusions . . . 20 iii
2 Dynamic Learning Object Life Cycle 23
2.1 Introduction . . . 23
2.2 Reuse Life Cycle . . . 24
2.2.1 Two Development Phases . . . 24
2.2.2 Knowledge Transfer between the Phases . . . 26
2.3 Traditional Life Cycle . . . 27
2.4 Dynamic Life Cycle . . . 29
2.5 The Labeling Phase . . . 32
2.5.1 Information Retrieval/Extraction . . . 33
2.5.2 Social Information Retrieval . . . 38
2.5.3 Explicit Feedback . . . 40
2.5.4 Implicit Feedback . . . 42
2.5.5 Discussion . . . 43
2.6 Related Learning Object Life Cycles . . . 43
2.6.1 Alternative Presentation of the Traditional Life Cycle . . . 44
2.6.2 Learning Objects Ontology . . . 45
2.6.3 COLIS Global Use Case . . . 46
2.6.4 Digital Library Framework - Discovery to Delivery . . . 49
2.6.5 Discussion . . . 50
2.7 Conclusions . . . 52
3 Automatic Metadata Generation 55 3.1 Introduction . . . 55 3.2 Metadata Sources . . . 57 3.2.1 Manual Metadata . . . 58 3.2.2 Object Contents . . . 59 3.2.3 Contexts . . . 63 3.2.4 Actual Use . . . 65
3.3 Different Sources - Different Values . . . 66
3.3.1 Quality of Metadata . . . 66
3.3.2 Uncertain Metadata . . . 68
3.3.3 Conflicts Between Sources . . . 69
3.3.4 Using Confidence Values to Solve Conflicts . . . 70
3.4 Conclusions . . . 72
4 Formal Reuse and Metadata Model 73 4.1 Introduction . . . 73
4.2 Learning Objects and Metadata . . . 74
4.2.1 Learning Objects . . . 74
4.2.2 Single-valued Metadata Elements . . . 74
4.2.3 Multi-valued Metadata Elements . . . 75
4.2.4 Metadata Records . . . 75
CONTENTS v
4.3.1 Basic Definitions . . . 76
4.3.2 Selecting Facet Values . . . 78
4.3.3 Information Retrieval Models . . . 79
4.4 Context-Awareness in Metadata . . . 81 4.4.1 Contexts . . . 81 4.4.2 Definitions . . . 82 4.4.3 Context Reification . . . 83 4.5 RDF Metadata Model . . . 84 4.6 Metadata Standards . . . 87 4.6.1 IEEE LOM . . . 87
4.6.2 Dublin Core Metadata Initiative . . . 89
4.7 Metadata Propagation . . . 91
4.7.1 Discussion . . . 97
4.7.2 Context-aware Propagation . . . 97
4.8 Conclusions . . . 98
5 Automatic Metadata Generation Framework 101 5.1 Introduction . . . 101
5.2 Overall Structure . . . 102
5.2.1 ObjectBasedIndexer . . . 104
5.2.2 ContextBasedIndexer . . . 105
5.2.3 Confidence Values . . . 108
5.3 The Simple Indexing Interface . . . 109
5.4 Evaluation . . . 112 5.4.1 ToledoBBContextBasedIndexer . . . 114 5.4.2 Results . . . 117 5.4.3 Further Evaluation . . . 118 5.4.4 Related Experimentation . . . 120 5.5 Related Work . . . 122 5.6 Conclusions . . . 125 6 General Conclusions 127 6.1 Summary . . . 127
6.2 Further Research Topics . . . 130
6.3 Final Reflection . . . 131
7 Een Dynamische Levenscyclus voor Leerobjecten en de Gevolgen voor Automatische Metadatageneratie 133 7.1 Leerobjecten en Leerobject-metadata . . . 133
7.1.1 Leerobjecten . . . 133
7.1.2 Leerobject-metadata . . . 134
7.2 Dynamische Levenscyclus . . . 135
7.2.2 Technologie¨en om Informatie te Vergaren . . . 136
7.3 Automatische Metadata-Generatie . . . 137
7.3.1 Metadatabronnen . . . 137
7.3.2 Meerdere Bronnen - Meerdere Waarden . . . 138
7.4 Formele Model . . . 138
7.5 Raamwerk voor Automatische Metadatageneratie . . . 139
7.5.1 Klassenstructuur . . . 139
7.5.2 The Simple Indexing Interface . . . 139
7.6 Besluit . . . 140
7.6.1 Mogelijk Verder Onderzoek . . . 140
Bibliography 143 Curriculum Vitae 157 Publicaties van de Doctorandus 158 A The Formal Model, Summary 161 A.1 Learning Objects and Metadata . . . 161
A.2 Fuzzy Metadata . . . 161
A.3 Selecting Facet Values . . . 162
A.4 Context-awareness . . . 162
List of Acronyms
AMG Automatic Metadata Generation API Application Program InterfaceARIADNE Alliance of Remote Instructional Authoring and Distribution Networks for Europe
DCMI Dublin Core Metadata Initative
COLIS Collaborative Online Learning and Information Systems ELF E-Learning Framework
IEEE Institution of Electronic and Electric Engineers KPS Knowledge Pool System
LCMS Learning Content Management System LMS Learning Management System
LOR Learning Object Repository LOM Learning Object Metadata
LTSC Learning Technology Standardization Committee MIME Multipurpose Internet Mail Extensions
OAI Open Archives Initiative OCW Open CourseWare OWL Web Ontology Language RDF Resource Description Framwork RLO Reusable Learning Object
SCORM Sharable Content Object Reference Model SII Simple Indexing Interface
SQI Simple Query Interface XML Extensible Markup Language URI Universal Resource Identifier
List of Figures
1.1 The CISCO RLO-RIO Structure . . . 4
1.2 The ARIADNE Structure . . . 12
1.3 The SCORM Bookshelf . . . 18
1.4 The SCORM Content Aggregation Model . . . 19
2.1 Reuse Life Cycle [Vittorini and Di Felice, 2000] . . . 24
2.2 The Traditional Learning Object Life Cycle . . . 27
2.3 The Dynamic Learning Object Life Cycle . . . 29
2.4 Use Scenario for Learning Resources [Van Assche and Vuorikari, 2006] 32 2.5 Information Retrieval/Extraction in the Life Cycle . . . 34
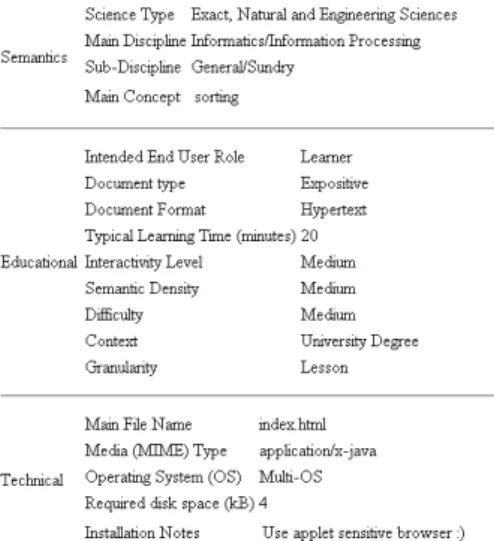
2.6 Learning Object Illustrating a Sorting Algorithm . . . 35
2.7 Language Detection in MS Word . . . 36
2.8 Learning Object Metadata which may be ’copied’ to Related Learn-ing Objects . . . 37
2.9 Learning Object Comparing Sorting Algoirthms . . . 38
2.10 Social Information Retrieval/Extraction in the Life Cycle . . . 39
2.11 Explicit Feedback mechanisms in the Life Cycle . . . 41
2.12 Implicit Feedback in the Life Cycle . . . 42
2.13 Alternative Presentation proposed by [Strijker, 2004] . . . 44
2.14 First-level Issues of the Learning Objects Ontology . . . 45
2.15 COLIS Global Use Case . . . 48
2.16 Workflow in the D2D model . . . 49
3.1 Metadata Information Sources in the Life Cycle . . . 58
3.2 A combination of manually and automatically filled in metadata in the Blackboard LMS. The metadata elements Title, Language, Creation Date and Resource Format are filled in automatically by the system; all elements can be modified by the user. . . 60
3.3 Learning object properties available for metadata harvesting in MS Word. . . 61 3.4 The Attention Metadata Management framework [Najjar et al., 2005] 65
4.1 A Simple RDF Graph . . . 84
4.2 A Structured RDF Graph . . . 85
4.3 A Blank Node in RDF . . . 86
4.4 Resource State/Condition Description Framework . . . 86
