Data Mining over Textual Data
Mandar S. Kale
Engineering and Industrial Services Tata Consultancy Services (TCS),
1, Mangaldas Road, Pune 411001, India.
Tel.:56042177 [email protected]
Girish K. Palshikar
Tata Research Development andDesign Centre (TRDDC), 54B, Hadapsar Industrial Estate,
Pune 411013, [email protected]
Sachin Chhajed, Laxmi Deshpande
Decision Systems InitiativeTata Research Development and Design Centre (TRDDC),
54B, Hadapsar Industrial Estate, Pune 411013, India. . [email protected]
ABSTRACT
Data mining techniques have been widely used in many different domains to discover valuable knowledge hidden inside structured databases. In this paper, we propose an approach to discover knowledge hidden inside records having textual data. We present a case study illustrating how useful knowledge could be automatically discovered in the maintenance records for diesel engines. The input database consisted of maintenance records for diesel engines. Each record contained textual data about the problem, its causes and remedial (repair) actions carried out. Information extraction (text mining) techniques were used to convert this unstructured text data into a structured text form. We then applied data mining techniques – such as association rule mining and sequence mining – to extract useful knowledge about maintenance problems and repairs. For example, we discovered some maintenance-related dependencies among various engine components, e.g., {air conditioner compressor, air conditioner condensor, charge air} ==> {bracket, cooler}. We also discovered that for the same engine problem (e.g., noise in engine), different sequences of repair actions were followed by different maintenance personnel. We discuss how this discovered knowledge could be re-used to improve the maintenance process (e.g., to reduce costs or efforts). We have included a description of the methodology followed and the results obtained.
1.
INTRODUCTION
Every organisation contains a huge amount of data in the unstructured form (e.g. in the form of reports, logs, emails, documents, and even text fields in database records). Particularly in service organizations, e.g., call centres, automobile maintenance centers etc., a lot of transactional data is generated in form of:
• Structured data: information about costs, time, persons,
components etc.;
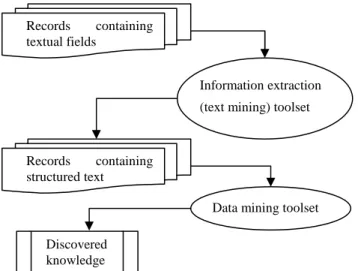
• Unstructured data: Problem Resolution logs (voice or text) The field of data mining (also known as knowledge discovery in databases) contains a wide variety of techniques that discover various types of useful knowledge hidden inside given structured databases. However, data mining techniques usually do not work with unstructured data such as text. But a huge amount of useful experience is hidden in unstructured data. So it is important to see how useful knowledge could be discovered in this unstructured textual data. In this paper, we propose a 2-step approach for handling this problem (Figure 1). In the first step, we use information extraction (text mining) techniques to convert unstructured text data into a structured text form. In the second step, we apply data mining techniques – such as association rule mining and sequence mining – to extract useful knowledge from this structured text data. We present a case study illustrating the approach where we demonstrate how useful knowledge could be automatically discovered in the textual maintenance records for diesel engines.
Figure 1. Approach to combine text mining and data mining. Permission to make digital or hard copies of all or part of this work for
personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee.
TACTiCS – TCS Technical Architects’ Conference’05
Records containing textual fields
Information extraction (text mining) toolset
Records containing structured text
Data mining toolset Discovered
The first step of converting given unstructured text data to structured text data was performed using the information extraction (text mining) tools developed within the Decision System Initiative at TRDDC, Pune. The data mining step was performed using the Knowledge-Discovery Toolset (KDTOOL) developed in the Machine Learning Group in TRDDC, Pune. For the sake of brevity, this paper focuses on the second step, where we explain how to apply various Data Mining techniques, such as association rule mining, clustering, outlier analysis, and sequence mining, to this structured data to extract hidden patterns or dependencies. The text analysis step is quite complex and deserves a separate paper.
The specific domain we studied is mining of text data related to maintenance of diesel engines. The knowledge extracted from maintenance records can be used later for various purposes:
• analysis, simplification and optimisation (e.g., for cost or time) of maintenance procedures
• representation of best practices for maintenance (e.g., as rules or fault trees)
• training of maintenance personnel in best practices
• root cause analysis of frequent, complex, or expensive problems
• reducing component replacements
• improvements in product manufacturing and design, etc. Section 2 gives an idea about the work done in the area of data mining. Section 3 gives an idea about conversion of unstructured text to structured text. Application of Data Mining techniques to structured text is explained in sections 4 and 5. Section 6 gives an understanding of the results and scope for future work is highlighted in section 7.
