A Robust Multi-attribute Watermarking
Technique for Relational Data
Vrushali B. Patil, Prof. P. M. Yawalkar
PG Student, Dept. of Computer Engineering, MET’s Institute of Engineering, Adgaon, Nashik, India Dept. of Computer Engineering, MET’s Institute of Engineering, Adgaon, Nashik, India
ABSTRACT: The Relational Databases contain the valuable information of various organizations and institutes. In this era of Internet Based services and Information Technology the Copyright Protection or Proprietary Rights Protection of Relational Database is critical issue. The data is used in collaborative environments for information extraction; wherethere are chances of data loss due to some distortions made in data which is not only hazardous to data quality but also to the data owner concerning proprietary rights and data manipulation. Watermarking is used to protect the proprietary rights of shared Relational Data and also providing the solution for data manipulation. The proposed technique uses Feature Selection and Data Partitioning techniques for the selection of multiple attributes of the original database for watermark encoding. Use of partitioning and preprocessing minimizes the data distortion and information loss. The experimental results show the strength of system against various attacks (for decoding accuracy up to 70 percent for deletion attack up to 90 percent). The proposed technique gives, a Firm, Reversible, Multi-attribute watermarking technique for numerical values of the Relational Databases.
KEYWORDS: Watermarking, proprietary right protection, Data Recovery.
I. INTRODUCTION
Nowadays data is dreadfully generated through the use of internet. This data is then saved in various formats such as phonic, video, images and relational data. In particular, the Relational data is highly shared by the owners with research association. The infringement of digital assets like video, image, software and text has long been a burden for owners of these assets. These assets are usually protected by inserting a small error which is called as watermark. The need of relational database watermarking is the growing use of databases in various applications. In shopping mall and other organizations the data generated every day is provided to the data analysts and the other users. This is a blessing to end users, but because of this the data providers are exposed to the danger of data theft [12]. Data recovery and Ownership protection is ensured by Reversible watermarking techniques. A guilty agent is identified as the source of data leakage by the digital water-marking. Watermarking is used to provide the proprietorship protection over the digital data by inserting a unique watermark in the original content. In image watermarking, the messages were are send from sender to receiver by inserting a small change into the original image. Proprietorship rights of the relational data are protected by the use of information hiding and copyright protection techniques. The drawback of these techniques is that the data quality is degraded as for the data protection the data is distorted. It is highly required to maintain the data quality of the watermarked data to make it useful for the further use. The correctness of the data for various applications is nothing but the data quality [6].The data quality degradation issue is tackled by Reversible watermarking technique. In reversible watermarking technique, original data is recovered along with the embedded water-mark information and the data is kept useful for knowledge discovery. In this process the modifications in the data are made such that for the knowledge extraction process the data quality must be acceptable.
II. RELATED WORK
thewatermark from the features of the dataset which is too strong to attack. As the water-marking make some changes in the original data bits hence this technique overcomes this problem by reversible watermarking [12].
JACK T. BRASSIL proposed a marking technique for Electronic distribution of text documents. This technique is used for the Copyright Protection of Electronic data. The encoding techniques are used for the modification of the character [1]. Fabien A. P. Petitcolas presents the solution for the issue of watermark evaluation. Functionality and assurance are the two independent categories are made for the water-mark evaluation. Functionality represents a set of required series of tests. The basic functionalities discussed are Perceptibility, Reliability, Capacity, speed, Statistical Undetectable. Assurance represents a set of evaluated functionality levels ranging from zero to infinity [2]. The relational databases were watermarked so that to obtain the data and the encoded watermark bit by Agrawal and Kiernan. In this method, a watermark bit was inserted at a particular tuple of the particular attribute. For the watermark detection, the watermark or the original data was not required. If a small sample of database containing the watermark bit is available then also one was able to detect the watermark This technique is not useful for non-numeric attributes and in those cases where there were possibilities of data theft by multiple sources [3].A reversible watermarking algorithm based on the difference expansion of colored images were proposed in [4], [5]. These are the image watermarking technique which are used to recover the original image. To hide pairs of bits any three pixel values are chosen from the given component. Test results of the algorithm shows the amount of data to be embedded into the image is strongly related to the nature of image. In [6], Statistical-property watermarking algorithm is used. In this algorithm, watermark bits are embedded in original data tuples. The whole database is partitioned into large number of uncommon, non-overlapping partitions of tuples. The decoding accuracy is depend on the usability constraints defined by owner of the data. The data owner have to elaborate the usability constraints is the drawback of this approach.
