Procedia Computer Science 79 ( 2016 ) 199 – 206 Available online at www.sciencedirect.com
1877-0509 © 2016 The Authors. Published by Elsevier B.V. This is an open access article under the CC BY-NC-ND license (http://creativecommons.org/licenses/by-nc-nd/4.0/).
Peer-review under responsibility of the Organizing Committee of ICCCV 2016 doi: 10.1016/j.procs.2016.03.026
ScienceDirect
7th International Conference on Communication, Computing and Virtualization 2016
Use of Fuzzy tool for example based machine translation
Manish Rana ,
Mohammad Atique
Manish Rana ,Research Scholar, Post Graduate Department of Computer Science & Engineering, Sant Gadge Baba Amravati University, Amravati, India [email protected]
Mohammad Atique Associate Professor, Post Graduate Department of Computer Science, Sant Gadge Baba Amravati University, Amravati, India, [email protected]
Abstract
This research paper proposes work carried in machine translation. It shows the comparison of various techniques like SMT, SSER, EBMT, RBMT etc used for machine translation. After going through the result of various techniques it conclude that still better result can be gained .Thus proposes an idea of using Fuzzy logic tool to improve the natural learning process and get better result around 81.7 percentage. This work shows the implementation of the tool for refining the result in example based machine translation using fuzzy logic.© 2016 The Authors. Published by Elsevier B.V.
Keywords:Keyword: SMT, NLP, RBMT, EBMT, SSER etc.
General Terms: Fuzzy logic, Tokenization, machine translation etc.
1. Introduction: Design of System EBMT Using NLP
The proposed EBMT [1] framework can be used for automatic translation of text by reusing the examples of previous translations. This framework comprises of three phases, matching, alignment and recombination.
Figure: 1.1 Design of system EBMT Using NLP
a. Tokenization
Tokenization [2] is a primary step of Example based machine translation. In this phase, the input sentence is decomposed into tokens. These tokens are given to POS stagger function to tag the tokens with their respective type. e.g. Sentence : “India has won the match by six wickets.”
Tokens : “India” “has” “won” “the” “match” “by” “six” “wickets.”
Tokenization is a primary step of Example based machine translation. In this phase, the input sentence is
decomposed into tokens. These tokens are given in to POS stagger function to tag the tokens with their respective © 2016 The Authors. Published by Elsevier B.V. This is an open access article under the CC BY-NC-ND license
(http://creativecommons.org/licenses/by-nc-nd/4.0/).
type.
Figure: 1.2.a Result of tokenization Figure: 1.2.b Result of tokenization
b. POS Tagger
A Part-Of-Speech Tagger (POS Tagger) is a piece of software that reads text in some language and assigns parts of speech to each word (and other token), such as noun, verb, adjective, etc., although generally computational applications use more fine-grained POS tags like 'noun-plural'.
A Part-Of-Speech Tagger (POS Tagger) is a piece of software that reads text in some language and assigns parts of speech to each word (and other token), such as noun, verb, adjective, etc., although generally computational applications use more fine-grained POS tags like 'noun-plural'.
Figure: 3.3 POS Tagger result.
c. Matching Phase
Searching the source side of the parallel corpus for ‘close’ matches and their translations [3]. In matching phase, each token which is tagged with POS tag is searched in the dictionary of words and if match is found, then that word is passed to next phase.
