ABSTRACT
ANGRISH, ATIN. Development and Evaluation of Data Models and System Architectures for Virtual Manufacturing Machines (Under the direction of Dr. Binil Starly).
Development and Evaluation of Data Models and System Architectures for Virtual Manufacturing Machines
by Atin Angrish
A thesis submitted to the Graduate Faculty of North Carolina State University
in partial fulfillment of the requirements for the degree of
Master of Science
Industrial Engineering
Raleigh, North Carolina
2017
APPROVED BY:
_______________________________ _______________________________ Dr. Binil Starly Dr. Yuan-Shin Lee
Committee Chair
DEDICATION
BIOGRAPHY
ACKNOWLEDGMENTS
First and foremost, my sincerest thanks to Dr. Binil Starly, whose patient guidance and motivation without which this thesis would never have come to fruition. He has been a guide, mentor and a friend which, I have found, is an extremely rare combination for an advisor. I would like to thank the faculty and colleagues at NC State University, who have helped me learn and expand the horizons of my knowledge: Dr. Yuan-Shin Lee for his support and encouragement towards exploring unconventional projects in my automation class which eventually led to one of the applications in this thesis. David Rosar, CEO of ARCon Parts LLC for his help with the pick and place robots. Justin Lancester for his help with the computer and networking troubles in the lab. Dr. Tim Horn and Austin Isaacs for their help with the ARCAM EBM machines. Special thanks to the National Science Foundation (NSF) for funding this research.
No acknowledgements are complete without thanks to friends and family. Shout out to Kaustav Mohanty and Sriram Chari for unlimited discussions, intellectual and trivial both, and endless games of Catan; Dr. Arun Kumar Rastogi and Shaurabh Singh for helping break the monotony of work; and numerous others who made every day at NC State something to look forward to. Thanks to my family and friends (KKT group) back home who, despite the distance, make every effort to make me feel comfortable.
TABLE OF CONTENTS
LIST OF TABLES ...vii
LIST OF FIGURES ...viii
Chapter 1 Introduction ... 1
1.1. Smart Manufacturing / Industry 4.0 ... 3
1.2. Problem Background ... 4
1.3. Research Motivation ... 6
1.4. Thesis Objectives ... 8
1.5. Thesis Outline ... 11
Chapter 2 Literature Review ... 12
2.1.1. Traditional Manufacturing ... 12
2.1.2 Digital Manufacturing ... 12
2.2. Cyber-Physical Systems (CPS) in Manufacturing ... 16
2.3. Cyber Physical Systems Use cases in Manufacturing ... 20
2.3.1 Digital Twins in Manufacturing ... 23
Chapter 3 Concept Of Virtual Manufacturing Machines ... 28
3.1. Introduction to NoSQL and MongoDB ... 30
3.2. VMM Data Architecture using NoSQL ... 33
Chapter 4 Evaluation Of Document Organization In A NoSQL Data Schema ... 42
4.1. Design of the Document based Model of Virtual Manufacturing Machines (VMM) . 42 4.2. Document type Database Schema for Virtual Manufacturing Machines (VMM) ... 42
4.3. Experimental Evaluation ... 46
Chapter 5 Applications Of VMMs With Manufacturing Machine Types ... 52
5.1. Makerbot ... 52
5.2. ARCAM Electron Beam Melting ... 56
5.3. Arcon Chip-Sorting Machine ... 58
Chapter 6 Conclusions And Future Work ... 61
6.1. Summary ... 61
6.2. Future Work ... 62
LIST OF TABLES
LIST OF FIGURES
Figure 1: Representation of a Digital Thread [23] ... 13
Figure 2: Different Aspects of Cyber Physical Systems [39] ... 18
Figure 3: Traditional Automation vs CPS enabled automation [47] ... 24
Figure 4: General Structure of MongoDB ... 31
Figure 5A: VMM Stack Architecture; Figure 5B: Sample Document Content for a Machine ... 34
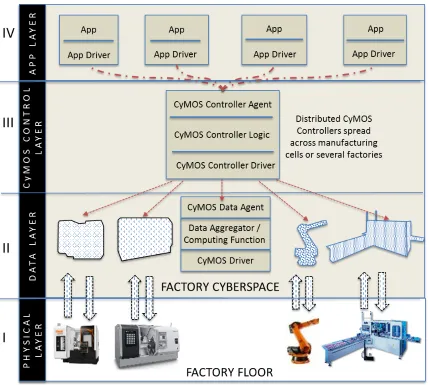
Figure 6: Four Layers of the CyMOS architecture. Layers II-IV exist in cyberspace, while Layer 1 represents the physical machine assets and necessary adaptors to communicate with layers above it. ... 38
Figure 7: Different strategies for storage of streaming machine data during the process of part fabrication ... 44
Figure 8: Representative Experimental setup of the Physical Organization of the Data by the server and associated storage drives. Any number of shards can be configured to make the system scalable across machines and factory floors. ... 48
Figure 9A: Simple Query response time vs Configuration; Figure 9B: Complex Query ... 50
Figure 10: Makerbot Replicator 2X ... 53
Figure 11A: Actual Part fabricated by the MakerBot and 11B: its associated sample document structure stored in the MongoDB ... 54
Figure 14:(A) Porous Mesh Football built on ARCAM EBM machine (B): Contour Time vs Build Time. Due to the shape of the football, it is expected that melting time to create a
contour is high in the center. ... 57
Figure 15: CT2000 Chip Sorting Machines ... 58
Figure 16: Cameras working with Vacuum Gripper to sort chips ... 59
CHAPTER 1 INTRODUCTION
The diversity and pace of machine data on a factory floor and economical methods to store, compute and explore this data for real-time technical and business decision making are key motivating factors towards improving factory productivity. These advances are inspiring the manufacturing information technology industry to re-evaluate conventional machine control and networking designs used today in the manufacturing shop-floors. In discrete manufacturing job shops, such as those in machining services, networking multiple manufacturing machines can be difficult to achieve due to a variety of reasons. This include, interoperability concerns between machine controllers from various vendors, outdated hardware controllers and a legacy infrastructure that is incapable of handling latest network communication protocols. This hinders the transformation of physical factory floors to the digital era. Advancements made in machine communications standards (example - MT-CONNECT[1], OPC/UA[2], MQTT[3]) have certainly lowered the barriers of machines communicating with centralized information systems (such as MES and ERP systems). The era of digitalization of manufacturing processes and its networking for efficient utilization of manufacturing resources requires a shift in the way data from manufacturing machines is handled, stored, retrieved and computed for actionable insights. Key manufacturing trends that are driving the need to rethink how data from factory floors and its extended enterprise are organized, include:
products. Reconfiguration of physical infrastructure rapidly based on changing market needs and demands is necessary. Production in quantities of one, such as in personalized medical products, to quantities less than one hundred will require new ways in which data from manufacturing systems is ‘pulled’ to satisfy market demands. This pull of information is necessary to assess distributed capability and dynamic capacity across job-shop and production floors regionally and globally.
