Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2897
A Feature selection on deep web Search data using two
web stage crawlers
MIRZA ASADULLAH BAIG1,MOHAMMED SOFIYAN MIRZA2, ABU HURAIRAH3 & SALMA
SULTANA4
1B-Tech Dept. of CSE,Lords Institute of Engineering & Technology, Hyderabad
Mail Id: - [email protected]
2B-Tech Dept. of CSE,Lords Institute of Engineering & Technology, Hyderabad
Mail Id: - [email protected]
3B-Tech Dept. of CSE,Lords Institute of Engineering & Technology, Hyderabad
Mail Id: - [email protected]
4Assistant Professor Dept. of CSE,Lords Institute of Engineering & Technology, Hyderabad
Mail Id: - [email protected]
Abstract
The main idea is to propose a an efficient harvesting deep-web interfaces using site ranker and adoptive learning methodology framework, concretely two keenly intellective Crawlers, for efficient accumulating deep web interfaces. The cyber world is a verity collection of billions of web pages containing terabytes of information arranged in thousands of servers using HTML. The size of this amassment itself is a difficult to retrieving required and relevant information. This made search engines a paramount part of our lives. To realize supplemental correct results for a targeted crawl, keenly belong to the Crawler, ranks websites to inductively authorize prodigiously relevant ones for a given topic. Within the second stage, smart Crawler, achieves quick in website looking by excavating most useful links with associate degree accommodative link -ranking. Search engines strive to retrieve information as useful as possible. One of the building blocks of search engines is the Web Crawler. Within the first stage, A Smart WebCrawler performs site-predicated sorting out center pages with the support of search engines, evading visiting an oversized variety of pages.
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2898
1.
Introduction
A web crawler is systems that avoid over internet storing and gathering data in to database for further arrangement and analysis. The process of web crawling involves collecting pages from the web. After that they arranging way the search engine can retrieve it efficiently and facilely. The critical objective can do so expeditiously. Additionally it works efficiently and moving without much interference with the functioning of the remote server. A web crawler commences with a URL or a list of URLs, called seeds. It can visited the URL on the top of the list Other hand the web page it probes for hyperlinks to other web pages that signifies it integrates them to the subsisting list of URLs in the web pages list. Web crawlers are not a centrally managed repository of info. The web can covered by a set of concurred protocols and data formats, like the Transmission Control Protocol (TCP), Domain Name Accommodation (DNS), Hypertext Transfer Protocol (HTTP), Hypertext Markup Language (HTML).Also the robots omission protocol perform role in web. The veryhuge volume of information which results related can only download an inhibited number of the Web pages within a given time, so it requires prioritizing it downloads. High rate of change can implicatively insinuate pages might have already been update. Crawling
policy is amply large; search engines can cover only a portion of the publicly available part. Every day, most of the web users limit their searches to the online, thus the specialization in the contents of websites we will reduce this text to look in search engines.
A search engine employs special code robots, or spiders, to make list of the words found on websites to find information on the many sufficient sites that live. Once a spider is building its list, the application is termed web crawling. (There are unit some disadvantages to line a component of the web the globe Wide web an oversized set of spiders – (centric names for implements is one among them.) So as to make and maintain a subsidiary list of words, a look engine's spiders ought to cross - check plenty of pages. We have developed an example system that's designed categorically crawl entity content representative. The crawl method is optimized by exploiting options distinctive to entity -oriented sites. In this paper, we are going to concentrate on describing compulsory elements of our system, together with question generation, empty page filtering and URL for not duplication.
2.
Related Work
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2899
maintain and functionality for which the crawler is built. The first ever web crawler to be built to planarity function is the WebCrawler in 1994. Subsequently of other better and more efficient crawlers were built over the years. There are units many key reasons why subsisting approaches don't seem to be very well fitted to maintain. First of all we visually observe, most antecedent work aims to optimize coverage of individual sites, that is, to retrieve the maximum amount deep-web content as within reach from one or a couple of sites, wherever resources is quantified by proportion of content retrieved. Searching move as depth as suggesting to crawl victimization routine stop words a, the etc. to enhance website coverage once these words area unit indexed. We have a tendency to area in line with in to modify content coverage for ahuge range of web sites on the online. Due to the sheer number of deep -web sites crawled we have a scientific discipline predicated sampling ignores the authentic fact that one IP address may have many virtual hosts, so missing several websites. To resolve the drawback of IP predicated splicing within the information Crawler, Denis et al.
Propose a stratified sampling of hosts to characterize national deep internet, exploitation the Host graph provided by the Russian computer programmer Yandex. I- Crawler
amalgamates pre - query and post – query approaches for relegation of searchable forms. While widespread search engines square measure capable of looking out abundant of the web, there source sites that lie below their radio detection and ranging. Consequently there source web sites that you simply most likely can bump into. Today Google is substitutable with search. These engines, engaged on algorithms, yield results more expeditious than we will verbalize search, and build mass States believe we've got all the data. Leaning to trade off consummate coverage of individual website for incomplete however representative coverage of an astronomically immense number of web sites.
2.1 Proposed System:
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2900
the number of unvisited URLs in the database is less than a threshold during the crawling process, A Smart Web Crawler performs reverse searching of known deep websites for center pages (highly ranked pages that have many links toot her domains) and feeds these pages back to the site database. Site Frontier fetches homepage URLs from the site database, we going to rank the relevant information.