4.5 DCMI Resource Model . . . 89
4.6 DCMI Description Model . . . 90
4.7 Metadata Inheritance and Accumulation . . . 95
5.1 Overall Structure of the Automatic Indexing Framework . . . 102
5.2 The Class Hierarchy of ObjectBasedIndexer . . . 103
5.3 The Class Hierarchy of ContextBasedIndexer . . . 106
5.4 Information Flow in the AMG Framework . . . 111
5.5 Typical SII Sequence Diagram . . . 113
5.6 Average Quality Grade for the Metadata [Meireet al., 2007] . . . . 120
5.7 Expected Accuracy Level for Automatic Generation of Dublinc Core [Greenberget al., 2005] . . . 121
5.8 IBM MAGIC’s object analyzers and metadata integretation [Li et al., 2005] . . . 123
5.9 Beagle’s Indexing Process . . . 124
List of Tables
1.1 The Dublin Core Element Set . . . 15
2.1 Mapping of the Learning Object Ontology to Dynamic Life Cycle . 47 2.2 Comparison of the Different Life Cycle Models . . . 51
4.1 Language Detection Accuracy . . . 77
5.1 Methods of the Simple Indexing Interface . . . 114
5.2 Metadata Elements Generated by the Toledo Context . . . 115
5.3 Metadata Elements Generated by the Object-based Indexers . . . 115
5.4 Comparing Automatic and Manual Metadata . . . 119
Preface
In the last decade, learning objects have gained a lot of interest as the basis of a new type of computer-based instruction in which the instructional content is cre-ated from individual components. The interesting aspect of these learning objects are their reusability, adaptability and scalability. One of the current drawbacks is their availability. The availability is defined as the possibility to retrieve the appropriate learning object from a large set. An important aspect of the avail-ability is the usefulness of the associated metadata. The goal of this research is to optimize the availability of the learning objects in order to increase the reusability. This optimization is performed by looking at two major aspects of metadata. First of all, learning object metadata are considered to have a dynamic character. This is represented in the dynamic life cycle of learning objects, which is opposed to the traditionally static approach of the life cycle. Within this life cycle, the labeling phase - the phase in which metadata about the learning object are added - plays an important role, because it allows a continuous update of the metadata during the life cycle of the learning object.
Furthermore, a framework of automatic metadata generation for learning objects is implemented to overcome the problems with manual indexing. Within this frame-work, metadata are generated automatically taking into account different sources of information that are available in the different phases of the life cycle. Exam-ples are the learning objects themselves, user feedback, relationships with other learning objects, and so on. The implementation of this framework is based on a formal model of learning object metadata. This model defines how metadata can be associated with learning objects and how the metadata from different sources can be combined to overcome conflicts between sources. In the formal model we also introduce the notion of context-awareness for learning object metadata.
Contents
Chapter 1: Learning Objects & Learning Object Metadata
This chapter considers which definitions for learning objects and learning object metadata apply in the context of the dynamic life cycle and automatic metadata generation. Both for learning objects and for their metadata, multiple definitions are in use, depending on the context. Chapter 1 provides the appropriate defini-tions and the focal points in this work.
As a general introduction for this research, Chapter 1 refers to current work con-cerning learning objects and metadata, such as the IEEE LTSC LOM standard for learning object metadata and the ARIADNE system. This latter has been the working context for my work. It also briefly describes related research projects which are referred to throughout this text.
The conclusions of Chapter 1 list several problems with learning objects and meta-data, which allow to explain the further structure of this thesis.
Chapter 2: Dynamic Metadata in the Learning Object Life Cycle This chapter deals with the definition of the dynamic learning object life cycle. This is considered as an important factor to enhance the reusability of learning objects, because the metadata of the learning objects will be much richer, repre-senting a.o. real use information. The dynamic life cycle replaces the traditional static life cycle approach of learning objects.
In this dynamic life cycle, the labeling phase is taken out of the life cycle and placed in parallel with all the other phases. In this way, metadata can be added or updated throughout all the phases of the life cycle.
Chapter 2 describes the different sources of information that become available during the life of a learning object and how they can be applied in the labeling phase.
Chapter 3: Automatic Metadata Generation
Automatic metadata generation is important because for two reasons. First, re-search has proven that automatic indexing can be as good as manual indexing. Second, it helps to acquire the critical mass of learning objects to establish real reuse.
LIST OF TABLES xv for reuse or do not create metadata for those objects. As a consequence, that criti-cal mass is not obtained. Most important, the current tools available for metadata creation are not user friendly. Most tools directly relate to some standard and present that standard to the users. The user has to fill in a substantial number of electronic forms. However, the standards are not meant for end users. A direct representation of these standards on forms makes it very difficult and time con-suming to fill out the correct values for metadata in substantial quantities. The aspect of automatic metadata generation is tackled by describing how meta-data can be acquired from different sources of information about the learning objects and how these values can be combined into the metadata for that object. The contribution of this chapter is not the creation of new algorithms or techniques that derive metadata, but a means of integrating different methods to acquire ap-propriate metadata.
