206
Efficient Search on XML Data by Using Context
Based Diversification
P
1
P
R.Aishwarya., P
2 P Y.Sudha Madhuri P 1 P
Assistant Professor, Department of CSE, Sridevi Women's Engineering College, JNTUH, Hyderabad, TS, India.
P
2
P
Assistant Professor, Department of CSE, Sridevi Women's Engineering College, JNTUH, Hyderabad, TS, India.
Abstract— Keyword query allows normal users to search massive amounts of data; the ambiguity
of keyword query makes it difficult to respond effectively keyword queries, particularly for queries
short and imprecise key words. To resolve this drawback a challenge, during this paper an approach
that mechanically diversify can XML search keyword supported their different contexts within the
XML data is projected. Given a query keyword tiny and imprecise and XML data to be searched,
initial it is derived from the keyword search query candidates by a simple model feature choice.
And then, we tend to design a keyword search diversified XML model effective action of measuring
the quality of every candidate. After that, two efficient algorithms are projected to calculate
incrementally quelled top-k query candidates as various search intentions. Two criteria are targeted:
the chosen candidate’s consultation is most relevant to the query given before they need to hide the
most range of various results. At last, a full assessment of the sets of real and synthetic data
demonstrates the efficiency of our model of diversification and efficiency of projected algorithms.
Keywords -- Data Mining,Search Engine Optimization, XML Dataset, XML Keyword Search,
Context-Based Diversification, Baseline Algorithm, and Anchor based pruning algorithm;
I. INTRODUCTION
Keyword search is the most significant information discovery technique as a result of the user does
not need to know either a query language or the fundamental configuration of the data. Large
number of techniques is used in XML search system. Keyword search is that the technique use for
the retrieving data or data. Keyword search may be implementing on machine learning databases,
additionally it possible on graph structure which combines relative, HTML and XML data.
Keyword search use variety of techniques and algorithm for storing and retrieving data, less
accuracy, does not giving an accurate answer, require large time for searching and huge quantity of
storage space for data storage. Data processing or information retrieval is that the process to retrieve
data from massive database and remodel it to user in understandable form easily gets that
207 database queries. User simply inserts a keyword for looking and gets a result related to that
keyword. The keyword explore on relational databases become conscious the solution of the tuples
which are connected to database keys like primary key and foreign keys. Thus this system also
present those comparative techniques used for keyword search like BANKS, BLINKS,
DISCOVER, SPARK and EASE. Existing techniques for data retrieval on real world databases and
additionally experimental result indicate that existing search techniques are not capable of real
world information retrieval and data processing task. Data mining is finding insights that are
statistically reliable from data; identification of records that does not match the usual patterns may
be interesting that require any investigation. Association searches for relationships numerous
attributes like milk and bread along with jam. So providing a decent discount on combination will
enhance the sales method of grouping along values within the data that have similar patterns
however these patterns are not known in advance. Analyzing the data we create clusters of
employee who reach the target quite 10 times per week and other who make less than ten
transactions. It is the method of grouping the data into totally different classed on the idea of
previously known structures. For example we tend to create classification for example student
percentage above seventieth as distinction, between sixty to seventieth percentage first class and
below hour average. Regression attempts to find to operate that models the data with the smallest
amount of error fits the data onto then to operate so one value may be derived from another.
II. RELATED WORK
In this system to considering the keyword and its relevant context in XML data, searching should be
done using automatically diversification process of XML keyword search is that the major area of
concern. During this for structured and semi-structured data, various progressive techniques are
mentioned for keyword search. During this query optimization, ranking phases, high k necessary
query processing is discussed. Different data models such as XML; graph-structured data is
mentioned. Application of those ideas is additionally mentioned in which keyword based search has
prime importance. During this paper some issues like diverse data Models, query Forms:
complexity versus expressive Power, Search Quality Improvement, and analysis are mentioned.
XRANK system is mentioned during this paper. Ranked search technique over XML data is
considered here. During this paper area saving and performance gaining techniques like index
structure and query analysis are focused. XRANK will facilitate in searching for HTML similarly as
XML documents. Disadvantage: as an example, authors have presently taken a document-centric
view, wherever they assume that query results are strictly hierarchical. Index preservation is major
208 approach is mentioned. Queries referred to as the Multi way – SLCA approach (MS) is useful to
market the keyword search beyond and recent ways like AND / OR. After LCA analysis improved
algorithms square measure place to solve search issues supported keywords. In this Indexed search
Eager and Scan Eager, algorithms square measure mentioned. XML search supported keyword
consistent with SLCA semantics is prime topic of debate and for this these algorithm are used.
