OUTLIER MINING IN MEDICAL
DATABASES BY USING STATISTICAL
METHODS
PROF. DR. P. K. SRIMANI*
Former Chairman, Dept. of Computer Science and Maths, Bangalore University, Director, R&D, B.U., Bangalore
MANJULA SANJAY KOTI**
Assistant Professor, Department of MCA, Dayananda Sagar College of Engineering, Bangalore Research Scholar, Bharathiar University, Coimbatore
Abstract
Outlier detection in the medical and public health domains typically works with patient records and is a very critical problem. This paper elaborates how the outliers can be detected by using statistical methods. A total of 78, 67, 82, 78 and 69 outliers in five medical datasets are detected for the statistics namely leverage, R-standard, R-student, DFFITS, Cook’s D and covariance ratio. The results of the present investigation suggest that (i) the extraordinary behavior of outliers facilitates the exploration of the valuable knowledge hidden in their domain and help the decision makers to provide improved, reliable and efficient healthcare services (ii) medical doctors can use the present experimental results as a tool to make sensible predictions of the vast medical databases and finally (iii)a thorough understanding of the complex relationships that appear with regard to patient symptoms, diagnoses and behavior is the most promising area of outlier mining.
Keywords: Data Mining, Medical data , Outliers, Statistical, Regression
1. Introduction
In recent years, conventional database querying methods are inadequate to extract useful information, and hence researches nowadays are focused to develop new techniques to meet the raised requirements. It is to be noted that the increase in dimensionality of data gives rise to a number of new computational challenges not only due to the increase in number of data objects but also due to the increase in number of attributes.
Outlier detection is an important research problem that aims to find objects that are considerably dissimilar, exceptional and inconsistent in the database. Medical application is a high dimensional domain hence determining outliers is found to be very tedious due to the Curse of dimensionality. There are various origins of outliers. With the growth of the medical dataset day by day, the process of determining outliers becomes more complex and tedious. Efficient detection of outliers reduces the risk of making poor decisions based on erroneous data, and aids in identifying, preventing, and repairing the effects of malicious or faulty behavior. Additionally, many data mining and machine learning algorithms, and techniques for statistical analysis may not work well in the presence of outliers. Outliers may introduce skew or complexity into models of the data, making it difficult, if not impossible, to fit an accurate model to the data in a computationally feasible manner. For example, statistical measures of the data may be skewed because of erroneous values, or the noise of the outliers may obscure the truly valuable information residing in the data set. Accurate and efficient removal of outliers may greatly enhance the performance of statistical and data mining algorithms and techniques [Hadi A. S. et al.,(2009)]. Detecting and eliminating such outliers as a pre-processing step for other techniques is known as data cleaning. As can be seen, different domains have different reasons for discovering outliers: They may be noise that we want to remove.
is an important task in data mining. Outlier detection as a branch of data mining has many important applications and deserves more attention from data mining community [Jiawei Han (2008)].
To statisticians, unusual observations are generally either outliers or ‘influential’ data points. In regression analysis, the unusual observations are categorized as: outliers, high leverage points and influential observations. Outlier is an observation in a data set which appears to be inconsistent with the remainder of the set of data [Hawkins et al., (1984)]. In other words, an outlier is an observation that deviates so much from other observations as to create suspicion such that it was generated by a different mechanism . Statistical approaches assume that the objects in a data set are generated by a stochastic process (a generative model). The two methods are parametric and non-parametric. TheParametric method assumes that the normal data is generated by a parametric distribution with parameter θ.The probability density function of the parametric distribution f(x,
θ) gives the probability that object x is generated by the distribution. The smaller this value, the more likely x is an outlier. The non-parametric method does not assume an apriori statistical model and determine the model from the input data. This is not completely parameter free but considers the number and nature of the parameters as flexible and not fixed in advance. Examples are histogram and kernel density estimation. Statistical methods (also known as model-based methods) assume that the normal data follow some statistical model (a stochastic model).The data which does not follow the model are outliers. This first uses Gaussian distribution to model the normal data. For each object y in region R, estimate gD(y) and the probability of y fits the Gaussian distribution. If gD(y) is very low, y is unlikely generated by the Gaussian model, thus an outlier.