d. Word-based Matching Corpus Size (No. of Sentences) Unigram Precision Unigram Recall
F-measure BLEU NIST mWER SSER
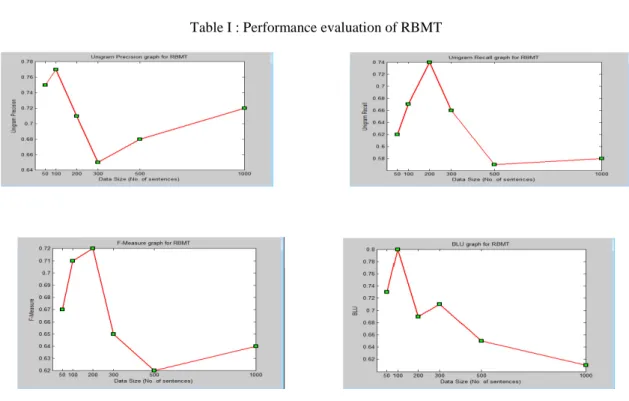
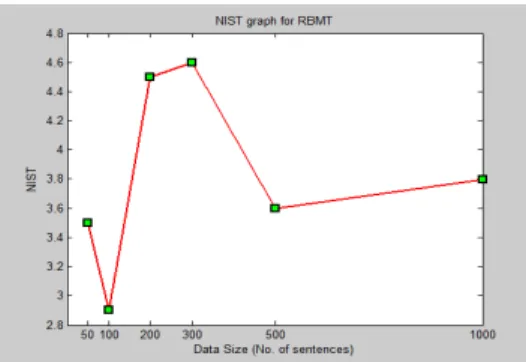
50 0.73 0.63 0.67 0.71 2.5 80.24 92.36 100 0.77 0.65 0.70 0.72 2.5 85.63 91.45 200 0.78 0.72 0.74 0.70 3.5 86.33 96.21 300 0.69 0.62 0.65 0.69 4.1 85.11 90.14 500 0.76 0.53 0.62 0.62 3.8 79.45 94.99 1000 0.70 0.56 0.62 0.62 3.9 88.14 97.21
Perhaps the “classical” similarity measure, suggested by Nagao and used in many early EBMT systems [4], is the use of a thesaurus or similar means of identifying word similarity on the basis of meaning or usage [6]. Here, matches are permitted when words in the input string are replaced by near synonyms (as measured by relative distance in a hierarchically structured vocabulary or by collocation scores such as mutual information) in the example sentences.
e. Indexing
In order to facilitate the search for sentence substrings, we need to create an inverted index into the source-language corpus. To do this we loop through all the words of the corpus, adding the current location (as defined by sentence index in corpus and word index in sentence) into a hash table keyed by the appropriate word. In order to save time in future runs we save this to an index file.
f. Chunk Searching and Subsuming
Keep two lists of chunks: current and completed.
¾ Looping through all words in the target sentence:
¾ See whether locations for the current word extend any chunks on the current list ¾ If they do, extend the chunk.
¾ Throw away any chunks that are 1-word. These are rejected.
¾ Move to the completed list those chunks that were unable to continue ¾ Start a new current chunk for each location
¾ At the end, dump everything into completed. ¾ Then, to prune, run every chunk against every other:
¾ If a chunk properly subsumes another, remove the smaller one ¾ If two chunks are equal and we have too many of them, remove one
RBMT
Table I : Performance evaluation of RBMT
Figure: 5.1 Performance evaluation of RBMT
SMT
Table II : Performance evaluation of SMT
Corpus Size (No. of Sentences) Unigram Precision Unigram Recall F-measure
BLEU NIST mWER SSER
50 0.75 0.62 0.67 0.73 3.5 79.21 91.17 100 0.77 0.67 0.71 0.80 2.9 82.52 90.24 200 0.71 0.74 0.72 0.69 4.5 84.00 90.21 300 0.65 0.66 0.65 0.71 4.6 82.31 90.14 500 0.68 0.57 0.62 0.65 3.6 69.45 89.93 1000 0.72 0.58 0.64 0.61 3.8 88.14 93.22
Figure: 5.2 Performance evaluation of SMT
EBMT
Table III : Performance evaluation of EBMT
Corpus Size (No. of Sentences) Unigram Precision Unigram Recall F-measure
BLEU NIST mWER SSER
50 0.71 0.79 0.74 0.71 2.6 81.11 94.21 100 0.74 0.80 0.76 0.73 3.2 78.44 93.96 200 0.79 0.85 0.81 0.75 3.9 77.24 93.12 300 0.84 0.88 0.85 0.81 4.5 74.02 92.32 500 0.85 0.92 0.88 0.83 5.0 70.00 89.44 1000 0.90 0.94 0.91 0.91 6.6 65.22 81.77
2. Comparison of results for RBMT, SMT and EBMT
Size of Data Set (No. of sentences)
1. Figure 6.1: Comparison of results for RBMT, SMT and EBMT
2. Reference
1. Manish Rana, Mohammad Atique, “Example Based Machine using fuzzy logic from English to Hindi” Int'l Conf. Artificial Intelligence , ICAI'15 , pp 354-359.
