2016 International Conference on Artificial Intelligence and Computer Science (AICS 2016) ISBN: 978-1-60595-411-0
A Chinese Website Analysis Approach Using Ontology
Segmentation and Topic Model
Da-wei LIU
1,*, Xue-mei LI
1, Hai-yang WANG
1,2and Wei LIU
1,21Institute of Network Technology, Institute of Computing Technology (YANTAI),
Chinese Academy of Sciences, Yantai 264005, China
2Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100090, China
*Corresponding author
Keywords: Website classification, Topic model, LDA, Section analysis, Ontology construction.
Abstract. A website analysis approach based on ontology segmentation and topic model is proposed to represent the website sections and retrieval similar websites. Definitions of concepts and taxonomy are introduced considering both structural and content characteristics. Features are extracted from websites leveraging linkage information and section tags. Topic model is used to perform information retrieval and get relevance scores between websites. The experimental results show that comparing with existing methods, the proposed approach can get more accurate results in website section analysis and searching for similar websites.
Introduction
With the rapid development of Internet applications, online network information has increased dramatically. Studying the diverse, heterogeneous and constantly changing information is a hot issue for researchers. In the field of information retrieval, traditional keywords-based indexing and database technology are replaced by automatic annotation based on knowledge graph. However, for website analysis, due to the complicated structure, hierarchical sections and massive multimedia content, it’s still a hard work to mine the value of data, especially for large-scale setting.
Websites are information sources containing mainly text data, the most important task is the semantic understanding. Topic model such as LDA [1][2] is the state-of-the-art mothed, which is a Bayesian generative model [7][8]. We can leverage massive Internet data to learn topics in an unsupervised setting, and these topics are easy to understand and contain latent semantic features. However most recent website classification algorithms using text mining technology [3], ignoring that structural features of websites are equally important. Websites are consisted of pages with links, there are relations between different websites and various sections in the same websites.
Ontology [4] has concept levels and logical supports, and is appropriate for defining structural features and representations. In this paper, we propose a website analysis approach based on ontology segmentation and topic model. Combining the two important aspects: content and structure, we define concept levels using website linkage relations. With the content of web tags, we generate feature representation for each website in the level of section. Then topic model is introduced and we design the topic learning method and evaluate the results. Our framework can perform the websites section classification and searching for semantic similar websites. Note that in our scenario, the language used in websites and all the text collected are Chinese.
Website Information Representation Based on Ontology Segmentation
Website Structural Segmentation
Sections are intuitive guide for browsers to read website content. We leverage web crawler to obtain pages of different levels in a website. Analyzing the source file of pages, segmentation is performed to each website using section divisions. In practical application, we find that the best number of level is no more than six. More levels can increase the time complexity. For example, we obtain the structure of Sohu.com to be: Sohu.com ->Sports->NBA->LA Lakes, Sohu.com->News->Society.
Definition of Conceptual Relationships
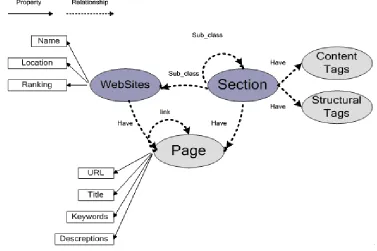
[image:2.612.119.496.208.459.2]To get the keywords vectors of websites, we define several website concepts based on ontology, including attributes and relationships, as shown in figure 1.
Figure 1. Definition of Concepts and Relationships of Website Structure.
Page is the basic concept, its upper concept are Section and Website. Section is sub-class of Website and Section also have subsections. According to the concept system, we obtain the content tags and structural tags. Content tags are keyword vectors generated from website structure segmentation. Information include title, keyword, description, URL, etc. And geographical position and ranking information such as Alexa can also be used to identify the website. Structural tags are relationship between links. Based on ontology, we define 5 types of relationship between Sections: Direct SubClass, InDirect SubClass, Mutual SubClass, Equivalent, Intersection, NonIntersection as follows:
1. Direct SubClass: refer to Website-Section or Section-SubSection, e.g. auto-popular car,
sohu.com-sports, sports-NBA.
2. InDirect SubClass: refer to Website-Section-SubSection or Section-SubSection-SubSection,
e.g. sports-NBA-LA Lakers.
3. Mutual SubClass: refer to two-way connection between two Sections, e.g. news-society and
society-news, news-health and health-news.
4. Equivalent: refer to Sections having the same SubSections or semantic meanings, e.g. parent
and child – infant and mom.
Note that Sections with the relationship of Equivalent may having no direct link between them, that is without relationship of Direct SubClass.
Website Feature Extraction
According to the ontology segmentation and concept relationships, for a given website we can obtain structural and content representation information. To further analyze the websites and sections, we
leverage the Vector Space Model. Each website Sm,wherem1,...,M ,M is the total number of
websites is represent by a high-dimensional feature vector Vi, each dimension corresponding to
concept relationship and the keyword tags. E.g. Vi(vd1,...,vdx, ,..., , ,...,vi1 v viy e1 vez),where vd1,...,vdxis content
tags sequences from direct subclass; vi1,...,viy is the content tags sequences from indirect subclass;
1,..., e ez
v v is the content tags sequences from mutual subclass, where x y z, , is the number of each type of
relationship. When generating the feature vectors, we choose the constant dimension for each feature. Note that we leverage the concept of ontology with the structural information to extract feature vectors of websites, which is different from traditional website analysis methods. Traditional methods only concern about the content in the websites and process the document mining. We take advantage of both content and structure information, which is the foundation of topic learning.