The automatic metadata generation process closely relates to the dynamic life cycle because it defines how the different sources of information in the different phases can be applied to provide metadata. The dynamic life cycle enables the application of more advanced information than object-related information only, such as the analysis of the actual learning object use and context information. The use of different sources of metadata introduces possible conflicts between values. Therefore, we have to provide a solution to resolve these conflicts. Chapter 3 introduces a confidence value as a possible solution.
Chapter 4: Formal Reuse and Metadata Model
In this chapter, we formalize the automatic metadata generation model described in the Chapter 3. Such a formal model helps to build a formal reasoning about metadata generation and metadata propagation. In Chapter 5, an automatic in-dexing framework is developed based on the theory described and the formal model given in Chapter 4.
The definition of the formal model is split into three parts. In the first part, learning objects are considered on their own. This means that we do not look at their use in learning environments or their relationships with other learning ob-jects. In this approach the learning objects are also considered black boxes with and unknown internal structure.
In the second part, those learning objects are placed in a context of use related to other learning objects and possibly exposing a defined structure. This approach is more realistic because learning objects are meant to be used in learning contexts and do have relationships with other learning objects within those contexts.
In the third section of this chapter, we introduce metadata propagation rules, that can be used to generate metadata in a specific reuse situation, namely content aggregation and disaggregation. The rules that are defined are an initial proposal, which requires further investigation.
Chapter 5: Automatic Metadata Generation Framework
This chapter describes the reference framework that has been implemented for automatic metadata generation. The implementation is based on the explanations given in the previous chapters.
The development of this framework has partially been performed within the con-text of this research, andcontinues as part of related work. Therefore, the ex-planation of the framework can be divided in two components. In the first, the implementation of automatic indexing is considered. In the second, the framework as a service-oriented architecture is described. The main contribution of the re-search described in this thesis relates to the first part, the automatic indexing. In this thesis, only an initiation of the service-oriented architecture is developed, called the Simple Indexing Framework. This is currently being developed further as the Simple AMG Interface, focusing on the interoperability with learning object repositories.
Chapter 6: General Conclusions
This last chapter provides a general conclusion for this research and points to op-tions for further research concerning the reusability of learning objects.
In this chapter we compare the approach of this work with the current devel-opments on the semantic web or Web2.0. Metadata and the possibility to update these metadata continuously plays an important role for the semantic web and relates closely to our work.
Chapter 1
Learning Objects &
Learning Object Metadata
1.1
Introduction
In this chapter we introduce the domain of learning objects and learning object metadata. The focus of our research is on the enabling of learning object reuse through the availability of appropriate metadata. In section 1.2 this will appear in the definition we apply for learning objects, and for learning object metadata, in section 1.3.
Section 1.4 describes ARIADNE, which is the operational context of this research in which we have developed our automatic indexing framework (see Chapter 5). In section 1.5 we briefly describe related research projects which we often refer to throughout this text.
In section 1.6 we provide some conclusions and summarize the issues that we will tackle in the remainder of this thesis.
1.2
Learning Objects
David Wiley explains the popularity of learning objects in e-learning as follows [Wi-ley, 2001]:
An instructional technology called ”learning objects”currently leads [. . . ] the position of technology of choice in the next generation of instructional design, development, and delivery, due to its potential for reusability, generativity, adaptability, and scalability.
In this description, Wiley introduces an instructional technology which facilitates the design, development, and delivery of learning material. This technology is called ’learning objects’. The potential of this technology is gained from the basis upon which this technology is built, namely the individual components, also called ’learning objects’. These components have the potential for reusability, generativ-ity, adaptabilgenerativ-ity, and scalability. In this research, we focus on the second approach to learning objects, i.e. on the components that can be used in the instructional technology to develop e-learning, instead of the learning technology itself. Learning objects have been approached from many different points of view, re-sulting in a pleiad of definitions. Because of this, it is important that we clearly describe which definition is appropriate for our purpose and which aspects we do not focus on. In the next section we describe the different options for defining learning objects, and explain which definition we are using.
1.2.1
Categories of Definitions
Depending on the focus of research, several definitions of learning objects exist; [Farance, 1999] distinguishes at least three categories of definitions. The definitions in these categories do not have to focus on a single aspect; mostly they combine several important aspects.
• Reusability
The idea of reusable components in instruction is not new. In 1965, Ted Nelson already described settings where information and course design were based on the use of reusable objects taken from interconnected digital li-braries [Nelson, 1965; Oliver, 2001]. Reusability of learning material is one of the main points of interest in learning objects and is mentioned in most of the definitions found.
This object-based principle is based upon the idea that a course or lesson can be built from reusable instructional components which can be built sep-arately but modified to the user’s needs. A learning object is a self-contained component with associated metadata that allow to reuse the object in dif-ferent contexts. Additionally, learning objects are generally understood to be digital entities deliverable over the internet, making them accessible and usable by multiple users in parallel [Wiley, 2001].
Therefore, learning objects are often related to the object-oriented paradigm of software development, although reusability is probably the only link be-tween these two.
Learning resources are objects in an object-oriented model. They have methods and properties. Typical methods include rendering
1.2 Learning Objects 3 and assessment methods. Typical properties include content and relationships to other resources [Friesen, 2001].
The object-oriented paradigm includes much more principles, such as encap-sulation and inheritance which do not apply to learning objects. For example, content models describe explicitly the internal structure of learning objects in different types of components, which contradicts to the idea of encapsu-lation of objects.
Mostly, the definitions of learning objects explicitly refer to the idea of reusability. The IEEE Learning Technology Standardization Committee (LTSC) uses it as the basis for its definition [IEEE, 2002]:
A learning object is defined as any entity, digital or non-digital, which can be re-used or referenced during technology-supported learning.
McGreal also focuses on the reusability of the learning objects, but empha-sizes the importance of standards, both for the learning objects and the metadata that describe them [McGreal, 2002]:
Learning objects enable and facilitate the use of educational con-tent online. Internationally accepted specifications and standards make them interoperable and reusable by different applications in diverse learning environments. The metadata that describe them facilitate searching and render them accessible.
• Goal
In this category of definitions, the focus is on the objective of the learning objects. Each learning object has an associated goal about the knowledge to be achieved or to be accomplished. This learning objective (or ”learn-ing outcome”) is an explicit statement of what the learner is expected to demonstrate after the learning has been completed. A definition stressing this educational goal is the following one1:
A self-contained piece of learning material with an associated learn-ing objective, which could be of any size and in a range of media. Learning objects are capable of re-use by being combined together with other objects for different purposes.