Statistical outlier detection techniques are essentially model-based techniques; i.e. they assume or estimate a statistical model which captures the distribution of the data, and the data instances are evaluated with respect to how well they fit the model [Suzuki et al., (2003)]. If the probability of a data instance to be generated by this model is very low, the instance is deemed as an outlier. The need for outlier detection was experienced by statisticians as early as 19th century. The presence of outlying or discarding the observations in a data encouraged statistical analysis being performed on the data [Barnett et al., (1994)]. This led to the notion of accommodation or removal of outliersin different statistical techniques.
In the regression methods for the outlier analysis, two approaches are distinguished. In the framework of the first approach, the regression model is constructed with the use of all data; then, the objects with the greatest error are successively, or simultaneously, excluded from the model. This approach is called a reverse search. The second approach consists in constructing a model based on a part of data and, then, adding new objects followed by the reconstruction of the model. Such a method is referred to as a direct search [Knorr et al., (1998)]. Then, the model is extended through addition of most appropriate objects, which are the objects with the least deviations from the model constructed. The objects added to the model in the last turn are considered to be outliers. Basic disadvantages of the regression methods are that they greatly depend on the assumption about the error distribution and need a priori partition of variables into independent and dependent ones.
1.1 Literature Survey
Some of the recent works in this direction include [Srimani and Manjula (2011)]. The most extensive effort in this direction has been done by[Hodge and Austin (2004)]. But they have only focused on outlier detection techniques developed in machine learning and statistical domains. Most of the other reviews on outlier detection techniques have chosen to focus on a particular sub-area of the existing research. A short review of outlier detection algorithms using data mining techniques was presented by [Markou and Singh (2003a)]. Markou and Singh presented an extensive review of novelty detection techniques using neural networks [Markou and Singh (2003b)] and statistical approaches [Lazarevic et al., (2003)]. Outlier detection techniques developed specially for system call intrusion detection have been reviewed by[Snyder (2001)], [Forrest (1999)] and later by Dasgupta and Nino (2000). A substantial amount of research on outlier detection has been done in statistics and has been reviewed in several books [Rousseeuw et al., (1987)] as well as other reviews [Beckman (1983) and Tang et al., (2006)] provide a unification of several distance based outlier detection techniques. These related efforts have either provided a coarser classification of research done in this area or have focused on a subset of the gamut of existing techniques. No work is available in this direction.
2. Materials and Methods
Table 1
Specification for the medical data set
Sl.No Medical dataset No. of
instances
No. of attributes
No. of classes
1 Bupa Liver disorders 345 7 2
2 Parkinson 198 24 3
3 Statlog Heart 270 14 2
4 Thyroid 216 6 3
5 Haberman 306 4 2
Table 1, presents the five types of medical datasets namely viz., Bupa liver, Parkinson, Statlog heart, Thyroid and Haberman considered in the present work along with their specifications. The resources for these medical datasets are available from the UCI repository of standard data sets [http:archieve.ici.edu] [Little (2007)].
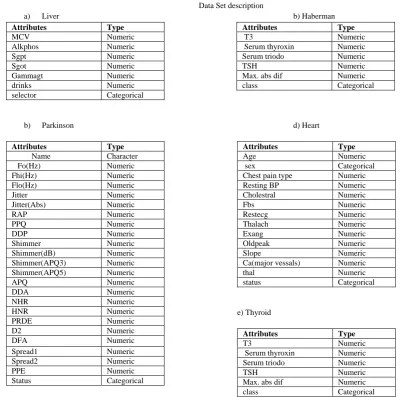
Table 2 Data Set description
a) Liver b) Haberman
Attributes Type MCV Numeric Alkphos Numeric Sgpt Numeric Sgot Numeric Gammagt Numeric drinks Numeric selector Categorical Attributes Type
T3 Numeric
Serum thyroxin Numeric
Serum triodo Numeric
TSH Numeric
Max. abs dif Numeric
class Categorical
b) Parkinson d) Heart
Attributes Type
Name Character
Fo(Hz) Numeric
Fhi(Hz) Numeric Flo(Hz) Numeric Jitter Numeric Jitter(Abs) Numeric RAP Numeric PPQ Numeric DDP Numeric Shimmer Numeric Shimmer(dB) Numeric Shimmer(APQ3) Numeric Shimmer(APQ5) Numeric APQ Numeric DDA Numeric NHR Numeric HNR Numeric PRDE Numeric D2 Numeric DFA Numeric Spread1 Numeric Spread2 Numeric PPE Numeric Status Categorical Attributes Type Age Numeric
sex Categorical
Chest pain type Numeric
Resting BP Numeric
Cholestral Numeric Fbs Numeric Restecg Numeric Thalach Numeric Exang Numeric Oldpeak Numeric Slope Numeric
Ca(major vessals) Numeric
thal Numeric status Categorical
e) Thyroid
Attributes Type
T3 Numeric
Serum thyroxin Numeric
Serum triodo Numeric
TSH Numeric
Max. abs dif Numeric
class Categorical
Table 2, presents the structure of the five medical datasets considered for the purpose of analysis.
