Enhanced Reliable Collaborative Filtering For
Book Prediction In Academic Libraries
Dr. L. Santhi
Abstract : Book collection management in academic libraries needs special care with the basis of analyzing the rating provided by the readers. Additionally, a book loaned out count details help measure its popularity. Due to the wrong prediction of books the count of readers getting decreased. Even though multiple research works are carried out in this thrust research area, it still didn’t meet its objective of correct prediction of books. In this paper, enhanced reliable collaborative filtering (ERCF) is proposed to predict the user expected book based on the rating. Different readers provide different rating at different times. ERCF considers the dynamicity of rating and predicts the expected books. ERCF is evaluated against Kalman Filtering using benchmark metrics in MATLAB. Results with better results show that the proposed work has outperformed the baseline method.
Keywords: books, filtering, library, rating, readers
—————————— ——————————
1
INTRODUCTION
In the library, every year a huge quantity of books are
introduced and it increases the overall book count. Library users (i.e., readers) are spending much time to
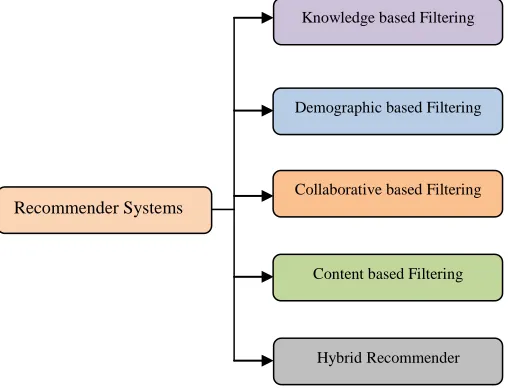
choose a book and it is because of the information-overload phenomenon. To address this issue, the library needs to utilize the information-filtering mechanism. There exist two types in the information-filtering mechanism, which are (i) search mechanism (SM), and (ii) recommendation mechanism (RM). Previous mechanisms are based on keywords that the readers provide. Personalized RM predicts the preferred books based on behavior, the interest of user and rating provided by other users. Application software for RM in libraries resolves the complexity in selecting books and enhances the library utilization rate. The main intention of a process in data mining is applying the filtering concept. It is the main target of the recommender system to provide a recommendation to the user. Because of this method, we can make predictions and look for alternatives based on score values and that is provided to the user. The object that receives the maximum value is passed to the recommendation list that is given to the user. To verify the results in the recommendation list, it is necessary to use different performance metrics. The filtering of information indicates the methodology of investigating the huge quantity of data. Because of the enhanced growth of technologies, administrators are challenging each other to reduce issues in data retrieval. Some of the solutions of overloaded data are Group lens, Tapestry and Lotus Notes. Recommender systems classifications are shown in Fig 1.
Collaborative Filtering (CF) is one of the excellent recommender systems for the library. CF receives all opinions from the user in the format of rating on book relevance, readability, and service provided by the library. Reader well knows about its library use against e-library and online reading. Most prominently, CF based recommender system builds the model with word-of-mouth pattern but automatically. It confers the opinion of different users with a related rating of the target user (i.e., reader) and ensures its recommendation to the user. CF affords technology to recommend books of prospective interests. Different people visit the library for different reasons and they have a different expectation based on their subject taste. If a couple of books are rated equally by two different people, then it indicates that they have similar expectations. Traditional CF-based recommendation system usually faces the issues in sparsity and scalability. Most researchers suggest having a modification in CF to solve the problems towards providing the expected books to the reader, which results in making the reader, visit the library more.
2
LITERATURE
REVIEW
Reusable pattern mining [1] proposed to detect usage patterns of libraries by the third party automatically. It focused on collecting information from libraries, which are commonly utilized by developers. This method makes use of a hierarchical clustering method to form clusters based on external readers.