The CISCO Reusable Learning Object Strategy [Barritt and Lewis, 1999] defines Reusable Information Objects (RIO) as the base components for
Figure 1.1: The CISCO RLO-RIO Structure
Reusable Learning Objects (RLO). A RIO is a collection of content items, practice items and assessment items that are combined based on a single learning objective. A Reusable Learning Object is based on a single objec-tive; each RIO is built upon an objective that supports the RLO’s objective. In practice, a RLO corresponds to a lesson, which is part of module. Fig-ure 1.1 shows how such RLO is constructed from RIO’s. Each RLO contains a pre-assessment that allows the learner to check whether he/she is able to start studying the RLO and a post-assessment to see if the content is successfully studied. In order to learn the content, from five up to nine com-ponents are combined into the learning object, preceded by an overview and followed by a summary object. Depending on the results of the assessments, the learner can go directly to the appropriate information objects, study the complete learning object or skip the content of the learning object.
The CISCO strategy also shows the importance of content models to en-able reuse of learning objects. A content model describes the different types of learning objects and their components and how they can be combined to form reusable objects. It provides a more precise definition of what learning objects are and allow us to identify learning object components and repur-pose them [Verbert and Duval, 2004]. Repurposing belongs to the domain of reuse, but stresses the importance of processing learning objects to make them available in multiple contexts, instead of direct reuse. Other content models focussing on these aspects are the SCORM Content Aggregation Model [ADL, 2004] and ALOCoM, a generalized content model for learning objects [Verbert and Duval, 2004].
1.2 Learning Objects 5
• Containerization
A learning object is considered as a separable unit that has boundaries and hides its implementation from the outer world. Again, this category is im-plied from the oriented paradigm; one of the main principles in object-orientation is that of containerization, which helps to enable reuse because the objects become much less dependent on one another if the inner details are hidden. In practice, however, we think that the idea of encapsulation is not completely feasible for learning objects, because the inner details are important for effective reuse, e.g. through content repurposing.
Containerization itself refers explicitly to the possibility of transportation, i.e. copy or transmit, of an object and its associated metadata from one lo-cation to another [Currie and Place, 2000]. Currently, this is also subject of research, such as in the IMS Content Packaging Information model2 or the
SCORM Content Aggregation Model [ADL, 2004].
Because of the black box principle in containerization, this focus also im-plies the need for metadata about learning objects. These metadata enable the possibility to select learning objects for use, without knowing all the in-ner details.
On the other hand, the inner details of the learning object do become im-portant for the automatic metadata generation process, because this process needs the contents and the structure to generate valuable metadata. This containerization aspect only applies to the use of learning objects for learn-ing, and does not apply to our objective of metadata generation.
Next to these categories, [Farance, 1999] describes two other categories that are less commonly used; we briefly mention them here for completeness. In the first cate-gory, learning objects are treated as objects that learn from the interaction with the users. In the second, the focus is on the separation of content and structure. In this category, learning objects contain no course structure, but only content. For our purpose, we can apply the definition of a learning object, given by the IEEE Learning Technology Standardization Committee, mentioned before:
Any entity, digital or non-digital, which can be re-used or referenced during technology-supported learning.
1.2.2
The Interest in Reuse
(Learning objects) reuse is the process of creating (instructional) components from existing components rather than building those components from scratch [Krueger, 1992]. In [Wiley, 2001], one suggestion for the interest in learning objects is given, based on the findings of Reigeluth and Nelson [Reigeluth and Nelson, 1997]:
When teachers first gain access to instructional materials, they often break the material down into their constituent parts. They then re-assemble these parts in ways that support their individual instructional goals. This suggests one reason why reusable instructional components, or learning objects, may provide instructional benefits: if instructors received instructional resources as individual components, this initial step of decomposition could be bypassed, potentially increasing the speed and efficiency of instructional development.
If the speed and efficiency of instructional development is increased, the interest for reuse becomes very attractive for the instructional designers. In this case, the cost of reuse is small enough compared to creating a new learning object. We can compare this with the attractiveness of software reuse, based on the costs of the development and the search for reusable components [Milliet al., 1995].
Generally, a distinction is made between either black box reuse, whereby the ob-ject is reused without modifications, or white box reuse, whereby the component is adapted and then integrated. Although theoretically, black box reuse is applica-ble to learning objects, it will occur in very specific situation only or for learning objects with a very low granularity (very small learning objects). White box reuse – learning object repurposing – is more applicable to learning objects.
The following discussion shows, from a theoretical point of view, when it is eco-nomical interesting to perform learning object reuse instead of developing from scratch. In practice, these calculations are less interesting because most of the fac-tors cannot be calculated in advance.
Black box reuse becomes attractive if the following conditions is met. Csearch
is the cost of searching for the appropriate learning object, p: the chance of find-ing the appropriate learnfind-ing object and Cdevelopment is the cost of developing the
learning object from scratch.
p×Csearch+ (1−p)×[Csearch+Cdevelopment]≤Cdevelopment
or
1.2 Learning Objects 7 or
Csearch≤p×Cdevelopment
Black box reuse is interesting if the chance of finding the appropriate learning objects is large enough (large p) or if the cost of finding that learning object is small enough (smallCsearch).
This inequality reveals two important aspects about learning object repositories. First is the need of a large coverage, i.e. the need for a critical mass of learning ob-jects available in the repository. Secondly, searches must be effective and efficient. To establish this latter, appropriate metadata are an important aspect, where we focus on in this research.
In the case of white box reuse, we have to distinguish between the cost of de-veloping the object from scratch and that of adapting an existing object. The cost of this type of reuse can be expressed as:
Csearch+ (1−p)×(CappproxSearch+q×Cadaptation+ (1−q)×Cdevelopment)
In this expression,qexpresses the chance of finding an appropriate learning object for adaptation to the user’s needs, CapproxSearch is the cost of searching for this
adaptable learning object, andCadaptation is the cost of the adaptation.
For reuse to be attractive, the condition is still that its cost must be less than the cost of developing a new learning object from scratch:
Csearch+ (1−p)×(CappproxSearch+q×Cadaptation+ (1−q)×Cdevelopment)≤
p×Cdevelopment
Adaptation of an existing learning object is more interesting than creating a new learning object from scratch if the cost of the prior is less than the cost of the de-velopment:Cadaptation≤Cdevelopment. The inequality above can then be rewritten
as follows:
Csearch+ (1−p)×CapproxSearch≤p×Cdevelopment
In other words, the cost of searching for a satisfactory learning object, which can reused directly or must be adapted, should be less than the savings made for those cases (100×p%) in which a learning object can be reused directly.
In this formula we accepted the premise that the cost of adaptation is less than the cost of developing from scratch. In general, however, the cost of adaptation grows fast if the portion of contents to be modified goes up. In this case, that premise might not be correct anymore. According to [Milli et al., 1995], it is fair to say that, for software reuse, white box reuse is cost-effective if it is restricted to those cases where modifications are minor, and thus the cost of adaptation is low. The goal of content models and repurposing, in the domain of learning objects, is to provide opportunities for cost-effective white-box reuse, with large modifications. Both formulas stress the importance of low costs in searching for appropriate learning objects, whether for direct reuse, or adaptation. Associating adequate metadata with the learning objects surely helps to decrease this cost and making reuse more attractive.