2. Manish Rana, Mohammad Atique, “Example Based Machine using various soft computing techniques review" IJSER “International Journal of Scientific & Engineering Research”, Volume 6, Issue 4, April-2015, ISSN 2229-5518E pp.1100-1106.
3. Manish Rana, “Review: Machine using various soft-computing Tools “International Conference on communication computing & Virtualization Vol 6 Issue 2, Feb 23 & 24, 2015 pp. 813- 816..
4. H. H. Owaied, M. M. Qasem, “Developing Rule-Case- Based Shell Expert System,” Proc.of Int. MultiConf. of Engineers & Scientists, vol. 1, 2010.
5. M. G. Tsipouras, C. Voglis, D. I. Fotiadis, “ A Framework for Fuzzy Expert System Creation -Application to Cardiovascular Diseases,” IEEE Transactions Biomedical Engg., vol. 54, no. 11, pp. 2089-2105, 2007. 6. Medical diagnosis control System”, International Journal on Computer Science and Engineering (IJCSE),
ISSN : 0975-3397 Vol. 3 No. 5 May 2011
7. Zadeh LA: Fuzzy sets. Information and control 8: 338-353, 1965 A system architecture for medical informatics. Fuzzy sets and systems 1994 ; 66 : 195-205.
8. Jort F. Gemmeke*, Student-Member, IEEE, Tuomas Virtanen, Antti Hurmalainen “Exemplar-based sparse representations for noise robust automatic speech recognition”This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publicationCopyright (c) 2011 IEEE. Personal use is permitted. For any other purposes, Permission must be obtained from the IEEE by emailing [email protected]: 1-14
9. Mehrez Boulares1 and Mohamed Jemni2, Research Lab. UTIC, University of Tunis, 5, Avenue Taha Hussein, B. P. : 56, Bab Menara, 1008 Tunis, Tunisia “Toward an example-based machine translation from written text to ASL using virtual agent animation” IJCSI International Journal of Computer Science Issues, Vol. 9, Issue 1, No 1, January 2012
10. Stephen J. Wright, Dimitri Kanevsky, Senior Member, IEEE, LiDeng, Fellow, IEEE,, Xiaodong He, Senior Member, IEEE, Georg Heigold, Member, IEEE, and Haizhou Li, Senior Member, IEEE “Optimization Algorithms and Applications for Speech and Language Processing”IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 21, NO. 11, NOVEMBER 2013 Pages: 2231-2243 11. Hongshen Chen, Jun Xie, Fandong Meng, Wenbin Jiang Qun Liu “A Dependency Edge-
based Transfer Model for Statistical Machine Translation” Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, August 23-29 2014, pages 1103–1113.
Author Detail:
Manish Rana, PhD scholar Department of Computer Science, Sant Gadge Baba Amravati University, Amravati. He has more than seven years Teaching Experience. His area of interest includes Artificial Intelligence, Machine translation and soft computing. He has published 5 International Journal and 3 Papers in national Conference. ([email protected])
Dr. Mohammad Atique , is presently working as Associate Professor, P.G. Department of Computer Science, Sant Gadge Baba Amravati University, Amravati. He has around 37 publications to his credit in International/National Journal and conferences. His area of interest includes Artificial Intelligence, Machine translation and soft computing.([email protected])
5. Reference styles used in Procedia master templates: Title Reference style
SMT Statistical Machine Translation NLP Natural Language Process RBMT Rule-Based Machine Translation EBMT Example Based Machine Translation SSER Subjective Sentence Error Rate