• The shift to connecting product lifecycle data with the manufacturing processes: The
digital thread concept linking product information throughout its lifecycle from conception to production, then use and final disposable requires that we have fundamentally new ways in which information is linked across its various points of use [4]. Today, data generated during a product lifecycle is stored in siloed information systems – from PDM/PLM, to ERP/MES, to unique databases maintained by end customers. Integrating data across these disparate systems and linking across them in meaningful contexts across multiple enterprises in the supply chain can be challenging and expensive to implement.
• Increasing granularity of data collected from manufacturing machines: With the ubiquity
of sensors (RFID and machine mounted sensors), wireless networking and cloud storage, collecting and storing large amounts of data is not a bottleneck. Analytics conducted on manufacturing data can be beneficial beyond just monitoring, but useful in predictive and prescriptive maintenance [5]. It can also be used to inform key shop-floor decisions such as production scheduling and supply chain performance [6-8].
• The scrutiny placed on machine-to-machine connections in a network: With all this
include both explicit (raw signals, feature attributes) and implicit (operator name, part name, description), compounded with a time-reference to make sense of large machine generated data. The consumer of this data is presented with customized visualization and context to make data-driven decisions.
1.1. Smart Manufacturing / Industry 4.0
returns on investment [11]. The recent push in the form of initiatives such as Factories of the Future [12], Industry 4.0, Advanced Manufacturing Initiative by NIST[13] are valuable in outreach efforts to educate manufacturers on the benefits of new technologies and their potential impact on their ROI.
The growth and acceptance of ideas like Industry 4.0 depend heavily on the technological paradigms on which such programs are built. One such core idea is the notion of Cyber Physical Systems (CPS). Simply put, CPS are systems of physical assets, each of which has an associated digital representation in the cyberspace, leading to each asset virtual counterpart being interconnected in cyberspace. This enables the machines to be highly modular, intelligent and extensible via third party extensions. However, the concept of CPS for manufacturing is far from reality and there are several problems, both at technological as well as business fronts in manufacturing, which are inhibiting immediate and faster acceptance of CPS in the manufacturing shop floor. We shall discuss some of the most important problems in the next sections and the research motivations that have risen out of these problems.
1.2. Problem Background
The central problem behind CPS in manufacturing is the lack of appropriate architectures and data models for effectively collecting and analyzing the large amounts of data generated by the machines in the manufacturing domains, both in discrete and continuous manufacturing. Currently, there are large amounts of data stored by plant historians[14] and ERP systems, but they present 3 problems that make transition to smarter manufacturing harder:
temperature readings in a chemical process. However, that data lies dormant and is infrequently accessed by managers only on an as needed basis, usually in the case of accidents, serious quality defects or during random audits check for process verification. Such queries are mostly done after the fact and is purely meant for asset management and documentation purposes.
2. Data Silos: Another major problem with these is the formation of silos. Different departments of the enterprise have large silos of data which are unshared and under-utilized. This lack of sharing results in redundant expenditures and unoptimized utilization of resources and physical assets. Such siloed systems occur due to company acquisition and merger which tend to have systems that are not unified.
3. Closed systems v/s open systems: Often, manufacturing machines have been a closed system, tightly controlled by the makers of the machines. As a result, the pace of innovation in the manufacturing world has been stifled due to the ability to make improvements in the machines lying in the hands of a few companies. An open system for manufacturing would imply that the machines control system is easily accessible by the end users and modifiable to serve their needs suitably.
problems posed technologically have resulted in the author identifying the research objectives, which directly addresses an important need of current manufacturing machines to be incorporated in an advanced CPS system.
1.3. Research Motivation
A key motivation in the attempts to answer the 3 research problems posed above lies in the adoption of open frameworks for effectively capturing and analyzing the data generated by the machines in a shop floor. During the course of our research, we have realized that manufacturing machines are capable of generating enormous amounts of data in a very short span of time. The variety of machine manufacturers and the manufacturing technologies involved in the production of even the simplest products implies that data heterogeneity is almost always assured. Such heterogeneity means we need an architecture which is flexible with regards to differing machines and their varying data schemas. This also implies that the volume of data generated would require us not only to store this data effectively, but also optimize the manner in which the data is stored to address the needs of computation on this data, real-time or otherwise. This suggests that there needs to be an architecture which effectively addresses them.
Another issue that plagues discrete manufacturing is the lack of open source data management solutions to collect raw and refined data across the lifetime of the machine and the parts that they manufacture. The traditional relational database schemas are also not very equipped to handle the large volumes of real time data being generated by these machines. There is a lack of scalability which hinders the analysis of data and its storage. This eventually results in lack of interest on the end of plant managers to utilize any historical data to perform any “big data” analytics on these valuable data sets.
With increasing advancements being made in fields such as high performance computing and the machine learning algorithms, the world of manufacturing stands to make tremendous gains. There is a need for accelerated adoption of such techniques in manufacturing enterprises. Nonetheless, the lack of easily accessible machines and their data is a major hindrance. There is a clear evidence that access to data helps increase the pace of technology development. An example of this is the progress of image recognition technologies in the field of Computer Vision. The establishment of the ImageNet repository by Stanford University helped democratize a large databank to the general public to enable them to test new and untested image recognition algorithms which eventually has led to development of computer vision algorithms which can successfully categorize images even better than humans [15].
connected to. All that the developer needs to know is the specific function call and the parameters needed for accessing these sensors to collect data from them needed for their application. In the context of manufacturing, this abstraction is much more valuable as it is seldom a good idea to allow third party direct access to a machine core hardware and software controls. Providing such direct unfettered access can be damaging, several hundred thousand folds more than an ordinary mobile phone. Therefore, providing an abstraction layer would give manufacturers the needed assurance that their machine’s internal codes and wiring shall stay unaffected. Also, this would allow machine end users to make their own adjustments to the machines or hire a third-party application developer without the fear or the need of providing direct access to their valuable machine. A well designed system, thus would enable a potentially cross enterprise cyber manufacturing system which can be used effectively for development of applications or ‘apps’ on top of a manufacturing infrastructure.
1.4. Thesis Objectives
Our approach to solving these problems is development of a reusable and scalable architecture to reliably collect and analyze the data generated by machines which acts as a repository of machine states at all times, thus creating a “virtual/digital twins” of the machines. Furthermore, we would like the twins to be easily programmable and capable of performing some basic calculations for the data collected by them. Furthermore, these features of the digital twins would allow us to create novel data analytics based apps on top of these machines. For this purpose, we shall also create Application Programming Interfaces (APIs) to expose the data from the twins to the outside world for easier interfacing with these digital representations of the machines. As such, the approach raises two important research objectives as listed below: The research objectives are as follows:
Research Objective 1: To develop a virtual twin data architecture for manufacturing machines which would enable data stored in the virtual twin to power an ecosystem of third party applications for the manufacturing machine.
different types of machines in the manufacturing environment: discrete and continuous as well as closed and open source systems. Secondly, we also discuss the abstraction methodologies offered by our architecture which enables us to access the machine data without direct access to the machines. This is crucial in order to bring a more object oriented approach to programming applications for different applications.
