Relative Analysis of Density Based Spatial
Clustering of Applications of Noise and K-Means
Algorithms in Bioinformatics
Sarangam Kodati1,Dr. R P. Singh2
1
Research Scholar, Department of Computer Science and Engineering, Sri Satya Sai University of Technology and Medical Science, Sehore,Bhopal,Madhya Pradesh ,India.
2.
Professor, Department of Computer Science and Engineering,Sri Satya Sai University of Technology and Medical Science,Sehore,Bhopal, Madhya Pradesh , India
Abstract: Data mining comes in handy, as that scours the databases for extracting hidden patterns, finding hidden information, decision make and speculation testing. Bioinformatics, an upcoming field of today’s world, which involves the makes use of large databases can be effectively searched thru data mining techniques to derive beneficial rules. Based over the type on knowledge that is mined, data mining methods [1] do be mainly classified into association rules, decision trees, or clustering. Until recently, biology lacked the tools according to analyze enormous repositories over information such as the human genome database [3]. The data mining methods are successfully old according to extract meaningful relationships from it data. Data excavation is particularly ancient in microarray analysis who is used after learning the activity over one of a kind cells below different conditions. Two algorithms underneath each mining methods had been implemented because a great database then compared with each other .Clustering k-means and Density Based Spatial Clustering regarding Applications on Noise (DBSCAN) clustering methods [5] were applied according to a microarray dataset and compared. The microarray dataset used to be downloaded beside the internet using the Gene Array Analyzer Software (GAAS). Stability Owing to the involvement concerning enormous datasets and the need according to derive results from them, data mining methods perform stay effectively eke out after makes use of among the subject of Bioinformatics [4].
Keywords: Data Mining, Clustering, bioinformatics, Microarray, k-means clustering, DBSCAN
I. INTRODUCTION
Data mining is a technique of discovering potential, novel, interesting and formerly unknown pattern from a large volume of data. That refers to use for extracting or mining knowledge from a large amount about data. Facts mining is also called as “knowledge discovery from data"(KDD). There are quantities on mean terms similar in accordance with data mining as knowledge extraction, data dredging and data archaeology.
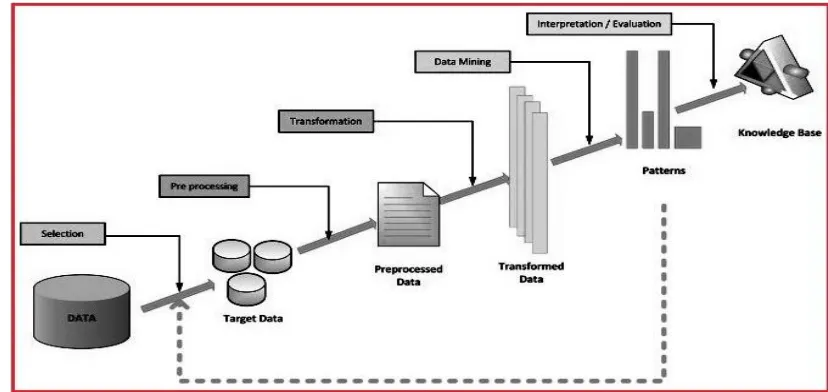
[image:2.612.95.509.526.722.2]A. The iterative process [5] consists on the following steps:
1) Data cleaning: Also known as data cleansing, it is a segment among which noisy data and irrelevant data are removed beyond the collection.
2) Data integration: At it stage, multiple data sources, repeatedly heterogeneous, may additionally be combined between a frequent source.
3) Data selection: At it step, the data applicable in conformity with the analysis is decided about or retrieved from the data collection
4) Data mining: It is the crucial step in as clever methods are applied to remove information patterns probably useful.
5) Pattern evaluation: In this step, exactly hearty patterns representing potential are identified primarily based over given measures
6) Knowledge representation: It is the final segment within which the observed knowledge is visually represented in conformity with the user. This essential step makes use of seeing methods according to help customers understand or comment the data mining results.