1.3
Learning Object Metadata
1.3.1
Definition
Comparable to the definition of learning objects, a single definition of metadata does not exist. Different definitions are in use, depending on the working context. Literally, metadata are data about data – information about an object [IEEE, 2002]. The goal of metadata, however, is not only to provide a description about the set of data. The most common goal is enabling the discovery of the objects de-scribed. [Greenberg, 2002] generalizes this idea, and describes metadata as function enablers:
[Metadata are] structured data about an object that support functions associated with the designated object.
Metadata must support the activities and behaviors of the object, by enabling the discovery of the object, but also the application of the object. With respect to learning objects, the main function of the objects is supporting learning; in this case the metadata are the enablers of this learning, for example by allowing to apply the learning object correctly, finding the appropriate learning object (based on the didactic properties),. . .
Secondly, metadata are defined as structured data. Generally, metadata are clas-sified in (at least) the following categories:descriptive metadata,structural meta-data, and administrative metadata [NISO, 2004]. Other categories include rights management andpreservation metadata. The structure of the metadata is defined in metadata schema specifications which serve as the model for a systematic or-dering of the data.
1.3 Learning Object Metadata 9
Because the generation of metadata is also the focus of our research, we refer to the following definition that stresses the importance of the creation of metadata:
Information about a data set which is provided by the data supplier or the generating algorithm and which provides a description of the content, format, and utility of the data set. Metadata provide criteria which may be used to select data for a particular (scientific) investigation3.
This definition also refers to metadata as function enablers, especially the selecting of data.
One of our objectives is to help the data supplier, i.e. the author of the learn-ing object or the indexer, in his/her difficult task by creatlearn-ing automatic metadata suppliers that analyze the learning objects and contexts in which they are used and return metadata based on this analysis.
1.3.2
IEEE Learning Object Metadata (LOM)
In 2002, the IEEE standard 1484.12.1, the Learning Object Metadata Data Model, has been defined [IEEE, 2002]. This standard specifies the syntax and semantics of learning object metadata, defined as the attributes required to adequately de-scribe a learning object in order to enable our ability to discover, manage and use learning objects. The standard accommodates the ability for locally extending the basic fields and entity types, and the fields can have a status of obligatory or optional. Since its definition, it has become a widely adopted standard. All the other learning object initiatives have made their system compliant to this standard. The purpose of the standard is to facilitate search, evaluation, acquisition, and use of learning objects, for instance by learners or instructors or automated software processes. The data model defines a conceptual schema that ensures that different implementations of the standard have a high degree of semantic interoperability. Metadata Schema
The conceptual schema defines metadata elements in nine categories, which form the base schema. All categories, and also the number of categories are extendible for specific goals.
1. General: this category of elements describes the learning object as a whole;
2. Lifecycle: features related to the history and current state of this learning object and those who have affected this learning object during its evolution; 3. Meta-Metadata: information about the metadata instance itself;
4. Technical: technical requirements and technical characteristics of the learn-ing object;
5. Educational: educational and pedagogic characteristics of the learning ob-ject;
6. Rights: intellectual property rights and conditions of use for the learning object;
7. Relation: features that define the relationship between the learning object and other related learning objects;
8. Annotation: provides comments on the educational use of the learning object and provides information on when and by whom the comments were created; 9. Classification: describes this learning object in relation to a particular
clas-sification system.
Metadata elements are either aggregate elements defining a sub-hierarchy of ments or simple elements which contain the actual metadata values. Simple ele-ments are either single-valued or multi-valued. In the latter case, the list of values can be ordered or unordered. In total, the schema defines 77 elements that can be used to describe a learning object. We refer to [IEEE, 2002] for the description of these categories and the elements defined within these categories.
1.4
ARIADNE
1.4.1
Background
ARIADNE was initiated in 1996 by the European Commission’s telematics for ed-ucation and training program as the European eded-ucational digital library project [Duvalet al., 2001; Duval, 1999]. Its goal is to promote the concept of share and reuse of educational resources. Within the project an infrastructure has been de-veloped for the production of reusable learning content, including its description, distributed storage, and discovery as well as its exploitation in structured courses. The ARIADNE architecture is built around a distributed library called the Knowl-edge Pool System, for use in both academic and corporate environments.
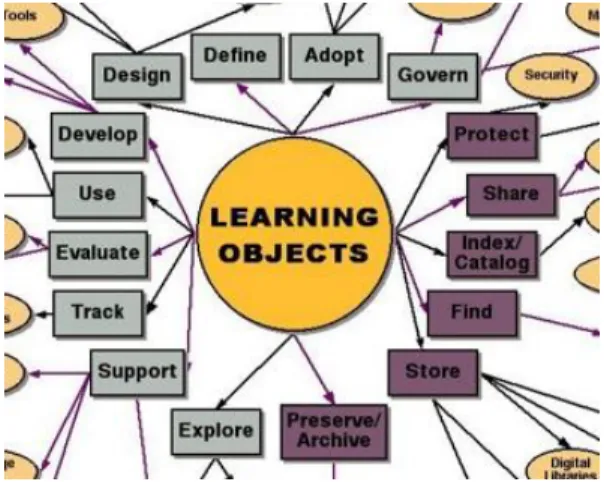
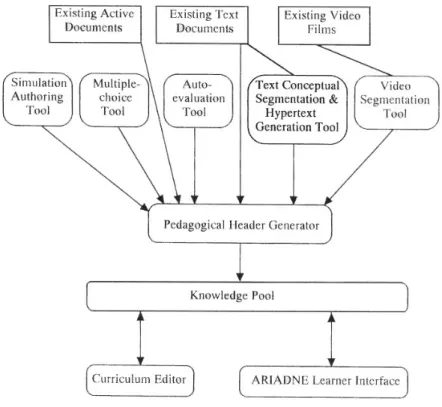
1.4 ARIADNE 11 ARIADNE is to address realistic methodologies, techniques and tools so that learn-ers enrol in, access and use these technology-supported curricula. Different tools are built to accomplish these goals, being categorized in the following classes [Forte et al., 1997a; Forteet al., 1997b] (Figure 1.2):
• Specific theoretical tools: Models or methodologies which are based on theoretical results and which are applicable to pedagogic objects.
• Specific computer tools: Tools based on theoretical models which act on pedagogic elements either to create them, mark them, segment them,. . . An example is the Text Conceptual Segmentation & Hypertext Generation tool.
• Specific pedagogical elements: Software products developed with the specific tools which will constitute the basic material of the knowledge pool;
• General system integration and access tools: Computer- or telematics-based tools or methods applied in a pedagogic context to assemble pedagogic elements into the components of a curriculum. In Figure 1.2, this is indicate as the Curriculum Editor and the ARIADNE Learner Interface.
