Development Of Power And Performance Efficient
32-Bit Variable Latency Parallel Prefix Adder
Srinivasulu Gundala, Rajani Kumari
Abstract: A variable latency adder pays speculations in arithmetic circuits can replaced with appropriate one, which will produces faster and correct results. In this paper it is proposed Variable-Latency Adder(VLA) based Brent-Kung Parallel-Prefix configuration that outperforms Kogge-Stone. In proposed adder has two stages of operations, one is Pre-processing stage and another one is Generation-stage. The pre-processing stage is the design has propagation and generation circuits. Generation stage producess on the carry generation and result and the performance of the Brent-Kung adder throughout black-cell attain the wide area. Gray cell can be replacing the place of black cell which provide the Efficiency in BKA. Finally, a new move towards the design of efficient 32 bit low-power variable latency parallel prefix Brent Kung Adder (BKA) concentrates the gate levels for improve increase & decreases memory. The Adder which gives the addition process offers great advantages in dropping delay. Brent-Kung adder mostly used for low-power Designs and in this paper implementation of Brent-Kung Adder synthesized using Xilinx ISE 14.7 has been modelled with VHDL.
Index Terms: Speculative Adder, Variable Latency Adder, Parallel-Prefix Adder, Grey Cell, Black Cell. —————————— ——————————
1
INTRODUCTION
The VLSI configuration relates to structure of a solitary coordinated circuit to execute a complex computerized work. Normally, the plan procedure is an iterative procedure that tweaks a thought for a gadget which can be fabricated through different dimensions of structure reflection. The procedure is intricate and includes a progression of steps that incorporates detail to manufacture, in which the coordinated circuit is created. Starting with dynamic prerequisites, the procedure includes changing over these necessities into a register exchange portrayal, e.g., control stream, registers and number juggling and intelligent tasks, which is reenacted and tried. It is then moved to circuit portrayal including entryways, transistors and interconnections. At this crossroads, reenactment is utilized to confirm every segment. At last, the geometric design of the chip is created as geometric shapes embodying circuit components and their interconnections. The diagram of the format, hence, plans to accomplish territory conservativeness and exactness in directing and timing. The unmistakable advances engaged with VLSI configuration cycle. These means are framework particular, useful structure, rationale configuration, circuit plan, physical structure, manufacture and testing [1].
2
LITERATURE
SURVEY
Adders are key structure modules in ALU and subsequently expanding the speed and lessening the energy utilization firmly influence the speed performance and power utilization of processors [2].
Fig.1.1: VLSI design flow
There are numerous takes a shot at the subject of upgrading the speed and intensity of these units, which have been accounted for. Clearly, it is very alluring to accomplish faster operations at low-control/power utilizations, which is a test for the architects of universally useful processors. One of the viable systems to bring down the power utilization of computerized circuits is to decrease in supply voltage because of reliance of the exchanging energy on the voltage. Also, the isubthreshold current, which is the principle spillage segment in OFF gadgets, has an exponentially reliance on the supply voltage level using the drain-actuated boundary bringing down impact. Contingent upon the measure of the supply voltage decrease, the activity of ON gadgets may live in the isuperthreshold, close threshold, or sub threshold locales. Working in the superthresholdl district gives us lower delay and higher exchanging and spillage forces contrasted and the close/sub threshold locales. In the isubthreshold district, the logic door delay and spillage power display exponential conditions on the supply & threshold voltages. In addition, these voltages are (conceivably) subject to process and natural varieties in the nano-scale advances[3]. The varieties increment vulnerabilities in the aforementioned execution parameters[4], [5]. Moreover, the little sub threshold current causes an enormous delay for the circuits working in the sub
_________________________________
• Dept. of ECE, Lakireddy Bali Reddy College of Engineering (Autonomous), Krishna Dt. Andhra Pradesh, India, PH-9440831750. E-mail: [email protected]
3795 threshold level in fig 1.1.