One of the defining features of a CPS is the existence of a machines’ entire data history in a digital format which may be subjected to different kinds of analysis by end users, and eventually for control through its digital representation. In order to do this, we demonstrate the use of our architecture, coupled with an optimized data model for storage, to build third party applications which allow us to extend the capabilities and the use cases for the manufacturing machines on the shop floor. More importantly, we show how we can enable end users for these machines to build custom applications for increasing security of their machines, traceability and enhanced productivity. We show the development of a generic application programming interface (API which allows developers access to the machine database and a set of functions and layers to facilitate uniformity and ease in programming.
Research Objective 2: To perform a quantitative and qualitative analysis of the flexible data storage schema used in the Virtual Twin architecture of the manufacturing machines.
incorporate different kinds of machines and sensor systems along with the enterprise management software in the future, if need be.
1.5. Thesis Outline
CHAPTER 2 LITERATURE REVIEW 2.1.1. Traditional Manufacturing
The adoption of new technologies in the 1980s such as the introduction of Computer Aided Design (CAD) and Computer aided Manufacturing (CAM) helped to reduce the response times, improve product quality and optimize the efficiency of the product development process. With the advent of enterprise resource planning, material resource planning and product lifecycle management, organizations were further able to optimize their resource inventory and product data information with their production requirements. Similarly, we are now at a stage of exploiting the latest advances in information technology to develop new and improved ways of interacting with the manufacturing machines. New data structures and enterprise data architectures can enable users to be in better control over the data generated by the machines on the shop-floor. This control now enables a new generation of quality control enabled by big data analytics to help improve product quality and shop-floor efficiency. This data driven product design and manufacturing is enabling better integration of digital technologies into the manufacturing process.
2.1.2 Digital Manufacturing
is quite popular as a term, there is a lack of a unified definition for digital manufacturing. According to Chryssolouris et al[17], digital manufacturing is the integration for virtualization of different resources within the enterprise such as workers, machines, simulations, modelling for process and product development [18]. Other researchers such as Chen [19]call it “Direct” Digital Manufacturing or DDM as “the process of using a 3D (CAD) model for directly fabrication without the need for process planning” in accordance with the definition laid out by Gibson et al in 2010 [20]. They have implied that their paradigm of digital manufacturing is primarily limited to additive manufacturing. There is another group of researchers such as Beckmann et al[21]who look at digital manufacturing concept from the paradigm of a “digital thread”, the integration of data envisioned as the linkage of data from cradle to grave of a product during its lifecycle.
The concept of “digital thread” is a relatively new one. It is defined as the link between different types of systems in a product’s lifecycle across the supply chain, thus enabling the transmission, collection and sharing of data easily [22]. This leads to what is known as a single source of truth, where all the stakeholders in a supply chain of a product are looking at exactly the same data. This concept prevents formation of data silos and increases standardization of data formats across internal departmental divisions. It also enables data to be integrated across various separate IT systems that may be used during the design and production of the product, particularly in the context of discrete product manufacturing.
reductions in their tool reworks and decreasing ambiguity in communication of design concepts across the business units and value chains[25].
The recent push for digital manufacturing is partly due to the advancements in cloud computing technologies. The development of concepts such as distributed computing[26], parallel computing [27], virtualization [28] have given us satisfactory proofs of their disruptive potential in the service and product marketplaces. Some of the major reasons for their success have been increased speed of deployment, lesser maintenance expenditures, higher uptime and lesser costs to avail and run services based on these technologies [29]. The rise of these technologies have given rise to new service models : Infrastructure as a Service, Platform as a Service, Hardware as a Service and Software as a Service [30].
However, there has been a lack of uptake on the part of the manufacturers for the same due to the nature of the industry itself. Manufacturers are typically risk averse and often find it difficult to modify internal process unless there are true champions of change internally within the company. A major part of this technology risk averseness has to do with lack of standardization of communication protocols for machines, extensive lock-in periods and agreements along with fears of voiding of warranty on the machines without the consent of the machine OEM and a conservative outlook to business.
manufacturing. The digital thread is a central concept to cyber physical systems in manufacturing which are discussed in detail in the following section.
2.2. Cyber-Physical Systems (CPS) in Manufacturing
While such ideas have been implemented in parts in the past with the rise of ideas such as e-manufacturing [33], computer integrated e-manufacturing [34], Networked Manufacturing [35], they have typically been within the plant floor and extremely specific in terms of their application. As noted by Tao et al[36], the lack of effective models for transaction and on-demand use of manufacturing resources, manufacturing knowledge management, connectivity of physical resources to internet, virtualization and service encapsulation and reliable cyber security are the 5 key bottlenecks to the implementation of the ideas such as e-manufacturing. Baheti and Gill [37] defined a CPS as “a new generation of systems with integrated computational and physical capabilities that can interact with humans through many new modalities”. Noticeably, there is quite an overlap in the definition of different patrons in the research community regarding the definition of a CPS: an interconnected system of machines which continuously store data generated by themselves and/or the sensors attached to them, analyze that data to convert it into meaningful and usable information and close interaction with other machines using some form of machine to machine (M2M) communication.
discussion. Since the paradigm encompasses many different branches of engineering and science such as electronics, manufacturing, sensors, wireless communication and networking. Fortuitously, this turns out to be a blessing in disguise as it helps the acceptance of CPS in various fields.
Figure 2: Different Aspects of Cyber Physical Systems [39]
by Wang et al [40], various problems with implementation of CPS were also covered. The primary amongst them were as follows:
1. Conservative industrial outlook to new technologies: In an age of increasing competition, companies are working with tighter profit margins and smaller product lifecycles. This leads to skepticism towards new technologies and slow progression towards new ones. One of the potential solutions suggested by Wang is the use of transitional technologies to help make the shift easier and to take such projects in phases. Wells [41] have also discussed the potential breach of security as a point of concern in industries. Intellectual property is a major competitive advantage for companies and they fear loss in case of security breaches into their network particularly when all machines are interconnected and externally connected to the enterprise. Cybersecurity is a growing concern as IoT becomes more pervasive across different industries. There are numerous cases of systems being hacked, from mobile electronics to power plants being affected by malicious viruses [42].
neither of them might be out of place in their respective contexts, this absence of unanimity will lead to problems in enhancing interconnectivity between the CPS, which leads to a defeat of the paradigm itself.
Despite such problems, cyberphysical systems promise to integrate entire industries and result in significant cost and efficiency gains. The next section covers the advent of cyberphysical systems in manufacturing, digital twins and the promise they show to advance manufacturing towards a more data oriented, integrated model.
