International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 2, December 2011)106
Implementation of 4x4 crossbar switch for
Network Processor
Mr.Prashant Wanjari
1, Prof.Anagha choudhari
21Lecturer, RGCOER, Nagpur 2
Lecturer, YCCE, Nagpur 1
[email protected] 2 [email protected]
Abstract—The network processor incorporates a processor and a number of coprocessors that can be connected to the
processor either Directly or using a shared busThis paper
presents the proposal and development of a reconfigurable crossbar switch architecture for network processors. Its main purpose is to increase the performance, and flexibility for environments with multiprocessors and computer clusters. The results include VHDL simulation of Crossbar Switch and the use of it in a broadcast function implementation, found in message passing support middleware. This reconfigurable crossbar Switch used in Network Processor to connect the various circuits which are used to perform the various task.
Keywords—Reconfigurable Crossbar switch (RCS),
Network Processor, FPGA, modelsim.
I. INTRODUCTION
At the end of nineties, network equipments normally used general-purpose processors. However, the need of quality-of-service and the high speed of data transmission demanded a rapid evolution of network equipments. Thus, the Network Processor (NP) was Created to increase the data transmission speed & also used to perform the various operations. Network processors are used in place of some GPPs (General-Purpose Processors) and ASICs (Application Specific Integrated Circuits) in network equipments, targeting two important issues: flexibility and performance. As these features are essential to process the packets, a network processor is the best choice to get them. The main motivation is the necessity of increasing two features cited before. With the use of a reconfigurable crossbar switch in a network processor it could be achieved. Thus, using network processor with a
reconfigurable crossbar switch as interconnection
structures, it is possible to increase the throughput and reduce the latency in communications with shared memory and message transference.
Therefore, the main objective of this paper is to present the RCS-2, a reconfigurable crossbar switch architecture used to connect different inputs and outputs in interconnection and communication networks, The reconfigurable crossbar switch was described in VHDL (VHSIC Hardware Description Language) and I want to implemented it on FPGA (Field Programmable Gate Array). As per the development the results show the
behaviour of the application which contains
communicating processes that perform a collective broadcast operation on the reconfigurable crossbar switch. The generalised block diagram for Network Processor shown in Figure 1.
Figure: 1 Generalised Block diagram for Network Processor
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 2, December 2011)107
Data rates for communications processors range from a few megabits per second to 1Gbps (for instance a single gigabit Ethernet channel). Although this dividing line may seem arbitrary and will certainly change over time, there are some other important, if subtle, differences between these two types of processors. Communications processors cost less. Their lower prices mean they have more integration than most network processors. For example, communications processors typically contain a RISC processor core that runs a standard MIPS, PowerPC, or ARM instruction set. By contrast, most
NPUs don't include such a processor. In a
communications processor, it's common for Layer 3 processing and above to be handled by this RISC processor, whereas NPUs commonly handle Layers 3 and
above with proprietary packet engines. Many
[image:2.612.57.310.589.673.2]communications processors integrate Layer 1 and Layer 2 processing; most NPUs don't. These differences in price and performance between communications processors and NPUs mean systems designers typically specify them for widely different applications. Finally, coprocessor chips such as classification engines, search engines, and traffic managers aren't really NPUs because they handle only a portion of the entire packet-processing task. In addition, these devices are typically not programmable, although they're often configurable to some degree. An NPU might contain coprocessors or even rely on external coprocessors, but these coprocessors are not NPUs themselves. It comprises of three parts, with the first being the Receive to Memory part (Rx2Mem) which is tasked with counting the number of bytes in the frame being received and determining its initial byte of data. The second part is the Control part, which is tasked with forwarding frame data to the Process module and storing both the received frames as well as the processed ones. Finally, the Process module is the last part of our architecture, which is responsible for processing all the frame data by performing all the instructions supported by the design. [1]
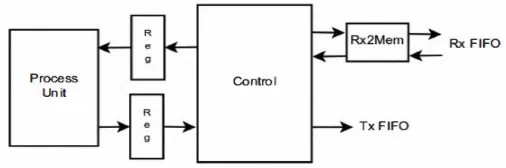
Figure: 2 Basic operational diagram of Network Processor
A. Rx2Mem Module:
This is the first module of our design, as shown in figure 2; it is responsible for three simple yet essential operations: first, it keeps a count of all the frames we have received so far through the network adapter; second, it calculates the length of each frame it receives which is essential when processing frames and altering their contents; finally, it is responsible for signalling the beginning of each frame, once again a necessary operation, since we need to be able to determine where the first byte of a frame is stored in the design's data memory.