2.1 Ripple-Carry Adders
The aggregate phase is bolstered truly to pass on in to the going with stage. In n-bit parallel process it may require n number of adders shown in fig 2.1.
2.2 Carry Select Adders
This results in two pre computed total and complete sign sets (s0i-1: k, s1i-1: k , c1i) , soon after as the square's real pass on in (ck) ends up known , the correct sign sets are picked. Overall multiplexers are used to incite passes fig 2.2.
2.3 Carry Look Ahead Adders
Pass on Look Ahead Adder can make passes on speedier due to pass on bits created in parallel by additional equipment at whatever point information sources change [6]. These techniques uses pass on evade reason to quicken the pass on inciting in the fig 2.3. Allow ai and bi to be the added ends and numbers to be included information sources, ci the pass on data, si and ci+1 , the sum and complete for the ith bit in the position. If the associate limits, pi and gi are called the cause & make flag, the aggregate yield exclusively are portrayed as seeks after [7]. pi = ai + bi gi = ai xor bi xor ci ci+1 = gi + pi ci.
3
PROPOSED
SYSTEM
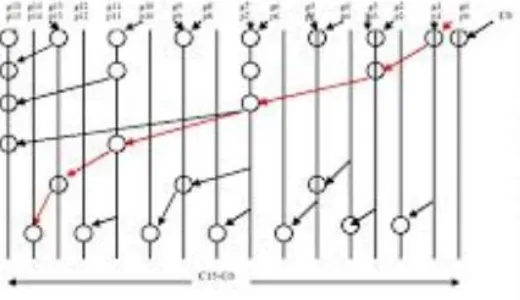
Brent-Kung adder is a notable and most extensively use dipper. Generally, it gives a phenomenal number of stages from commitment to all yields yet with upside down stacking of in-between stages. This is one of a parallel-prefix-adders.
Fig.3.1 Bit wise PG logic
The wellsprings of data An and B are given to PG reason as showed up in the square diagram fig 3.1. 32 PG method of reasoning squares are required for a 32-piece snake. The yields of this square are incite (P) and produce (G) signals. These sign are given to the tree structure of Brent Kung snake. This structure contains dim cells and dull cells organized as analyzed in Brent Kung viper territory. A diminish cell has three data sources and one yield as showed up in the figure. Make and induce signals from present stage and produce signal from past stage are inputs. Social occasion produce sign is the yield. Each stage closes with a diminish cell in any tree structure and the yield of this dim cell is the social event produce signal which is considered as the pass on of that sort out in fig. 3.2. Dim cell has 4 wellsprings of data and 2 yields. The commitments for a dim cell are P and G indication of present stage and P, G indication of past stage[6].
Fig.3.3. Proposed 32-bit Brent Kung Adder
The structure of efficient BK adder involves the three stages. The three stages are pre-process stage, carry generating stage, and post-process shown in fig 3.3.
3.1 The Pre-Processing Stage
In preprocessing stage, produce & spread the from the each pair will wellsprings of information. Multiply perform "EXOR" movement the data bits and make action "AND" action of data bits. The multiply (Pi) and make (Gi) are showed up in underneath conditions 1 and 2.
(1)
(2)
3.2 The Carry-Generation Stage
In Carry Generation, pass on delivered for each piece called as pass on make (Cg). The pass on induce and pass on produce is made for the further action yet last cell present in the each piece of movement and gives pass on it. The last piece pass on will convey total of the accompanying piece simultaneously till the last piece. The pass on make and pass on induce are given in underneath conditions 3 and 4.
(3)
(4)
The above pass on spread Cp and pass on age Cg in conditions 3 and 4 is dim cell and the underneath exhibited
pass on age in condition 5 is diminish cell. The pass on multiply is made for the further movement yet last cell present in the each piece action and it gives the pass on. The last piece pass on will convey entire of the accompanying piece simultaneously till the last piece. This pass on is used for the accompanying piece all out action, the pass on make is given in underneath conditions 5.