2.3. Cyber Physical Systems Use cases in Manufacturing
tool directly. Both these methods would allow us to passively or actively observe the machine state continuously and potentially make adjustments in real time in order to react to unforeseen problems such as chatter during milling or design modifications in the assembly line in real time.
Another major area crucial for the success of cyber physical systems in manufacturing will be the development of communication protocols for sensors and machines. There is currently a lack of communication standards in terms of transfer of manufacturing data in between systems. While there are several legacy machines which work on SCADA systems capable of networking, they may not be adequate to handle the high volumes of data transfer rates and cybersecurity required for the new age of CPS in manufacturing, especially considering the fact that most networking capabilities for the SCADA systems were developed in 1980’s with scant regard for cybersecurity. However, there are several strides being made in regards of communication protocols.
Similarly, there is the Message Queueing Telemetry Transport (MQTT) [3] which is a lightweight M2M communication protocol for IoT enabled devices. The primary advantage that MQTT offers is twofold: it allows for buffering of messages which means it provides reliable communication in the case of spotty network connectivity and secondly, it works on a publisher-subscriber model. This means that the MQTT can be used in cases where application use case is specific and when network bandwidth is a premium.
2.3.1 Digital Twins in Manufacturing
Another enabling platform of CPS for manufacturing is the concept of machines having its digital counterpart or ‘twin’ available in cyberspace. As observed by Rosen et al [46], development of autonomous manufacturing systems would require them to have access to representation of machine states and machine information in real time for development of real time decision making models and understanding the contexts of machine interaction with the outside world. This representation of machines is called digital twins. These twins will play an important role in the development of CPS for manufacturing systems. As observed in the paper, the new CPS enabled production systems give us new opportunities like:
• Distributed production systems for dynamic planning and rapid rescheduling,
• Improved decision making using simulation models utilizing actual data from the
machines and
• Automatic planning and execution of orders by production units along with
Figure 3: Traditional Automation vs CPS enabled automation [47]
The above mentioned decentralization with machines communicating with each other will not be easily achieved due to the lack of standardization. Weyer et al [48] has discussed the need for modular, multivendor products. In their paper, the researchers discussed the absence of a unifying framework for machines made by multiple manufacturers. They pointed out that most of the research till date has been on isolated production systems with single vendor machines. The interface between machines is crucial and yet an unexplored aspect of the CPPS. In order to tackle this, the researchers worked with multiple industry partners to develop an interoperable standard for electromechanical components and development of “infrastructure boxes”, which are essentially systems for supplying energy and means of communication for the machines of different vendors. The exercise, while confirming several benefits of a CPPS such as higher interoperability, they found some important shortcomings in their implementation. They realized that most PLCs did not support OPC UA’s advanced communication implementations. Also, the modules exhibited a tendency to fail often due to frequent power cycling. Therefore reliability of services offered through CPPS is a critical issue of concern.
also play a role as autoencoders to reverse engineer possible inputs from a given representational system state. Features such as these would help factory troubleshooting to be far more effective and requiring lesser human effort. New algorithms are also being developed for fast anomaly detection using techniques such as columnar machines [50].In short, CPPS are enabling manufacturing to become increasingly smarter.
While most examples above have been implementations in discrete manufacturing, the application of CPS is not limited to them. CPS holds great potential in continuous manufacturing industries (e.g. petroleum, textile, electronic chip, food and beverages, textiles etc.) as well. Continuous production often demands a high level of control over the process parameters as the batch sizes are often large and in process optimization is typically not preferred unless the process is irrevocably out of control. Due to the large number of parameters and numerous possible interactions, the continuous production industries operate within a range of possible values for their process parameters. The possibilities of continuous monitoring and online control of process parameters to ensure optimal manufacturing conditions offered by CPS would enable them to reduce wastage, downtime, costs and hazardous conditions.
pose health problems to personnel. An image depth sensor was implemented by researchers identifying the position and orientation of the covers of the loading containers and the robot controller automatically detects the kinematics needed for opening the covers.
The rise of CPS has also prompted increased R&D in the PLC manufacturers, leading to the rise of “soft PLCs” [52] which are essentially software defined PLCs. These are controllers which combine traditional PLC hardware with sophisticated networking and memory hardware and software. An implementation of a soft PLC was demonstrated by Saggiomo et al [53]for self-optimizing textile weaving machines. The researchers developed a system for collection of 3 process parameters: basic warp tension, revolutions per minute and vertical stop motion positions. These parameters were used as an input for a Nelder Mead algorithm solver implemented on the soft PLC running the machine for multiobjective optimization of warp tension, energy consumption and fabric quality. This resulted in reduction of set up times by 75% and improvement in observed parameters by 14% compared to static machine settings done typically by the operators.
CHAPTER 3
CONCEPT OF VIRTUAL MANUFACTURING MACHINES
One of the most important things for the implementation of a CPS in manufacturing is the development of a suitable architecture. Such an architecture should allow for easy and inexpensive scaling, flexibility in terms of development and suitable abstraction for different users. In this chapter, we shall propose a new architecture and data model for digital twins to be used in a CPS and present the results of our studies on the same.
The following section until the end of this chapter has been taken from the author’s own publication in Atin Angrish et. al. “A Flexible Data Schema and System Architecture for the Virtualization of Manufacturing Machines (VMM)” published in the Journal of Manufacturing Systems [80].
Levels 2 and 3, to enable higher order elements of a manufacturing focused CPS. At these levels, we focus on a data architecture that supports the concept of a ‘digital twin’ for a machine or more specifically, ‘Virtualized Manufacturing Machines’.
unstructured data from machines and have that data be made available to third-party applications.
The ultimate goal of any cyber-physical manufacturing system is the ability for global enterprises to quickly respond to business and customer demands while containing costs and maintaining operational flexibility. Wang et. al.[55] discusses various types of cyber-physical systems in manufacturing. Their work expands on the examples of CPS in manufacturing such as multi-agent systems [56-58] adaptive manufacturing systems [59-60], model driven manufacturing systems [61] and cloud manufacturing [62,63]. To this end, there is an imminent need to consider advanced database systems which allow large scale storage and retrieval needs for cyber-physical systems.
3.1. Introduction to NoSQL and MongoDB
structure. Several organizations have implemented MongoDB as back-end IT systems for crunching through various schema-less data and as a way to store and present data in a web compatible formats [70]. Most recently, NIST has started a “Materials Genome initiative” which uses MongoDB at the backend with RESTful services to enable third-party software integration [71-72].
NoSQL databases are a distinct class of databases that do not have a prescribed schema when compared to conventional SQL based databases. The most common of such schema-less data type stores include graph and document based stores. In document based stores, data is stored in the form of key-value pairs known as the JSON format (javascript object notation). The documents form the atomic units for a NoSQL database. This enables the NoSQL databases to efficiently handle unstructured data generated from a variety of sources. Multiple documents belonging to a same named group is called a collection. Multiple collections form a NoSQL database, which is a container for holding a single or multiple collections. Documents and collections in a NoSQL structure are analogous to records and tables in a traditional SQL structure respectively.