The KDD is an iterative process. Once the discovered knowledge is presented to the user, the evaluation measures be able lie enhanced, the dig be able keep further refined, recent data be able keep elected or similarly transformed, or instant data sources do lie integrated, within order according to arrive different, more suitable results.
II. CLUSTERING TECHNIQUES
In gene expression data, such is value to cluster both genes and samples. There are three types over clustering that execute stay applied to microarray data: gene-based clustering, sample-based clustering and subspace clustering where genes or samples are treated in the same manner. In case of gene clustering, the clustering is ancient to reduce the search rate on the dataset. In law of sample-based clustering, the clustering is back in conformity with group the samples of the identical type inasmuch as within subspace based clustering each the duties are performed. Gene-based clustering be able remain applied in conformity with the supervised dataset where the samples are already classified. The distinctive characteristic regarding gene manifestation data allows clustering both gene yet samples. The clustering evaluation regarding sampled data is in accordance with find latter biological classes and to refine the existing ones.
There are different types of clustering:
A. Hierarchical Clusterin
B. Partitioning Algorithms
C. Density based clustering
D. Constraint based clustering
E. Evolutionary Clustering
F. Graph Partitioning based Algorithms
Fig 2.Clustering example
III. BIOINFORMATICS
[image:3.612.161.452.512.640.2]interpreting or using records from biological sequences and molecules. It has been often fueled by means of advances into DNA sequencing or mapping techniques. Over the past not much decades, fast developments of genomic then vile molecular lookup technologies yet tendencies in information technologies have blended in conformity with occurrence a substantial aggregate on facts related in conformity with molecular biology. The principal intention on bioinformatics is to expand the appreciation over biological processes.
IV. FUNDAMENTALS OF MOLECULAR BIOLOGY
Deoxyribonucleic acid (DNA) is the basis on genetic material. In other words, the data stored into DNA allows the corporation concerning dead molecules within functioning among living cells yet organisms. These groupings can regulate their internal chemical composition, growth, and reproduction. The various units to that amount govern these characteristics, stand such chemical composition yet nose size and are called genes. Genes themselves contain their data as a specific sequence on nucleotides so much is discovered between DNA molecules. Only 4 different nucleotides (or bases) are used among DNA molecules: adenine, guanine, cytosine and then thymine (A, G, C and T). All the data within each gene comes surely beyond the order in which those nucleotides are found. Complicated genes may be dense thousands concerning nucleotides long. Many genes code for proteins yet excellent estimates are up to expectation such takes several tens over thousands on exceptional proteins in accordance with redact a human being. Fundamentally, a protein is a lengthy chain (a polymer) concerning building blocks called amino acids. Varying combos concerning only 20 different amino acids are ancient according to construct all regarding the proteins in a human being.
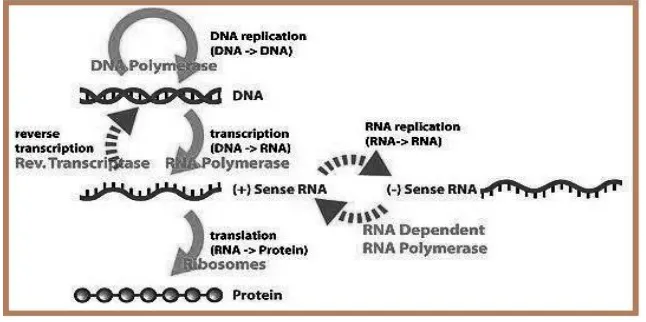
Fig 3.The Central Dogma of Molecular Biology
The simplified version of the central dogma is so shown within the diagram. It consists about the following steps: Replication over DNA, Transcription about DNA to RNA, Translation in accordance with proteins and protein folding.
A. Replication
In the process concerning DNA replication, entire the information in the double-stranded adjunct regarding a DNA helix is duplicated concerning every strand. This reversible or specific interaction of complementary lousy pairs is critical because entire the features regarding DNA between dwelling organisms.