In [7], an exact and lossless method to authenticate the relational databases is provided, especially suitable for sensitive data requiring no permanent distortions. The overhead information traces are kept data quality authentication. This technique is not firm for the heavy attacks. In [8], a watermarking technique is proposed for which the result of watermark embedding process gives distortion. It is a strong watermarking technique against various attacks. E. Sonnleitner, proposed a strong, blind and reversible watermarking technique for large scale databases. In a database, substitution of whitespace for information hiding gives a strong watermarking scheme. With this approach, the rate of watermark detection is decreased even after the data is strongly contaminated [9]. In [10], a Genetic Algorithm is used. This technique is firm against various attacks. The issue of false positive rate is solved with this approach.
The image watermarking scheme based on prediction error expansion is proposed by Xiaolong Li et al. To achieve more accuracy in image watermarking the authors have focused on adaptive embedding and pixel selection. As the system focuses more on highly correlated regions and pixels, better exploitation of spatial redundancy is achieved [14]. In [15], an information preserving watermarking scheme is proposed for the Electronic Medical Records which will help the personnel to keep their medical details. This technique is resilient against various attacks. In [16], the database tampering is detected by inserting vital characteristics of original database into it. If the databases is attacked then the approach is not able to recover the original data. M. E. Farfoura et al. have proposed a reversible watermarking databases. This technique uses prediction- error expansion for numerical values. It is a firm and reversible watermarking technique which ensures the data quality after being attacked by various attacks [13]. In [17] author have proposed a reversible watermarking scheme based on the time stamping protocol for relational databases. This is a most resilient technique against various attacks. Random bit pattern technique is used in [11], for relational database watermarking. Theyproposed a watermarking method for numericdata. It is firm against various attacks andefficient watermarking scheme for relationaldatabases. This is best approach for data setscontaining unsigned numeric values. A strongand reversible watermarking technique for numerical values of relational databases is givenin [12]. The importance of this work is, even ifa huge part of data is attacked this approach isable to recover the data. This technique is ableto detect the watermark with highest decodingaccuracy.
III.PROBLEM STATEMENT
generated using the date-time which is more robust and the watermarking technique is reversible. So original data is recovered by removing the watermarked bits and data loss is minimized by partitioning.
IV.PROPOSED SYSTEM
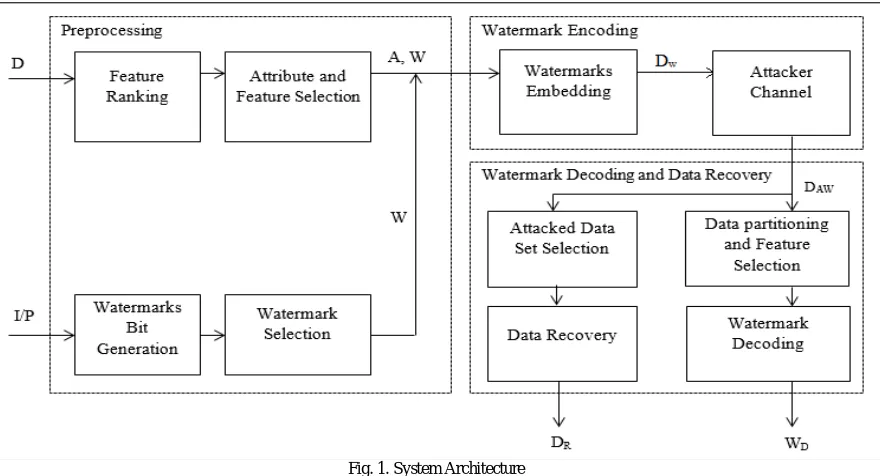
The system architecture is presented in Figure. It includes the three major phases: (1) watermark preprocessing; (2) watermark encoding; (3) watermark decoding and data recovery. Various parameters which are used for watermark encoding and decoding are calculated in watermark preprocessing phase. In watermark encoding phase, the watermark bits are encoded such that the data quality remains unaffected. The tolerable contamination into data that is usability constraints must be given by the data owner. Based on the mutual information, suitable feature is selected for watermark encoding. After the watermark encoding phase data is sent through the communication network where it is supposed to attacked, this network is called as attacker channel. In watermark decoding phase, embedded watermark detected and in recovery phase, the original data is successfully recovered.