Time series data. Developed by MongoDB Inc. Information within MongoDB is stored in the following format (Figure 4). At the core of the MongoDB structure are documents, which are the most basic units of the database. Documents contain a JSON-like representation of the information stored in the database. Documents are analogous to rows in an SQL table. A bunch of documents form a collection. A collection is analogous to a table in SQL, except no schema is enforced on the data stored within a collection. Above the collection in the hierarchy, exists the database system which is the container to hold single or multiple collections. The problem we face involves generation of vast amounts of unstructured machine data and sensor data, which needs to be collected, analyzed and stored. Since we are looking at scalability and ease of use, we decided to opt for the MongoDB. We collect the machine data and sensor data at a set polling frequency. The data collected is assigned a timestamp. At any given instance of time, a single or multiple data points may be stored. Therefore, the schema-less storage and the ability to create documents without a predefined structure of MongoDB is useful.
For the purposes of this study, we have used MongoDB, an open source NoSQL database with extensive use across information technology applications. Its use in manufacturing contexts are nascent and still developing. We have selected to use NoSQL over SQL structured databases for the development of VMMs based on two primary reasons:
pre-determined table that must be changed if the machines capabilities are changed. NoSQL document structures enables us to ignore the schema of the data and still maintain the data in a manner that maintains data integrity and validity.
b. Scalability: SQL databases scale vertically, while document type NoSQL databases scale horizontally through the process of ‘sharding’, which implies NoSQL databases enable us to scale the data by distributing it across multiple servers. This enables us to increase the storage and performance as the volume of data increases. In contrast, as the amount of data increases, the ideal way to scale a typical SQL database is by increasing the hardware and performance capabilities of a system of servers. Manufacturing machines have much faster write requirements than read or transaction speed requirements. Processes such as metal fabrication for a single part fab can easily generate TBs of data depending on the amount and type of data collected. Therefore, a horizontal scalable solution is desired to optimize performance, particularly when many types of machines exist on a factory-floor.
Figure 5A: VMM Stack Architecture; Figure 5B: Sample Document Content for a Machine
The primary purpose of this research is to utilize the distributed nature of the modern NoSQL database to create a virtualized version of the physical manufacturing machine. This is intended to store the data generated by a machine but also to create an economically feasible and scalable middleware architecture that can be implemented on industrial floors. The proposed architecture for a generic VMM for any physical machine is composed of 3 parts: A Driver, a Database and a Generic Machine Access Library (Fig 5A). Each of these components are described below:
machine, collect sensor state, format it as a defined object and then pushed into the database at a set polling frequency. Technologies such as MT-CONNECT for CNC machines can be used as an enabler to extract data out of the machines. Many legacy machines simply do not have this capability and therefore drivers must be written to extract this data out of the machine.
2. The Database implemented in the proposed architecture is a NoSQL type document database divided into 3 layered data structures:
a) Raw Data Layer: This layer of data structures contains the raw in-process data generated during the manufacturing of a part on the machine. The drivers continuously collect information from the machine and push it into the database – a raw data layer in the form of documents. A sample document structure is shown in Figure 5B. A point to note is that there is no necessity for the documents schema to be similar within the collections contained in the database.
b) Information Layer: These data structures pertain to mostly static information about the machine, most of which is populated during the instantiation of both the physical machine and its virtual version. It contains a list of the machine’s assets, capabilities, sub-systems etc. Information contained here is retrieved by higher order information systems when required.
data to systems that request it. This is especial useful when such information is calculated during a machine’s downtime. When configured properly, it helps to enable rapid response to external applications that request information from a machine.
3. The Generic Machine Access Library (GMAL): This library is a set of Application Programming Interface (API) tools which allow end-users to build third-party applications for the machine. The library provides functions to pull data out of the raw-data layer, thereby providing a layer of abstraction to third-party software developers. The library also offers an object oriented approach to programming. As a result, the application developers simply have to initialize an object referring to the machine and they can directly monitor and control the machines, provided access rights are granted. It offers several functions such as getMachineData(layer) [for pulling specific layer data] or sendCommand(command) [for sending commands to the machine]. The generic access libraries give us the ability to analyze and retrieve information intelligently. It is the job of the drivers below the GMAL layer to translate the requests to specific machine level code.
this paper. The following section will describe the design of the MongoDB document and the evaluation of its various organization types that is suited for manufacturing.
3.3. Enabling an Enterprise level Middleware of VMM Integration
Figure 6: Four Layers of the CyMOS architecture. Layers II-IV exist in cyberspace, while Layer 1 represents the physical machine assets and necessary adaptors to
communicate with layers above it.
cybermanufacturing as ‘CyMOS’. CyMOS provides a programmatic interface for the data generated and consumed by the physical machine assets on a production floor. It integrates data from the lowest level of a manufacturing enterprise – Physical Machine Layer (Layer 1 in Figure 5) to the highest level of the enterprise user through a set of middleware layers – Data Layer, Control layer, and the App Layer. We have briefly highlighted the function of each layer that comprises the CyMOS architecture.
Physical Machine Layer – This layer represents the bottom portion of the stack. It represents the edge from which a host of data is collected and to be controlled. This layer also represents the software and hardware adaptors necessary to communicate with the layers above it. Data Layer – This layer represents the data communication from and to the physical machine asset. Each machine on the shop floor will have its individual virtualized state. This virtualization is enabled by a database instance structured to receive real-time streaming data from the machines. Drivers written at this data layer serves to communicate with the proprietary interfaces of the individual machines. Data analysis algorithms built in this data layer serve to aggregate and summarize information to be made available to higher level system calls (as shown in Figure 5A). At the upper level of this layer, each virtualized state of the machine has an agent that communicates with the CyMOS control layer. This agent is responsible for translating instructions from the control layer and generating results for requests about the physical machine made available to any software app or device that requests it.
machines in its network, current status of machines and other information gleaned from external data sources (such as an ERP or MES system). At the bottom of this layer, is the necessary driver that communicates with each individual virtualized machine. At the middle of the stack are higher level computational algorithms that aggregate data from the virtual states. It is able to translate requests from Apps that sit on top of the CyMOS architecture and then fetches valid data requests from the respective virtualized state. The CyMOS control layer can also interface with other external databases either within or outside the enterprise for processing instructions to the layers below it that are sent to it. Depending on the complexity of the factory-floor, there could be multiple distributed controllers spread across factory floor in an enterprise that spans multiple geographic locations.