2.
RELATED WORK
Data mining is a rapidly emerging field designed to analyze a vast amount of data gathered from applications. A good introduction to various data mining techniques is given in [9]. Association rule mining, as originally proposed in [1] with its apriori algorithm, has developed into an active research area. Many additional algorithms have been proposed for association rule mining [4, 8, 11]. An efficient algorithm for sequence mining is discussed in [12]. An introduction to various text mining algorithms is given in [8]. A survey of various interestingness measures for the discovered knowledge is given in [6].
Data Mining has been applied to a variety of fields [5] including fraud detection, investment analysis, portfolio trading, marketing, and sales. The algorithm given in [12] was used for the analysis of plan database to set alarms to predict plan failures.
3.
TEXT TO STRUCTURED DATA
3.1
Input Data
The input database consisted of maintenance records for diesel engines. Each record contained textual data about the problem, its causes and remedial (repair) actions carried out. Each record in this text data describes a specific instance of maintenance (servicing) of a particular diesel engine. The record contains the following information in text form:
• Problem note: problem description (e.g., symptoms) for a specific diesel engine
• Cause note: diagnosis of the reported problems including the causes and faulty components
• Correction note: sequence of repair (or remedial) actions carried out to correct the problems; e.g., component replacements
Figure 2 shows a sample record.
Problem Note:
NOISE IN ENGINE, REPLACE CYLINDER BLOCK
Cause Note:
CONNECTING ROD SPLIT IN THE BEAM AT THE OIL
DRILLING #7LB. SPLIT ROD FAILURE
PREOGRESSIVELY DAMAGED CYLINDER BLOCK CASTING AND CRANKSHAFT BEYOND SALVAGE (DAMAGED #13 COUNTER. WEIGHT AND MOUNTING SURFACE). FOUND #7 R.B. HAD A DROPPED VALVE IN DRC HEAD THAT WAS NOT VISIBLE BEFORE
ENGINE WAS COMPLETELY DISASSEMBLED.
OBSERVED PROGRESSIVE DAMAGE TO THE PISTON AND # 7 L.B. ROD AND LINER AS A RESULT OF THE ROD FAILURE.
Correction Note:
STEAM CLEANED LEFT BANK OF ENGINE AND BROUGHT INTO SHOP. REMOVED SIDE COVER PLATE.
REMOVED ROD FROM BLOCK AND REMOVED CRANK.
REMOVED CYLINDER HEAD FOR WARRANTY
INSPECTION. DISASSEMBLED ENGINE TO REPLACE CYLINDER BLOCK AND CRANKSHAFT. DISASSEMBLED HIGH PSI REG. CLEANED AND REASSEMBLE. DISSASSEMBLED LUBE PUMP AND FOUND METAL DAMAGE TO BUSHINGS. TAGGED FOR WARRANTY AND REASSMBLED. INSPECTION OF LOW PSI TURBOS FOUND ROTOR DAMAGE TO ONE, THE OTHER WAS OKAY. TAGGED DAMAGED TURBO FOR WARRANTY AND PUT IN CORE BIN.
REBUILT TWO UPPER ROCKERS AND ONE CAM FOLLOWER. CLEANED BLOCK. INSTALLED OIL COOLERS, NEW CRANKSHAFT, AND. ASSEMBLED PISTONS AND INSTALLED. COMPLETED REASSEMBY OF ENGINE. DYNO TESTED.
Figure 2. A sample maintenance record (record ID = 3)
3.2
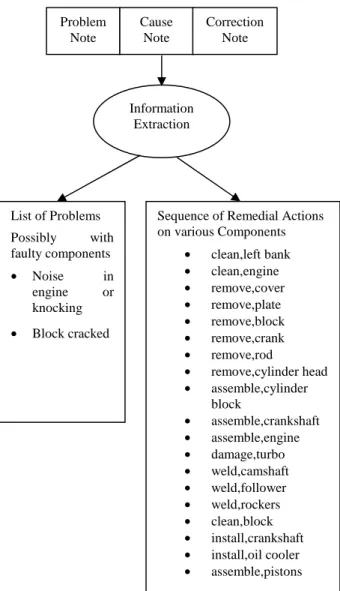
Conversion to Structured Text
Figure 3. Converting maintenance record text to structured form
Figure 4 shows the structured record obtained from the textual maintenance record shown in Figure 2.