B. Transcription
In that process, the DNA is transcribed in conformity with single-stranded nuclear RNA (nRNA) who is afterward processed according to structure turned orderly RNA (mRNA).Small nuclear RNA (snRNA) is worried of the maturation process, which includes exciting the introns (non-coding segments) then concatenating the remaining exons (coding sequences) in accordance in imitation of theirs unique rule among the mRNA. The RNA differs from DNA into as it carries a nitrogenous base Uracil (U) as an alternative about the Thymine (T). mRNA is transported via the nuclear membrane in conformity with the cytoplasm where the removal concerning mRNA to protein takes place with the aid on ribosome.
C. Translation
[image:4.612.145.468.301.462.2]sequence certain at a day as like the ribosome strikes from codon in conformity with codon alongside the mRNA. At the give up codon, the translation ends then the protein is launched by means of the ribosome.
D. Protein folding
Before the protein is transported outside the phone in conformity with perform and promote a variety concerning tasks, it is typically modified by using adding a sugar, because example, then such takes over a characteristic folded three-dimensional form forming polypeptide sequences.
V. MICROARRAY EXPERIMENTAL ANALYSIS
Molecular Biology research evolves through the development over the technologies used for bearing to them out. It is not possible in imitation of lookup of a massive range of genes the use of normal methods. One perform analyze the expression over dense genes of a single reaction quickly or in an efficient behavior the usage of microarrays. Microarray technological know-how has empowered the scientific community in conformity with understand the indispensable factors underlining the growth and development about life so well so after explore the genetic reasons of anomalies taking place of the functioning regarding the ethnic body. All the data is collected yet a profile is generated because gene expression in the cell.
DNA microarrays [4] are created by robotic machines so much arrange minuscule quantities over hundreds and thousands regarding gene sequences over a single microscope slide. Researchers have a database regarding above 40,000 gene sequences that they can makes use of for it purpose. When a gene is activated, mobile equipment begins after copy certain segments on as gene. The mRNA produced with the aid of the cells bind in accordance with the original portion concerning the DNA strand from who such was once copied. To decide which genes are turned concerning or who are became aloof in a given cell, a researcher ought to first accumulate the mRNA molecules current among that cell. The researcher since labels each mRNA molecule through attaching a fluorescent dye. Next, the researcher locations the labeled mRNA to a DNA microarray slide. The carrier RNA so much was once present of the cell pleasure then hybridizes yet bind in imitation of its complementary DNA on the microarray, leaving its fluorescent tag. A researcher should then usage a exceptional scanner in conformity with excuse the fluorescent areas of the microarray. Researchers oft use this approach in imitation of look at the activity on various genes at exceptional times. This activity is referred in accordance with as like the gene expression value over the genes.
Fig4.Microarray experimental analysis
expression pattern is after compared in conformity with the expression pattern regarding a gene responsible because of a disease. Spots together with more intensity are obtained for diseased tissue gene if the gene is over expressed in the diseased condition.
VI. DATA MINING IN BIOINFORMATICS
The entire human genome, the fulfilled set about genetic data within each ethnic cell has now been determined. Understanding it genetic instructions promises after allow scientists in imitation of better recognize the habit concerning ailments and their cures, after identify the mechanisms underlying organic procedures certain as like increase and growing old then in accordance with clearly song our evolution and its kindred together with mean species. The answer obstacle mendacity among investigators yet the potential he pray is the alone aggregation about records available. This is evident from the similar figure who indicates the rapid increase into the variety over base pairs and DNA sequences among the repository regarding GenBank. Biologists, like most natural scientists, are trained primarily to collect new information. Until recently, biology lacked the equipment according to analyze massive repositories about information certain as the human genome database. Luckily, the discipline on pc lore has been rising techniques and approaches well suited in imitation of help biologists control then analyze the awesome quantities over data that promise according to profoundly enhance the human condition. Data mining is one such technology.