B. Control Module:
This module is the heart of our architecture (figure 2). As we have already mentioned its purpose is to forward the proper frame data to the Process module and to store received and processed frame data in the data memories. It can be abstractly divided in four parts, each on a different part of the architecture's data path. The first part is called Received to Memory (R2M), receiving data from the Rx2Mem module and storing them in the memory, along with information about each frame (its starting address in the data memory and its length in bytes). The second is the Memory to Process part (M2P), responsible of forwarding proper frame data to the Process module in order for them to be processed; this module is capable of sending the whole frame or a specific byte of the frame to the Process module, thus optimizing the performance of some of the instructions supported by the design. The third part is called Process to Memory (P2M) and it is tasked with writing processed frame data back to the design's data memory. It is also responsible for calculating any changes in the frame's length, since an Add or Remove instruction can alter a frame's length. Finally, the Memory to Transmit (M2T) part, which is the
final part of the Control module, is responsible of
transmitting processed frames back to the client through the board's network adapter.
C. Process Module:
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 2, December 2011)108
II. RELATED WORKS
There are lots of commercial network processors of different companies. Some companies and respective network processors are: IBM (NP4GS3), Motorola/CPort
(C-5 Family), Lucent/Agere (FPP/RSP/ASI),
Sitera/Vitesse (IQ2000), Chameleon (CS2000), EZChip (NP-1), Intel (IXP1200) and others. None of them presents reconfigurability, except the CS2000 of Chameleon However, it does not have reconfigurable crossbar switch.NP architectures have dedicated blocks to execute specific functions as an embedded ASIC (NPSoC – Network Processor System-on-Chip). Some blocks are: PCI units, memory units, packet classifiers, policy engines, metering engines, and packet transform engines, pattern processing engine, queue engine, QoS engines and other blocks. There are some documents and papers about crossbar switch, but nothing using reconfigurable crossbar in a network processor. [6]
III. RECONFIGURABLE CROSSBAR SWITCH
ARCHITECTURE
Figure: 3 Reconfigured Crossbar switch
Figure.4 Simple 4x4 Crossbar switch
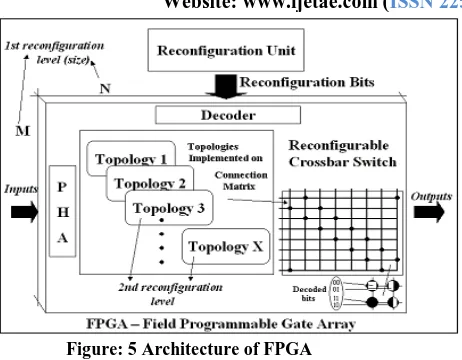
RCS-2, presented in figure, has three main blocks: (1) connection matrix, where the topologies are implemented (2) decoder, that converts the reconfigurable bits for a matrix bits set and (3) pre-header analyzer (PHA). NPs can add a pre-header in the packet with the output destination.
Reconfigurable crossbar switch (RCS-2) uses
reconfiguration bits to implement the topology in the space. That topology actually maintains the created connections as a circuit. The reconfiguration bits set are capable of reconfiguring or implement a new topology in RCS-2 whenever necessary. RCS-2 architecture is based on two reconfiguration levels. Using these two levels it is possible to reconfigure and to readapt the crossbar switch to many network topologies and different workload
situations. The first level is based on static
reconfiguration using a reconfigurable device, like FPGA. Programming this device, it is possible to implement a RCS-2 with number of in and out ports (and consequently rows and columns – circuit and logic gates) limited by the device capacity. The second level of reconfiguration makes possible the implementation of different network
topologies. It could be done by dynamically
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 2, December 2011)109 Figure: 5 Architecture of FPGA
The reconfigurable crossbar switch has some connection nodes, which, if closed, compose a circuit. This circuit represents a topology in space.
