The candidate confirms that the work submitted is their own and the appropriate credit has been given where reference has been made to the work of others.
I understand that failure to attribute material which is obtained from another source may be considered as plagiarism.
(Signature of student)______________________________
Data Provenance for e-Social
Science Cloud Applications
Data Provenance for e-Social
Science Cloud Applications
Che Wan Amiruddin Chek Wan Samsudin
MSc Computing and Management
Session (
2010/2011)
ii
ABSTRACT
__________________________________________________________________________________ e-Social Science applications use Grid Computing technology to collect, process, integrate, share, and present social and behavioural data. The option to use cloud computing technology for both computation and data storage has now arisen due to its on-demand strategies where customers only pay for their what-they-use service. However, data stored on cloud can be heterogeneous and can pose some problems in identifying the source of the data and information on who stored the data. The integrity of the data used is crucial for the use by e-Social Scientists when conducting experiments. These issues can be solved by using data provenance when deriving data from the cloud environment. The aim of this study was to derive common data provenance requirements needed by the e-Social Scientists, to facilitate the uptake of cloud computing technology for the e-Social Sciences which would help social scientists to use an authenticate data from the cloud environment. The method used to derive the e-Social Science provenance requirements was by interviewing e-Social Scientists themselves, followed by surveys on current provenance schemes. Experimental evaluations of cloud provenance were conducted using a real test bed to fulfil those requirements. Comparison of the current provenance schemes and the simple provenance schemes drawn were then conducted. Three main requirements were derived from the results of interviewing the e-Social Scientists which were: 1) The ability to replicate the results based on the input data; 2) The ability to evaluate the processes based on the metadata; and 3) The ability to secure the sensitive data obtained from being accessed by unauthorised users. The survey on the current provenance schemes showed that schemes such as Chimera and PASS could support both the provenance requirements needed by e-Social Scientists. The proposed scheme created also supported the result replication. The experimental evaluation on performance with regard to the time taken to record the process details, the time taken to record the result generated, and the time taken to retrieve results showed that the current provenance schemes can be applied on cloud environment. A design of a simple provenance scheme for e-Social Science cloud application was drawn as a proof of concept to show that recording provenance on cloud environment was possible. Findings showed that two out of four provenance schemes discussed as well as the cloud provenance schemes created met the e-Social Science requirements. The concept drawn showed that recording and querying data provenance on cloud applications is possible. Further studies to work on provenance data security should be performed to prevent unauthorised access of data.
iii
ACKNOWLEDGEMENT
__________________________________________________________________________________ First and foremost, I would like to thank my project supervisor, Dr Paul Townend for suggesting me this topic as my Master’s thesis project, and for his invaluable advice, guidance, support, and time throughout the preparation of my MSc project. Without his support and guidance, I would not be able to complete my project on time.
I would like to thank Andy Turner from the School of Geography, and Dr. Colin Venters for spending his busy time to hold an interview session with me so that I was able to derive the provenance requirements needed by e-Social Scientists.
Great appreciation to thank Peter Garraghan for allowing me to use the iVIC system for me to conduct the experiment. Without his generous help, it will cost me a fortune having to use an enterprise cloud provider such as Amazon.
To my MSc Computing and Management colleagues as well as other Malaysian friends and families in Leeds, thank you for the support, motivation and friendship throughout my student life in Leeds. Thank you to my twin brother and my little sister for their encouragement and support throughout the year. They insist that I work hard at keeping well so that I could submit this work on time.
And most importantly, my utmost gratitude to my parents for their prayers, moral and financial support, invaluable encouragement, advice and guidance given at all times. Many thanks Mom and Dad, I could not have done it without you.
Che Wan Amiruddin Chek Wan Samsudin MSc Computing and Management (2010/2011) University of Leeds
iv
Table of Contents
ABSTRACT ... ii
ACKNOWLEDGEMENT ... iii
LIST OF ABBREVIATIONS ... vii
LIST OF FIGURES ... viii
LIST OF TABLES ... ix
CHAPTER I... 1
1. Introduction ... 1
1.1 Project Outline ... 1
1.1.1 Overall aim and objective of the project ... 1
1.1.2 Minimum requirement and further enhancement ... 1
1.1.3 List of deliverables ... 1
1.1.4 Resource required. ... 2
1.1.5 Project schedule and progress report ... 2
1.1.6 Research methods. ... 2 1.2 Chapter overviews ... 3 CHAPTER II ... 4 2. Background Reading ... 4 2.1 e-Science ... 4 2.2 e-Social Science ... 5
2.2.1 e-Social Science Research ... 6
2.3 Cloud Computing ... 8
2.3.1 Deploying Models ... 10
2.4 Provenance ... 11
CHAPTER III ... 15
3. Analysis & Survey ... 15
3.1 Requirement Analysis ... 15
3.1.1 Provenance requirement ... 15
3.1.2 Provenance requirement for cloud ... 16
3.1.3 Provenance requirement by the e-Social Scientist ... 16
3.2 Current Provenance Schemes Survey ... 18
3.2.1 Chimera ... 19
v
3.2.3 Provenance Aware Service-oriented Architecture (PASOA) ... 22
3.2.4 Provenance-Aware Storage System (PASS) ... 24
3.3 Discussion of the current provenance schemes ... 25
3.3.1 Storage Repository ... 27 3.3.2 Representation Scheme ... 27 3.3.3 Result Replication ... 27 3.3.4 Provenance Distribution ... 27 3.3.5 Evaluate metadata ... 27 CHAPTER IV ... 29
4. Design and Implementation ... 29
4.1 Proposed Design ... 29
4.1.1 System Design Scenario ... 29
4.1.2 System Architecture ... 30
4.1.3 Database Design ... 32
4.2. Implementation ... 33
4.2.1 Creating the database ... 33