Figure 4. Structured record obtained from text record in Figure 2.
Each Problem, each Component and each Remedial Action is represented by a specific keyword (string). For example, “noise” and “cracked” are Problem keywords; “engine”, “block” are Component keywords; and “assemble”, “weld”, “clean” etc. are Remedial Action keywords.
The extracted information from the record is stored in structured form as database tables (one Problem-component table and the other Remedy-component table). Table 1 is the remedy-component table. In Table 1, the first column indicates record ID of maintenance record ID (sequence ID), the second indicates sentence ID, the third column indicates the remedial action, and the fourth column indicates the component on which remedy was performed. For example, the first row of Table 1 indicates that for the record in Figure 2, in the first sentence (event), remedial action “clean” was performed on component “left bank” (3rd and 4th column of Table 1). Table 2 shows the problem-component table for the record in Figure 2. Note that both Table 1 and Table 2 show data for only one input maintenance text record (record in Figure 2).
Table 1: Remedy-Component Table for Record in Figure 2.
Record ID (Seq. Id)
Sentence ID (event id)
Remedial Verb
Component
3 1 clean left bank
3 1 clean engine
3 2 remove cover
3 2 remove plate
3 3 remove block
3 3 remove crank
3 3 remove rod
3 4 remove cylinder head
3 5 assemble cylinder block
3 5 assemble crankshaft
3 5 assemble engine
3 11 damage turbo
3 13 weld camshaft
3 13 weld follower
3 13 weld rockers
3 14 clean block
3 15 install crankshaft
3 15 install oil cooler
3 16 assemble pistons
Table 2. Problem-Component table for for Record in Figure 2.
Record ID (Seq. Id)
Sentence ID (event id)
Problem Verb
Component
3 1 knocking engine
3 1 cracked block
After this transformation, data mining techniques can be now applied to this structured data to discover interesting patterns.
4.
ASSOCIATION RULE MINING
4.1
Problem Formulation
Each transaction (also called a market basket) in a super market indicates the items bought by a customer. Given a set of such transactions, association rule mining techniques can discover Information
Extraction
List of Problems Possibly with faulty components
• Noise in
engine or knocking
• Block cracked
Sequence of Remedial Actions on various Components
• clean,left bank
• clean,engine
• remove,cover
• remove,plate
• remove,block
• remove,crank
• remove,rod
• remove,cylinder head
• assemble,cylinder block
• assemble,crankshaft
• assemble,engine
• damage,turbo
• weld,camshaft
• weld,follower
• weld,rockers
• clean,block
• install,crankshaft
• install,oil cooler
• assemble,pistons Problem
Note
Cause Note
Correction Note Cause
Note Problem
Note
Correction Note
Information Extraction
List of Problems Possibly with faulty
Components
Sequence of Remedial
dependencies among the items. For example, one may find that whenever a customer buys milk and sugar, quite often he/she also buys tea. Let I = {i1, i2, i3,…..in) be a set of n distinct items. Let T ⊆ I be a transaction. Association rule mining analysis attempts to discover relationships between various items that are present together in a transaction.
We now demonstrate how association rule mining techniques can be applied to the structured data obtained from textual maintenance records. We can think of a maintenance record as a transaction comprising sets of items in various ways as follows. F1. Set of problems or remedial actions
F2. Set of components on which remedial actions are performed F3. Set of components in which some fault (problem) is observed Association rule mining exercise can be done for each of the above market basket formulations to find out interesting dependencies between problems, remedies and components. 1. Associations Rules between Problems and Remedies (formulation F1)
Example: Problem X is frequently resolved by remedies {P and Q} or {S and T and U}
2. Association Rules between Remedies (formulation F1)
Example: Whenever remedies {P and Q} were applied, remedies
{S and T and U} were also applied
3. Association Rules between different components on which some remedial action is performed (formulation F2)
Example: Whenever some Remedies are applied to components {A and B}, some Remedies are also applied to components {C and D and E}.
4. Association Rules between faulty (Problem) components (formulation F3)
Example: Whenever some faults are observed with components {A and B} some faults are also observed with components {C and
D and E}.