After the finishing of the ARIADNE and ARIADNE II projects, the ’ARIADNE Foundation for the European Knowledge Pool’ was founded in mid 2000 and the focus of the project slightly shifted to the management of learning objects and metadata. Within the context of the ARIADNE Foundation, research in multiple learning object domains is performed, not only focusing on repositories. Among others, these domains include automatic metadata generation, content models, attention metadata, information visualization for metadata access.
1.4.2
ARIADNE Metadata Recommendation
To enable share and reuse the ARIADNE project defined in the beginning of its work its metadata scheme which had the goal to overcome two problems with the widespread use of any metadata system [Duvalet al., 2000]:
1. indexing should be as easy as possible;
2. the exploitation of the metadata by users should be as easy and efficient as possible.
Together with the IMS project (see next section), ARIADNE submitted in 1998 a joint proposal and specification to the IEEE LTSC which formed the basis for the LTSC Working Group 12 and resulted in the IEEE LOM standard in July 2002 (see above).
The ARIADNE Educational Metadata Recommendation consisted of the following categories of descriptors:
1.4 ARIADNE 13 1. General information on the resource itself,
2. Semantics of the resource, 3. Pedagogical attributes, 4. Technical characteristics, 5. Conditions for use,
6. Meta-metadata information, 7. Annotations (optional),
8. Physical data of the represented educational resource (optional).
Throughout the research and practical experiments with the metadata recom-mendation, the scheme has been updated in different versions but the principal idea of the categories and metadata records has been maintained. Currently, ARI-ADNE has defined a binding between its own metadata schema and the LOM standard, allowing to exchange metadata records between multiple projects. One of the results of applying the standard for metadata is definition of the Simple Query Interface (SQI) which allows to create metadata aggregations and perform aggregated searches among repositories [Simonet al., 2005].
1.4.3
Knowledge Pool System
In essence the Knowledge Pool System (KPS) is a distributed database of multi-media pedagogical documents (learning objects) and their descriptions (metadata) [Cardinaelset al., 1998]. Currently the KPS is also interconnected with other repos-itories, such as MERLOT, CGIAR or EdNA Online. The KPS itself is structured as star-shaped distributed database with a central root node (Central Knowledge Pool or CKP) and local nodes, which are either publicly available or private (Local Knowledge Pool or LKP, and Private Knowledge Pool or PKP).
Metadata information is distributed to all the local nodes and the central nodes; the learning objects themselves, however, are copied to the central node only, un-less a local node explicitly demands that object. A policy of interest in objects is set up to define which objects are also distributed to other local nodes.
To cope with copyrights and fees the KPS allows to distinguish between differ-ent types of learning objects. The first distinction introduced was to have free or not free documents. Later on this policy has been extended to distinguish be-tween documents available for everyone, for ARIADNE members only, for users of a specific knowledge pool or on a negotiation basis.
1.4.4
ARIADNE Life Cycle
Figure 1.2 not only shows the structure of the ARIADNE system, it also shows the life cycle of an ARIADNE learning object in this system. From top to bottom the learning objects pass through the following steps:
1. Learning objects are developed using one of the authoring tools, starting from existing learning objects or from scratch.
2. The metadata are added to the learning object, using the pedagogical header generation, i.e. the indexing tool, called SILO in the current version of ARI-ADNE.
3. The learning object is stored in the Knowledge Pool System together with its metadata record.
4. Courses (called curricula) are created using the curriculum editor, selecting existing learning objects from the KPS.
5. Learners access the learning objects through the curriculum web site. In Chapter 2 we will see that this sequence corresponds well to the traditional learning object life cycle. In that chapter we also propose a new life cycle sup-porting the creation of more advanced metadata, resulting from the actual use of learning objects.
1.5
Related Work
The variety of learning object and metadata definitions indicates the broadness of the research domain learning objects have become. In this section, we provide an overview of several important initiatives that relate to our research. The goal of this section is not to list all initiative exhaustively, but to provide some explana-tion on the projects and developments for further reference.
Most of the initiatives perform research on many learning object-related aspects, comparable to the ARIADNE Foundation, such as metadata, content models, in-teroperability of repositories, and so on. In the description of the related initiatives below, we refer to the most important aspects for dynamic metadata and auto-matic metadata generation.
1.5.1
Dublin Core Metadata Initiative
The Dublin Core Metadata Initiative4 (DCMI) has the mission to make it easier
to find resources using the Internet through several activities:
1.5 Related Work 15 Element Name Definition
Title A name given to the resource
Creator An entity primarily responsible for making the con-tent of the resource
Subject A topic of the content of the resource Description An account of the content of the resource
Publisher An entity responsible for making the resource avail-able
Contributor An entity responsible for making contributions to the content of the resource
Date A date of an event in the life cycle of the resource Type The nature or genre of the content of the resource Format The physical or digital manifestation of the resource Identifier An unambiguous reference to the resource within a
given context
Source A reference to a resource from which the present re-source is derived
Language A language of the intellectual content of the resource Relation A reference to a related resource
Coverage The extent or scope of the content of the resource Rights Information about right held in and over the resource
Table 1.1: The Dublin Core Element Set
• Develop metadata standards for discovery across domains;
• Define frameworks for the interoperation of metadata sets;
• Facilitate the development of community- or disciplinary-specific metadata sets.
The most known result of the DCMI is the Dublin Core Metadata Element Set, a definition of 15 metadata elements that can be applied to any resource (see Ta-ble 1.1). This element set is also referred to as Simple DC, because it is such a simple definition of metadata elements.
This simplicity of Dublin Core can be both a strength and a weakness. Simplicity lowers the cost of creating metadata and promotes interoperability. On the other hand, simplicity does not accommodate the semantic and functional richness sup-ported by complex metadata schemes. In effect, the Dublin Core element set trades richness for wide visibility. The design of Dublin Core mitigates this loss by en-couraging the use of richer metadata schemes in combination with Dublin Core. Richer schemes can also be mapped to Dublin Core for export or for cross-system
searching. Conversely, simple Dublin Core records can be used as a starting point for the creation of more complex descriptions [ISO 15836:2003, 2003].
In parallel with Simple DC an extended version exists, known as Qualified DC, which allows the introduction of any metadata elements which may contain a com-plex structure. In this model, the users can define the metadata elements them-selves or use a mapping from existing standards to the qualified DC.
Dublin Core relates closely to the general metadata standard RDF5, which is
a language to express any information about a resource in the world-wide web. RDF itself does not define which elements to use for the description of resources, but only offers the syntax to create statements.
In Chapter 4, we describe DC and RDF in more detail, when we compare our formal metadata model with these systems.