4.2.2 Accessing the virtual machine ... 34
4.2.3 Computational software ... 35
CHAPTER V ... 37
5. Evaluation ... 37
5.1 Performance evaluation... 37
5.1.1 Recording the result ... 37
5.1.2 Querying the result ... 39
5.1.3 Discussion ... 41
5.2 Do the current provenance schemes meet the e-Social Science requirements? ... 41
5.3 Current provenance schemes and cloud ... 42
5.4 Summary ... 43
CHAPTER VI ... 45
6. Conclusion ... 45
6.1 Overall project evaluation... 45
6.2 Problems encountered ... 46
6.3 Future Work ... 46
REFERENCES ... 48
vi
Appendix B – Contribution on project ... 54
Appendix C - Interim Report ... 55
Appendix D – Gantt chart ... 56
Appendix E – Interview session with Andy Turner ... 57
Appendix F – Database Tables Created ... 61
vii
LIST OF ABBREVIATIONS
AVHRR Advance Very-High Resolution Radiometer
CMS Compact Muon Solenoid
DAMES Data Management through e-Social Science DReSS Digital Record for e-Social Science
DAG Directed Acyclic Graph DTD Document Type Definitions ESSW Earth System Science Workbench ESRC Economic and Social Research Council ERM Entity Relationship Diagram
GENeSIS Generative e-Social Science
GeoVUE Geographic Virtual Urban Environments HaaS Hardware as a Service
PC Personal Computer
PHP Hypertext Preprocessor IaaS Infrastructure as a Service iVIC infrastructure Virtual Computing KBDB in-Kernel Berkeley DB Database
IP Internet Protocol
MeRC Manchester eResearch Centre
MoSeS Modelling and Simulation for e-Social Science NCeSS National Centre for e-Social Science
NeSC National e-Science Centre NHS National Health Service
NIST National Institute of Standards and Technology NOAA National Oceanic and Atmospheric Administration NGN Next Generation Network
ND-WORM No-Duplicate Write Once Read Many
OS Operating System
PaaS Platform as a Service
PASOA Provenance Aware Service-Oriented Architecture PReP Provenance Recording Protocol
PASS Provenance-Aware Storage System PReServ Provenance Recording for Service
viii SDSS Sloan Digital Sky Survey
SaaS Software as a Service
OPM The Open Provenance Model VDC Virtual Data Catalogue VDL Virtual Data Language VFS Virtual File System
VM Virtual Machine
WBBIs Web-based behavioural interventions
LIST OF FIGURES
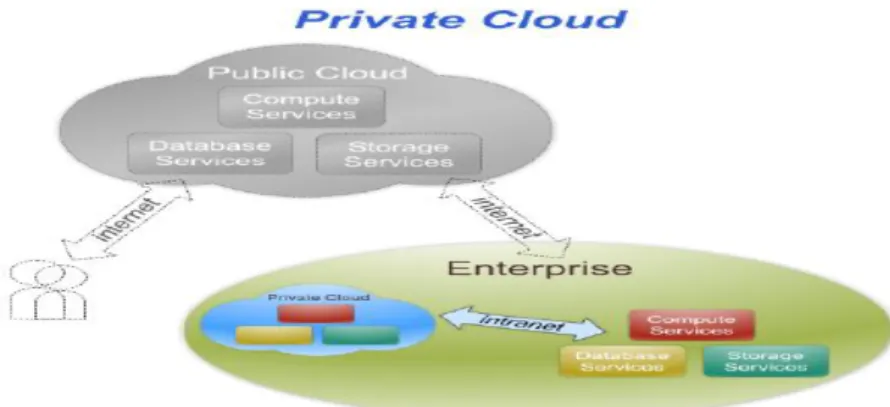
Figure 1 Illustration of a public cloud. Users accessing data and application without knowing how the underlying architecture works
Figure 2 Illustration of a private cloud. Useful for large enterprise to handle a maximum workload Figure 3 Illustration of a hybrid cloud. Combination of public and private cloud together
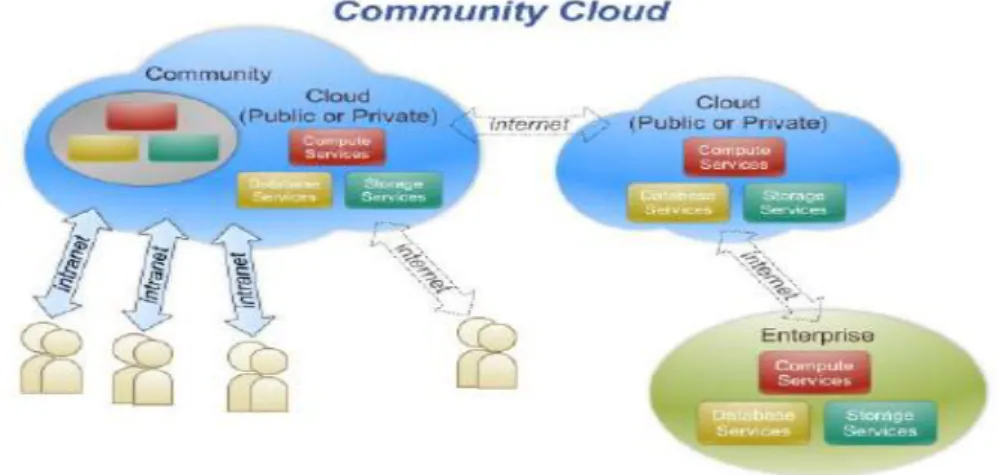
Figure 4 Illustration of a community cloud. Shared infrastructure among enterprise with a common purpose
Figure 5 Example of provenance graph Figure 6 Schematic of Chimera Architecture Figure 7 ESSW conceptual diagram
Figure 8 Lab Notebook and Laware (ND-WORM) architecture Figure 9 An illustration of how a service acts as another client Figure 10 PReServ layers
Figure 11 PASS system architecture
Figure 12 Edges in the OPM (sources are effects, and destinations are causes). Figure 13 Overview of the proposed design on how the system will work Figure 14 An architecture diagram of the proposed system design Figure 15 ERM diagram for the provenance database
Figure 16 The structure for client table.
Figure 17 All the databases created in the provenance database
Figure 18 Using the VNC viewer to connect to the virtual machine. ‘:0’ assign to the virtual machine to access
ix Figure 19 The virtual machine that is ready to be used
Figure 20 The class diagram of the system created. All the class will connect to the database when performing an operation
Figure 21 Time taken to record result with and without the provenance data, based on the number of iterations generated from a single call operation.
Figure 22 Time taken to record result with and without the provenance data based on the number of iterations generated using two different calls.
Figure 23 Time taken to get the result with and without the provenance data Figure 24 Initial schedule for completing the project
Figure 25 Revised schedule for completing the project Figure 26 The structure for client table
Figure 27 The structure for virtual machine table Figure 28 The structure for process table
Figure 29 The structure for result table
Figure 30 The structure for recording the time taken to store table
LIST OF TABLES
Table 1 Comparison between Chimera, ESSW, PASOA and PASS Table 2 The entity table schemes for the provenance database Table 3 Workload classification in a web database system
Table 4 Comparison of the system created together with the provenance schemes discussed in Chapter Four
Table 5 Description of the system used by each schemes
Table 6 Result of the time taken to record the results together with the provenance data in a single operation call
Table 7 Result of the time taken to record the results only in a different operation call Table 8 Time taken to query results with provenance data
1
CHAPTER I
__________________________________________________________________________________
1.
Introduction
1.1 Project Outline
1.1.1 Overall aim and objective of the project
The aim of this project is to derive common data provenance requirements for e-Social Science applications and research, and extend existing provenance frameworks to facilitate the uptake of cloud computing technology for the e-Social Sciences. This project should be able to help social scientists to use an authenticate data from the cloud environment by using provenance to get the information.
The project will address several objectives, which are: Understand current e-Social Science projects.
Investigate cloud computing functionality and data provenance.
Survey existing provenance schemes and extend them to the cloud paradigm, with an emphasis on meeting the e-Social Science requirements.
Identify the emergent functionality of provenance and cloud.
Develop initial schema for e-Social Science data provenance in cloud computing. Conduct experiments according to a chosen framework.
Evaluate the experiment conducted. Evaluate the whole project process.
1.1.2 Minimum requirement and further enhancement
Minimum requirements of the project:
Perform requirements analysis for provenance in e-Social Science projects. Develop initial scheme for e-Social Science data provenance in cloud computing.
1.1.3 List of deliverables
A cloud-based data provenance schema for e-Social Science. An analysis of emergent functionality in provenance and cloud.