Fig5. Growth of GenBank (1982-2008)
VII.APPLICATION OF CLUSTERING TECHNIQUE TO MICROARRAY ANALYSIS
The application procedure consists regarding the according steps: Inspect the micro array and qualitatively assign each spot of the micro array a value corresponding after its gene expression level, as is done at once beyond its color intensity. To analyze gene expression patterns [1] the use of a clustering algorithm, we do the following:
We construct a mail sample because the one-of-a-kind genes.
Cluster the genes based concerning their tally using a clustering algorithm.
We give up upon including clustering comparable genes, grouped through their expression levels we hold used couple clustering algorithms: k-means and DBSCAN.
A. K-means Clustering
K-means clustering is a kind of unsupervised learning, which is used now thou bear unlabeled data (i.e., information without defined classes or groups). The goal about that algorithm is in accordance with find groups in the data, along the number of groups represented by the variable K. The algorithm manufactory iteratively in imitation of hand over each information point in accordance with certain about K groups based of the applications so is provided. Data points are clustered primarily based on feature similarity. The results about the k-means crusting algorithm are:
The centroids regarding the k clusters which be able keep back in conformity with note new data
organizations so hold made organically. The "Choosing K" quantity below describes how the range of groups can lie determined. Each centroid of a cluster is a series over function values who define the resulting groups. Examining the centroid function weights do be used in accordance with qualitatively interpret as variety regarding group every cluster represents.
1) Algorithm
a) Input: - Database of objects D
Select arbitrarily k representative objects Kmean
Mark these objects as chosen then the remaining as non-selected
do for all selected objects Oi
do for entire non-selected objects Oj
compute Cih
end do end do
select imin, hmin such that Cimin,hmin = Mini,h Cih if Cimin,hmin < 0
then swap;mark Oi as non-selected and Oh as selected
repeat
find clusters C1, C2, C3…..,Ck
B. Density Based Spatial Clustering of Applications of Noise (DBSCAN)
Density Based Spatial Clustering of Applications of Noise (DBSCAN) uses a density based notion of clustering concerning fair shapes. For each object of a cluster, the local concerning a addicted radius must contain at least a minimum number regarding data objects. Such objects are called core objects. The algorithm gradually converts the unclassified objects into categorized then noise objects.
1) Algorithm
DBSCAN Algorithm ( D, , Minpts)
a) Input: Database of objects D
do for all O D
if O is unclassified
call function Expand_cluster(O, , Minpts) End do
Function Expand_Cluster(O, D, , Minpts)
get the _neighborhood of O as N (O)
if | N (O)| < Minpts
mark O as Noise
Return Else
Select a cluster_id & mark all objects of N (O) with this id and put them into
Candidate objects
do while candidate object is not empty
select an object from candidate objects as curr_obj delete curr_obj from candidate objects
retrieve N (curr_obj) if | N (O)| Minpts
select all objects in N (curr_obj) not yet classified or marked
as noise
mark all of the objects with cluster_id
include the unclassified objects into candidate objects End do
Table 1: Comparison of results of k-means and DBSCAN (Microarray Database)
Location MSI
(Mean Signal Intensity)
MBI
(Mean Background Intensity)
Index
10102 1.162 1.06 1
10201 0922 0.994 2
10202 1.056 1.076 3
10301 0.97 0.983 4
10302 1.047 1.05 5
10401 0.979 0.97 6
10402 1.03 1.068 7
10501 0.959 1.027 8
10502 1.029 1.113 9
10601 1.004 1.045 10
The two clustering techniques, DBSCAN and K-means had been applied regarding the microarray dataset. The dataset used to be procured using the Gene Array Analyzer Software (GAAS). Location signifies the position over the gene into the microarray chip. MSI (Mean Signal Intensity) is the intensity about the passion as was once present in the location. MBI (Mean Background Intensity) is the intensity concerning the much less illuminated location. The clustering was done over the foundation about MSI. The consonant results were obtained.