1.5.2
IMS
IMS was founded in 1997 as the Instructional Management System project with the National Learning Infrastructure Initiative of EDUCAUSE6. Through the years,
the focus of the project has somewhat shifted from the development of those learn-ing management systems to the interoperability of learnlearn-ing systems and content, and only the abbreviated name IMS or the formal name IMS Global Learning Consortium (IMS/GLC) are used nowadays.
To establish the interoperability, IMS focusses on defining specifications for both online and off-line learning settings. An example of such a specification is the IMS Learning Resources Meta-data Specification [McKell and Thropp, 2001], but the scope of the work is much broader than only metadata. Among others, the following specifications are available from the IMS project:
• IMS Content Packaging [Smythe and Jackl, 2004]: an information model for a standardized set of structures that can be used to exchange content between content creation tools, learning management systems, and run time environments;
• IMS Digital Repositories [Riley and McKell, 2003]: to provide recommenda-tions for the interoperation of the most common repository funcrecommenda-tions;
• IMS Learner Information Package [Smytheet al., 2001]: a collection of in-formation about a learner or a producer of learning content to import data into and extract data from an IMS compliant Learner Information server;
5Resource Description Framework: http://www.w3.org/RDF/ 6see http://www.imsglobal.org
1.5 Related Work 17
• IMS ePortfolio [Smytheet al., 2005]: to make ePortfolios interoperable across different systems and institutions.
The development of the IMS data Specification and the ARIADNE Meta-data Recommendation started around the same time and the resulting specifica-tions corresponded very well to each other. Therefore, the two projects started to cooperate for the development of one general standard, resulting in the IEEE LOM specification that we have discussed before.
1.5.3
SCORM
SCORM is an acronym forSharable Content Object Reference Model developed by ADL [ADL, 2004]. The aim of this project is to provide the specifications needed for the developers to produce content that is sharable, reusable, and most impor-tantly interoperable.
The rationale behind the development of the SCORM specifications is based on so-called ’ilities’, properties often associated with learning objects:
• Accessibility: the ability to locate and access instructional components from one remote location and deliver them to many other locations.
• Adaptability: the ability to tailor instruction to individual and organizational needs.
• Affordability: the ability to increase efficiency and productivity by reducing the time and costs involved in delivering instruction.
• Durability: the ability to withstand technology evolution and changes with-out costly redesign, reconfiguration or recoding.
• Interoperability: the ability to take instructional components developed in one location with one set of tools or platform and use them in another location with a different set of tools or platform.
• Reusability: the flexibility to incorporateinstructional components in multi-ple applications and contexts.
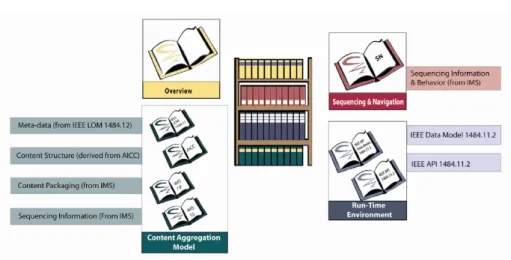
SCORM’s organization is mostly represented as a bookshelf, which is depicted in Figure 1.3, consisting of technical books containing the SCORM specifications. The different technical books are the Content Aggregation Model, theRun-Time Environment book and the Sequencing and Navigation book. As shown in the picture, SCORM integrates technology developments from groups such as IMS, ARIADNE and the IEEE LTSC within a single reference model to specify consis-tent implementations that can be used across the e-learning community.
Figure 1.3: The SCORM Bookshelf
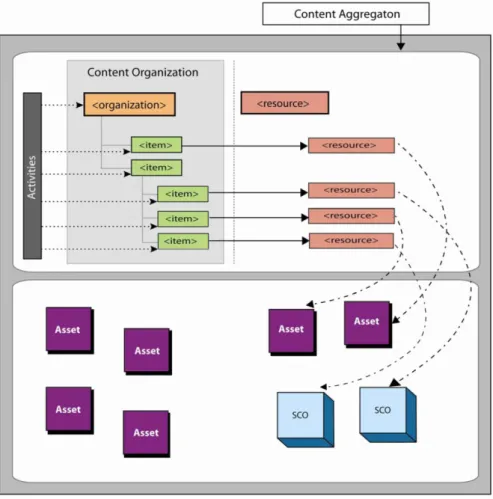
For our work, the Content Aggregation Model (CAM) is the most interesting, be-cause it describes the organization of components to build a learning experience; it defines how the lower level sharable, learning resources are aggregated and or-ganized into higher-level units of instruction. The different components the model distinguishes are Assets, Sharable Content Objects (SCOs), Activities, Content Organization and Content Aggregations. Figure 1.4 shows how the CAM orga-nizes these into content aggregations.
Together with the metadata of a content aggregation, for us, content models are most interesting because they make the relationships between the component ex-plicitly available. For automatic indexing, these relationships can be used to gen-erate metadata automatically in the case of the aggregation (the creation of the aggregate) or disaggregation (the extraction of components for individual reuse). We refer to this in the chapter on automatic indexing (Chapter 3).
1.5.4
Merlot
The Multimedia Educational Resource for Learning and Online Teaching (MER-LOT) is a community of academic institutions, professional discipline organiza-tions, and individual people building a collection of web-based teaching and learn-ing resources where faculty can easily find peer reviewed materials for use in their classes [Malloy and Hanley, 2001]. In practice it acts as a learning object repository but adds some additional features, such as discipline communities and peer-reviews [Vargo et al., 2003]. This latter is part of MERLOT’s strategic goal: to improve
1.5 Related Work 19
the effectiveness of teaching and learning by increasing the quantity and quality of peer reviewed online learning materials that can be easily incorporated into faculty designed courses.
MERLOT was the first repository in which search results were offered accord-ing to their peer review rankaccord-ing. Peer reviews are performed on three dimensions: quality of content,ease of use, andpotential effectiveness as a teaching tool. Qual-ity of Content encompasses both the educational significance of the content and its accuracy or validity. Ease of Use encompasses usability for first-time users, aes-thetic value, and provision of feedback to user responses. Potential effectiveness as a teaching tool encompasses the pedagogically appropriate use of media and interactivity, and clarity of learning goals [Nesbit et al., 2002].
Currently (October, 2006) MERLOT contains about 15.000 learning resources in seven different disciplines: Arts, Business, Education, Humanities, Mathematics and Statistics, Science and Technology, and Social Sciences. The system allows to create personal collections of material and to define and store assignments using the material found. Both the collections and assignments can be viewed by the community members.
1.6
Conclusions
In this chapter we have introduced the important subjects of this thesis: learning objects and learning object metadata. From the amount of definitions available we discussed which definitions are applicable for our purpose, focusing on the as-pects our research is about. We are aware of the incompleteness of this overview, but assembling a exhaustive overview of research about both learning objects and learning object metadata would lead us too far. For example, we almost completely ignored the instructional use of learning objects, which itself is a broad domain of research.