Instant search result's the wonder of theses algorithm. XK-Search design implementation is
discussed in it. The XK-Search system inputs a list of keywords and precedes the set of Smallest
Lowest Common ancestor nodes.
III. FRAME WORK
To address the present issues, we are going to develop a method of providing diverse keyword
query suggestions to users supported the perspective of the given keywords within the data to be
searched. By doing this, users might choose their preferred queries or vary their original queries
based on the returned various query suggestions. To deal with the prevailing limitations and
challenges, we tend to initiate a formal study of the diversification drawback in XML keyword
search, which might directly compute the diversified results without retrieving all the relevant
candidates. Towards this object, given a keyword query, we tend to initial derive the co-related
feature terms for every query keyword from XML data supported mutual data within the probability
theory, that has been used as a criterion for feature choice. The choice of our feature terms is not
restricted to the labels of XML components. Every combination of the feature terms and also the
original query keywords might represent one in all diversified contexts (also denoted as specific
search objective). And then, we evaluate every derived search objective by measure its relevance to
the first keyword query and also the novelty of its made results. To efficiently calculate diversified
keyword search, we tend to propose one baseline algorithm and two improved algorithms supported
the discovered properties of diversified keyword search results. By using this approach the
following benefits are reduce the computational price, efficiently calculate the new SLCA results
and computational time also reduced. Recognizing diverse current XML keyword search and
remove the duplicates to match by the results generated cover many search algorithms will meet the
209
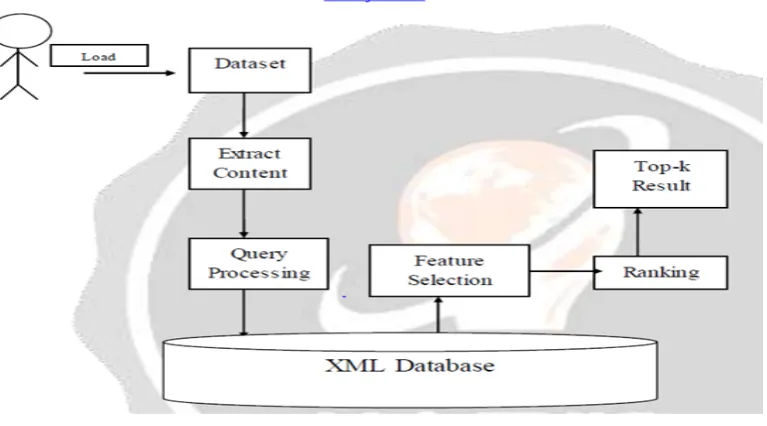
Figure 1: System Architecture
Keyword Search Diversification Algorithms:
We initial introduce the method of a new query from the matrix of the first keyword query
generating the data to be searched. And then, we projected on the basis of a matrix based algorithm
to recover the diversified keyword search results. Finally two anchor based mostly pruning
developed algorithms to enhance the efficiency of keyword search diversification by the interim
results are going to be used.
Anchor based pruning Algorithm:
When a keyword query is that the intuitive plan of the Anchor based pruning algorithm, we initial
retrieve the predicted function in terms of match query from the XML data T; then we tend to
generate all possible meant queries based on the retrieved operate terms; Finally, we tend to
calculate the social stability sheets as keyword or query search results for any query and compute
their diversification score. Diversifies the top -k inquiries and also the results in user can be
returned. Unlike traditional XML keyword search, we have to find and take away, by comparing the
new generated results with the previously generated ones or the duplicated ancestor results. This
can be as a result of covering results of multiple search intentions. To satisfy the requirement of
Keyword diversification justice, however we are obligated to return the distinct SLCA results to the
user.
IV. EXPERIMENTAL RESULTS
In our experiments, any number of users can upload the DBLP dataset into the system after
uploading dataset will be loaded then features will be generate to search the keyword the searching
keyword similarity score will be generate in these case pruning will not be perform and then to
210 accurate result based on that we can reduced the keyword ambiguity problem, searching delay,
computational time and also reduced the cost.
Fig 2: Uploading DBLP dataset
Fig 3: Features Generation
211
Fig 4: Enter Query
After feature generation we have to enter a query as an input which is taken from the
DBLP dataset.
Fig 5: Before pruning result
212
Fig 6: Pruning result
If user clicks on pruning keyword search then it deletes duplicate search result related to keyword
query and shows pruning result.