2
Experimental analysis of feasibility of using provenance in cloud for e-Social Science applications.
1.1.4 Resource required.
The resource needed is a cloud service to host sample data to be used by the experiment.
1.1.5 Project schedule and progress report
The schedules for both the initial and the revised plan can be found in Appendix D. The standard waterfall methodology will be used as the method that will cover:
Background reading and literature review on each research area.
Collection of qualitative analysis from e-Social Scientists to derive provenance requirements for future e-Social Science projects.
Development process.
Evaluation of the development.
Progress report: From the beginning of conducting the project until the submission of the interim report, everything went as planned as shown in the initial schedule plan. Deviations from plan started from the beginning of ‘July 2’ phase.
Tasks undertaken:
Further survey of existing provenance schemes extended to ‘July 3 and 4’ phase while the process of implementing the system continued.
A simple cloud-base data provenance schemes as a proof of concept conducted.
1.1.6 Research methods.
Thorough of literature research and analysis with regard to cloud computing, provenance and e-Social Science.
Interview with e-social scientists to derive the provenance requirements for e-Social Science projects.
Survey on existing provenance schemes and extend these to the cloud paradigm, with emphasis on meeting the e-Social Science requirements.
3
1.2
Chapter overviews
Chapter On - introduction to the project describing the aims and objectives.
Chapter Two - background reading and research into e-Social Science, cloud computing, and data.
Chapter Three - analysis of the provenance requirement from both cloud and e-Social Science perspective and survey of the current provenance schemes.
Chapter Four - design and implementation of a simple cloud provenance schemes.
Chapter Five - evaluation based on the system created and difference with the previous provenance schemes.
4
CHAPTER II
__________________________________________________________________________________
2. Background Reading
Section 2.1 explains a general description about Science. Section 2.2 discusses how e-Science technology is used in e-Social e-Science together with some examples of current projects. Section 2.3 and 2.4 describe what Cloud computing and Provenance are.
2.1 e-Science
The National e-Science Centre (NeSC) defines e-Science as the large scale science that will increasingly be carried out through distributed global collaborations enabled by the internet (Taylor). The fundamental idea behind e-Science is to enable scientists to conduct new discoveries and obtain advancement in areas ranging from dentistry to medicine (eScience-Grid). It is also a tool that enables scientists to network their data to other researchers, and deals with data storage, interpretation, and. The United Kingdom (UK) government has also defined e-Science as:
“science increasingly done through distributed global collaborations enabled by the internet, using very large data collections, tera-scale computing resources and high performance visualisation”
(Illsley, 2011)
e-Science programme was developed to invent and apply computer-enabled methods to ‘facilitate distributed global collaborations over the internet, and sharing a very large data, collections, terascale computing resources and high performance visualisations’ (EPSRC, 2009). The government has funded more than £250 million to run the UK e-Science programme. Funds were divided between the e-Science core programme, where the focus on the development of the generic technologies to integrate different resources across computer network was done, and individual research council of e-Science programme specific to its discipline support. Technically, the initial emphasis of the programme was to focus on exploiting the Grid (the hardware, software, and necessary standard) to co-ordinate geographically distributed and possibly heterogeneous computing and data resources and deliver over the internet for researchers to use (Halfpenny and Procter, 2010). The purpose was to demonstrate the potential of Grid technologies in advancing the social science and encourage other researchers to adopt the emerging technologies.
Grid has been described as a hardware and software infrastructure that provides dependable, consistent, pervasive, and inexpensive access to high-end computational capabilities (Foster, 2002);
5
as well as an enabler for Virtual Organisation (Foster et al., 2001). In e-Science, the aim of grid computing is to construct a ‘cyber infrastructure’ or ‘e-infrastructure’ for the use of research collaboration (Scot and Venters, 2006). It has emerged as a major paradigm shift for sharing resources such as processing power, data storage, scientific instrument etc. (Turner et al., 2009). The grid has a number of distinct components (Procter):
Access grids: Provide advanced video conferencing and collaboration tools, an important element in Virtual Research Environment.
Computational grids: Provide scalable high performance computing.
Data grids: Provide access to datasets that makes their discovery, linkage and integration more transparent.
Sensor grids: Provide an opportunity to gather data in new ways.
Turner (2009) stated that the use of grid computing has gradually moved towards other sciences and research areas. The application now currently covers the area of business, economic medicine as well as performing arts.
2.2 e-Social Science
e-Social Science is a term which encompasses technological developments and approaches within social science that work with Social Scientists and Computer Scientists on tools and research which Social Scientists can take and use to help their research (NCeSS, 2009). e-Social Science is a valuable tool to help the Social Science researchers in conducting new researches, or to conduct a new research more quickly. Within NCeSS, the term ‘e’ in e-Social Science also refers to ‘enabling’. Another definition of e-Social Science is “a programme to use networked information to collect, process, and present social science research data. Like science, the essence of social science it to process (human) information. Unlike sciences that have immediately benefited from the latest information technologies, most of social science research has remained labour intensive in data collection and processing” (Xiaoming Li, 2006).
The e-Social Science programme was run by the UK National Centre for e-Social Science (NCeSS) activities and was funded by the Economic and Social Research Council (ESRC). The programme was created to “facilitate bigger, faster and more collaborative science, driven by a vision of researchers worldwide addressing key challenges in new ways “(Halfpenny and Procter, 2010). The programme encompasses two strands that concern the application of grids technologies within social science and the design, uptake, and use of e-Science (i.e. the design of the grid infrastructure) (Woolgar,
6
2004). It was developed in conjunction with wider developments in e-Science programme as mentioned earlier. NCeSS is exploring the use of grids in e-Science by exploring its potential to be used in social science research.
The e-Social Science research uses the adoption of grid technologies and tools that have been applied in natural science to advance social science (Scot and Venters, 2006). Distribution data in social science is now common. Some of the issues are data curation, data management, distributed access, platform and location independence, confidentiality, and access control (Turner et al., 2009).
2.2.1 e-Social Science Research
NCeSS projects were carried out in a 3-year projects or ‘nodes’ located across different universities in the UK. The projects ran on two phases. The first phase which ran between 2004 to 2007 had seven nodes and the second phase that ran between 2008 to 2012 had eight nodes, three of which were the extensions of the first nodes, one was the combination of the two first phase nodes and the remaining four were new (Halfpenny and Procter, 2010).
A ‘hub’ team based at the University of Manchester coordinated all the e-Social Science projects under the directorship of Professor Rob Procter. He has re-vitalised the e-Social Science research programme with the launch of MeRC (Manchester eResearch Centre).
The team was responsible for designing and managing the research programme, dissemination strategies, played a key role on the commissioning panels, creating and exploiting synergies across the components of the programmes, and strategically planning any future developments (MeRC). There are two strands in the NCeSS research programme which are the ‘applications strand’ and the ‘social shaping strand’ (Halfpenny and Procter, 2010). The applications strand focused on unfolding developments in technologies, tools and services from the e-Science programme and applies them to the social science research community needs. Improving the existing method or developing a new method that enables advances in the fields that would not otherwise be possible is the objective of this strand. The second NCeSS research programme strand (the social shaping strand) falls within the social studies of science and technology tradition. The aim of this strand is to understand the social, economic and other influences on how e-Science technologies are being developed and used, and the technologies implications for scientific practice and research outcomes. The use of e-Social Science strand is to understand the origin of the technological innovations and the difficulties, and the facilitators to their uptake within the scientific research communities and use the knowledge to extend the reach of e-Science (Halfpenny and Procter, 2010).
