EVOLUTIONARY ALGORITHMIC
APPROACH FOR DATA MINING
ASAD MOHAMMED KHAN
Department of Computer Engineering, ZHCET, AMU Aligarh, Uttar Pradesh, India
RAMIZUDDIN KHAN
Department of Computer Engineering, ZHCET, AMU Aligarh, Uttar Pradesh, India
SAAD SHAMIM
Department of Computer Engineering, ZHCET, AMU Aligarh, Uttar Pradesh, India
RAFAT MUNSHI
University Polytechnic, AMU Aligarh, Uttar Pradesh, India [email protected]
Abstract - Data Mining is extracting useful information from large database that cannot be obtained by standard search mechanisms. We live in a world where a vast amount of data is generated and collected every day, giant database are getting filled with raw data. Analyzing such a huge amount of data is a big hurdle but is important because it helps the organization in decision making tasks. Classification is a supervised learning technique of data mining which is used to extract hidden useful knowledge over a large volume of database by predicting the class values based on the attribute values. Recently, both the probabilistic and evolutionary techniques are worked upon. This paper presents an approach for classifying diabetes patient based on features extracted from database using evolutionary technique i.e., genetic algorithm. For the experimental work, we have used the Diabetes 130-US hospitals 1999-2008 Data Set taken from the UCI Machine Learning Repository.
Keywords- Classification, genetic algorithm, data mining.
1. Introduction
With the rapid advancement of technology, large volume of data are collected from day to day applications such as satellite data, stock market, health services administration and universities. This large amount of raw data stored contains valuable hidden knowledge, which could be used to improve the decision-making process of an organization. Thus, data mining techniques such as classification, clustering and association are generally used to extract the hidden knowledge from voluminous of database.
A lot of research papers have discussed the classification using genetic algorithm and the result suggest that genetic algorithms are becoming practical for classification problems as faster serial and parallel computers are developed.
Of the various data analysis technique, classification is a supervised machine learning technique which predicts the class values based on the attribute values. In the present work, we analyse the voluminous data using Genetic Algorithm (GA). In the present work, we aim to answer the following questions: Can we find which patients are readmitted or not-readmitted? If so, can we predict a class for any individual patient? With this information, we can then predict better whether the patient is readmitted or not readmitted.
2. BACKGROUND
Definition 1(Fitness Function): Fitness Function of rule discovery is the most important factor for the
convergence of the GA. The basic parameter used to measure the fitness function of GA is Confidence.
Definition 2(Confidence Factor): Let a rule be of the form: IF A THEN C. Confidence factor (CF) of the
rule defined as:
CF = |A & C| / |A| (1)
where |A| is the number of tuples satisfying all the conditions in the antecedent A of the rule and |A&C| is the number of tuples satisfying both the antecedent A and the Consequent C i.e. the predicted class.
3. Genetic Algorithm Technique
Genetic Algorithm (GA) is a search method that has been used by the data mining community for discovering classification rules. The accuracy of the rules that GAs find are generally comparable and sometimes even more accurate than the rules obtained by the other classification algorithms.
GAs are global search algorithms that work by using the principles of evolution. Genetic algorithms depend on the generation-by-generation development of possible solutions, by eliminating bad solutions and allowing good solutions to replicate and be modified. GA will evaluate each individual as a potential solution according to a predefined evaluation function. The evaluation function assigns a value of goodness to each individual based on how well the individual solves a given problem.[1]
The genetic algorithm uses rule based classifiers in general. One can design an individual to represent prediction (IF-THEN) rules. Classification rules can be considered a particular kind of prediction rules where the rule antecedent (“IF part”) contains a combination of conditions on predicting attribute values, and the rule consequent (“THEN part”) contains a predicted value for the goal attribute.
Examples:
IF (Housing=convenient)
∧
(Finance=convenient)∧
(Social=slightly problematic)∧
(Health= recommended)
(class = very recommended)IF (Health=not recommended)
(class = not recommended)The classification problems have been well studied as a major category of data analysis in genetic algorithm which generally uses rule based approach. The initial literature on rule based genetic algorithm was found in [2]. It describes the kind of rule assessment schemes which have been proposed for rule discovery systems. It reviews the definition, theory and extent applications of classifier systems.
