International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 6, Issue 3, March 2016)
251
Enhanced Document Annotation Using Clustering and
Alignment Based Algorithms
Shraddha Awathe
1, Rajeev Saxena
21Dept. of Computer Science Engineering, Sagar Institute of Research & Technology, Bhopal, India. 2
Assistant Professor, Sagar Institute of Research & Technology, Bhopal, India.
Abstract— Web Mining is a technique of analyzing the web database so that it can be used for a variety of applications such as text analysis, natural language processing and searching. Semantic text analysis is one of the efficient techniques of analyzing the text using annotation based searching. Although there are various techniques implemented for the efficient searching using annotations. By identifying the problems with the existing techniques for the annotation of web databases such as alignment problem or to divide into composite text nodes when there are no precise barriers between them Here in this paper an efficient support vector based machine learning approach is applied for the document annotations on various text and words. The proposed methodology implemented is compared with existing methodology implemented for the document annotation. The Result Analysis shows the performance of the proposed methodology. The proposed methodology shows higher precision and recall as well as has high Accuracy.
Index terms— Annotations, Wrapper, Semantic Model, HTML Tags, NLP, Ontology, UIUC.
I.INTRODUCTION
In these days‟s web search knowledge, the link formation of the web takes part in a significant responsibility. In this work, the goal is to utilize semantic correlations for ranking documents exclusive of relying on the existence of any precise arrangement in a document or links connecting documents. People make annotations on documents for a wide variety of personal and collaborative jobs. For individual utilize, annotations can be expensive for summarizing a document or remembering which measurements of it were significant or interesting. Annotations are very usual way to collaborate on a document, as when on condition that comments to other authors. Whether creating annotations for individual or to distribute with additional, annotating straightforwardly on a document permits the annotator to straightforwardly call consideration to exacting parts and give context to notes by their location. Having the circumstance in the document for an annotation permits shorter observations and can enlarge the transparency of an observation for other person who reads, or even the unique annotator after a little bit has leave behind.
Semantic annotation and indexing take place as primary pre-processing steps. For querying, UIMA incorporates competence of retrieval of documents that match either a keyword query in the conventional technique, or a keyword as part of a scrupulous annotation. It is at this point where our method takes the outcomes from UIMA and calculates a score for the documents based on the input keywords. The novelty of their move toward is in by means of semantic associations between entities to establish relevance of documents. In particular, the significance determines primarily gets the annotations within a document that compare the keyword input from user.
Figure-1: Documents Containing Named Entities and their Relationships.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 6, Issue 3, March 2016)
The keyword input from user is interpreted concerning the ontology that imprisons the area of concentration. The documents are expected to be in or connected to such area so that named entity counterpart appropriately to the annotations in documents. It is at this position where the semantics of associations play a significant role.
Annotation is information related to data present and therefore it is useful in organizing the documents. Google base [1] is a sharing tool. Google base is databases used by the Google in that user can proficient to insert any kind of data, for instance text, pictures, videos, etc. It allows the users to define or suggest the characteristics of data besides allow the customers to choose characteristic importance from predefined templates. But these types of tagging or annotation process necessitate enormous quantity of information innovation due to the huge database information discovery.
In previous effort, semantic annotation was serious for an application addressing how semantics can help in the Document-Access problem of Insider Threat [2]. The Semantic Enhancement Engine of Freedom was used for automatic semantic annotation of an undersized i.e., 1K collected works of documents. The indexing of these documents was completed split from the Freedom toolkit and incorporated maintaining path of the named-entities marked by the semantic annotation process. In fact, the experiences expanding such applications show the way to examine other alternatives in respect to architectures/frameworks for processing unstructured data. Existing information sharing implements, like content management software e.g., Microsoft Share-Point, allow customers to share documents and annotate or tag them in an ad hoc technique. Correspondingly, Google Base permits customers to describe attributes for their things or decide from predefined templates. A low level tag association that is originating from collective information may be exploited to specializing state association which is found in the user particular connection [6]. This annotation process can make easy successive information innovation. So there is constraint of an adaptive method for automatically producing data input forms, for annotating unstructured textual documents, such that the process of the introduced data is take full advantage of given the client information needs and an algorithms to effortlessly put together information from the query workload into the data annotation process to produce metadata that are not just appropriate to the annotated document, but also valuable to the users querying the database. If we exploit automated information removal algorithms to take out aimed relations
When we development documents that do not control the under attack in order and they exploit automated information extraction algorithms to remove such fields, we frequently features an important number of false positives which can show the way to considerable excellence difficulties in the data [4].