In this paper, we illustrate how formulation F3 was used to discover association rules as in (4) above.
4.2
Data Preparation
Data for association rule mining is a subset of the structured data discussed above. Table 3 shows the transactions corresponding to each record; this transaction consists of those components for which some remedial action was performed as per that record. For example, transaction 3 shows the components in the record in Figure 2 for which some remedial action was performed. Other transactions in Table 3 are obtained from maintenance text records not shown in Table 1.
Table 3. Sample transaction database of components on which some remedial actions are done.
Transaction ID
Components on which some remedial actions are done.
1 engine, rod cap, screw 2 engine, block, crank
3 left bank, engine, cover, plate, block, crank, rod, cylinder head, cylinder block,
crankshaft, turbo, camshaft, follower, rockers, oil cooler, pistons
5 piston
6 cylinder block, suction tubes, lube pump, drive
4.3
Data Analysis
Before doing actual association rule mining, let us look at some characteristics to get a deeper understanding about the data (Table 4).
Table 4. Characteristics of Component Transactions.
No of Transactions (Records) 6786
Max. Size of Transaction 51
Min. Size of Transaction 1
Average Size of Transaction 7.47
Standard deviation in the Size of Transaction 6.45 Max. Number of Transactions per Item 2520 Min. Number of Transactions per Item 1 Avg. Number of Transactions per Item 51.36 Standard deviation in the Number of Transactions per item
160.140
4.4
Experimentation and Results
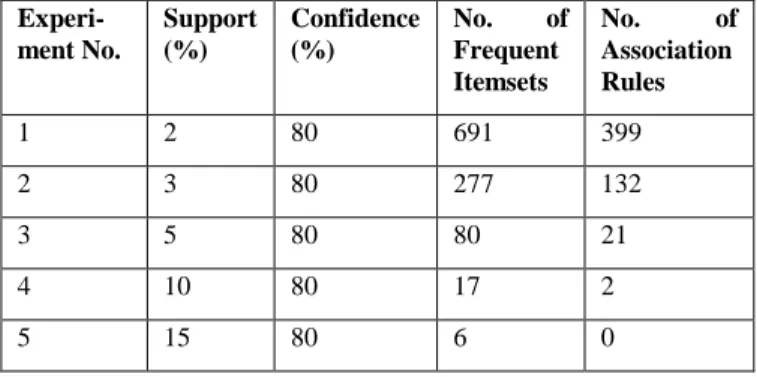
The data mining toolset KD-TOOL developed at TRDDC, Pune contains implementations of several different algorithms, including algorithms for association rule mining. We used the well-known a priori algorithm [2] for association rule mining on the components transactions discussed above. Table 5 summarizes the discovered rules and Table 6 shows some examples of actual association rules that were discovered. We could not find any interesting relationships at higher values of support, but for low support values we could find some association rules with very high (> 99.0%) confidence value.
Table 5. Summary of Discovered Association Rules.
Experi-ment No.
Support (%)
Confidence (%)
No. of Frequent Itemsets
No. of Association Rules
1 2 80 691 399
2 3 80 277 132
3 5 80 80 21
4 10 80 17 2
5 15 80 6 0
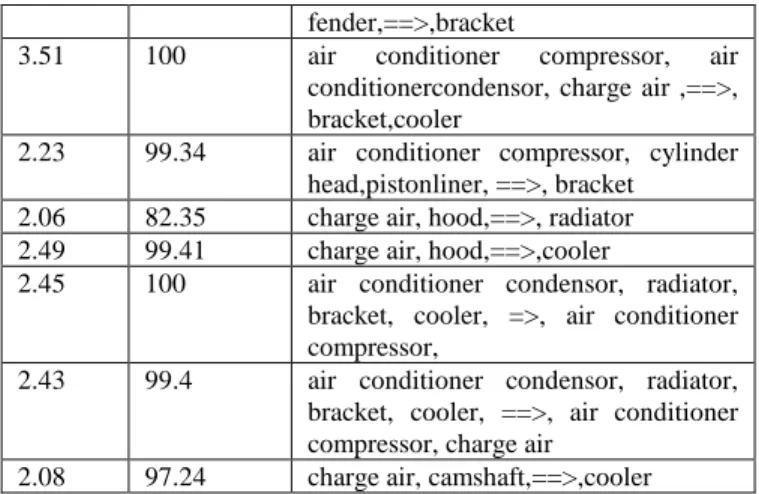
Table 6. Examples of Discovered Association Rules.