attributes in the data set are either continuous or categorical. Having different attribute types in a data set makes it difficult to find relations between two attributes (for example, the correlation between the attributes) and to define distance or similarity metrics for such data points (for example, what is the distance between the TCP and UDP protocols?). When processing data sets with a mixture of attribute types, many techniques homogenize the attributes by converting the continuous attributes into categorical attributes by discretization (quantization), or converting categorical attributes into continuous attributes by applying some (arbitrary) ordering, which can lead to a loss in information and an increase in noise.
Regression is a data mining (machine learning) technique used to fit an equation to a data set. There are two kinds of linear regression: 1) simple linear regression, and 2) multiple linear regressions (also known as multivariate linear regression). In Simple linear regression there is only one dependent variable (also known as an outcome, or response variable) and one independent variable (also known as a predictor or explanatory variable). In the case of Multiple linear regression there is one dependent variable and two or more independent variables. The simplest form of regression i.e., linear regression, uses the formula of a straight line (y = mx + b) and determines the appropriate values for m and b to predict the value of y based upon a given value of x. It is possible to fit more complex models by using advanced techniques which allow more than one input variable [Knorr (1998)].
Regression models are tested by computing various statistics that measure the difference between the predicted values and the expected values. The historical data for a regression project is typically divided into two data sets: one for building the model, the other for testing the model.
Regression modeling has many applications in trend analysis, business planning, marketing, financial forecasting, time series prediction, biomedical and drug response modeling, and environmental modeling. Methods for detecting outliers based on the regression analysis are also classified among statistical methods. The regression analysis problem consists in finding a dependence of one random variable (or a group of variables) Y on another variable (or a group of variables) X. Specifically, the problem is formulated as that of examining the conditional probability distribution. Regression model based on outlier detection techniques typically analyse the residuals obtained from the model fitting process to determine how outlying an instance with respect to the fitted regression model is.
Grubbs' test is also called as ESD method (extreme studentized deviate). The first step is to quantify how far the outliers is from the others. Then the second step is to calculate the ratio Z as the difference between the outlier and the mean divided by the SD. If Z is large, the value is far from the others. Finally, the mean and SD are calculated from all values, including the outlier.
3. Experimental Results and Discussion
Performance of a multiple linear regression analysis for a large set of data would be immensely time-consuming. Hence statistical analysis software could be used to quickly perform the test. The results obtained by using such software on the five medical datasets clearly predict: (i) R² value and (ii) p-value. The results are presented in Table 3.
Table 3 Global results
Dataset Endogenous attribute
Sample R2 Adjusted- R2 Sigma error F-test
Bupa liver Selector 345 0.1336 0.1182 0.4641 8.6909
Parkinson Status 198 0.4927 0.4278 0.3266 7.5945
Statlog Heart Status 270 0.5452 0.5221 0.3441 23.6111
Thyroid Class 216 0.4633 0.4504 0.5387 36.0869
Haberman Status 306 0.0898 0.0808 0.4149 9.9395
An test is any statistical test in which the test statistic has the distribution under the null hypothesis. The F-test in one way analysis of variance is used to assess whether the expected values of a quantitative variable within several predefined groups, differ from each other. The alpha value arising from a test gives the p-value. Degrees of freedom is an integer value measuring the extent to which an experimental design imposes constraints upon the pattern of the mean values of data from various meaningful subsets of data.
Table 4 Analysis of Variance
Dataset Regression Residual Total
xSS d.f. xMS F xSS d.f. xMS xSS d.f.