————————————————
Author name is Dr.L.Santhi, Librarian, PSGR Krishnammal
Recommender Systems
Knowledge based Filtering
Demographic based Filtering
Collaborative based Filtering
Content based Filtering
Hybrid Recommender
Fig 1. Recommender Systems
Process mining [2] proposed to find the expectations of readers to enhance their visit to the library. It applies a 5-step methodology in the library system to discover hidden details from the event logs. It finds the information that there exists too much difference in readers' activities and their daily tasks. Bibliomining [3] proposed to identify library usage based on bibliometrics. It presents a conceptual framework to apply to mine on bibliometrics and highlights the issues faced in bibliomining. It has provided a template for cross-domain researches to explore research systematically. Literature Retrieving Method [4] focused on solving decreased quality in data retrieval from the library. It adopts machine-learning strategies in retrieving the works of literature and library user characteristics to enhance the literature retrieval quality. Further, it makes use of Wiki methodology for retrieving the data. Distributed Data Processing [5] focused on processing library information with big data. It studied machine-learning-based libraries to perform distribution and explore the advantage in distributing computing. It compared two different platforms (i.e., Hadoop and Spark) for effective use of the library to increase the visitors' count. Effective Hybrid Technique [6] proposed to recommend books for the library user one who searches for a specific topic. It utilizes the ontology concept to enhance the efficiency of the system towards providing the recommendation. Shortly, it optimizes the search result and guides in selecting books. Text Mining Approach [7] applied to the tweet dataset by academic institution libraries. It founds information that libraries posts less than 50 tweets in a month that becomes a drawback of invisibility of resources to the users. Besides, it has found the most common term as ―resources‖ in most tweets by academic libraries. Hybrid Recommendation System [8] proposed to satisfy users in providing the most efficient books. It analyzes user behavior by making use of different book recommendation methods. It aimed to provide novelty in taking the decision to recommend a book liked by the user. User-Oriented Service [9] focused on service provided to the library user to increase their visit. It utilizes big data to analyze user behavior and offer literature resources digitally. Further, it addressed the issues in digital libraries to enhance the service provided to the user. Frequent
Pattern Growth [10] proposed to identify the relationship between books to recommend alternative books to the readers. It utilizes a prefix-tree structure to save the library database concisely and divide-and-conquer methodology increases the performance of the mining task.
3
ENHANCED
RELIABLE
COLLABORATIVE
FILTERING
This section introduces enhanced reliable collaborative filtering (ERCF) for library book readers when searching for an expected book. Its main intention is to add a sufficient factor of a neighborhood to ERCF to enhance accuracy in
book search. The attributes of many CF-based
methodologies are dependent on predetermination, inclination and popularity (rating given by previous readers), where all are static. These methods assume that all books are rated by individual readers and all readers probable to rate every book every time, where the assumption is not true all time. Firstly, the book's popularity persistently changes when a new book releases. The factors regarding season also are considered as more important. Secondly, a reader’s inclinations for a book continuously change over a period, where it leads to a change in their expectancy from books. Readers’ mood also considered as a significant factor, because readers who rated a book at 2 stars might change it to 4 stars based on their current mood. Hence, it’s necessary to consider the factor of dynamicity in rating. General CF rarely finds the dynamicity in the rating provided for books. Considering the rating provided only by few readers are not suitable for providing accurate book search results, where it acts as a feature vector in providing results. Hence this research work proposes ERCF which adjoins the dynamicity of rating and neighborhood. It holds three important parts, which are Calculating the dynamic change in ratingUpdating the weightage of readers feature vector
Considering the neighborhood value to monitor the preference of readers.
ERCF predicts the book rating as below
where is the general average rating; is the favoritism of readers, is the deviation observed, indicates the item (i.e. the book). Reader favoritism indicates the natural trend of individuals. For instance, few readers tend to provide increased ratings than others. Book favoritism indicates the natural rating of the book. For instance, few books receive increased ratings than other books. Both types of favoritism free from readers interactions.
To make optimization in root mean square error, ERCF calculates the loss in rating as
(1)
Similarly, to make optimization in mean absolute error, ERCF calculates the loss in rating as
The objective function of ERCF is calculated as
(3) where is the observing probability of user , i.e., the count of books rated by reader; is the observing probability column of item , i.e., the count of readers who have given rating for the book ; and is the parameter used to check the missing values..
Distribution probabilities of user rated books are not common due to the popularity of books and expectancy to receive a rating. Ratings from some users are mostly expected and it results in decreasing the feature vectors of readers or increasing the books ratings.
Stochastic gradient descent (SGD) is an iterative based effective tool to make optimization in a dynamic environment. ERCF adopts SGD to optimize Eqn.(3) and
achieve update rules :
(4)
(5)
(6)
(7)
where is rating of prediction, and is
the rating that is already known. is a parameter used to check missing values. indicates the parameter used in rating that controls the in every step.