7 Below are some of the Nodes programmes:
DAMES (Data Management through e-Social Science) is the second-phase node of the NCeSS research from the University of Stirling / University of Glasgow (2008-2011). The data management refers to operations on data performed by social science researchers and the tasks associated with preparing and enhancing data for the benefits of analysis (i.e. matching data files together, cleaning data, and operationalising variables) (Lambert et al., 2008). There are four social science theme objectives from DAMES: 1) Grid Enabled Specialist Data Environment (Occupations, education, ethnicity) 2) Micro-simulation on social care data 3) Linking e-Health and Social Science database, and 4) Training and interfaces for data management support.
DReSS (Digital Record for e-Social Science) is a node from the Nottingham University (2004-2011). It is sought to develop Grid-based technologies for social science research through three driver projects that have common methodological themes (recording data, replaying data, representing and re-representing data) (Rodden et al., 2008). Driver Project One explored the themes through the use of digital records in ethnographic research to investigate the social character of technology used. Driver Project Two used digital records in corpus linguistics to investigate the multi-modal character of spoken language. Driver Project Three employed digital record alongside psychological approaches to investigate the efficacy of e-learning. GENeSIS (Generative e-Social Science) is a second phase node from a combination of two first
phase nodes, called MoSeS (Modelling and Simulation for e-Social Science)(Leeds University, 2004-2007) and GeoVUE (Geographic Virtual Urban Environments)(University College London, 2004-2007). MoSeS aims to use e-Science technique to develop a national demographic model and simulation of the UK population (Birkin et al., 2006, Townend et al., 2008). GeoVUE focuses on generating environments using network-based technologies (i.e. the grid and web-based services) to enable users to map and visually explore spatially coded socio-economic data (Batty, 2006, Steed, 2006). GENeSIS project seeks to develop models of social systems where the main applications are to build environments and cities using new techniques of simulation involving complexity theory, agent-based models and micro-simulation (Birkin and Townend, 2009).
LifeGuide is a project from Southampton University (2008-2011). It is a social science research environment designed by both computer scientists and behavioural psychologists for accelerating Web-based behavioural interventions (WBBIs) research (Yang et al., 2009).
8
2.3 Cloud Computing
Grid computing requires the use of a software that can divide and farm out pieces of a program as one large system image to several thousand computers (Myerson, 2009). It is better suited for organisation with large amounts of data being requested by a small number of users or few but larger allocation requests (Schiff, 2010). In grid computing, if one of the software in node fails, other pieces of the software on other nodes may also fail. Users will not have access to the hardware and servers to upgrade, install, and virtualise servers and applications. Providing a standard set of services and software that will enable sharing of storage resources and geographically distributed computing is one of the aims of having grid computing. This includes security framework for managing data access and movement, utilisation of remote computing resources and many more (Rings et al., 2009).
With cloud computing, customers will no longer need to be at a personal computer (PC), use an application from a PC or purchase specific version of software to be configured on their smartphone or PDA devices. Customers will not have to worry about how servers and networks are maintained in the cloud as they do not own the infrastructure, software or platform in the cloud. And finally customers can access multiple servers anywhere in the world without having to know which one and where the location of the server is (Myerson, 2009). One of the main reasons why people switched to cloud was that, it provides companies with scalable, high-speed data storage and services at an attractive price (Schiff, 2010). It offers a solution to the problem of organisation that need resources such as storage or computing (CPU) in high dynamic level of demand (Rings et al., 2009). With both grid and cloud aim to provide access to a large computing or storage resources, cloud utilises virtualisation to provide a standardised interface to a dynamically scalable underlying resources that will hide the physical heterogeneity, geographical distribution, and faults by using the virtualisation layer (Rings et al., 2009).
Cloud computing allows users to plug into and use web services and application of networked software application by just using a web browser to run it. Using an open standard interface, cloud computing also allows external users to write applications using web based service (Adair, 2009). Adair (2009) explained that hardware is not an important factor since the main emphasis is placed on software and networking. There are two parts of the hardware equivalent to software-driven cloud computing concept mentioned:
1. Relates to network based storage system that abstracts some of the connectivity details of externally attached storage, and making it location independent to a host machine needing storage space.
9
2. Parallel or grid computing based on a form of virtualised server resources where the underlying platform may consist of blade servers or in the form of on-demand hardware allocation.
The technologies used to build cloud applications are much the same as developing web site on the three-tier web architecture. The front end will be the end user, client or applications, and the back end is the network of servers with data storage system and computer program (Dave, 2009). IBM, Sun Microsystems, Microsoft, Google, and Amazon are some of the big manufactures that provide cloud computing services and platforms (Adair, 2009).
Based on its essential characteristics, service models, and deployment models, the National Institute of Standards and Technology (NIST) has proposed the following definition:
“Cloud computing is a model for enabling convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction.” (Mell and Grance, 2009).
Cloud computing can also be referred as applications delivered over the internet and system software and hardware in the data centre that provide those services (Armbrust et al., 2009). These services come to customers based on on-demand strategies where customers only pay for what they really use. The three most often mentioned services are: Software as a Service (SaaS), Platform as a Service (PaaS), and Infrastructure as a Service (IaaS) (Mell and Grance, 2009).
NIST defines those three services as:
Software as a Service (SaaS): Customer uses applications locally without having any control over the running of operating system, hardware or network infrastructure. Example of this service will be the webmail provided by Yahoo! Mail, Hotmail and Gmail as well as Google Docs provided by Google (Robison, 2010).
Platform as a Service (PaaS): Provides customers more than just the software. It allows customers to host their applications in cloud infrastructure. Customer has controls over the deployed applications and possibly some control over the hosting environments but has no control over the cloud infrastructure (network, servers, operating system and storage).
Infrastructure as a Service (IaaS): Provides fundamental computing resources to customer such as processing, storage and networks. Customer has controls over operating system,
10
storage, deploying applications and possibly networking components (i.e. firewall) but has no control on the cloud infrastructure beneath it.
2.3.1 Deploying Models
Along with the services, there are many ways to deploy the cloud. Mell and Grance (2009) comes up with four deployment models of cloud computing which are as follow:
Public Cloud. The cloud infrastructure is made available to the general public or a large industry group and is owned by an organisation selling cloud services.
Figure 1: Illustration of a public cloud. Users accessing data and application without knowing how the underlying architecture works. Source from (Amrhein et al., 2009)
Private Cloud. The cloud infrastructure is operated solely for an organisation. It may be managed by the organisation or a third party and may exist on premise or off premise.
Figure 2: Illustration of a private cloud. Useful for large enterprise to handle a maximum workload. Source from (Amrhein et al., 2009)
Hybrid Cloud. The cloud infrastructure is a composition of two or more clouds (private, community, or public) that remain unique entities but are bound together by standardised or proprietary technology that enables data and application portability (e.g., cloud bursting for load-balancing between clouds).