Support Confidence Association Rule
11.58 99.75 air conditioner compressor, ==>, bracket
6.23 100 air conditioner condensor, charge air,==>,cooler
fender,==>,bracket
3.51 100 air conditioner compressor, air conditionercondensor, charge air ,==>, bracket,cooler
2.23 99.34 air conditioner compressor, cylinder head,pistonliner, ==>, bracket
2.06 82.35 charge air, hood,==>, radiator 2.49 99.41 charge air, hood,==>,cooler
2.45 100 air conditioner condensor, radiator, bracket, cooler, =>, air conditioner compressor,
2.43 99.4 air conditioner condensor, radiator, bracket, cooler, ==>, air conditioner compressor, charge air
2.08 97.24 charge air, camshaft,==>,cooler The results show interdependencies between various components. For example, for the following association rule
{air conditioner condensor, radiator, bracket, cooler} =>{air conditioner compressor}
the support is 2.45% i.e. all these components co-occur in 166 transactions (out of 6786). Furthermore, the confidence of this rule is 100% i.e. whenever the left side components are present in a transaction, it is 100% true that the components on the right hand side are also present in the same transaction. Thus this association rule indicates a very strong dependence among these components.
5.
SEQUENCE MINING
5.1
Problem Formulation
Various maintenance activities carried out to resolve a particular problem are recorded in a sequential order. This sequential information is also available in the structured data in Table 1 (remedy-component table) and Table 2 (problem-component table).
Let I = {i1, i2, i3,…..in} be a set of distinct items. An event is a
subset of items. A sequence S is an ordered list of events, denoted as <e1, e2, e3,….,em>, where each event ei⊆ I. We consider a
maintenance record as a sequence of events, where each event is a set of remedy actions. Size of an event is the number of remedy actions in it; e.g., size of event {clean left bank, clean engine} is 2. Figure 5 shows example of an input sequence; the events are shown in text boxes and their temporal dependencies are shown by arrows. The first number beside each event is the serial number of that event and the second number is the size of the event. Size of a sequence is sum of the sizes of all events in it; e.g., the size of the sequence in Figure 5 is 21.
Once we transform each maintenance record to a sequence, we can readily apply any of the standard sequence mining algorithms to find out frequent sequences.
5.2
Data Preparation
Data preparation for sequence mining is done as follows:
A unique ID is given to problems, problem-component combinations, remedy-component combinations. Problems in each record are added in sequence table as first event. (event ID of
–10 ensures that the problem is always first event). Table 7 shows one sequence in the sequence table.
Table 7. Sequence of Problem and Remedial actions.
Seq_id (Record no)
Event_id (sentence no)
Item (problem-component, remedy-component, problem, remedy, problem state)
3 -10 6639 (Noise in engine or knocking)
3 -10 6643 (Block cracked)
3 1 2665 (clean,left bank)
3 1 2688 (clean,engine)
3 2 5391 (remove,cover)
3 2 5402 (remove,plate)
3 3 5389 (remove,block)
3 3 5392 (remove,crank)
3 3 5470 (remove,rod)
3 4 5086 (remove,cylinder head)
3 5 1749 (assemble,cylinder block)
3 5 1768 (assemble,crankshaft)
3 5 1809 (assemble,engine)
3 11 448 (damage,turbo)
3 13 6555 (weld,camshaft)
3 13 6564 (weld,follower)
3 13 6583 (weld,rockers)
3 14 2720 (clean,block)
3 15 4069 (install,crankshaft) 3 15 4116 (install,oil cooler)
Figure 5. Example of an input sequence (of Remedial Actions to resolve a particular problem)
Note: Last text box (problem resolved) in Figure 5 is not considered as part of the sequence.
5.3
Data Analysis
We looked at some simple statistical characteristics to get more understanding about the data (Table 8). Sequence Table contains 7500 input sequence. Each sequence is a sequence of events (activities) during problem resolution.