II.LITERATURE SURVEY
Euardo J. Ruiz, Vangelis Hristidis , and Panagiotis G. Ipeirotis proposed approach in paper “Facilitating Document Annotation Using Content and Querying Value”[1] that is based on CADS (Collaborative Adaptive Data Sharing platform), which is an “annotate-as-you create” communications that creates uncomplicated to their fielded kind of data explanation.. In the process of analytical the substance or data of the document an explanation involvement of their system is the direct use of the type of query workload to direct the annotation process. They were trying to prioritize the annotation of documents in the direction of producing attribute-value pair of attributes that are often used by querying users. The primary goal of CADS infrastructure is to give confidence, sustain and lower the cost of generating complicated and adequately annotated documents that can be useful for commonly issued and type of queries entered semi-structured queries. Their most important explanation objective is to give confidence sustains and make available the annotation of the documents provided or entered at formation instance, though the methods also be used for post creation document annotation while the creator of a particular document is in the stage of “document creation”. Facilitation of Document Annotation using substance and querying importance scheme architecture is shown below.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 6, Issue 3, March 2016)
253 In this paper author D. Eck, P. Lamere, T. Bertin-Mahieux proposed a paper “Automatic Generation of Social Tags for Music Recommendation” [3] The proposed paper suggests the same kind of auto suggestions of tags. This is dedicated to the melodious records; here they are using text based documents. The type of work proposed is preliminary, but the user believes that a supervised learning move toward to auto classification has considerable merit like other system. The next step of the system is to compare the performance of our boosted model to another type of approaches such as SVMs and neural networks. The data set used for these experiments is already larger than those used for publishing results for genre and artist classification. A dataset another order of magnitude larger is necessary to estimated even a little viable database of music. Next further step of the system is comparing the performance of our audio characteristics with other positions of audio characteristics.
A. Jain and P.G. Ipeirotis propose a paper “A Quality- Aware Optimizer for Information Extraction”[4].The respective paper presents and explains the Receiver Operating Characteristic (ROC) curves to compute the removal excellence and assortment of removal constraints. Automated information extraction (IE) algorithms used to remove objective relations or attribute of the document. In this case we should process only documents that essentially hold such information. When they progression documents that do not counterpart with the predefined objectives.
Another document annotation techniques support on extraction of document features. Elements are consider term weight, proper noun, numerical data and thematic word. Before extracting features preprocessing is done. In preprocessing module, all unwanted things like stop words, special symbols are removed and stemming is done. After features of document are extracted and finds feature score and same is provided as input to fuzzy logic. By using summary and annotation label document is a noted.
A keyword-based web search technique put together methods that are found on string or lexical matching of the query terms with the expressions restricted in web documents. Conventionally, keyword-based search is creature employed for the recovery of web documents, without making the significance of these keywords precise in any prescribed method.
There are numerous methods that have been suggested for keyword-based exploration over the web [5] simple Boolean search (mixing keywords using the Boolean operators AND, OR and NOT), wildcard and nearness search, human or subject directed search, thesaurus-based search, fuzzy search, contextual search, keyword location-based search, statistics-location-based search such as Google‟s Page Rank knowledge.
Keyword-based search skill has also been employed to recover SWDs by corresponding query expressions to expressions that lexicalise ontology fundamentals in an SWD. Such a method is creature understand by the Swoogle search engine (Keyword-based retrieval of SWDs). On the other hand, this knowledge does not make use of the semantics of the SWDs and consequently does not create the most excellent of the accessible information. In the most common case, semantic search must be produced as an expansion of the keyword-based one where the syntactic comparison between expressions even though it may present a confirmation for semantic matching, it is not of undeviating attention. Actually, what is significant is the comparison of expressions‟ meaning. For example, a match between the query-expression „book‟ and a document-expression „reserve‟ may be in the approved manner acknowledged if the significance of the term „book‟ is “the reservation of a ticket. Alternatively, a match of the expression „book‟ with an indistinguishable expression found in a web document may be inaccurately recognized, if their meanings are entirely different: The query-term „book‟ may indicate any journal, and the document-expression „book‟ may indicate any condition.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 6, Issue 3, March 2016)
III.PROBLEM DEFINITION
The Existing methodology implemented for the Document Annotation using Content and Querying Value provides an efficient technique for the annotations of the document. The methodology is implemented on Amazon and CNet Datasets. Some composite text nodes failed to be split into correct data units when no explicit separators can be identified so the technique implemented so far has Low Precision and Recall Rate and Less Accurate for other Datasets.