11
Figure 3: Illustration of a hybrid cloud. Combination of public and private cloud together. Source from (Amrhein et al., 2009)
Community Cloud. The cloud infrastructure is shared by several organisations and supports a specific community that has shared concerns (e.g., mission, security requirements, policy, and compliance considerations). It may be managed by the organisations or a third party and may exist on premise or off premise.
Figure 4: Illustration of a community cloud. Has shared infrastructure among enterprise with a common purpose. Source from (Amrhein et al., 2009)
2.4 Provenance
Provenance can be referred to the sources of information, such as entities and processes, involved in producing or delivering an object. The provenance of information is crucial to making determinations about whether information is trusted, how to integrate diverse information sources, and how to give credit to originators when reusing information. In the free environment such as the Web, users may find information that is often contradictory or questionable (W3C, 2005).
12
“Provenance of a resource is a record that describes entities and processes involved in producing and delivering or otherwise influencing that resource. Provenance provides a critical foundation for assessing authenticity, enabling trust, and allowing reproducibility. Provenance assertions are a form of contextual metadata and can themselves become important records with their own provenance.”
(W3C, 2005)
Other definitions of provenance available are:
“The provenance of a piece of data is the process that led to that piece of data. “ (Groth et al., 2006)
“Digital provenance is metadata that describes the ancestry or history of a digital object” (Muniswamy-Reddy et al., 2010)
Nowadays, data can easily be obtained through the web. Data available on cloud can be heterogeneous. It is hard to know how data were updated and how trustworthy the data are. The use of provenance in the cloud will be crucial in this case. Without provenance, data consumers have no means to verify its authenticity or identity of the data (Muniswamy-Reddy et al., 2010). Provenance can help to validate the process to generate data sets for researchers to decide if they want to use the data. Another reason could be bugs from hardware and software release on cloud could be faulty. Using provenance can help to identify if a data set was tainted by faulty hardware or software in cloud (Muniswamy-Reddy and Seltzer, 2009).
The use of provenance can establish an end users trust since it can be served as an indicator of data quality (Souilah et al., 2009). Providing information about the creation of the dataset also is one of the most important ways that provenance can contribute to trust (Rau and Fear, 2011). Rau and Fear (2011) also stated when users trust the data used, it is most likely that the data will be reused in the future. It allows the users to accept the data results created by the authors of the reports.
Provenance can also be abstractly defined as a directed acyclic graph (DAG) (or provenance graph) where the edges of the graph signify the dependency between the nodes that help to explain how a product of a data or an event come to be produced in an execution (Moreau, 2010, Groth, 2008). Moreau (2010) assumed that the nodes and edges in DAG represent data items and data derivation. Figure 5 is a simple example of the computation 3 + 4 = 7 adopted from (Acar et al., 2010). The graph shows that 7was a result from a process of addition from inputs 3 and 4. The provenance graph is a way to illustrate how a trace of the origin of particular processes can be done. In practice, scientific researchers may conduct the same experiment repeatedly and hence the experimental result needs to be reproducible. A trace of the origin of the raw data needed to ensure trusted and authenticated data were used. This is because scientists perceived provenance as a crucial
13
component of workflow systems that helps reproducibility of their scientific analysis and processes (Moreau et al., 2011a).
Figure 5: Example of provenance graph
Provenance also concerns with a very broad range of sources and uses. Business applications may exploit provenance in trusting a product as they consider the manufacturing processes involved. In a scientific context, data are integrated depending on the collection and pre-processing methods used, and the validity of an experimental result is determined based on how each analysis step was carried out.
In e-Social Science, there were questions regarding how the data were created, analysed, or interpreted, and conclusions drawn. The use of provenance will be the answer to these questions. Provenance will be important to provide information about how data were created as well as information about the context of the data (Philip et al., 2007). Context of the data is important to evaluate the quality and the reliability of data, the robustness of analysis, the generalisability and the validity of finding. This is indeed useful when using that particular data when conducting research. An example of such context could include, an account of the characteristic of secondary data and why it was used; an account of data collection methods including who and from whom the data were collected etc.
Philip et al. (2007) also stated that conducting research in ethical manner is important in e-Social Science. They must be able to produce, through transparent process, a robust system for the analysis of data which forms evidence of policy success or failure. This also applies to legal issue such as data protection, copyright and intellectual property right. Thus, it is one of the important reasons of having provenance in e-Social Science. The role of provenance will allow it to act as decision makers by producing evidence of a context that shows all the data, methods and instruments used. Based on The Green Book by UK Government (Treasury, 2003), evidence is important to support conclusions and recommendation made to ensure that decision makers understand the assumption underlying the conclusions of the analysis and the recommendations put forward.
From the study conducted, it shows that provenance is an important component in e-Social Science. Contexts of the data used will be important when evaluating the research conducted especially if the
14
data were used to process human information such as health record. Having adopted the e-Science grid technology to collect, process, integrate, share, and present social and behavioural data, the use of cloud computing technology that provides on-demand strategies where customers only pay what-they-use service could arise in the future for e-Social Science.
However, data stored on cloud can be heterogeneous and can pose some problems when trying to get the information about the context of the data. The integrity of the data used will also be crucial for the use of e-Social Scientists when conducting experiments on cloud environment. This issue can be solved by using data provenance when deriving data from the cloud environment. The study also shows that currently there are lack of analysis and surveys of the current provenance schemes for cloud.
In order to deal with this problem, provenance requirements for e-Social Scientist is needed to ensure the right information will be captured. Study about the current provenance schemes will also need to be discussed. Chapter Three begins by deriving the provenance requirements for both cloud and e-Social Science. Survey and analysis of the current provenance schemes will also be conducted where various provenance schemes available for the use on different domains will be analysed. An example of the schemes is The Provenance Aware Service-Oriented Architecture (PASOA) (Groth et al., 2005a) which was used on Biology domain. The Earth System Science Workbench (ESSW) (Frew and Bose, 2001) was used by the Earth Science researcher, and Chimera (Foster et al., 2002) was used in the Physics and Astronomy domain. Each of these schemes will be discussed in further details in Chapter Three.
15
CHAPTER III
__________________________________________________________________________________
3. Analysis & Survey
3.1 Requirement Analysis
Requirement analysis is part of the methodologies conducted to get the necessary requirements. Two methods used to derive the requirement are by conducting study on research papers published that are related to the topic and by interviewing e-Social Scientists to derive the provenance requirement. The analysis will comprise of three parts which are the requirement of the provenance itself, the provenance requirement needed for cloud, and the provenance requirement needed by the e-Social Scientists. Each of these will be derived in a separate sub section as follows.
3.1.1 Provenance requirement
Before defining the provenance requirement for cloud and provenance requirement by the e-Social Scientist, requirements regarding the provenance itself need to be gathered. Dave (2009) stated that the technologies used to build cloud application are the same as developing web site on three-tier web architecture, hence the requirement identified by (Groth et al., 2004) can be used. Some of the requirements identified are:
Verifiability: The ability to verify the process in terms of actors involved, actions, and relationship with one another.
Reproducibility: The ability to repeat and possibly reproduce a process from the provenance that has been stored.