4. Proposed Approach
The present work finds the rule based genetic algorithm classifier by improving upon the fitness function parameter. We have used the genetic algorithm because it always gives better results and is very efficient in case there is attribute dependency in the problem, which is not true in most of the real world problem including diabetes dataset we have considered for our work.
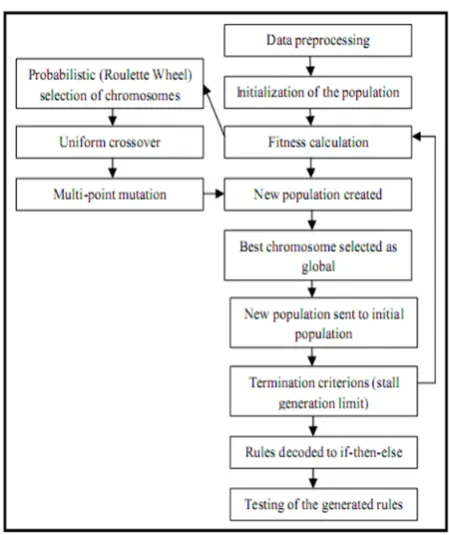
The framework for the proposed approach is shown in Figure1 and proposed approach of GA uses the following steps:
4.1 Representation of the Rule
Let a rule be of the form: IF A
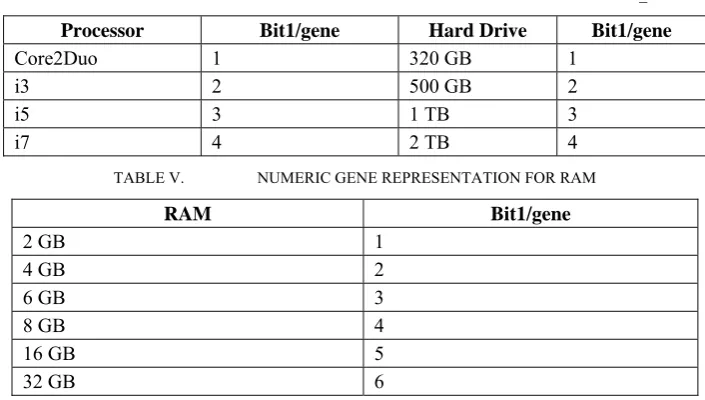
C, where A is the antecedent and C is the consequent. The rule antecedent A may be consisting of attributes .... .... . Let us consider attributes , i.e ‘Processor’, ‘RAM’, ‘Hard_Drive’ and their attributes values are {Core 2 Duo, i3, i5, i7 }, {2, 4, 6, 8, 16, 32}, {320 GB, 500 GB, 1 TB, 2TB}. Gene representation for the different attribute values in case of binary chromosomes will be as follows:TABLE I. BINARY GENE REPRESENTATION FOR PROCESSOR
Processor Bit 1 Bit 2 Bit 3 Bit 4
Core2Duo 1 0 0 0
i3 0 1 0 0
i5 0 0 1 0
TABLE II. BINARY GENE REPRESENTATION FOR HARD_DRIVE
Hard Drive Bit 1 Bit 2 Bit 3 Bit 4
320 GB 1 0 0 0
500 GB 0 1 0 0
1 TB 0 0 1 0
2 TB 0 0 0 1
TABLE III. BINARY GENE REPRESENTATION FOR RAM
RAM Bit 1 Bit 2 Bit 3 Bit 4 Bit 5 Bit 6
2 GB 1 0 0 0 0 0
4 GB 0 1 0 0 0 0
6 GB 0 0 1 0 0 0
8 GB 0 0 0 1 0 0
16 GB 0 0 0 0 1 0
32 GB 0 0 0 0 0 1
The gene representation for the different attribute values, in case of numeric chromosomes will be as follows:
TABLE IV. NUMERIC GENE REPRESENTATION FOR PROCESSOR AND HARD_DRIVE
Processor Bit1/gene Hard Drive Bit1/gene
Core2Duo 1 320 GB 1
i3 2 500 GB 2
i5 3 1 TB 3
i7 4 2 TB 4
TABLE V. NUMERIC GENE REPRESENTATION FOR RAM
RAM Bit1/gene
2 GB 1
4 GB 2
6 GB 3
8 GB 4
16 GB 5
32 GB 6
For Example: IF (Processor = i7)
∧
(RAM = 8 GB)∧
(Hard_Drive = 1 TB). Then the rule Antecedent can be represented as in binary chromosome representation: 0001| 000100|0010. In numeric chromosome representation attribute values can be assigned numeric value as shown in Table IV and Table V:A flag bit may be associated with every attribute, which indicates presence or absence of an attribute in the antecedent part of the rule.