Fig. 1. System Architecture
4.1 Data Pre-processing Phase
In this phase, the features are ranked according to their mutual information dependency. Those features having value less than the secret threshold are selected for watermarking. The watermark string is generated with the use of genetic Algorithm. Optimal watermark is selected from the various watermarks generated through the different operations of genetic algorithm. The selected features and the watermark generated is send to the watermark encoding phase.
4.2 Partitioning Phase 4.2.1 Data Partitioning
In data partitioning phase data is logically partitioned into some clusters which are not having any common tuple. The partitioning algorithm can be given as:
Step 1: Start
Step 6: Stop
The symbols used in the paper and their description is given in the table 1.
4.2 Partitioning Phase 4.2.1 Data Partitioning
In data partitioning phase data is logically partitioned into some clusters which are not having any common tuple. The partitioning algorithm can be given as:
Step 1: Start
Step 2: Read the values of D, m, Ks; P K Step 3: Repeat for all r from 1 to R in D Step 4: par(r) = H(Ks || (r:P K || Ks)) mod m Step 5: Return S0. …, Sm-1
Step 6: Stop
4.2.2 Threshold Computation
Based on threshold value the tuples to be watermarked are selected. Those tuples having value greater than the threshold are selected for watermark encoding. The algorithm forcomputing tuples having values greater than the threshold can be given as:
Step 1: Start
Step 2: Read the values of S0…,Sm-1, c
Step 3: Repeat for all i from 1 to m-1do for each attribute A from Si do
Step 4: Compute and on A Step 5: Calculate T, T = c + µ * σ Step 6: Return D’T← (∀R >T )
where, T is threshold, c is the confidence factor with value ranging between 0 to 1, µ is mean and σ is standard deviation. The tuples having value greater than the threshold only selected for the even hash calculation step let’s say the tuples as D’T
4.2.3 Hash value Computation
The even hash value for each of the cluster iscalculated to make the watermarking schememore precise. This partitioning results in fewtuples to be selected for watermark encodingwhich keeps the data more usable than allprevious watermarking schemes for relationaldata.
Step 1: Start
Step 2: Read the values of D’T ; Ks
Step 3: Repeat for all r from 1 to R in Step 4: D’T do
Even-hashV(r) = H(Ks || r.P K)mod2 Step 5: if even-hashV(r) == 0 then Step 6: insert r into D’’T
else
don’t consider the tuple for watermarking Step 7: Return D’’T
Step 8: Stop
4.3 Watermark Encoding Phase
The watermark encoding process uses the watermark bit generated from data and time. The algorithm used for watermark encoding is as given below:
Step 1: Start
Step 2: Read the values of D’’,T, Ks; w Step 3: for all r from 1 to R in D’’T do
Step 4: if b == 1 then
Step 5: compute δij, (δij = ρ %ofvij)
insertδij into change matrix Dwij = Dwij + δij
Step 6: else
Step 7: compute δij , (δij = ρ %ofvij)
insertδij into change matrix Dwij = Dwij - δij
Step 8: compute τ Step 9: Return Dw
Step 10: Stop
4.4 Watermark Decoding Phase
In watermark decoding phase all the preprocessing phases done for encoding are performed on the watermarked data. The watermarked data is partitioned into m partitions. Then the threshold is calculated and values greater thanthreshold are selected for decoding (D’wr ). The even hash value for the dataset (D’wr )calculated is (D’’ wr ) The algorithm used forwatermark decoding is as given below:
Step 1: Start
Step 2: Read the values of (D’’wr ), Ks; w Step 3: for all r from 1 to R in D’’wr do Step 4: γ = val - τ
Step 5: if γ > 0 then ones[i] = ones[i] + 1; Step 6: else
Step 7: if ones[i] > zeros[i] then b[j] = 1;
Step 8: else b[j] = 0 Step 9: Return WD
Step 10: Stop
4.5 Data Recovery Phase
The data recovery phase enables the data owner to obtain the original data from the attacked watermarked data. The algorithm for data recovery is given as:
Step 1: Start
Step 2: Read the values of (D’’wr ), b Step 3: Repeat for all r from 1 to R do Step 4: if b[j] == 1 then
// 0 or 1 watermark bit is detected from every tuple r data is recovered by Dwij = Dwij - δij
Step 5: else
data is recovered by Dwij = Dwij + δij Step 5: Return Dr Step 6: Stop
4.6 IMPLEMENTATION DETAILS 4.6.1 Mathematical Details
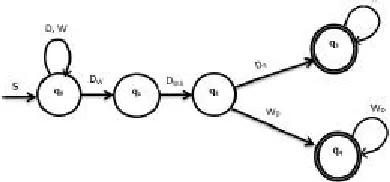
Deterministic Finite Automata(DFA): A deterministicfinite automaton M is a 5-tuple, M = ({q0, q1, q2, q3, q4},{W,D},δ,q0,{q3,q4}).