Preservation: The ability to maintain provenance information for a long period of time. Scalability: As provenance information could be bigger than the output data, it is necessary
for the provenance system to be scalable.
Generality: Where different systems might be used, the provenance system should be general enough to record provenance from a various different applications.
Customisability: To allow for more application specific use of provenance information, a provenance system should allow for customisation. Aspects of customisability could include constraints on the type of provenance recorded, time constraints on when recording can take place, and the granularity of provenance to be recorded.
16
3.1.2 Provenance requirement for cloud
Muniswamy-Reddy et al. (2009) has drawn some requirements needed by cloud providers in order to make provenance as a first class citizen. These requirements are to ensure that clients will get the benefits by reducing the extra development efforts needed to store provenance, and providers can take advantage of the rich information inherent in provenance for various applications ranging from searching to improving the performance of their services. Those requirements are:
Co-ordination between Storage and Compute Facilities: Cloud providers usually provide both storage and compute facilities. During the compute process, data can be generated and transmitted. A virtual machine that can handle the automated provenance transmission to the storage device together with the data as well as tracking record of the provenance can be installed.
Allow Clients to Record Provenance of their Objects: Clients may generate data locally and the data may be stored on the cloud. Client should be responsible to track the provenance and provide the provenance to the cloud for storage. Cloud providers should provide an interface that will allow clients to record provenance for generating data locally instead on cloud.
Provenance Data Consistency: Provenance stored on cloud should be consistent with the data it describes. Cloud itself is inherited from the distributed system, the provenance can be inconsistent if the provenance and the data were recorded using separate methods. Cloud providers should provide an interface that can store provenance and data automatically to ensure consistency between the provenance and data.
Long Term Persistence: Provenance should be kept for longer period than the object it described. An unrelated object could still be connected to the provenance. This is to ensure that the provenance chain will not be split when the objects were deleted.
Provenance Accessibility: Clients may want to access the provenance database to verify the properties or simply checking the lineage of data used. Cloud providers should support an access for clients to efficiently query the provenance by providing the right interface.
3.1.3 Provenance requirement by the e-Social Scientist
Getting the requirements by the social scientists is crucial, as they will be the clients who will use the system to retrieve, insert, and analyse the data saved on the cloud storage for research purposes. In this study, an interview method was used in order to obtain the requirement from the social scientists.
17
Andy Turner, one of the social scientists from the School of Geography, University of Leeds who was involved in one of the e-Social Sciences nodes projects in the UK (GENeSIS project) was chosen as a contact. During the interview, Turner pointed out various general points about the data used by social scientists. In social science, various data about people are kept. Some of the data can be described as an open data, where everyone has the authority to access. Another type of data is the closed data, which is classified and only available to an authorised research project, where data were usually stored in an anonymous form.
An example of the data mentioned by Turner was the Census survey data. It is considered as one of the most important data collected for researcher (within Turner’s research subject). The recently collected Census survey is now in the process of being updated and soon it will be available for researchers to use it in various output data form. Turner stated that it is important to link the Census data with other databases such as the council registry on health condition that can be shared across the health service providers such as public National Health Service (NHS) provider, and private providers by using a shared common registry. In an example of people having cancer, this will allow the city council to track the record of the patients’ cancer stages so that more help can be provided systematically. All of this information can be linked between the databases where the name and address can be used as the identifier (for Census in UK). In other parts of the world, a unique code stitched together with the data is used to link with other government data sets.
If the e-Social Scientists were to use the system on cloud, data security will be one of the issues. If the cloud infrastructure is not secured, it will expose the sensitive data to an unauthorised user. This issue can be a subject of another study of securing the cloud application for the use of e-Social Scientists. As for the data, Turner mentioned that provenance could be useful to provide confidence and trust when using the data from cloud.
Result replicability is also crucial . Example given was when running a simulation type model to simulate cities or population where changes of the characteristic of population overtime need to be repeated. When an average trend result achieved during the experiment, for debugging and for other types of reasons, the researcher will want to be able to produce the exact same result from a given set of metadata input. Another example will be the ability to reproduce the results of a city evacuation simulation using different scenarios of transport changes. Replicability is also useful when running the same program in a distributed fashion that has ten different instances, where those instances were evaluated against the input. Other forms of running the model will have certain stages that start with a given set of data, process it, get the result and archive it at a different repository. A separate process will be required to draw on these results.
18
An interview with Dr. Colin Venters, a computer scientist who worked with social scientist when he was a Grid Engineer at the NCeSS was also conducted.
Dr. Venters has pointed out several data provenance issues which are:
Currently there are no exact data provenance specification requirements to be kept. Data provenance used by the social scientist will vary depending on the project conducted. Quality of the data provenance is an important issue.
The integrity of data provenance collected is crucial as the data used will have to be validated before using it for research purpose.
e-Social Science researcher usually conducts several experiments before using the final output data as an input data for another experiment.
From the interview sessions above, the provenance requirement for e-Social Science can be derived. Full interview with Andy Turner can be found in the Appendix E. The key provenance requirements are:
1. Ability to replicate the results based on the input data. 2. Ability to evaluate the processes based on the metadata.
3. Ability to secure the sensitive data obtained from being access by unauthorised users. In this project, security issues will not be discussed. An assumption regarding security will be made when designing the cloud provenance schemes as part of alternative solution later.
3.2 Current Provenance Schemes Survey
The use of provenance can be applied to mostly anything either on scientific domain or on a business domain. In business domain, organisations usually work with a large organised data that are shared across the corporation. Even for the data usually shared among the trusted partners, validation of the originality of the data is still required.
In scientific domain, researchers often shared the experiments conducted. Other researchers who would like to use the results may have several questions before using them. Such questions could be: who did the experiment? What methods were used? What are the original data? Etc.
In this section, a survey on current scientific provenance scheme will be discussed in order to understand how the recording and querying the provenance were done. Even if none of the schemes discussed below are created for the use of e-Social Science project, as mentioned in 2.2, social science research is exploring the possibility of using the e-Science grid project for conducting
19
social science researches. Thus, an understanding of the schemes below is important to understand how recording and querying the provenance can be done so that it can be applied on Cloud application.
3.2.1 Chimera (Foster et al., 2002)
Chimera, a virtual data system for representing, querying, and automatic data derivation is a provenance system that manages derivation and analyse data (virtual data) objects in a collaboration environments. It has been applied to the physics and astronomy domain that has provided a generic solutions for scientific communities such as the “generation and construction of simulated high-energy physics collision event data from the Compact Muon Solenoid (CMS) experiment at CERN” (V. Innocente a et al., 2001) and used on “the detection of galactic clusters in Sloan Digital Sky Survey (SDSS) data” (Annis et al., 2002). It uses a process oriented model to record provenance by constructing workflows (in form of directed acyclic graph (DAG)) using the high level Virtual Data Language (VDL).
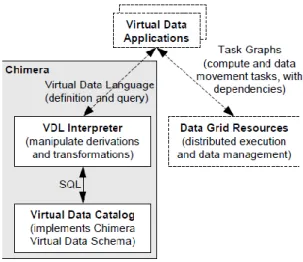
Figure 6: Schematic of Chimera Architecture
The architecture of Chimera virtual system (Figure 6) consists of two main components, the Virtual Data Catalogue (VDC) that implements Chimera Virtual Data Schema that defines the object and the relations used to capture descriptions of program invocations, and the Virtual Data Language (VDL) interpreter that is used for defining and manipulating data derivations procedures stored in the VDC operations.