IV.PROPOSED METHODOLOGY
The planned procedure applied here for the Annotations of manuscript Brochures using Gratified and Inquiring Values follows the steps as given below:
1)Take an Input Text Document from which Annotations can be predicted.
2)Extract the important features from the web pages. 3)Compare the Semantic Similarity of each of the word
in the text document
4)Fetch the words having highest Semantic Similarity. 5)Align the Data Units
6)Classify the annotations available using Support Vector Machine based Classifier.
7)Wrapper up the Annotations on the content values and querying values based on the classified instances. 8)Annotate the text Document
.
Semantic Similarity Using Cosine Similarity
Data content similarity (SimC). It is the Cosine similarity between the term frequency vectors of d1 and d2:
Where, Vd is the occurrence vector of the rapports secret statistics unit d, ||Vd|| is the length of Vd, and the numerator is the internal product of two trajectories.
Number Of Common Neighbors
It is defined as the total number of nodes that are connected directly in relationship with node x and y for unweighted network,
Where, Is The Set Of Neighbors Of Nodes X. Is The Set Of Neighbors Of Node Y.
To Compute Link Calculation Among Nodes For
Support Vector Machine
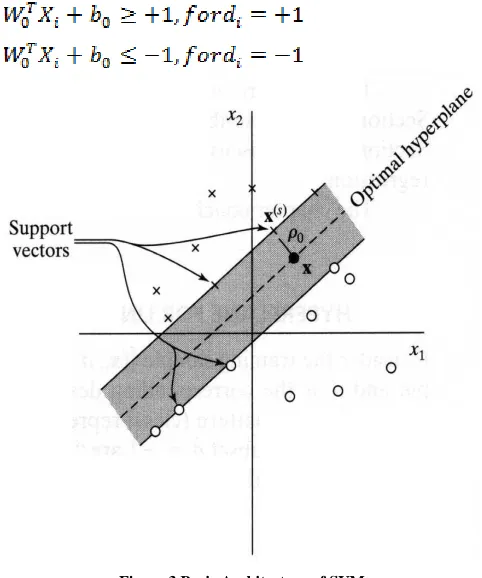
[image:4.612.323.564.216.505.2]Consider training sample where the input pattern is, is the desired output:
Figure 3 Basic Architecture of SVM
The statistics opinion which is actual close is called the boundary of parting
The foremost goal of consuming the SVM is to find the specific hyperplane of which the boundary is exploited
Optimal hyperplane
For example, if we are choosing our model from the set of hyperplanes in Rn, then we have:
f(x; {w; b}) = sign(w . x + b)
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 6, Issue 3, March 2016)
255
Proposed Algorithm
1. Input „T‟ is the Text Document which contains all the annotations and their content values and querying values.
2. Repeat till T[i][j]==null 3. For each C1 in T and C2 in T
4. Compute Similarity(C1,C2) in G using
Sim(C1,C2)=precence(C1UC2)/precence(C1)+precence( C2)- precence(C1nC2)
4 Best Sim(C1,C2)
5 Let be the set of
queries in W that use Aj as one of the predicate condition use
6 For the Content value then Text Document „T‟ with „A‟ attributes that contains some words and text is given by the
7 Compare the probability of each of the attribute in the Document with content and querying values and add to the annotations.
8 Remove text node from Right R (R means right) 9 Add LUR to V (union of left and right)
10 Return V;
Datasets
I CNET: The CNET corpus consists of electronic product reviews obtained from CNET The dataset contains different kinds of products like cameras, video games, television, audio sets, and alarm clocks[7].
II Amazon: The Amazon Products corpus are documents downloaded from Amazon. This dataset also included electronic products, books, Pen Drives and other items that are selling at Amazon[8].
V. RESULT ANALYSIS
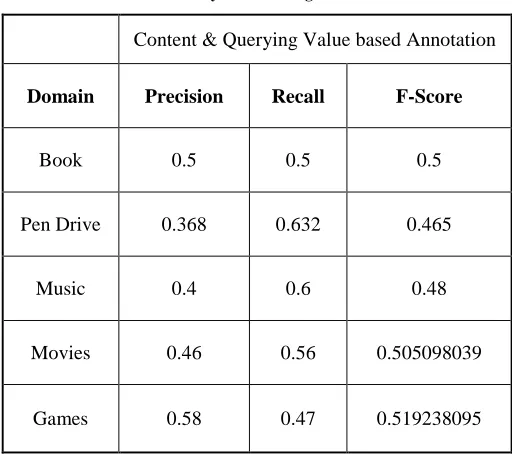
The table shown below is the experimental analysis of the existing technique implemented for Text Documents.