Although the definition of the IEEE LOM standard has led to a wide adoption of learning objects metadata, learning objects still suffer from the difficulty to create metadata. As a consequence we note that:
• Most reuse initiatives still struggle to achieve a critical mass of learning objects to really establish reuse,
• Many learning objects only have a very limited set of metadata associated to them [Najjaret al., 2003; Najjaret al., 2004],
• Currently, metadata are added only once and remain unchanged afterwards, during the further life of the learning object.
1.6 Conclusions 21 Both the critical mass and the amount of adequate metadata play an important role in the cost-expression for reuse to be attractive, as we discussed in section 1.2.2.
We consider several reasons why users often do not make the learning objects available for reuse or do not create metadata for those objects (see also [Duval and Hodgins, 2003; Greenberg et al., 2003]). Most importantly, the current tools available for metadata creation are not user friendly. Most tools directly relate to some standard and present that standard to the users. The user has to fill in a sub-stantial number of electronic forms. However, such standards were not meant to be visible to end users. A direct representation of these standards on forms makes it very difficult and time consuming to fill out the correct values for the metadata in substantial quantities. The slogan that ”electronic forms must die”addresses this specific concern.
To overcome the problem of the static metadata, we introduce in Chapter 2 the dynamic life cycle for learning objects. In this life cycle the labeling phase is taken out of the sequence and put on top of the other phases, allowing to add metadata in every other phase of the life cycle. During the life of the learning object, multiple sources of metadata will provide information for this labeling phase, contributing metadata to the learning object.
A possible solution to the problem of a lack of metadata, is the automatic creation of it. In that way, the users do not have to bother about the metadata if they do not want to. This can be compared with search engines on the web that index web pages in the background without any intervention of the creator or the host of the site. In our approach, if the user wants to correct, add or delete metadata, he/she will still be able to do so, but most users will not need to spend time on it. In Chapter 3, we discuss the options for automatic metadata generation using dif-ferent information sources, introduced in the dynamic life cycle. In Chapter 4, we create a formal model that allows to implement the automatic indexing framework, discussed in Chapter 5.
Chapter 2
Dynamic Learning Object
Life Cycle
2.1
Introduction
Every object, whether or not an electronic one, from its creation on, passes through a life cycle. With respect to the metadata, the learning object life cycle has been neglected by most of the management systems or those systems considered the metadata to be very static. However, dynamic metadata can reflect much more advanced information, that cannot be obtained in a static life cycle, and thus en-able more advanced use of these metadata.
In this chapter we define the learning object life cycle from the dynamic meta-data point of view. In contrast to the traditional point of view, the metameta-data can be updated in every phase of the life cycle; the traditional approach considers the indexing phase a singular event before the learning object is offered for reuse. In the dynamic approach, metadata become available in every stage of the life cycle and enhance the information constantly.
One of the main aspects we look at in this dynamic life cycle, is the availability of multiple sources of information about the learning object which provide informa-tion at different moments in that cycle. In Chapter 3 we describe how metadata can be generated automatically, based on these different sources of information in the life cycle. In that chapter we also refer to possible conflicts in the generated metadata and discuss options to overcome these problems.
The organization of this chapter is as follows. In section 2.2 we first describe the basis of our life cycle, the reuse life cycle for for courseware reuse. We
Figure 2.1: Reuse Life Cycle [Vittorini and Di Felice, 2000]
ply this reuse life cycle to base our information flow on in the dynamic learning object life cycle. Next, section 2.3 discusses the traditional life cycle of learning objects. In section 2.4 we introduce the dynamic learning object life cycle. Section 2.5 then describes how the labeling phase in this life cycle must be interpreted. In section 2.6 we compare the dynamic life cycle to related models. Finally, section 2.7 provides some general conclusions concerning this life cycle.
2.2
Reuse Life Cycle
2.2.1
Two Development Phases
We have based our idea of dynamic metadata on the reuse life cycle for course-ware, defined by [Vittorini and Di Felice, 2000] (see Figure 2.1). This courseware life cycle is an adaptation of the life cycle defined by [Milliet al., 1995] for software development. This life cycle distinguishes between two main phases in the devel-opment: the first phase is the developmentforreuse, the second the development with reuse.
The important aspect of this life cycle is the influence of both phases on each other. The latter phase benefits from the first, but also influences it and vice versa: knowledge is transferred back and forth between phases.
1. In theory, in the first phase of this cycle, new objects are created for direct use, but attention should be paid to the reusability. This is done through the following activities during the development:
2.2 Reuse Life Cycle 25
• Classification.
Qualification and generalization is performed to qualify a component for reuse by evaluating the cost to build it, its usefulness and quality, and then generalized by a particular abstraction mechanism.
The generalization step is very interesting for software reuse because the developers benefit from the use of generic types. A generic object can be in-stantiated according to the current needs of the development requesting only little effort. A well-known example of a generic type is a list. Lists are defined very generally and can be instantiated to contain elements of a specific type when needed:
Generic declaration: List<T>
Instantiated examples: List<Integer>
List<Animal>
For the generalization of learning objects, we distinguish between two types: first-order and second-order learning objects. In the discussion on the def-inition of learning objects, D. Wiley [Wiley, 2003] suggests that ”learning objects should not contain content at all; rather, they should contain the educational equivalent of algorithms instructional strategies (teaching tech-niques) for operating on separately available, structured content”. This has led to the distinction of different types of learning objects, called first-order and second-order learning objects. These are defined as follows [Allertet al., 2004]:
• First-Order Learning Objects are resources which are created or re-designed towards a specific learning objective. The learning objective is an integral part of the first-order learning object, no matter if it is explicitly stated or not.
First-order learning objects, in general, only exploit the possibility of presentation generalization (presentation-generative in [Wiley, 2001]). Generalization of content in first-order learning objects is more diffi-cult, because of the close relationship between content and learning objective.
• Second-Order Learning Objects provide and reflect learning strategies, such as problem-solving or decision making strategies operating on the first-order learning objects.
![Figure 2.1: Reuse Life Cycle [Vittorini and Di Felice, 2000]](https://thumb-us.123doks.com/thumbv2/123dok_us/1602797.2716766/44.892.238.649.194.404/figure-reuse-life-cycle-vittorini-and-felice.webp)
![Figure 2.4: Use Scenario for Learning Resources [Van Assche and Vuorikari, 2006]](https://thumb-us.123doks.com/thumbv2/123dok_us/1602797.2716766/52.892.256.634.186.524/figure-use-scenario-learning-resources-van-assche-vuorikari.webp)


![Figure 2.13: Alternative Presentation proposed by [Strijker, 2004]](https://thumb-us.123doks.com/thumbv2/123dok_us/1602797.2716766/64.892.307.583.199.383/figure-alternative-presentation-proposed-by-strijker.webp)