Algorithm: ERCF Parameters :
Input : a series of pairs used for rating Initialize :
Random matrix for
readers feature matrix ;
books feature matrix and Zero matrix for
;
number of books rated by user and ;
number of readers who rated the book ;
For do
Obtain rate prediction request of on item Calculate and predict
Discovery of original rating Algorithm endure a loss
Revise cum
Revise cum
Revise , , , and depending on
, respectively End for
4. ABOUT PERFORMANCE METRICS
This research work makes use of benchmark data mining oriented metrics to evaluate the performance of the proposed methodology in predicting the expected books of readers and it helps in increasing their visit to the library. Benchmark performance metrics are formulated as below:
(8)
(9)
(10)
(11)
(12)
(13)
(14)
(15)
The above-mentioned performance metrics depend on the below-mentioned attributes
True-positive : Accurate positive prediction in searching for a book.
True-negative : Accurate negative prediction
in searching for a book.
False-positive : Inaccurate positive prediction in searching for a book.
False-negative : Inaccurate negative
prediction in searching for a book.
5. RESULTS AND DISCUSSIONS
This research work makes use of data collected from different libraries in and around Coimbatore from the academic year 2014-2015 to 2018-2019. It includes information of 39728 users, 75423 books and 161478 book borrowing records.
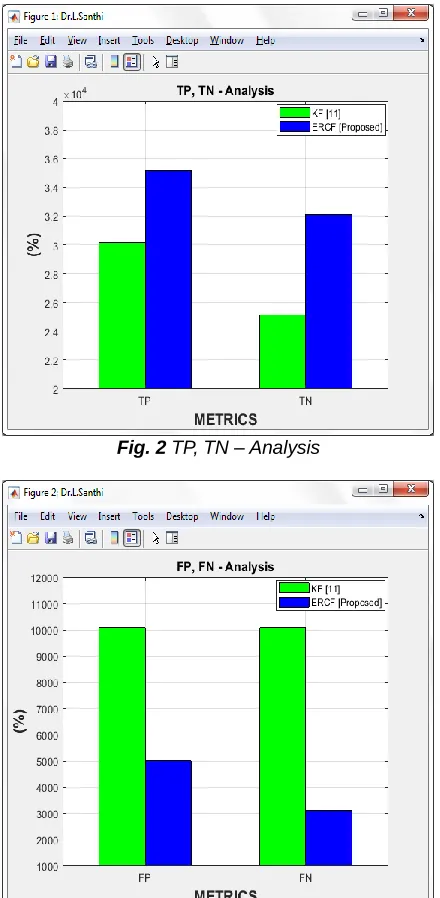
5.1 Analysis of True Positive and True Negative
better in predicting the expected books of readers. It is because ERCF considers the rating provided by the readers dynamically.
5.2 Analysis of False Positive and False Negative Analysis
Fig 3 compares the FalPos and FalNeg of ERCF against KF [11]. Fig 3 demonstrates that ERCF has low levels of false prediction when comparing with KF [11]. The reason for KF [11] getting more false prediction is due to considering the rating that is provided by the readers in later days.
5.3 Analysis of Sensitivity and Specificity
Fig 4 compares the Sensitivity and Specificity of ERCF against KF [11]. Fig 4 clearly illustrates that ERCF has better Sensitivity and Specificity when comparing with KF [11]. ERCF makes use of the neighborhood values towards prediction and it results in better results than KF [11].
Fig. 2 TP, TN – Analysis
Fig. 3 FP, FN – Analysis
5.4 Analysis of Positive Rate
Fig 5 compares the Positive rates of ERCF against KF [11]. Fig 5 clearly shows that ERCF has better true and false positive rates when comparing with KF [11]. ERCF optimizes the results that it receives from the rating provided by the readers and it results in better outcomes than KF [11].