CHAPTER 4
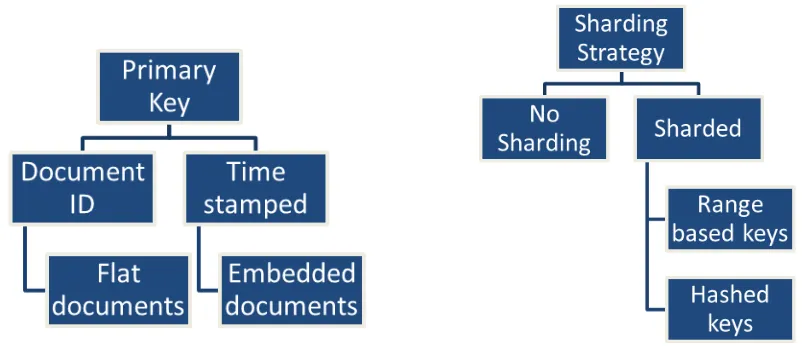
EVALUATION OF DOCUMENT ORGANIZATION IN A NOSQL DATA SCHEMA 4.1. Design of the Document based Model of Virtual Manufacturing Machines (VMM) The success of a VMM implementation in manufacturing depends heavily on the way in which enormous amounts of data generated by the manufacturing machines is stored and then made available to users of the data. This in turn affects the speeds of data storage, retrieval and consequently, analysis. We experimented with 6 different data models, each of which have their own strengths and weaknesses. In this section we will discuss the different data models for the VMM which may be used for data storage. We explore the concept of “sharding”, a technique used for distributed database implementation, effects of selecting various primary keys and document organization in an unstructured schema. These document models were subjected to statistical analysis for identification of the most suitable data model for use in a manufacturing VMM.
does not necessarily have to be tied down to a schema, its organization is critical to the proper functioning of a VMM. This selection of the document organization is based on – the amount of data streaming in, the need for high querying/read operations on the data and the degree of scalability desired. There are 3 aspects to consider when designing the schema for the unstructured database: the selection of the primary key, the documentation organization type and the sharding strategy.
The second type of primary key is a timestamp based primary key. This would imply that a buffer collects data from the machine for a specific period and then stores the data generated by the machine. Once the time period has elapsed, it attaches a time stamp to all of the data generated during that period and then uses the time-stamp as the primary key. This way, each document stores a lot more data content compared to a document ID based method. The benefit of the time-stamp based primary key is that it would be easy to query back events that may have occurred between time periods, which may help link to specific process plan steps in the processing of a part. A similar document ID based key can also help retrieve the same data but it comes with a computational overhead required to process the request and report back the same results. With machines that report a lot of data within milliseconds, a timestamp based method is far more efficient at storing data.
Figure 7: Different strategies for storage of streaming machine data during the process of part fabrication
2). If each document is based on a timestamp, then it is possible that data from many types of sensors/axes are being reported. In such a scenario, we must consider how to organize the data record within a document. There are two possible methods – a flat document or embedded (nested) documents. A flat document structure implies that each document contains only one specific schema of data in each document. An embedded document structure utilizes nested documents within the data parameters to represent multiple values or characteristics of the data generated.
Sharding strategy: The NoSQL databases may be sharded and/or not sharded depending on whether the VMM for a particular machine needs to be scaled horizontally or vertically. ‘Sharding’ is the mechanism to split a database into smaller, faster more nimble parts. This choice of centralization versus decentralization of data storage affects the rate at which manufacturing data can be accessed by higher order IT systems or by apps that need to fetch data about the machine.
There are two types of sharding strategies –
1) Ranged sharding, in which the primary key itself becomes the shard key. The raw data is split into chunks that are sent to different shards of the system. The configuration server holds the shard addresses and the shard keys tell the DB where the data is stored in a sequential manner.
especially during a read operation since the key must be first recovered before data is submitted back to the application.
4.3. Experimental Evaluation
Table 1: All possible combinations for document structures
Configuration Primary Key Document type Sharding strategy Shard key type
C1 Timestamp Embedded Sharded Hashed
C2 Timestamp Embedded Sharded Unhashed
C3 Document_id Flat Sharded Hashed
C4 Document_id Flat Sharded Unhashed
C5 Timestamp Embedded Unsharded N/A
C6 Document_id Flat Unsharded N/A
Table 2: Query Types and Queries
Query Type Query Parameters
Simple
(querying for a key value pair to return all document(s) which match the criteria)
db.rawLayer.find ( { document_id : value } )
Document_id
Table 2 continued
Complex
(queries requiring computations before results are returned)
records = db.rawLayer.find( { "$and": [ { "time_second" : { "$gte" : search } } , {
"Core_Cache_Performance_MaxCy cleTime" : { "$exists" : True } } ] } , {
"Core_Cache_Performance_MaxCy cleTime" : 1 , "time_second" : 1, "_id" : 0 } )
Time_second:
timestamp after which we need the results Core_Cache_Performan ce: system parameter being measured
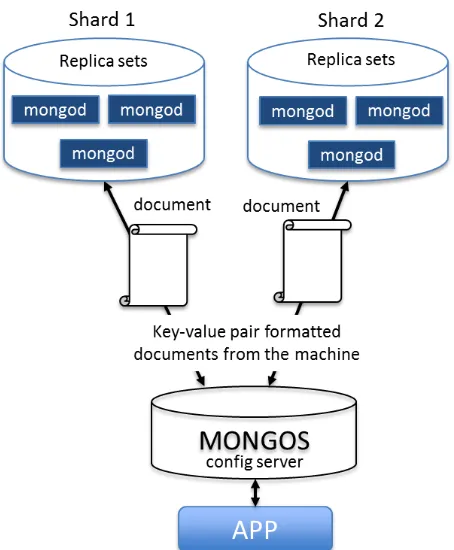
driver was written for the collection of data from the ARCAM EBM machine and it was then directed into the MongoDB system. The ARCAM EBM data is an example of a data stream with varying schema structure depending on the part being fabricated. The data generated by the controller is not periodic. The machine may record 5 data points at one instance and then possibly 10,000 data points at another instant in time. The type of data collected also varies depending on the amount of process monitoring equipment attached to the system. The drivers were written to parse through the data and then sent to the data store in the 6 configurations noted in Table 1.
Figure 8: Representative Experimental setup of the Physical Organization of the Data by the server and associated storage drives. Any number of shards can be configured to make the
The sharding setup was as follows: The system comprises of two shards, one configuration server and 1 mongos server (Figure 8). This setup is similar to the one set up by Kang et al [64]. For a detailed description of the MongoDB configuration, the readers are directed to its manual which describes the function of the mongod and mongos components of the database [79].
A randomized test was conducted with the 6 configurations. We conducted 10 replicated queries with 2 different kinds of query types. One query was a simple query where the system is queried for a manufacturing parameter either with a document id or with a time stamp. The other query is a more complex one where the system is required to check for the existence of a particular manufacturing parameter, perform calculations and then return a usable list to the app. After each query execution, the response speed was calculated. The queries are as follows in Table 2. Based on the above experiments, we generated a matrix of size 6x10 for each kind of query. The response times were measured and subjected to a Tukey-HSD pairwise comparison. The TukeyHSD tests for significant differences in the means for different configurations, taken two at a time for analysis.
organization type has to be amongst C1, C2 and C3 configurations. Figure 4 suggests that C1 or C2 should be the best configuration especially with machines that report various types of data. For example, a metal 3D printer may collect X-ray images after every processing layer along with data from its various sensors. These two different data types will require nested forms of document organization to ensure easy correlation. The C3 configuration, with the flat documents is best served for simple machines. Given the needs of storing large amounts of data, a sharded database makes more sense. Therefore, we recommend, C1, i.e. a timestamp based document structure storing data in a sharded manner through a hashing function for storing streaming data from machines.