Bupa liver 11.23 6 1.87 8.69 72.82 338 0.2155 84.05 344
Parkinson 17.82 22 0.81 7.59 18.35 172 0.1067 36.18 194
Statlog Heart 36.34 13 2.79 23.61 30.31 256 0.1184 66.66 269
Thyroid 52.36 5 10.47 36.08 60.65 209 0.2902 113.02 214
Haberman 5.13 3 1.711 9.93 51.12 305 0..1722 57.12 305
From Table 4, it is found that the p-value is zero for all the cases. Further if the p‐value is lower than the significance level of test α (probability of the outcome under the null hypothesis), then the model is considered to be significant.
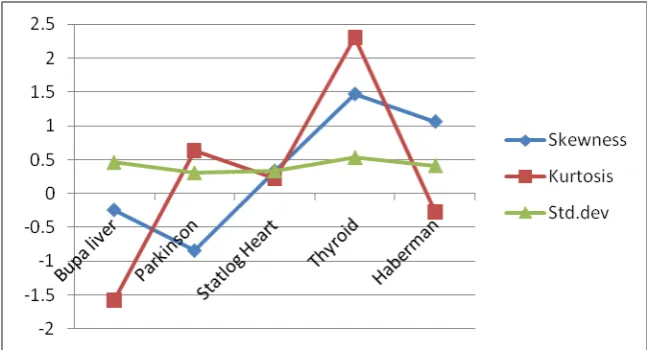
Fig. 1. Variation of Skewness, Kurtosis and Standard deviation
From fig.1, it is observed that the kurtosis is of subGuassian type. The standard deviation is almost in the same range for all datasets whereas the datasets liver and Parkinson exhibit negative skewness and the other three datasets exhibit positive skewness. There is a drastic variation in the results with regard to the different datasets. This would certainly help in the effective diagnosis of the diseases.
Table 5 Residuals
a) Liver b) Parkinson
c) Heart d) Thyroid
d) Haberman
TABLE 6
Outliers and influantial points detection for regression
Statistic Liver Parkinson Heart
LB UB #detected LB UB #detected LB UB #detected
Leverage - 0.0406 31 - 0.2359 15 - 0.1037 6
RStandard - - 0 - - 0 - - 0
RStudent -2.00 2.00 0 -2.00 2.00 10 -2.00 2.00 19
DFFITS -0.2849 0.2849 14 -0.6869 0.6869 7 -0.4554 0.4554 22
Cook’s D - 0.0118 14 - 0.0233 4 - 0.0156 19
|COVRATI| 0.9391 1.0609 19 0.6462 1.3538 31 0.8444 1.1556 16
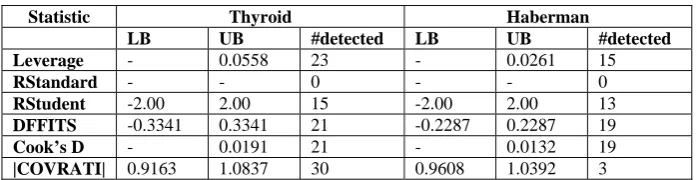
TABLE 7
Outliers and influantial points detection for regression
Statistic Thyroid Haberman
LB UB #detected LB UB #detected
Leverage - 0.0558 23 - 0.0261 15
RStandard - - 0 - - 0
RStudent -2.00 2.00 15 -2.00 2.00 13
DFFITS -0.3341 0.3341 21 -0.2287 0.2287 19
Cook’s D - 0.0191 21 - 0.0132 19
|COVRATI| 0.9163 1.0837 30 0.9608 1.0392 3
From Tables 6 and 7, it is found that 78 outliers for liver, 67 for Parkinson, 82 for heart, 110 for Thyroid and 61 for Haberman medical datasets are detected.
It is important to note that the Statistical methods possess a number of undoubted advantages. Firstly, they are mathematically justified. For example, the verification of competing hypotheses is a conventional problem of mathematical statistics, which can be applied to statistical models used and, in particular, to the detection of outliers. Secondly, if a probabilistic model is given, statistical methods are very efficient and make it possible to reveal the meaning of the outliers found. Thirdly, after constructing the model, the data on which the model is based are not required. It is sufficient to store the minimal amount of information that describes the model. However, statistical models have some disadvantages also, which make their use in data mining systems inconvenient. One of the main disadvantages of statistical methods is that they require either construction of a probabilistic data model based on empirical data, which is a rather complicated computational task, or a priori knowledge of the distribution laws.