[image:5.612.49.291.255.523.2] [image:5.612.322.578.298.525.2]The result is analyzed on various domains such as Book and Pen Drives and Music and Movies as well as Games. The result is analyzed on the basis of Precision and Recall and F-Score. Here Precision can be computed on the basis of correctly identified annotations to the total number of annotations fetched from the web databases. Recall is the computation of total number of annotations fetch from the web databases to the total number of annotated records present.
Table 1
Result Analysis of Existing Work
Content & Querying Value based Annotation
Domain Precision Recall F-Score
Book 0.5 0.5 0.5
Pen Drive 0.368 0.632 0.465
Music 0.4 0.6 0.48
Movies 0.46 0.56 0.505098039
Games 0.58 0.47 0.519238095
International Journal of Emerging Technology and Advanced Engineering
[image:6.612.47.301.140.408.2]Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 6, Issue 3, March 2016)
Table 2
Result Analysis of Proposed Work
Proposed Work
Domain Precision Recall F-Score
Book 0.65 0.54 0.59
Pen Drive 0.825 0.548 0.66
Music 0.754 0.712 0.7323984
Movies 0.823 0.743 0.7809566
Games 0.632 0.593 0.6118792
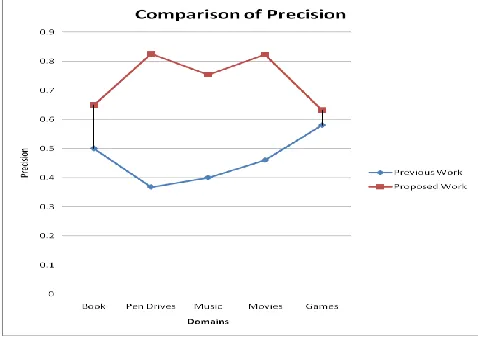
[image:6.612.325.564.232.404.2]The Figure shown below is the experimental analysis and comparison of existing and proposed technique implemented for Text Documents. The result is analyzed on various domains such as Book and Pen Drives and Music and Movies as well as Games. The result is analyzed on the basis of Precision. Here Precision can be computed on the basis of correctly identified annotations to the total number of annotations fetched from the web databases.
Figure 4 Comparison of Precision on various Domains
[image:6.612.323.569.503.700.2]The Figure shown below is the experimental analysis and comparison of existing and proposed technique implemented for Text Documents. The result is analyzed on various domains such as Book and Pen Drives and Music and Movies as well as Games. The result is analyzed on the basis of Recall. Recall is the computation of total number of annotations fetch from the web databases to the total number of annotated records present.
Figure 5 Comparison of Recall on Various Domain
[image:6.612.48.287.515.684.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 6, Issue 3, March 2016)
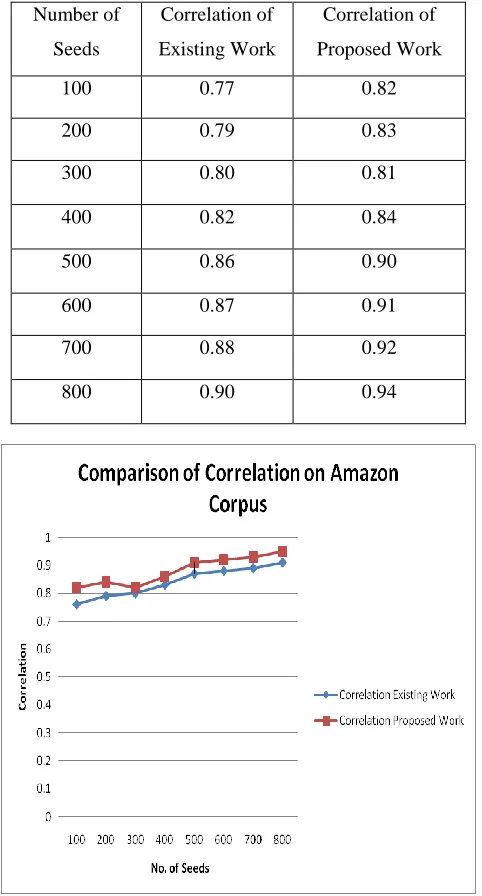
[image:7.612.330.559.230.478.2]257 The Table shown below is the analysis and comparison of number of annotations extracted from the text documents using content and querying based annotation and proposed methodology on Amazon Dataset. The experimental results are performed on Amazon dataset on the basis of various Seed values or keywords.