The Chimera virtual data schema from the VDC is divided into three parts, which are transformation, derivation, and data object. Transformation is a schema defining formal types of input and output required to execute a particular application and is mapped onto an executable, a derivation
20
represents the execution of a particular transformation, and a data object is the input or output of a derivation (Arbree et al., 2003).
VDL comprises data derivation for populating the system database and query statement to retrieve information from the database. The VDL conforms to a schema that represents data products as abstract typed dataset (compromise from files, tables and objects) and their materialised replicas that are available at a physical location.
The provenance in Chimera was represented in VDL that was managed by the VDC service. The VDC will then map the VDL to a relational schema and stores it in a relational database that can be accessed using SQL queries. The metadata of the process can be stored in a single or multiple VDC storage that enables scaling through organisation. The provenance information can then be retrieved from the VDC using queries written in the VDL that can search derivations that generate a particular dataset. The search can be made by search criteria such as input/output filename, transformation name, or the application name itself (Annis et al., 2002). The result from the query will return an abstract of the workflow plan in DAG format where the node will represent an application and the edge will represent the input/output data. When a created dataset needs to be generated, the provenance will be able to guide the workflow planner in selecting an optimal plan for resource allocation.
Foster et al. (2002) stated that the design of Chimera is viable and not only feasible to represent complex data derivation relationships. It can also integrate the virtual data concepts into the operational procedures of large scientific collaborations.
3.2.2 Earth System Science Workbench (ESSW) (Frew and Bose, 2001)
The Earth System Science Workbench (ESSW) is a metadata management and data storage system used by the earth science researchers that manage custom satellite-derived data product such as receiving image from the Advance Very-High Resolution Radiometer (AVHRR) sensors on board National Oceanic and Atmospheric Administration (NOAA) satellites (Kidwell, 1998) and researchers that managed metadata for ecological research project. The key aspect of the metadata created in the workbench will be the lineage. It will be used as an error detector in deriving the data products, and in determining the quality of dataset collected. ESSW processed the data using a scripting model (Perl scripts). The script was used to wrap the legacy code to improve the burden of refashioning older program to generate useful metadata so that only minimal alterations needed to be done.
21
DAG model was used as the model that serves as a framework for defining the workflow process and metadata collection for each experiment and steps. The metadata will be defined in XML document type definitions (DTD) format that includes specification of the metadata elements. The ESSW workflow scripts links the data flow between successive scripts to form the lineage trace of the data products by using their metadata IDs. By chaining the scripts and the data using parent child link, ESSW system between data and the process can produce a balance-oriented lineage. By having this chain, it can help data provider to discover the source of errors in a derived data product whenever there are faults by tracing descending the lines of connected objects. The workflow of the metadata and the lineage can then be navigated through a web browser that uses Hypertext Preprocessor (PHP) scripts to access the provenance database in a DAG format (Bose and Frew, 2004).
Figure 7 below shows the conceptual diagram of ESSW.
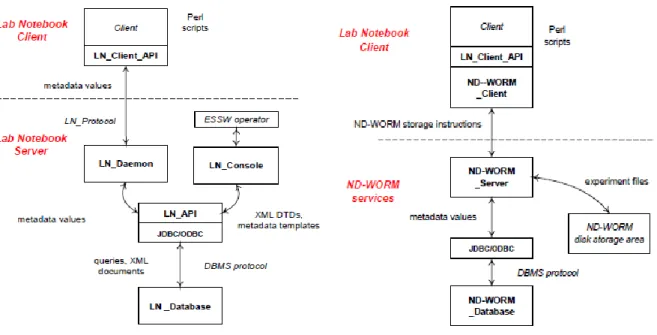
Figure 7: ESSW conceptual diagram. Source (Frew and Bose, 2001)
ESSW architecture consists of two basic components which are Lab Notebook and Labware. Lab Notebook is an application that logs metadata and lineage for experiments into XML format and stored it in a relational database. Labware is a No-Duplicate Write Once Read Many (ND-WORM) service that managed storage archive for the Lab Notebook by keeping unique processed file and namespace metadata including data in a relational database.
Lab Notebook is a Java client/server application. The server collects the specific metadata value from the client and constructs it as XML documents. These XML document as well as the metadata parse
22
are then transferred to a database record. The Lab Notebook server consists of three main components which are: Lab Notebook Daemon (responds to Client API), Lab Notebook Console (provide an interface to submit XML DTD), and Lab Notebook Database (storage for the XML and metadata documents).
Labware (ND-WORM) service is also a Java client/server application. The server operates through the interaction of three components which are: the Labware server (copies files to archives, group them and sends pertinent information to clients in response to request), Labware Database, and dedicated disk storage.
Figure 8: Lab Notebook and Laware (ND-WORM) architecture. Source (Frew and Bose, 2001)
3.2.3 Provenance Aware Service-oriented Architecture (PASOA) (Groth et al., 2004, Groth et al., 2005a)
The Provenance Aware Service-Oriented Architecture (PASOA) is a provenance infrastructure project that is built for recording, storing, and analysing over provenance using an open provenance protocol used by e-Science community to foster interoperability. PASOA system has been applied to the biology domain to identify scripts and steps of execution being invoked as well as making copy of the changes made so that it will be able to detect changes between one execution to another. It was used to decide if two results were obtained by the same scientific process. Example could be to check if valid operations were performed, or to decide the specific data item used as computation input.
23
In PASOA, both client and service act as an actor. Service could act as another client that will invoke other services. Figure 9 illustrates how a service acts as another client to another service.
Figure 9: An illustration of how a service acts as another client. Source (Groth et al., 2004)
PASOA architecture consists of two main systems, which are Provenance Recording Protocol (PReP), and Provenance Recording for Services (PReServ). PReP is a system that defines interaction provenance message that are generated by actors, synchronously or asynchronously, with each service invocation (Simmhan et al., 2005). PReP is divided into four phases protocol that consist of negotiation phase, invocation phase, provenance recording phase, and termination phase. To put it in words, actors should have an agreement before invoking a service; it will then record the interaction provenance and terminate the protocol respectively. The interaction and provenance message generated by actors in the workflow were linked using an ID that will be presented in the provenance message itself. The trace can then link all assertions that have the same ID as the assertion that contain the data as output. PReP only record the documentation of the activities invoked by the actors and it is not designed for duplication of data (Groth and Moreau, 2009). PReP currently does not have security in its specification and this has been proposed as the future work intended.
PReServ is a java-based web implementation of the PReP protocol that stores the provenance either in a relation database, file system or in a memory (Groth et al., 2005b). It contains a provenance store for web service as well as a set of interfaces for recording and querying the provenance message, a client side library for communicating with the provenance store and an Apache Axis library that automatically records the exchange messages in PReP and construct the workflow. There are three main components available in PReServ. Those components are ‘Message Translator’, ‘Plug-Ins’, and ‘Backend Storage’. The Message Translator isolates the Provenance Store’s storage and the query logic from the message layer. This will allow the Provenance Store to be easily modified to support different underlying message layer. The Plug-Ins implements functions provided
24
by the Provenance Stores (i.e. store plug-in and query plug-in). The last component is the Backend Storage where the provenance assertions are stored in the Provenance Store in the form of either database, file system or memory. Figure 10 illustrates the PReServ layers.