Table 8. Characteristics of Input Sequences
Number of Sequences 7500
Max. Size of Sequence 78
Min. Size of Sequence 1
Average Size of Sequence 12.37
Standard deviation in the Size of Sequence 10.89 Max. Number of Events per sequence 41
Min. Number of Event per sequence 1
Average Number of Events per sequence 7.19
Standard deviation in the Number of Events per sequence
5.41
Max. Number of Sequences per Item 2736
Min. Number of Sequences per Item 1
Average Number of Sequences per Item 13.94 Standard deviation in the Number of Sequences per Item
72.66
5.4
Experimentation and Results
The data mining toolset KD-TOOL developed at TRDDC, Pune contains implementations of several different algorithms, including algorithms for sequence mining. We used the well-known SPADE algorithm [12] for sequence mining on the components transactions discussed above. Table 9 summarizes the discovered frequent sequences. We could not find any frequent sequence at higher values of support, but for low support values we could found some interesting sequences.
Table 9: Experimentation Summary for Sequence Mining Experiment No. Support (%) No. of Frequent
Sequences
1 1 4961
2 2 841
3 3 239
4 5 77
5 10 9
6 15 3
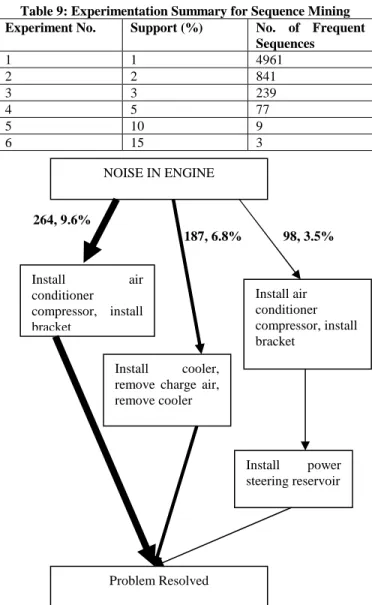
Figure 6. Different paths used to resolve a particular problem. (discovered by sequence mining)
Noise in Engine, Block Cracked
Problem Resolved
Clean Left Bank, Clean Engine
Remove plate, remove cover
Remove Block, remove crank, remove rod
Remove cylinder head
Assemble Block, Assemble Crank Shaft, Assemble Engine
Damage turbo
Weld camshaft, weld follower, weld rockers
Clean Block
Install crankshaft, install oil cooler
Install pistons
1 : 2
2 : 2
3 : 2
4 : 3
5 : 1
6 : 3
7 : 1
8 : 3
9 : 1
10 : 2
11 : 1
NOISE IN ENGINE
Problem Resolved
Install air
conditioner compressor, install bracket
264, 9.6%
Install air conditioner compressor, install bracket
Install power steering reservoir 98, 3.5%
Install cooler, remove charge air, remove cooler
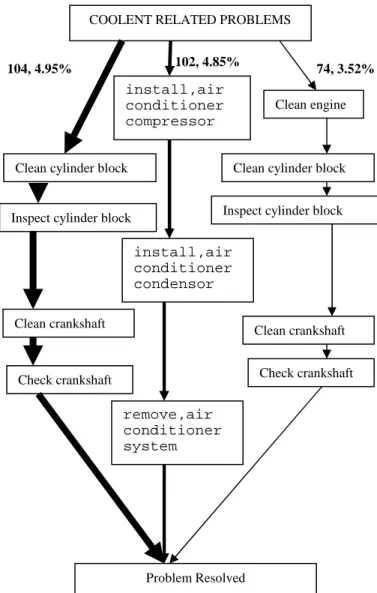
Figure 6 shows different paths to resolve a particular problem. The numbers beside each path indicate frequency and probability of the path respectively. The probability is calculated by dividing frequency by total number of records in which this particular problem is observed (2736 in this case). Similarly, Figure 7 shows different frequent paths followed to resolve coolent related problems.
Figure 7. Different paths used to resolve a particular problem. (Coolant related problems)
6.
UNDERSTANDING THE RESULTS
As seen from these results, in a complex system (comprising thousands of components) there are many reasons for a particular problem. It requires experience to locate and fix the problem, which makes the current maintenance processes manual effort-intensive and person-dependent. In critical cases, resolution of a problem may take a long time even for an experienced person and may end up in unnecessary replacements of costly components. If we can automatically capture the experience from the maintenance records and store it in some reusable and easy to understand structure like fault trees, then this knowledge can be re-used bymaintenance personnel by to improve efficiency, to achieve low replacement costs and to save time, etc.