Fig 7: Top K Query Suggestion chart
Here it shows Top 10 query suggestion chart result based upon time.
1 2 3 4 5 6 7 8 9 10
1.024 1.026 1.028 1.03 1.032 1.034 1.036 1.038
Top ten Results
v
al
u
es
Top K Query Suggestion Chart
213
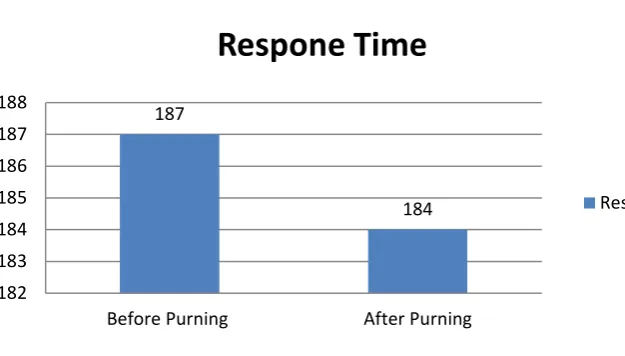
Fig 8: Response time
In the above chart we can observe that difference between the response time of both before pruning
and after pruning. Through our implementation we can search the accurate keywords as well as we
can reduce the keyword searching delay, keyword ambiguity problem, computational time and cost,
response time.
V.CONCLUSION
In this work, we tend to first approach diversified results of keyword querying XML data on the
contexts of the query to search for keywords within the basis of the info. The diversification of the
contexts was measured by exploring their relevance to the first query and also the novelty of their
results. Additionally, we tend to developed three efficient on the experimental properties of XML
keyword search results based mostly algorithms. Finally, we've got shown the effectiveness of our
projected algorithms executed by significant number of queries over each DBLP records.
Meanwhile, we tend to additionally confirmed the effectiveness of our diversification model
through the returned search analyze intentions for keyword queries concerning DBLP record. From
the experimental results, we tend to get that our projected diversification algorithms competent
search return intentions and results to users during a short time.
REFERENCES
[1] Y. Chen, W. Wang, Z. Liu, and X. Lin, “Keyword search on structured and semi-structured
data,” in Proc. SIGMOD Conf., 2009, pp. 1005–1010.
[2] L. Guo, F. Shao, C. Botev, and J. Shanmugasundaram, “Xrank: Ranked keyword search over
xml documents,” in Proc. SIGMODConf., 2003, pp. 16–27.
[3] J. Li, C. Liu, R. Zhou, and W. Wang, “Top-k keyword search over probabilistic xml data,” in
Proc. IEEE 27th Int. Conf. Data Eng., 2011, pp. 673–684. 187
184
Before Purning After Purning 182
183 184 185 186 187 188
Respone Time
214 [4] R. Agrawal, S. Gollapudi, A. Halverson, and S. Ieong, “Diversifying search results,” in Proc.
2nd ACM Int. Conf. WebSearch Data Mining, 2009, pp. 5–14.
[5] M. Hasan, A. Mueen, V. J. Tsotras, and E. J. Keogh, “Diversifying query results on
semi-structured data,” in Proc. 21st ACM Int.Conf. Inf. Knowl. Manag., 2012, pp. 2099–2103.
[6] C. Sun, C. Y. Chan, and A. K. Goenka, “Multiway SLCA-based keyword search in xml data,” in
Proc. 16th Int. Conf. World Wide Web, 2007, pp. 1043–1052.
[7] C. L. A. Clarke, M. Kolla, G. V. Cormack, O. Vechtomova, A. Ashkan, S. B€uttcher, and I.
MacKinnon, “Novelty and diversity in information retrieval evaluation,” in Proc. SIGIR, 2008, pp.
659–666.
[8] S. Gollapudi and A. Sharma, “An axiomatic approach for result diversification,” in Proc. 16th
Int. Conf. World Wide Web, 2009, pp. 381–390.
[9] J. G. Carbonell and J. Goldstein, “The use of MMR, diversitybasedreranking for reordering
documents and producing summaries,” in Proc. SIGIR, 1998, pp. 335–336.
[10] M. R. Vieira, H. L. Razente, M. C. N. Barioni, M. Hadjieleftheriou, D. Srivastava, C. Traina J.,
and V. J. Tsotras, “On query result diversification,” in Proc. IEEE 27th Int. Conf. Data Eng., 2011,
pp. 1163–1174.
[11] Z. Liu, P. Sun, and Y. Chen, “Structured search result differentiation,”J. Proc. VLDB