Figure 10: PReServ layers. Source (Groth et al., 2005b)
3.2.4 Provenance-Aware Storage System (PASS) (Muniswamy-Reddy et al., 2006)
The Provenance-Aware Storage System (PASS) is a storage system that collects provenance automatically and transparently for objects stored in it. PASS system has been successfully used on cloud as a system to collect the provenance (Muniswamy-Reddy et al., 2010). PASS system observes system calls that application makes and captures relationship between objects to construct the provenance graph. An example given by Muniswamy-Reddy et al. (2006) was, PASS would create a provenance edge recording the fact that the process depends upon the file being read when a process issues a read system call. When a write system call issued, PASS will then create an edge stating that the file written depends upon the process that wrote it, thus transitively recording the dependency between the file read and the file written.
As for the process that works within the PASS system, it records several attributes such as; command line arguments, environment variables, process name, process ID, and a reference to the parent of the process. PASS system stores data and the provenance record together to ensure that the provenance collected is consistent with the data. PASS also records the provenance of the temporary objects since persistent object such as files are related to each other via data flows through that temporary object.
25
Figure 11: PASS system architecture. Source from (Seltzer et al., 2005)
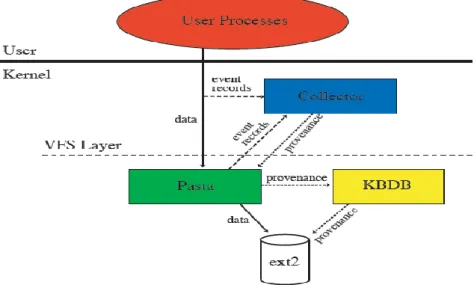
PASS system architecture (Figure 11) consists of two main components, which are the Collector and the Storage Layer that reside within the Virtual File System (VFS) Layer. The VFS Layer provides a uniform interface for the kernel to deal with various inputs/outputs request and specifies a standard interface that each file system must support (Kroeger, 2001). The collector generates a provenance record for each provenance-related system call and binds the record to the appropriate structure. It intercepts system calls and translates it into a memory provenance record that will be attached to the key kernel data structures.
The storage layer composed of a stackable file system called PASTA that uses an in-kernel database engine to store the metadata, and in-kernel port of the Berkeley DB embedded database library called in-Kernel Berkeley DB Database (KBDB) to store and index the provenance data. The provenance is accessible via a variety of programming language as a way to query the provenance in the database. PASS also has a built in file system browser tool for querying the provenance stored in the Berkeley DB database.
PASS system currently does not implement security in the system. Planning to implement the security model will be included in the second version of the PASS system that will look at provenance ancestry and attributes separately.
3.3 Discussion of the current provenance schemes
The schemes above show that there are various systems available to record and query provenance in a different scientific domain. Data are now increasingly being shared across organisation and it is essential for provenance to be shared across the data.
26
The use of cloud computing will offer users a variety of services covering the entire computing stack from the hardware up to the application level by means of virtualisation technology on a pay-per-use basis. This will give researchers the ability to scale up and down the computing infrastructure used according to the application requirements and the budget of users (Vecchiola et al., 2009). The use of cloud will also offer an access to a large distributed infrastructure and allow researchers to customise their execution environment so that they will have the desired setup for their experiments.
Each scheme discussed also has their own protocol for managing provenance and there are no open standards for collecting, storing, representing and querying for provenance between the four schemes described. This issues can be solved by applying The Open Provenance Model (OPM) specification (Moreau et al., 2011b) into each schemes discussed above. The OPM is a provenance model that is designed to meet a set of requirements so that it will:
Allow exchanging of provenance information between systems, by means of the compatibility layer based on a shared provenance model.
Allow developers to build shared tools that operate on such provenance model. Define provenance in precise, technology-agnostic manner.
Support a digital representation of provenance for any “thing”, whether produced by computer systems or not.
Allow multiple levels of description to coexist.
Define a core set of rules that identify the valid inferences that can be made on provenance representation.
Figure 12: Edges in the OPM (sources are effects, and destinations are causes). Source from (Moreau et al., 2011b)
OPM representation will be in a format of a directed graph. Figure 12 above shows an example of how the representation of OPM will look like. The first and the second edges show that process (P) used an artefact (A) and that artefact (A) was generated by a process (P). The process is identified by a role (R). The role is important when mapping the graph because a process may process more than one artefacts and each may have a specific role.
27
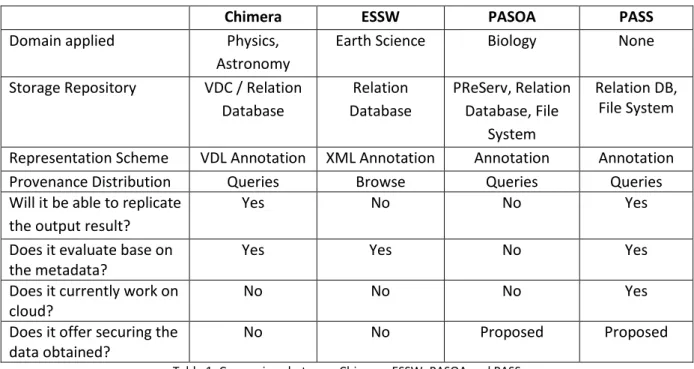
Table 1 below shows the comparison of the schemes discussed based on the principle below together with the finding if it met the e-social science requirements derived in the previous section.
3.3.1 Storage Repository
The size of the provenance data will depend on how rich the information of the provenance collected. It may vary from different process created. The manner of how it is stored is important to scalability. This is because provenance of certain process can have many versions available.
3.3.2 Representation Scheme
There are two ways to represent provenance. Provenance can be represented in either annotations or inversion approaches (Simmhan et al., 2005). Annotations approach collect metadata comprising of the derivation history of the data product as well as the process. Inversion method uses the property by which some derivation can be inverted to find the input data supplied to derive the output data.
3.3.3 Result Replication
A researcher might perform various experiments for their project. The experiment might use result derived from the previous stage before proceeding to the next stages. If an error was found on the current stage, the researcher might want to use the previous result data set again. Result replicable will allow the researcher to use the dataset again.
3.3.4 Provenance Distribution
A system should allow researcher to access the provenance in various ways. DAG is one of the methods where researcher can browse and inspect the tree. Another method is searching using the dataset based on the provenance metadata to locate dataset generated by flawed execution or to find the owner of the source data used to derive that certain data.
3.3.5 Evaluate metadata
A researcher usually conducts several experiments before using that final output data as an input data for another experiment. Researcher will want to be able to evaluate the metadata so that the final output used will be a reliable source for further uses.
28
Chimera ESSW PASOA PASS
Domain applied Physics,
Astronomy
Earth Science Biology None
Storage Repository VDC / Relation Database Relat