Table 3
Analysis and Comparison of Correlation on Amazon Dataset
Number of
Seeds
Correlation of
Existing Work
Correlation of
Proposed Work
100 0.77 0.82
200 0.79 0.83
300 0.80 0.81
400 0.82 0.84
500 0.86 0.90
600 0.87 0.91
700 0.88 0.92
800 0.90 0.94
Figure 7 Comparison of Correlation on Amazon Dataset
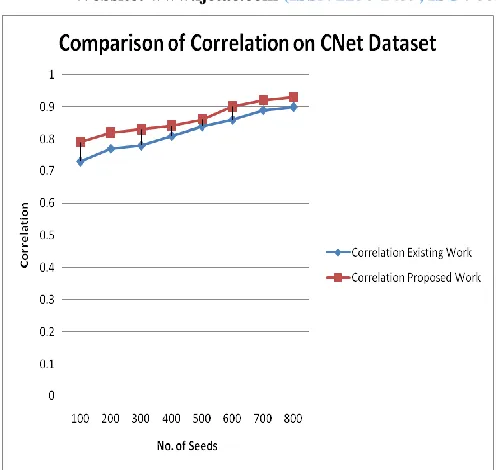
The Table shown below is the analysis and comparison of number of annotations extracted from the text documents using content and querying based annotation and proposed methodology on CNET Dataset. The experimental results are performed on CNET dataset on the basis of various Seed values or keywords
Table 4
Analysis and Comparison of Correlation on CNET Dataset
Number of Seeds
Correlation of Existing Work
Correlation of Proposed
Work
100 0.73 0.78
200 0.78 0.81
300 0.79 0.83
400 0.81 0.84
500 0.84 0.85
600 0.86 0.89
700 0.89 0.91
800 0.90 0.92
[image:7.612.49.290.231.679.2]International Journal of Emerging Technology and Advanced Engineering
[image:8.612.48.296.125.360.2]Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 6, Issue 3, March 2016)
Figure 8 Comparison of Correlation on CNET Dataset
[image:8.612.324.568.126.304.2]The Table shown below is the analysis and comparison of number of annotations extracted from the text documents using content and querying based annotation. The experimental results are performed on Amazon dataset on the basis of various Seed values or keywords. The proposed methodology implemented here provides efficient accuracy as compare to the existing methodology
Table 5
Analysis and Comparison of Accuracy on Amazon Dataset
Analysis and Comparison of Accuracy on Amazon
Dataset
Number of
Seeds
Correlation of
Existing Work
Correlation of
Proposed Work
100 0.77 0.82
200 0.79 0.83
300 0.80 0.81
400 0.82 0.84
500 0.86 0.90
600 0.87 0.91
700 0.88 0.92
800 0.90 0.94
Figure 9 Comparison of Accuracy on Amazon Dataset
VI.CONCLUSION
The Proposed Methodology implemented for the Documents Annotations using Clustering and Alignment based Algorithms provides efficient results as compared to the existing technique implemented for Annotations based on Content and Querying Values. The Experimental results performed on various dataset including Amazon and CNET Datasets. Simulation result shows that, our implemented methodology provides efficient Precision, Recall rate, F-Score, Accuracy and Correlation as compared to the existing methodology
REFERENCES
[1] Eduardo J. Ruiz, Vagelis Hristidis, and Panagiotis G. Ipeirotis proposed “Facilitating Document Annotation Using Content and Querying Value”, IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 26, NO. 2, FEBRUARY 2014.
[2] B. Aleman-Meza, P. Burns, M. Eavenson, D. Palaniswami, and A.P.
Sheth. An Ontological Approach to the Document Access Problem of Insider Threat. In Proc. IEEE International Conference on Intelligence and Security Informatics, Atlanta, Georgia, pages 486-491, 2005.
[3] D. Eck, P. Lamere, T. Bertin-Mahieux, and S. Green, “Automatic
Generation of Social Tags for Music Recommendation,” Proc. Advances in Neural Information Processing Systems 20, 2008
[4] A. Jain and P.G. Ipeirotis, “A Quality-Aware Optimizer for
Information Extraction,” ACM Trans Database Systems, vol. 34, article 5, 2009
[5] Alesso, P. (2004) „Semantic search technology‟, AIS SIGSEMIS
Bulletin, Vol. 1, No. 3, pp.86–98.
[6] D. Yin, Z. Xue, L. Hong, and B. D. Davison, “A probabilistic model
for personalized tag prediction,” in ACM SIGKDD, 2010.
[image:8.612.53.284.491.706.2]