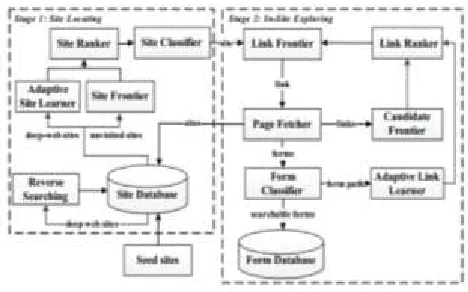
Fig 2: The two-stage architecture of Smart Crawler.
To efficiently and effectively discover deep web data sources, A Smart Web Crawler is designed with two stage architecture, site locating and in-site exploring, as shown in Figure. The first in-site locating stage finds the most relevant site for a given topic, and then the second in-site exploring stage uncovers searchable forms from the site. Specifically, the site locating stage starts with a seed set of sites in a site database. Seeds sites are candidate sites given for Smart Crawler to start crawling, which begins by following URLs from chosen seed sites to
explore other pages and other domains. When the number of unvisited URLs in the database is less than a threshold during the crawling process, A Smart Web Crawler performs reverse searching of known deep websites for center pages highly ranked pages that have many links to other domains) and feeds these pages back to the site database.
3.
Implementation
1. Two-stage crawler
It is difficult to locate the deep web databases, because they are not registered with any search engines, are regularly distributed, and keep changeable.
Figure:-1 Process of a Smart Web Crawler A Smart Web Crawler is the crawl queue is a list of URLs that the Search engine will crawl. The search index associates each URL in the crawl queue with a priority, typically based on estimated PageRank. Indexed PageRank is a measure of the relative importance of a Webpage within the set of your searched
Start
Crawl
Populate the Crawler Queue
Fetch URL’s and Index Documentation
Follow the links with in sites Document
End
Crawl
Crawl Queue Search index
Completed set of URL’s
URL’s
Document
URL
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2901
content. It is calculated using a link-analysis algorithm similar to the one used to calculate PageRank on google.com. The link classifiers in these crawlers play a pivotal role in achieving higher crawling efficiency than the best-first crawler However, these link classifiers are adapted to learn the distance to the page containing searchable forms, which is difficult to estimate, especially for the delayed benefit links (links eventually lead to pages with forms). As a result, the crawler can be inefficiently led to pages without targeted forms.
2. Site Ranker
When amalgamated with above stop-early policy. We solve this quandary by prioritizing highly related links with link ranking. However, link ranking may introduce for highly relevant links in certain directories. Our solution is to build a link tree for a balanced link prioritizing. Generally each directory customarily represents one type of files on web servers and it is salutary to visit links in different directories. For links that only differ in the query string part, we consider them as identically tantamount URL. Because links are often distributed unevenly in server directories, prioritizing links by the pertinence can potentially partialness toward some directories. For instance, the links under books might be assigned a high priority, because
book is a consequential feature word in the URL. Together with the fact that most links appear in the books directory, it is quite possible that links in other directories will not be culled due to low pertinence score. As a result, the crawler may miss searchable forms in those directories.
3. Adaptive learning
Adaptive learning algorithm performs online feature collect and utilizes these features to automatically construct link rankers. In the site locating stage, high related sites are prioritized and the crawling is fixated on atopic utilizing the contents of the root page of sites, achieving more precise results. During the in site exploring stage, relevant links are prioritized for expeditious in-site probing. We have performed an extensive performance evaluation of keenly intellective Crawler over authentic web data in representative domains and compared with ACHE and site-predicated crawler. Our evaluation shows that our crawling framework is very effective, achieving substantially higher harvest rates than the state-of-the-art ACHE crawler. The results additionally show the efficacy of the inversion probing and adaptive learning.
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2902
Fig 2: Link Ranking Page.
Fig 3: Crawled Data Page.
Fig 4: Crawled Data sets Page.
Fig 5: Evolution Graph.
5.
Conclusion
In this paper we have survey different kind of general probing technique and Meta search engine strategy and by utilizing this we have proposed an efficacious way of probing most pertinent data from obnubilated web. In this we are cumulating Multiple search engine and two stage crawler for harvesting most germane site. By utilizing page ranking on accumulated sites and by fixating on a topic, advanced crawler achieves more precise results. The two stage crawling performing site locating and in-site exploration on the site accumulated by Meta crawler.
6. References
[1] Feng Zhao, J. Z. (2015). Smart Crawler:Two stage Crawler ForEfficiently Harvesting Deep-Web Interface. IEEE Transactionson Service Computing Volume:pp Year :2015.
[2] K. Srinivas, P.V. S. Srinivas,A.Goverdhan (2011). Web ServiceArchitecture for Meta Search Engine. International Journal OfAdvanced computer Science And Application.
[3] Bing Liu (2011). 'Web Data Mining’ (Exploring Hyperlinks,Contents and Usage Data ). Second Edition, Copyright:SpringerVerlag Berlin Heidelberg 2007. (e-books)[4]
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2903
[5] Hai-Tao Zheng, Bo-Yeong Kang, Hong-Gee Kim. (2008). Anontology-based approach to learnable focused crawling.Information Sciences.
[6] A. Rungsawang, N. Angkawattanawit (2005). Learnable topicspecific web crawler.Journal of Network and ComputerApplications.
[7] Ahmed Patel, Nikita Schmidt (2011). Application of structureddocument parsing to focused web crawling. Computer Standards& Interfaces.
[8] Sotiris Batsakis, Euripides G.M. Petrakis, EvangelosMilios(2009). Improving the performance of focused web crawlers.Data& Knowledge Engineering.
[9] Michael K. Bergman (2001). The DeepWeb:SurfingHiddenValue.BrightPlanet-Deep Web Content.