TD-SIGNET: COMMUNITY MINING
WITH WSD BASED ON IMPLIED
GRAPH STRUCTURE IN SOCIAL
NETWORKS
Mr.S.BALAJI*,
*M.Tech (IT), Information Technology Department, KSR College of Technology, Tiruchengode, India
+0-91-9942577794, [email protected]
Ms.S.SASIKALA**
**Assistant Professor, Computer Science Department, KSR College of Arts and Science, Tiruchengode, India
+0-91-9942333764,[email protected]
Abstract:
Social networks on the web are growing dramatically in size and number. The huge popularity of sites like MySpace, Face book, and others has drawn in hundreds of millions of users, and the attention of scientists and the media. The public accessibility of web-based social networks offers great promise for researchers interested in studying the behavior of users and how to integrate social information into applications. Discovering communities from a graph structure such as the Web has become an interesting research problem recently. In this paper, comparing with the state-of-the-art authority detecting and graph partitioning methods, we propose a new model to more accurately define communities.We conduct a case study to automatically discover similar interest groups (SIGNET) with taxonomy-driven (TD-SIGNET) structure in the computer science domain from the Web along with word sense disambiguation (WSD). Experiments show that our method is very effective to generate high-quality communities with more clear structure and more tunable granularity.
Keywords: Authority, DBLCSPAMCLUST, HITS, Hub, Link spam, Content spam, PageRank, Search engine.
1. Introduction
Social Networking is one of the biggest trends on the web, with hundreds of millions of people participating. While social interaction and community organization on the web is not new, the scale at which people are forming explicitly social connections in public forums is unique to social networks in the last couple years. There are hundreds of web-based social networks. Some websites are dedicated specifically to social networking (e.g. Face book, Friendster, and MySpace), while others support social networks, but they are secondary to other features and purposes (e.g. YouTube, Spout, and Tickle). Their purposes vary from religious to political to entertainment, and membership in a given network can be as small as a few dozen users to over 100,000,000. Thirteen social networks were included in this study, ranging from small (about 1,000 members) to very large (over 10,000,000 members). Where available for each network, we gathered statistics on total membership, day-to-day changes in the size and relationships, and activity patterns for each user.
2. Social networks in web and usage limitations
networking services fully as an infrastructure of disseminating and sharing information. In the absence of such a system, a user would feel unsafe and would therefore be discouraged from disseminating information.
2.1.Communities in social networks
Many communities, either in an explicit or implicit form, have existed in the Web today, and their number is growing at a very fast speed. Discovering communities from a network environment such as the Web has become an interesting research problem recently. Network structures like the Web can be abstracted into directional or non-directional graphs with nodes and links. It is usually rather difficult to understand a network’s nature directly from its graph structure, particularly when it is a large scale complex graph. Data mining is a method to discover the hidden patterns and knowledge from a huge network. The mined knowledge could provide a higher logical view and more precise insight of the nature of a network, and will also dramatically decrease the dimensionality when trying to analyze the structure and evolution of the network. Information extraction from social networks and web2.0 scenario would be mentioned in figure 1.
Figure 1: Information extraction from web 2.0
3. Related work
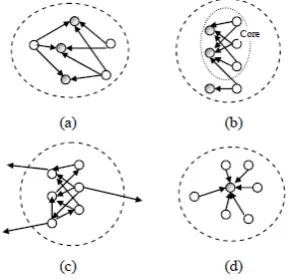
Quite a lot of work has been done in mining the implicit communities of users, web pages or scientific literature from the Web or document citation database using content or link analysis [4, 5, 6, and 7]. Several different definitions of community were also raised in the literature. In [5], a web community is a number of representative authority web pages linked by important hub pages that share a common topic as shown in Figure 2(a). In [6], a web community is a highly linked bipartite sub-graph and has at least one core containing complete bipartite sub graph as shown in Figure 2(b). In [4], a set of web pages that linked more pages in the community than those outside of the community could be defined as a web community (see Figure 2(c)). Also, a research community could be based on a single most-cited paper and contain all papers that cite it [7] (see Figure 2(d)).
Figure 2: Community formation – possible structures
methods, authoritative resources finding [5, 7, 8, 9] and graph structure partitioning [6, 4] are the two major clustering methods currently widely used in community mining. Using these clustering methods to identify communities has several shortages. First, objects in a cluster are not ranked. Secondly, clusters are not allowed to overlap. That is, one object generally can only belong to one cluster. Thirdly, the similarity between objects is required to be measured by some explicit functions, which are usually hard to define. In this paper, we develop a new method based on our proposed taxonomy-driven model to automatically discover communities in a complex graph structure. This method overcomes the above shortages and has proved to be effective from our experiments. This method could generate understandable communities with more clear structure and tunable granularity.