for given system is shown in Fig.2.
Fig. 2. Deterministic Finite Automata
Where,
1) q0 : Watermark Encoding. 2) q1 : Attacker channel. 3) q2 : Watermark Decoding. 4) q3 : Data Recovery. 5) q4 : Watermark Detection. 6) DW : Watermarked data.
7) DWA : Attacked Watermarked data.
8) DR: Data recovered from attack.
9) WD : Detected Watermark.
4.6.2 Results and Discussion
V. SIMULATION RESULTS
Result Analysis for MI
The Mutual Information between the two attributes before watermark and after watermark is plotted in the form of graph. The graph shows that the co-relation between two attributes before watermark and after watermark is not drastically changed, which means that there is minimum data loss after watermark encoding.
Fig. 3. Result Analysis for MI
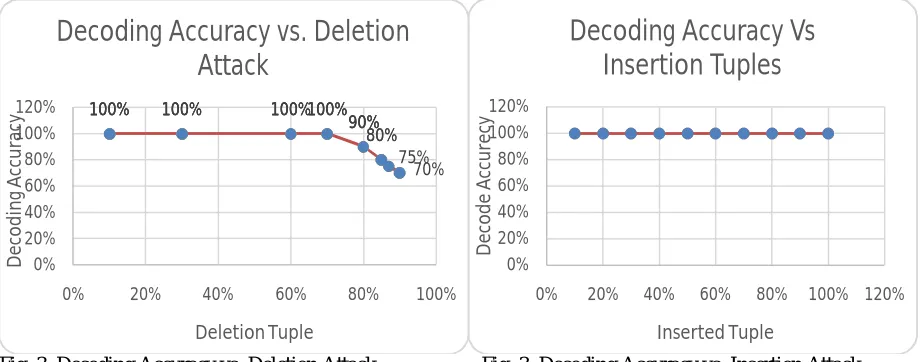
The results of watermark decoding accuracy for deletion attack and insertion attack are given graphically as follows:
Fig. 3. Decoding Accuracy vs. Deletion Attack Fig. 3. Decoding Accuracy vs. Insertion Attack
VI.CONCLUSION AND FUTURE WORK
The proposed technique is a novel, strong and reversible technique for watermarking numerical data of relational databases that will allow recovery of a large portion of the data even after being subjected to malicious attacks. This technique is able to recover both the embedded watermark and the original data. The experimental results against various types of attacks like deletion attack, insertion attack are tested. For deletion attack the decoding accuracy is 90 percent for 80 percent tuple deletion. Similarly for insertion attack 100 percent decoding accuracy is achieved. The system experientially proved better against existing system for the data loss issue. The difference between the MI values before watermarking and after watermarking is negligible. Hence we are succeeded to keep data more usable
100% 100% 100%100%
90% 80%
75% 70%
100% 100% 100%100%
90% 80%
100% 100% 100%100%
90% 0% 20% 40% 60% 80% 100% 120%
0% 20% 40% 60% 80% 100%
D ec o d in g A cc u ra cy Deletion Tuple
Decoding Accuracy vs. Deletion
Attack
0% 20% 40% 60% 80% 100% 120%0% 20% 40% 60% 80% 100% 120%
D ec o d e A cc u re cy Inserted Tuple
Decoding Accuracy Vs
after watermarking. The use of data partitioning results in less distortion of data as the number of tuples selected for watermarking is minimized by pre-processing technique.