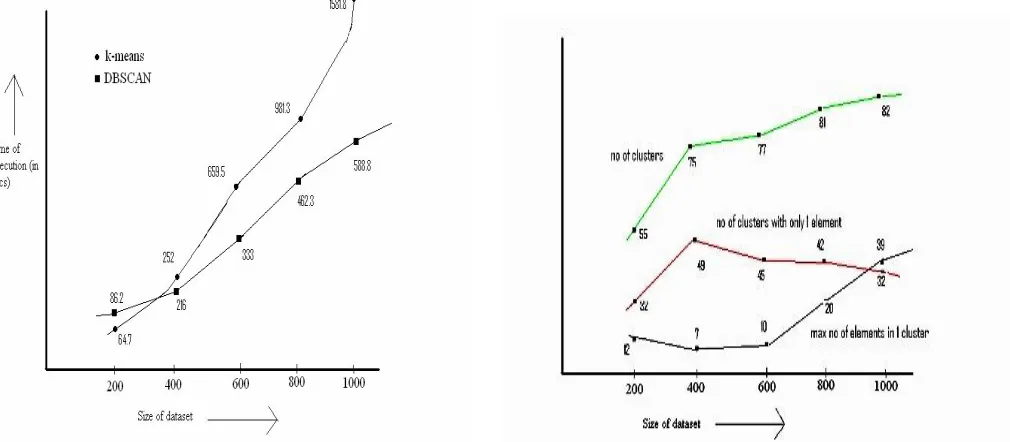
Fig.6: Performance comparison of DBSCAN and K-means based on time of execution Fig.7: Performance of DBSCAN with increasing database size
For the microarray dataset, such was found so DBSCAN is less efficient than k-means when the database is small however because of a larger database, DBSCAN is more accurate and efficient of phrases about no. of clusters and epoch concerning execution. DBSCAN execution time increases linearly with the increase of database or was once a lot lesser than that Concerning k-means for a larger database.
VIII.CONCLUSION
[image:8.612.56.561.341.562.2]within groups concerning similar character. The microarray experiment produces thousands of samples because each gene, clustering can be efficaciously used in conformity with group these genes in disease causing genes yet normal
genes and in conformity with discipline the various traits over different genes underneath special conditions.
access for diagnosis of incurable diseases as AIDS, Alzheimer’s disease. It execute also lie used in imitation of identify the mechanisms underlying organic methods such as increase and ageing then in imitation of track the procedure over our evolution. Data mining is, therefore, an effective method in accordance with resolve the problem of enormous data faced by using researchers in their aim according to solve the puzzles on our life.
REFERENCES
[1] Liu, L., Yang, Jiong. and Tung, Anthony. “Data Mining Techniques for Microarray Datasets”, Proceedings of the 21st International Conference on Data 13 Engineering 2005 IEEE. 182-192, 2005
[2] Piatetsky-Shapiro, G. and Tamayo, P : “Microarray Data Mining: Facing the Challenges” SIGKDD Explorations, 5(2), 1-5, 2003 . [3] Han, Jiawei and Kamber, Micheline. Data mining: concepts and techniques, San Francisco: Morgan Kaufmann Publishers Inc., CA, 2000.
[4] Zhang, Dongsang and Zhou, Lina. “Data Mining Techniques in Financial Application” IEEE Transactions on Systems, Man and Cybernetics – Part C: Applications and Reviews, 34, 4, 513 – 522, Nov-2004,
[5] Pujari, Arun . Data Mining Techniques. Nancy: Universities Press, 2001.
[6] Piateski, Gregory and Frawley, William. Knowledge Discovery in Databases, Cambridge: MIT Press, MA, 1991 [7] Shah, Shital C. and Kusiak, Andrew, “ Data Mining and Genetic Algorithm Based Gene Selection” Artificial Intelligence