Figure 9A: Simple Query response time vs Configuration; Figure 9B: Complex Query
In this section we analyzed the different models for data storage for our VMM. We identified 6 possible data models and tested them on the data from the ARCAM EBM machine, which was chosen because it presents an extreme case of varying data schema, irregularly polled data and immense range of the process parameters. A TukeyHSD test was used for comparing the
6 different configurations of documents in the MongoDB database. Based on this, we were able to identify the best document data model for use in our database.
CHAPTER 5
APPLICATIONS OF VMMS WITH MANUFACTURING MACHINE TYPES In this chapter, we describe three applications currently built on top of the proposed VMM middleware architecture. While we have built VMMs for other CNC machines [74], here we focus on three machines, a partially open sourced low-end fusion deposition based 3D printer (Makerbot 2X), a high-end closed source metal based 3D printer (ARCAM series of EBM machines) and Arcon CT2000 chip sorting machines. Any number of applications can be built with the middleware architecture using programming language of choice, provided there is the necessary adaptor to interface with VMM generic access library. The code for the VMM architecture has been built in Python with extensive use of libraries available within the Python language ecosystem.
5.1. Makerbot
Figure 10: Makerbot Replicator 2X
This particular app written for the Makerbot is designed to capture machine axis movements and to rebuild the part digitally by collecting data from the controller via driver codes, the part file and any associated sensor data. We will be using this raw data to identify the parts printed on the Makerbot, then associate and visualize sensor readings with the slice layers of the part. This can be especially useful when there are fleets of FDM printers and the need for traceability on part validation and verification, particularly when process monitoring data is gathered. Moreover, by associating process information with product information, it becomes possible to identify differences at a slice level between products.
movement in a 3D scatter plot using the generic access library and the matplotlib library available in Python.
Figure 11A: Actual Part fabricated by the MakerBot and 11B: its associated sample document structure stored in the MongoDB
The summary layer of the machine contains statistics for various parts including the mean, minimum and maximum values for the sensors. This is especially useful from a quality control perspective, if traceability is required to find process layer levels that exceeded a certain value. Such an analysis can be used for enhanced study of FDM printed parts and may also be used as a “playback” system for the machine. By storing the values of the encoders, it will be possible to make an app which can compare the commanded movements with the actual movement of the axes. Such a system can be used for complete quality control of 3D printed products for every single part produced. It can also be useful when security implications are considered. Advanced pattern recognition apps can be written to identify deviations of part fabrication from the norm to warn users of errors and potential malfunction. This can help mitigate cyber-threats with apps that specifically look for deviation from the accepted norm in part fabrication.
5.2. ARCAM Electron Beam Melting
Electron Beam Melting machines are far more complex since it is a closed system with its ability to generate data for thousands of parameters that are tracked during the part
fabrication process. We demonstrate the use of our architecture for development of an app which can be used to facilitate research into development of analytical models and data visualization. In this app, we demonstrate the use of the generic access libraries to interface with custom machine specific log files for developing statistical and visualization tools. This is unique such that it allows researchers to go beyond the basic tools offered by the vendor (ARCAM) in their custom machine software(figure 13).
Figure 13: An ARCAM EBM machine
simultaneously without writing excessive code to compare data across multiple log files. This is particularly important when file sizes in excess of 300MB and even more than a TB can be easily generated during the fabrication of a part [74].
This example app requires the user to select a parameter and it then fits a curve to the data collected during the part fabrication. As an example, we modeled the time for melting of a particular layer as the build proceeds for the fabrication of the NCSU football. We demonstrate our result in the following graph (generated via the app) in Figure 8B. As can be seen, the time taken for melting the powder for each layer (contour) is low at the beginning and at the end of the build. But it increases as we move to the middle of the part. Just by interfacing with the log data generated, it is possible to identify the general contour shape of the part. Any number of 3rd party apps can be written that extends the process monitoring capabilities of the EBM machine. More importantly it lowers the barrier of future software developing by providing the core interface libraries needed to interact with the machine core.
5.3. Arcon Chip-Sorting Machine
Continuous manufacturing is another area of manufacturing which could benefit from use of the virtual manufacturing machine model adoption. For example, a high speed chip handling robot is an electronics manufacturing plant might often break down and bring the entire assembly line to a halt. Alternatively, a scenario where the wear and tear of the machine may go unnoticed because of lack of monitoring of adequate parameters in the machine. We implemented the VMM model on two CT2000 chip sorting robots (developed by Acron Parts LLC) in the ISE automation lab. These machines are quite old and do not have any features for data access, analysis or planning via a third party application.
Figure 15: CT2000 Chip Sorting Machines
indicated by the red circle. The cameras detect the original and the final required orientation of the chips and send a signal to the head to reorient them if required. Once done, the head goes and places the chips in a tray on an incoming conveyor. This process goes on till all 16 chips are placed and the conveyor then releases the tray.
Figure 16: Cameras working with Vacuum Gripper to sort chips
visualized using a custom built GUI in GLADE-VTK. The implementation can be shown in a simple flow chart as shown below:
Figure 17: Data Flow in the VMM
Using the app built (shown in Figure 18), we can now visualize the data from the machine for analysis of idle times of the machine, mean time between failure and time taken by the cameras for analysis of the chips in the machine.
CHAPTER 6
CONCLUSIONS AND FUTURE WORK 6.1. Summary
Streaming data from machines comprise an important feature that enriches CPS in manufacturing. While many machine to machine communication protocols and standards are in development across the discrete and continuous manufacturing space, the architecture must adapt to making it interoperable as much as possible. We have followed an architecture stack similar to the software architecture in smartphones (iOS and Android) and the Software Defined Networking (SDN) built to communicate over the internet [75]. Constructing stacked software layers is critical to the wide scale adoption of CPS systems in manufacturing and would make third-party software development easier.
transcend any machine type. The intent of the VMM is not to replace a controller for the machine but rather to complement its capabilities and have a silent system that listens and records events carried out by the machine. While we have proposed an initial architecture, it will require significant amount of work to build an entire ecosystem of hardware drivers and adaptors accompanied by an extensive generic access library to cover all the tools required. Machine vendors will need to be actively involved in writing software adaptors for their machines to help fully implement the cyber-physical manufacturing system architecture.
6.2. Future Work
various components of the machine would be critical to offers levels of abstraction to third-party software developers. The library of API level functions implemented in GMAL would be further extended to offer the level of usability depending on the user type (such as an app developer/end-user) and manufacturing context.