For example: IF (Processor = i7)
∧
(RAM = 8 GB)∧
(Hard_Drive = 1 TB). The binary and numeric chromosome representation for this expression is as follows: Binary chromosome: 0001|1|000100|1|0010|1| and its Numeric chromosome: 4|1|4|1|3|1|.IF (Processor = i7)
∧
(Hard_Drive = 1 TB). Binary Chromosome Representation: 0001|1|000100|0|0010|1| and its Numeric chromosome: 4|1|4|0|3|1|. Here entries of bold and italics show the flag bit.The presence of a flag bit helps in the process of chromosomes crossover. For example in the absence of the flag bit the following rule will have the binary or numeric representation as follows:
IF (Processor = Core2Duo)
∧
(Hard_Drive = 1 TB). Binary Chromosome: 1000|1|0010|1|. Numeric chromosome: 4|1|3|1|. As a result of a crossover operation, one of the children might be an invalid individual (i.e. invalid chromosome), such as:IF (Processor = i7)
∧
(Hard_Drive = 8 GB). IF (Processor = Core2Duo)∧
(RAM = 1 TB).Here the value of attribute Hard_Drive and RAM are out of the domain of the attributes. For the current problem, the numeric representation of the chromosomes is considered.
4.2 Crossover
Crossover selects a point for crossover in the chromosomes from two parent chromosomes and creates a new offspring.[3] The single point crossover is performed by choosing some random crossover point and cloning everything before this point from the first parent and then everything after the crossover point from the second parent. Crossover can then look like this (| is the crossover point) as follows:
TABLE VI. Crossover Computation
Chromosome 1 11010 | 00101010110
Chromosome 2 11001 | 11000101110
Offspring 1 11010 | 11000101110
Offspring 2 11001 | 00101010110
4.3 Mutation
Mutation is performed to prevent all solutions in the population from falling into the local maxima or minima. Mutation changes the gene randomly in the new offspring. The mutation process is performed with low probability so that chromosomes could settle to achieve global maxima or minima.
Example: As discussed earlier, let a chromosome be 3|1|6|1|4|1|, for mutation a random number is chosen using the random() function. For example, let the first gene is selected for mutation, then after mutation chromosome becomes 4|1|6|1|4|1|. The mutation process can also leads to the formation of invalid chromosomes for example, if after mutation, the new chromosome is 1|1|6|1|4|1|which is an invalid chromosome because no Core 2 Duo processor computer is available with 32 GB RAM. For the current problem, we are using both single and multi-point mutation.[3]
4.4 Selection
For performing crossover, parents are selected using Roulette wheel selection process. In roulette wheel selection, individuals are given a probability of being selected that is directly proportional to their fitness i.e., higher their fitness value, greater is their chances of being selected. Two individuals are then selected based on these probabilities and produce offspring.
Figure 1. Frame work for evolutionary rule-based-classification
5. Results
Diabetes dataset[4] was developed to identify which diabetes patients are readmitted after diagnosis and after how many days? This dataset contains 101766 instances of 18 attributes. For our experimental work we have considered 60% distribution of each class for training and 40% for testing.[5]
Parameters used for proposed genetic algorithm approach are: Population Size:100
No of Generations:500 Probability of Crossover:0.85
Probability of Mutation of flag bit per bit: 0.20 Probability of Mutation of attribute bit per bit: 0.04 Overall Accuracy Calculation
Class Distribution (number of instances per class Class.NN[%]
Not_readmitted 54864 (53.91 %) Readmitted (<30 days) 11357 (11.16 %) Readmitted (>30 days) 35545 (34.93 %) Total Instances = 101766
Overall_Accuracy= ∑ _ _ _ _′ ′ ∗ _ _ _′ ′_ _ _
TABLE VII.AVERAGE CONFIDENCE FOR EACH CLASS
Class_Label Average_Confidence_of_Class_’i’
Not_readmitted 0.45
Readmitted (<30 days) 0.59 Readmitted (>30 days) 0.60
TABLE VIII. FITNESS VALUES FOR TEST DATASET
We have got good results using GA because of the fact that there exist attribute dependency in the problem which is analogous to many real world scenario.