Website Semantic Analysis Based on Topic Model
Topic Model LDA
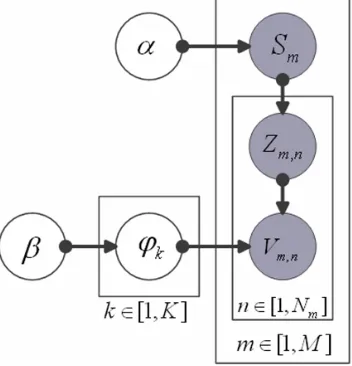
[image:3.612.226.402.412.595.2]Topic Model LDA is introduced by Blei et.al which is a three-level Bayesian model. LDA is widely used in text mining. LDA defines document, latent semantic and keywords. In this paper we leverage LDA model to perform analysis with our ontology segmentation. As is shown in figure 2, the framework of our method is a two-step process. [5]
Figure 2. Framework of analyzing websites based on Topic Model.
1. SmZm n. , in this step when generating the mwebsite, firstly a website-section latent
semantic distribution Smis chosen and the nlatent semantic number Zm n, according to Sm.
2. kVm n, kZm n, , in Klatent semantic and feature vector distribution, choose the generate
feature label Vm n, with the number kZm n, , that is the nfeature label with the mwebsite and
Website Semantic Analysis
With the latent semantic model generated by LDA learning, we take advantage of AP (Affinity Propagation) clustering algorithm [9] to cluster the websites and sections. Compared with other
clustering algorithms such as K-means, AP algorithm can perform without determining K in advance.
Meanwhile the time complexity of AP algorithm is O N( * * log )N N , which is higher than the O N( * )K of
K-means algorithm. Considering the amount of data in our scenario is several thousands, the higher time complexity of AP algorithm is acceptable.
Experiments
We design a semi-artificial experiment to evaluate our proposed method. We use the results of similarsitesearch [6] as benchmark, also some manual annotated ones. We combine the two results and compare to ours and list the evaluation process. As shown in table 1 and table 2.
Our dataset are taken from 19 popular website in China, such as www.sina.com.cn, www.sohu.com, www.163.com, and www.xinhuanet.com, www.people.com.cn, and their similar websites. The total number of different website are more than 300 with 60,000 sections. We filtered and choosed 7,000 and 30,000 linkage data. The dimension in this experiment is 1,000. The number of latent semantic topic is 10 and we take the first 100 feature labels as the input of subsequence process.
The feature labels in Table 1 is much better than in Table 2 in the concept of semantic similarity, which illustrate that our proposed method can perform better result of website analysis.
Table 1. Results of Ontology-based Topic Model.
Semantic Feature Label Weight Semantic Feature Label Weight
T1 Auto 0.01187
T2
Health 0.02797 Auto Library 0.00996 Keep Fit 0.00837 New Auto 0.00411 Illness 0.00619 Brands 0.00281 Medicine 0.00619
Mini Car 0.00281 Diet 0.00515
Sports Car 0.00277 Face-lift 0.00505 Luxury Car 0.00274 Help 0.00379 Second-hand
Car 0.00221 Doctor 0.00316
Pricing 0.00214 Foods 0.00278
Auto Pics 0.00214 Care 0.002
Table 2. Results of Model based on Word Frequency Statistics.
Semantic Feature Label Weight Semantic Feature Label Weight
T1 Sports 0.00734
T2
Special Issue 0.01369 Study Abroad 0.00556 Travel 0.01309
Media 0.00549 News 0.01019
Conclusions
In this paper, we focus the website analysis task and proposed a website structural representation method based on ontology segmentation. We also introduce a framework leveraging topic model. The contribution of this paper is that we consider both content and structural information, define the concept of relationship in links using ontology technology. Experiments showed that compared to traditional methods our proposed method can get results with better semantic meaning.
Acknowledgement
This research was financially supported by Technology Innovation Program of Shandong Provence of China (No. 2014XGA06014), Shandong Technology Research and Development Program (No. 2016GGX101020) and Yantai Technology Research and Development Program (No. 2014LGS005).
References
[1] Blei D.M., Ng A.Y., Jordan M.I. Latent Dirichlet Allocation. Journal of Machine Learning Research, 2003, 3(5): 993-1022.
[2] Wang Chan, Wang Xiao-jie, Yuan Cai-xia. A Topic Tracking Oriented Dirichlet Process Mixture Model. Journal of Beijing University of Posts and Telecommunications. 2012, 35(3), 91-94.
[3] Liu Zhen-lu, Wang Da-ling, FengShi, Zhang Yi-fei. An Approach of Latent Semantic Space Partition and Web Document Clustering. Journal of Chinese Information Processing. 2011, 25(1), 60-65.
[4] Grigoris Antonious, Frank van Harmelen. A semantic web primer. Cambridge: The MIT Press, 2004.
[5] G. Heinrich. Parameter estimation for text analysis. Technical Report, 2005. [6] SimilarSiteSearch: http://www.similarsitesearch.com/
[7] Zhao Ai-hua, Liu Pei-yu, Zheng Yan, Subtopic Division in News Topic Based on Latent Dirichlet Allocation [J]. Journal of Chinese Computer Systems. 2013, 34(4): 732-737.
[8] Li Bao-li, Yang Xing, Analyzing Research Topic Evolution with LDA and Topic Filtering. Journal of Chinese Computer Systems. 2012, 33(12): 2738-2743.