4. Proposed model
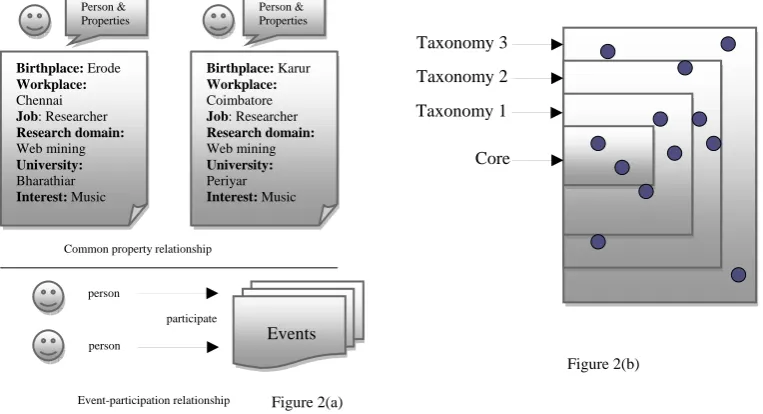
The system enables users to analyze their social network to provide awareness of the information dissemination process within the social network. Using social relationships and the results of social network analyses, users can decide who can access their information. Currently, the proposed system is applied to an academic society because researchers have various social relationships (e.g., from a student to a professor, from a company to a university) through their activities such as meetings, projects, and conferences. Importantly, they often need to share various information such as papers, ideas, reports, and schedules. Sometimes, such information includes private or confidential information that ought only to be shared with appropriate people. In addition, researchers have an interest in managing the information availability of their social relationships. The information of social relationships of an academic society, in particular computer science, is easily available online to a great degree. Such information is important to obtain social networks automatically. Generally the common property relationship and event participation relationship may exist and here in this paper the common property “Area of Expertise” between persons and event participation “Research papers” are taken into consideration illustrated in figure 3(a). The taxonomy model is depicted in figure 3(b). If the core in figure 3(b) indicates “data mining” then the taxonomy 1 may have web mining, text mining, link mining etc and if the taxonomy 2 indicates “web mining” means then taxonomy 2 may have web structure mining, web content mining etc. This is how the TD model works out in given scenario.
Figure 3(a): Relationship which social network contains 3(b): Taxonomy-based model
The most important objects representing the concept of a whole community lie in the center and are called core objects. Affiliated taxonomy objects, which are related to the core objects, surround the core with different ranks.With this model, a community is defined as a four-tuple <CR, TA, FN, Va>. CR denotes the core object set; TA denotes the affiliated taxonomy object sets; FN is the affiliation definition function measuring two objects x and y, and will return a positive value if x is affiliated by yVa is the importance vector for TA to measure the affiliating degree for every object in TA to the core.
5. Community Mining
Based on the above taxonomy-based model, the goal of community mining is to discover object sets conforming to this model from a graph. This algorithm is initially applied to the academic community as
Common property relationship
Birthplace: Erode Workplace: Chennai Job: Researcher Research domain: Web mining University: Bharathiar Interest: Music Birthplace: Karur Workplace: Coimbatore Job: Researcher Research domain: Web mining University: Periyar Interest: Music Person & Properties Person & Properties person person participate Events
Event-participation relationship Figure 2(a)
Core Taxonomy 1 Taxonomy 2 Taxonomy 3
mentioned in section 3. Some terms and definitions regarding forming the graph on social network are as follows.
5.1.Characterization of the social-networks
For our analysis, we have considered a number of parameters characterizing the topology of the networks. Degree of a vertex (k): number of edges connected to that vertex. In the case of commiter networks, for each commiter it represents the number of companion commiters, contributing to the same modules as the given one.
Weighted degree of a vertex: sum of the weights of all edges connected to that particular vertex. This can be interpreted as the degree of relationship of a given vertex with its direct neighborhood.
Distance centrality of a vertex (Dc): proximity to the rest of vertices in the network. It is also called closeness centrality: the higher its value, the closer that vertex is to the others (on average). Given a vertex v and a graph G, it can be defined as:
(1)
Betweenness centrality of a vertex: The betweenness centrality of a vertex Bc is a measurement of the number of shortest paths traversing that particular vertex. Given a vertex v and a graph G, it can be defined as:
(2)
Clustering coefficient of a vertex: The clustering coefficient c of a vertex measures the connectivity of its direct neighborhood. Given a vertex v in a graph G, it can be defined as the probability that any two neighbors of v be connected. Hence
(3)
Weighted clustering coefficient of a vertex: The weighted clustering coefficient cw of a vertex is an attempt to generalize the concept of clustering coefficient to weighted networks. Given a vertex v in a weighted graph G it can be defined as:
(4)
5.1 Algorithm TD-SIGNET
An algorithm about how to use (m-1)-item sets to generate m-item sets orderly is described in [2]. Below is the pseudo code of finding frequent item sets.