(5)
C. Post-processing stage
It is the last period of a compelling Brent Kung snake, the pass on of an at first piece is XOR with the accompanying the bit of multiplies then yield is given as aggregate and showen in condition 6.
(6)
It is utilizes the two-sixteen piece development exercises and each piece pass on is encounters post-getting ready stage with multiply and produce the last aggregate. The essential data bits goes through pre-taking care of stage & will make multiply and generate. These causes and makes encounters pass on age arrange which produces pass on makes and pass on multiplies, these encounters post-taking care of stage and gives last all out. In Efficient Brent Kung snake, dim cell works three entryways and diminish cell works two passages. The dim cell will decrease the deferment & memory since this works two portals. In the proposed adder is structure with both dim and diminish cells. By means of faint cell exercises at the last period of planned adder gives a colossal reducing deferment & memory use. In the planned adders showed in fig 3 can fabricates the rapidity & decrease the remembrance for movement of 8-piece development. The data bits Ai and Bi centers around make and multiply by XOR AND exercises. These induces and makes encounters the exercises of dim cell and diminish cell and gives the pass on Ci. That pass on is EXOR with the spread of piece, that gives sum.
4
SIMULATION
RESULTS
The Efficient BKA is design using VHDL. Xilinx ISE 14.7 is used and Simulation results of efficient 32-bit Low Power Variable Latency Speculative Parallel Prefix BKA are as below. Fig.4.1 dipicts the RTL schematic of anticipated design and Fig.4.2 represents technology schematic.
3797 Fig. 4. 2 .Technology transfer
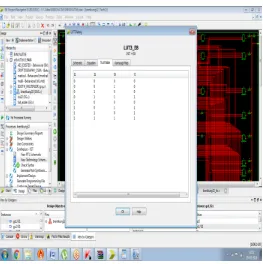
Fig. 4. 3 Look Up Table (LUT)
The development adders done on VHDL and the design of Look up table (LUT) is shown in Fig.4.3 and 4.4.
Fig.4.4Truth Table
Fig.4.5 K MAP
The Above Fig.13 and Fig.14 represents the truth table and K-Map of 32 bit BKA.
Fig. 4. 6 Result of 32-BKA
The simulation result is 32-bit Low Power Variable Latency Speculative parallel prefix Brent-Kung Adder has been shown in Fig.4.5 and 4.6
5
CONCLUSIONS
A new approach to designing an Efficient Brent Kung Adder in this project focuses on gate levels for speed improvement and memory reduces. It’s look like a cells and tree structure are reduced at Carry-Generation Stages to increase the speed of binary summation. The summation operation of the proposed Adder provides a huge benefit in decreasing delay. The future scope is to design 32 Bit Proposed Adder with fewer black cells to enhance the area and delay by the performance of adders.
REFERENCES
[1]. Chakali, Patnala “Design of the high speed Fischer based carry selection adder” IJSCE, Vol. 3, Issue.1, March. 2013
[2]. Haridimos T. Modulo 2n+1 design IEEE Trans. on computers, vol .61, no. 2, Feb 2012.
prefixing adders using FPGAs, Trans. On circuit IEEE., Pages.0168-0172, March 2011
[4]. Al-Khalili, “performance of parallel prefix adders implemented with FPGA technology,” IEEE Workshop on C&S, pp.0498-0501, Aug-2007.
[5]. S. Knowles,” A family of adders,”proc.15thsymp. Comp. Arith, pp. 277-281, June 2001.
[6]. Dimitris Nikolos, “High Speed Parallel Prefix ...Ling adders," IEEE
Transactions on Computers, vol.54, no.2, February 2005
[7]. R. Brentand Aregular layout for the parallel adders,” IEEE Trans. Computers, vol. C-31, no.3, pp. 0260-0264, March 1982.