VII. ACKNOWLEDGEMENT
The authors are grateful to METs Institute ofEngineering Bhujbal Knowledge City Nashik,HOD of computer department, parents andfriends for their blessing, support and encouragementbehind this work
REFERENCES
1. SamanIftikhar, M. Kamran, and Zahid Anwar, ”RRW-A Robust and Reversible Watermarking Technique for Relational Data”, In IEEE Trans. on knowledge and Data Engineering, VOL. 27, NO. 4 , APRIL 2015.
2. J. T. Brassil, S. Low, and N. F. Maxemchuk, ”Copyright protection for the electronic distribution of text documents”, In Proc. IEEE, vol. 87, no. 7, pp. 11811196, Jul. 1999.
3. F. A. Petitcolas, Watermarking schemes evaluation”, IEEE Signal Process. Mag., vol. 17, no. 5, pp. 5864 , Sep. 2000.
4. R. Agrawal and J. Kiernan, Watermarking relational databases”, In Proc. 28th Int. Conf. Very Large Data Bases, pp. 155166, 2002. 5. A. M. Alattar, Reversible watermark using difference expansion of triplets”, In Proc. IEEE Int. Conf. Image Process.,
pp. I501, vol. 1, 2003.
6. D. M. Thodi and J. J. Rodriguez, Prediction-error based reversible watermarking”, in Proc. IEEE Int. Conf. Image Process. vol. 3, pp. 15491552, 2004.
7. D. M. Thodi and J. J. Rodriguez, Reversible watermarking by prediction-error expansion, In Proc. 6th IEEESouthwest Symp. Image Anal. Interpretation, pp. 2125, 2004.
8. R. Sion, M. Atallah, and S. Prabhakar, ”Rights protection for categorical data”, In IEEE Trans. Knowl. Data Eng., vol. 17, no. 7, pp. 912 926, Jul. 2005.
9. S. Subramanya and B. K. Yi, Digital rights management, In IEEE Potentials, vol. 25, no. 2, pp. 3134, Mar.-Apr. 2006. 10. Y. Zhang, B. Yang, and X.-M. Niu, ”Reversible watermarking for relational database authentication”, J. Comput., vol.
17, no. 2, pp. 5966, 2006.
11. D. M. Thodi and J. J. Rodriguez, Expansion embedding techniques for reversible watermarking, In IEEE Trans. Image Process., vol. 16, no. 3, pp. 721730, Feb. 2007.
12. G. Gupta and J. Pieprzyk, ”Reversible and blind database watermarking using difference expansion”, In Proc. 1st Int. Conf. Forensic Appl. Tech. Telecommun., Inf., Multimedia Workshop, p. 24, 2008.
13. M. E. Farfoura and S.-J. Horng, A novel blind reversible method for watermarking relational databases, In Proc. IEEE Int. Symp. Parallel Distrib. Process. Appl., pp. 563569, 2010.
14. X. Li, B. Yang, and T. Zeng, Efficient reversible watermarking based on adaptive prediction-error expansion and pixel selection, In IEEE Trans. Image Process., vol. 20, no. 12, pp. 3524 3533, Dec. 2011.
15. M. Kamran and M. Farooq, An information-preserving watermarking scheme for right protection of EMR systems, In IEEE Trans. Knowl. Data Eng., vol. 24, no. 11, pp. 19501962, Nov. 2012.
16. J.-N. Chang and H.-C.Wu, Reversible fragile database watermarking technology using difference expansion based on SVR prediction, in In Proc. IEEE Int. Symp. Comput.,Consum. Control, pp. 690693., 2012.
17. M. E. Farfoura, S.-J. Horng, J.-L. Lai, R.-S. Run, R.-J. Chen, and M. K. Khan, A blind reversible method for watermarking relational databases based on a time-stamping protocol, Expert Syst. Appl., vol. 39, no. 3, pp. 31853196, 2012.
18. E. Sonnleitner, ”A robust watermarking approach for large databases”, In Proc. IEEE First AESS Eur. Conf. Satellite Telecommun., pp. 16, 2012.
19. K. Jawad and A. Khan, ”Genetic algorithm and difference expansion based reversible watermarking for relational databases”, J. Syst. Softw., vol. 86, no. 11, pp. 27422753, 2013.