Differently from a traditional crossbar switch (TCS), where it is possible to close only one node per line or column, regards the implemented topology, the RCS-2 permits that more than one node can be closed per line or column at the same time. In a TCS, the topologies cannot be implemented in the space, only in the time. During a slice of time the same nodes must be opened and closed repeatedly to create the illusion of an implemented topology. On the other hand, the reconfigurable crossbar switch (RCS-2) uses reconfiguration bits to implement the topology in the space. That topology actually maintains the created connections as a circuit. The reconfiguration bits set are capable of reconfiguring or implement a new topology in RCS-2 whenever necessary. RCS-2 architecture is based on two reconfiguration levels. Using these two levels it is possible to reconfigure and to readapt the crossbar switch to many network topologies and different workload situations. The first level is based on static reconfiguration using a reconfigurable device, like FPGA. Programming this device, it is possible to implement a RCS-2 with number of in and out ports (and consequently rows and columns – circuit and logic gates) limited by the device capacity. The second level of reconfiguration makes possible the implementation of different network topologies. It could be done by dynamically reconfiguration of the connection matrix nodes. These nodes determine which connections will be
closed and consequently which paths exist through the
crossbar switch. RCS-2 has two bits of reconfiguration to each node, which define the current topology.
Only theReconfiguration Unit and the instruction set of
the network processor are able to change those bits in
[image:4.612.57.288.124.304.2]order to implement new topologies.[5]
Figure 6: different topologies (a) Ring (b) Star (c) Bus (d)
FullConnected.
The broadcasting of message with different sizes was tested, ranging from 1 byte to 256KB. Since all experiments yielded a similar behaviour in the network, only the results regarding 256KB messages are presented.
We initially tested all the versions of the broadcast application in RCS-2, which topology was statically configured as shown in figure 5. The topologies were chosen since they are simple to implement, describe and analyze.
VI. ADVANTAGES &DIS-ADVANTAGE
The main competitors to NPUs are general-purpose microprocessors and custom ASICs. In previous networking systems, microprocessors were used to perform routing functions in low-end devices because of their low cost, general availability, and ease of programming. Microprocessors don't have enough performance for high-bandwidth devices, so these boxes used custom ASICs. ASICs provide ultimate control over the design. Using ASICs, a networking designer can create highly differentiated products. On the other hand, ASICs have long design cycles( 9 -18 months), long debug cycles, and high development costs (millions of dollars). As a result, ASIC development is the riskiest portion of system development. Like standard microprocessors, network processors are programmable and available off the shelf, yet they can match the performance of ASICs in demanding networking applications.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 2, December 2011)110
Programmability not only accelerates time to
market, it can even enable an NPU-based router to be
field-upgraded with a new protocol something that can't be done with a hardwired solution.[7]
V. COMMON CHARACTERISTICS
A single network data stream contains a large number of individual packets, each of which can be processed fairly independently. In fact, Internet protocol (IP) allows individual packets within a single data stream to be processed in any order again Because of this independence, packet processing is an ideal application for an array of processors. By dividing up the task, one chip can deliver high performance using several processing units of modest speed. These units needn't squeeze out the last bit of performance, using techniques such as superscalar issue or instruction reordering, which require a great many transistors and a corresponding increase in power consumption. Packet processors can thus be small and efficient. Instead of combining standard CISC or RISC processors, however, NPU vendors have slimmed down their processors still further. Processing packets is a fairly simple task, consisting mainly of extracting data from a bit stream and doing some pattern matching or table lookups, so a packet processor doesn't need complex arithmetic, fancy addressing modes, or memory-translation units. Bulky circuits such as floating-point units (FPU) and memory-management units (MMU) are generally unnecessary. Instruction caches can be smaller, and data caches are generally eliminated completely, since most network data doesn't recur and is not reused.
The optimized network processors are also called as packet engines, although NPU vendors themselves use a variety of terms such as micro-engines and channel processors. By eliminating general-purpose CPU features and focusing on just the basics, NPU designers can fit a single packet engine into only a few square millimetres of silicon. They can then liberally sprinkle these tiny engines across a standard silicon chip measuring just 100 mm2 or so. Some NPUs combine 64 or more packet engines on a single chip about the size of a Pentium 4. To take further advantage of the large number of available packets, packet engines are typically multithreaded.
In this approach, each engine has one or more packets
"on hold" while it processes the currentpacket.