4. Conclusion
Acknowledgement
One of us Mrs. Manjula Sanjay Koti is grateful to Bharathiar University, Tamil Nadu for providing the facilities to carry out the research work.
References
[1] Hadi A.S., A.H.M.R. Imon, and M. Werner, “Detection of outliers,” Computational Statistics, vol. 1, 2009, 57-70. [2] Jiawei Han and Kamber. Data Mining Concepts and Techniques , II Edition, 2008, 451-453.
[3] Hawkins, D. M., Bradu, D., and Kass, G. V. 1984. Location of several outliers in multiple-regression data using elemental sets. Technometrics 26, 3 (August), 197-208.
[4] Suzuki, E., Watanabe, T., Yokoi, H., and Takabayashi, K. 2003. Detecting interesting exceptions from medical test data with visual summarization. In Proceedings of the 3rd IEEE International Conference on Data Mining. 315-322.
[5] Barnett, V. and Lewis, T., “Outliers in Statistical Data,” 3rd ed. UK : Wiley, Chicester, 1994.
[6] Knorr, E. M. and Ng, R. T. 1998. Algorithms for mining distance-based outliers in large datasets. In Proceedings of the 24rd International Conference on Very Large Data Bases. Morgan Kaufmann Publishers Inc., 392-403.
[7] Srimani, P. K. and Manjula Sanjay Koti, 2011. Application Of Data Mining Techniques For Outlier Mining In Medical Databases”, IJCR,, Vol. 33, Issue, 6,,402-407.
[8] Srimani, P. K. and Manjula Sanjay Koti, Acomparison of different learning models used in data mining for medical data, AIP Conf. Proc. 1414, 51-55 (2011); doi: 10.1063/1.3669930.
[9] Srimani, P. K. and Manjula Sanjay Koti, 2011.The impact of rough set approach on medical diagnosis for cost effective Feature selection. IJCRVol. 3, Issue, 12, 175-178,
[10] Hodge, V. and Austin, J. 2004. A survey of outlier detection methodologies. Artificial Intelligence Review 22, 2, 85-126. [11] Petrovskiy, M. I. 2003. Outlier detection algorithms in data mining systems. Programming and Computer Software 29, 4, 228-237. [12] Markou, M. and Singh, S. 2003b. Novelty detection: a review-part 2: neural network based approaches. Signal Processing 83, 12,
2499-2521.
[13] Markou, M. and Singh, S. 2003b. Novelty detection: a review-part 2: neural network based approaches. Signal Processing 83, 12, 2499-2521.
[14] Lazarevic, A., Ertoz, L., Kumar, V., Ozgur, A., and Srivastava, J. 2003. A comparative study of anomaly detection schemes in network intrusion detection. In Proceedings of the Third SIAM International Conference on Data Mining. SIAM.
[15] Snyder, D. 2001. Online intrusion detection using sequences of system calls. M.S. thesis, Department of Computer Science, Florida State University.
[16] Forrest, S., Warrender, C., and Pearlmutter, B. 1999. Detecting intrusions using system calls: Alternate data models. In Proceedings of the 1999 IEEE Symposium on Security and Privacy. IEEE Computer Society, Washington, DC, USA, 133-145. [17] Dasgupta, D. and Nino, F. 2000. A comparison of negative and positive selection algorithms in novel pattern detection. In
Proceedings of the IEEE International Conference on Systems,Man, and Cybernetics. Vol. 1. Nashville, TN, 125-130.
[18] Rousseeuw, P. J. and Leroy, A. M. 1987. Robust regression and outlier detection. John Wiley & Sons, Inc., New York, NY, USA.
[19] Beckman, R. J. and Cook, R. D. 1983. Outlier...s. Technometrics 25, 2, 119-149.
[20] Tang, J., Chen, Z., Fu, A. W., and Cheung, D. W. 2006. Capabilities of outlier detection schemes in large datasets, framework and methodologies. Knowledge and Information Systems 11, 1, 45-84.
[21] Kristin B. DeGruy, 2000. Healthcare Applications of knowledge discovery in databases, JHIM, vol 14, no.2 [22] http://archive.ics.uci.edu/