Generate 1-itemsets IS1 with minimal support S k _ 2
while k _ m do //generate up to m-itemsets, m is the length of the longest itemset
Generate k-itemsets ISk using (k-1)-itemsets IS(k-1) with S
Prune IS (k-1) using ISk k _ k +1
end
Put IS1 to ISm to itemsets set IS
for every itemset I in IS Put objects in I to community C
do
Add objects not in C but having links to objects in C to C
Calculate ranking value of new added objects
until No more objects could be added Put a copy of C to communities set CS Clear C
End
In this algorithm, the support threshold S is used to denote the minimal support needed to put objects in an item set. Once core sets are found, they can be expanded to produce complete communities. The basic idea is to use these core sets as initial communities, and then get affiliated objects according to the core’s in-links and add them to the communities. This process is performed iteratively until no more objects could be added to any communities. If we want to distribute affiliated objects into multiple outer circles, local hub values of these affiliated objects are calculated as the ranking and differentiating criteria. The pseudo code of this expanding phase has been given in figure 4. Considering the named entity Disambiguation in TD-SIGNET could lead to the sensible result offering. The reason of why should this task to be considered has been given as follows with example illustration. Named Entity Disambiguation associates names with entities that are predefined in an external repository. Building a comprehensive repository of entity definitions can be a very complex and laborious endeavor. For example, in the more general problem of Word Sense Disambiguation (WSD), a traditional source of sense definitions is WordNet (Fellbaum, 1998) – an “electronic lexical database” that has taken many person years to develop. The ranking function that is evaluated experimentally is Based on the TF-IDF cosine similarity between the context of the query and the text of the entity’s article:
. .
( , ) cos( . , . )
. .
q T e T score q e q T e T
q T e T
= =
The factors q.T and e.T are represented in the standard vector space model, where each component corresponds to a term in the vocabulary, and the term weight is the standard TF-IDF score (Baeza-Yates & Ribeiro-Neto, 1999).
Consider the named entities mayilsamy(scientist) and mayilsamy(film actor) One query q, characterized by the following fields:
q.name = “Mayilsamy ′′; q.E = {e1, e2};
q.e = e1;
and q.T = {“Mayilsamy′′, “last′′, “year′′, “launched′′, “satellite′′, “chandirayan′′...}.
The word-category features from the feature vector (q, e) have binary values that depend on the text of the query q (i.e. q.T) and the categories (immediate and ancestor) to which the entity e belongs (i.e. the set e.C).Thus the predictions were made in here.
The word-category features from the feature vector (q, e) have binary values that depend on the text of the query q (i.e. q.T) and the categories (immediate and ancestor) to which the entity e belongs (i.e. the set e.C).Thus the predictions were made in here.
The first feature vector
φ
(q, e1):• φw,c(q, e1) = 1 for hw, ci ∈{{launched, scientist}, {launched, people},……}
The second feature vector
φ
((q, e2)):φw,c(q, e2) = 1 for hw, ci∈ {{launched, program}, {launched, film} ...,}
6. Experiments
This application is on building a social network among persons and area of expertise by extracting their relationship from crawled WebPages. Therefore, in this experiment, the two most important named entities considered are PERSON_NAME and AREA_OF _EXPERTISE. The WebPages used in the experiments are crawled from academic sites and institution websites. In order to better show the effectiveness of the proposed framework, it is only selected some WebPages containing multiple mentions of the same entity. These pages include biography and personal homepages. It is randomly sampled 25 pages for training and 100 pages for testing. In this experiment, we only compared the results from the traditional named entity recognition algorithm with SIGNET [1] and TD-SIGNET. The simulated results are shown in Figure 6 (a,b,c).