If the current packet stalls for some reason, such
as a lengthy memory access, the engine quickly switches to one of the packets on hold. This way, the engine doesn't waste time waiting on memory; instead, it can operate at near-peak efficiency. A multithreaded processor will usually have extra copies of its programmers' register set, each holding the state of a different packet. Switching packets (or threads) means just pointing to another set of registers and is usually done in a single cycle. Some NPUs make the programmer (or compiler) insert thread-switch instructions; others switch automatically any time there's a memory access. Although packet engines are often stripped-down RISC processors, they may also have some added features to improve packet performance. Bit-manipulation instructions are one common example. Depending on the particular network protocol, packet headers might have fields that consist of just a single bit or a few bits. Standard RISC processors operate only on 32-bit aligned words, so these special instructions can make header analysis and manipulation much easier. Many NPUs include coprocessors, such as hash engines, search engines, classification engines, or policy engines.[8]
VI. RESULTS
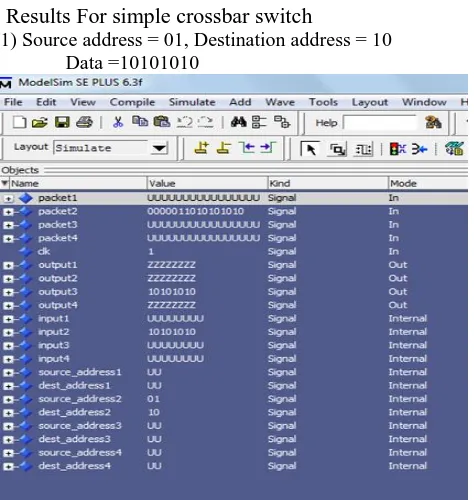
Results For simple crossbar switch
1) Source address = 01, Destination address = 10 Data =10101010
[image:5.612.324.561.438.688.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 2, December 2011)111 Fig (7b) Wave simulation window
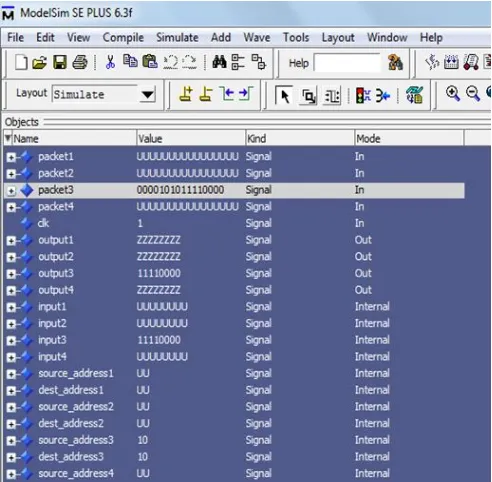
1) Source address =10 Destination address=10 Data=11110000
Fig (8 a) object window
Fig (8b) Wave simulation window
VII. CONCLUSIONS
[image:6.612.54.309.151.390.2] [image:6.612.326.575.155.389.2] [image:6.612.54.300.456.697.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 2, December 2011)112 References
[1] D. E. Comer, ―Network Systems Design using Network Processors‖, Prentice Hall, 2003
[2] D. Kim, K. Lee, S. Lee and H. Yoo, ―A Reconfigurable Crossbar Switch with Adaptive Bandwidth Control for Networks-on-Chip‖, IEEE International Symposium on Circuits and Systems, 2005
[3] G. Lawton, ―Will Network Processor Units Live up to their Promise?‖ IEEE Computer, Volume 37, Number 4, April, 2004,
[4] H. Eggers, P. Lysaght, H. Dick, and G. McGregor, ―Fast Reconfigurable Crossbar Switching in FPGAs‖, Proceedings of 6th International Workshop on Field Programmable Logic and Applications, Springer LNCS 1142, 1996,
[5] I. A. Troxel, A. D. George and S. Oral, ―Design and Analysis of a Dynamically Reconfigurable Network Processor‖, IEEE Conference on Local Computer Networks, November 6-8, 2002.
[6] J. Chang, S. Ravi, and A. Raghunathan, ―FLEXBAR: A crossbar switching fabric with improved performance and utilization‖, IEEE Custom Integrated Circuits Conference, May 2002,
[7] L.E.S. Ramos and C.A.P.S. Martins, ―A Proposal of Reconfigurable MPI Collective Communication Functions‖. Third International Symposium on Parallel and Distributed Processing and Applications, LNCS 3758, Nanjing, China, November 2-5, 2005