Fig. 4 Sensitivity, Specificity - Analysis
Fig. 5 Positive Rate – Analysis
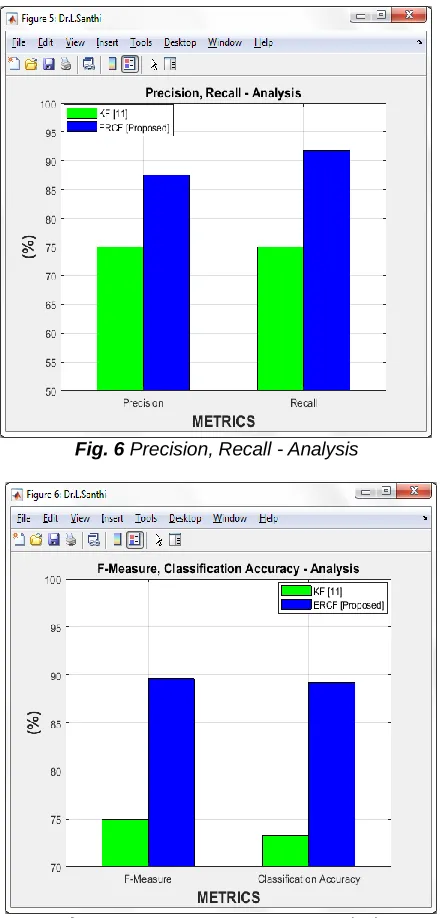
5.5 Analysis of Precision and Recall
5.6 Analysis of Accuracy and F-Measure
Fig 7 compares the accuracy and f-measure of ERCF and KF [11]. From Fig 7 it is clear to understand that ERCF is better in predicting the user expected book by considering the rating given by reader to a book, where KF [11] has poor results in predicting the user expected book due to fully depending on the rating provided initially and some specific users.
Fig. 6 Precision, Recall - Analysis
Fig. 7 Accuracy, F-Measure - Analysis
6. CONCLUSION
This paper has proposed enhanced reliable collaborative filtering to predict the user expected book in academic libraries. Due to weak filtering, readers are not able to get their expected book which results in a decreased visit to the library. Previous filtering methods consider the rating provided previously by the users and it never considers the rating that is updated, which results in poor prediction of expected books. This research work gives importance to all
the ratings given by all user and it considers neighborhood values in updating the exact rating. Results show that the proposed filtering approach has better performance than the baseline scheme.
REFERENCES
[1] M. A. Saied, A. Ouni, H. Sahraoui, R. G. Kula, K. Inoue, and D. Lo, ―Improving reusability of software libraries through usage pattern mining,‖ J. Syst. Softw., vol. 145, pp. 164–179, 2018.
[2] E. Kouzari and I. Stamelos, ―Process mining applied on library information systems: A case study,‖ Libr. Inf. Sci. Res., vol. 40, no. 3, pp. 245–254, 2018.
[3] S. Nicholson, ―The basis for bibliomining: Frameworks for bringing together usage-based data mining and bibliometrics through data warehousing in digital library services,‖ Inf. Process. Manag., vol. 42, no. 3, pp. 785– 804, 2006.
[4] C. Wang, L. Liu, D. Chao, and L. Chen, ―Application of Wiki technology in literature retrieval of digital library,‖ in 2009 Joint Conferences on Pervasive Computing (JCPC), 2009, pp. 665–668.
[5] E. C. Yıldız, M. S. Aktas, O. Kalıpsız, A. N. Kanlı, and U. O. Turgut, ―Data Mining Library for Big Data Processing Platforms: A Case Study-Sparkling Water Platform,‖ in 2018 3rd International Conference on Computer Science and Engineering (UBMK), 2018, pp. 167–172.
[6] M. Chandak, S. Girase, and D. Mukhopadhyay, ―Introducing hybrid technique for optimization of book recommender system,‖ in Procedia Computer Science, 2015, vol. 45, no. C, pp. 23–31.
[7] S. M. Al-Daihani and A. Abrahams, ―A Text Mining Analysis of Academic Libraries’ Tweets,‖ J. Acad. Librariansh., vol. 42, no. 2, pp. 135–143, 2016.
[8] A. Sase, K. Varun, S. Rathod, and P. D. Patil, ―A Proposed Book Recommender System,‖ IJARCCE, pp. 481–483, 2015.
[9] S. Li, F. Jiao, Y. Zhang, and X. Xu, ―Problems and Changes in Digital Libraries in the Age of Big Data From the Perspective of User Services,‖ J. Acad. Librariansh., vol. 45, no. 1, pp. 22–30, 2019.
[10] Y. Song and R. Wei, ―Research on application of data mining based on FP-growth algorithm for digital library,‖ in 2011 Second International Conference on Mechanic Automation and Control Engineering, 2011, pp. 1525– 1528.
![Fig 2 compares the TruPos and TruNeg of ERCF against KF [11]. Fig 2 makes a clear indication that ERCF performs](https://thumb-us.123doks.com/thumbv2/123dok_us/8634500.1424208/3.612.304.571.202.470/compares-trupos-truneg-ercf-makes-clear-indication-performs.webp)