Automated Alignment in Multilingual Corpora
10
0
0
Full text
Figure


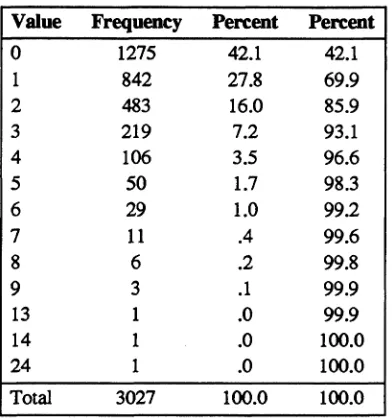
Related documents
We described a simple approach to comparable sentence alignment, termed STACC , which is based on automatically extracted seed lexical transla- tions, the Jaccard
In multilingual topic models, “knowl- edge” refers to word distributions for a topic in a language ` , and we study how multilingual topic models transfer this knowledge from
nmnipulate and analyse text corpora and to create multi- lingual text corpora with structural and linguistic markt, p. It will attempt to establish conventions for
Texts from comparable corpora, as opposed to parallel corpora, contain a great deal of “noise.” In Figure 2 which plots the manually identified align- ment for a text pair in
3 Latent Domain HMM Alignment Model Because the heterogeneous data contains a mix of diverse domains, the induced statistics derived from word alignment models reflect