6. Conclusion
The most important factor of GA is its fitness function, the rate of convergence of search space is proportional to the effectiveness of fitness function in other words better the fitness function better is the convergence of GA for a given problem. Also genetic operator improvement for a problem plays an important role for the convergence of search space to an optimal solution. Proper mutation probability distribution to avoid redundancy and inconsistency. We can further improve these factors of GA in future.
References
[1] Melanie Mitchell Santa Fe Institute, Santa Fe, NM, An Introduction to genetic algorithms. MIT Press Cambridge, MA, USA © 1996 [2] Jiawei Han, Micheline Kamber, Data mining: concepts and techniques. Morgan Kaufmann Publishers Inc. San Francisco, CA, USA
©2000
[3] Keshavamurthy B.N, Asad Mohammed Khan & Durga Toshniwal, Improved Genetic Algorithm Based Classification, IJCSI ISSN (PRINT) 2231-5292, Volume-1,Issue-3, 2011
[4] Beata Strack, Jonathan P. DeShazo, Chris Gennings, Juan L. Olmo, Sebastian Ventura, Krzysztof J. Cios, and John N. Clore, “Impact of HbA1c Measurement on Hospital Readmission Rates: Analysis of 70,000 Clinical Database Patient Records,” BioMed Research International, vol. 2014, Article ID 781670, 11 pages, 2014.
[5] UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science. © 2015
Class Labels Mined Rules Confidence Fitness
Not_Readmitted
IF (race = Caucasian AND gender = Female AND ad_ty_id = 1 AND disc_dis_ty_id = 1 AND adm_sour_id = 7 AND nu_pro = 3 AND dia_2 >= 40 AND dia_3 >= 70 AND ins = No AND ch = Ch AND dia_Med = 2) THEN (re_ad = No) IF (race = Caucasian AND gender = Female AND ad_ty_id = 1 AND disc_dis_ty_id = 1 AND adm_sour_id = 7 AND time_in_hos >= 2 AND nu_med = 1 AND dia_2 >= 40 AND dia_3 >= 20 AND nu_dia = 1 AND ins = Steady AND ch = Ch AND dia_Med = 2) THEN (re_ad = No)
IF (race = Caucasian AND disc_dis_ty_id = 1 AND nu_lb_hos = 6 AND dia_2 >= 40 AND dia_3 >= 40 AND nu_dia = 2 AND ins = No AND ch = No AND dia_Med = 2) THEN (re_ad = No)
IF (gender = Female AND disc_dis_ty_id = 1 AND dia_1 >= 70 AND dia_2 >= 40 AND dia_3 >= 40 AND nu_dia = 2 AND ins = No AND ch = No AND dia_Med = 2) THEN (re_ad = No) 0.49 0.46 0.44 0.41 0.49 0.46 0.44 0.41 Readmitted ( < 30 days)
IF (race = Caucasian AND ad_ty_id = 1 AND dia_3 >= 40 AND dia_Med = 2) THEN (re_ad = <30)
IF (race = Caucasian AND gender = Female AND nu_lb_hos = 4 AND ch = No AND dia_Med = 2) THEN (re_ad = <30) IF (race = Caucasian AND nu_med = 1 AND dia_2 >= 40 AND ins = No AND ch = No AND dia_Med = 2) THEN (re_ad = <30)
0.65 0.57 0.56 0.65 0.57 0.56 Readmitted ( > 30 days)
IF (race = Caucasian AND ad_ty_id = 1 AND adm_sour_id = 7 AND nu_med = 1) THEN (re_ad = >30)
IF (race = Caucasian AND adm_sour_id = 7 AND nu_dia = 6 AND dia_Med = 2) THEN (re_ad = >30)
IF (race = Caucasian AND nu_lb_hos = 5 AND nu_pro = 0 AND dia_Med = 2) THEN (re_ad = >30)
IF (race = Caucasian AND disc_dis_ty_id = 3 AND nu_med = 1 AND ch = Ch AND dia_Med = 2) THEN (re_ad = >30)