Further, questions arise on where this data should be stored, whether at the machine itself, at the factory level or at the cloud level. Latest fog computing protocols that bridge both edge and cloud computing infrastructure make it extremely attractive to store portions of this data across the cyberinfrastructure [76]. Cloud computing in manufacturing is seen as a vital technology to expand the use of computational resources beyond the capacity of individual manufacturers [77]. VMMs can be a critical piece of technology to enable the data analytics that can be performed on large sets of historic data critical for machine health monitoring and maintenance applications. More work needs to be done to explore manufacturing data organization and how best it must be served to client applications that request this data with value of this data to be of top concern. Exploring technologies that couple MongoDB with latest data mining infrastructures such as Apache Spark or Hadoop [78] also increases the potential of VMM in the cybermanufacturing space.
machine, custom software will be required to analyze the process data locked into the multiple log files generated between scheduled maintenance interval times. The data to be analyzed will be in the multiple terabyte data block sizes, requiring facilities to manage computing hardware to crunch and analyze through the data. In some instances, production scale AM machines archive the data or portions of it are deleted after a production run is completed. For example, when metal additive manufacturing machines are coupled with x-ray image capture technology, data can easily span terabytes. This image based data is deleted at the end of a fabrication resulting in valuable data being lost. Therefore, we do require efficient methods of storing unstructured data to help analyze and compute across the data generated during the part fabrication process.
of various types need to interact. The control layer must encapsulate verification/validation algorithms and communication handling protocols. This work did not utilize the Control layer since we have not connected multiple VMMs together for any coordinated control action. More work is yet to be done in this space and will require significant community effort to build an operating system that spans various factory systems.
The VMM paradigm presented here focuses on a stacked architecture for ease of implementation on the shop-floor while maintaining interoperability and scalability. Rather than forcing third-party software developers to deal directly with the intricacies of physical machine infrastructure, the stacked VMM platform handles lower level functionality and allows developers to build app instances using API libraries. By doing so, VMM enables broader ease of implementation into a distributed manufacturing problem, with two foci area – at the highest level, developers can focus on building applications for the digital thread, while at the lower level, machine developers can focus on building drivers that interface with the VMM middleware.
chip sorting machines. This concept of building apps through a middleware can be extended to any type of machine.
REFERENCES
1. Vijayaraghavan A., Huet L., Dornfeld D.A., Sobel W., Blomquist B., Conley M., Addressing process planning and verification issues with MTConnect, Transactions of the North American Manufacturing Research Institution of SME, 2009; 557-564 2. Hannelius, T., Salmenpera, M., & Kuikka, S., Roadmap to adopting OPC UA., 6th
IEEE International Conference on Industrial Informatics, 2008; 756-761.
3. Hunkeler, U., Truong, H. L., & Stanford-Clark, A., MQTT-S—A publish/subscribe protocol for Wireless Sensor Networks, 3rd international conference on
Communication systems software and middleware 2008; 791-798. 4. Kim D.B., Witherell P., Lipman R., Feng S.C., Streamlining the additive
manufacturing digital spectrum: A systems approach, Additive manufacturing 2015; 5: 20-30
5. Gao R., Wang L., Teti R., Dornfeld D., Kumara S., Mori M., Helu M., Cloud-enabled prognosis for manufacturing, CIRP Ann Manufacturing Technlogy 2015; 64(2): 749– 772.
6. Moyne J., Iskandar J., Big Data Analytics for Smart Manufacturing: Case Studies in Semiconductor Manufacturing, Processes 2017, 5(39); doi:10.3390/pr5030039
7. Chen H., Chiang R.H.L., Storey V., Business intelligence and analytics: from big data to big impact, MIS Quarterly 2012; 4 (36): 1165–1188
9. BITKOM, F. I. (2012). Gesamtwirtschaftliche Potenziale intelligenter Netze in Deutschland. Berlin & Karlsruhe.
10. CATERPILLAR AND THE INTERNET OF BIG THINGS. (2015, October 15). Retrieved from
http://www.caterpillar.com/en/news/caterpillarNews/innovation/caterpillar-disrupted.html
11. Baldwin, J. R., & Rafiquzzaman, M. (1998). The determinants of the adoption lag for advanced manufacturing technologies.
12. Ferreira, J., de Beca, M. F., Agostinho, C., Nunez, M. J., & Jardim-Goncalves, R. (2013). Standard blueprints for interoperability in factories of the future (FoF). IFAC Proceedings Volumes, 46(9), 1322-1327.
13. Anderson, A. (2011). Report to the President on Ensuring American Leadership in Advanced Manufacturing. Executive office of the President.
14. Huang, S., Chen, Y., Chen, X., Liu, K., Xu, X., Wang, C., ... & Halilovic, I. (2014, June). The next generation operational data historian for iot based on informix. In Proceedings of the 2014 ACM SIGMOD international conference on Management of data (pp. 169-176). ACM.
16. Gilbert S.,and Lynch N., Brewer's Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services, 2002, ACM SIGACT News, 2001; 33(2): 51-59.
17. Chryssolouris, G. Manufacturing systems – theory and practice, 2nd edition, 2006 (Springer-Verlag, New York)
18. Chryssolouris G, Mavrikios D, Papakostas N, Mourtzis D, Michalos G, Georgoulias K (2008) Digital manufacturing: history, perspectives, and outlook. J E
19. Chen, D., Heyer, S., Ibbotson, S., Salonitis, K., Steingrímsson, J. G., & Thiede, S. (2015). Direct digital manufacturing: definition, evolution, and sustainability implications. Journal of Cleaner Production, 107, 615-625.
20. Gibson, I., Rosen, D. W., & Stucker, B. Additive Manufacturing Technologies Rapid
Prototyping to Direct Digital Manufacturing. 2010.
21. Beckmann, B., Giani, A., Carbone, J., Koudal, P., Salvo, J., & Barkley, J. (2016). Developing the digital manufacturing commons: a national initiative for US manufacturing innovation. Procedia Manufacturing, 5, 182-194.
22. Helu, M., Hedberg, T., & Feeney, A. B. (2017). Reference architecture to integrate heterogeneous manufacturing systems for the digital thread. CIRP Journal of Manufacturing Science and Technology.
![Figure 1: Representation of a Digital Thread [23]](https://thumb-us.123doks.com/thumbv2/123dok_us/1338303.1166807/24.612.143.492.389.618/figure-representation-digital-thread.webp)
![Figure 2: Different Aspects of Cyber Physical Systems [39]](https://thumb-us.123doks.com/thumbv2/123dok_us/1338303.1166807/29.612.93.537.219.529/figure-different-aspects-cyber-physical-systems.webp)
![Figure 3: Traditional Automation vs CPS enabled automation [47]](https://thumb-us.123doks.com/thumbv2/123dok_us/1338303.1166807/35.612.120.547.75.275/figure-traditional-automation-vs-cps-enabled-automation.webp)