Figure 5: Communities related to “Data Mining” retrieved with TD-SIGNET
Figure 6(a): Community detection Figure6(b): Crawled result of academic Figure6(c): Relationship
Community (Data Mining) of TD-SIGNET Analyzer
7. Conclusion
We introduced a mining algorithm to automatically generate communities from a graph. Experiments on a documents citation database showed that our algorithm is solid and effective. It could find communities of adaptive granularity. Currently it is only applied that the TD-SIGNET model and mining algorithm to discover interest groups from paper citation database. Since this is a general method that could potentially be used in any application scenarios where the data can be abstracted to a graph structure, we prepare to test its usefulness in other environments such as human relationship network, newsgroups, communication network, etc. We also plan to analyze the evolution of communities. Since deriving graph communities to lay down the relationship
Similar interest groups of researchers:
Data mining
Data mining Authors Social network
page
Graph: Crawled the social network to reveal the TD
Crawled from academic website
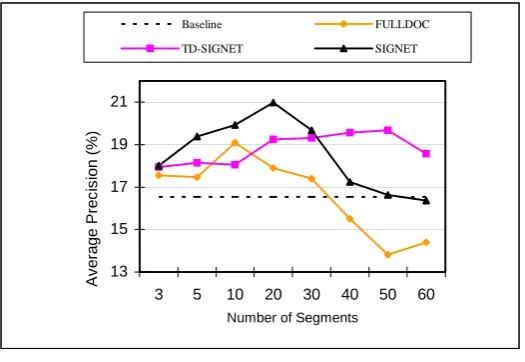
could yield greater benefits. The comparison of the results with the baseline method, FULLDOC method and SIGNET has been given in figure 7.
Figure 6(a): Performance Comparison of the proposed algorithm
Since the objects and links in a network are usually dynamic, we could observe the communities and their changes in a time series manner based on the temporal nature. The usefulness of the social networks is very vital as we could see that in the Japan earthquake at 2011.
References
[1] S.Sasikala, S.Balaji, "SIGNET: Web Information Retrieval with NE Disambiguation Based on HMM and CRF”, Proc. , 2011 3rd International Conference on Machine Learning and Computing (ICMLC 2011), Singapore, IEEE Xplore, CFP1127J-PRT, ISBN: 978-1-4244-9252-7, 2011
[2] S.Sasikala, Dr.S.K.Jayanthi “Hyperlink Structure Attribute Analysis for Detecting Link Spamdexing “ International Conference on Advances in Computer Science – (AET-ACS 2010), Kerela, (Available in Engineers Network Search Digital Library), 2010. [3] S.Sasikala, “An archetype for web mining with enhanced topical crawler and link spam trapper” National conference on advanced
computing’2010, Coimbatore (ISSN no : 0975-0290).
[4] Gary William Flake, Steve Lawrence, C. Lee Giles, Efficient Identification of Web Communities, in Proceedings of the 6th International Conference on Knowledge Discovery and Data Mining (ACM SIGKDD-2000), 2000
[5] David Gibson, Jon Kleinberg, Prabhakar Raghavan, Inferring Web Communities from Link Topology, in Proceedings of the 9th ACM Conference on Hypertext and Hypermedia, 1998
[6] Ravi Kumar, Prabhakar Raghavan, Sridhar Rajagopalan, Andrew Tomkins, Trawling the web for emerging cybercommunities, in Proceedings of The 8th International World Wide Web Conference, 1999
[7] Alexandrin Popescul, Gary William Flake, Steve Lawrence, Lyle H. Ungar, C. Lee Giles, Clustering and Identifying Temporal Trends in Document Databases, in IEEE Advances in Digital Libraries, ADL 2000
[8] Chaomei Chen, Les Carr, Trailblazing the Literature of Hypertext: Author Co-Citation Analysis (1989-1998), in Proceedings of the 10th ACM Conference on Hypertext and hypermedia: returning to our diverse roots, 1999
[9] David Cohn, Huan Chang, Learning to Probabilistically Identify Authoritative Documents, in Proceedings of the 17th International Conference on Machine Learning, 2000
Bibliographical Notes
Balaji Subramani Pursuing the M.Tech (IT) in K.S.Rangasamy College of Technology has received the B.E (CSE) from the Anna University in 2009. He has presented 3 papers in International Seminars and among them 2 has been presented in Singapore, Malaysia (published in IEEE Xplore), and 6 papers in national seminars and has a total of 8 publications. And participated in various symposiums and workshops held at different places. His area of interest includes Word sense disambiguation, web mining, Information retrieval and social network analysis.
S.Sasikala, currently working as an Asst. Prof. in Department of Computer Science in K.S.R. College of Arts & Science and has received the B.Sc(CS) from the Bharathiar University, M.Sc(CS) from the Periyar University, M.C.A. from Periyar University , M.Phil from Periyar University, PGDPM & IR from Alagappa university in 2001, 2003, 2006, 2008 and 2009 respectively. And she is currently pursuing her Ph.D in computer science at Bharathiar University. Her area of Doctoral research is Web mining. She secured University First Rank in M.Sc(CS) Programme under Periyar University and received Gold Medal from Tamilnadu State Governor Dr.RamMohanRao in 2004. She has published 3 papers in International Journals (IJACST, IJNGN, IJANA) and refereed 2 International Journals IJNGN and JEEER. She has
13 15 17 19 21
3 5 10 20 30 40 50 60
Number of Segments