Thus, if data mining techniques are used in a more focused manner (in consultation with domain experts), the results will improve the understanding of the products under maintenance as well as of the maintenance procedures themselves. This knowledge will help decision-makers to reduce costs, improve product design and optimise maintenance procedures. Specifically, we can use the extracted knowledge for the following tasks:
• analysis, simplification and optimisation (e.g., for cost or time) of maintenance procedures
• representation of best practices for maintenance (e.g., as rules or fault trees)
• training of maintenance personnel in best practices
• root cause analysis of frequent, complex or expensive problems
• reduction of component replacements
• improvements in product manufacturing and design etc.
For achieving these benefits, we need to work on:
• systematically validate the extracted knowledge (obtained using data mining techniques)
• relate the extracted knowledge to product design and maintenance procedure manuals
• incorporate the extracted knowledge in decision-support and business analysis systems
7.
FUTURE WORK
We could use quantitative association rules as well as quantitative sequence mining (sequence mining with multiple attributes) techniques so that we can relate attributes like cost and time to the associations or sequences found. We can also work on converting the output of the data mining into fault trees or rules, which can then be validated and re-used later. We also need a more focused (i.e., problem-specific) formulation, mining and analysis to solve particular problems in engine maintenance. We can also apply other data mining techniques such as clustering and outlier analysis to the output of text mining data. For example, clustering will help us identify groups of similar problems (which require similar remedial actions). Outlier analysis will help us identify unusual or anomalous maintenance procedures that were followed in specific records e.g., outliers may correspond to unnecessary repairs or incomplete repairs.
8.
ACKNOWLEDGMENTS
We like to thank Prof. Mathai Joseph, Executive Director, Tata Research Development and Design Centre (TRDDC) for his support. Special thanks to Dr. Gautam Sardar, Manoj Apte, and other colleagues in TCS and TRDDC for support and useful discussions.
9.
REFERENCES
[1] Agrawal, R., T. Imielinski, A. Swami, Mining Associations between Sets of Items in Massive Databases, Proc. ACM
SIGMOD 1993, pp. 207-216.
COOLENT RELATED PROBLEMS
Problem Resolved Clean cylinder block
104, 4.95% 74, 3.52%
install,air conditioner compressor
102, 4.85%
Inspect cylinder block
Clean crankshaft
Check crankshaft
install,air conditioner condensor
remove,air conditioner system
Clean cylinder block
Inspect cylinder block
Clean crankshaft
[2] Agrawal, R., H. Mannila, R. Srikant, H. Toivonen, and A. I, Verkamo. Fast discovery of association rules. In Advances in
Knowledge Discovery and Data Mining, pages 307–328,
1996
[3] Cohen, E., M. Datar, S. Fujiwara, A. Gionis, P. Indyk, R. Motwani, J. D. Ullman, C. Yang, Finding Interesting Associations without Support Pruning, Knowledge and Data
Engg., vol. 13, no. 1, 2001, pp. 64-78.
[4] Han, J., J. Pei, Y. Yin, Mining Frequent Patterns without Candidate Generation, Proc. ACM SIGMOD 2000.
[5] Hatonen,K., M. Klemettinen, H. Mannila, P. Ronkainen, and H. Toivonen. Knowledge discovery from telecommunication network alarm databases. In 12th Intl. Conf. Data
Engineering, February 1996.
[6] Hilderman, R. J., H. J. Hamilton, Knowledge Discovery and Interestingness Measures: A Survey, Tech. Report CS-99-04, Dept. of Computer Science, Univ. of Regina.
[7] Jurafsky, Daniel, J. H., Martin. Speech and language
processing: An introduction to natural language processing,
computational linguistics and speech recognition, Pearson
Education 2004
[8] Lin, D., Z. M. Kedem, Pincer-Search: An Efficient
Algorithm for Discovering the Maximum Frequent Set, IEEE
Tran. Know. and Data Engg., Vol. 14, No. 3, May/June
2002, pp. 553-556.
[9] Pujari A.K.. Data Mining Techniques, University Press, 2001.
[10] U. Fayyad, G. Piatetsky-Shapiro, and P. Smyth. From data mining to knowledge dis-covery: An overview. In Advances
in Knowledge Discovery and Data Mining
[11] Zaki, M. J., C. Hsiao. Charm: An Efficient Algorithm for Closed Itemset Mining, Proc. SIAM International
Conference on Data Mining, 2002.